by James Padgett and Jonathan Hooper
Background
In 2012, Innovative released a major upgrade to their long established Millennium Library Management System (LMS). The Sierra Integrated Library System (ILS) [1] comes with a feature named Sierra Database Navigator Application (SierraDNA)[2] – giving Sierra customers direct read-only access to their ILS data through a PostgreSQL database. PostgreSQL[3] is a modern object-relational database management system allowing easy access to data via the Structured Query Language (SQL)[4]. Whether directly via a PostgreSQL client such as pgAdmin[5] or as we have done, through a PHP PostgreSQL connector, custom SQL can be executed against virtually the entire gamut of ILS data. From acquisitions to circulation; reading histories to electronic resource access attempts – Library data is available to be exploited. Our own use of SierraDNA focuses on the creation of RESTful APIs based on the Tonic PHP Framework[6] and PHP scripts executed through the Cron time-based job scheduler[7]. Thus we highlight our experiences with SierraDNA through three of our favorite use cases.
SierraDNA
SierraDNA is actually a simple concept represented by two capabilities – (1) it provides a mechanism to connect a PostgreSQL client to the Sierra database to gain read-only access to the data and (2) the provision of 349 SQL views so that queries may be run safely without fear of overwriting your data. The views represent most aspects of the ILS system, from bibliographic[8] and item level data to circulation transactions to reading history. Each view is constructed from one or more tables and can be queried using SQL as if it were a table, through PostgreSQL client software. SierraDNA is not an API, or a DBMS layer – it is a direct connection to a structured set of SQL views of the Sierra ILS database.
Detecting Compromised User Accounts
Academic Libraries face the same intrusion threats as any other sector; their users vulnerable to the same phishing attacks[9]. The purpose of such attacks is to capture username / password pairs which can be subsequently used to exploit corporate IT systems. In the case of the University of Leeds, compromised accounts are commonly used to circumvent the Libraries’ proxy to gain unauthorized access to 3rd party eResources. At Leeds, the first indication the Library had of this activity was a notification the eResources Coordinator received from an eResource publisher. They highlighted, with examples, several episodes of suspicious activity originating from our proxy server. Upon examination of the Library’s proxy server Web Access Management (WAM) access logs it was clear this activity was systematic and it had been going on for some time. In a typical attack (measured over a 24 hour period) multiple IP addresses (35+), on several continents were being used to machine read content from over 60000 URLs across more than 155 publishers.
Having identified the problem, the Library turned to SierraDNA to help with a solution. The WAMREPORT view within SierraDNA records each WAM access attempt, whether successful or not, capturing the following information:
WAMREPORT ("id", "logged_gmt" "requesting_ip" "requesting_port", "requesting_iii_name", "dest_port", "dest_code", "response_category_code_num", "patron_record_metadata_id", "ptype_code_num", "pcode1", "pcode2", "pcode3_code_num", "pcode4_code_num", "rejection_reason_code_num")
This view combined with three SQL queries have been created to highlight potentially suspicious activity. The first counts the number of IP addresses used by a user within a 24 hour window. The second performs a similar task for the number of different resource providers accessed. The last counts the number of individual URL access attempts made over the same period.
The first query (Script 1) consists of an inner (line 3 – 8 inclusive) and an outer query and generates a list of users who accessed e-resources from more than 2 IP addresses in the previous 24 hours. Line 3 of the inner query selects the patron number of the user and the IP address the request originated from and joins the patron_view table – line 4 specifies the columns on which the join is performed. On line 5 we limit our search of requests to those within the last day – to standardize the query timeframe – but in theory this could be shorter if one wanted to generate reports more frequently. The group by clause on line 6 allows our script to count the connection attempts by patron number / IP pairing. On line 7 we specify that we want to list all connections attempts; ordering by patron number (line 8).
The outer query groups the results from the inner query by patron number, returning all those who connected using more than 2 IPs.
