By Péter Király
Introduction
Europeana [1] is a multilingual database that contains cultural heritage metadata from all European countries in many languages. The service provides different tools to help users run automatic machine translations, one of which is a new tool for query translation. The usage scenario is simple: the user sets the languages he or she wants to use in the process (up to six languages in total), then when a search expression is entered, the Europeana portal extends the query by injecting translations of the terms or phrases found in it, and runs the modified version against the search index. This paper highlights the details of this process in the hope that it can be reused in other projects.
Europeana makes use of Apache Solr for searching. Solr reads and parses the search expressions, runs a couple of transformations, analyses and filters, and creates its own internal representation. The process is highly configurable, and Solr provides tools to modify the query by injecting synonyms or by skipping stop words. Query translation is a similar modification; however, while the synonyms come from a static source (usually a file), translations come dynamically from external sources. This would normally not be a problem because Solr provides methods which enable the developer to write a custom plugin, but there is a price for that: the developer has to separate this particular part of his/her project into a different codebase because its product will be a distinct artifact – a Solr plugin. It should have its own development cycle with deployment and maintenance issues – partly-independent from the main project. This plugin should be inline with the Solr version and can become outdated if the Solr API changes.
At Europeana, we chose a different route. We made this injection code part of the main Europeana project and the system performs a query modification before the query reaches Solr. This code takes a query string and produces another query string. The string should conform to the underlying Lucene query syntax [2], which has not changed much in the past ten years and is less dependent on Solr API changes.
In order to do this, the process somewhat mimics what Solr itself does:
- Normalize the Boolean operators of the query
- Extract the terms from the query
- Call translation service on the extracted terms
- Inject the translations back into the appropriate position of the query string
Below we will discuss these steps in detail.
Boolean Normalization
Normalizing the Boolean operators of the query is the easiest step. Solr lets us set a default Boolean operator. Solr’s default operator is OR, but Europeana uses AND. This means that when the user enters Mona Lisa, Solr understands that the query has two atomic terms and it sets the Boolean AND operator between them. So the resulting query will be Mona AND Lisa. But what happens if the user enters Mona Lisa OR La Joconda? You would expect that Solr understands that it is two expressions: Mona Lisa, and La Joconda, however what Solr really understands is three expressions: the first is Mona, the second is either Lisa or La, and the third one is Joconda. Fortunately the Lucene query language allows us to use parentheses for grouping terms together forming an expression in an unambiguous way. The query (Mona Lisa) OR (La Joconda) does what the we originally expected: it finds the records either having both Mona and Lisa or both La and Joconda. The query normalization uses some text analysis to add parentheses to the user query and groups together the common parts. It does not use any Solr-related library. It is purely text manipulation based on guessing.
Extraction of Terms
Now we have a normalized query from which we have to extract terms and phrases. For instance, in dog OR cat we have two terms; in (Mona Lisa) OR (La Joconda) we have two phrases and each contains multiple terms. Solr supports a number of syntactical patterns to distinguish between query types (descendant of Lucene’s basic Query object). Some examples include:
- Spinoza – a term query (Lucene’s TermQuery object)
- Den Haag – a Boolean query (BooleanQuery) composed of two term queries, using the default boolean operator
- “Den Haag” – a phrase query (PhraseQuery)
- Spinoza* – a prefix query: terms starting with Spinoza (PrefixQuery)
- Spinoza~ – a fuzzy query: terms similar to Spinoza [3] (FuzzyQuery)
- [alpha TO beta] – a term range query: terms in lexicographical order standing between alpha and beta (TermRangeQuery)
- timestamp_created:[2013-03-15T19:58:36.43Z TO 2013-04-15T19:58:36.43Z] – a special term range query: because the type of this particular field is a date (represented in ISO 8601 format for UTC standard), the query using date comparisions. This example matches records created between 15th March and 15th April, 2013.
- *:* – matches all documents (MatchAllDocsQuery)
Any query could be a component in a bigger Boolean query. The process should take into account that we do not have to inject translations into certain types of queries. To be precise, we only need to inject them into term queries and phrase queries. Sometimes we should handle two terms as a compound phase (for example Mona Lisa or Den Haag), and we have to subject them to query translation.
