by Gregory Wiedeman
The acquisition of born-digital records for institutional archives is nothing new. Over the past five to ten years a consensus has developed within the profession that the best practice for the long-term preservation of digital records is the use of forensic disk imaging to preserve the records’ original bitstreams in their original context. Yet, despite the recent growth and success of these techniques, disk imaging may provide some problems for institutional archives that may be subject to records retention schedules and public records laws. This article examines a different and more challenging approach to managing permanent digital records in institutional archives: the use of digital forensics tools in records’ original creation environment to preserve contextual metadata at accession, and the preservation of records at the file layer. Forensic tools have developed to a point where they can be employed as part of an automated workflow – limiting practical usability barriers. Even gathering a small portion of valuable contextual metadata in the form of filesystem timestamps has the potential to make records more usable and discoverable.
The key to employing digital forensics at accession is developing a user-friendly transfer application that runs basic forensic tools in records’ native environments prior to transfer. At the University at Albany, SUNY, we are developing ANTS – a basic desktop application that will enable records creators to transfer born-digital records to an institutional archive over shared network drives or File Transfer Protocol (FTP). Written in Python and limited to NTFS filesystems, this experimental tool contains a basic GUI that allows records creators to describe the accession – either as a whole or by adding descriptions or access concerns to individual directories and files. ANTS then attempts to run MFTRCRD, Plaso, and Python’s os.stat functions to gather as many record-events as possible before packaging records with BagIt and transferring them to the archives. ANTS should serve as a useful proof of concept and a tool for future experimentation.
Evolution of Digital Forensics in Archive
Digital records first became widely discussed by archivists in the 1990s, and the challenges of these new formats appeared formidable. Some of the first major questions concerned the stability of records in volatile digital environments where they could be easily altered or manipulated. In order to grapple with the complexity and volatility of digital records, archivists turned to the field of Diplomatics to help identify the general requirements to manage digital records – namely the establishment and maintenance of their authenticity, reliability, and integrity. [1] Still, modern computers were not designed for the permanent maintenance of electronic records and the technical challenge of preserving this information was still daunting.
The application of forensic disk imaging to archives gained widespread traction after 2010. Matthew G. Kirschenbaum, Richard Ovenden, and Gabriela Redwine made the case that the work of digital forensic practitioners overlapped with archivists’ requirements for managing digital records. Digital Forensics methodologies, they offered, can provide a way to stabilize digital information and preserve it in a state that includes the contextual information necessary for demonstrating records’ authenticity. [2] Soon after, Kam Woods and Christopher A. Lee began an effort to directly apply digital forensics tools to archival workflows – work that evolved into the BitCurator Project. They emphasized how, “Disk images that contain complete operating systems capture significant information about the ‘digital ecosystem’ in which documents and media were created.” [3] The BitCurator Project itself has developed effective and accessible forensics tools for archivists – enabling them to use, and see value from, disk imaging. [4] Generally, the stated focus of these efforts has been on “cultural heritage collections” and “collecting institutions” generally, but how does digital forensics apply to institutional archives?
In conjunction with the developing digital archives theory and the evolution of forensics tools, over the past five years there have been a number of practically-focused publications on managing born-digital archives. [5] These case studies and best practices have correctly prioritized getting file contents onto stable media, establishing intellectual control, and providing access. The available literature seems to show that many institutional repositories are accepting digital records as files rather than disk images. Only more recently have practical case studies been published that showcase the preservation of contextual metadata outside of files. [6] Part of this is likely due to lag time in the publishing process, but it might just be that some archivists are still making an educated decision to preserve digital records as files. This could be because the technical barriers to disk imaging are still too high for some repositories, or perhaps some repositories are finding that disk imaging—despite its applicability to digital archives as a whole—is not a perfect fit for many types of materials.
Institutional Archives and Public Records
While disk imaging offers the easiest way to ensure that digital materials are authentic and complete, the consensus on disk imaging for digital records also poses a few major challenges for institutional archives:
- Imaging all of the physical disks which hold institutional records can be very impractical.
- Disk imaging retains additional information that should have been disposed of in accordance with a traditional records retention schedule.
- Archives managing records that are subject to public records laws may not be able to limit or restrict access to information that was unwittingly preserved in disk images.
