By Bruce Godfrey and Jeremy Kenyon
Introduction
As academic and research libraries move further into building research data collections, a growing number will become familiar with geospatial metadata formats and standards. A common feature of geospatial metadata formats – as opposed to those such as Dublin Core or MODS – is the granularity of description with which they are encoded. Contact information, data distribution services and methods, and a myriad of other details all are specified at the element and attribute levels. In many cases, geospatial technology is designed to take advantage of this rich description. However, the cost of being highly granular is the requirement to keep the content of records up to date as people come and go, web services change, and even data is updated (Wayne 2005).
Over the past 15 years, INSIDE Idaho at the University of Idaho Library has amassed an extensive collection of geospatial data. As the collection has grown, maintenance and curation tasks have required us to utilize a variety of approaches to perform batch updates on large numbers of metadata records. We receive metadata authored by a variety of data creators with varying levels of expertise. These records come either through agreements with agencies to submit data periodically, are obtained from federal or private organizations, or come from university research projects. Maintaining consistency and accuracy of these metadata records across the collection presents a challenge. In most cases, there are no formal rules for cataloging in geospatial metadata, with the exception of syntactical rules, so it is not uncommon to see different variations of the same information.
Below, we describe three approaches that we have utilized to perform batch edits to large numbers of metadata records. These include a locally developed software application and techniques using both XSLT and Python. Different methods are appropriate for different skill levels of users and open up possibilities to varied ways of automating workflows. Each approach has been used successfully to update records in our repository.
Common Geospatial Metadata Formats
INSIDE Idaho supports metadata based on 1) the Content Standard for Geospatial Metadata (CSDGM), 2) ISO 191151 [1], and 3) ArcGIS Metadata Format 1.0. CSDGM dates to 1995, when the Federal Geographic Data Committee (FGDC) originally adopted it. (Executive Order 12096 1994) CSDGM has undergone significant use and growth over the past 20 years, including the development of multiple “profiles” which extend the standard to cover areas like biology and ecology. Over time, federal agencies, state and local governments, higher education institutions, and other geospatial data creators have worked industriously to document the geospatial data they create and curate, primarily using this standard. Today, the default format for most geospatial metadata is CSDGM.
In recent years, we have seen the adoption of the ISO 191** (such as ISO 19115) standards as the successor to CSDGM. These include 19110 for cataloging features, 19115-2 for cataloging remotely sensed imagery and gridded data, and 19119 for cataloging web services (against which a user would access the data). (International Standards Organization 2015) These also function as the standard international geographic metadata format. ISO standards are more complex than CSDGM and are developed with modularity and interoperability in mind. This means that a given ISO 191** series record may contain portions of each of the different standards. A map described in 19115 may refer to a 19110 record in order to describe the features represented on that map. As a result of the modularity, ISO is very powerful, particularly for supporting the use of web services or for aggregating a series of associated metadata records. (Federal Geospatial Data Committee 2011)
ArcGIS Metadata Format 1.0 has also become a major standard due to the popularity and widespread use of ESRI’s ArcGIS product suite. This format is used internally within the ArcGIS suite of products, and for many users, is the primary tool for generating standards-compliant metadata. However, for many repositories, a best practice would be to transform this format into one of the other two for long-term curation and maintenance.
A GUI Approach – the Batch Metadata Modifier (BMM) Tool
Solutions that employ a graphical user interface can be easier for some users than ones that require some form of coding or scripting. The need to avoid repetitious script development led us to create the BMM[2]. It is a .NET application, which requires Windows (our primary workstation environment). It can be used either as a standalone application or as a plug-in for ArcGIS, most recently configured for use in ArcGIS 10.2/10.3. (Godfrey et al. 2015) This tool is used most often where metadata records that have identical structures require simple updates. For many organizations, simple GUI tools can be very cost-effective and efficient.
