by Jason A. Clark and Scott W. H. Young
Introduction and Background
The library as place and service continues to be shaped by the legacy of the book. The book itself has evolved quickly in recent years, with various technologies vying to become the next dominant book form. Identifying an effective and popular next step for the book has been an ongoing challenge for publishers, libraries, and content creators, all of whom have focused significant resources on developing new models for creating, publishing, and accessing book content.
An overall view of this landscape is provided by the Pew Research Center, whose survey data shows that e-reading continues to rise [1], e-reading device ownership continues to rise [2], and mobile device and tablet ownership continues to rise [3]. Within this context many examples from across book publishing attest to the level of attention and resources now dedicated to developing new models for publishing. Representing the efforts of content creators are services such as Editorially, a collaborative web-based platform for both creation and publication (since acquired by Vox Media) [4]. PressBooks is a similar publication service, with the added ability to publish to various formats, including PDF, Mobi, EPUB, and a fully web-based format that PressBooks calls a “webbook” [5]. Leanpub is a self-publishing tool that the blurs the line between writer and publisher [6]. Other more grassroots efforts are seen in The People’s E-Book, a successful Kickstarter project that promises to “make e-books better ” [7], and in FuturePress, an open source HTML5 and JavaScript epub3 reader for the web [8]. Project GITenberg is a new and fast-growing collection of over 43,000 free, open, collaborative, and trackable ebooks built and distributed through the Git version control system [9].
In addition to e-book tools and services, recent conferences, library training, and specific employment opportunities have explored the publishability and accessibility of book content. The international “If Book Then” conference brings together writers, publishers, technologists, scholars, journalists, and others to imagine what happens when “we really jump away from the boundaries of the physical (and even digital) book” [10]. The New York Public Library hosted the Open Book Hack Week in December 2013, an event designed “to help us imagine the future of digital books, and advance the open source and open API building blocks needed for the diverse ecosystem of authors, designers, developers, publishers, libraries, booksellers, and readers.” The NYPL has positioned itself as a leader in developing ebooks for libraries, led by its NYPL Labs digital division (a recent NYPL Labs job advertisement for the position of Lead Systems Architect/Engineer included, “If you’re game to help re-imagine the public library eBook experience, then make that vision real (and scaleable), then we want you”) [11]. The Digital Public Library of America (DPLA) has announced a partnership with President Obama to provide children with greater access to eBooks [12], and the second annual DPLAfest conference this year included a multi-day workshop to explore the future of ebook publishing [13], This group identified a 10-part “ebook stack” to help frame discussion around possible shared services at a national network scale. The ebook stack includes reader interfaces, discovery systems, and assessment feedback mechanisms.
Wake Forest University Libraries is pursuing a related initiative with its mini-MOOC series, “ZSRx: Digital Publishing.” With this online learning program Wake Forest promises to explore the “past, present, and future perfect tenses of e-books, self-publishing, and the digital publishing landscape” [14]. Other universities are experimenting with alternative modes of open publishing, such as SUNY’s Open Textbook initiatives [15]. Questions of information access, ease-of-use, and content quality are of vital importance not only to libraries and publishers, but to the public as well.
Discussion in public forums continues to emphasize, and in some corners even agonize, over publishing and the state of the book. A recent posting on the Chronicle blog network warns of “celebrating booklessness” in libraries, as such a development will damage libraries and librarians over the long term [16]. Other analyses identify the evolution of technology and book publishing not as a sign of the end times, but simply as the driver of a new form of reading. A feature published on the website of Random House of Canada remarks, “People aren’t reading less, just differently. Technology has innovated” [17]. The feature offers a quote from artist Tan Lin: “People forget that a book or codex is a technology.”
Indeed, discussion within publishing and libraries regarding this topic too often focuses on the loss of our primary artifact, the book, while neglecting new forms of publishing enabled by today’s primary and most powerful information technology, the web. For more than two decades the web has enabled alternative forms of publishing, and now newer web technologies and publishing services have been introduced that promise even further advancement of content publishing.
