By Wesley Teal
Introduction
In June 2016 Vogel Library at Wartburg College migrated its integrated library system from Millennium to Alma. For the most part, the migration went smoothly. Most records transferring over correctly, but as with any large-scale data migration various problems arose. Among the thorniest of these issues was the loss of enumeration and chronology data for roughly 79,000 print serial items housed in Millennium’s serials module. This meant Vogel Library’s new discovery layer, Primo, couldn’t filter serials by volume number or year. Fortunately, the enumeration and chronology data was preserved in each item’s free text description field in strings like “v.2 no.10 Sum 2010.” The problem lay in how to best extract this data and re-enter it into the appropriate fields in each item record.
Considerations
As Vogel Library’s lone technical services staff member, the responsibility of updating these records largely fell to me. Given the large number of records that needed to be updated, manually editing each record was not a realistic option, not even with the help of student employees. Fortunately, Alma has a well-documented REST API that made large-scale programmatic updates possible. Alma stores information for physical materials as bibliographic records, with one or more associated holding records, which in turn have associated item records. In each item record, Alma stores volume, issue, and other enumerative numbers in enumeration_a through enumeration_h fields, and stores date information in chronology_i through chronology_m fields, as shown in this XML snippet:
<enumeration_a>44</enumeration_a> <enumeration_b>3</enumeration_b> <enumeration_c></enumeration_c> <enumeration_d></enumeration_d> <enumeration_e></enumeration_e> <enumeration_f></enumeration_f> <enumeration_g></enumeration_g> <enumeration_h></enumeration_h> <chronology_i>2014</chronology_i> <chronology_j>11</chronology_j> <chronology_k>12</chronology_k> <chronology_l></chronology_l> <chronology_m></chronology_m> <description>v.44 no.3 Nov 12 2014</description>
To correctly populate these fields I needed a way to programmatically extract the enumeration and chronology data and place it in the correct item record fields.
This was more easily said than done. While I had some prior programming experience, I had minimal experience working with REST APIs, had not done any complex text processing, and had not worked with XML, which Alma’s API used for data exchange. There was a reasonable possibility that I’d be unable to successfully write a program that could update item records as required. I decided to give myself a couple weeks. If I couldn’t build something that was at least promising in that time, I’d give up and start looking for another solution. If the project turned out to be beyond my skills, being two weeks behind on updating 79,000 records wouldn’t matter much. On the other hand, if I could get something working in that time I might be able to have all, or at least most, of the item records updated before classes started in late August.
To begin the project I decided to use Python. I had some prior experience with Python and it had a reputation as an easy-to-use and easy-to-learn programming language with a wide variety of useful libraries. Since library staff did not have administrative privileges and I was unsure of what libraries I would need, I chose to use WinPython, a portable distribution of Python that didn’t require administrative privileges to install and provided a large number of libraries pre-installed. A similar distribution I considered was Anaconda, but at the time I did not realize it could be installed without administrative privileges.
Design and Redesign
The initial design involved a two-stage process that remains the basis of how the software that came to be called Alma Enumerator works. The first stage was to download all the item records connected to a bibliographic record in Alma, parse the description field in each record, and save the resulting data to a file that can be checked for errors. The second stage was to update the item records in Alma with the data from the saved file.
To accomplish these tasks I identified what libraries I would need. To handle requests to the Alma API, I used the Requests library which simplifies the process of handling HTTP requests over Python’s default libraries. To process the XML records I used Beautiful Soup, a library designed for parsing and manipulating HTML and XML documents.
After deciding on a basic structure and the needed Python libraries, I developed the Alma Enumerator primarily via exploration rather than conscious design. While I did make design decisions throughout the process, they were more often driven by trial and error than through planning and careful consideration. This led to frequent redesigns, especially for the description parsing algorithm which went through three major iterations.
The first iteration of the description parsing algorithm was a single regular expression. I assessed the item descriptions for a small number of bibliographic records. Each description used a set pattern. As long as the pattern held, a regular expression would be sufficient to extract the desired fields. This worked quite well for the first few titles that I had assessed. Unfortunately, after I began working on titles beyond my initial sample, I began to discover that there was a much wider variety of description formats than I had anticipated. I began to expand the application’s regular expression to handle these new variations, but this approach soon proved unworkable. The Vogel Library catalog had descriptions that ranged from the simple “v 149” to the complex “v.302 no.2-3 Jan 11 2016 – Jan 18 2016” along with outliers like “v.85 no.6 2009 International focus issue” and typos like “\v.523 no.7560 Jul 16 2015”[1]. There was no regular expression that I could write and maintain that would handle the level of variation in item descriptions, so I had to find another approach.