The Lucene Java library provides a way to deconstruct queries into atomic components (via the QueryParser class) by extracting terms and query types, but the Query object and descendants do not give information about the position, e.g. where the term or phrase takes place in the user-entered query. Moreover, usually the extracted term has undergone some character transformations such as white space removal, making terms lower case, and truncation.
Let us imagine a fictitious query for ‘“Prince” is the prince of music’. The first Prince is a phrase query, so we do not extract it. The second prince is a term query, so we would like to get synonyms for that. Now we have translations for only one prince, but how do we inject it? We do not know which prince should be modified in the string. In the time we built a mapping of the normalized query terms and their translated versions, we already lost the information where the term occurred in the original query string.
Lucene provides tokenization as another tool for solving this problem. The same analyzer – which the process uses in creating the QueryParser – can extract the stream of tokens, which are terms in the query string with additional metadata, such as position (start and end offset). When both tokenization and query parsing end, the next process merges the two kinds of information and tries to figure out which token belongs to which query component. By the end of this process our aforementioned mapping will contain the position information as well. Thus it has now been enabled for use in injecting translations into the right position.
Calling the Translation Service
Currently, Europeana uses Wikipedia’s API to run translations via the following URL pattern:
http://[language].wikipedia.org/w/api.php?action=query&prop=langlinks&lllimit=200&format=json&titles=[query term]
There are two variables in this pattern. The first is the [language] variable which is the ISO 639-1 language code [4] and in Europeana’s case comes from the user’s settings. The second variable is the [query term], which is a title of a Wikipedia entry and comes from the term extraction. We know the user’s language preferences, but we do not know which language was used in entering the query string, so the process runs the same API call in all languages in order to be certain. It then extracts all possible language variations (so it calls en.wikipedia.org, de.wikipedia.org, nl.wikipedia.org, etc., with the same query). The API returns the response in JSON format and the software ingests it using Google’s GSON library.
An example for the returning JSON (querying for the Hungarian version of Den Haag http://hu.wikipedia.org/w/api.php?action=query&prop=langlinks&lllimit=200&format=json&titles=h%C3%A1ga):
{
...
"query": {
"normalized": [
{
"from": "hága",
"to": "Hága"
}
],
"pages": {
"123336": {
"pageid": 123336,
"ns": 0,
"title": "Hága",
"langlinks": [
...
{"lang": "de", "*": "Den Haag"},
{"lang": "en","*": "The Hague"},
...
]
}
}
}
}
The Wikipedia API does some normalization and corrects lower case issues (line 4-9). The current language’s main translation in the title property (line 14), and all other versions are available in the langlinks array (we removed the bulk of the items in the array, keeping only two language versions).
Post-Translation Positioning
Now that we have both the positions and the translations, all we have left to do is modify the query in order to inject the translations back into the appropriate position within the query string. The basic pattern looks like this:
Original query: terma AND termb
Modified query: (terma OR translationa1 OR translationa2) AND (termb OR translationb1 translationb2)
For example:
Original query: Den Haag AND Warsaw
Modified query: (“Den Haag” OR “The Hague” OR Hága) AND (Warsaw OR Varsó OR Warschau)
The injection is usually rather straightforward, but there are some cases where it is a bit complicated. For example:
- If the translations are the same for multiple languages, the second instance of the term is filtered out.
- If the term or translation is a phrase or expression, then we have to handle quotation marks correctly (Lucene QueryParser does not accept them as part of the phrase).
- Lucene handles phrases containing only one element such as place:”Paris” as a TermQuery and not a PhraseQuery, so place:”Paris” and place:Paris are equivalent.
User Interfaces
The query translation feature is available in the Europeana API and Europeana portal.
In the Europeana API the end point is http://europeana.eu/api/v2/translateQuery.json. On top of parameters common to all Europeana APIs (namely wskey and callback, see http://labs.europeana.eu/api) it accepts the following two parameters:
- term, the query string to be translated
- languageCodes, space or comma separated list of ISO 639-1 language codes denoting the language(s) of the translations
It returns the list of the translations and a well-formed query string which can be used in a Search API call.
