by Santiago Chumbe and Roddy Macleod
Introduction
WattJournals [1] is an economic, simple-to-implement and easy-to-use search toolkit developed by the JournalTOCs Project [2] for the library of Heriot-Watt University. Its main purpose is to enable library patrons to find new articles as soon as they have been published, limited to those in journals to which the library subscribes. It thus ensures that the full-text of articles found will always be available. What makes this mashup interesting is that it is a real-low cost alternative to expensive library management and database search systems. It does not involve buying a new system, creating a new database or developing any software. The library concerned needs only to install a software toolkit that enables the combination of relevant library web applications and the reuse of data exposed by the API provided by the JournalTOCs Project.
Although WattJournals is a customised version of JournalTOCs, designed specifically for Heriot-Watt University, it can also be easily implemented by other libraries. As libraries are faced with financial cutbacks, many may be forced to cancel licenses for expensive database search services. In this article, we argue that a low-cost option similar to WattJournals may be a real alternative for academic libraries.
Background
JournalTOCs, hosted at Heriot-Watt University, was a project funded by JISC [3] to prototype a current awareness API by making use of article metadata that was already completely freely available through journal Table of Contents (TOC) RSS feeds. The initial aim of the project was to help Institutional Repository (IR) managers to ensure that their repository content was complete and kept up-to-date. It has become the largest, free and searchable collection of scholarly journal Tables of Contents in the world and now contains TOCs for over 14,700 journals collected from more than 600 publishers. JournalTOCs has taken special care to include all the highest rated journals in their fields, with the caveat that it omits TOCs from journals that do not provide TOC RSS feeds.
In December 2009, JournalTOCs produced a lightweight API to handle RESTful search requests from external web applications. The simple RSS standard is the core technology of this API. JournalTOCs uses RSS to daily aggregate new content from the publishers’ web sites, and can also return search results in RSS format to queries received from other web applications. The RSS 1.0 feeds produced by the JournalTOCs API incorporates the Dublin Core [4], CONTENT [5] and PRISM [6] modules to normalize and extend the functionality of the original TOC RSS feeds.
The base URL for the JournalTOCs API is http://www.journaltocs.ac.uk/api It supports four types of calls:
- Search for journals: http://www.journaltocs.ac.uk/api/journals
- Search for articles: http://www.journaltocs.ac.uk/api/articles
- List your favourite journal TOCs (requires user account): http://www.journaltocs.ac.uk/api/user/your@email.address
- Customised searches (requires previous setup of the JournalTOCs toolkit): http://www.journaltocs.ac.uk/api/institution/institutionID
For example, http://www.journaltocs.ac.uk/api/articles/”University of Warwick” will return the latest articles published by authors from the University of Warwick (notice the double quotes around University of Warwick for phrase searching). http://www.journaltocs.ac.uk/api/journals/0267-5730?output=articles returns the latest TOC of the journal with ISSN 0267-5730.
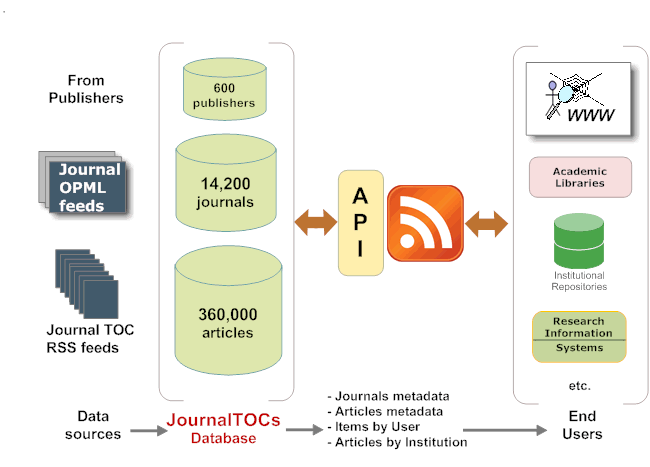 Figure 1. JournalTOCs data sources, database, API and end-users.
Figure 1. JournalTOCs data sources, database, API and end-users.
Figure 1 shows the database and the API created by the JournalTOCs Project, as well as the potential end users for the API. The data is collected directly from the publishers using their own Journal OPML files, if available, and individual TOC RSS feeds where OPML files are not available. Current Research Information Systems (CRIS) are among the potential end users of the API. Institutions, particularly European universities, use CRIS systems to manage, analyse and access information on their research activity. For example, CRIS systems could use the API, alongside other data sources such as Web of Science, Scopus and Biomed Central, to provide cataloguers with a source of bibliographic references. The API could also be used as a mechanism to alert Institutional Repository (IR) managers when new articles written by their academics were published in the TOC RSS feeds or when items submitted to IRs are subsequently published in scholarly journals. The API is also able to search against the email address of a registered user and to return a list of journal TOCs that a user has added to his previously selected MyTOCs folder.
