by Max J. Seidman, Dr. Mary Flanagan, Trish Rose-Sandler, and Mike Lichtenberg
Introduction
Purposeful Gaming and BHL: engaging the public in improving and enhancing access to digital texts was a project which ran from December 1, 2013 through November 30, 2015. Funded by the Institute of Library and Museum Services (IMLS) and led by staff at the Missouri Botanical Garden (MBG) along with partners from Harvard, Cornell, the New York Botanical Garden (NYBG) and Dartmouth, its aims were to significantly improve access to digital texts through the applicability of purposeful gaming for the completion of data enhancement tasks needed for content found within the Biodiversity Heritage Library (BHL). This project tackled a major challenge for digital libraries: full-text searching of texts is significantly hampered by poor output from Optical Character Recognition (OCR) software. Historic literature has proven to be particularly problematic because of its tendency to have varying fonts, typesetting, and layouts that make it difficult to accurately render.
The BHL is an international consortium of the world’s leading natural history libraries, that have collaborated to digitize the public domain literature documenting the world’s biological diversity. This has resulted in the single largest, open-licensed source of biodiversity literature made available both through the Internet Archive and through a customized portal at http://www.biodiversitylibrary.org/. BHL is a perfect testbed for investigating alternate solutions to the generation of digital outputs both because it is a significantly large corpus (48 million pages of scanned texts accompanied by 48 million OCR outputs) and because most of its content is historic literature (primarily published between 1450s-1900s). Purposeful Gaming and BHL set out to demonstrate whether or not digital games could be a successful tool for analyzing and improving digital outputs from OCR and transcription activities because large numbers of users can be harnessed quickly and efficiently to focus on the review and correction of particularly problematic words by being presented the task as a game.
Project Design
The basic design approach for Purposeful Gaming and BHL was to take two digital outputs for a text page (from two different sources), identify differences, push only those differences through a game for further verification by players, and extract and interpret the game output.
Preparation of data for the games
The data preparation phase is as follows: Before any data can be sent to the games, it first has to be prepared and run through a workflow to determine if it would be a good candidate. First the team generates two OCR outputs from two different OCR applications. OCR applications, by design, must identify the coordinates of the words on the page to determine the OCR output. They automatically create a bounding box around each recognized word as part of the process. In order to be sent to the games, the coordinate systems and units of measure used by the different OCR application must match. Bounding boxes around words found by each OCR application must also match (or be very close). For example, if the first application locates a word in a document with a bounding box identified by the coordinates
(100, 100), (150, 100), (150, 75), (100, 75)
and the second application locates the same word at the coordinates
(99, 100), (152, 100), (152, 74), (99, 74)
that is acceptable. The bounding boxes are nearly identical. However, if the second application locates the word at
(700, 650), (780, 650), (780, 690), (700, 690)
then clearly the OCR applications are using different coordinate systems to locate the words in the document. Thus, two OCR applications cannot be used together unless the coordinates match, or can be converted to the same coordinate systems.
For the Purposeful Gaming project, the team uses the two OCR applications ABBYY (which produces OCR output in the DJVU format) and Tesseract (which produces output in the hOCR format).
OCR quality
Once two OCR outputs are generated on the individual document scanned, the quality of each OCR output is checked twice to determine the suitability of the document for correction by the game.
Initially, quality is determined by matches to real words. Each OCR output document is compared to dictionaries of known words. The ratio of known words to the total number of words in the document produces a Quality Score for that particular OCR output. If each output’s Score is high enough, then further processing of that document can proceed. (The “high enough” threshold is configurable. For the BHL/Tiltfactor collaboration it was set to 0.7; that is, 70% of the words in the document identified by OCR are recognizable words in a dictionary.)
The next step is to compare the two OCR outputs with one another and assign an accuracy score that provides a measure of the differences between the ‘quality’ scored outputs. The Accuracy score is the sum of 1) the percent difference in total word counts between the two OCR outputs, 2) the percentage of words on which the two OCR applications disagreed, and 3) the percentage of words for which one of the OCR applications produced no output (a blank). If the Accuracy score is low enough, then the page can be corrected by the games. (The threshold for the Accuracy score is configurable. The BHL/Tiltfactor collaboration set it at 0.15). If the Quality Score of either OCR output is not high enough, or if the Accuracy score from the comparison of the two OCR outputs is too high, then the document is not a candidate for correction via the games. In this case, it needs to be manually corrected or transcribed.
The complete workflow for sending data through the game is:
- Create a single OCR output for a document.
- Check the quality of the OCR by comparing it against known dictionaries. Assign an OCR Quality score. The Quality score provides a measure of how good a job the OCR technology did at identifying words in the document.
- If the Quality score is high enough, create a second OCR output for the document with software that uses the same bounding box coordinates.