The example:
returns
{
"apikey": "xxxxxxxx",
"action": "translateQuery.json",
"success": true,
"requestNumber": 13811,
"translations": [
{"text": "Den Haag", "languageCode": "de"},
{"text": "Warsaw", "languageCode": "de"},
{"text": "Warschau", "languageCode": "de"},
{"text": "The Hague", "languageCode": "en"},
{"text": "Warsaw", "languageCode": "en"},
{"text": "Hága", "languageCode": "hu"},
{"text": "Varsó", "languageCode": "hu"},
{"text": "Den Haag", "languageCode": "nl"},
{"text": "Warsaw", "languageCode": "nl"},
{"text": "Warschau", "languageCode": "nl"}
],
"translatedQuery": "(\"Den Haag\" OR \"The Hague\" OR \"Hága\")) OR (Warsaw OR \"Varsó\" OR \"Warschau\")"
}
The API key used in this example (line 2) is fictitious – please use your own API key. The translations key (lines 6-17) contains the list of translations, each having two properties: text is the translation and languageCode is the ISO 639-1 code of the language. The translatedQuery key (lines 18-19) contains the Solr query the API user can run in a distinct search call.
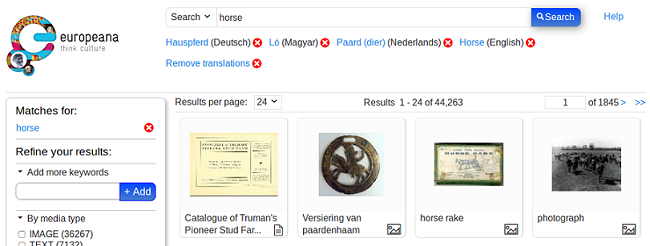
In the portal the user has to set up language preferences in order to utilize the query translation feature. It can be done in Language settings within My Europeana (available for anonymous users as well). Below the search input box the user can see the individual translations (with language information), and he or she can remove them one by one or all of them with one click. The language versions are saved in all the links of the search result page, and if the user follows a link, the portal extracts the translation from the URL instead of trying to call the translation API again.
Conclusion
This model can be followed in other projects as it is flexible enough to use a different translation service or any other service to help users enhance their query by other means than multilinguality. One can imagine a classification system, a thesaurus, or an ontology instead of a translation service – each would serve different purposes and target different user experiences.
The hardest part of implementation is term extraction. Europeana’s solution is closely coupled with the Lucene library and Java language. If another project would like to follow this approach they should find out which techniques support the parsing of the query language used by their favorite search engine. If they do not use Java but still use Solr (or any other Lucene-based search engine), Lucene query parsers are available in almost all programming languages (such as Python, PHP, C#, C++, Perl, Ruby, JavaScript).