Widespread support of digital publishing, however, is not a given. Criticism of book publishing in a digital environment has been recently expressed with some force by UCLA professor Johanna Drucker, who approaches digital publishing with marked apprehension in an essay titled, “Pixel Dust: Illusions of Innovation in Scholarly Publishing” [18]. Drucker maintains a strong skepticism of digital platforms as a cure for the crisis of publishing. She notes that most phases of the complex publishing cycle—acquisition, editing, reviewing, fact-checking, design, promotion, and distribution—remain in place in the digital environment, and that only the final stage—the form of production—experiences a foundational shift. In the context of the web, how viable is book publishing? How is content acquired and vetted? What is the sustainability model for production? What technologies underpin open web publishing? These questions are fundamental to our own project at the Montana State University (MSU) Library.
Responding to these questions and to the need for a new book publishing model, we at the MSU Library are exploring new possibilities for publishing through the web with open standards. We were particularly interested in the possibilities that open standards have for moving outside of DRM restrictions for book content and how open markup standards allow for broader access to book content for anyone with a web browser. We even speculated that these open standards would bring an easier archiving model to digital books as preserving and emulating text and simple images could be brought into web archiving routines and allow us to move away from the emulation and software restrictions of .pdf or ebook proprietary formats present in long-term archiving of book content. The initial “book objects” for our MSU Library prototypes represent two distinct categories of non-fiction and fiction: 1) a cookbook with essays for an MSU undergraduate history course, 2) a student literary journal featuring images, prose, and poetry created by MSU students. In the pipeline, are two additional academic press formats including: a textbook for a statistics undergraduate course, and an academic journal featuring the mountain science of the region [19]. One of our goals was to test the software across multiple textual formats and see how broadly our book model could be applied.
Our overall approach to this project is outlined within a wider framework of machine-readable, structured, semantic data (Arlitsch et al. 2014). Our project utilizes a new method for publishing within a web browser using HTML5, structured data with RDFa and Schema.org markup, linked data components using JSON-LD, and an API-driven data model [20]. These technologies together unlock the book by transforming its content into a semantic, machine-readable, and extensible platform. Drucker in fact reserves her limited praise of digital publishing for this particular aspect, “the most exciting and innovative aspects of digital presentation are the ways in which structured data—texts with humanly-embedded organization—can be searched and analyzed” [21]. We agree with this viewpoint, and have begun this work partly to demonstrate the capabilities enabled by publishing semantically structured book data within a modern web browser.
In this article, we will outline the application and benefits of RDFa, Schema.org, and linked data models for book production. We will detail the structured data model that can turn book content into API-enabled webpages. We will also analyze the effects of this web publishing practice for machine-understanding, Search Engine Optimization (SEO), and User Experience (UX). Finally, we will discuss the advantages and disadvantages of this model. This web book model can function as a demonstration of a real-world application of semantic structured data. With this project we aim to tie together three threads within the context of the evolving library: open web publishing, software development, and the book.
Structured Data
At first thought, the idea that publishing would be tied to forms of markup seems at odds with the present. Modern writing software relies on text-based WYSIWG interfaces (think of Microsoft Word or the Google Docs interface). However, early word processors required special tags to create text that was bold, paragraphed, paginated, and countless other styles. And even more recent textual markup standards such as SGML and eventually DocBook worked by requiring strict declarative markup that described a document’s structure and attributes. It is interesting to think how these previous markup structures informed the semantics of the written word. These early notions of structured data were an inspiration as we started to think about the value of structured data for the book. For our web book prototypes we chose to build with HTML5 and embedded RDFa, coupled with the web-scale controlled vocabulary of Schema.org. Our first goal was to create markup that was rich and nuanced so that it might have its own semantic value evident to any user who viewed the source code on the page. We began by building the components of the book using EPUB 3.0 HTML [22].
This allowed us to break the book into pieces and assign common divisions that you might see for book content. For example, we were able to give our book cover (index.html) some common types such as:
<main epub:type="cover" role="main" id="top"> … <section epub:type="titlepage" role="navigation" id="menu">
We followed a similar pattern for our table of contents pages (table-of-contents.html) and from there designated our item level pages (item.html) as chapter divisions.
<main data-bookmark="#" id="top" epub:type="bodymatter chapter" role="main">
With a semantic HTML5 structure in place, we next turned to the idea of annotating page content for machine-readability. RDFa and Schema.org are perfectly suited for this task of description. We gave each of the pages several Schema.org types including: CreativeWork and Article. Below are some of the above HTML tags modified to use Schema.org types.
