By Janifer Gatenby, Gail Thornburg and Jay Weitz, OCLC
Introduction
A collected work can be defined as a group of individual works, selected by a common element such as author, subject, or theme, brought together for the purposes of distribution as a new work. The IFLA FRBR Review Group established a working group to review collected works, the Working Group on Aggregates. In 2011, this group produced a report (IFLA 2011) after six long years of study and thirteen years after the FRBR model [1] was first published (IFLA Study Group on the Functional Requirements for Bibliographic Records, 1998). The conclusion took the form of a proposal to enhance the FRBR model to encompass viewing a collected work in two ways: first as a new aggregate work and expression or expressions, and second as a manifestation related to the expressions and works of its various component works.
Like IFLA, the first implementations of the FRBR model in OCLC’s WorldCat shied away from collected works. WorldCat contains more than 335 million cataloguing records (OCLC 2015) for actual publications of a work, termed “manifestations” by the FRBR model. Determining the actual works represented by these records has been a decade long, continually evolving task within OCLC, recognizing that, for most users, the works are more important to the discovery experience than the bibliographic records. Thus the 335 million-odd records have been clustered into approximately 267 million work-sets (Toves 2015) and further clustered into content and manifestation clusters (called GLIMIR clusters (Gatenby 2012)). Manifestation clusters are clusters of bibliographic records that describe the same publication, such as parallel records catalogued in different languages conforming to the FRBR definition of “manifestation.” Content clusters comprise groups of manifestations that are generally equivalent from the end-user perspective (e.g., the original print text and its microform, ebook, and reprint versions, but not new editions). They approximate the FRBR “expression level” (Gatenby 2012). The work-sets are used in OCLC’s discovery and cataloguing services and are distributed as linked data for the benefit of systems world-wide handling bibliographic data (OCLC Developer Network 2015). Within the large work-sets in particular, sub-clustering is needed in order to present the sets in a manageable way, by surfacing various editions (for example different revisions and different annotations) and various translations of a work, by different translators into different languages, and clustering their various manifestations (reprints, electronic and text versions).
Until 2014, most focus was given to clustering within single works, with the understanding that collected works were more difficult but would need attention one day. It is estimated that more than 36 million bibliographic records and 11 million works in WorldCat represent collected works (Toves 2014). As electronic publications become more numerous, the ability to mix and mash will increase the numbers of collected works and probably produce new types of aggregations of increased complexity. It is important to master the nature of collected works as they currently present themselves in order to arm ourselves for their future evolution. As for the work-sets, the sub-work clustering being done on WorldCat will be of benefit to the bibliographic community as a whole.
The original GLIMIR project created programs for making clusters of records within WorldCat at the sub-work level for parallel records describing the same resource and for records that described the same content, not necessarily the same resource. Early in the project, it became clear that mixing single works and collected works in the same cluster would cause serious clustering faults. The first implementation strove to focus on clustering within single works by identifying and setting aside collected works. Gail Thornburg’s paper, “A Candid Look at Collected Works: Challenges of Clustering Aggregates in GLIMIR and FRBR” (2014), states:
The greatest problem, and most immediate need, was to stop the snowballing of clusters.
A follow on project revisited GLIMIR clustering for collected works. The results of this project and the further work it identified are the main focus of this paper. This project aimed to:
- Improve GLIMIR clusters for collected works, i.e., increase clustering by reviewing singletons (work-sets containing only one record) to see if they should or could cluster
- Reduce the size of some of the very large GLIMIR clusters — i.e., reduce over-clustering by better detecting collected works and by better detecting their content
- Improve, in particular, GLIMIR clustering of sound recording records — (because sound recordings are frequently collected works).
Work-level clustering itself was not in scope, although, like the original GLIMIR project, this project has provided information to improve work-level clustering of collected works. Also, generating links from single works to collected works (contained in) and vice versa (contains) was not in scope, though it is envisaged for a related project.
Implementation and Testing of the Algorithms
The software to identify cluster members is written in Java and runs in Linux. Records are drawn from pools and processed in batches through the same framework that handles batch loading of records to WorldCat, de-duplicating of WorldCat, and other functions. Speed of processing varies considerably according to the overall loads and other factors.