1 SELECT w.record_num, count(*) from 2 ( 3 SELECT pv.record_num,wr.requesting_ip, COUNT(*) from sierra_view.wamreport wr, sierra_view.patron_view pv 4 WHERE wr.patron_record_metadata_id = pv.id 5 AND wr.logged_gmt::date >= now()::date - 1 6 GROUP BY pv.record_num,wr.requesting_ip 7 HAVING count(*) >= 1 8 ORDER BY pv.record_num ASC 9 ) w 10 group by w.record_num 11 having count(*) > 2 12 ORDER BY count(*) DESC;
Script 1
The second query (Script 2) consists of an inner (line 3 – 8 inclusive) and an outer query and generates a list of users who accessed more than 8 eResource publishers. Line 3 of the inner query selects the patron number of the user and the publisher the request is accessing and joins the patron_view table – line 4 specifies the columns on which the join is performed. On line 5 we limit our search of requests to those within the last 24 hours – to standardize the query timeframe. The group by clause on line 6 allows our script to count the access attempts by user / publisher pairing. On line 7 we specify that we want to list all access attempts; ordering by patron number (line 8).
The outer query groups the results from the inner query by patron number, returning all those who accessed more than 8 publishers.
1 SELECT w.record_num, count(*) from 2 ( 3 SELECT pv.record_num, wr.dest_code, COUNT(*) from sierra_view.wamreport wr, sierra_view.patron_view pv 4 WHERE wr.patron_record_metadata_id = pv.id 5 AND wr.logged_gmt::date >= now()::date - 1 6 GROUP BY pv.record_num, wr.dest_code 7 HAVING count(*) >= 1 8 ORDER BY pv.record_num ASC 9 ) w 10 group by w.record_num 11 having count(*) > 8 12 ORDER BY count(*) DESC;
Script 2
The third query (Script 3) lists users who accessed more than 500 e-Resource URLs.
1 SELECT pv.record_num,COUNT(*) from sierra_view.wamreport wr, sierra_view.patron_view pv 2 WHERE wr.patron_record_metadata_id = pv.id 3 AND wr.logged_gmt::date >= now()::date - 1 4 GROUP BY pv.record_num 5 HAVING count(*) > 400 6 ORDER BY count DESC;
Script 3
Line 1 selects the patron number and a count of the number of eResource URLs accessed and joins the patron_view table – line 2 specifies the columns on which the join is performed. As in the previous two scripts we limit our search to the last 24 hours (line 3). The group by clause allows a count of URL access attempts to be made.
Each of the 3 queries produces a list of users identified by their patron number. The lists are combined into a daily report – users appearing in more than one list are highlighted for our eResource Team, who receive the report each morning.
The daily report has taught us that a typical compromised account will be represented in each list; an account being used to systematically steal eResource content will have a considerable count in the second and third scripts; an account used to machine read content will often have used a large number of IP addresses.
Since its introduction, the report has often been the first indication that a University account has been compromised. In all cases we have identified the compromised account before receiving notification from the eResource publisher. Indeed, we proactively report suspicious activity to the publishers, explaining the actions taken to prevent further theft.
People Who Borrowed…
Index based discovery systems have in recent years allowed for an explosion of searchable content (Breeding 2015). Relevancy-based retrieval is ever more important to users who want best match items on the first page. However, what if there was a different way of searching; a more serendipitous way, one in which you can stumble upon that key item you may have otherwise overlooked. SierraDNA has allowed us to offer a “People who borrowed this, also borrowed…” feature – presented as a carousel at the bottom of our record display screens on our OPAC – Figure 1. The feature relies on the collection of reading history from the circulation activity of our users. Sierra can be configured to collect reading history in a number of ways; our Library uses the opt-out setting – allowing reading history to be collected automatically unless a user opts out of the feature (an option which is available to users through their Library account). The collection of reading history data in this manner adheres to the University of Leeds code of practice on data protection [10].