<html lang="en" vocab="http://schema.org/" typeof="CreativeWork" xmlns:epub="http://www.idpf.org/2007/ops"> … <main data-bookmark="#" id="top" typeof="Article" epub:type="bodymatter chapter" role="main">
With these types in place, we looked to assign multiple properties that could bring a web-scale classification into place for all the pages in the book. We applied common properties like name (title), description, creator, datePublished to help provide minimum viable descriptive metadata, but we knew that we needed more detail to achieve the rich, semantic descriptions that a machine could interpret. This primary consideration led us towards introducing linked data into our annotation practice.
Using a mechanism known as External Enumerations [23], we brought an externally-maintained vocabulary into Schema.org markup. External Enumerations are a method of introducing HTML markup for descriptions of web page content using externally-maintained vocabularies and/or datasets. In this case, we wanted to apply topics from Dbpedia.org, as it is currently one of the most widely-implemented linked data vocabularies available. We hypothesized that the scale of Dbpedia’s vocabulary would result in the best return on discoverability and findability for our page content. For our linked data model, external enumerations embedded as RDFa are implemented as attributes in HTML tags. The goal is to link out to the target linked data vocabulary or entity and provide a robust, machine-readable definition of the primary topics of the page. An example of this practice is below in the Category and Context <dt> sections.
<dl> <dt>Date:</dt> <dd property="datePublished">2015-02-02T01:43:19Z</dd> <dt>Category:</dt> <dd property="genre" resource="http://dbpedia.org/page/Poetry"><a property="url" href="https://en.wikipedia.org/wiki/Poetry">Poetry</a></dd> <dt>Context:</dt> <dd property="additionalType" resource="http://dbpedia.org/page/Baucis_and_Philemon"><a property="url" href="https://en.wikipedia.org/wiki/Baucis_and_Philemon">Baucis and Philemon</a></dd> <dt>Read Time:</dt> <dd><time property="timeRequired" datetime="PT1M">< 1 minute(s)</time></dd> <dt>Page:</dt> <dd epub:type="pagebreak" class="pagination">3</dd> </dl>
The <dl> markup above is the visible scope note for the page detailing the basic metadata around any book page item. Fields like date, page number, and read time appear, but the more interesting data are under the “category” heading where we are able to map the genre and additionalType properties to a linked data vocabulary and give the page a topical, machine-readable description. With the RDFa and Schema.org embedded and nested correctly in the HTML, we then tested the page through utilities such as the RDF Translator (http://rdf-translator.appspot.com/). Diagnostic tools such as this allow us to view our page content as a machine would, formatted as JSON-LD, N-triples, or XML. We were also interested in an automated representation of our page as machine-readable linked data. To this end, we created an alternate representation of each page as JSON-LD specifically for bots, intelligent software agents, and developers that might have a preference for the reusable key-value pairs of a .json file. Initially, we included JSON-LD in the <head> of each HTML page, but we found that this practice was confusing to bots as they had to decide when to use RDFa versus JSON-LD values to understand the semantics of the page. An example JSON-LD version of one of our book pages is represented in Figure 1.
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "CreativeWork",
"@id": "http://arc.lib.montana.edu/book/opsis/",
"mainEntity": {
"@type": "Book"
"name": "Opsis: Literary Arts Journal at Montana State University (MSU)",
"description": "Opsis is the literature and arts magazine of Montana State University",
"image": "http://arc.lib.montana.edu/book/opsis/meta/img/opsis.png",
"datePublished": "2015-02-02T01:43:19Z",
"inLanguage": "en",
"genre": "Journals (Publications)",
"learningResourceType": "Student literary journal",
"creator": {
"@type": "Person",
"name": "Multiple Authors"