Each record processed produces a set of GLIMIR matches written as rows to an HBase table [2]. The entries to this table are processed offline nightly in a map/reduce process which synthesizes matches to produce and update clusters. Once a month, the results of the daily GLIMIR processing are integrated with the FRBR work set processing, a separate set of map/reduce processes, so that, as work ids are updated, GLIMIR clusters that cross work sets can be aligned.
For training sets, known use cases for works difficult to cluster correctly were identified by our subject experts. This included 17 sets of collected works known to over-cluster. There was one cluster included that was known not to be a collected work, thus serving as a negative test. Set sizes ranged from 50 to 336 records. By the end of the test cycles, four clusters had been removed from the training sets due to invalid data.
Five formal test cycles were set up, and all cases were tested and reviewed by several domain expert team members to identify errors. Errors were logged in our shared project environment, and expert comments were responded to by development team members. In addition, other recordings test files and regression tests were used to verify the changes, though these were not part of the formal test cycles. Questionable cases were discussed and resolved at regular team meetings. The measured goals of the project included both refinement of over-clustered cases and improvement to clustering difficult cases which had been under-clustered. Reports are now regularly generated for large GLIMIR clusters which can be evaluated as needed.
Identifying Collected Works
The first implementation of GLIMIR concentrated on clustering single works by manifestation and by equal content. Collected works, along with sparse bibliographic records, were the “danger zone”, needing identifying so that they could be isolated from the clustering process. Special processing for sparse records has been discussed in a previous article (Gatenby 2012). Collected works are isolated and separated from individual works because an undetected collected work within the work cluster of an individual work can cause the snowballing of the cluster and the blurring of the distinction of the individual works that severely hampers search and discovery. Not only do collected works and individual works need to be distinguished from each other, but it is equally important to distinguish among those identified as collected works (for instance, the same title but different content).
GLIMIR clustering and work clustering use similar routines for identifying collected works. A detailed table of GLIMIR tests has been published (Thornburg 2014). Certain material types are systematically flagged as collected, including “mix” and “kit”. [3]
Particular focus was given to sound recordings, which are known to have a high proportion of collected works. Smiraglia (2001) and Velluci (2007) note the high incidence of derivative works in music such as adaptations, amplifications, arrangements and performances. In addition, sound recordings exhibit large problems whose solution could benefit all other material types. Examples of these problems include a high number of recordings by the same performer of different works, numerous recordings of the same work by different performers, high numbers of generic titles and different arrangements. Also noted are recordings of the same work by the same performer over time, such as early and late career.
Identifying Content of Collected Works
This project then focused on the clustering of WorldCat records flagged as collected works. Records are clustered where the content is determined to be equal. Until now, collected work records were only clustered at the manifestation level where they were determined to be describing the exact same resource.
From a pragmatic viewpoint, there are collected work records where the contained works can be identified and those where the contained works cannot be identified. The latter are exemplified by generic titles in the 245 $a such as “selected works” or “collected works” without any more precise data elsewhere in the record. Beyond simple tagging these can only be ignored; they cannot enter into a content cluster unless they have matched at the manifestation level with another record. There is a case for declaring such records to be sparse records and to try to downplay them in displays, preferring other more detailed records. This is a subject for a future project.
Identifying the content of collected works differs from identifying content of individual works. An individual work may appear in different editions, different translations, different formats and different performances (e.g., talking book versus printed, or different orchestral performances). GLIMIR separates these into different content clusters. Thus there may be multiple content clusters within a work cluster. However, for collected works, the determination of content is largely at a higher level, i.e., the checking of the component works. Though the checking is currently done by the GLIMIR algorithms at the GLIMIR content level, if it is determined that one bibliographic record for a collected work has different multiple work content compared with another bibliographic record, then it should not only be a separate content cluster, but it should also be in a separate work cluster. More work is required to harmonise GLIMIR and work clustering in this area.
The works within collected works can be expressed in a record in different ways, depending on the chosen cataloguing style. It is this mixture of cataloguing styles that presents a challenge to content identification and clustering.
