By Henrik Lindström and Martin Malmsten
Introduction
Many of the present OPACs have been in use for years, during which time little development and improvement has taken place. These systems have not only fallen behind in terms of functionality, but also suffer from overly complex and library specific solutions that are unfamiliar to most non-expert users. Today, one expects user friendly, intuitive and aesthetically pleasing interfaces. Users have also adopted new search behaviors from other services, such as Google, that highly influence how they expect a library system to work.
These well known shortcomings, as well as suggestions for improvements, have been discussed for several years in conferences, papers, and email lists (Schneider 2006, Bates 2003, Calhoun 2006, numerous threads on NGC4Lib [1], etc.). We know what we would like to see in the next generation of OPACs, but how do we turn this into a usable system, and how do we make sure that in five years we are not back in the same position of outdated systems?
On December 19, 2007, a new version of the search service for LIBRIS (http://libris.kb.se), the Swedish National Union Catalogue, was released after just over a year of development. The system was completely rebuilt from top to bottom, including the search engine. Why did we not choose an existing solution? The answer is simply that there was no system that could meet our requirements. For example, we wanted to experiment with relevancy ranking and had specific requirements regarding providing faceted browsing without compromising performance. We also wanted to avoid vendor lock-in and external dependencies. It was important for us to be in control over the whole design and development process. This also makes for the ability to continuously develop the system, even after the release.
The release of LIBRIS was preceded by half a year with a public beta version, which was used for continuous development and testing. Not only did we develop the application itself, we also tested and adopted new methodologies for software development.
During the project an iterative agile development methodology evolved in combination with a user-centred design (UCD) process. We argue that these two methodologies allow you to meet the demands and expectations of today’s users, as well as keep up with and adapt to the constantly changing world of web applications. This article will briefly present these two methodologies and describe how they can benefit from each other.
We are not the first ones to point to the benefits of combining agile development and UCD. For example, Patton (2002) describes how interaction design was successfully added to an agile software development project and Gulliksen et al. (2003) discuss how agile methods could be adapted to fit a user-centred design process.
Usability
In the introduction we mentioned the importance of designing for usability. But what do we mean by a “usable” system? ISO 9241-11 defines usability as:
The extent to which a product can be used by specified users to achieve specified goals with effectiveness, efficiency and satisfaction in a specified context of use (ISO 1997).
In the case of an OPAC, this implies that the system can be usable for a librarian, who is familiar with library systems, at the same time as the usability is quite poor for a first-time, non-librarian user. Expert users (e.g. a librarian) and non-expert users (e.g. an undergraduate student) may differ in goals and satisfaction (the librarian wants an exact and exhaustive answer, whereas the student is content by finding the course book), the degree to which they can perform the task efficiently (the librarian is familiar with the system and knows how to perform a search, whereas the student may struggle finding what he or she is looking for, perhaps because the system differs in design and functionality from other systems he or she is used to) and so forth.
Therefore, in many respects, designing a usable OPAC is a task of designing a tool for at least two quite different user groups. For example, the non-expert users may need a simpler and more supportive system that guides them to functionality they do not know of, or are uncertain of how it works. However, this does not necessarily imply a conflict in design as long as the transparency and supportiveness of the system is provided for in a manner that does not obstruct the workflow of an expert user. Generally speaking, designing for usability is a matter of finding compromises. And if you take a closer look at both the “expert” and the “non-expert” user groups you probably find them to be quite heterogeneous within themselves. However, it is important to understand who the users are and in which contexts they are going to use the system.
User-centred design
User-centred design (UCD) can be defined in many ways, but all definitions are characterized by a focus on the user, and on incorporating the user’s perspective in all stages of the design process. Donald Norman describes UCD as “a philosophy based on the needs and interests of the user, with an emphasis on making products usable and understandable” (Norman 2002, p.188). By this definition, actual user involvement is not a part of UCD by necessity. However, involving the users in the user-centred design process is a common way of ensuring that their needs and interests are being met.
The user-centred design process has also been formalized in the ISO-standard 13407 Human–centred design processes for interactive systems (ISO 1999). The standard describes UCD as an iterative process consisting of five steps, depicted in figure 1, and also states the following key principles:
- The active involvement of users and clear understanding of user and task requirements.
