By Tito Sierra, Joseph Ryan, and Markus Wust
Introduction
Many libraries, with the goal of modernizing their web presence, are racing to deploy a “next generation catalog.” Next generation catalog applications typically offer a mix of these features: faceted navigation, keyword searching, relevance-ranked search results, “did you mean?”-style search revisions, item recommendations, RSS feeds, and mechanisms to collect and display user feedback [1(COinS)]. These “OPAC 2.0" efforts to replace or upgrade legacy OPACs with more powerful alternatives will no doubt improve the overall catalog experience for many library users. Unfortunately, the gains from these efforts are limited because a single catalog application cannot be optimized for all library users and uses.
Consider, for example, the two basic types of searches a user might perform in a library catalog: known-item and exploratory. In a known-item search the user typically has a specific item in mind; the goal is to acquire information about this item as quickly as possible. In an exploratory search the user has a topic in mind and the goal is to acquire a list of items related to the topic. An interface optimized for a known-item search would likely take advantage of the information the user knows about the item, thus emphasizing bibliographic metadata such as the item’s title or author. Optimizing for an exploratory search would likely emphasize descriptive metadata that items share in common, such as subject headings or user-defined tags. It would be challenging, if not impossible, to optimize a single library catalog application for both of these common use cases.
This conflict begs the question: why should the discovery of library collections be limited to a single catalog application? Given the resources required to keep library catalog data accurate and up-to-date, libraries ought to explore methods for integrating this data into relevant external applications. Lorcan Dempsey, of OCLC, refers to this process as “lifting out the catalog discovery experience.” He writes:
As we work to aggregate supply… so we must work to place these resources where they will best meet user needs. In this process, discovery of the catalogued collection will be increasingly disembedded, or lifted out, from the ILS system, and re-embedded in a variety of other contexts — and potentially changed in the process. [2]
Realizing Dempsey’s vision requires increased flexibility in how we provide programming interfaces to our catalog data. To enable creative use of catalog data and improve interoperability with external systems, we need to think beyond the application-specific enhancements that characterize current OPAC 2.0 efforts. One strategy is to think about our catalogs as a platform that can support many discovery applications, not just the OPAC. We believe this approach shows great promise for libraries looking to enhance long-term end-user discovery and use of library collections.
CatalogWS
Netscape co-founder Marc Andreessen’s definition of “platform” neatly describes the fundamental difference between platforms and applications:
… a “platform” is a system that can be reprogrammed and therefore customized by outside developers — users — and in that way, adapted to countless needs and niches that the platform’s original developers could not have possibly contemplated, much less had time to accommodate.
In contrast, an “application” is a system that cannot be reprogrammed by outside developers. It is a closed environment that does whatever its original developers intended it to do, and nothing more. [3]
In early 2007 the NCSU Libraries began to experiment with the “catalog as platform” approach through an initiative called CatalogWS.
The original designers of CatalogWS, Tito Sierra and Emily Lynema, were members of the team that implemented the first Endeca-powered OPAC [4] in January 2006. Following the release of the new OPAC, the implementation team faced a list of post-launch feature enhancements. Two of these enhancements were RSS feeds for catalog searches, and the integration of catalog search results into Quick Search [5], our library website search tool. Rather than modify the OPAC application, the designers decided it would be better to create a separate application programming interface (API) to the search indices used by the OPAC. Once in place, the API would make it easier to build the desired feature enhancements, as well as enable more versatile catalog data use in the future. After a few weeks of development, the CatalogWS API was born.
CatalogWS currently provides two functions: the “search” service and the “availability” service. The search service returns item and facet values for a given search query, whereas the availability service returns item availability information for a given ISBN. Documentation for both services is available on the CatalogWS project homepage [6]. To date, most of our CatalogWS-powered applications have used the search service.
The scope of the API is necessarily limited because it uses search indices, rather than querying the full set of data stored in the ILS. For example, the API does not expose all the data in the MARC record for our catalog items, since not all MARC fields are indexed by our search server. The designers decided to use search indices as a data source because they provide easy access to normalized data. Using search indices also made the data modeling process much easier because the indices already captured and consolidated the most useful catalog data for end-user application development. This convenience comes at the price of limiting the type of applications that can be built with the API. Since the API is read-only, we could not build tools for modifying bibliographic data or updating the inventory status of items in the catalog. These ILS-oriented functions were beyond the scope of what the designers intended to accomplish with the API.
