Introduction
With the advent of large book data repositories such as Google Book Search, Open Library and Worldcat along with the application programming interfaces (APIs) that accompany them, programmers are quickly developing new tools to enhance patron user experiences at library web sites. At Paul Smith’s College, I recently implemented a “New Books” display on the front of our web page using some of these open APIs in conjunction with a very affordable 3rd party application used to create an image scroller. In this article I’ll give a brief overview of the some of the larger book data providers, show how I used some of this data to create a New Books Widget at Paul Smith’s College, and provide readers with some practical and simple code to show how to collect this data.
This article will be of interest to anyone who wants a brief overview of current state of free book data service providers and some projects that were created using them. Additionally, beginner programmers will likely find the examples at the end of the article helpful when getting started with projects of their own.
Introduction to 3rd Party Data Providers
A trend in online service providers has been to create application programming interfaces (APIs) for software developers. APIs are simple ways for computers to give and take data from each other, allowing developers to use the data and repackage it in different and creative ways. Worldcat, Google Book Search, LibraryThing and Open Library have extensive data repositories with metadata on millions of books. Each of them has an API that allows developers to query, collect and use only the information they need.
Additionally, some of these providers (namely Google and Open Library) have been offering full or limited access to the actual scanned text of some books. Libraries that recently had access to these books only in print now have the ability to point their users to online copies of these books and allow them to search and see them without having to travel to the book shelves. I recently queried Open Library with a subset of books we house in our library archives and found that between 30-50% of my queries reached a book that had been scanned, placed online, and was available for viewing or download in full-text. By simply adding a link in our catalog records for these books, we can allow our patrons to have access to books that were recently only able to access with special permission.
Let’s take a brief look at some of the major data providers and discuss some of the offerings of each.
Google Book Search API
Google Book Search API documentation can be found at http://code.google.com/apis/books/.
Google Book Search (GBS) API allows you to programmatically embed book previews on your websites, gather social information such a book reviews, ratings, labels, and user library data, and perform searches on the GBS database to get back detailed results on the books. This allows users to, for example, query the GBS database by keyword, ISBN or OCLC number and receive back general record information such as title, author, and publisher, etc. as well as whether Google has a thumbnail cover image or a book preview is available.
Some uses of Google Book Search
Many institutions and organizations are using GBS in creative ways to enhance the products and services they deliver. The strength of GBS that sets it apart from the other services providers is its embedded preview capabilities. Perhaps the most notable example of GBS uses related to library services is found in OCLC’s Worldcat. When viewing an item level record in Worldcat, users can see the “Google Preview” button located in the “Get It” section of the page when a preview is available.
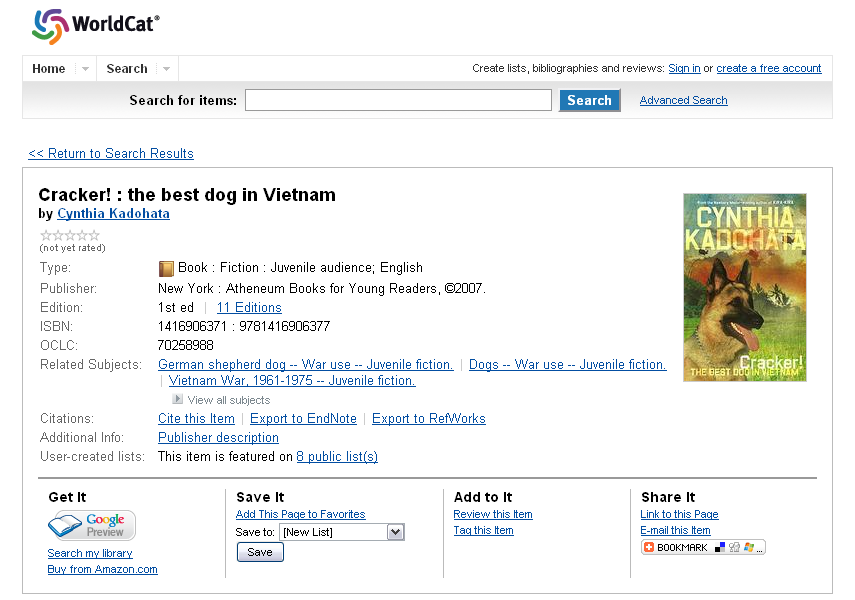
Figure 1: A screenshot from an item record in the WorldCat catalog showing the Google Preview icon when a preview is available. [View full-size image]
When clicked, the user is brought to a new Worldcat page with the Google Preview embedded in the site.