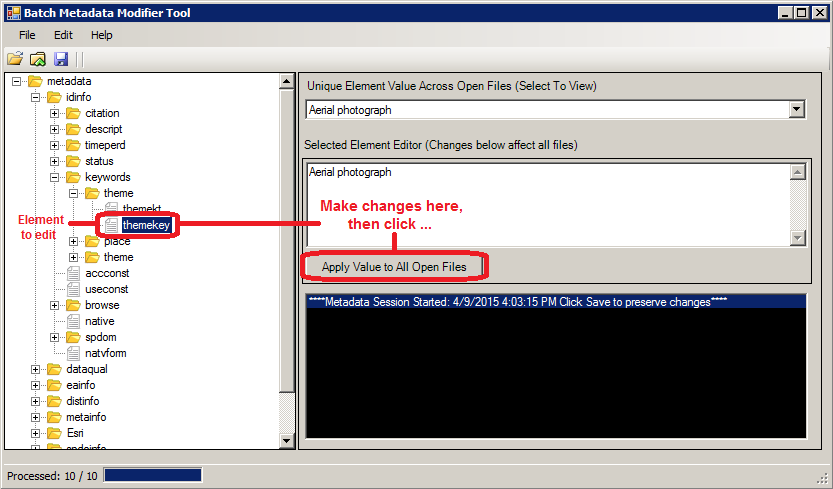
Figure 1. Screenshot from the Batch Metadata Modifier Tool. The image shows some features used to make changes to a single element across many files.
One example of using this tool is standardizing keywords across multiple records. If we needed to make all representations of a term standardized, the BMM allows you to open all records in a set, select (as in Figure 1) the specific keyword element, enter the correct value for that element, and then apply the change to all the files.
Alternatively, if you need to add missing information, you can load a template that represents the XML structure you need, and import the relevant elements – and their values – as you see fit (see Figure 2). One set of our CSDGM records (approximately 75) contained the common names of insect and plant species as keywords. We sought to also add the scientific names of the same species, in order to enhance discoverability and indexing. The BMM tool allowed us to add those terms and a reference to the thesaurus across all records. In other use cases, you can add elements required in order to validate schema or even replace elements wholesale, if they contain difficult modifications, such as altering the element attributes.

Figure 2. Screenshot from the Batch Metadata Modifier Tool. The image shows some features used to make changes to a single element across many files.
The BMM does have some limitations. First, it is only available for the Windows platform, and is for use with metadata in FGDC CSDGM, ISO 19115, and ArcGIS Format 1.0. So, if you are working in a Linux environment with Ecological Metadata Language (EML) records this is not the tool for you. Secondly, it does not have the ability to recognize conditionality or interdependency present between elements within a schema. Case in point: if you need to update the contents of a contact position element based on a specific contact person’s name you will need to use the XSLT or Python approaches described below. Lastly, it is advisable to use this tool on files that have identical metadata structures. Users need to be careful when modifying elements in multiple files that don’t have identical structures. In many use cases, the BMM’s features are very useful, but as metadata formats become more complex and semantically rich, the tool will need further development.
An XSLT Approach
Complex metadata formats, such as ISO 19115, contain elements and attributes which are dependent or conditional on other aspects of the schema. For example, one of the significant differences between CSDGM and ISO 19115 is the introduction of schema-specific codelists. Codelists add attributes that semantically modify elements. The element can be used to represent different types of work associated with a dataset by using the element, including custodian, owner, user, distributor, originator, publisher, principal investigator, and more. Figure 3 shows an example of this:
<gmd:CI_ResponsibleParty> . . . <gmd:role> <gmd:CI_RoleCode codeList="http://www.isotc211.org/2005/resources/Codelist/gmxCodelists.xml#CI_RoleCode" codeListValue="principalInvestigator">Principal Investigator</gmd:CI_RoleCode> </gmd:role> . . . </gmd:CI_ResponsibleParty>
Figure 3. Example of a codelist in use in ISO 19115-2.
This approach means that we can have multiple instances of in order to list the various parties involved in the creation, distribution, and management of a dataset, but in management of the record, we may only want to change the value of an element that relates to a specific role.
Recently, we were presented with a task where the BMM tool was insufficient without significant modification. We received hundreds of ArcGIS format 1.0 metadata records from the Bureau of Land Management (BLM), Idaho State Office which were created using ESRI’s internal metadata schema. Across the records, we found that the organization’s name was written in many different forms. Since the records were in ArcGIS format, we verified that there were multiple variations of the publisher name by examining the content of the field across all records using ESRI’s ArcCatalog software. At least three variations of the publishing organizations name existed in the records:
- Department of Interior (DOI), Bureau of Land Management (BLM), Idaho State Office
- United States Department of Interior, Bureau of Land Management
- U.S. Department of Interior (DOI), Bureau of Land Management (BLM), Idaho State Office
The source of the inconsistency was that more than one author over time had created these records and few rules were in place governing metadata creation. Our locally-developed indexing tool ran against this field, and if the names were inconsistent, it would reject any that failed to match a designated string. Normalization of the organization name was necessary for enabling indexing, discovery by users searching the catalog, and so that the inconsistencies didn’t propagate to other catalogs like data.gov. We decided that the role code of publisher needed to be normalized to:
- U.S. Department of the Interior (DOI), Bureau of Land Management (BLM), Idaho State Office
It was apparent that creating an XSLT stylesheet to handle the updates would be a preferable and workable solution. XSLT is expressly designed for manipulation of XML and is commonly used in many different domain communities. (Nogueras-Iso et al. 2004) First, we created a template in XSLT to normalize the responsible party organization name if it already existed and had the role code of publisher.