My second approach was to split each description into a list of tokens to sanitize the descriptions, removing undesirable punctuation and words like “index” or “International focus issue” that did not provide enumeration or chronology information. The majority of descriptions I’d encountered up to that point still fell within a fairly small number of patterns that varied primarily in the number of tokens in the description. To handle different descriptions, I wrote a series of if-else statements that first checked the length of the token list then had nested if-else clauses to handle different patterns of the same length. This approach worked, but was inflexible. For each new description format, I had to add a new series of if-else statements. This was the approach I used for most of the summer of 2016 to update item records, but by August I decided there had to be a better way.
# ['v.65', 'no.3', 'May', '2012', '-', 'Jun', '2012']
if len(info) == 7:
if has_digitsp.match(info[2]) == None and has_digitsp.match(info[5]) == None and info[4] == '-':
print('Seven. Matched.')
item_info['enumeration_b'] = snarf_numerals(info[1])
if info[3] == info[6]:
item_info['chronology_i'] = snarf_numerals(info[6])
else:
item_info['chronology_i'] = '/'.join([snarf_numerals(info[3]), snarf_numerals(info[6])])
item_info['chronology_j'] = '/'.join([info[2], info[5]])
else:
print('{} appears to be irregular. Please correct by hand.'.format(item))
item_info['error'] = item
I decided to rewrite the parsing function once again. The new approach split each description into tokens and sanitized them, as in the previous approach. Instead of writing a custom series of if-else statements for each description pattern, however, I took a more generalized approach. Now the function iterated over the list and attempted to identify and collect years and month/season words like ‘May” or “Winter,” and pagination data. It also flips a Boolean flag if a description includes the day of publication in its chronological data. After this initial parsing, the remaining tokens were apportioned based on the number of remaining tokens and some logic that attempts to determine if excess tokens are days of the month. Although I did need to make some tweaks to handle various unusual descriptions, this new algorithm was generally able to handle new description formats without requiring a new series of if-else statements.
# Go through each item in the list
for i in info:
# If it's a hyphen, ampersand, or slash, add it to the deletion list.
if r_exp.match(i):
delete_me.append(i)
# If it's not a numeric value, check to see if it's a pagination marker,
# otherwise, add it to the month/season list. In either case, mark it
# for deletion.
elif not has_digitsp.match(i):
if has_pagination(i):
pp = snarf_numerals(info[info.index(i) + 1])
info[info.index(i) + 1] = pp
pages.append(pp)
delete_me.append(i)
delete_me.append(pp)
else:
for key in date_patterns:
if key.match(i):
mo_season.append(i)
# Check the item after this one.
if last_index > info.index(i):
look_ahead = info[info.index(i) + 1]
# If it looks like a numeric value and not like a year. Mark it
# as a chronology_k (day) value.
if has_digitsp.match(look_ahead) and not is_yearp.match(look_ahead):
has_chron_k = True
break
delete_me.append(i)
# If it is a numeric value, sanitize it by running it through
# snarf_numerals()
else:
info[info.index(i)] = snarf_numerals(i)
i = snarf_numerals(i)
# If it looks like a year, add it to the years list and the deletion
# list.
if is_yearp.match(i) and i not in pages:
years.append(i)
delete_me.append(i)
# Only month values should have leading zeros if anything left in this list
# has a leading zero, it's probably something like an abbreviated year that
# has been misidentified as not a year (ie 07 for 2007). Treat it as an
# error.
if has_leading_zero(i):
item_info = handle_record_error(item, item_info)
This third approach remains the way Alma Enumerator parses descriptions. It transforms the item description, as the second approach did, to convert a description like ‘v.44 no.3 Nov 12 2014 pp 205/298’ along with the item’s MMS ID into a Python dictionary with the following structure:
{'id': 999999999,
'enumeration_a': 44,
'enumeration_b': 3,
'chronology_i': 2014,
'chronology_j': 11,
'chronology_k': 12,
'pages': 205/298,}
It also attempts to identify descriptions it can’t correctly parse. Alma Enumerator then writes the dictionaries created from item descriptions to a CSV file and saves the errors it identifies to a separate file. To update the item records in Alma, the program reads from the saved CSV file, converting each line back into a Python dictionary and then inserting the data from each key-value pair in the dictionary into the matching element of the item record.
The code to handle requests to the Alma API is relatively simple, although it did take a little thought to handle bibliographic records with multiple holding records, and to retrieve a full item list since Alma’s API limits its responses to 100 items and Wartburg had several print serial titles with more than 100 items.
Matching the two stage process, Alma Enumerator initially began as two separate programs: one that downloaded and parsed descriptions and another that updated the records based on the output of the first. However, there was enough overlapping code in each of these that I combined them into a single library called AE.py.