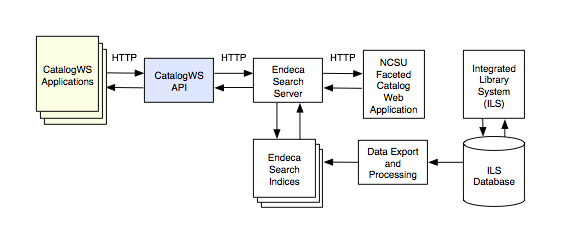
Figure 1: NCSU Libraries catalog architecture [View full-size image]
Despite the scope limitations, we have realized several benefits by using our existing Endeca-generated indices as a data source. Architecturally, search indices are designed to accommodate a high volume of low-latency requests. Building on search indices has also enabled us to include search-specific features in our applications, such as faceted data and spelling suggestions. The earlier Endeca implementation decision to include holdings information in the search indices proved to be very useful for the API. It means we are able to include inventory data in our applications, such as the name of the library that holds the item, the call number of the item, and even the current availability status of the item since the last index update.
The technical implementation of the API was modeled after the REST web APIs implemented by companies such as Yahoo! [7], Facebook [8], and Amazon.com [9]. Requests to the API are made through the HTTP GET protocol. Here is an example of a basic search request:
http://www.lib.ncsu.edu/catalogws/?service=search&query=usability
The search service supports many features one might expect from a search API, such as the ability to limit the number of results returned, and ability to change the sort order of returned results. By default, the service queries our catalog’s “keyword anywhere” index, which looks for keyword matches across many fields in the catalog record. One can also search specific fields such as title, author, or ISBN/ISSN. It is even possible to supply a null keyword to browse the entire catalog. Including facet results in the response makes it possible to query specialized slices of the catalog using shared facet attributes, such as commonly shared subject headings, material formats, or author names.
CatalogWS responses are available in a variety of output formats, with a custom XML format as the default. The decision to define a custom base XML format for the search and availability services was motivated by several factors. First, the API designers believed it would be useful to include as much of the data from the search indices as possible into a single search request, rather than requiring multiple requests to the same data source. For example, the search service returns several categories of response data including search metadata (e.g. total results, spelling suggestions), bibliographic metadata (e.g. item title, author name), holdings data (e.g. library location, call number), and facet results. Although there are many existing standards such as MARC-XML, MODS, and Dublin Core that could describe some of this data in varying levels of granularity, no existing standard seemed suitable for such a heterogeneous collection of data. Second, the API was intended for use by developers at NCSU, rather than for programmatic external application consumption, so cost-benefit analysis of distilling the base API profile into one or more specific standard formats weighed in favor of a custom approach.
Below is an abbreviated XML response for the earlier example. A cached version of the full response is available here.