- Check the quality of the second OCR output and assign an OCR Quality score.
- If both OCR Quality scores are high enough, compare the OCR outputs.
- Generate an Accuracy score. The Accuracy score provides a measure of how well the two OCR outputs match.
- Keep track of the words on which the two OCR technologies did not agree. Be sure to track the coordinates of those words.
- If the Accuracy score is low enough, create Game Inputs and a template for the final corrected OCR. Game Inputs are files containing the words to be corrected by the game, along with the bounding boxes of the words. The template should include placeholders for the words to be corrected by the games.
- Send the Game Inputs to the games.
- Play the games.
- Extract the corrected words from the games and update the final OCR template with the corrected words.
Digitization of seed and nursery catalogs
While BHL’s traditional literature presents its own challenges for OCR software, the project team also wanted to test other types of texts that would present different types of OCR challenges. Seed and nursery catalogs were perfect candidates. “Since the mid-19th century, seed and nursery catalogs have reflected the agricultural and horticultural landscape of the United States. These catalogs—which began as guides to medicinal herbs, and are still printed today—often contain lists of plant varieties and gardening advice. While seed catalogs are used primarily by commercial growers and home gardeners, they also represent an invaluable resource to historians, artists, and researchers of all kinds” (Randall 2014). Their varying column structures, images, tables, and whimsical font designs often confuse OCR software as to the order in which to read the text. Because BHL only contained a small fraction of all the published seed and nursery catalogs in existence, team members decided to digitize them as part of the project activities. BHL Partners at Cornell, NYBG and MBG digitized approximately 1600 catalogs equaling over 100k pages.
Transcription of field notebooks, diaries and catalogs
Field notebooks are another type of text for which OCR software is largely ineffective. These hand-written notes are recorded by scientists during or after an observation event. William Brewster was a renowned American amateur ornithologist (1851-1919) who bequeathed his bird specimen collection to Harvard University along with his journals and diaries which are a “gold mine of scientific observations and a delightful account of years spent exploring the woods, fields, lakes, and rivers of New England” (Paul 2014). Brewster’s notebooks and diaries had already been digitized and made available in the BHL portal so they only needed to be transcribed for this project. BHL partners at Harvard took the lead on selecting and setting up the transcription software as well as enlisting volunteers on two different transcription sites – FromThePage and DigiVol. Two tools were chosen because the team wanted to test the effectiveness of each for the transcription task and also to generate two digital outputs, just as the team did for the published texts.
The Games
The project team hired and collaborated with Tiltfactor laboratory at Dartmouth College to design and create the games.
Carefully choosing target audiences and target devices are crucial steps in the game design process to creating successful game experiences that players want to play. In prior work, Tiltfactor identified two distinct audience motivations for playing crowdsourcing games: the altruistic motivation, in which players are playing primarily to contribute knowledge, and the gameplay motivation, in which players are playing primarily to enjoy the game experience. For our project these audiences turned out to be distinct groups; the altruism-motivated audience tended to be older and have some investment with the Biodiversity Heritage Library (being interested in plants or biodiversity, or being a part of the library sciences). The game-motivated audience skewed younger with no connection to BHL aims or collections. Instead of choosing to craft a single game for both audiences, or choosing to build a game for one audience over the other, Tiltfactor created two games. Smorball was targeted to the game-motivated audience and Beanstalk was targeted to the altruism-motivated audience.
Initial investigations into these audiences revealed a preference for both mobile games and apps. While this was our preferred direction for the games, early game design prototype tests showed that due to on-screen keyboard and small screen sizes, mobile devices did not provide enough screen real estate for players to type words. As a result the games were optimized to be played on desktop computers through web-based browsers.
Smorball
Smorball is a challenging, time based browser game. In Smorball, players take on the role of the coach of the Eugene Melonballers, a fictitious team that competes in the goofy, fictional sport of “Smorball.” Through shrewd tactics and excellent typing ability, players must coach/direct their athletes to victory. The player’s team plays defense in every game of Smorball, and must prevent the opposing players from getting across the field to score in their endzone. As the coach, the player must shout (type) commands to their athletes to tell them when to tackle their opponents. The fewer points the opposing team scores in each match, the better for the player (and their accumulated winnings).

The Smorball title screen.
Smorball is designed for players who play games between casually and regularly, and players who are game-motivated (rather than altruism-motivated): players who don’t care or don’t know about the game’s data correction purpose. The game is intended to be played over multiple sessions, and saves progress locally on the user’s computer.