During the early stages of development, I used Alma Enumerator mainly by running it directly from my IDE or by loading it into a Python REPL and running its fetch and update functions from within the REPL. However, as the project became more mature, I realized it might prove useful to others. I decided to provide interfaces for using the Alma Enumerator library: a set of command-line scripts that could accept arguments (I already had a couple primitive scripts that relied on edits to a settings document to change behavior) and to build a GUI that could be used by non-technical library staff.
For the command-line scripts, I initially used docopt to parse command line arguments. I found this library easier to wrap my head around than argparse, the recommended command-line argument parser in Python’s standard library. docopt comes as part of WinPython and Anaconda, so I thought it would be reasonable to assume that it would be likely that others would be able to install the package. However, I had difficulty getting docopt to handle arguments the way I wanted. In March 2018, I rewrote the argument parsers for Alma Enumerator’s command-line scripts to use argparse.
For the GUI, I used Tkinter, a GUI toolkit that is part of Python’s standard library. By the time I decided to build a GUI I’d realized that if Alma Enumerator was used by other libraries, it would most likely be in situations similar to mine at Wartburg: a Windows (or perhaps Apple) computer that wasn’t set up for non-technical users to use Python or install new libraries. Wanting to minimize the barriers for use in such a set up, I opted for the default GUI library over the various other options available outside Python’s standard library.
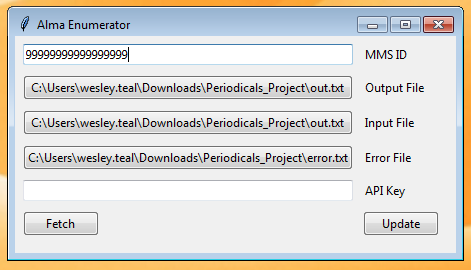
Figure 1. Screenshot of the Alma Enumerator GUI.
Analysis
For my immediate goal of updating 79,000 item records, Alma Enumerator was a success. I didn’t manage to have the records for all the print serials updated by the start of fall semester 2016 as I had hoped, but I had made something that could update item records much faster than I could have done manually. As I refined Alma Enumerator over the summer, I’d processed a number of print serial titles, starting with smaller collections that would be easier to correct by hand if errors arose. Once Alma Enumerator was reasonably reliable, I prioritized the titles that were current subscriptions followed by those that had the largest number of items, assuming these would be the titles most commonly used by students and faculty. I was able to complete the updates for these first two categories by the time classes began. I updated the remainder over the course of the fall semester.
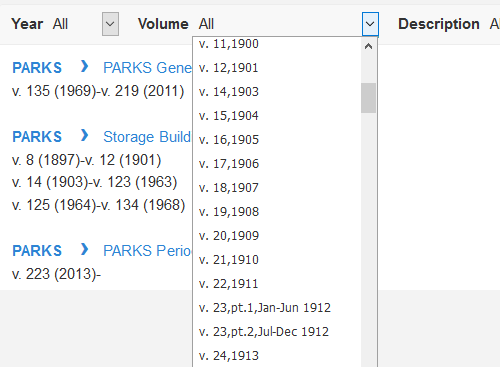
Figure 2. Screenshot showing Primo’s drop-down menu for filtering print serial items by volume number. The figure demonstrates that the menu uses item description text when there is no data in an item record’s enumeration_a field.
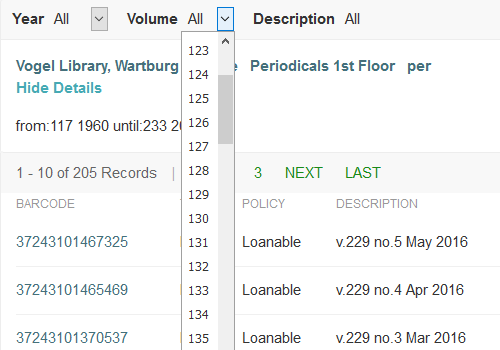
Figure 3. Screenshot showing another example of Primo’s drop-down menu for filtering print serial items by volume number. The figure demonstrates how item records can be filtered by volume number when there is data in the record’s enumeration_a field.
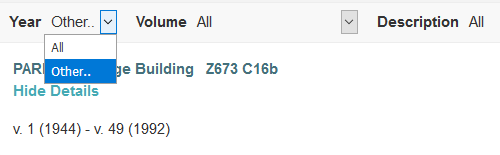
Figure 4. Screenshot of Primo’s drop-down menu for filtering print serial items by year. The figure demonstrates that items cannot be filtered by year when there is no data in an item record’s chronology_i field.