<?xml version="1.0" encoding="UTF-8"?> <searchResponse xmlns="http://www.lib.ncsu.edu/catalogws/1.0"> <requestUri>http://www2.lib.ncsu.edu:9921/catalogws/?service=search&query=usability</requestUri> <catalogLink>http://www2.lib.ncsu.edu/catalog/?Ntt=usability&Ntk=Keyword&N=0&Nty=1</catalogLink> <searchInfo> <query> <terms>usability</terms> <key>Keyword</key> </query> <totalResults>477</totalResults> <offset>0</offset> <itemsPerPage>30</itemsPerPage> </searchInfo> <item id="1791483"> <catalogLink>http://catalog.lib.ncsu.edu/web2/tramp2.exe/do_ccl_search/guest?setting_key=files&record_screen=record_brief.html&*search_button=keyword&servers=1home&index=ckey&query=1791483</catalogLink> <title>Cost-justifying usability : an update for an Internet age</title> <pubDate>c2005.</pubDate> <format>Book</format> <isbn>0120958112</isbn> <holdings institution="ncsu"> <library name="D.H. Hill Library"> <holdingsItem> <callNumber>QA76.9 .U83 C67 2005</callNumber> <location>Stacks (6th floor)</location> <status>Available</status> </holdingsItem> </library> </holdings> </item> <!-- repeating <item> elements--> <facet id="format"> <title>Format</title> <catalogLink>http://www2.lib.ncsu.edu/catalog/?Ntt=usability&Ntk=Keyword&N=0&Nty=1&Ne=200043#200043</catalogLink> <value> <requestUri>http://www2.lib.ncsu.edu:9921/catalogws/?service=search&query=usability&N=206437</requestUri> <catalogLink>http://www2.lib.ncsu.edu/catalog/?Ntt=usability&Ntk=Keyword&N=206437</catalogLink> <title>Book</title> <count>461</count> </value> <!-- repeating <value> elements --> </facet> <!-- repeating <facet> elements --> </searchResponse>
Although the base XML format is custom, the CatalogWS search service has built-in support for returning results in several standard output formats. Search results can be returned in RSS 2.0, OpenSearch, and JSON formats. Additionally, the API supports an optional “style” parameter that enables requests to specify a path to an XSL stylesheet. When the style parameter is passed, CatalogWS provides server-side XSL transformation services for the request. The style parameter makes it possible for developers to create interactive CatalogWS-powered web applications using only XSL stylesheets.
Current Applications
Since going into production in January 2007, CatalogWS has provided the infrastructure for a variety of applications at NCSU Libraries. Some of the applications developed to date include specialized or experimental catalog interfaces, while others are innovative collection promotion display tools. Below, we provide a few examples of how we have used CatalogWS thus far.
To begin, we will discuss the MobiLIB catalog, an application designed for known-item searches in a mobile context [10]. Some example use cases for this application are looking up call numbers and checking the availability of items in the library bookstacks. Unlike our information-rich OPAC, the MobiLIB catalog is a barebones search tool that allows users to look up an item by keyword, title, author, or ISBN. Given the importance of item location and item availability implied by the mobile use context, the application emphasizes the display of inventory data, such as call numbers, and enables users to limit their search to items that are not checked out.
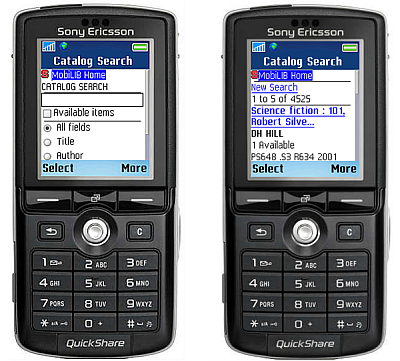
Figure 2: MobiLIB catalog [View full-size image]
Developing MobiLIB presented several challenges. The first was getting the application to function and display properly on a variety of mobile device platforms including handheld PCs, web-enabled cell phones, and PDAs. The smaller displays on these devices limit the amount of information that can be displayed in each view. Mobile devices also have speed and cost-related bandwidth issues. These unique constraints forced us to rethink the catalog search experience from the ground up.