Gameplay and game mechanics
Smorball is a highly leveled game experience; each level represents one sports match in a national series, leading up to the final match of the season: the “Smor Bowl.” Over the course of the first 3 levels players learn the basics of gameplay, and over the following levels they are challenged to apply the game mechanics more expertly to succeed. The levels are intended to give the game-motivated players a sense of direction and to retain players at least through the course of all of the levels once, with the potential for replaying each of those levels multiple times. At the end of each level, players are scored on how well they did, and this score directly contributes to the currency they accumulate to spend on upgrades. This mechanism lends the game replayability, as players can revisit earlier levels to complete them with a better score.
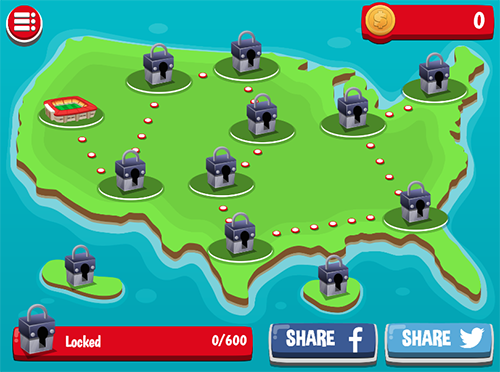
The Smorball map/level selection screen.
During each level, Smorball’s player (the coach) encounters the opposing team’s robots, whom she must stop from scoring by typing commands to her own athletes. Smorball field has three ‘lanes’ down which athletes may run. When opponents come down the bottom lane, for example, the player must type the word shown in the bottom row. If she gets the word correct, her athlete in the bottom row runs forward, tackling the opponent.
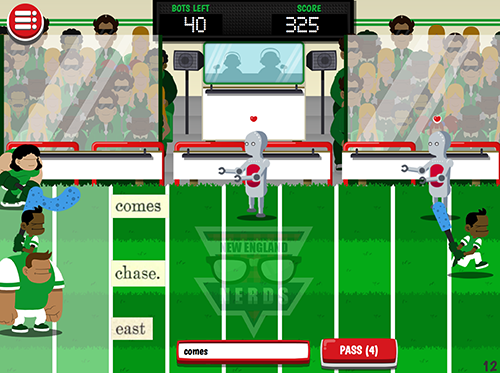
An example Smorball level during gameplay.
Over the course of the game several types of equipment are introduced, which can be picked up off of the field during levels and used by the player at opportune moments to empower their athletes and more efficiently stop the opposing robots. When to use equipment is an important tactical decision that players need to practice in order to become more adept.
At the end of each level, players are given winnings based on how well they performed. Each level has a maximum payoff, and the winnings are reduced for each point the opposing team scores against the player. Players can then use these winnings to purchase upgrades for their team including: the ability to start each level with one unit of each type of the aforementioned equipment, more frequent equipment spawning on the field, increased knockback, increased damage on long words, shorter cooldowns on mistakes, and more.
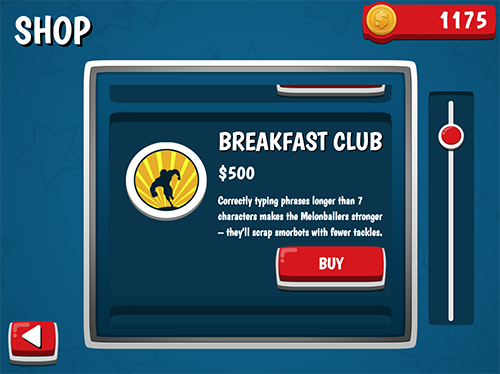 The Smorball shop where players can spend their winnings to upgrade their teams.
The Smorball shop where players can spend their winnings to upgrade their teams.
Smorball uses a hybrid automatic leveling system, as well a as manual system to adjust for players’ differing typing abilities. During the first level, the game measures players’ typing and gameplay proficiency and sets a recommended difficulty: easy, normal, or hard. This difficulty can then be changed manually by the player via the menu screen. The game relies on time pressure, scoring motivation, and incremental challenges to encourage players to persist in the game, which in the end decodes more words. A typical Smorball game level presents 30-60 words for players to correct.
Beanstalk
Beanstalk is a non-time based web browser game in which players tend to a budding fictional bean plant that must be “spoken to” in order to grow. As the player types words correctly to “speak,” an eclectic assortment of leaves and flowers sprout from the beanstalk, and the beanstalk grows higher and higher into the atmosphere and sky. Should the player make a mistake while typing a word, the beanstalk shrinks a small amount. The plant starts off as a seedling, growing among blades of grass. When the player reaches the stars, her beanstalk drops another seed, and she can start a second stalk.

The Beanstalk title graphic.
Beanstalk is designed for altruism-motivated players who are playing in order to contribute to the Biodiversity Heritage Library’s collections, and whose game experience ranges between ‘zero experience’ and ‘some experience in the past, but no recent experience.’ The game is intended to be played over multiple sessions, and will save progress to the user’s account (if signed in), or locally on the user’s computer (if not logged in).