Appendix
In this section you will find some code snippets from the Europeana’s QueryExtractor class. I removed some of the details such as parameter checking and try-catch blocks etc. to concentrate instead on the Lucene library usage. If you are interested please consult the code at Europeana’s GitHub repository. [5]
a) By initializing the QueryParser we made use of SimpleAnalyzer, and “text” as the default query field [6]:
Analyzer analyzer = new SimpleAnalyzer(); QueryParser queryParser = new QueryParser(Version.LUCENE_40, "text", analyzer); queryParser.setDefaultOperator(Operator.AND);
b) Getting the topmost Query object:
Query query = queryParser.parse(rawQueryString);
c) Iterating over the query components:
public void deconstructQuery(Query query, Stack<QueryType> queryTypeStack) {
if (query == null) {
return;
}
if (query instanceof TermQuery) {
queryTypeStack.add(QueryType.TERM);
deconstructTermQuery((TermQuery)query, queryTypeStack);
} else if (query instanceof PhraseQuery) {
group++;
queryTypeStack.add(QueryType.PHRASE);
deconstructPhraseQuery((PhraseQuery)query, queryTypeStack);
} else if (query instanceof BooleanQuery) {
group++;
queryTypeStack.add(QueryType.BOOLEAN);
deconstructBooleanQuery((BooleanQuery)query, queryTypeStack);
} else if (query instanceof PrefixQuery) {
group++;
queryTypeStack.add(QueryType.PREFIX);
deconstructPrefixQuery((PrefixQuery)query, queryTypeStack);
} else if (query instanceof FuzzyQuery) {
group++;
queryTypeStack.add(QueryType.FUZZY);
deconstructFuzzyQuery((FuzzyQuery)query, queryTypeStack);
} else if (query instanceof TermRangeQuery) {
group++;
queryTypeStack.add(QueryType.TERMRANGE);
deconstructTermRangeQuery((TermRangeQuery)query, queryTypeStack);
} else if (query instanceof MatchAllDocsQuery) {
group++;
queryTypeStack.add(QueryType.MATCHALLDOCS);
deconstructMatchAllDocsQuery((MatchAllDocsQuery)query, queryTypeStack);
} else {
log.warning("Unhandled query class: " + query.getClass());
}
if (queryTypeStack.size() > 0) {
queryTypeStack.pop();
}
}
In this method QueryType is an enumeration of the Lucene QueryTypes and denotes the name of the actual query class. The object collects them into a stack, for later usage (in some cases we have to investigate the parent query component’s type to determine what to do with the terms of the actual component). The deconstructXxxQuery() methods usually extract and save the terms. I mentioned previously that BooleanQuery connects two or more components together, so the deconstructBooleanQuery() method recursively calls this deconstructQuery() method to find those components. The role of the group variable is simple. It helps to find implicit phrases such as Den Haag without the quotes.
d) Lastly, extracting tokens from the user-entered search query.
TokenStream ts = analyzer.tokenStream("text", new StringReader(query));
OffsetAttribute offsetAttribute = ts.addAttribute(OffsetAttribute.class);
CharTermAttribute charTermAttribute = ts.addAttribute(CharTermAttribute.class);
ts.reset();
while (ts.incrementToken()) {
int start = offsetAttribute.startOffset();
int end = offsetAttribute.endOffset();
String term = charTermAttribute.toString();
String termInQuery = query.substring(start, end);
// save the above information
}
We use the same analyzer as in the first snippet. We explicitly have to ask the TokenStream object to provide information about the position (OffsetAttribute), and the term (CharTermAttribute). In line 10 we extract the original term, since the token may be in an already transformed state, which could be different than the user entered version.
Notes
[2] Apache Lucene is a Java library created for supporting indexing and searching. Solr is built on top of this library, and makes use Lucene’s query language. The Europeana query translation also depends on some functionalities of this library.
[3] The similarity between terms are measured with the edit distance: how many atomic letter changes (replacement, deletion, addition) should be done to get from terma to termb. See http://lucene.apache.org/core/4_0_0/queryparser/org/apache/lucene/queryparser/classic/package-summary.html#Fuzzy_Searches and http://en.wikipedia.org/wiki/Damerau%E2%80%93Levenshtein_distance.
[4] http://en.wikipedia.org/wiki/List_of_ISO_639-1_codes
[5] https://github.com/europeana/api2/, and https://github.com/europeana/corelib/. You can use the API’s QueryTranslationController class (https://github.com/europeana/api2/blob/master/api2-war/src/main/java/eu/europeana/api2/v2/web/controller/QueryTranslationController.java) as entry point.
[6] Text is a kind of super field in Europeana’s index. The indexing process copies almost every other field’s content into this field. When the user does not specify a field, the search runs this field again.
About the Author
Péter Király is a software developer with a humanities background (history and philology). He works at Gesellschaft für wissenschaftliche Datenverarbeitung Göttingen (Germany). His main interests are publishing and searching large textual corpora, digital libraries, digital humanities, and new possibilities of digital cultural heritage. He has participated in projects like Project Gutenberg, eXtensible Catalog and Europeana. You can reach Péter at peter.kiraly[at]gwdg.de.

Subscribe to comments: For this article | For all articles
Leave a Reply