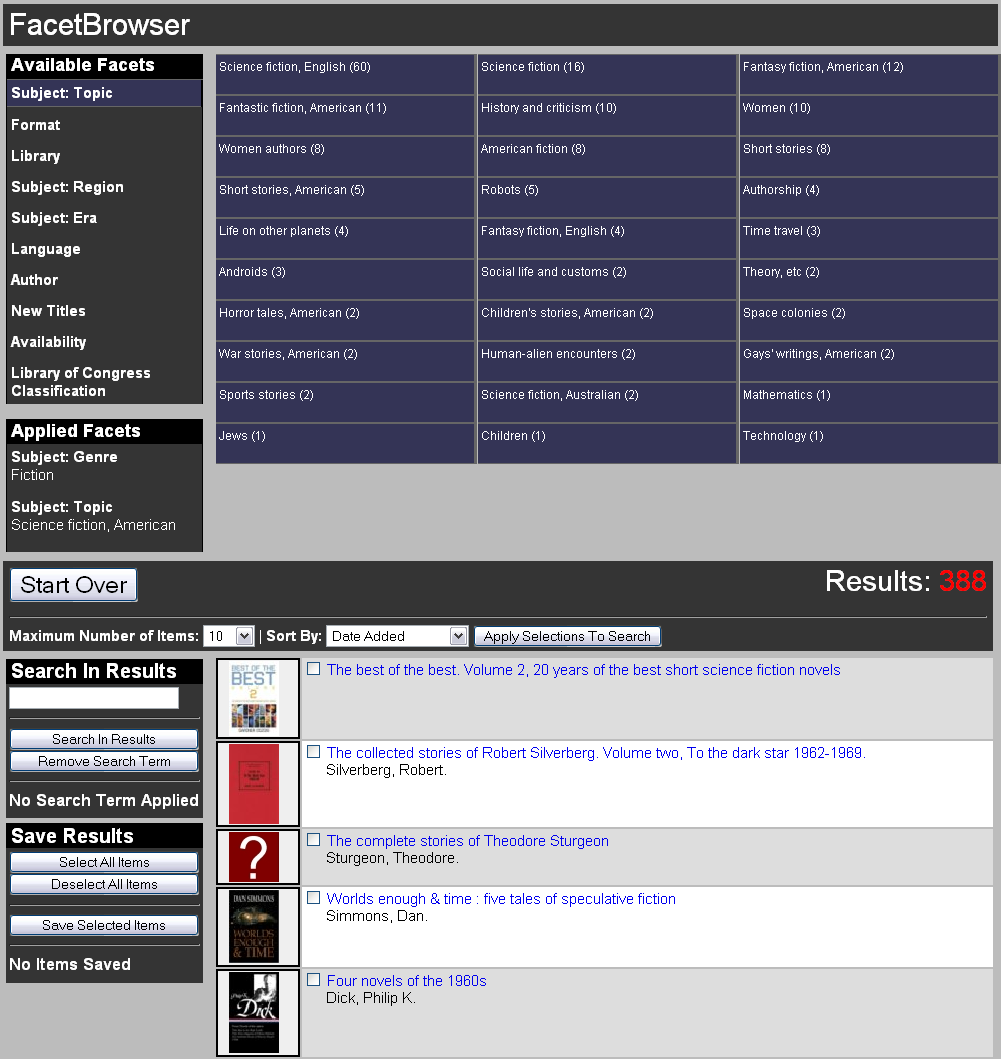
While the MobiLIB catalog is optimized for known-item searches, FacetBrowser is an experimental catalog interface that was designed to emphasize facets for use in exploratory searches [11]. FacetBrowser places facets persistently at the center of the application’s interface. This design encourages users to browse the entire catalog at once, promoting use of facets as a way to explore or navigate the results set at every level. We believe this approach has the potential of exposing users to items in the catalog that they otherwise might not have discovered in a more conventional catalog search application.
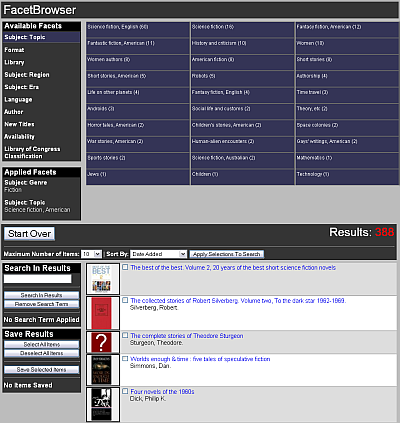
Figure 3: FacetBrowser [View full-size image]
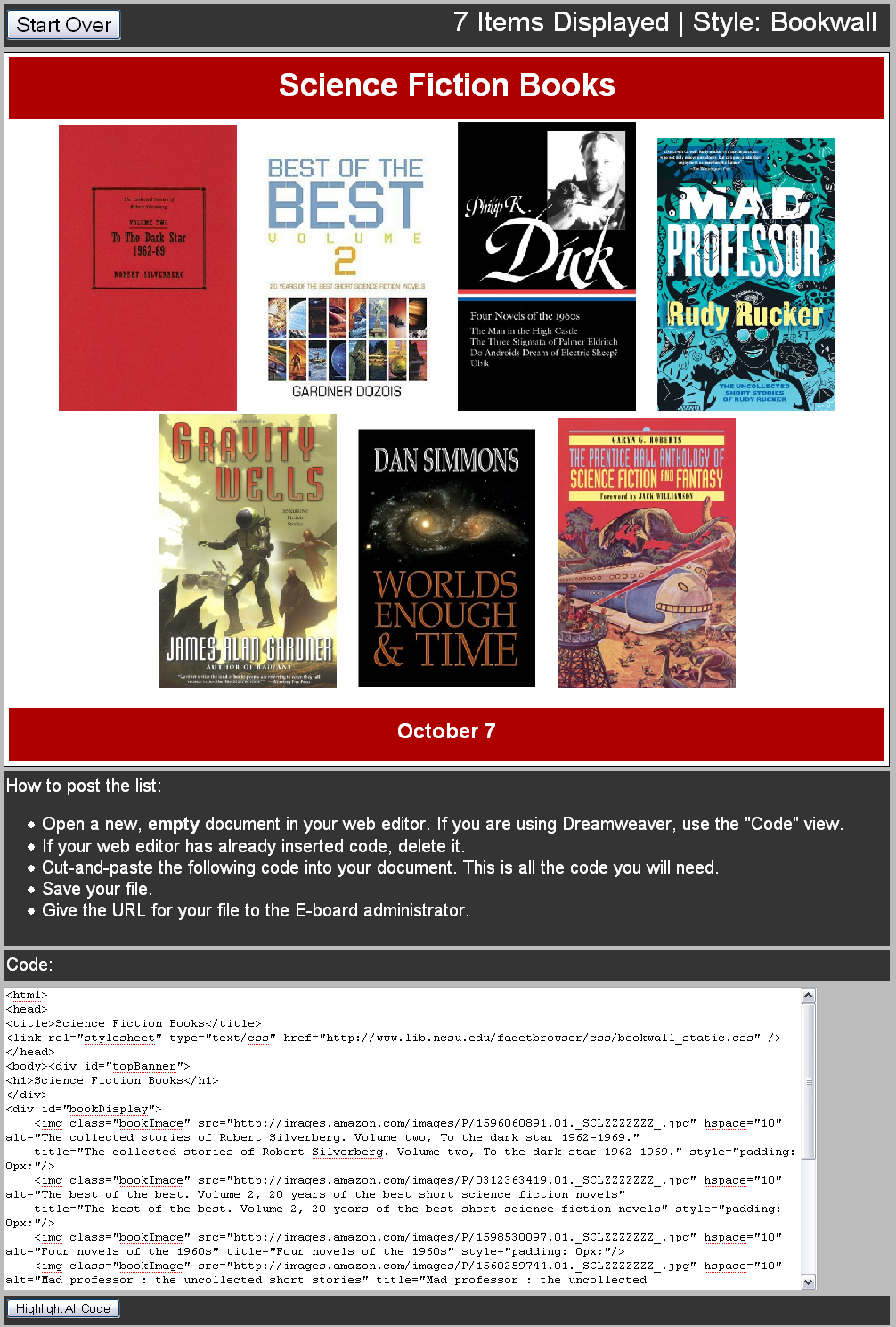
Besides serving as an experimental catalog interface, FacetBrowser has also provided us with an opportunity to promote library collections in new ways. As part of our recently opened NCSU Libraries Learning Commons, several large screen displays were installed in the new space to promote a variety of library services. Some of these displays are dedicated to showing “bookwalls,” which are displays of book cover images for a thematic collection of books from the catalog. FacetBrowser provides the means for library staff to quickly generate these bookwalls. The process involves applying one of several built-in output styles to an editorially selected list of items in FacetBrowser. The application automatically generates the HTML used to display the bookwalls on our large screen displays, enabling library staff with limited technical skills to promote specialized collections of books in a visually appealing way.