Even with these concerns, institutional archivists should not easily abandon digital forensics or even disk imaging. Recordkeeping practices are always changing and archivists may be able to update their records management strategies to meet these new realities. [7] Organizations could also adopt an enterprise document or records management system to manage the entire records process from creation to final disposition. Still, these methods may not help archivists who are legally obligated to make all information obtained from disk imaging available for public use.
The University at Albany, SUNY is a good example of where a large disk imaging program is unworkable for an institutional archives. First, we manage the permanent records of a large public university with over 17,000 students and more than 3,400 employees on three campuses. Since the University Archives has only one full-time professional staff member, imaging innumerous hard disks and managing the data footprint that would be created is more than impractical without a large organization-wide commitment driven from the university administration.
Secondly, as a public university, we are subject to New York State’s FOIL law which mandates that all records must be made available to the public, with only minor exceptions. [8] Copying all the bits from a disk inevitably retains additional information outside of what was selected to be retained, and—by law—we are not able to enforce access policies to restrict the availability of deleted files, data found in slack space, or other records unwittingly transferred. Outside of select cases, the risk of keeping all the bits is simply too great.
Managing Records as Files
Without disk imaging, we must manage records using the same abstractions used by operating systems: files, stored on filesystems, which likely contain the primary content of records. Documenting the authenticity and integrity of the file itself is easy with the use of cryptographic hashes, commonly called checksums. This ensures the preservation of content as well as whatever contextual metadata that is included within the file. We can handle file format identification, extract embedded metadata like EXIF data, and document file size after records are transferred to the archives if we rely on checksums.
So what are we missing if we preserve only files? Computers also maintain a variety of other information on how a record was created, used, and maintained outside of a file, providing valuable context. As the BitCurator project reported, “Extraction of basic technical metadata (such as timestamps) from file systems can provide a foundation on which one can establish a ‘ground-truth’ for content and structure on a device. They can provide significant support for assessment and preservation activities.” [9] Additionally, dates have traditionally supported description in archives and worked to make records more accessible.
The most useful and pragmatic approach is to gather as many forensic artifacts that can be attached to records as possible. These “record-events” would be any point of activity relating to a record that can be gathered from the original computing environment, including timestamps found in a filesystem, as well as actions entered into an event log or journal. These events could signify record creation, alteration, or use, and helps to contextualize the record itself. To gather this information, we need to take action in records’ native environment, which means we need to run forensics tools on each individual’s desktop before records are transferred to the archives. By combining an effective transfer application with basic forensic tools, we can make it easier for creators to transfer records while establishing a consistent submission package that includes at least some contextual metadata in addition to the files themselves.
Building a Transfer Tool
At the University at Albany, SUNY, we are building a basic GUI desktop application that can be run on a records creators’ computer that will easily perform these tasks while transferring records to servers accessible to the University Archives. ANTS, for Archives Network Transfer System, is written in Python and uses wxPython, a cross-platform GUI wrapper that allows us to easily use and manipulate wxWidgets in Python. Application data is stored and managed in XML using the lxml library, and the program is frozen as an executable using PyInstaller, so it should run on any modern computer without any external dependencies. [10] While the technology used to develop ANTS is not very fast nor resource-efficient, the application manages and stores only a small amount of data and only performs a few simple tasks. These tools also make ANTS very open and easy to develop, and since it runs on the desktop, efficiency and scalability are much smaller concerns.
While it might not be the most popular GUI framework, wxPython is mature, easy to use, and is open and well-documented. The code below places a text label, a one-line text box where users can enter a Path, and a button which simply checks if that path is a valid location.
This is a simplified example of some of the code in the ANTS options panel and serves to show how easy desktop development can be.