- An appropriate allocation of function between user and system.
- Iteration of design solutions.
- Multi-disciplinary design teams (ISO 1999).
Much could be said about each of these principles, but we will only briefly comment on the second and the fourth, since the other two should be quite self explanatory. “An appropriate allocation of function between user and system” means that it is important to determine which aspects of a task should be carried out by the system and which should be carried out by the user (Maguire 2001). It is, for example, desirable to limit the amount of tedious time-consuming routine work for the user and instead let him or her focus on the aspects that require the users’ expertise. UCD is collaborative in its nature and implies the involvement and exchange of different competences, which leads to the last principle of multi-disciplinary teams (Maguire 2001). We will return to the benefits of working across disciplines later in this article.
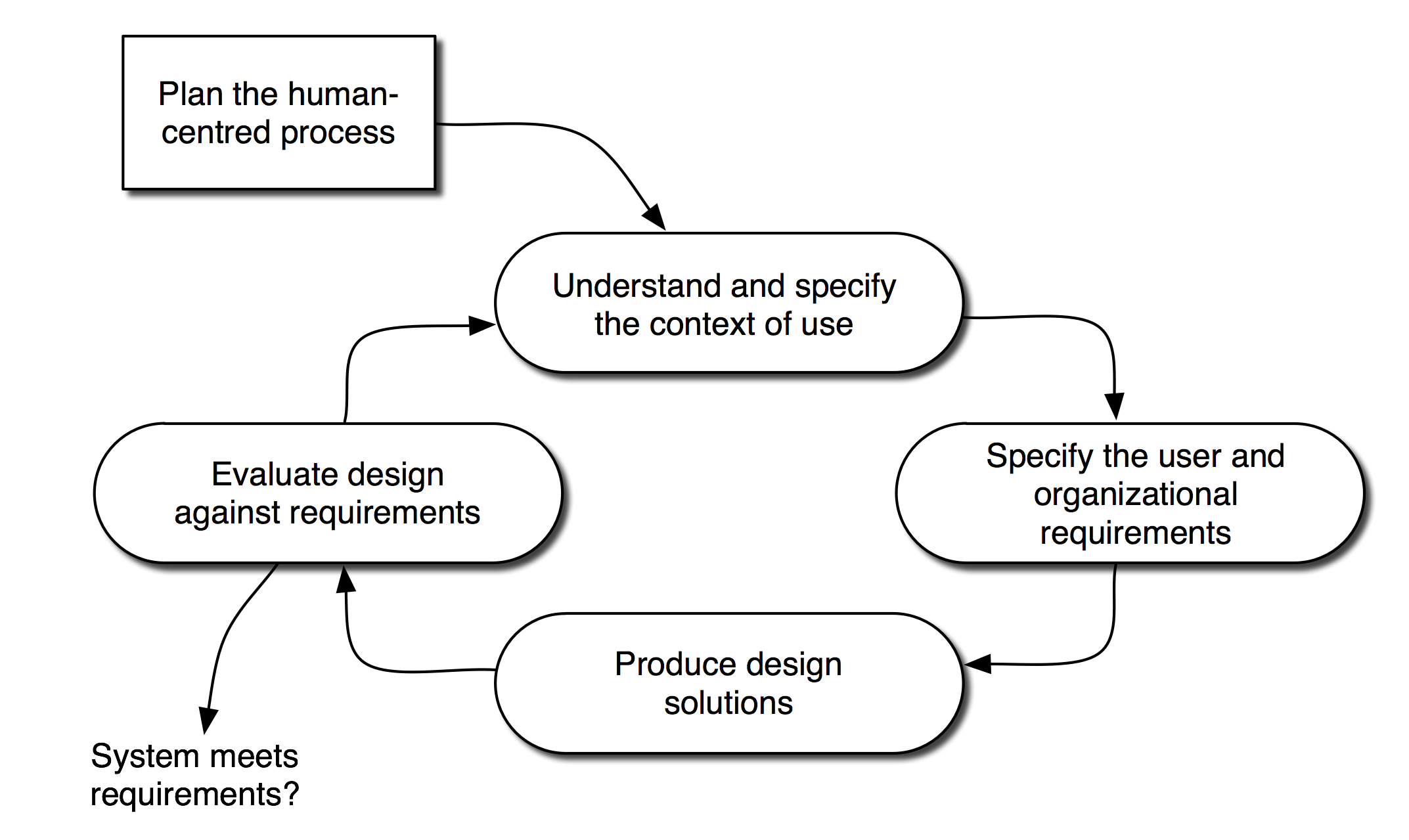
Figure 1. The human-centred design process, ISO-13407 (ISO 1999)
In figure 1 we see a schema of the iterative user-centred design process as defined in ISO-13407. In order to make the users an active part of each step in this process there are a number of empirical methods, such as:
- Interviews
- Surveys
- Workshops
- Focus groups
- Field studies
- Usability testing
The different methods each have their strengths and weaknesses. For example, interviews can give in-depth, qualitative data, but are resource-consuming to carry out on a large number of users. Surveys, on the other hand, can be distributed to a large number of subjects, but with more quantitative data as result. However, if we carry out a survey and conduct interviews to study the same thing, we can eliminate some of the weaknesses and at the same take advantage of the strengths of each method. This is known in social science as triangulation, a concept based on the idea that if you use more than one method to study one phenomenon you increase the validity of the study (Jick 1979).