These are some of the cases where the content can be identified:
- The record has multiple 700s or 710s with $a (name) and $t (title) subfields
- The 505 (contents note) has multiple works separated consistently by punctuation or by subfielding
- Multiple titles can be detected in the main title field (245).
Cast list, determined by examining the participant or performer note (511), and added creator / title entries (7xx) are considered together with contents notes (505).
Further tests for differentiating contents were added that were applicable to both single and collected works, looking for conductor and orchestra. Where there is a different combination of conductor and orchestra, different content was determined.
 Figure 1: OCN 40834246 Example record with content expressed in 505 contents field
Figure 1: OCN 40834246 Example record with content expressed in 505 contents field
 Figure 2: OCN 75301540 Example record with content expressed with multiple 700 fields containing $t (and multiple titles in 245)
Figure 2: OCN 75301540 Example record with content expressed with multiple 700 fields containing $t (and multiple titles in 245)
 Figure 3: OCN 36906049 Example record with 700 indicator 2 (and 245) = analytical work
Figure 3: OCN 36906049 Example record with 700 indicator 2 (and 245) = analytical work
By examining the 505 content field, together with the 511 notes on participant or performer (cast), good clustering has been made possible as per the example in Figure 4.
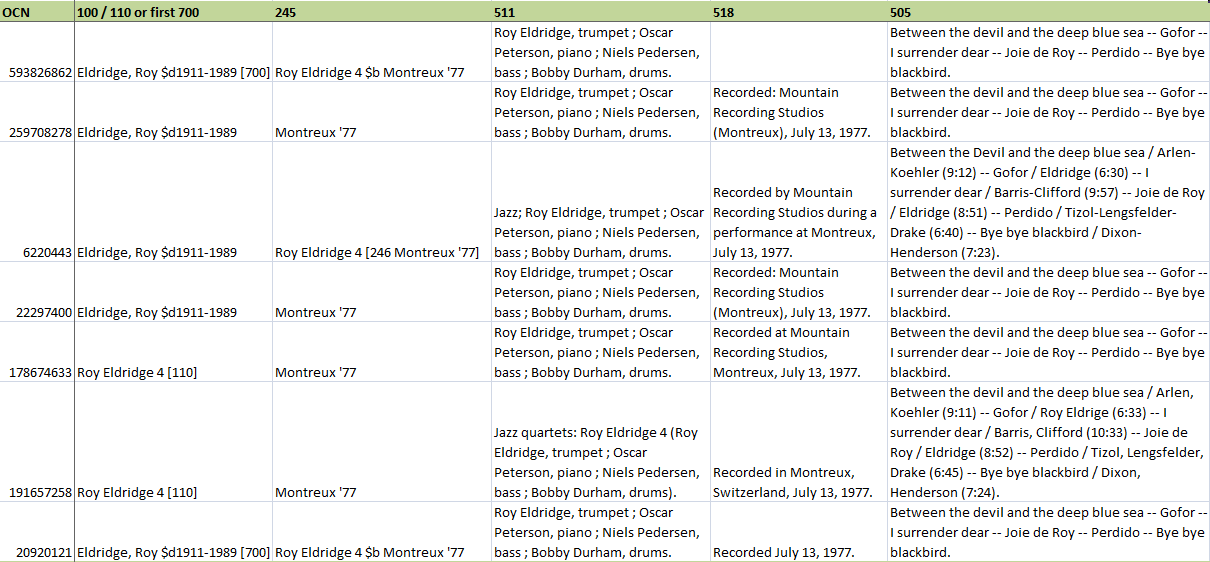 Figure 4: Spreadsheet used for testing algorithms
Figure 4: Spreadsheet used for testing algorithms
Figure 4 illustrates part of a manually crafted spreadsheet that was used for testing the algorithms as they were developed. All seven records have been identified manually as having equal content, and this has been replicated by the algorithms; all seven now have all the same content identifier applied by the algorithms. This is despite differences in all key fields — main creator, title, cast, performance notes and content notes. Some records attribute Roy Eldridge (the person) as the main contributor and others Roy Eldridge 4 (the musical group). Some contents notes have titles only, and some include performers and timing. The algorithms will also treat incomplete contents notes that end in an ellipsis.