Other use cases for the API were identified by librarians from universities and colleges. In particular, librarians showed interest in using the capabilities of the “customised searches” call offered by the API:
http://www.journaltocs.ac.uk/api/institution/institutionID
In this type of call, institutionID is a unique identifier assigned by JournalTOCs to an entity wanting to have customised search results. For example, TechXtra [7] is a subject-based service that wanted to search TOCs only for articles published in engineering, mathematics and computing. Thus, TechXtra registered the techXtra unique ID with JournalTOCs to be able to filter search results to those appearing in the three subjects. For example:
http://www.journaltocs.ac.uk/api/techXtra/geospatial%20technology/from/1/to/40 searches the JournalTOCs database for TOCs that include the keywords geospatial and technology in their items; filters the items that are not part of the engineering, mathematics or computing subjects and finally; returns only the first 40 filtered items. The results are returned in RSS format, and TechXtra uses a simple web application to handle the results retuned by the JournalTOCs API and to display the final results on its web interface:
http://www.techxtra.ac.uk/techtocs/index.html?query=geospatial technology
The JournalTOCs developers realized that the API’s “customised searches” call could be used to limit search results to only those journals to which a library subscribed. This means that users from that institution will always be able to access the full-text of the articles returned in the search results. Heriot-Watt University Library was the first library to implement this capability. The Library required that the new search service be able to interoperate with its A-Z journal lists, its OpenURL link resolvers and with off-campus access control mechanisms such as EZproxy. In addition, the Library wanted to give its users the option to save searches for later use, and export citations to citation management software, such as EndNote.
Technical Implementation
JournalTOCs Toolkit is a PHP script running against a MySQL table that contains the journal subscription list. The minimum information stored in this table is the ISSN numbers and the titles of the journals. The table is indexed by ISSN number. The library needs to set up this table on its own database server. Because the JournalTOCs API Institutional Call provides access to filtered search results for an institution’s own journals, the first step is to register a unique Institutional ID with the JournalTOCs service. This is an easy process and is more fully described at http://www.journaltocs.ac.uk/docs/index.php?subAction=institution. Secondly, the library needs to purchase a licence and set up the toolkit on its own server if it plans to search in more than 100 journals. The library then needs to either develop its own toolkit to query the JournalTOCs API or customise a toolkit sample provided by JournalTOCs. At Heriot-Watt University Library, the Toolkit was additionally configured to register the Library OpenURL resolver and EZproxy. The toolkit also provides a basic HTML template to display search results on the Web. These templates can be customised or replaced by the Library staff.
The toolkit is designed to act as a lightweight broker between JournalTOCs, the Library software applications and the user web interface. Its main function is to pass “messages” between those applications. Below, we present a high-level outline of the key components of the toolkit algorithm.
- Establishes a connection with the library database system.
- Receives and handles user queries.
- Sends HTTP GET search requests to the JournalTOCs API. The request could be as simple as executing the stream_get_contents() function in PHP.
- Receives lists of matched journals, if any, and their corresponding query IDs.
- Queries the library system database to remove journals that are not subscriptions.
- Sends back (HTTP POST) filtered lists of journals using two key-value pairs (i.e. queryID=123456 and filteredJournals=issn1, issn2, issn3, …).
- Requests, receives and decodes final filtered search results.
- Renders search results in HTML format.
Figure 2 illustrates in more detail the interactions that happen between the applications handled by the toolkit, in response to a search request received from the Web.
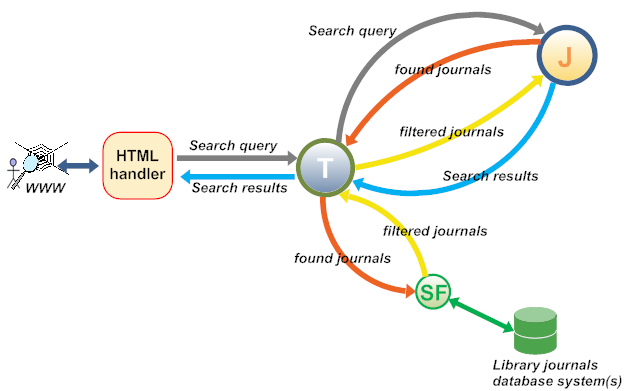 Figure 2. JournalTOCs Toolkit interactions.
Figure 2. JournalTOCs Toolkit interactions.