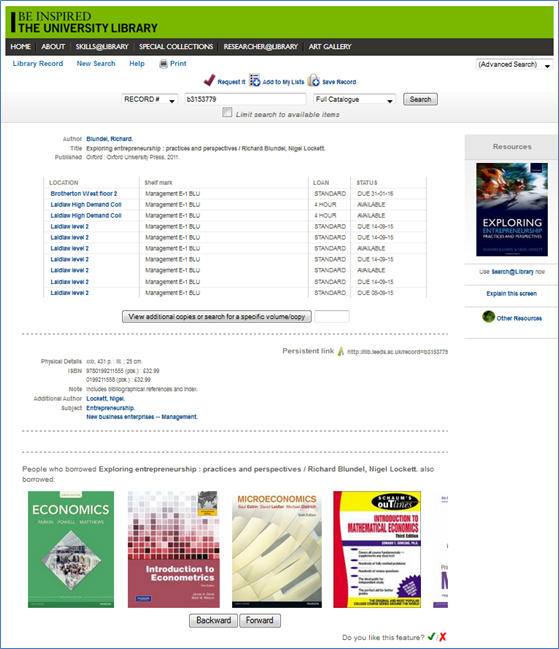
Figure 1
Reading histories are collected within the Sierra database in the reading history table – the following information is captured.
READING_HISTORY("id", "bib_record_metadata_id", "item_record_metadata_id", "patron_record_metadata_id", "checkout_gmt")
Each row has a primary key id, used to uniquely identify the loan, along with a bib_record_metadata_id identifying the bib record of the item borrowed, item_record_metadata_id identifying the actual item borrowed, patron_record_metadata_id identifying the user to which the loan was made and checkout_gmt identifying when the item was checked-out.
The first script (Script 4) generates a list of users who borrowed the item currently being viewed – in Figure 1 this is a monograph with an Entrepreneurship Library of Congress Subject Heading. On line 1 we select the distinct patron record number and join with the bib_view table – line 2 specifies the columns on which the join is performed. On line 3 we pass the bib record number of the item being viewed.
1 SELECT DISTINCT(rh.patron_record_metadata_id) FROM sierra_view.reading_history rh, sierra_view.bib_view bv 2 WHERE rh.bib_record_metadata_id = bv.id 3 AND bv.record_num = $bib_record_num;
Script 4
The second script (Script 5) consists of an inner (line 3 – 14 inclusive) and an outer query and uses the list of users obtained in the first script to generate a list of items also borrowed amongst that group of users – excluding the item currently being viewed (line 5). Line 3 of the inner query selects the bib title, ISBN, bib record number, and a count representing the number of times the item has been borrowed amongst the group of users. We use a window function to rank the ISBN number for the item – which is used in combination with line 16 from the outer query to return the highest value. Bib records may contain multiple ISBN fields and this approach guarantees we return only one. The ISBN is needed only to provide a book jacket image from Syndetics[11].
1 SELECT * FROM 2 ( 3 SELECT COUNT(bv.title) as count, bv.title, s.content as isbn, rank() OVER (PARTITION BY bv.record_num ORDER BY s.content DESC), bv.record_num as bib FROM sierra_view.bib_view bv, sierra_view.reading_history rh, sierra_view.subfield_view s 4 WHERE bv.bcode3 = '-' 5 AND bv.record_num <> $bib_id 6 AND bv.record_num = s.record_num 7 AND rh.checkout_gmt::date > now()::date - 365 8 AND rh.patron_record_metadata_id IN ($patron_ids) 9 AND rh.bib_record_metadata_id = bv.id 10 AND s.record_type_code = 'b' 11 AND s.field_type_code LIKE 'i' 12 AND s.tag = 'a' 13 GROUP BY bv.title, bv.record_num, s.content 14 ORDER BY count DESC 15 ) sub_query 16 WHERE rank = 1 17 LIMIT $limit;
Script 5
Additionally, on line 3 we join the reading_history table with the bib_view table and another table subfield_view, which contains the ISBNs associated with the bib record. Lines 6 (subfield_view) and 9 (reading_history) specify the columns on which the joins are performed.