#sizer that positions widgets gridSizer = wx.FlexGridSizer( 4, 3, 0, 0 ) gridSizer.SetFlexibleDirection( wx.BOTH ) gridSizer.SetNonFlexibleGrowMode( wx.FLEX_GROWMODE_SPECIFIED ) #label for TextCtrl self.tranferLabel = wx.StaticText( self.transferTab, wx.ID_ANY, u"Transfer Location (PATH or FTP URL)", wx.DefaultPosition, wx.DefaultSize, 0 ) self.tranferLabel.Wrap( -1 ) gridSizer.Add( self.tranferLabel, 0, wx.ALL, 5 ) #TextCtrl where user enters transfer path self.transferLocInput = wx.TextCtrl( self.transferTab, wx.ID_ANY, configData["transferLocation"], wx.DefaultPosition, wx.Size( 300,-1 ), 0 ) gridSizer.Add( self.transferLocInput, 0, wx.ALL, 5 ) #button to test if transfer path is valid self.checkLocation = wx.Button( self.transferTab, wx.ID_ANY, u"Test Transfer Location", wx.DefaultPosition, wx.DefaultSize, 0 ) gridSizer.Add( self.checkLocation, 0, wx.ALL, 5 ) #binds button to function self.checkLocation.Bind( wx.EVT_BUTTON, self.testTransferLocation ) #function to test path on button click def testTransferLocation(self, event): #gets content of TextCtrl location = self.transferLocInput.GetValue() #check to see if TextCtrl contains value if not len(location) > 0: #shows popup dialog noLoc = wx.MessageDialog(None, 'You must enter a local or network path.', 'Location Test Error', wx.OK | wx.ICON_ERROR) noLoc.ShowModal() else: #example of testing a path if os.path.isdir(location): #shows popup dialog goodDir = wx.MessageDialog(None, 'The directory you entered is correct.', 'Found Directory', wx.OK | wx.ICON_INFORMATION) goodDir.ShowModal() else: #shows popup dialog badDir = wx.MessageDialog(None, 'Invalid location, did not find the directory you entered.', 'Incorrect Directory', wx.OK | wx.ICON_EXCLAMATION) badDir.ShowModal()
Complex positioning using sizers can be unintuitive, but wxFormBuilder is an open-source application that can easily position widgets with a GUI and export the code. There are some limitations to wxFormBuilder, as it does not allow you to directly bind functions to widgets, but the code is easy to modify after it is exported.
 Figure 1. ANTS splash page
Figure 1. ANTS splash page
When users run ANTS, they are shown an entry window that looks like a splash screen. This asks them to browse and select a folder to transfer while letting them directly access ANTS’s other functions. Using an entry window like this is not ideal, but in this case the user needs a “Browse” button, otherwise dropping them directly into a directory select dialog is disorienting. Functionally, ANTS performs three primary tasks. Most importantly, it allows users to select, describe, package, and transfer directories and files. ANTS also maintains a running receipt of transferred files that will let users easily request files they transferred in the past. Clicking this button creates a Bootstrap HTML report with links that lets donors email the archivist with a specific file identifier, accession number, and transfer information. For UAlbany, this is configured to send email requests directly into our ticket system. Finally, ANTS allows users to view and download files through the same method they transferred them. [11]