Though the test sets used were focusing on music (Bruckner’s symphony number 9, Bernstein’s Mass, Montreux 77, 16 greatest hits), the improvements made to creator and cast checking to identify them in new fields within bibliographic records enabled improved differentiation for illustrators of juvenile works.
Further Work
As the project deadline drew closer, focus was given to ensuring that, as good clusters were made, no bad ones were made at the same time. As with any project, some already defined enhancements were sidelined for a potential future project and some new problem areas were detected.
Refining the current clustering
- Event dates, such as performance dates extracted from field 518, are currently used in duplicate detection. More use could be made of these dates in differentiating content.
- The weights given to the various tests could be further adjusted to achieve more content matches. Specifically, some cases were noted where a mismatch on material type and extent have overruled matching content and cast notes.
- Sparse records were identified for special treatment early in the first GLIMIR project and isolated so that they did not cause over-clustering and also so that they could be downplayed in search and retrieval (Gatenby 2012). This project is revealing that collected works require stricter sparse rules. Locally bound items, particularly of musical scores, were noted as a potentially problematic case for further review.
Enriched authority control
Name / title authority records are useful in work clustering. Authority records containing established facts complement clustering algorithms as they can provide the missing link between two bibliographic records, enabling them to be clustered. Salaba and Zhang (2007) claim that the main weakness of most current implementations of the FRBR model is the reliance only on bibliographic data without authority data. Ted Fons (2014) argues for extracting entities from WorldCat and creating rich authority records with as much context as possible to enable sharing as linked data to maximize their value to the Web as a whole. A work linked-data service is already offered; it is desirable to explore the possibilities for sub-work entities. A recent OCLC research project has examined the richer records in WorldCat and used them to generate more than 1 million authority records for translated works (OCLC Research 2014-2015 and Smith-Yoshimura 2014).
Thus, the richer records in WorldCat are mined to make new-style authority records that are akin to Wikipedia’s and Google’s knowledge cards, capable of informing work clustering algorithms and enabling them to better cluster all records. In a similar way, clustering at a work and sub-work level could greatly benefit from the extension of the authority record model to include records for performances and repertoire. Like translations, these can be created by mining the most complete records in WorldCat. For example there are three identified different published performances of Bernstein’s Mass. A knowledge card containing the conductor, lead performers, choirs and orchestra, and place and time, could be crafted that would permit better identification and clustering of bibliographic records of varying degrees of detail. Similarly, knowledge cards could include titles with opus or thematic index identifiers, such as Köchel identifiers, and be linked to the known recorded performances. Use of knowledge cards especially for well-known, deceased creators would greatly improve the discovery experience by providing accurate clustering within large clusters. It is ironic to produce less than optimal results knowingly for fear of over-clustering by relying solely on algorithms, where rich information is widely known and available that could supplement and complement the algorithms. Moreover, less than adequate clustering and presentation of well-known identities and their works weakens the perceived authority of the catalogue. The work sets associated with well-known identities tend to be large and difficult to cluster. Thus exploring a combined algorithm / data mining / knowledge card approach is highly desirable. Once we understand the repertoire, we are better able to identify collected works, and the ensemble of works they contain, and improve the discovery experience.
Container or work? Optimising retrieval of contained works
Is a collected work really a work, or is it just a container? To date, librarianship practice has treated all collected works as new works, or, in FRBR terms, aggregate works (Tillett 2009). However, sometimes a collected work is merely a container, as is clearly the case for locally bound items, mentioned previously, or individual works grouped together for marketing purposes. Sometimes a collection has been brought together with a critical introduction and more. Thus a continuum exists between collected works that are containers and works in their own right, and the portion in the middle is fuzzy and open to interpretation. Users probably do not distinguish between the two, and catalogue records are not consistent in their detail, making it hard to classify them solely from the data within a bibliographic record. For these reasons, it is pragmatic to treat all collected works as real works in their own right, separate from their component works. Nevertheless, it is possible to improve retrieval of individual works by also identifying them within collected works. Retrieval of individual works from within collected works is patchy. Some records, as illustrated above, do not have added entries for their components, and those that do may have a variant title form — meaning that a work within a collected work can only be retrieved by that one title string. Where the content of collected works has been identified, the work could be linked to the individual work records by explicit “contains / containedIn” links. Such links could be considered as an application of the changes to the FRBR model proposed by the IFLA Review Group Working Group on Aggregates (IFLA 2011). These explicit links can be important in finding translations of works, as publishers commonly release translations as collected works — for example, the only available Russian translations of the works of Dick Francis are in compendiums. Generating these links could be the subject of a future proposal.