}
},
"Article": {
"@type": "Article",
"@id": "http://arc.lib.montana.edu/book/opsis/item/3",
"name": "Bloom",
"author": {
"@type": "Person",
"name": "Peter Hoag"
},
"image": "",
"articleBody": "%3Cp%3EBloom+was+more+than+one+color%2C+or+three.+No%2C+%3Cbr+%2F%3E%0D%0Ashe+was+a+myth+spun+from+soft+fur+and+green%3Cbr+%2F%3E%0D%0Apea+plants%2C+simple+things+that+saw+the+golden+grass+%3Cbr+%2F%3E%0D%0Aand+white+picket+fences+and+let+them+be.+%3Cbr+%2F%3E%0D%0APhilemon+and+Baucis+tried+to+guide+the+%3Cbr+%2F%3E%0D%0Achariots+from+unnecessary+heights%2C+%3Cbr+%2F%3E%0D%0Abut+they+soared+out%2C+further+than+we+could+see.+%3Cbr+%2F%3E+%0D%0AThey+became+solar+sentinels%2C+watching%2C+%3Cbr+%2F%3E%0D%0Ajust+out+of+reach%2C+waiting+for+us+to+fall.+%3Cbr+%2F%3E%0D%0AUnknown+amounts+were+lost+when+the+Fire+%3Cbr+%2F%3E%0D%0Acovered+Quiet%2C+and+Quiet+covered+the+Earth.+%3Cbr+%2F%3E%0D%0AThe+burning+Bloom+peeled+the+Harmony+off+%3Cbr+%2F%3E+%0D%0Alike+skin+and+leaped+and+danced%2C+singing+its+last+%3Cbr+%2F%3E%0D%0Asong.+Then%2C+it+disappeared%2C+its+form+intact.+%3Cbr+%2F%3E%0D%0AWe+all+stopped+and+watched%2C+our+eyes+toward+the+sky.%3C%2Fp%3E%0D%0A%3Cp%3E%0D%0AThe+world+still+remains%3B+changed%2C+not+the+same.+%3Cbr+%2F%3E%0D%0AThe+good+is+too+old+...+everything+was+gold.%3C%2Fp%3E",
"url": "http://arc.lib.montana.edu/book/opsis/item/3",
"timeRequired": "PT1M",
"datePublished": "2015-02-02T01:43:19Z",
"publisher": {
"@type": "Organization",
"name": "Montana State University (MSU)"
},
"additionalType": "http://dbpedia.org/resource/Poetry",
"additionalType": "http://dbpedia.org/resource/Baucis_and_Philemon",
"potentialAction": {
"@type": "ReadAction",
"actionStatus": "PendingActionStatus",
"target": {
"@type": "EntryPoint",
"urlTemplate": "http://arc.lib.montana.edu/book/opsis/item/3"
}
}
},
"publisher": {
"@type": "Organization",
"@id": "http://dbpedia.org/resource/Montana_State_University",
"name": "Montana State University (MSU)",
"sameAs": "http://dbpedia.org/resource/Montana_State_University"
},
"url": "http://arc.lib.montana.edu/book/opsis/"
}
</script>
Figure 1: Page of Book using Structured Linked Data (json-ld), https://arc.lib.montana.edu/book/opsis/item.json?id=3
As each page is defined with incredible granularity, we were even able to move outside of basic descriptive metadata and introduce action metadata. You can see this activity in the potentialAction assignment where a ReadAction and target are defined to show a machine what it could do with a page. Machine understanding was our goal with this activity, and as we started to apply these forms of structured and linked data to book content, we could monitor how well one of our target bots, Googlebot, was able to understand the linked metadata in our book content including primary keywords in the page text body as well as the assigned genres and topics. (Figure 2).
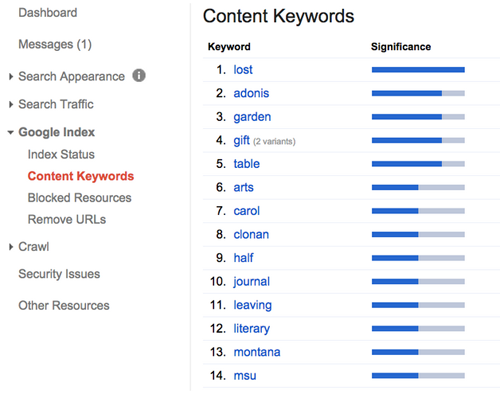
Figure 2: Basic Machine Understanding of Book Content
With this information from Google Webmaster Tools, we can start to see how our pages are understood and we can adjust our metadata practices accordingly. Terms like “lost”, “garden” and “adonis” are interpreted from our linked data assignments and our book as a discoverable entity is starting to take shape. Our next steps here will be to continue to analyze these results and bring in other machine learning tools to see how we might optimize the linked data for other purposes like automated classification.
Book-as-API
Another goal with this project involved connecting the practice of modern publishing with the process of software development. The markup practices and the work of linked data described above require a new view of library work from the perspective of web publishing. One of the key benefits of this web book project has been the recognition that digital library work is complementary to the act of publishing. In order for the networked web book to scale into broader production settings, we needed to consider how we might “atomize” the book content into a data store. Figure 3 shows how we stored the pieces of book data into data fields.