Figure 2: Google Book Preview embedded into the WorldCat catalog website. Users can search and view pages. [View full-size image]
GBS limits the pages that users are able to see, but still allows access to a significant portion of the book. Users are also able to search the full content of the book.
Worldcat Search API
Worldcat Search API documentation can be found at http://www.oclc.org/worldcatapi/.
The WorldCat API provides access to the Worldcat database using RESTful URI queries that return the results in a variety of formats, including RSS, Atom, MARC XML and Dublin Core. The Worldcat API is free to all cataloging members with a subscription to Connexion and requires member libraries to apply for an access key that is used when performing queries.
The Worldcat database contains over 100 million records written in 470+ languages from 112 countries in every conceivable physical and electronic format, all of which are accessible via the Worldcat Search API [1]. The clear strength of the Worldcat API is the vast amount of information that is available and the flexibility of the API itself.
Some uses of Worldcat Search API
Perhaps the most notable demonstration of the API that illustrates its power and flexibility is a prototype online public access catalog (OPAC) that was built completely using API commands to Worldcat. David Walker, from California State University, developed this prototype and gave a presentation at Code4lib 2008 titled “Working with the WorldCat API” [2]. David was able to create a completely customized user interface and populate it with data from Worldcat.
At Paul Smith’s College we use the Worldcat API to populate our item level displays in our OPAC with bibliographic citations.

Figure 3: An item level view of the Paul Smith’s College OPAC showing bibliographic citations for the book downloaded via the WorldCat API. [View full-size image]
Open Library API
Open Library API documentation can be found at http://openlibrary.org/dev/docs/api.
Open Library, a project of the Internet Archive, has the goal of creating one page for every book ever published. They currently have 20 million available records and over 1 million books available in full-text [3]. The entire project is open, including the source code that runs the web page and all of the data in the database. Open Library has scanning centers that scan out-of-copyright books which are then added to the database. Much of the data in Open Library comes from donated MARC records from large university libraries. While still in beta, the Open Library API is a great source of data for projects that can leverage its API.
Some uses of the Open Library API
While not as large as the Worldcat database or providing as much copyrighted information as Google, the strength of Open Library is found in its openness with the content it houses. It is the only source of bibliographic data that is both open source and open data, meaning all of its data and the software that displays it is available to download, use and reuse [4]. Perhaps the most popular example of one of its uses is found in the OpenBookData plugin for WordPress [5]. WordPress is a an open source blog software package and WordPress plugins are created by community members that allow users to extend the capabilities or WordPress. The OpenBookData plugin allows users of WordPress to put book covers and book information from Open Library on their sites. For more information on the OpenBookData plugin, please see John Miedema’s article in Issue 4 of Code4lib Journal [6].
At Paul Smith’s College, our thumbnails and some book information in the New Books Widget come directly from the Open Library API.
LibraryThing API
LibraryThing API documentation can be found at http://www.librarything.com/services/ and http://www.librarything.com/api.
LibraryThing is a for-profit company that lets book lovers create online catalogs of their books. LibraryThing connects people who have similar reading interests by finding similarity between their libraries. Users are able to rate books, write reviews and even have conversations about books online. LibraryThing’s API comes in a variety of different packages and flavors ranging from web based XML queries to simple book thumbnail requests.