Unification or synchronisation of algorithms
Another challenge is the unification or synchronisation of algorithms. Currently, for practical purposes, in OCLC’s WorldCat, the three processes of duplicate detection and resolution (DDR), manifestation and content clustering (GLIMIR), and work clustering, are separate. New and significantly modified records, whether added online or in batch load, are normally put through the DDR process after an interval of seven days to allow time for a possible reversal if required. Work clustering is neither incorporated in batch loading nor is it part of online additions; it is currently done at monthly intervals (though more frequently is envisaged) on a dedicated machine with a database copy, and then the work identifiers are copied into the production copy. GLIMIR simple clustering of books is treated similarly, and there are separate processes for the retrospective processing of GLIMIR clusters for more complex material types. Retrospective GLIMIR clustering is thorough, but slow, and batches of records for the remaining 39% of records that are lacking GLIMIR IDs are being steadily processed in nightly runs. Having three processes has meant duplication of code that is not always easy to fully align, resulting in discrepancies due not only to different code but also different processing timescales. Ideally, when new records are loaded into the database, the three processes should be integrated into one. That is: “Is this record a duplicate of an existing record? If not, is it the same manifestation as an existing record? If not, is it the same content as an existing record? If not, is it the same work?” GLIMIR clusters are used by the work algorithms to bring works together and have caused 3.6 million bibliographic records to move work-sets to date (Toves 2015). The work-set algorithms could also use the new GLIMIR collected work content clustering, where it identifies different component works of a collected work, to realign some work clusters.
Cluster presentation
As previously mentioned, optimizing clustering has been a decade-long event, and determining optimum ways to present the clustering information to end users has been just as challenging. OCLC Research has presented some prototype displays in its Work Records project (OCLC Research 2013-2015), and VIAF [4] has some new work displays to present translations of works. These displays are being evaluated for incorporation in the main displays of WorldCat.org as entities other than the bibliographical record become the focus (Fons 2014).
Conclusion
The identification of collected works was the key starting point of the project. The existing identification rules established for the first GLIMIR project were confirmed and extended, and these rules have also been adopted for work clustering. The major objective was to cluster collected works by content. For the sound recordings test sets, the project has succeeded in identifying component works within collected works and has done so without making any false clusters. By extensively analysing the cast-list (508, 511, 245 $c), performance notes (518) and contents notes (505), titles (245, 246, 7XX $t), uniform titles (240, 740) and added entries (7xx), the contents of collected works could be identified and differentiated so that correct clustering was achieved.
Retrospective clustering of approximately 4 million musical sound recordings identified as collected works is in progress as part of a drive to process all sound recordings, musical and non musical, single and collected work. Other sets of records affected by the enhancements of this project are also being identified and will be scheduled for re-processing.
The project has inspired ideas for further significant development. Refining the existing algorithms is desirable but more impact will come from incorporating rich authority records and knowledge cards into the clustering process in conjunction with the effort to mine new entities from the database. These new entities will lead to new ways of displaying the data and new ways of sharing with the bibliographic community world wide, particularly as linked data.
Acknowledgments
This paper has greatly benefitted from the input, and patient and meticulous review from Jenny Toves and Stephan Schindehette. Richard Greene contributed significantly to the project with his considerable musical and metadata expertise. Tribute is also due to the team as a whole: Robert Bremer, Tony Chirakos, Bert Cousins, Janifer Gatenby, Richard Greene, Marianne Kozsely, Glenn Patton, Russ Pollock, Bob Schulz, Gail Thornburg and Jay Weitz. OCLC Quality Control provided invaluable input and review throughout the successive test cycles.