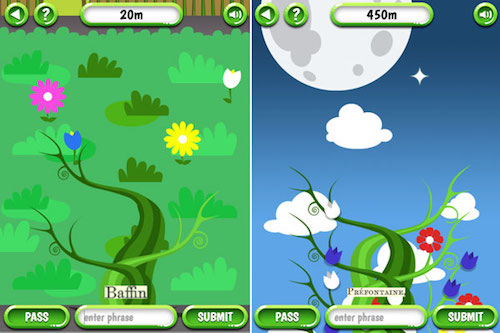
Beanstalk gameplay screens showing a small initial beanstalk after very few words have been typed (left) and a larger beanstalk after more words have been typed (right)
Game Mechanics
Beanstalk is an extremely easy game with no time constraints. The reward for players are changes in the background and growth of the plant, with some hidden animations that change each round. Because of the lack of time constraints and compact screen size, Beanstalk can be played on phone and tablet browsers as well as desktop browsers. For players who are so inclined, Beanstalk features leaderboards to compare the height of their plants (and thus the amount of data they have corrected) with other players’ successes.
Game Design Approach
Design Goals
In order to create compelling game experiences, games need to be able to immediately reward players for positive decisions, and either withhold rewards from or penalize players for negative decisions (Fullerton 2014). This poses a clear problem for crowdsourcing games since, by definition, crowdsourcing is typically applied in cases where one cannot computationally identify the correct answers to the problems they are trying to solve.
Because the task of correcting OCR outputs is most effective and accurate if corrected through the act of typing out words, we adopted the approach used by many typing training games. To approximate the feel of a commercial typing game that would be familiar to players, the Tiltfactor team tested several approaches to estimating the correctness of players’ inputs, so that the games could give players appropriate game feedback (such as gaining points when correct, and playing a buzzer noise when incorrect). The end goal of each of these playtests was to maximize true positives (marking the player ‘correct’ when typing the word correctly) and true negatives (marking the player ‘incorrect’ when making a typo), while minimizing false positives (marking the player ‘correct’ when in reality, the player made a typo), and false negatives (marking the player ‘incorrect’ when, in fact, the word was typed correctly). The goal is to help the players feel as though the game knows when their input is correct and when it is incorrect.
Research conducted by Tiltfactor has shown that games intended to change players’ attitudes are found to be more engaging when the players aren’t aware of the games’ attitude change goals (Kaufman and Flanagan 2015). Because of this research, during the design of Smorball and Beanstalk Tiltfactor operated under the assumption that general gamers with no connection to the Biodiversity Heritage Library or crowdsourcing would find crowdsourcing games less fun than traditional commercial games. To this end, one of the major design goals of Smorball was to make the crowdsourcing purpose of the game invisible to players; Smorball was intended to appear to players as a commercial typing game, such as Typing of the Dead.
Past Solutions and Limitations
Comparison to previous players
Crowdsourcing games traditionally judge ‘correctness’ of player inputs by comparing them to previous players’ inputs for the given word; if someone (or multiple someones) previously submitted the same input, then the current player is marked as ‘correct.’ Otherwise, the current player is marked as ‘incorrect’ (Chrons and Sundell 2011). This approach can solve the problem of providing correct feedback to players, with two rather noticeable exceptions: when new databases of words are uploaded, since no players have played them yet, these words will have a 100% false negative rate–everyone who plays them will be marked incorrect when they type the word correctly. On the other end of the spectrum, once words have been played many times, many different typos and other incorrect inputs will have been logged. If a player types one of these many typos, she will be marked as correct; in other words, the false positive rate will be very high.

Problems with the “Comparison to Previous Players” method of judging player accuracy in crowdsourcing games.
Comparison to current players
Some crowdsourcing games have attempted to solve the shortcomings of the comparison to previous players approach by instead pairing current players together synchronously, and comparing them to one another (von Ahn 2006). While this solution works in theory, in practice it is dependent upon a consistent player base which is a challenge for most games. When a player can be found to match against, both the start of project and late in project problems are alleviated. In addition, games that implement this solution can experience subversion problems if players can communicate with one another and collude to match each others’ inputs without those inputs being actually correct.
Comparison to golden set
A second solution to the shortcomings of the comparison to previous players approach is to temper it by intermittently giving the player words with known solutions, and using the player’s performance on the known ‘golden set’ words to infer their performance on the actual crowdsourcing work. While not often used in games, this approach has been used very successfully for ReCaptcha (von Ahn et al. 2008), software designed to test for human users instead of bots. ReCaptcha gives users images of two words: one known to the system, and one unknown to the system; the software then infers the user’s input correctness on the unknown words based on their accuracy on the known words. With a large enough golden set, this approach solves the problems many projects face when starting in that there is no previous player data against which to refer.