Their Web Services API allows users to download interesting and often unique information about books, and herein lies its most important strength. Because a lot of LibraryThing data is created by its users, it is often possible to collect some really unique information on books that might not be available elsewhere, such as first and last lines, awards and honors the book has received, important places in the book, and user book reviews. Also of notable mention is the fact that LibraryThing now has over 1 million user-uploaded book covers that are open and available to use by developers as well as data feeds that enable users to download certain sets of raw data and thumbnail images [7].
Some uses of LibraryThing API
LibraryThing provides JavaScript generation tools on their website to help users add LibraryThing data on their web pages and blogs as well as getting LibraryThing on your cell phone. In the LibraryThing developers’ forum there is some talk of getting LibraryThing applications for the iPhone or iPod Touch [8].
Making a New Books Display at Paul Smith’s College
At Paul Smith’s College, we recently undertook a major website redesign and we left a large center portion of our site available to advertise some of the services we offer to our patrons. One of the services we decided to start with was a new books widget that mirrored our new books display in the library. To make the library web page more interesting and useful to our users, we incorporated data that is freely available from Open Library and Google Book Search to supplement the information already available in our library catalog. Here are screenshots of our website before and after the new books widget was implemented:

Figure 4: Paul Smith’s College Library website before and after the new books widget was implemented. [View full-size image]

Figure 5: Paul Smith’s College Library website after the new books widget was implemented. [View full-size image]
The user interface was created using a very inexpensive 3rd party JavaScript scroller creator called Sothink JavaScript Web Scroller [9]. After modifying the scoller templates in the Sothink product, I was able to collect data from a database populated with book information from our ILS, Google Book Search and Open Library.
Implementation
The process between adding new books in the catalog to displaying them on the web page has many steps and components. Here is an overview of the process that the New Books application performs to create an automated new books widget on our library website:
- Each night, our ILS outputs a pipe delimited text file to a web accessible folder on the server. The file contains the title, author, and ISBN of books that are newly added to our catalog.
- The web server downloads the created text file from the ILS server.
- A Python script reads the text file and, for each item, uses the 3rd party APIs to download and store the relevant book data in a MySQL database for use by the New Books Widget.
- If a thumbnail image of the book cover is found in the search process, it is also downloaded, renamed to match the ISBN number of the book, and saved.
- The New Books Widget, created with the Sothink JavaScript Web Scroller and a PHP script, queries the database for relevant new book information and populates the widget with the data as well as the saved thumbnails.
When a user opens the library web page, the New Books Widget loads the thumbnail files and queries the required information from the database and displays it. I wanted to keep the book data separate from the tool so that if, down the road, we decide to change our web presence, the data would still be accessible to be used in a different form. Additionally, keeping the data separate from the widget allows us to create other tools, such as RSS feeds for new books; novel ways to display book covers and information, such as making a wall of books [10], creating a Coverpop [11]; or using book data to support a digital signage display [12].
Getting the book data
The code for Paul Smith’s College’s New Books Widget will continue to be customized as our needs evolve. So, instead of delving into the specific details of how I made the widget, let’s look at some basic principles on how to get data from a couple of the content providers, namely Google Book Search and Open Library, so that you can start making your own services to meet the needs of your users.
One common search feature that each of these services has is the ability to query by ISBN number. Let’s walk through a Python code sample of reading data from a text file that contains ISBNs and querying each of the services to retrieve book data and cover thumbnails.
What you will need:
- A copy of Python [13] installed on your computer. The code in the article has been tested on Python version 2.5. (http://python.org/)
- The demjson python library. (http://deron.meranda.us/python/demjson/) Note: At the time of writing this article, demjson does not currently work with Python 3.0. A new version is in production.
The process:
Our sample program will perform the following steps:
- Read a text file that contains ISBN numbers
- For each ISBN, query Open Library and Google Book Search API and retrieve back the data in a usable format.
- Download and save book covers from Open Library and Google Book Search if available.
Step 1: Reading the ISBN text file
The first thing we have to do is load the Python modules that we will be calling.