Choosing the best methods depends on what we are studying and which stage in the design process we are working on. Generally speaking, interviews, surveys and field studies are well suited for the first two steps (see fig. 1), i.e. when specifying and understanding who the users are, in what context they are going to use the system, and for what purposes. It is perhaps needless to say that interviews and surveys are not very well suited for producing actual design solutions. Hence for the last two steps, when designing and evaluating, we need different methods such as focus groups, workshops and prototyping.
Agile and iterative development
Iterative approaches to development have been around since the early days of software development but have not been formalized until the last few decades. Iterative development is a central part of models such as Rational Unified Process, the Dynamic Systems Development Method and Agile methods, such as Extreme Programming and SCRUM (Basili & Larman 2003).
There are many reasons why the classic single-pass waterfall model [2] is still popular, especially amongst managers; for instance, it gives you a feeling of knowing exactly what the end result will be, how much it is going to cost, etc. However, at the same time as the advantages of iterative development are becoming better documented and more widely known, the shortcomings of the single-pass, document driven waterfall model are becoming clearer. Many of the iterative methodologies have, in fact, evolved from bad experiences with waterfall projects (Basili & Larman 2003).
The biggest problem of the waterfall model is failure to adapt to discoveries made during the design and implementation phase. There is little or no room for adjustments once the analysis phase is over. Also, the demand for constantly evolving products and services can be hard to meet with such a rigid model. If the duration of a project runs over a significant amount of time, chances are that the desired end-result changes during the project. Simply put: the waterfall model does not take into account the fact that conditions and goals change over time.
Agile software development is a generic term for a number of methods using iterations to avoid the problems described above. One iteration usually lasts from one to four weeks and optimally comprises planning, analysis, design, coding and testing. One of the main points is that evaluation is done many times during the project, which enables change in direction and/or redesign at an early stage, saving time and resources (Schwaber & Beele 2002). The key principles of agile software development are found in the so called Agile Manifesto. It states that priority should be given to:
- Individuals and interactions over processes and tools
- Working software over comprehensive documentation
- Customer collaboration over contract negotiation
- Responding to change over following a plan (Agile Alliance 2001)
Since iteration in design is a key principle of UCD, there is much to gain by employing an iterative approach for implementation as well. It makes the developers more aware of the changing nature of the project, but also lets them give feedback to the design process. A focus on in-person communication (for example, sitting together in one room or not communicating via paper) also lowers the participation threshold for all team members.
Case study: LIBRIS – the Swedish National Union Catalogue
In this section we will describe the development of a new search service for the Swedish National Union Catalogue, LIBRIS (http://libris.kb.se). The different methods we have used for the user-centred design process are described and exemplified, as well as the model for agile development. The focus is on these two aspects; therefore, this section is not a report on the entire LIBRIS project. It should also be noted that the user-centred design process as described here leaves out many important aspects concerning interaction design and user experience. For example, we do not touch upon visual design and communication.
In the project the methodology was not formalized from the start, but rather it evolved with the project. In particular, agile development is something that we have adopted as much by experience as by actually studying documented methodologies.