Unfortunately, this method is not well suited for use in games for two reasons. First, ReCaptcha software was relying on many users each doing only one data correction. Games typically aim to attract fewer players in favor of more time (and thus more corrections) per player. Even with a golden set that grows from user input, at least a few users typing multiple words would begin to see the golden set items repeated, and the game would be ripe for subversion (players could identify the golden set item since they had seen it before, and then willfully mislead the game on the unknown words). Second, while this method minimizes false negatives by having a golden set with a high confidence solution (presumably typed by a trustworthy source), it provides a very high rate of false positives. When a player makes a typo, there’s a roughly 50% chance that the typo will occur in the unknown word, and will be accepted by the game as ‘correct.’
Smorball and Beanstalk Solutions
Smorball and Beanstalk have a leg up on other crowdsourcing transcription games and tools in that they are not truly transcription games; they are OCR data correction games. Because every word to be typed was guaranteed to have two OCR readings associated with it, the game development team chose to use these OCR readings to determine player accuracy, thus resolving the start of project problems that tools and games using the comparison to previous players approach fell prey to.
Initial attempts
Initially, the research and game development teams worked under the assumption that of the two OCR readings for each word, one would be correct and one would be incorrect. This would allow for a very simple matching algorithm: if the player types one of the two OCR readings, they are marked correct and that reading is recorded in the database as correct. This would provide a low rate of false positives, as any typo would have to coincide with the wrong OCR reading to be wrongfully marked as correct, and as long as one of the two readings was always correct, there would be zero false negatives.
Working with a sample set of over 500 words, it quickly became clear that while some words had one correct OCR reading, many did not, as shown below. This obviously posed a problem: while better than nothing, direct comparison to OCR for these pages would result in false negatives roughly 50% of the time.
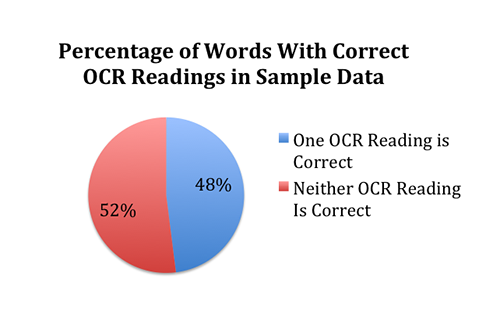
The percentage of words in sample data provided by the BHL which have one correct OCR reading.
Over the long term, this problem would be solved by the game team’s choice to combine the OCR comparison approach with the comparison to previous players approach. This way, only one player would ever need to feel the frustration of typing the word correctly and being marked ‘wrong.’ Subsequent players would type that same word correctly, and be matched to that first player’s input, and thus marked correct. Over the short term, however, the game team deemed this problem untenable, as initial players of the games would surely be driven away when half of their inputs were marked incorrect. It became clear that the games would need a more sophisticated algorithm to infer player accuracy.
Longest common substring
The game team developed a modified longest common substring (LCS) algorithm for this purpose. Simply put, this algorithm compares the two OCR readings to find character sequences upon which they agree, and requires the player’s input to contain those sequences in order to mark the player as correct. In the diagram below, the arrow character pointing to the right refers to the start of a word, and the arrow character pointing to the left to the end of a word.
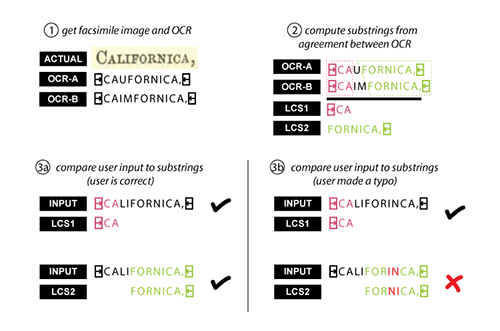
Illustration and example of the modified longest common substring algorithm used by Beanstalk and Smorball.
Applying this algorithm to the sample data set proved its use; while direct comparison to OCR would yield false negatives 52% of the time, adding in the LCS algorithm resulted in false negatives for only 3% of the words. These false negatives occurred only when both OCR readings agreed on an incorrect interpretation of a letter. User testing showed that at this frequency, when a false negative did occur players would often assume that they themselves had made an unnoticed typo rather than attributing the error to the game. Since there is an unknown portion of every word, every word does have the potential to result in a false positive if the player’s typo happens to fall in the unknown portion. However, because the unknown portion of each word is usually rather small, this means that the chance to throw a false positive is equally small. This is much improved over using a “ReCaptcha-style” method where false positives occur at minimum 50% of the time.

