By Katherine Perdue
Background
In 2010, the University of Mary Washington participated in the Lyrasis Mass Digitization Collaborative (MDC), an initiative partially funded by the Alfred P. Sloan Foundation that helped libraries complete digitization projects that they would not have had the resources to accomplish on their own.. Lyrasis partnered with the Internet Archive to host digitized materials so that they would be accessible to users all over the world [1]. UMW digitized five collections through the MDC: academic course catalogs from 1913-2013, the alumni magazine, 1939-2011, the Aubade literary magazine, 1971-2010, the Battlefield Yearbook, 1913-2010, and the Bullet student newspaper, 1922-2010. Together they comprise some two thousand documents and a century of UMW history. Over the course of the next four years, these collections were added to the Internet Archive, with the final issues of the Bullet uploaded in the spring of 2014.
The Internet Archive does not offer detailed usage statistics, but it does provide number of views per day per item [2]. UMW’s content is all held within the University of Mary Washington collection, so therefore it is possible to see views per month for the entire collection. Usage has increased steadily since January 2011, totaling nearly 350,000 views [3].
It is difficult to say anything definitive about who these users are. Some of the spikes in usage correlate with times the Libraries were adding to the collection or doing maintenance, and surely represent library staff use. What is clear from looking at the Libraries’ statistics is that most usage did not originate from the Libraries’ website [4]. In a five month period from July 2014-November 2014 (during which there were almost 44,000 views), links from the Libraries’ website to one of the Internet Archive collections were clicked 160 times. The Bullet newspaper was the most popular at 64 times, and the Aubade literary magazine, the least, at only 6. It is possible that our patrons were able to find the collections through other means: through Google perhaps or by going directly to Archive.org. However, it is equally possible that users affiliated with UMW, students, faculty, and alumni, failed to find the collections at all: collections that should have have been highly relevant to them.
Moreover, although Lyrasis and the Internet Archive allowed us to digitize and make available collections that we would never have been able to host on our own, they did not do so in a way that allowed our patrons to accomplish what they most wanted from an online archive. Looking back at our records of reference questions, the most frequent request was to find all mentions of a specific person, event, building, or UMW tradition: be it alumni looking for articles about themselves or that they wrote when they were on the Bullet staff, family members in search of their mother’s yearbook photo, researchers trying to find information about the construction of the amphitheatre, or students looking for pictures of Devil-Goat Day [5] festivities long past. Previously, the only way to find such material was to consult the Bullet Index, a detailed subject index first on cards and later online as a series of PDFs. However the index was cumbersome to use and only covered materials through 2004. There was no index for the other collections. The way modern users expect to find such information is via full-text search.
When a file is added to the Internet Archive, an OCR’d text is automatically created. It is easy to search within the text of each item. It is not possible, however, to search within multiple items: to find, for example, as one student wanted to do, all mentions of Apartheid anywhere in any issue of the student newspaper. Each issue would have to be searched separately. The student in question elected to page through paper copies instead.
The Libraries do not have vast reserves of server space. For the present, it isn’t feasible to host all of our digital collections ourselves. Additionally, we have no desire to replace or duplicate functions that the Internet Archive is already fulfilling. We are happy with the way that items are presented there: the Book Reader viewer is a pleasant way to read and users are able to download content in many different formats. We simply wanted to make sure that our patrons were able to view our collections in a way that was cohesive and coherent and that allowed them to find the information they most wanted. To accomplish these goals, we built Eagle Explorer (named for our mascot), an interface and search engine for UMW’s Internet Archive collections [6].
The Project
We chose to use the Apache Lucy search engine library to power Eagle Explorer. Lucy is a “‘loose’ port” of Lucene in C with Perl bindings [7]. Lucy worked well for us because we were already using Perl for several other library projects and Lucy’s features met our needs for this project. It allows for Boolean search and (of particular interest in this case) range searching, so that users could search within a date range. It is also fast, easy to set up, and modular, with many options for tweaking results [8].
To build the index, the first step was to obtain the text for all items. The Internet Archive uses a predictable URL structure: if the identifier for an object is known, it’s possible to deduce the URL for the text (https://archive.org/stream/IDENTIFIER/IDENTIFER_djvu.txt) and many other useful views (the Book Reader viewer, for example, at https://archive.org/stream/IDENTIFIER, and the cover image at https://archive.org/services/img/IDENTIFIER). Because of this, it was easy to automate the download using our list of identifiers.