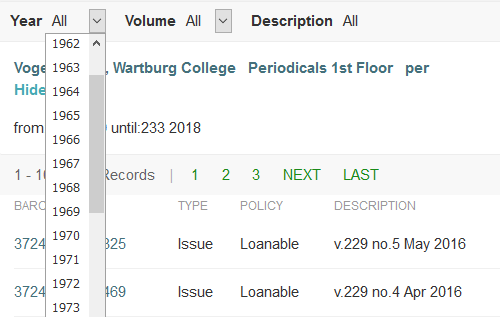
Figure 5. Screenshot of Primo’s drop-down menu for filtering print serial items by year. The figure demonstrates how item records can be filtered by year when there is data in the record’s chronology_i field.
Although I consider Alma Enumerator a success, it is not without its shortcomings. Due to the exploratory nature of much of the design process, the code tended to grow organically rather than following a clear structure. Some functions, especially get_info_from_description, which parses item descriptions, are overly long and complex and could probably be split into smaller functions. The code is messy in places and variable names like rp, r_exp, and info are not exactly intuitive. I suspect the description parsing process could be further refined to be less convoluted.
There were also trade offs made during the development process that make Alma Enumerator less efficient than it could be. Early in the design process, my primary goal was to get something working as quickly as possible, so many early design decisions emphasized development efficiency over efficient operations. One of the places this is the most obvious is in the way Alma Enumerator updates item records. For each item record that needs to be updated Alma Enumerator downloads one existing item record, updates it, and uploads that updated record back to Alma before repeating the process for each subsequent record. This requires two HTTP requests per item record and each request is made in sequence as each item is processed in sequence. For bibliographic records with only a few items, this doesn’t matter much, but for titles with dozens or hundreds of items an update would take minutes to complete. In the case of Nature which had 657 items, the time it took to update each record was approximately half an hour. One option to speed up this process would be to save the item record XML files downloaded during Alma Enumerator’s first stage. Another would be to use multiple threads or processes to make the HTTP requests so that the main thread can continue.
Another issue is the number of description patterns that Alma Enumerator can’t handle. Some of these are outliers or outright errors like “100,02/04,1997/1998,v 100 no 2 Feb 1997-v 101 no 2 April” or “v 67 #3 AUG 986” that are better left to be handled manually. When these are correctly identified as errors, things are still working as intended. The more troubling class of problem descriptions are those that pass through without correctly being identified as errors and thus must be caught by manual inspection lest inaccurate data is added to an item record. Some of the descriptions that pass through are outliers and errors as above, but others are descriptions like “v.302 no.21 & 22 May 23/30 2016” that Alma Enumerator should ideally be able to handle. To fix these issues would require further tinkering with the way the program parses item descriptions.
I have also not written enough tests to make sure that Alma Enumerator is robust. The only part of the project that is tested at all is the get_info_from_description function and even there the testing is incomplete. If I had taken a more test-driven approach, I expect the development time it took to create Alma Enumerator may have been reduced at certain points where I became mired in trying to root out unexpected bugs. More thorough test coverage would also help to minimize the potentially large number of still unknown bugs that may lurk in the code.
Perhaps the most troubling shortcoming is that it is not all that easy to use Alma Enumerator despite my efforts to make it reasonably simple to set up and run. On and off over the past year and a half, I have been trying, with a colleague at a university that migrated to Alma at the same time as Wartburg, to get Alma Enumerator to work for his institution. It was not until early October, 2018, that we were able to get Alma Enumerator to work for this institution. Part of the problem was due to a lack of testing, as he has encountered problems I did not at Wartburg. The larger part of the problem was that I overfit my code to the way I needed it to work. For example, I had initially hard-coded a slash character as the separator for multiple numbers, a description like ‘v. 100-102’ would result in an enumeration_a value of 100/102. His library preferred to use a hyphen, which meant I had to rewrite several parts of the code to accommodate the possibility of different separator characters. There may be additional code that similarly hard codes other local idiosyncrasies.
Conclusion
Alma Enumerator is far from perfect, but it did accomplish the job it was meant to do. The process of creating it has also helped me gain a deeper understanding of Python and the programming process from design to coding, testing, and refactoring that I can apply to other projects and hopefully avoid some of the pitfalls that affected this project. It also helped me start thinking about other ways to apply automation to large-scale and tedious tasks.
As for Alma Enumerator itself, the code lives on on GitHub and has been released under the terms of the Unlicense. I’m still actively, though minimally, maintaining it and dreaming of that day when I’ll have the time and energy to fix all its various flaws.
Notes
[1] For a fuller picture of all the various descriptions encountered in the Vogel Library catalog, see https://github.com/wtee/alma_enumerator/blob/master/notes.md.
About the Author
Wesley Teal is a Metadata Librarian at Parks Library at Iowa State University. Previously, he served as the Technical Services Supervisor at Vogel Library at Wartburg College.

Subscribe to comments: For this article | For all articles
Leave a Reply