The percentage of words in sample data provided by the BHL that can have their correct answers identified algorithmically by either the LCS algorithm or having one OCR reading correct.
All together now
Combining the LCS algorithm, comparison to other players’ inputs, and direct comparison to OCR readings into a three tiered approach, Smorball and Beanstalk are able to, with great success, infer players’ data correction accuracy for any given word and provide player feedback with minimal false negatives and false positives.
Upon a player’s submission of a word, the games’ first check is to compare that word to both OCR readings, and any previously accepted player submissions. If the player’s word matches any of those, that entry in the database has its score increased by 1, which will eventually be used to select the most accurate answer. This check serves two purposes. First, it reduces tax on the game, as in approximately 50% of all OCR disagreements, one of the OCR readings is correct. Second, this check begins to mediate the few cases in which the LCS algorithm marks correctly typed words as incorrect. Since previous players’ submissions are also possibilities for this check, even in cases when neither OCR is correct, and the LCS algorithm fails, players will still often have their correct answers marked as correct. In essence, in the 3% of cases where neither OCR option is correct and the LCS algorithm fails, a single player will be frustrated by being marked ‘incorrect’ when she should be marked ‘correct’ for that word once, and all future players will be rewarded correctly.
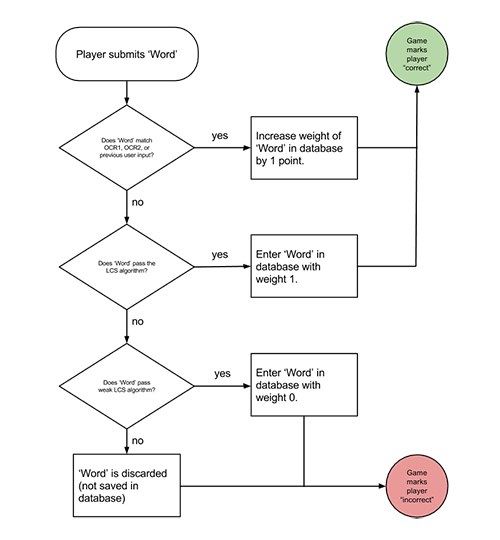
Logical flow for saving player inputs to the database in Beanstalk and Smorball
If the player’s word matches neither the OCR readings nor previous submissions, the game system runs the word through the LCS algorithm. This is particularly relevant in the approximately 48% of cases where neither OCR output is correct, for OCR disagreements that haven’t been played before. In these cases, if the player’s word passes the LCS algorithm, it is inserted into the database as a new option for future players to input, and the player is marked ‘correct.’
If the player’s word matches none of the above, it is checked against a weaker LCS algorithm, which allows for a specific number of character discrepancies from the LCS. If it passes this algorithm, then one of two things has happened: either the player made a small typo, or the original LCS algorithm failed. Because it might be a typo, the game marks the player as ‘incorrect.’ However, because it’s possible they typed the right word and the LCS algorithm failed, their submission is still entered into the database to see if future players agree with it. If their word fails the weak LCS algorithm, however, it bears no relation to the OCR output and can be safely discarded as a garbage word. This prevents players from being able to ‘seed’ the database with garbage words to attempt to ensure future matches.
Project Results
Both games were released to the public on June 9, 2015. Once deployed there was a significant amount of activities involving publicity and promotion of the games, which Harvard and all project partners did through multiple channels. These included both print media (regional newspapers, academic journals, university publications) and social media (blogs, Facebook, Twitter) as well as presentations at both national and international meetings,workshops, and seminars. There were two on-site gaming sprints (one held at the Boston Festival of Indie Games and another at the New York Botanical Garden’s Mertz Library). An online sprint called “Data Dash” (BHL Data Dash 2015) was held at the end of the project to encourage one final data collection push.
Both games drew over five thousand participants in just under six months[1]. There were over 140,000 words typed and at its peak there were 8000 words per day and 1000 sessions per month. Smorball was the clear favorite of the two, generating 61% of participation and even garnering the “Best Serious Game” award at the Boston Festival of Indie Games (BFIG). The award itself was presented by Cambridge City Councilor Leland Cheung, who spoke about how playing Smorball is “more than just playing a game – it’s a form of civic engagement”. Clearly, gaming with a purpose has earned a level of respect on par with gaming as entertainment in the field of game design and is being valued for its contributions to society.
Both altruism-motivated and game-motivated players reacted positively to the games, and competition amongst them often became heated. Reviewers at BFIG had this to say about Smorball:
“The world of the sports game isn’t innovative or unique, but it’s an original made-up
game where humans get to smash robots, which makes it fun to watch and play.”
“I do feel that this is a complete game, very polished, and addictive.”
These sentiments were echoed by players, and are representative of the game’s reception in general: players enjoy Smorball on its own, even without knowing its prosocial goals. Often, players do not notice that it is anything more than just a web game.