#import some of the modules we will need to use to complete our tasks import urllib, urllib2, demjson, os
The modules imported on the 1st line of the code snippet perform several different functions. The urllib [14] and urllib2 [15] modules provide functions that allow users to gather data from the Internet and are used to query GBS and Open Library. The demjson module will allow us to quickly and easily take the JSON [16] data from GBS and Open Library and convert them into Python variables that we can reuse in our programs. The os [17] module allows us to read and write to files which will be useful when we want to read the text file that contains ISBN numbers as well as save the image thumbnail images that we collect. The urllib, urllib2 and os modules come with Python 2.5. The demjson module needs to be downloaded and installed before you use it.
Given a text file of ISBN numbers separated by carriage returns, we can read these items into a Python list (also called an array in other programming languages).
#create a function that will read lines from a text file and
#store the contents in a list
def read_newbooks_file(path):
data = open(path)
isbnlist = []
for isbn in data.readlines():
isbnlist.append(isbn.replace("\n",""))
return isbnlist
#read our text file and name the list "isbns"
isbns = read_newbooks_file("C:\\newbooks.txt")
#print our results
print isbns
If our text file found at C:\newbooks.txt contained the following ISBNs:
0618379436 9780700615582 9781593761288 9781405163354
This program would output the “isbns” list that looks like this:
['0618379436', '9780700615582', '9781593761288', '9781405163354']
We can now use this list to query the service providers for book information.
Step 2a: Searching Open Library
Open Library API Documentation can be found at http://openlibrary.org/dev/docs/api
The Open Library API allows users to query its database in a number of ways. The result of an ISBN query returns unique IDs to the book that are specific to the Open Library database. In order to get actual book data from Open Library, we first need to query the database for items that match our ISBN. Open Library will return the unique ID values back which we could then use to find book specific data for each title.
Open Library returns JSON formatted data which, after it has been gathered, needs to be parsed and converted to Python using a JSON library. There are several JSON libraries available to use for Python, but I chose to use demjson.
The following code cycles through our ISBN list and queries Open Library to see if it has the books in their database.
#cycle through each isbn in the list
for isbn in isbns:
#create the url string to query openlibrary
url="http://openlibrary.org/api/search?q={%22query%22:%22(isbn_10:(" + isbn + ")%20OR%20%20isbn_13:(" + isbn + "))%22}"
#send the url request and name the JSON response "response"
response=urllib.urlopen(url)
#translate the JSON response into a python variable of dictionaries and lists
book=demjson.decode(response.read())
#if the result set isn't empty (i.e. it returned a hit)
if book["result"]!=[]:
results = book["result"] #value of python dictionary value - returns a list
#print out the list
print results
#take the 1st item in our list, the Open Library Key for the book and create a url to query again
url = "http://openlibrary.org/api/get?key=" + results[0]
#send the url request and name the JSON response "OLResult"
OLResult=urllib.urlopen(url)
#translate the JSON into a python variable
data=demjson.decode(OLResult.read())
#print it
print data
When you run this code, it should output a dictionary object with the book data embedded in it. Here is sample output:
[u'/b/OL7604987M']
{u'status': u'ok', u'result': {u'publishers': [u'Houghton
Mifflin'], u'languages': [{u'key': u'/l/eng'}], u'subtitle':
u'And Other Stories of Intriguing Kitchen Science',
u'key': u'/b/OL7604987M', u'title': u'How to Read a French
Fry', u'number_of_pages': 320, u'isbn_13':
[u'9780618379439'], u'isbn_10': [u'0618379436'], u'publish_date':
u'September 8, 2003', u'last_modified': {u'type':
u'/type/datetime', u'value': u'2008-04-29 13:35:46. 87638'},
u'authors': [{u'key': u'/a/OL2688000A'}], u'type': {u'key':
u'/type/edition'}, u'id': 10350312, u'first_sentence':
{u'type': u'/type/text', u'value': u'Everyone loves
deep-fried foods, as a glance at any fastfood menu will
prove.'}, u'revision': 1}}
Step 3a: Getting book covers from Open Library
Now that we have the book data, we need to download the book cover image. Open Library stores its book covers in small, medium and large formats and uses the Open Library Unique IDs in the URL.