CREATE TABLE `bodymatter` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `creator` varchar(255) DEFAULT NULL, `url` varchar(255) DEFAULT NULL, `description` text, `about` text, `image` varchar(140) DEFAULT NULL, `articleBody` text COMMENT 'http://schema.org/Article', `articleSection` text COMMENT 'http://schema.org/Article', `publicationType` varchar(255) NOT NULL COMMENT 'https://schema.org/publicationType', `additionalType` varchar(255) DEFAULT NULL, `additionalType2` varchar(255) DEFAULT NULL, `isbn` varchar(40) DEFAULT NULL, `genre` varchar(140) DEFAULT NULL, `keywords` varchar(255) DEFAULT NULL, `publisher` varchar(255) DEFAULT NULL, `dateCreated` varchar(255) DEFAULT NULL, `dateModified` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, `datePublished` varchar(255) DEFAULT NULL, `version` varchar(140) DEFAULT NULL, `learningResourceType` varchar(140) DEFAULT NULL, `inLanguage` varchar(5) DEFAULT NULL, PRIMARY KEY (`id`), FULLTEXT KEY `search` (`name`,`creator`,`description`,`genre`,`keywords`,`dateCreated`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8;
Figure 3: “Atomizing” the Book to Turn it into an API
In this case, we utilized a simple MySQL table, but many other types of data stores could function in a similar way in different local environments. Schema.org was our guide here as well, with database field names mapping directly to Schema.org properties for CreativeWork and Article.
The real value in atomizing the book is in its newfound reusability, as the book in this form can be transformed into a platform and an API. The articleBody and articleSection fields above allow us to actually store the chapter or page data as text. With this fielded data in place, we can do things like count words in the articleBody field and build estimated read times for the content. More importantly, we can expose all of the fields in a REST API and make the book remixable. In addition to the JSON-LD format, each item/chapter page has an XML and JSON representation. This structured data also provides the opportunity to become clients of our own API, and in this way we have built a book search functionality using our REST API endpoint (Figure 4).
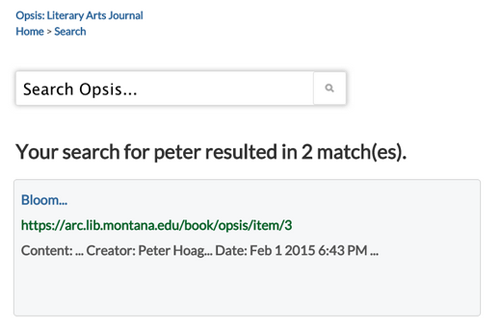
Figure 4: Search built using REST API from Book Data Model (api.html), https://arc.lib.montana.edu/book/opsis/api?v=1&type=search&q=peter&format=json
When the book becomes a platform and adapts to the open nature of the web, the remix becomes possible. New sharing and discovery opportunities become possible, and we’ll examine some of the network effects of this open model in our next section.
Machine-readability for SEO and UX
As the traditional book moves into a networked environment, new applications for SEO and UX become available. SEO is a method for enhancing the discovery of digital content on the Web (Arlitsch 2012; Killoran 2013). In the context of online publishing, the pages and words of the book become digital content on the Web, and can therefore benefit from optimization techniques that enhance discovery on major search engines such as Google. Onaifo (2013) details four SEO techniques for improving library content visibility in search engine results: website design, content, external links, and social media optimization (SMO).
SEO
Website design
This wide-ranging category considers the size and structure of a website. For our own “web book,” we have designed individual items pages to be lightweight, and have maintained a relatively small overall size for each book. In total, our Prototype 1 includes 42 pages with a median page weight of 140 kilobytes, and our Prototype 2 includes 35 pages with a median page weight of 26 kilobytes. We have also employed semantic structured data in constructing the web book, as described above. Notably this includes meta tags in the <head>, such as <link rel="canonical">, that enable machine-readability of page content. Deep-linking book content with semantic URLs and semantic markup also enhances SEO, as individual pages can be indexed by search engines and subsequently discovered by users with rich supplementary data, such as cook time for a recipe page (Figure 5). Finally, information architecture is an important aspect of SEO-effective website design. A clearly hierarchical website structure is not only human-friendly, but machine-friendly, as search engines can easily crawl and index webpages. As an example, our web book features the following hierarchical structure: title page, a table of contents, and a series of numerically-ordered item pages. This site structure is then expressed through an XML sitemap, and made available to web indexers.