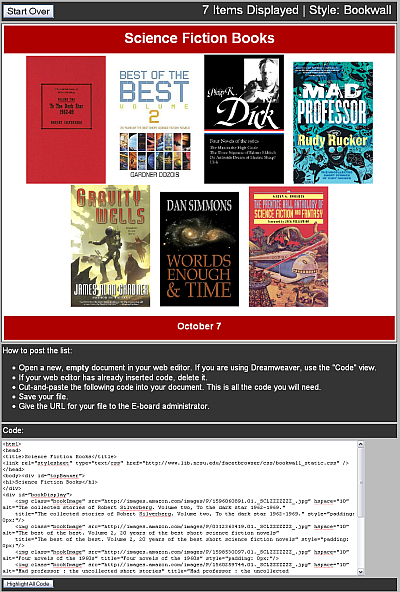
Figure 4: FacetBrowser bookwall output display [View full-size image]
In addition to bookwalls created by FacetBrowser, we use CatalogWS to promote library collections in other ways. The New Books Bookwall is similar to the staff created thematic bookwalls, except that the focus is on featuring books recently added to the collection [12]. This bookwall is different because the items it displays are not hand selected. Instead, a scheduled CatalogWS request retrieves the 300 newest items, with the goal of providing a peek at what’s new at the library.
The New Faculty Books display is a variant on the New Books Bookwall [13]. This application focuses on featuring new books published by NCSU faculty. Although the user interface is slightly different, the underlying technical implementation is the same. The New Faculty Books display adds an additional filter constraint to items authored by NCSU faculty.

Figure 5: New Faculty Books list [View full-size image]
Closing Thoughts
Returning to Andreessen’s definition of a “platform,” we see that the final part of his definition is that a platform enables outside developers to adapt the system “to countless needs and niches that the platform’s original developers could not have possibly contemplated, much less had time to accommodate.” This observation mirrors the NCSU Libraries’ experience perfectly. Although the original motivation for the API was to enable development of some OPAC feature enhancements, we have been able to use the API to create completely new applications that exist independently of the OPAC.
The platform approach has provided us with two distinct benefits. First, the API has reduced catalog application development time because it exposes data in an easy-to-use format. A second benefit is that our API has enabled versatile use of catalog data, as illustrated by the applications we have built so far.
As we reflect on our experience to date, we find that the collection of data exposed by our API could be more comprehensive. We encourage those who are developing a similar platform to cast a broad net when deciding what content to include in their API. Although our lightweight approach has worked well for us, we acknowledge the limitations of relying on search indices as a catalog data source. Those interested in learning from a more ambitious “catalog as platform” approach should look at the Talis Platform [14], which supports a wide range of interfaces and technologies.
Overall, we believe the time invested in developing our catalog platform was worth the effort and should continue to pay dividends in the near future. We never anticipated that CatalogWS would serve as a basis for such a broad range of applications. In our organization, it has fostered a culture of experimentation and enabled a larger group of staff to work with library catalog data in new and interesting ways. Although we are in the early stages of working with our platform, we recognize there is a large amount of untapped potential. We would like to see other institutions experiment with the platform approach and we welcome the opportunity to learn from other libraries about how to fully exploit the value of catalog data beyond the OPAC.
Notes
- Marshall Breeding. Next-Generation Library Catalogs. Library Technology Reports 43(4). July/August 2007.(COinS)
- Lorcan Dempsey. The Library Catalogue in the New Discovery Environment: Some Thoughts. Ariadne 48. July 2006. http://www.ariadne.ac.uk/issue48/dempsey/
- http://blog.pmarca.com/2007/06/analyzing_the_f.html
- http://www.lib.ncsu.edu/catalog/
- http://www.lib.ncsu.edu/dli/projects/quicksearch/
- http://www.lib.ncsu.edu/catalog/ws/
- http://developer.yahoo.com/search/
- http://wiki.developers.facebook.com/index.php/API
- http://aws.amazon.com
- http://www.lib.ncsu.edu/m/catalog/
- http://www.lib.ncsu.edu/facetbrowser/
- http://www.lib.ncsu.edu/display/bookwall/eboard.php
- http://www.lib.ncsu.edu/display/facultybooks/list
- http://www.talis.com/tdn/platform/
About the Authors
Tito Sierra is Assistant Head for Digital Library Development at NCSU Libraries where he leads a small research and development team that builds new digital library applications.
Joseph Ryan is an NCSU Libraries Fellow in the Digital Library Initiatives and Administration departments.
Markus Wust is an NCSU Libraries Fellow in the Digital Library Initiatives and Special Collections departments.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Subscribe to comments: For this article | For all articles
Leave a Reply