How we worked with user-centred design
Even though we have not followed the ISO-13407 standard to the letter, we have worked according to many of its concepts and principles (see section on User-centred design). Firstly, the design process has been iterative, as described in more detail under the section about iterative development; secondly, the project group has been multi-disciplinary, including experts on:
- Design (visual and interaction)
- Engineering (system architecture, databases, interface programming etc.)
- Human computer interaction (HCI)
- Format (metadata)
As much as possible, we have also included the users in every step of the design process, even though the degree and methods of participation have varied during the project. This reflects that the design process is an ongoing and changing process. The main components of our user-centred design process consisted of a survey, a focus group/workshop, and usability testing. We also conducted interviews with researchers and library colleagues and worked in close collaboration with a reference group.
When talking about user-centred design we have sometimes come across the misconception that it would imply some sort of “least common denominator solution” or “design by majority vote.” However, this is not the case. The role of the project group is by no means diminished when users are involved. On the contrary, the work of conducting and analysing usability tests, focus groups, workshops, surveys, etc. makes great demands on the development team. And in the end it is up to the team to make informed decisions on how the system best can meet user preferences and demands.
Survey
The ISO-13407 standard states that the first step in the design process is to understand and specify the context of use. In order to get this background information we conducted a user survey and a focus group/workshop. The user survey was publicly accessible from the start page of the old version of LIBRIS, and during seventeen days in November 2006 we got 873 replies. The survey consisted of multiple choice questions in combination with open questions. The selection was uncontrolled and therefore the results cannot be seen as representative for LIBRIS’ users. Rather, the survey aimed at gaining general background information and finding out what some of our users expect from a new version of LIBRIS. One of the most valuable outcomes of the survey was the suggestions for improvements and new features that showed up in answers to the open questions.
Focus group
The focus group/workshop was conducted in November 2006 and aimed at gaining more qualitative data. The group consisted of 7 users: 1 pensioner, 3 doctoral students and 3 undergraduate students. The participants were recruited by postings at libraries, universities and email lists.
The workshop consisted of two parts; the first part concerned search behavior and was conducted with a scenario-based method. The scenario was about an undergraduate student who had to find literature for a paper. The participants were divided into two groups with the task of coming up with a strategy for the student.
The second part of the workshop consisted of a design task where the participants were asked to come up with features they would like to see in a personal login area and to describe how this area should integrate with the rest of the system. The groups presented their suggestions to each other and we discussed pros and cons of the different designs. Even though the login area did not become part of the release, the workshop was valuable for getting an understanding of the users and will also provide background material for an upcoming project to design and implement a personal login area.
In general, the focus group was a good method for getting qualitative data and for going into detail with some key concepts. However, the composition of the group is very important, both when it comes to profile and personality of the participants. It is also important to have a good moderator who is able to make sure that the discussion does not go off topic nor get stuck on one subject.
Usability testing
During the project we had two extensive test periods. The first was conducted on a so called vertical prototype, where the functions we wanted to test were almost fully implemented, but the rest of the interface was inaccessible. The other test was conducted on the aforementioned public beta version.
These tests were controlled and took place in the office premises of the National Library. The subject was seated by a computer and the test leader orally presented the tasks. We used a “think aloud” methodology where the subject is instructed to talk out loud about how he or she perceives the system and how he or she reasons when performing the tasks. The tasks alternated between open ended and more specific. The screen was filmed with a dv-camera which also recorded the sound. In connection with the test we also conducted an interview. The interviews had two purposes: firstly to get some background information about occupation, age, and comfort with new web services, etc., and secondly to discuss in more detail how the subject experienced the system. This also gave the opportunity to ask about desirable functions and other things that were not part of the test itself.
There are many methodological problems with controlled tests such as those we conducted: the formulation of the tasks strongly influences the subjects, there is a lack of real motivation to perform tasks, the environment is unfamiliar, subjects experience additional stress from being observed, etc. On the other hand, you have the possibility to pinpoint certain parts of the system and functions that you want to test.
In order to get some real use data we also conducted a more naturalistic test in a library environment. The test took place at a university library and we asked visitors to conduct their searches in the beta version of LIBRIS instead of the local OPAC or the old version of LIBRIS. The task was therefore determined by the subjects and there was a real motivation for searching. This test mainly aimed at studying how users approached the system when seeing it for the first time and how the basic search functionality worked. We also conducted tests on a couple of librarians to see how the system was used by expert users.