Project Challenges
Despite the critical success of the games, there were some challenges along the way that diminished some of their overall impact for the BHL. These include being unable to automatically generate coordinates for hand-written texts and catalogs and being unable to collection enough data from the games to be able to apply the corrections to the full BHL corpus.
Lack of coordinate information for hand-written outputs
In order to include a word in the game, coordinate data is needed to be able to link the text output of a word to an image of the word on the page. This data is then used to generate a picture of the word for display to players in the game. OCR software automatically generates coordinates for these words, but transcription tools for dealing with hand-written text do not. None of the six transcription tools that the project team reviewed could provide this functionality [2]. The team identified a few other tools[3] that attempted to provide the text to image linking services, the most viable of which is called TILT2 , and is being developed at the University of Queensland Australia. This tool, while a likely candidate for preparing hand-written texts for the games, was not fully developed enough to be used within the timeline of our project. Without the coordinates, we were unable to include words from Brewster’s handwritten documents or the horticultural catalogs through the games for further verification. While disappointing, we still had the two outputs generated from the transcription tools for these documents which were used to replace the poor quality OCR in the BHL portal.
Unable to reach a critical mass of data
Another challenge was our inability to generate a critical mass of data corrections needed to be able to apply them to the larger BHL corpus of 48 million pages. While over 140,000 words have been typed since the games were released, this has resulted in only 7,821 words and 330 pages entirely completed. We believe there were three primary factors that contributed to this outcome: 1) lack of a robust marketing strategy; 2) a limited data collection period; and 3) too high of a player agreement threshold in the game design.
Marketing
Despite employing a wide variety of marketing strategies we did not draw the number of players we had hoped. Although several media outlets covered the games, none of them had a high enough readership profile to draw a significant number of players. The project needed a large media outlet such the NYTimes or a celebrity endorsement to be able to garner more attention and none of the marketing strategists at the partner institutions had these contacts. One of the lessons learned is to have a more robust marketing plan with significant time and resources devoted to it because it is critical in getting uptake of your games.
Data collection period
The data collection period was only six months from the time the games were released until the project end date. Considerable time was spent at the beginning of the project developing and broadcasting the request for proposals, as well as selecting and hiring a game design team. In hindsight, the project team should have had a game designer selected before the project began. This would have allowed for game development to begin earlier in the project and allowed for an earlier release date, thereby resulting in more time for data collection.
Player agreement threshold
An additional factor had to do with the games’ level of player agreement needed for a word to be considered “complete” and thus be removed from the system. When using untrusted users for crowdsourcing work, “agreement” scores are used to minimize the likelihood that any single mistake or intentional subversion will be included in the final data. Instead of marking a word “complete” as soon as one player has typed it, the games wait for multiple players to type the same word, and mark it “complete” if there is a sufficient level of agreement between what the players type. Clearly, the determination of this score results in a trade-off between accuracy and efficiency; a high required agreement score would result in many players having to type any word, but a low agreement score could result in accidentally including incorrect data in the final dataset. When the games were released the agreement score was set to 4 (i.e. a minimum of 4 people had to agree on a word before it was considered “complete”). This could require anywhere from 4-12 or more plays of a word before agreement is reached. It wasn’t until about five months after the games were released the team decided to lower this threshold, which significantly reduced the time needed to complete words and pages. Whether the lowered score negatively impacted the quality of the data corrections has yet to be determined.
Conclusions
The result of not being able to collect a critical mass of data corrections means that the benefits to the BHL corpus are limited for now. Our original plan was to use the corrections to create a robust error matrix that would automate further cleanup of the entire corpus, thereby enabling results from the game to become much more scalable. Instead we had to opt for a “proof of concept” matrix to illustrate how it could be applied in the future once the data corrections reach a certain tipping point.
These challenges, however, do not diminish the overall impact of the project’s benefits to the larger digital library community. The primary aim was to demonstrate whether or not digital games could be a successful tool for analyzing and improving digital outputs from OCR and transcription activities. We believe the games developed for this project successfully proved how human verification of texts could succeed where machines had failed; most people are not willing to sit down and transcribe an entire page from a manuscript. By combining the efficiency of crowdsourcing with the enjoyment and motivation of gameplay, Smorball and Beanstalk elevated a normally tedious task into an activity full of wonder, reward, and action.
We believe the project’s games will become a model for intersecting gaming with crowdsourcing in the cultural heritage sector. When we wrote our original proposal at the beginning of 2013 we noted that despite the uptake of games and crowdsourcing in the museum communities, games have been underexploited in the library community and we would argue little has changed since then. A review of the 2015 New Media Consortium’s Horizon reports for both libraries (Johnson 2015) and museums ( Johnson 2015) confirms that museums continue to take the lead on use of gamification and crowdsourcing in their digital strategies.