Once we had the text archive, we chose five fields to index: identifier, title, content (the full text), date, and source (which publication the document was from). The identifier and source we already had and the content we had just downloaded. The title and date were trickier to obtain. Because the Lyrasis MDC project had occurred over a period of four years, during which there was staff turnover both at Lyrasis and UMW, no consistent naming convention had been applied to identifiers. Most identifiers contained at least the year and some form of the title, but even within the same publication, the exact formatting varied. Some did not contain a date at all. For these, we used screen scraping (using Web::Scraper [9]) to pull the title, which did contain the date, off the Internet Archive page at the same time we were copying the text.
for my $id (@identifiers) {
sleep 2; #Two second delay between items to be polite
my $url = "http://archive.org/stream/$id/" . $id . "_djvu.txt"; #location of full text
my $scraper = scraper {
process "div.container pre", fulltext => 'TEXT'; #div containing full text
process "div.container h1 a", title => 'TEXT'; #div containing title
};
… }
Further complicating our efforts, the Alumni magazine had changed titles eight times and the course catalog, eleven; not surprising at a school that has changed names almost as many times. With much parsing and massaging of data, we managed to extract consistent titles and dates that at the very least included the year from all items.
A good example of this process is the 1952 Spring issue of the alumni magazine. The identifier for this item is “alumnaeassociati00univ”, which gives no clue about the date. The title in the Internet Archive is “Alumnae Association – News Bulletin, 1952 (Spring)”. Although date formats were not consistent in titles (they might also appear as “Alumnae Handbook and the News, 1942-43” or “Alumnae News, 1961 (February)”) the format [title],[date] was consistent, so we were able to separate the two and extract only the date. Ultimately, it proved short-sighted not to retain the title as well, since this was something we had to deal with again in a later step. At this point, we had a file that contained the full text of the issue and was named “alumnaeassociati00univ,1952 (Spring).txt”. A series of Unix shell commands converted the various season and month names to numbers. In this case:
for filename in *\(Spring\)*; do mv "$filename" "${filename/ \(Spring\)/-03}"; done
leaving us with “alumnaeassociati00univ,1952-03.txt” ready to be indexed. During indexing, we used the identifier to distinguish between eight possible alumni titles; anything beginning with alumnaea was translated to ‘Alumnae Association’ versus alumnaeb, which would have made it ‘Alumnae Bulletin’, and so on.
Lucy uses ‘analyzers’ to filter text before matching it to a query [10]. Applying these analyzers is part of the indexing process. For identifier, title, date, and source, we did not use any analyzers, since they contained exact values and finding near matches would not be useful. For content, we found that the defaults used in Lucy’s Easy Analyzer module suited our purposes. Easy Analyzer combines Lucy::Analysis::StandardTokenizer, which splits strings into words, Lucy::Analysis::Normalizer, which normalizes to unicode, and Lucy::Analysis::SnowballStemmer, which is language specific and reduces words to their roots, so that searching for ‘horses’ also returns results for ‘horse’. In the future, we may want to investigate whether using different Analyzers would improve search results. In particular, the stemmer is over-aggressive: searching for “John Williams” in quotation marks should not return results for “John William”. However, for now, this approach works well enough.
It was important to us that users be able both to search for specific keywords and to browse by date. The interface for Eagle Explorer features a timeline at the top [11]. In browse mode, the user selects a year on the timeline, then can move forwards and backwards in time by pressing the arrows on either side or moving the marker on the timeline [figure 1]. Matching titles and their covers are displayed below and if a user clicks on one, the Internet Archive page in Book Reader view opens in an iframe [figure 2]. If the user enters a search term, then the timeline shows an expandable date range instead of a single year. The term must occur between the two years indicated. If the user changes the values on the timeline, a new search is run. The user may also choose to change the sort order from relevance to date. At any time, users may also choose to limit the search to one publication source or to search all of them at once.