<!-- Process the metadata using the templates below --> <xsl:template match="/"> <xsl:apply-templates select="node() | @*" /> </xsl:template> <!-- Copy all metadata content --> <xsl:template match="node() | @*" priority="0"> <xsl:copy> <xsl:apply-templates select="node() | @*" /> </xsl:copy> </xsl:template>
Figure 4. Section of XSLT for creating the base template.
Next, in some records a citation existed, but the citation responsible party element (<citRespParty>) did not exist at all. We needed to generate a template to create the element and populate it with the correct responsible party organization text along with the role code value. As part of this template, we counted the number of times the BLM was somehow listed as publisher, by checking for instances in which the role code had a value of ‘010’ (meaning ‘publisher’) and if the ‘Bureau of Land Management’ text was listed in the organization name. If the value of the count was zero, we had to add the responsible party organization name and role code. Lastly, if none of those earlier cases applied, we left everything alone. The XSLT stylesheet (see Figure 5) performed the necessary edits.
<xsl:variable name="normalize_rpOrgName">U.S. Department of the Interior (DOI), Bureau of Land Management (BLM), Idaho State Office</xsl:variable>
<xsl:template match="dataIdInfo/idCitation/citRespParty[role/RoleCd[@value = '010']]/rpOrgName[contains(.,'Bureau of Land Management')]" priority="1" >
<rpOrgName>
<xsl:value-of select="$normalize_rpOrgName" />
</rpOrgName>
</xsl:template>
<xsl:template match="dataIdInfo/idCitation" priority="1">
<xsl:choose>
<xsl:when test="not(citRespParty)">
<xsl:copy>
<xsl:apply-templates select="node() | @*" />
<citRespParty>
<rpOrgName>U.S. Department of the Interior (DOI), Bureau of Land Management (BLM), Idaho State Office</rpOrgName>
<role>
<RoleCd value="010"/>
</role>
</citRespParty>
</xsl:copy>
</xsl:when>
<!-- Now, count the number of times BLM is listed as a publisher. If it is zero then we need to add it. -->
<xsl:when test="count(citRespParty[role/RoleCd[@value = '010']]/rpOrgName[contains(.,'Bureau of Land Management')]) = 0">
<xsl:copy>
<xsl:apply-templates select="node() | @*" />
<citRespParty>
<rpOrgName>U.S. Department of the Interior (DOI), Bureau of Land Management (BLM), Idaho State Office</rpOrgName>
<role>
<RoleCd value="010"/>
</role>
</citRespParty>
</xsl:copy>
</xsl:when>
Figure 5. Section of XSLT for normalizing the organization name.
XSLT allowed us to resolve an issue that the BMM tool could not. Also, XSLT is portable between many software environments. We can execute XSLT from ArcCatalog, Oxygen, Python, .NET and other environments as needed. Even though it took us a bit of time to become familiar with the syntax of this approach we feel certain that it was time well-spent and that we will take advantage of the knowledge we gained moving forward.
A Python Approach
Python offers a lot of flexibility to address geospatial metadata maintenance. An advantage to Python is the tremendous freedom a user has to incorporate not only XML document modifications, but also to make use of its other libraries to automate and process metadata in highly variable ways. We found the multiprocessing module an opportunity to run parallel processes on large numbers of files across a network, reducing the time required to make the modifications.
For example, we recently had the need to update a position description as an employee received a new job title. Nearly all of our metadata records contained the employee’s name as the primary metadata contact and needed to be changed. The BMM tool can be cumbersome to use on large numbers of files and once again the need to update one element based on the specific contents of another element was an issue. Our Python script utilizes the ElementTree module to parse the XML schema and find the relevant elements. Conditional expressions are used to check for null values and match the text and then the script will make a modification from “GIS Specialist” to “GIS Librarian” and record the number of times it made the change in a that record (Figure 6).