References
Fons, Theodore (2014). Authorities, Entities and Communities: Paper delivered at IFLA 2014, Lyon.
Available from: http://library.ifla.org/1034/1/086-fons-en.pdf (viewed 2015-03-11)
Gatenby, Janifer, Greene, Richard O., Oskins, W. Michael and Thornburg, Gail (2012) GLIMIR: Manifestation and content clustering within WorldCat. Code{4}lib journal issue 17, 2012-06-01. Available from: http://journal.code4lib.org/articles/6812 (viewed 2015-03-10)
IFLA. FRBR Review Group. Working Group on Aggregates (2011). Final report
Available from: http://www.ifla.org/files/assets/cataloguing/frbrrg/AggregatesFinalReport.pdf (viewed 2015-03-16)
IFLA Study Group on the Functional Requirements for Bibliographic Records (1998). Functional Requirements for Bibliographic Records: Final Report. — München: K.G. Saur, 1998. — (UBCIM publications; new series, vol. 19). — ISBN 3-598-11382-X [viewed 2015-03-24]. Available from: http://www.ifla.org/en/publications/functional-requirements-for-bibliographic-records
OCLC (2014) WorldCat Works linked data: Connecting library resource into the core of the web
Available from: http://www.oclc.org/en-europe/publications/nextspace/articles/issue23/worldcatworkslinkeddataconnectinglibraryresourcesintothecoreoftheweb.html (viewed 2015-03-12)
OCLC (2015) WorldCat statistics: 2015-02-15. Available from: http://www.oclc.org/en-europe/publications/nextspace/articles/issue24/worldcatstatistics.html (viewed 2015-03-12)
OCLC Developer Network (2015) OCLC Linked data. Available from: http://www.oclc.org/developer/develop/linked-data.en.html (viewed 2015-03-12)
OCLC Research project (2014-2015): Multilingual Bibliographic structure. http://www.oclc.org/research/themes/data-science/multilingual-bib-structure.html?urlm=168909 (viewed 2015-03-09)
OCLC Research project (2013-2015) Work records in WorldCat. http://www.oclc.org/research/themes/data-science/workrecs.html (viewed 2015-03-31)
Salaba, Athena and Zhang, Yin (2007) From a conceptual model to application and system development: Functional requirements for Bibliographic Records. American Society for Information Science and Technology. August/September 2007. Available from: http://www.asis.org/Bulletin/Aug-07/Salaba_Zhang.pdf (viewed 2015-03-24)
Smiraglia, Richard P. (2001). The Nature of “A Work”; Implications for the Organization of Knowledge. Lanham, Maryland, Scarecrow Press, 2001.
Smith-Yoshimura, Karen (2014) Challenges posed by translations. Hanging Together May 20th 2014.
Available from: http://hangingtogether.org/?p=3878 (viewed 2015-03-12)
Thornburg, Gail, and Oskins, W. Michael (2012). Matching Music: Clustering Versus Distinguishing Records in a Large Database. OCLC Systems and Services, v. 28, issue 1
Available from: http://dx.doi.org/10.1108/10650751211197059 (viewed 2015-03-10)
Thornburg, Gail (2014): A candid look at collected works: challenges of clustering aggregates in GLIMIR and FRBR. Information technology and libraries vol 33, no.3 September 2014
Available from http://ejournals.bc.edu/ojs/index.php/ital/article/view/5377 (viewed 2015-03-10)
Tillett, Barbara (2009) Definition of Aggregates and Works: Tillett Proposal [to the IFLA FRBR Working Group on Aggregates IFLA Conference 12 August 2009]
Available from http://www.ifla.org/files/assets/cataloguing/frbrrg/aggregates-as-works.pdf (viewed 2015-03-11)
Toves, Jenny (2014) email correspondence 2014-08-14 and 2014-04-21
Toves, Jenny (2015) email correspondence 2015-03-10
Vellucci, Sherry L. (2007). “FRBR and Music”. in Understanding FRBR: What It Is and How It Will Affect our Retrieval Tools, Ed. Arlene G. Taylor (Westport, CF: Libraries Unlimited, 2007), 131-151.