One important question regarding usability testing is how many test subjects you need. This depends on what you are testing and how heterogeneous the users are. However, Nielsen (2000) argues that when it comes to discovering usability problems a few test subjects (he mentions 5) are sufficient in order to discover most of the problems. He also advocates running many small tests throughout the design process, rather than having one big test period. We used 4 subjects for the prototype tests, 7 for the controlled beta tests and 8 for the naturalistic tests conducted in the library. We feel that these subjects were sufficient to test the basic functionality and work flow of the system, though we could have used a couple of more subjects for the prototype tests. What we feel is lacking, in terms of testing, is a longitudinal study that examines how the system is being used by experienced users and how it functions as a working tool.
How we worked with iterative development
Our focus on flexibility extended both to the physical environment and to our development environment. Turnaround time in any part of the project needed to be short, whether making changes to the server configuration, fixing a bug, or redesigning part of the interface. It was vital that the different competences needed for these tasks were part of the project team.
Flexible development environment
In order to facilitate rapid communication and knowledge sharing between project members, a separate project room was acquired. This room was big enough to hold all project members, including any consultants, and was also used for project meetings and reference group meetings. It was, in essence, the heart of the project. However, the room was not available to us exclusively. This meant that we had to find a way to set up and take down the project room, sometimes on a daily basis. Increased knowledge sharing also led to increased security due to the fact the project success or failure did not depend on one single project member.
It was also important to get the right tools for the job when it came to development. We needed to be flexible, both in terms of software and hardware. We used open source tools almost exclusively and applications were deployed on Apache Tomcat servers.
The project team included members with experience in Unix maintenance, which meant short turnaround time for server related bug fixing and reconfiguration. When needed, changes could often be made on-the-fly.
Since almost all development was done in Java, we could choose any platform for developers. However, since the application was being deployed on hardware from Sun Microsystems, a Unix-based development environment was considered optimal. We chose iMacs from Apple Inc. running Mac OS X. The iMac has the advantage of being in one piece (computer + display) and thus can be effortlessly moved, meaning that we could assemble or disassemble the project room in a matter of minutes.
By design, our day-to-day communication had almost no external dependencies on people or hardware outside the project group. This led to low information latency, allowing us to make most decisions quickly and easily. An external consultant was used for one task: building browser independent CSS. Since it was vital for us to understand and learn about the work of the consultant, he was integrated into the project rather than being an external partner. The consultant was in essence a part of the development team, albeit for a shorter time.
Iterative development
As mentioned before, we did not have a clear view of any particular iterative development method before starting the project. We did have enough experience to understand that in order to realize our goal of continuous development, we would have to adopt some kind of iterative approach. However, in retrospect, we realize that we have fulfilled most of the individual parts of the Agile Manifesto (see section on Agile and iterative development):
- Individual interactions over processes and tools – the shared project room made communicating easy. Our development process was deliberately malleable from the start.
- Working software over comprehensive documentation.
- Customer collaboration over contract negotiations – meetings with the reference group throughout the project.
- Responding to change over following a plan – we revised our plan continually to meet changing requirements during the project.
The first version that could be used to test some functionality was produced two months after the project started. After seven months of development, about half-way through the project, we released the first version of the public beta version of the service. This gave us, in addition to user input, invaluable data concerning performance and statistics.
Since the iterative approach encourages continuous change, there is a risk that the codebase will become unstable or that the same problem will be solved in different ways depending on when the solution was implemented. Also, there is a tendency when working against a deadline to favor quick fixes in one place and to not propagate these changes throughout the code. This is natural since the “gold standard” changes during the progress of the project.
To normalize the codebase we planned a 3 week long code review phase into the project. In the code review the whole codebase was put under scrutiny and discussions were made about the best way to solve a certain problem. Parts of the code were then refactored [3] to meet the requirements. Steps were also taken to improve the overall readability of the code.