You can request different book cover image sizes by changing the URL of the image. Ending the URL with a –S, -M, or –L provides you with small, medium and large images respectively. The following URLs point to thumbnails with an Open Library Unique ID of OL7604987M:
- Small: http://covers.openlibrary.org/b/olid/OL7604987M-S.jpg
- Medium: http://covers.openlibrary.org/b/olid/OL7604987M-M.jpg
- Large: http://covers.openlibrary.org/b/olid/OL7604987M-L.jpg
Because we already have the Open Library Unique IDs from our previous code section, we simply need to add a few lines of code to download the book covers. When Open Library doesn’t have a book cover, it returns a small file with a length of 808 bytes. In the code below, we check this by downloading the file and checking its size (in the case of the code below, we check if it’s smaller than 1000 bytes). If the file is smaller than 1000 bytes we know we have an invalid thumbnail and delete the bad file.
#The url to the thumbnails end with -S for small, -M for medium, -L for large
imgurl = 'http://covers.openlibrary.org/b/olid/' + results[0][3:] + '-M.jpg'
#retrieve the file and save it to C:\ with the name of the isbn as the name of the file
imgfile = urllib.urlretrieve(imgurl, "C:\\" + isbn + ".jpg")
#retreive the file size and if the file size is less then 1000 bytes, delete it
fsize = os.path.getsize(imgfile[0])
if fsize < long(1000):
os.remove("C:\\" + isbn + ".jpg")
[/sourcecode]
Notice on the 1st line of the code I needed to add the "<code>[3:]</code>" to remove the 1st three characters from the Open Library IDs, because the API returns the IDs with a "<code>/b/</code>" appended to the front (i.e. "<code>/b/OL7604987M</code>") and we only need to use the ID (i.e. "<code>OL7604987M</code>"). After running the program, I found three book thumbnails in my C:\ folder with ISBN numbers as their name, indicating that one of our books doesn't have a thumbnail in Open Library:
<p class="caption"><img id="figure6" title="Figure 6" src="https://journal.code4lib.org/media/issue6/beccaria/figure_6.png" border="0" alt="Figure 6" width="376" height="565" />
<strong>Figure 6: Three book thumbnails downloaded from Open Library.</strong>
<h3>Step 2b: Searching Google Book Search</h3>
Google Book Search API documentation can be found at <a href="http://code.google.com/apis/books/">http://code.google.com/apis/books/</a>
Google Book Search provides an API that allows users to get access to the metadata associated with books in its library. Google has partners with a number of publishers and large academic libraries and has been scanning a large number of books and adding them to their collection [<a id="ref18" href="#fn18">18</a>, <a id="ref19" href="#fn19">19</a>]. Depending on copyright and publisher permissions, Google allows snippets, previews or full-access to books scanned into its database. At Paul Smith's College, we are using GBS information in our open source OPAC [<a id="ref20" href="#fn20">20</a>] as well as in our New Books Widget. If a Google Book preview is available, an icon is shown under the book title in the results page. In our New Books Widget, when a user hovers over a book cover with their mouse, a popup is shown with more detailed book information. For both tools, if a preview is available from Google, an icon is shown with a link to the book on the Google Books site.
<p class="caption"><a title="Figure 7" href="https://journal.code4lib.org/media/issue6/beccaria/figure_7.png"><img id="figure7" src="https://journal.code4lib.org/media/issue6/beccaria/figure_7_tb.png" border="0" alt="Figure 7" width="500" height="291" /></a>
<strong>Figure 7: When a user hovers over a book cover with their mouse, a popout window displays further information and, in this case, a Google Preview link.</strong> [<a href="https://journal.code4lib.org/media/issue6/beccaria/figure_7.png">View full-size image</a>]
The GBS API allows you to perform searches and get back book information, reviews, ratings, labels, and user libraries, as well as embed Google Book previews on your website. The documentation on the Google site is quite extensive and allows the potential for some great tools to be made. To get started, we are going to continue our book code sample by gathering data that indicates whether Google Book Search has a preview and a cover image for a given book.