In addition to the games, the architecture we developed for managing game input/output and the data preparation workflows provide a roadmap for how other libraries can embark down a similar path. We hope our strategies and outcomes provide the confidence needed for other libraries to engage in similar projects. In this spirit, we have tried to document, in as much detail as possible, our activities on our project website, and in this article.
Notes
[1] Exact count was 5,327 players and 7,122 sessions between the two games (composed of Smorball 4365 sessions/3,326 players and Beanstalk 2,757 sessions/1,911 players)
[2] Transcription tools reviewed included: Smithsonian Transcription Tool (https://transcription.si.edu/); FromThePage (http://fromthepage.com/); Transcribe Bentham (http://www.transcribe-bentham.da.ulcc.ac.uk/td/Transcribe_Bentham); DigiVol (http://volunteer.ala.org.au/); Transcribe http://www.archives.gov/citizen-archivist/transcribe/; T-PEN (http://t-pen.org/TPEN/)
[3] Other Text to image linking tools revewed included: TextGrid (https://wiki.de.dariah.eu/display/TextGrid/Main+Page); TILE (http://mith.umd.edu/tile/); Alethia (http://www.primaresearch.org/tools)
References
- BHL Data Dash. [Internet]. 2015.[cited 2016 Apr 2]. Available from: http://blog.biodiversitylibrary.org/2015/12/bhl-data-dash-dec-7th-9th-2015.html
- Chrons O, Sundell S. 2011. Digitalkoot: Making Old Archives Accessible Using Crowdsourcing. Human Computation [Internet]. [cited 2016 Feb 08]; 20-25. Available from: http://cdn3.microtask.com/assets/download/chrons-sundell.pdf
- Fullerton T. 2014. Game Design Workshop. Boca Raton (FL): CRC Press. p. 99-100 (COinS)
- Johnson, L., Adams Becker, S., Estrada, V., and Freeman, A. 2015. The NMC Horizon Report: 2015 Museum Edition [Internet] Austin, Texas: The New Media Consortium. [cited 2016 Apr 22]. Available from: http://cdn.nmc.org/media/2015-nmc-horizon-report-museum-EN.pdf
- Johnson, L., Adams Becker, S., Estrada, V., and Freeman, A. 2015. The NMC Horizon Report: 2015 Library Edition [Internet] Austin, Texas: The New Media Consortium. [cited 2016 Apr 22]. Available from: http://cdn.nmc.org/media/2015-nmc-horizon-report-library-EN.pdf
- Kaufman G, Flanagan M. 2015. A psychologically “embedded” approach to designing games for prosocial causes. Cyberpsychology: Journal of Psychosocial Research on Cyberspace [Internet]. [cited 2016 Feb 08]; 9(3). Available from: http://cyberpsychology.eu/view.php?cisloclanku=2015091601
- Paul, E. 2014. Step back into ornithological history. [Internet]. [cited 2016 Apr 22]; Available from: http://ornithologyexchange.org/articles/_/community/step-back-into-ornithological-history-r182.
- Randall, P. 2014. The Stories Seeds Tell [Internet][cited 2016 Apr 22];. Available from: http://blog.biodiversitylibrary.org/2014/11/the-stories-seeds-tell.html
- von Ahn L. 2006. Games with a purpose. Computer [Internet]. [cited 2016 Feb 08]; 39(6): 92-94. Available from: http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=1642623
- von Ahn L, Maurer B, McMillen C, Abraham D, Blum M. 2008. reCAPTCHA: Human-Based Character Recognition via Web Security Measures. Science [Internet]. [cited 2016 Feb 08]; 321(5895): 1465-1468. Available from: http://science.sciencemag.org/content/321/5895/1465
About the Authors
Max Seidman is a Game Designer at Tiltfactor, the game design and research lab at Dartmouth College, where he designs impactful digital and tabletop games for health, equality, and knowledge. His formal training lies in engineering and human centered design.
Mary Flanagan is the founding director of Tiltfactor and the Sherman Fairchild Distinguished Professor in Digital Humanities at Dartmouth College.
Trish Rose-Sandler is the Data Projects Coordinator for the Center for Biodiversity Informatics at the Missouri Botanical Garden. She served as principal investigator for Purposeful Gaming and the BHL project.
Mike Lichtenberg is a Senior Consultant with SBS Creatix. In that role, he has worked at the Missouri Botanical Garden since 2007 as the developer for the Biodiversity Heritage Library. Prior to entering the library non-profit world, he earned experience in varied industries including retail, travel, insurance, engineering, agriculture, healthcare, education, and professional sports.

Subscribe to comments: For this article | For all articles
Leave a Reply