On line 4 we place a restriction to include only bibliographic records that are available for circulation. On line 7 we limit our search of checkouts to those within the last year – mainly to improve query performance. On line 8 we pass the list of users generated by the first script as a list of comma separated patron ids. Lines 10, 11 and 12 allow us to retrieve the ISBNs of the items. Line 5 prevents the item currently being viewed from being returned. We group the results by the bib title, record number and ISBN (line 13) – since title is in essence a controlled vocabulary we can be confident this will be meaningful. We order the results of the inner query by the count representing the number of times the item has been borrowed amongst the user group (line 14). We can also limit the maximum number of returned results by passing a limit parameter to the outer query on line 17. The key part of the outer query is line 16 which limits the ISBN returned to the one ranked the highest. This technique is sufficient for our needs and appears to work well with Syndetics book jacket image API[12].
Demand driven acquisitions
Patron Driven Acquisitions are ever more popular in a world of shrinking resource budgets. Although usually driven through an initial eBook offering, our Library wanted a process which could identify which items from our physical collection were being heavily used. The original aim of Script 6 was to mimic the Purchase Alerts report in Sierra, reduce staff time needed to process the report and to allow the Resource Acquisition Team (RATS) to respond more quickly to changes in demand. Whereas Purchase Alerts is run weekly – due to the processing overhead, Script 6 is run nightly. In the long term, it is hoped the script will allow the Library to gradually reduce the size of its main collection, since it will be able to respond to changes in demand quicker and with less staff involvement.
The report generated by Script 6 lists monographs with long hold queues; in essence it is a decision support tool for the ordering process. The query looks for records with more than three bib-level holds, or with more than three item-level holds on any single attached item. It outputs: hold type (“bib” or “item”), bib record number, book title, if any item is currently available in the library, the maximum holds on any one item, the total holds on all items, the number of items attached to the bib, the date of the latest hold. An implicit measure of urgency is manifested in the sorting of the report, with those most urgent being presented at the top. An example report is presented in Figure 2 in HTML format – although a CSV version is also produced.
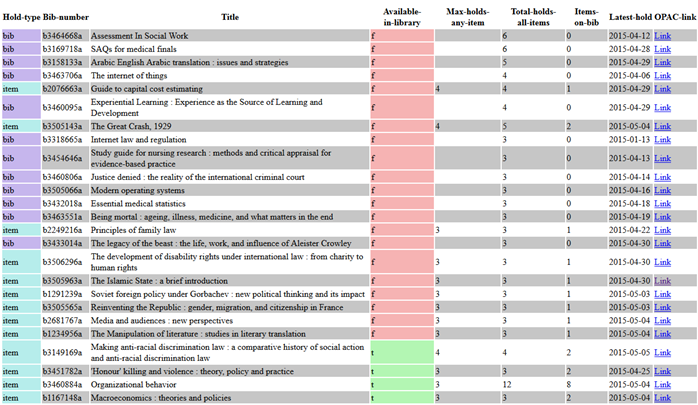
Figure 2
The script (Script 6) consists of two parts; the first (line 1 to 12) returns bib holds and the second (line 14 to 36) bibs with item holds – the two are combined with the UNION operator on line 14. The first part of the script contains an inner and outer query. The inner query of the first part of the script selects the bib id, record number, title, if the item is available, a hold count on the bib and the date of the latest hold on the item. We join the query with the hold table on line 6 and group by the bib id and record number on line 7. On line 8 we restrict to rows with an item hold count of 3 or more.
The outer script select on line 1 specifies these rows to be bib holds and carries through the bib record number, title, if the item is available, the total hold count and the date of the latest hold. It also introduces the total number of items attached to the bib, which becomes possible following the join on line 11 with the bib_record_item_record_link table – which contains details of bib / item record links. Line 2 introduces a hold queue index – which is the measure of urgency used to sort the report.

Script 6
The second part of the script starts on line 14 and consists of a series of nested sub-queries to build up the rows on line 15 of the outer query. They match identically the ones seen in the first part of the query on line 1, except they relate to bibs with item holds.