GBS API allows HTTP GET requests to be made with OCLC, ISBN or LCCN numbers and it returns data in JSON format. Because we already have ISBN numbers for our books, we will use those to search GBS in our example.
Here is a sample URL request that will receive data back from Google:
<a href="http://books.google.com/books?bibkeys=ISBN:0451526538&jscmd=viewapi&callback=mycallback">http://books.google.com/books?bibkeys=ISBN:0451526538&jscmd=viewapi&callback=mycallback</a>
Google returns JSON-formatted data with these elements:
<pre>JsonSearchResult {
string bib_key;
string info_url;
string preview_url;
string thumbnail_url;
string preview;
};</pre>
Starting where we are cycling through our ISBNs, let's take our example code and append a section that returns Google Book information.
[sourcecode language='python']
#create parameters that will be used in the URL sent to Google. The results will be called gcallback.
gparams = urllib.urlencode({'bibkeys': isbn, 'jscmd':'viewapi','callback':'gcallback'})
#open a new urllib2 handler and send the request
opener = urllib2.build_opener(urllib2.HTTPHandler())
request = urllib2.Request('http://books.google.com/books?%s' % gparams)
#We need to change the headers to trick google to think that firefox is sending the request
opener.addheaders = [('User-Agent', 'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.3) Gecko/2008092417 Firefox/3.0.3')]
#Read the response from Google
g = opener.open(request).read()
#print the results
print g
#if the results aren't empty, strip the "gcallback" parameter from the JSON results leaving only the relevant data
if g != "gcallback({});":
g = g[10:-2]
#translate the JSON into a python variable
gbookinfo=demjson.decode(g)
#Google only sends values that have data, so we need to check if that data
#exists before we can print it or else Python will throw an error.
#print the URL to the Google Page and the URL to the thumbnail
if gbookinfo[isbn].has_key("info_url"):
print "GB info url: " + gbookinfo[isbn]["info_url"]
if gbookinfo[isbn].has_key("thumbnail_url"):
print "GB thumbnail url: " + gbookinfo[isbn]["thumbnail_url"]
Notice that I didn’t use the typical urllib python library in the same way that we did for Open Library. After some trial and error, I realized that Google wasn’t returning results to me despite the fact that the program was structurally correct. Google’s API would not accept the HTTP headers that were being sent by the Python module. I had to trick Google into thinking the request was coming from the Firefox web browser by changing the headers.
Also note that the GBS API only returns results when it actually has the data (i.e., it will not return any thumbnail URL data if it doesn’t have any, versus returning an empty string). I had to check if the results included the key/value pairs that I was looking for (i.e., “info_url ” or “thumbnail_url”) or Python will throw an error. The above code sample should output the URL’s to the Google Books information page and the URL to the book cover thumbnail for the book in question. e.g., the code outputs URLs such as the following:
- GB info url: http://books.google.com/books?id=Qd0QAAAACAAJ&source=gbs_ViewAPI
- GB thumbnail url: http://bks8.books.google.com/books?id=Qd0QAAAACAAJ&printsec=frontcover&img=1&zoom=5&sig=ACfU3U2MMlbjE9kPba16K_RrAfmUKMn62Q
Step 3b: Getting book covers from Google Book Search
Let’s see how to download the thumbnails and add them to our folder with the images from Open Library. Because Google doesn’t accept Python headers when requesting objects, we need to send Firefox headers again so Google will allow us to download the image thumbnails. Google Book Search returns the image URL in the “thumbnail_url” value. Here’s the code to complete our program:
#we need to send a request to Google and change the headers to imitate firefox
opener = urllib2.build_opener(urllib2.HTTPHandler())
request = urllib2.Request(gbookinfo[isbn]["thumbnail_url"])
opener.addheaders = [('User-Agent', 'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.3) Gecko/2008092417 Firefox/3.0.3')]
#and download it and save it with a -g appended to the end to indicate it came from Google
picfile = open("C:\\" + isbn + "-g.jpg", "w+b")
picfile.write(opener.open(request).read())
The end product of the complete program should be book data stored as Python objects that can be used easily in any programs you write, as well as downloaded thumbnail images, with those saved by GBS having a –g appended to the end of the file name. You are now only a few small steps away from creatively using this data. Hopefully this sample got you started.