Figure 5: Search Engine Results Page
Content
The primary objective for web search engines is to match relevant content to user queries (Onaifo 104). A website can design its content so that its pages are visible to users through search engines, and web analytics software can provide insight into which channels and keywords are used to discover web content (Figure 6, Figure 7).
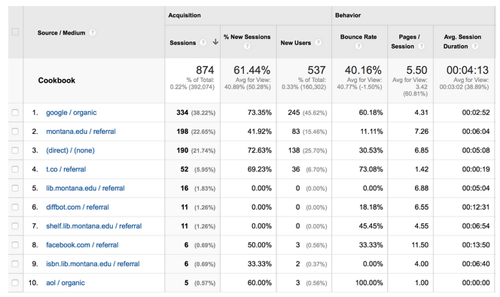
Figure 6: Traffic Sources, available through Google Analytics
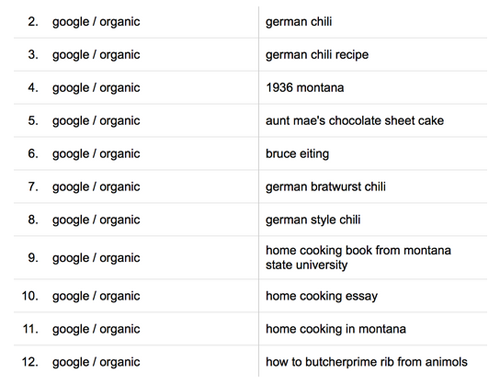
Figure 7: User-generated search queries, available through Google Analytics
With an open web book model, content can be optimized, indexed, and discovered through the web.
External Links
The number and quality of external sites linking to a website or webpage is a ranking and relevancy method used by web search engines, and there has been shown to be a statistically significant relationship between external links and user traffic for library web content (Onaifo, 96). Internal links also generate signals used by search engines, which together with external links can increase the discoverability of book content.
Social Media Optimization
Activity on social networking services (SNS) is a factor in search engine result rankings (Killoran, 62-63). Where SEO seeks to enhance the discoverability of content on the web, Social Media Optimization (SMO) is a related suite of web content optimization techniques that seeks to enhance the shareability of content through social networks. Sharing online and through SNSs creates relevancy signals that affect search engines rankings. We sought to enhance the discoverability of our web book by enhancing its shareability. SMO is defined by five principles (Killoran, 63), one of which is to make sharing easy for users by including relevant tags on webpages so that content can be richly presented on SNSs. To realize this aspect of SMO, we implemented machine-readable metatags specific to Facebook and Twitter (http://ogp.me/ & https://dev.twitter.com/cards/).
<!-- Social Media Tags --> <meta name="twitter:title" content="Bloom - Peter Hoag"> <meta name="twitter:description" content="Opsis: Literary Arts Journal at Montana State University (MSU)"> <meta name="twitter:image:src" content="https://arc.lib.montana.edu/book/opsis/meta/img/opsis.png"> <meta name="twitter:url" content="https://arc.lib.montana.edu/book/opsis/item/3"> <meta name="twitter:card" content="summary_large_image"> <meta name="twitter:site" content="@msulibrary"> <meta name="twitter:creator" content="@msulibrary"> <meta property="og:title" content="Bloom - Peter Hoag"> <meta property="og:description" content="Opsis: Literary Arts Journal at Montana State University (MSU)"> <meta property="og:image" content="https://arc.lib.montana.edu/book/opsis/meta/img/opsis.png"> <meta property="og:url" content="https://arc.lib.montana.edu/book/opsis/item/3"> <meta property="og:type" content="website" /> <meta property="og:site_name" content="Montana State University (MSU) Library"/> <!-- End Social Media Tags -->
These tags allow Facebook and Twitter bots to fetch content from our pages and display data attractively for users on their platforms (Figure 8), thereby increasing the likelihood of further sharing.

Figure 8: SMO-enhanced book content on Twitter
Web analytics can again help provide insights into the network effect of SNS sharing (Figure 9).
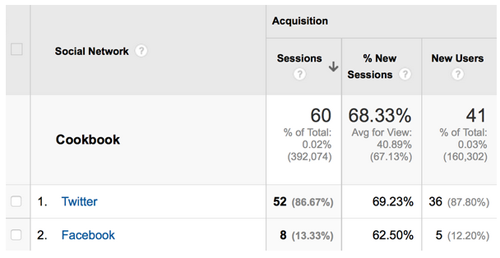
Figure 9: Social network traffic, available through Google Analytics
As the book enters a networked environment, its content can be configured for discovery and sharing. Once optimized for search and social, the book is poised for wide-spread discovery.