The JournalTOCs Toolkit is identified with the letter T in Figure 2. The toolkit is at the core of the implementation and handles all requests, communications and responses made by the rest of applications. The process starts when a web user enters a search query in the online form provided by the “HTML handler.” The query is immediately passed to the toolkit, which in turn sends the query to JournalTOCs via the JournalTOCs API (J). JournalTOCs executes the search and finds (1) ISSNs for the journals contained in the search results (“found journals”) and (2) the article-level citation information returned by the search query. J caches the search results, assigns a unique ID to the query and returns the “found journals” list to T, which in turn sends the list to the subscriptions filter (SF). SF can be a function of T or a separated web application. The SF is normally a simple piece of code provided by JournalTOCs in the toolkit sample code and customised by the library, with the support of JournalTOCs if necessary. In the case of WattJournals, the SF is simply a small API that tells whether a journal is in the subscriptions database or not. T uses SF to remove from the J “found journals” list the journals that are not subscriptions. Then, T sends the reminder journals back to J. This list of “filtered journals” is used by J to remove the articles that correspond to journals not found in the returned list. The final filtered search results are sent to T, which uses the “HTML handler” to render the results on the user’s web browser. J destroys the cached search results.
To speed up the exchange of data between J and T, a customised results output format was implemented by JournalTOCs for WattJournals. This format was a simple list of values separated by the | character; where each value contained the metadata for journals or articles and was interpreted as an array element by T. Because the communication between J and T requires a fast in-between lookup mechanism, it was felt that it would be “overkill” to use XML (RSS) to receive and parse results from J for every lookup made by T. However, other options, such as JSON, are available.
The full implementation of a service similar to WattJournals should take a few weeks. WattJournals is not a new system requiring continuous maintenance, but a combination of existing web applications or APIs, all converging together to produce a “new” service at a rapid pace. These combinations, or mashups, are becoming common nowadays, and include APIs, RSS, folksonomies, and social web tools, giving IT managers a new way to approach hard problems with surprisingly effective results.
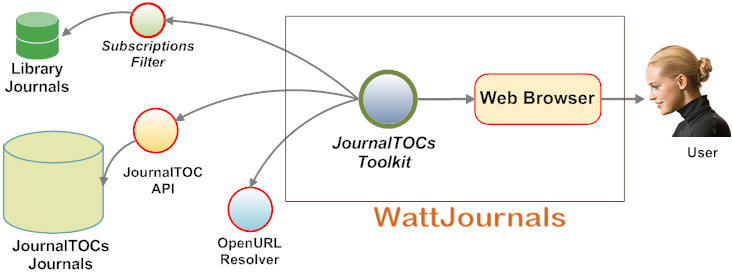 Figure 3. JournalTOCs implementation for WattJournals.
Figure 3. JournalTOCs implementation for WattJournals.
User Interface
From the start, we agreed that the user interface and key features for WattJournals needed to be as simple as possible. We assumed that our typical user was an undergraduate student familiar with rapid ways of looking for information on the Web using search engines such as Google. When unveiling WattJournals in the Library blog [8], Gill McDonald, Acting University Librarian, said “This new service will be particularly useful to students and researchers who want to get some up-to-date articles and research papers quickly and easily. We know that some students find the whole process of navigating several databases and e-journal sites quite confusing at first, and to do a search and then find that the Library doesn’t have a subscription to the journal you’ve found is really frustrating. WattJournals can be a gentle introduction to searching, with the added benefit that all the articles found will be available – no more dead ends!”.
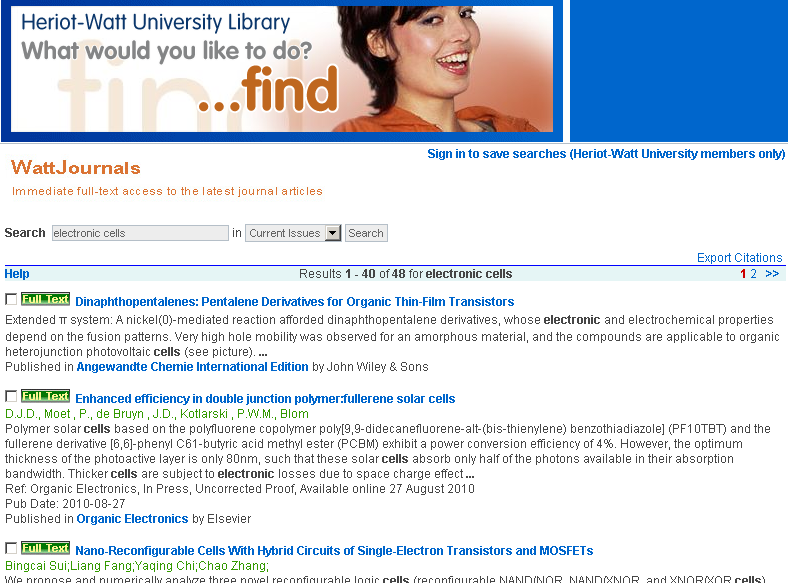 Figure 4. WattJournal search results screen.