Figure 8: Six thumbnail images, three from Open Library and three from Google Book Search. [View full-size image]
To make the sample easier to use, here is the complete version of the program with all of the comments removed.
import urllib, urllib2, demjson, os
def read_newbooks_file(path):
data = open(path)
isbnlist = []
for isbn in data.readlines():
isbnlist.append(isbn.replace(“\n”,””))
return isbnlist
isbns = read_newbooks_file(“C:\\newbooks.txt”)
print isbns
for isbn in isbns:
url=”http://openlibrary.org/api/search?q={%22query%22:%22(isbn_10:(” + isbn + “)%20OR%20%20isbn_13:(” + isbn + “))%22}”
response=urllib.urlopen(url)
book=demjson.decode(response.read())
if book[“result”]!=[]:
results = book[“result”]
print results
url = “http://openlibrary.org/api/get?key=” + results[0]
OLResult=urllib.urlopen(url)
data=demjson.decode(OLResult.read())
print data
imgurl = ‘http://covers.openlibrary.org/b/olid/’ + results[0][3:] + ‘-M.jpg’
imgfile = urllib.urlretrieve(imgurl, “C:\\” + isbn + “.jpg”)
fsize = os.path.getsize(imgfile[0])
if fsize < long(1000):
os.remove("C:\\" + isbn + ".jpg")
gparams = urllib.urlencode({'bibkeys': isbn, 'jscmd':'viewapi','callback':'gcallback'})
opener = urllib2.build_opener(urllib2.HTTPHandler())
request = urllib2.Request('http://books.google.com/books?%s' % gparams)
opener.addheaders = [('User-Agent', 'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.3) Gecko/2008092417 Firefox/3.0.3')]
g = opener.open(request).read()
print g
if g != "gcallback({});":
g = g[10:-2]
gbookinfo=demjson.decode(g)
if gbookinfo[isbn].has_key("info_url"):
print "GB info url: " + gbookinfo[isbn]["info_url"]
if gbookinfo[isbn].has_key("thumbnail_url"):
print "GB thumbnail url: " + gbookinfo[isbn]["thumbnail_url"]
opener = urllib2.build_opener(urllib2.HTTPHandler())
request = urllib2.Request(gbookinfo[isbn]["thumbnail_url"])
opener.addheaders = [('User-Agent', 'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.3) Gecko/2008092417 Firefox/3.0.3')]
picfile = open("C:\\" + isbn + "-g.jpg", "w+b")
picfile.write(opener.open(request).read())
[/sourcecode]
Conclusion
We have just begun to scratch the surface of gathering data from content providers and finding new ways to present it to our patrons. This article was meant to explain how we at Paul Smith’s College created a New Books Widget and added supplemental data to our book catalog using many of the same principles described in the provided code samples. We covered an overview of some of the larger content providers, gave an outline of how we used data from those content providers, and provided some building block code samples to get the beginning programmer started.
Book Data Downloader at Google Code
If you are interested in delving further into downloading and storing book data from these repositories, you can get a head start by downloading the source code to the program I have made that runs the book data download portion of the New Books Widget at Paul Smith’s College. This program is designed to act much like the example in this article with additional components that store the downloaded data into a MySQL database for future use. Additionally, the program is organized in such a way that allows additional repositories to be added easily.
The New Books Widget code can be downloaded from the Google Code repository at http://code.google.com/p/bookdatadownloader/.