All this previously theoretical flexibility and security was put to the ultimate test one month before launch of the beta version. The computers used for development were stolen while two developers, including the technical lead, were at a conference in another country. It took the remaining project members less than two days to have everything up and running again (mostly time waiting for new computers to arrive). This proves that enough knowledge was spread among the project members. Even though strictly this has nothing to do with iterative development, we are convinced that the constant cycle of plan/design/implement/deploy helped iron out any hidden problems.
Discussion
The methodology outlined in this article requires engagement from everyone in the project group; there is no room for hiding or not doing one’s share. This can be strenuous at times, but in general we believe that it leads to devotion and a greater sense of satisfaction. Furthermore the highly collaborative way of working ensures that any problems that may arise are noticed at an early stage.
By focusing on user-centred design, you develop an understanding of the user, and thereby an understanding of why and for whom you are developing the system. This, we have found, is highly motivating, whether you are doing visual design, writing code or working with metadata specifications. Agile methods have been criticized for not taking usability into consideration, with a too narrow focus on deliverable code (Gulliksen et al. 2003). However, even though the agile SCRUM methodology does not say anything about UCD, we do not see anything inherent in the methodology that prevents a focus on usability (Schwaber & Beele 2002).
At the same time that the UCD process ensures an understanding of the users, the agile development model ensures that you can work iteratively. The two methods reinforce each other; the latter makes for faster development of functional prototypes, which are more easily communicated and tested, thus giving you better input for the next iteration, and so forth.
An interdisciplinary project group also gives an understanding of one’s colleagues and their different competences. This is, in our opinion, almost a prerequisite for working iteratively. Our experience from other projects is that external dependencies slow down the process. In the LIBRIS project, we could implement new features in very small and effective iterations within the project group, doing everything from specifying and implementing metadata transformations to designing and implementing the interaction in the user interface. Furthermore, this could be done without having communication delays sending specifications and bug-reports back and forth with external consultants or development teams. And by communicating directly with each other in person, the amount of intermediary paperwork and lengthy email conversations is reduced.
It is important to stress the need for management support and trust when working with agile development. Since there is no final specification of requirements to show up front, before the project starts, you have to convince management that the methodology and process themselves will lead to a good product.
What could we have done differently?
Of course, there is no such thing as a perfect methodology; especially when trying new approaches you are bound to do some things backwards and run into difficulties now and then. However, during the LIBRIS project problems and drawbacks have been surprisingly absent. That is not to say that the methodology could not be improved. Sometimes the work has been a bit unstructured and perhaps ad hoc. This is not necessarily a problem with the methodology itself, but rather a lack of planning and of making sure that each and every design decision is well founded. Now, at the end of the project, we also feel that there is a lack of documentation. While there has been quite a lot of paperwork, some parts of the system are quite obscure for anyone other than the person who wrote the code. This is also a result of lack of knowledge transfer between the programmers. Agile methods such as eXtreme Programming stress the importance of pair programming, and this is something that we have to work more with in coming projects.
The user-centred design process could be improved in many aspects, not least in making the users even more involved in the design process. During the project, a few team members had most of the contact with the users, and it would be interesting to conduct more collaborative design workshops with the entire project group and the users working together. The methodology of making the users an active part of the design process is called participatory or cooperative design, and is also known as the “Scandinavian model” (Bødker et al. 2000). Even though we had from previous experience a good knowledge of the context of use of the system, we could also have done more toward specifying and understanding this context, e.g. by doing field studies. We also feel we could have devoted even more time for usability testing, especially by doing more naturalistic tests with real tasks in real contexts.
Conclusion
The fact that we had a version of the system with all essential parts integrated at an early stage in the project, in combination with the six months of beta-testing, made us confident that the system would work. The continuous user tests and user-centred design process also gave us confidence that the system would be well received by the users.
Furthermore, the iterative development model in combination with an efficient release process put us in a position were we can easily update and add new features to the live version. This allows us to have a service that can meet the continuously changing demands on web services in general, and on library systems in particular.
Finally, we would like to conclude that working with user-centred design in combination with iterative development is a better, faster and cheaper way of software development, compared to traditional models. Better – the product being released at the end is a more up-to-date and bug-free version than had we worked with a more traditional approach. Faster – it is our conviction that with traditional methodology we would not have finished on time, or at least not with the same amount of features implemented. Cheaper – if the same number of people are able to do a better job in a shorter amount of time, it is a more cost-effective way of getting the job done.