# Define a function to perform work
def update_metadata(metadataFile):
count = 0
try:
# parse the XML
tree = ET.parse(metadataFile)
# Find all occurrences of Contact Information (all the parents of Contact Position)
# For all the individual Contact Information elements find the Contact Person and Contact Position
# ".//" selects all sub-elements on all levels beneath Contact Information
# "/.." gets the parent element (Contact Information)
# Helpful information: http://elmpowered.skawaii.net/?p=74
parents = tree.findall(".//cntpos/..")
for parent in parents:
if parent.find("cntorgp/cntper") is not None and parent.find("cntpos") is not None:
if parent.find("cntorgp/cntper").text == "Bruce Godfrey" and parent.find(
"cntpos").text == "GIS Specialist":
parent.find("cntpos").text = "GIS Librarian"
count += 1
elif parent.find("cntperp/cntper") is not None and parent.find("cntpos") is not None:
if parent.find("cntperp/cntper").text == "Bruce Godfrey" and parent.find(
"cntpos").text == "GIS Specialist":
parent.find("cntpos").text = "GIS Librarian"
count += 1
else:
continue
result_array = metadataFile, str(count) + " elements updated"
#Update the original file if needed
if count > 0:
tree.write(metadataFile)
count = 0
except:
result_array = metadataFile, "XML was not parsed correctly"
return result_array
Figure 6. Section of Python for modifying the records.
The standard output from the script documents which files were examined and the number of times changes were made within the file, including zero. ElementTree is a very useful library for modifying XML especially since it is included with the Python install. However, other options exist such as lxml. You will need to install the lxml module but it offers additional functionality such as XPath and XSLT classes.
The advantage to using Python is not just the varied modules that can be used to deal with XML, it is also the added functionality that other Python modules introduce. We tested the script using approximately 9000 records stored on an internal (local) hard drive and found that the processing occurred in approximately 1.7 seconds without multiple processes across the CPU’s threads. When using the multiprocessing module, the same script ran in 1.6 seconds. While the difference is minor – especially with a simple activity like changing the text of a string – we noticed a decrease in time. Next, we tested the approach across 76,000 files across our network. As a single process, it took 45.5 minutes to run. As a multi-process, it took 33.2 minutes to accomplish the same task. Again, our modification in this instance was small, but larger tasks, such as running an XSLT schema transformation from within Python, would require more effort by the system, and multiprocessing could significantly reduce the time this takes.
This process is accomplished in a fairly straightforward manner. First, we set up the XML matching and modification function update_metadata within a process pool. Depending on how many CPUs you have available, the system will process each consecutive group of files simultaneously until your CPU reaches its maximum threshold. In no case did we detect any negative reactions from the CPU from this processing burden (Figure 7).
def main():
print "Start"
starttime = time.clock()
file_count = 0
# Create a list for all the files
my_list = []
# Loop through all the files (recursive)
for root, dirs, files in os.walk(path):
for filename in files:
if filename.endswith(".xml") and not filename.endswith(".aux.xml"):
metadataFile = os.path.join(root, filename)
file_count += 1
my_list.append(metadataFile)
# Create a pool class and run the jobs.
pool = multiprocessing.Pool()
result_arrays = pool.map(update_metadata, my_list)
for item in result_arrays:
print str(item) + '\n'
# Synchronize the main process with the job processes to ensure proper cleanup.
pool.close()
pool.join()
print "Finish"
stoptime = time.clock()
ttime = ((stoptime - starttime) / 60)
print str(ttime) + " minutes to process " + str(file_count) + " files"
if __name__ == "__main__":
main()
Figure 7. Section of Python for running the update function as a multiprocess.
Python presents some opportunities for establishing automated, highly efficient workflows that reduce the time necessary to make required updates to your records. In fact, beyond just metadata maintenance, using the multiprocessing module may introduce more efficient means of doing many different programmatic tasks throughout the library, including processing records for analysis and visualization.
Conclusion
The best technique for managing metadata is the one that works for the personnel who are required to perform the function for any repository environment. Those with more programming-oriented skillsets may benefit from using Python or other interpreted languages. Many metadata librarians and others who work with this information have experience in XSLT, which is itself a powerful scripting language. The BMM tool represents an approach that non-programmers can use to make changes across records, provided they have some familiarity with XML.
We have found that a toolbox approach to metadata management is the only one that affords us flexibility, creativity, and responsiveness to the metadata we receive. Just as an auto mechanic needs different tools for different tasks in repairing a vehicle, and some of those tools will be replaced by others over time, so too must geospatial metadata managers maintain a collection of different tools. Keeping that toolbox up-to-date is always a challenge, but as libraries progress further in their work with research data collections, managing metadata using different approaches will be the best way to keep up. Moving forward we will certainly be looking for tools in addition to the ones described here to help us do our jobs more effectively and efficiently.