References
[1] WorldCat Search API. <http://www.oclc.org/worldcatapi/default.htm>
[2] David Walker, Working with the WorldCat API, Code4Lib Conference 2008. <http://code4lib.org/conference/2008/walker>
[3] About The Open Library. <http://openlibrary.org/about>
[4] About Open Librarianship. <http://openlibrary.org/about/lib>
[5] John Miedema. OpenBook Book Data WordPress Plugin. <http://wordpress.org/extend/plugins/openbook-book-data/>
[6] John Miedema. OpenBook WordPress Plugin: Open Source Access to Bibliographic Data. The Code4Lib Journal, Issue 4. <http://journal.code4lib.org/articles/105>
[7] LibraryThing. Cover images repository. <http://www.librarything.com/feeds/>
[8] LibraryThing Forum. LibraryThing on iPod Touch. <http://www.librarything.com/topic/52201>
[9] Sothink JavaScript Web Scroller. <http://www.sothink.com/product/javascriptwebscroller/index.htm>
[10] Edward Vielmetti. Building a Wall of Books. HigherEdBlogCon 2006. <http://www.higheredblogcon.com/index.php/building-a-wall-of-books/>
[11] CoverPop. <http://www.coverpop.com/>
[12] GreetSaver digital signage. Ann Arbor District Library. <http://www.aadl.org/node/10631>
[13] Mark Pilgrim. Dive Into Python. <http://diveintopython.org/>.
[14] urllib — Open arbitrary resources by URL Python module. <http://docs.python.org/library/urllib.html>
[15] urllib2 — extensible library for opening URLs Python module. <http://docs.python.org/library/urllib2.html>
[16] Douglas Crockford. Introducing JSON. <http://www.json.org/>
[17] os — Miscellaneous operating system interfaces Python module. <http://docs.python.org/library/os.html>
[18] Google Books Library Project. <http://books.google.com/googlebooks/library.html>
[19] Google Book Search Partner Program. <https://books.google.com/partner/>
[20] Paul Smith’s College Library Catalog. <http://library.paulsmiths.edu/catalog/>
About the Author
Mike Beccaria is the Systems Librarian and Head of Digital Initiatives at Paul Smith’s College, a small baccalaureate institution located in the Adirondack Park in Northern New York.

{kind=link}
{kind=link}
{kind=link}
Matt Weaver, 2009-03-31
I am using a Drupal module called “Book Post”: http://drupal.org/project/bookpost in an online community for readers (just began testing). Via Book Post, an ISBN entered into a content type returns cover art and publishing info. The field is available in the Views module, allowing for the slide show on the front page.
Matt Weaver
Web Librarian
Westlake Porter Public Library (Westlake, Ohio)
Carol Bean, 2009-04-11
I am a bit confused by the initial steps of the process. In the Implementation section, it says,
“1. Each night, our ILS outputs a pipe delimited text file to a web accessible folder on the server. The file contains the title, author, and ISBN of books that are newly added to our catalog.”
But in the Process section, (Step 1: Reading the ISBN text file), it states,
“Given a text file of ISBN numbers separated by carriage returns, we can read these items into a Python list (also called an array in other programming languages).”
Where does the text file of ISBN numbers separated by *carriage returns* come from? Is there another step which converts the pipe delimited file to a carriage return delimited file, or is this conversion handled by one of the python modules?
Thanks,
Carol
Course, 2009-05-19
Could you provide me with some address that provides books
Mike Beccaria, 2009-10-16
Carol,
The script in the article is a shortened and simplified script relative to the one I am using in my production setting. I wanted to make the article as simple to read and (re)use as possible, so I tried not to make it too complicated. Modifying the script to take an input file from a specific ILS or file format shouldn’t be too hard. The principles are the same.
Josh Gachnang, 2011-10-13
One of the links at the bottom is broken. DiveIntoPython.org is permanently down. It has been mirrored at DiveIntoPython.net. Please update your link. Thanks!