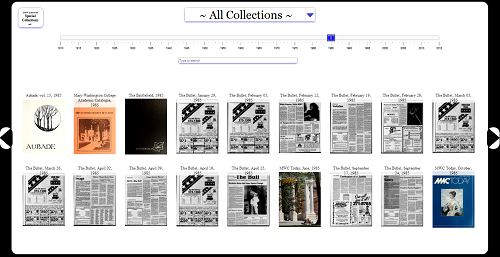 Figure 1. Eagle Explorer Timeline selector
Figure 1. Eagle Explorer Timeline selector
 Figure 2. Internet Archive Book Reader in iframe
Figure 2. Internet Archive Book Reader in iframe
All of this requires slightly complex search logic. Fortunately Lucy allows multiple search queries to be combined via Lucy::Search::ANDQuery. The relevant code follows, but in brief, if there is a search term, it is parsed and the results are then limited by date or date range and by source if set, then ordered by date or relevance. If there is no query, then all items are treated as a match, then limited down in the same way.
my $searcher = Lucy::Search::IndexSearcher->new(
index => $indexpath,
);
my $qparser = Lucy::Search::QueryParser->new(
schema => $searcher->get_schema,
);
if ($q ne '') {
#If there is a query, then parse it
$query = $qparser->parse($q);
}
else {
#If no query, match everything
$query = Lucy::Search::MatchAllQuery->new;
}
my $rangequery = Lucy::Search::RangeQuery->new(
field => 'date',
lower_term => $afterdate,
upper_term => $beforedate,
include_lower => 1,
include_upper => 1,
);
#Limit the results by the date range
$query = Lucy::Search::ANDQuery->new(
children => [ $query, $rangequery ]
);
my $sourcequery = Lucy::Search::TermQuery->new(
field => 'source',
term => $source,
);
#If a source is selected, limit the date range query by source
if ($source ne "all") {
$query = Lucy::Search::ANDQuery->new(
children => [ $query, $sourcequery ]
);
}
my $sortspec = Lucy::Search::SortSpec->new(
rules => [
Lucy::Search::SortRule->new( field => 'date' ),
],
);
#If searching, not browsing, keep the default relevancy sort
if ($type eq 'search' && $sort ne 'date' ) {
$hits = $searcher->hits(
query => $query,
offset => $offset,
num_wanted => $page_size,
);
}
#Otherwise, if browsing or if the user wants to sort by date, sort by date
else {
$hits = $searcher->hits(
query => $query,
offset => $offset,
num_wanted => $page_size,
sort_spec => $sortspec,
);
}
Reception
Eagle Explorer launched on July 6th, 2015, at the tail end of summer session. The Libraries posted an announcement on our Facebook page. Our director emailed key people on campus who might be interested in using it. Usage was moderate, with 96 sessions the first week. Users were clearly engaged with the content, spending an average of just over nine minutes on the site and viewing an average of sixteen pages per session. Then the Alumni Association posted a link on their Facebook page and Eagle Explorer was deluged with alumni looking themselves up. Within two days, thanks to the alumni, Eagle Explorer had received 201 referrals from Facebook, more traffic directly through the Libraries than the Internet Archive collection had received in five months the previous year.
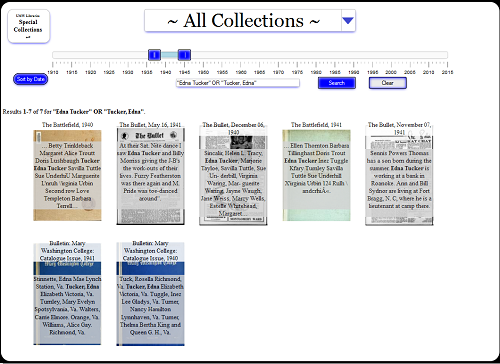 Figure 3. A search for the author’s grandmother yields newspaper articles, yearbook photos, and a graduation announcement
Figure 3. A search for the author’s grandmother yields newspaper articles, yearbook photos, and a graduation announcement
Usage has continued to be robust. It is hard to provide statistics that are directly comparable to the data from before Eagle Explorer because once a user left the Libraries’ website, it is impossible to know what they did on the Internet Archive site. What can be said is that where we had very little evidence in the past that our users were actually finding the Internet Archive collections, the evidence now is ample that they are finding them and that they are making meaningful use of them. Eagle Explorer accounts for 3.5% of the activity on the Libraries’ website. Between July and November 2015, there have been 1527 unique views of items in the collection through Eagle Explorer (a unique view is unique either because it is the first time that item has been viewed or because it contained a search term; search terms are passed on from Eagle Explorer to the Internet Archive Book Reader viewer so that users can quickly find what they are looking for). Roughly 60% of views included searches. Adding to our conviction that this use has been meaningful, during the same period, links to Eagle Explorer have been shared to Facebook or Twitter 27 times, often directly linking to a particular search term, date, or item.