References
Agile Alliance (2001). Manifesto for Agile Software Development. Webpage available at: http://agilemanifesto.org/ (2008-03-05)
Basili, Victor R. & Larman, Craig (2003). Iterative and Incremental Development: A Brief History. IEEE Computer. 36(6), p.47-56. doi:10.1109/MC.2003.1204375. Available online at http://www2.umassd.edu/SWPI/xp/articles/r6047.pdf (2008-02-28)
Bates, Marcia J. (2003). Improving user access to library catalog and portal information. Final report (version 3). Available at: http://www.loc.gov/catdir/bibcontrol/2.3BatesReport6-03.doc.pdf (2008-03-31)
Bødker, Ehn & Sjögren, Sundblad (2000). Co-operative Design – perspectives on 20 years with ‘the Scandinavian IT Design Model’. Proceedings of NordiCHI. Available at: http://cid.nada.kth.se/pdf/cid_104.pdf (2008-03-28)
Calhoun, Karen (2006). The Changing Nature of the Catalog and Its Integration with Other Discovery Tools. Prepared for the Library of Congress. Unpublished. Available at: http://www.loc.gov/catdir/calhoun-report-final.pdf (2008-03-31).
Gulliksen, Göransson, Bovie, Blomkvist, Persson & Cajander (2003). Key principles for user-centred systems design. Behaviour & information technology. 22(6), p. 397-409 (COinS)
ISO (1997). ISO 9241-11: Ergonomic requirements for office work with visual display terminals (VDTs). Part 11 – guidelines for specifying and measuring usability. Geneva: International Standards Organisation. Also available from the British Standards Institute, London.
(COinS)
ISO (1999). ISO 13407: Human–centred design processes for interactive systems. Geneva: International Standards Organisation. Also available from the British Standards Institute, London.
(COinS)
Jick, Todd D. (1979). Mixing Qualitative and Quantitative Methods: Triangulation in Action. Administrative Science Quarterly, 24(4), p.602-611. doi:10.2307/2392366 (COinS)
Maguire, Martin (2001). Methods to support human-centred design. Int. J. Human-Computer Studies. 55, p. 587-643. doi:10.1006/ijhc.2001.0503. (COinS)
Nielsen, Jakob (2000). Why You Only Need to Test With 5 Users. Webpage available at: http://www.useit.com/alertbox/20000319.html (2008-03-18)
Norman, Donald A. (2002). The design of everyday things. New York: Basic Books. ISBN: 0-465-06710-7
(COinS)
Patton, Jeff (2002). Hitting the target: adding interaction design to agile software development. OOPSLA 2002 Practitioners Reports, p. 1-ff. doi:10.1145/604251.604255. ISBN: 1-58113-471-1
(COinS)
Schneider, Karen G. (2006). How OPACs Suck, Part 2: The Checklist of Shame. Blog entry available at: http://www.techsource.ala.org/blog/2006/04/how-opacs-suck-part-2-the-checklist-of-shame.html (2008-03-31)
Schwaber, Ken & Beedle, Mike (2002). Agile software development with scrum. Upper Saddle River, NJ: Prentice Hall. ISBN: 0-13-067634-9
(COinS)
Notes
[1] NGC4Lib is a mailing list for discussions about the Next Generation Catalogs for Libraries.
See http://dewey.library.nd.edu/mailing-lists/ngc4lib/ (2008-03-31).
[2] The waterfall method generally involves a single iteration where all requirements are defined and system design is completed before any development occurs.
[3] Code refactoring is revision and restructuration of source code intended to make it more streamlined and to increase its readability.
About the Authors
Henrik Lindström is a developer at the National Library of Sweden. He holds a M.Sc. in Media Technology from the Royal Institute of Technology, Stockholm, Sweden. Henrik works with programming and interaction design, and has a special interest in Language Technology and Machine Learning. Email: henrik.lindstrom@kb.se
Martin Malmsten is a Senior Developer at the National Libary of Sweden. He is currently working on the Linked Data implementation for LIBRIS, the Swedish Union Catalogue, and has a special interest in semantic web technology and search engines. Email: martin.malmsten@kb.se

Subscribe to comments: For this article | For all articles
Leave a Reply