The inner bih query starts on line 21 and selects holds based on item records by joining with the bib_record_item_record_link and bib_view tables. The bh query on line 19 uses this item hold information and groups by bib id and record number and a series of aggregate functions to determine a max hold count, a total number of holds and a date for the latest hold from each of the attached items. The bhc query uses this information and groups by bib id, record number and max hold count to restrict the results to those bibs that have a max hold count of 3 or more. A join is again made with the bib_record_item_record_link table to enable a count to be made of the number of items attached to the bib. The hold queue index is calculated as an average of the max hold count and the number of holds per item. This is to ensure that the hold queue index is less sensitive to single items with a high number of holds, for example an item which may be in our high demand collection. Indeed, we recognize this as an area for improvement as currently we do not distinguish item types. The outer most query on line 15 orders the results by hold queue index and the hold date.
In combining item and bib type holds into a single report RATS can also determine if one or more of our library sites is experiencing abnormal demand. RATS can respond to demand fluctuations where they had previously been unable – allowing the Library to make more targeted use of its resource budget.
Summary
We have presented our favorite uses cases in demonstration of SierraDNA – a mechanism for read-only access to a Sierra ILS database. With considered reading of the SierraDNA documentation we have been able to demonstrate its usefulness improving services for users as well as the back-office.
It should be noted, our scripts have not been through any serious performance optimization, and we do not see this as a priority as most are run daily. Perhaps the “People who borrowed…” scripts would benefit further from such development, given they must load in real-time onto record displays within our OPAC. However, the content is loaded asynchronously using AJAX[13] and rendered at the foot of the webpage; on occasions the script takes longer to execute both features help to disguise any poor performance.
Our code is also subject to the changing structure of the Sierra ILS database. The fact queries using SierraDNA execute against a set of views, insulate our scripts from changes to the underlying database.
Although the examples presented relate to SierraDNA, we hope non-Sierra Libraries can use the principles discussed to good effect with their particular flavor of ILS.
Acknowledgements
Thanks must go to the staff of the Resource Acquisitions (RATS) and eResource teams within the University of Leeds Library. Without their help we would not have been able to gather the requirements to create the scripts in the first place. Their continued feedback and patience during development contributed considerably towards a successful outcome.
Notes
[1] Sierra. Available from: https://www.iii.com/products/sierra.
[2] SierraDNA. Available from: https://www.iii.com/news/it/InnTouchSierraDNA.pdf.
[3] PostgreSQL. Available from: http://www.postgresql.org/.
[4] SQL. Available from: https://en.wikipedia.org/wiki/SQL.
[5] pgAdmin. Available from: http://www.pgadmin.org/.
[6] Tonic – the Restful Web App PHP Micro-Framework. Available from: http://www.peej.co.uk/tonic/.
[7] Cron. Available from: https://en.wikipedia.org/wiki/Cron.
[8] MARC. Available from: http://www.loc.gov/marc/.
[9] Phishing. Available from: http://www.actionfraud.police.uk/fraud-az-phishing.
[10] Data protection – Code of Practice. Available from: http://www.leeds.ac.uk/dpa.
[11] Syndetics. Available from: http://proquest.syndetics.com/.
[12] Syndetics API. Available from: https://developers.exlibrisgroup.com/resources/voyager/code_contributions/SyndeticsStarterDocument.pdf.
[13] AJAX. Available from: http://api.jquery.com/jquery.ajax/.
References
Breeding, M. The Future of Library Resource Discovery, National Information Standards Organisation [Internet]. [cited 2015 Aug 10]. Available from: http://www.niso.org/apps/group_public/download.php/14487/future_library_resource_discovery.pdf
About the Authors
James Padgett is a Systems Librarian in the Library Systems Team at the University of Leeds, where he has been since 2009. Dr Padgett holds a PhD in Distributed and High Performance computing from the University of Leeds. He currently has a support and development role across a range of Library services including the Sierra ILS and DEDOCR, an in-house Online Course Readings management tool – which he developed.
Jonathan Hooper is also a Systems Librarian in the Library Systems Team at the University of Leeds, where he has been since 1999. His current role sees him supporting many of the Library’s back-office functions, including development against the Sierra ILS, for which he is secondary support contact. Hooper has created a number of in-house services, including a Reading List System and an Online Payments System.

Subscribe to comments: For this article | For all articles