Feedback from users has been positive. We have been able to strengthen ties between the Libraries and University Relations, who have been using Eagle Explorer to help personalize outreach to alumni. Our reference logs reveal that students and faculty have been using it to find more information about events mentioned in campus histories and to browse particular decades of the yearbook and the Bullet.
Future Improvements
While we are happy with Eagle Explorer, there is always room for improvement. We are in the process of scanning the missing issues of the Bullet from 2010-2014, when it changed names and became the Blue & Gray Press. We also plan to add a collection, the Bayonet student handbooks.
As noted above, there may be improvements we can make to search results by using different analyzers. Lucy also has different ways of weighting relevance that may provide better results and should be investigated. One such is the default bias towards shorter documents. Using LucyX::Index::LongFieldSim should remove this bias, but we have not yet had the chance to see if this improves results [12].
Eagle Explorer has an as yet undocumented API that we are using to pipe results into a bento-style search for Special Collections. A faculty member contacted the Libraries about using Eagle Explorer to set up a Twitter bot that could automatically tweet what our students were writing about fifty years ago, for example. We hope to use the API to help with this project and others that have yet to be thought of.
Conclusion
One of the most important things that sets digital objects apart from physical ones is that physical objects have a set place in the world and a set spatial relationship with other objects. In libraries of the past, this meant a library’s collections were held physically within the library, placed according to call number, and any alternative ordering had to be done laboriously with cards, which also had a set location and set order. Relationships and ordering are still important for digital objects; digital objects, like anything else, derive much of their meaning from their placement within a collection. But with digital objects, there are no limitations on order and relationship. They can be sorted and displayed in any order, anywhere, in whatever manner best meets the needs of whatever community of users might want them. They can be part of the vast collection that is the Internet Archive, available to researchers around the world who may want to compare, for example, student newspapers of the 1930s across the United States. At the same time, without needing extra copies on extra servers and without disrupting other users, we were able to bring our digital objects home with Eagle Explorer so that our users could find what they wanted in a single, unified Mary Washington collection.
Notes
[1] http://americanlibrariesmagazine.org/2011/08/10/step-easily-into-the-digital-future/
[2] https://archive.org/about/faqs.php
[3] The collection and the usage statistics can be found here: https://archive.org/details/universityofmarywashington&tab=about
[4] All usage statistics unless otherwise noted were collected with Google Analytics. These numbers are approximations: the actual numbers are likely to be higher because some people block analytics cookies and because some clicks don’t register. Additionally, Google uses sampling techniques that make it difficult to know how accurate the data is.
[5] An annual competition between the Devils (students graduating in an odd year) and the Goats (even year graduates): http://spinningwheel.umwblogs.org/devil-goat-day/
[6] Live project site: http://libraries.umw.edu/eagle-explorer
[7] http://lucy.apache.org/faq.html
[8] All modules are documented here: http://lucy.apache.org/docs/perl/
[9] http://search.cpan.org/~miyagawa/Web-Scraper-0.38/lib/Web/Scraper.pm
[10] http://lucy.apache.org/docs/perl/Lucy/Analysis/Analyzer.html
[11] We used the NoUiSlider, a lightweight Javascript slider whose claim to fame is that it does not use JQuery UI, to create the timeline. http://refreshless.com/nouislider/
[12] https://lucy.apache.org/docs/perl/LucyX/Index/LongFieldSim.html
References
Anderson, K, Gemmill, L. 2011. Step easily into the digital future: Lyrasis gets varied collections online quickly, and cheaply, through collaboration. American Libraries 42(7/8): 36-39. http://americanlibrariesmagazine.org/2011/08/10/step-easily-into-the-digital-future/
Apache Lucy. (n.d.). Apace Lucy. http://lucy.apache.org/
Internet Archive. (n.d.). Internet Archive: digital library of free books, movies, music, & the Wayback Machine. https://archive.org
About the Author
Katherine Perdue (kperdue@umw.edu) has been the Assistant Systems Librarian at University of Mary Washington Libraries since 2013.

Subscribe to comments: For this article | For all articles
Leave a Reply