UX
The flexibility of the web platform allows the book reading experience to be highly configurable. User feedback mechanisms available through web analytics and other UX research methods allow online reading interfaces to be designed from a user-centered perspective. Google Analytics, for instance, offers a “User Flow” view that shows movement through the pages of a website (Fig. 10). In the same way that a website can be studied at the page level, so too can a web book be studied at the page level. With a view such as the User Flow, we can start to understand how users move through the pages of a book and which pages attract more or less attention from users. In the example shown in Fig. 10, we can evaluate the effectiveness of our Table of Contents page with respect to our goals and our users’ goals. In this case, we expect the Table of Contents to be successful in moving users through to content within the book. During the sample period shown in Fig. 10, of 287 sessions on the Table of Contents page, 96.2% moved onward through the book, and 3.8% dropped off from the web book from the Table of Contents page. This provides a strong clue that that the Table of Contents is successful in directing users to content within the book. Had these percentages been inverted, we would direct more design and development effort towards the Table of Contents page, which we could then reconfigure based on user data such as this.
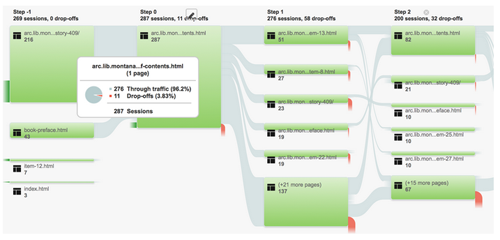
Figure 10: Google Analytics User Flow View
Further page-level analysis is offered by web analytics software such as Crazy Egg [24] that creates visual maps of user click behavior (Figure 11).

Figure 11: Visual Map of User Click Behavior, available through Crazy Egg
In this example, we can see that the gravity of clicks on the item page of our Prototype 1 are collected around the Previous button (lower left), the Next button (lower right), and our Table of Contents link (top left). This is the click behavior that we expect to see, and we can further refine our page display by increasing the size of these targets. This data view also shows us that errant clicks dot the page, perhaps indicating that users expect certain words or sentences to be linked to external entities. With this user data, we have further clues that can inform subsequent ethnographic research around the online networked reading experience.
Discussion
We have grounded our research in the concept of the evolving book—what it means for the book as a medium to be hyperlinked, marked up, atomized, and analyzed as a networked participant in the web of data. With this approach comes both advantages and disadvantages. We see advantages to the approach in breaking free from proprietary formats that bind the book to particular platforms like Amazon’s Kindle or OverDrive. More specifically, we see our application of open standards, like HTML, into book production opening up broader access for readers across platforms and building on the library goal of universal access. From an archival perspective, we see the rich markup approach to book development as a boon to preservation and long-term curation of book content as our book objects can be brought into web archiving and preservation routines free from the needs of software emulation or specialized digital archival practices. We also posit that our approach allows publishers to learn how digital library roles such as discovery and API design, data storage and archiving, metadata (structured and linked), UX and analytics, and sharing and reuse are complementary to publishing processes and offer new and valuable roles to their current publishing models. Building the book within a web browser also shifts the relationship between book consumer and book publisher, and the models for payment and copyright within this evolving dynamic are open for consideration. We also see this transformation as an advantage for both book producer and consumer. The consumer gains an enhanced flexibility in reading and reusing book content, while the publisher gains an opportunity to shift compensation models toward the initial work of book creation and away from existing cost models surrounding redistribution and editions.
In following this web book model, we have noted the development overhead that this type of markup and treatment requires. In many ways, we recognize this overhead as the primary disadvantage. As our research continues, we are focusing on how to scale production, ease the book creation onboarding process, and improve the metadata entry workflow for this time-intensive activity. We are also investigating reading interface design and the possible connections between online reading and comprehension. And finally, we are interested in how we might build more participatory models like open annotations into the book model and incorporate the assignment of behavioral and action metadata to take advantage of the network.
Our “web book” mode of publishing draws together new and existing web technologies to create a book that is accessible, discoverable, shareable, and analyzable:
- Accessible: we have built our framework using the open web standards of HTML5 CSS3, and RDFa, enabling interoperability so that content can be accessed across devices.