Figure 4. WattJournal search results screen.
The end product is a customised journal search service with a simple, easy-to-use local interface. It searches only journals to which a library (in this particular case, Heriot-Watt University library) subscribes. WattJournals only provides access to the content of those Heriot-Watt University subscribed journals which have Table of Contents (TOC) RSS feeds. WattJournals also enables searches to be saved for later use, and the export of citations to EndNote.
Initial Results and User Feedback
Between 1st and 11th June 2010, the JournalTOCs Project team conducted an online user survey for students and academic staff from Heriot-Watt University to help determine the usefulness of WattJournals and to receive user feedback. All the participants in the survey found WattJournals to be useful. In particular, students liked its direct access to the full-text. One student summarised: “It’s very useful to be able to search only articles to which I can gain access, so that I don’t have to scour through pages of articles which I can’t read.” Although WattJournals, by default, searches recently published articles, it also offers an option for searching past works. Based on the survey results, we are now investigating the possibility of merging recent with past issues into a single search target for WattJournals, but at the same time keeping its current awareness feature. Aside from the survey, we also received interesting comments and questions by email.
Behind the scenes, there are several improvements that we would like to make. Currently, WattJournals only searches 65% of the journals subscribed by Heriot-Watt University because not all the subscribed journals produce TOC RSS feeds and, therefore, are not contained in the JournalTOCs database. It is becoming clear, after the user survey and initial feedback received by email, that the service would be improved if WattJournals could somehow include these omitted journals. A possible alternative that the team is investigating is adding commercial external APIs or other web applications to the mashup.
Conclusions
Since its pre-launch in June 2010, WattJournals has quickly proven to be an innovative and economic alternative to large and sometimes complex e-journal search systems. The speed and ease with which WattJournals was built impressed the Heriot-Watt University Library staff and got them interested in the potential of building other mashups for the library. Since the pre-launch, interest from academic libraries wanting to implement similar services on their own web sites has been overwhelming. Besides enquiring on costs, librarians asked us for specific information on the range of content they could obtain from the JournalTOCs database via a WattJournals-type application. We stressed the fact that WattJournals-type applications are not intended to replace the large database systems to which libraries normally subscribe. They have also been made aware that, currently, WattJournals cannot cover all the journals to which the Library subscribes, as it is only able to search those which provide an RSS feed of their tables of contents. Nevertheless, the degree of interest was very high and confirmed to us that the benefits of WattJournals-type services are relevant for both librarians and researchers. Publishers would also reap benefits from having their new papers more readily available for end users.
References
[1] WattJournals. University Library. Heriot-Watt University. http://www.hw.ac.uk/library/WattJournals
[2] JournalTOCs. Institute for Computer Based Learning. Heriot-Watt University. http://www.journaltocs.ac.uk
[3] JISC. http://www.jisc.ac.uk
[4] RDF Site Summary 1.0 Modules: Dublin Core. http://purl.org/rss/1.0/modules/dc/
[5] RDF Site Summary 1.0 Modules: Content. http://purl.org/rss/1.0/modules/content/
[6] RDF Site Summary 1.0 Modules: PRISM. http://purl.org/rss/1.0/modules/prism/
[7] TechXtra. Heriot-Watt University. http://www.techxtra.ac.uk/
[8] “WattJournals has arrived!” Spineless. University Library. Heriot-Watt University. http://hwlibrary.wordpress.com/2010/06/02/wattjournals-has-arrived
About the Authors
Dr. Santiago Chumbe works at the School of Mathematical and Computer Sciences, Heriot-Watt University, Edinburgh, UK. He is the Principal Investigator of JournalTOCs and the Manager of TechXtra services. He has recently been the Project Manager of the WattNames and JournalTOCS-API projects funded by JISC. He is the main editor of the JournalTOCs blog and has more than 30 publications and conference presentations. He is a member of the Europeana Network and the euroCRIS Organisation.
Roddy MacLeod is a retired Information Professional. He previously worked at Heriot-Watt University Library, the University of Malawi Library, and the University of Botswana Library. He has published widely in various scholarly and professional journals and was editor of the Internet Resources Newsletter. He was manager of various JISC funded projects such as EEVL and PerX, and contributed to other projects such as ticTOCs and Gold Dust. He was the winner of the Information World Review Information Professional of the Year 2000. He now writes a personal blog at http://roddymacleod.wordpress.com/.

Aberdeen University Library | Roddy Macleod's Blog, 2013-09-16
[…] Journal is Open Access. But wait – when I clicked on the Details tab, there’s a View full text link, and it takes you to the full […]