Notes
[1] The FRBR model comprises four main entities: a work, an expression, a manifestation and an item. To illustrate: Emile Zola wrote Germinal (work) that was translated into English by Roger Pearson (expression) and published by Penguin in 2004 (manifestation) and a particular copy can be found on this library’s shelves (item).
[2] HBase is a column-oriented database management system that runs on top of HDFS. It is well-suited for sparse data sets, which are common in many big data use cases. Unlike relational database systems, HBase does not support a structured query language like SQL; in fact, HBase isn’t a relational data store at all. HBase applications are written in Java much like a typical MapReduce application. HBase does support writing applications in Avro, REST, and Thrift.
http://www-01.ibm.com/software/data/infosphere/hadoop/hbase/ (viewed 2015-09-08)
[3] Material type is a classification of format computed for each bibliographic record in WorldCat based on selected values in the Leader, 006, 007, 008, 33X, and occasionally other fields. It indicates certain aspects of content, medium, and carrier. Tests are made for uniform titles indicating collected works by coding and by a list of generic titles such as “selections” and “oeuvres completes”. A check is made for multiple paginations. Similarly added entry creator / title fields (7xx series) coded as analytic or in multiple occurrences are indicators. The title proper (245), if it contains the word “selection” or multiple occurrences of semicolons, is an indicator, as is also the occurrence of multiple 740 fields with second indicator 2 and the varying title field (246) in some circumstances. The most recent refinements involved checking contents notes (field 505). Punctuation (forward slash, hyphen and semicolon) and multiple occurrences of “movement” or a statement of responsibility subfield or title subfield are used as evidence of a collected work.
[4] http://viaf.org (viewed 2015-03-31) See for example: http://viaf.org/viaf/196911378/ Anatole France’s Les dieux ont soif.
About the authors
Janifer Gatenby works on metadata projects at the offices of OCLC BV in Leiden, Netherlands. Her main project for the last 5 years has been the development and maintenance of the ISNI database and system. She has been at OCLC since 2000, working on data-related projects including the multi-lingual bibliographic structure project, the GLIMIR project and standards related to system interoperability. She has contributed significantly to the development of international standards since 1993 including SRU, openURL Request Transfer Message, ISO Holdings, ISO data elements, SRU update, Library registry (ISO 2146), ISNI, ISCI and Z30.50 among others.
Gail Thornburg, Ph.D., has taught at the University of Maryland and elsewhere, and is now a senior-level developer and researcher at OCLC, and author of numerous papers. In recent years her work has focused on expert software algorithms for matching and clustering data in very large datasets. She has been recipient of an OCLC President’s Award in 2010, and recipient of Emerald Publishing Outstanding Paper Award in 2013.
Jay Weitz is a Senior Consulting Database Specialist at OCLC and was previously Assistant Catalog Librarian at Capital University, Columbus, Ohio. He has a BA in English from the University of Pennsylvania, an MLS from Rutgers University, and an MA in Education from Ohio State University. He is the author of Cataloger’s Judgment, both editions of Music Coding and Tagging, and the cataloging Q&A columns of the Music OCLC Users Group Newsletter and the Online Audiovisual Catalogers Newsletter. He serves as OCLC Liaison to numerous groups. Since 1992, he has presented dozens of cataloging workshops in the U.S., Canada and Japan. He was the recipient of the MOUG Distinguished Service Award in 2004, OLAC’s Nancy B. Olson Award in 2005, and for his work on the reimplementation of Duplicate Detection and Resolution software in WorldCat, an OCLC President’s Award in 2010. Since 1981, he has been program annotator for concerts of Chamber Music Columbus (Ohio, USA). He has been a performing arts critic in public radio, in print and on the Web, and currently serves as theatre and dance writer for the weekly alternative newspaper “Columbus Alive” (http://www.columbusalive.com).

Subscribe to comments: For this article | For all articles
Leave a Reply