References
Executive Order No. 12906, 3 CFR, 882 (1995). Retrieved from: http://www.archives.gov/federal-register/executive-orders/pdf/12906.pdf
Federal Geospatial Data Committee. 2011. Geospatial Metadata. [Internet] [cited 2015 Apr 10] (July) Available from: https://www.fgdc.gov/library/factsheets/documents/GeospatialMetadata-July2011.pdf
Godfrey B, Kenyon J, Kyrios A, Spinosa D. 2015. Updating your metadata just got easier. Esri ArcNews [Internet] [cited 2015 Apr 10] 18: 56-58. Available from: http://www.esri.com/esri-news/arcuser/winter-2015/updating-your-metadata-just-got-a-little-easier
International Standards Organization. 2015. Standards Catalogue: ISO/TC 211 – Geographic information/Geomatics. [Internet] [cited 2015 May 26] Available from: http://www.iso.org/iso/home/store/catalogue_tc/catalogue_tc_browse.htm?commid=54904
Nogueras-Iso, J, Zarazaga-Soria, FJ, Lacasta, J, Béjar R, Muro-Medrano, PR. 2004. Metadata standard interoperability: application in the geographic information domain. Computers, Environment, and Urban Systems [Internet]. [cited 2015 Apr 10]: 28(6): 611-634. Available from: http://dx.doi.org/10.1016/j.compenvurbsys.2003.12.004
Wayne, L. 2005. Metadata in Action: expanding the utility of geospatial metadata. GISPlanet [Internet] [cited 2015 Apr 10]: 1-6. Available from: http://gep.frec.vt.edu/pdfFiles/Metadata_PDF’s/2.2MetadataInAction.pdf
Notes
1. These standards are listed in the ISO catalogue: http://www.iso.org/iso/home/store/catalogue_tc/catalogue_tc_browse.htm?commid=54904. However, the National Oceanographic and Atmospheric Administration (NOAA) has created some training material that helps in learning more about them, including a workbook at: http://service.ncddc.noaa.gov/rdn/www/metadata-standards/documents/MD-Metadata.pdf
2. The Batch Metadata Modifier is available for download on the INSIDE Idaho website at: http://insideidaho.org/helpdocs/batch_metadata_modifier_tool.html
About the Authors
Bruce Godfrey is a GIS librarian at the University of Idaho. He previously served as its GIS Specialist from 2003-2013. He holds a M.L.S from the University of North Texas, an M.S. from the University of Idaho, and a B.A. from the University of Virginia.
Jeremy Kenyon is a Research Librarian at the University of Idaho. He has been the subject specialist supporting the College of Natural Resources since 2010. He holds an M.L.S and an M.A. from Indiana University, and a B.A. from the University of Oregon.
Appendix: Complete Code
XSLT
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="xml" version="1.0" encoding="UTF-8" indent="yes" omit-xml-declaration="no" />
<!-- Process the metadata using the templates below -->
<xsl:template match="/">
<xsl:apply-templates select="node() | @*" />
</xsl:template>
<!-- Copy all metadata content -->
<xsl:template match="node() | @*" priority="0">
<xsl:copy>
<xsl:apply-templates select="node() | @*" />
</xsl:copy>
</xsl:template>
<!-- All metadata XSLT stylesheets used to update metadata should be identical to this example up to this point -->
<!-- Add templates you'll use to update the metadata below -->
<!-- Desired result: Consistent responsible party organization name for the publisher role. There will be only one publisher -->
<!-- Begin by normalizing the Bureau of Land Management (BLM) citation publisher responsible party organization name if
it exists already.
The following 3 variations are present in the metadata:
1. Department of Interior (DOI), Bureau of Land Management (BLM), Idaho State Office
2. United States Department of Interior, Bureau of Land Management
3. U.S. Department of Interior (DOI), Bureau of Land Management (BLM), Idaho State Office
Make them all: U.S. Department of the Interior (DOI), Bureau of Land Management (BLM), Idaho State Office-->
<xsl:variable name="normalize_rpOrgName">U.S. Department of the Interior (DOI), Bureau of Land Management (BLM), Idaho State Office</xsl:variable>
<xsl:template match="dataIdInfo/idCitation/citRespParty[role/RoleCd[@value = '010']]/rpOrgName[contains(.,'Bureau of Land Management')]" priority="1" >
<rpOrgName>
<xsl:value-of select="$normalize_rpOrgName" />
</rpOrgName>
</xsl:template>
<!-- Now if dataIdInfo/idCitation/citRespParty does not exist, insert it and add BLM as the responsible party organization
name with the publisher role code (010).