- Discoverable: we have leveraged the tools and practices of search engine optimization, linked open data, and the semantic web so that book content can be described using structured data markup and found with greater relevancy in leading search engines such as Google.
- Shareable: we have fully atomized book content so that granular portions of the book may be linked, shared, and reused through a networked environment.
- Analyzable: we have enabled advanced analytics for our book content so that we may better understand user behavior and expectations for a reading experience on the web.
This model represents just one prototype in a larger conversation, but it does start to outline some of the emerging options for the book, one of the primary data formats of library and information science.
Appendix
Live Project: http://arc.lib.montana.edu/book
GitHub repository: https://github.com/msulibrary/bib-template-fiction
As a point of reference, we presented our idea and model at Code4Lib 2015. You can see the presentation here: https://www.youtube.com/watch?v=gCfpQgXcpTE&t=24m1s
Notes
[1] http://pewinternet.org/Reports/2014/E-Reading-Update.aspx
[2] http://pewinternet.org/Reports/2013/Tablets-and-ereaders.aspx
[3] http://pewinternet.org/Commentary/2012/February/Pew-Internet-Mobile.aspx
[4] http://stet.editorially.com/
[5] http://pressbooks.com/
[6] https://leanpub.com/
[7] http://www.kickstarter.com/projects/1371597318/the-peoples-e-book
[8] https://github.com/futurepress/epub.js
[9] https://gitenberg.github.io/
[10] http://www.ifbookthen.com/
[11] http://www.creativeapplications.net/jobs-archive/lead-systems-architectengineer-at-the-new-york-public-library/
[12] http://dp.la/info/2015/04/30/the-digital-public-library-of-america-partners-with-president-obama-to-provide-children-with-greater-access-to-ebooks/
[13] http://dp.la/info/2015/04/29/summary-report-from-dplafest-ebook-workshop/
[14] http://events.wfu.edu/event/zsrx_digital_publishing_the_past_present_and_future_perfect_tense_of_ebooks
[15] http://textbooks.opensuny.org/
[16] http://chronicle.com/blognetwork/theubiquitouslibrarian/2014/01/06/the-harm-of-booklessness/
[17] http://www.randomhouse.ca/hazlitt/feature/internet-killed-books-save-reading
[18] http://lareviewofbooks.org/essay/pixel-dust-illusions-innovation-scholarly-publishing
[19] Funding and support for the expansion of the prototypes is provided by the Institute of Museum and Library Services (IMLS) Sparks! Ignition Grant – http://www.imls.gov/applicants/detail.aspx?GrantId=19.
[20] You can find our current “web books” at http://arc.lib.montana.edu/book/ and our code is available at https://github.com/msulibrary/bib-template-fiction and https://github.com/jasonclark/bib-template.
[21] Ibid.
[22] Full documentation for EPUB 3.0 is available at http://www.idpf.org/epub/30/spec/epub30-overview.html.
[23] http://www.w3.org/wiki/WebSchemas/ExternalEnumerations
[24] http://www.crazyegg.com/
References
Arlitsch K, OBrien P. 2012. Invisible institutional repositories. Library Hi Tech 30(1): 60–81.
Arlitsch, K, Obrien P, Clark, JA, Young, SWH, & Rossmann, D. 2014. Demonstrating Library Value at Network Scale: Leveraging the Semantic Web With New Knowledge Work. Journal of Library Administration 54(5): 413–425.
Killoran, J B. 2013. How to Use Search Engine Optimization Techniques to Increase Website Visibility. IEEE Transactions on Professional Communication 56(1): 50–66.
Onaifo, D. 2013. Increasing libraries’ content findability on the web with search engine optimization. Library Hi Tech 31(1): 87–108.
About the Author(s)
Jason A. Clark (jaclark@montana.edu) is an Associate Professor and the Head of Library Informatics & Computing at Montana State University Libraries where he builds digital library applications and sets digital content strategy. His current research interests include: linked data, search engine optimization, web services & APIs, interface design, and application development. Read more of his occasional thoughts or check out his code samples at www.jasonclark.info.
Scott W.H. Young (swyoung@montana.edu) is an Assistant Professor and Digital Initiatives Librarian at Montana State University, where he specializes in user experience research, web development, and social media community building. Read more on his website, http://scottwhyoung.com/.

Subscribe to comments: For this article | For all articles
Leave a Reply