We need this template if BLM has simply synchronized and hasn't added a responsible party.
We assume dataIdInfo/idCitation exists. This is a safe assumption in this case since dataIdInfo/idCitation gets created when ArcGIS
synchronizes the metadata and all of these BLM data have been viewed in ArcCatalog-->
<xsl:template match="dataIdInfo/idCitation" priority="1">
<xsl:choose>
<xsl:when test="not(citRespParty)">
<xsl:copy>
<xsl:apply-templates select="node() | @*" />
<citRespParty>
<rpOrgName>U.S. Department of the Interior (DOI), Bureau of Land Management (BLM), Idaho State Office</rpOrgName>
<role>
<RoleCd value="010"/>
</role>
</citRespParty>
</xsl:copy>
</xsl:when>
<!-- Now, count the number of times BLM is listed as a publisher. If it is zero then we need to add it. -->
<xsl:when test="count(citRespParty[role/RoleCd[@value = '010']]/rpOrgName[contains(.,'Bureau of Land Management')]) = 0">
<xsl:copy>
<xsl:apply-templates select="node() | @*" />
<citRespParty>
<rpOrgName>U.S. Department of the Interior (DOI), Bureau of Land Management (BLM), Idaho State Office</rpOrgName>
<role>
<RoleCd value="010"/>
</role>
</citRespParty>
</xsl:copy>
</xsl:when>
<!-- Otherwise, leave everything alone -->
<xsl:otherwise>
<xsl:copy>
<xsl:apply-templates select="node() | @*" />
</xsl:copy>
</xsl:otherwise>
</xsl:choose>
</xsl:template>
</xsl:stylesheet>
Python
# This script updates the position name for Bruce Godfrey from GIS
# Specialist to GIS Librarian for CSDGM records
import os
import multiprocessing
import time
import xml.etree.cElementTree as ET
# Set path to directory containing files
path = (r"C:\temp\metadatamultiprocessing\data\csdgm\authenticatedmp")
# Define a function to perform work
def update_metadata(metadataFile):
count = 0
try:
# parse the XML
tree = ET.parse(metadataFile)
# Find all occurrences of Contact Information (all the parents of Contact Position)
# For all the individual Contact Information elements find the Contact Person and Contact Position
# ".//" selects all subelements on all levels beneath Contact Information
# "/.." gets the parent element (Contact Information)
# Helpful information: http://elmpowered.skawaii.net/?p=74
parents = tree.findall(".//cntpos/..")
for parent in parents:
if parent.find("cntorgp/cntper") is not None and parent.find("cntpos") is not None:
if parent.find("cntorgp/cntper").text == "Bruce Godfrey" and parent.find(
"cntpos").text == "GIS Specialist":
parent.find("cntpos").text = "GIS Librarian"
count += 1
elif parent.find("cntperp/cntper") is not None and parent.find("cntpos") is not None:
if parent.find("cntperp/cntper").text == "Bruce Godfrey" and parent.find(
"cntpos").text == "GIS Specialist":
parent.find("cntpos").text = "GIS Librarian"
count += 1
else:
continue
result_array = metadataFile, str(count) + " elements updated"
#Update the original file if needed
if count > 0:
tree.write(metadataFile)
count = 0
except:
result_array = metadataFile, "XML was not parsed correctly"
return result_array
def main():
print "Start"
starttime = time.clock()
file_count = 0
# Create a list for all the files
my_list = []
# Loop through all the files (recursive)
for root, dirs, files in os.walk(path):
for filename in files:
if filename.endswith(".xml") and not filename.endswith(".aux.xml"):
metadataFile = os.path.join(root, filename)
file_count += 1
my_list.append(metadataFile)
# Create a pool class and run the jobs.
pool = multiprocessing.Pool()
result_arrays = pool.map(update_metadata, my_list)
for item in result_arrays:
print str(item) + '\n'
# Synchronize the main process with the job processes to ensure proper cleanup.
pool.close()
pool.join()
print "Finish"
stoptime = time.clock()
ttime = ((stoptime - starttime) / 60)
print str(ttime) + " minutes to process " + str(file_count) + " files"
if __name__ == "__main__":
main()

Subscribe to comments: For this article | For all articles
Leave a Reply