When users click browse, ANTS asks to elevate the User Account Control (UAC) privileges that will help it run forensics tools later. Windows does not easily allow programs to elevate privileges within a single process, so after the elevation request ANTS actually runs a separate executable, antsFromBoot.exe, which contains the major portion of the tool, and can test for elevated privileges. This enables ANTS to run different tools depending on the privileges that it has been granted.
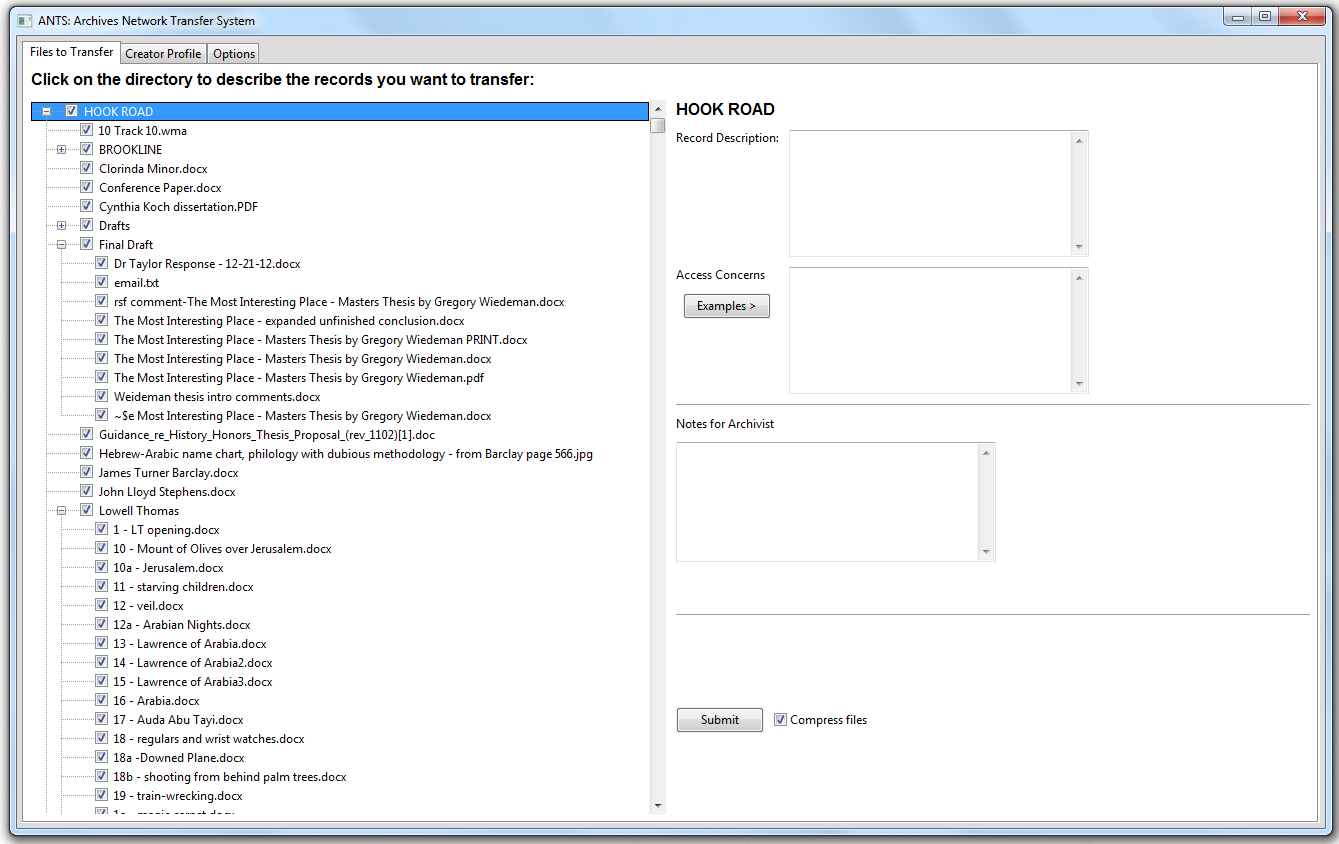 Figure 2. ANTS file browsing
Figure 2. ANTS file browsing
After users browse and select a directory, the main panel opens with an expanded directory tree that displays every file and folder. Checkboxes let users select which files and folders to transfer, and which they would like to omit. This encourages records creators to select files in their native environment without unnecessarily transferring them to avoid neighboring files.
The most difficult part of the GUI development was that wxPython’s default TreeCtrl widget does not contain checkboxes. Instead, ANTS uses a CustomTreeCtrl widget which is part of an extension library written by Andrea Gavana. The issue with this extension is that the checkbox rules that automatically toggle parents and children did not work as stated in the documentation. The solution was to write the directory information into an XML file at the same time the widget is displayed. Each file or folder is bound to an event that enters checkbox information into the XML file and reloads the widget. The rules for checking parents and children had to be written manually. Although tedious to develop, this works rather well and allows ANTS to add the description and access information to the XML file during the same event, but may cause scalability issues for transfers with hundreds of subdirectories and/or thousands of files.
The right side of the panel invites users to add descriptions and access concerns at any level of the directory. While it is unlikely that users will describe their files manually, ANTS does provide this functionality. Archivists might ask donors to provide a little information about files that may not be effectively named, and in a few cases they could provide some useful information. The bottom-right of the panel is a Submit button and an option to compress the data before transferring. Once ANTS is configured, users can transfer records simply by selecting a directory and clicking “Submit.”
Additional notebook tabs enable users to configure ANTS through the GUI. The “Creator Profile” tab sets the donor metadata that will be included with the packaged files. This includes the creator, a creator ID, the donor and the donor’s contact information such as an email address that will let archivists notify donors of a successful transfer. The “Options” tab contains the transfer and receive locations, credentials for FTP transfers, and timestamp, compression, and checksum options. Here users can also export the receipt data in Bootstrap HTML, CSV, or XML. All of this information is stored in the user’s AppData directory in a config.xml file. ANTS is also designed to be configured remotely, so that archivists can send a customized config.xml file that can be installed with the application.
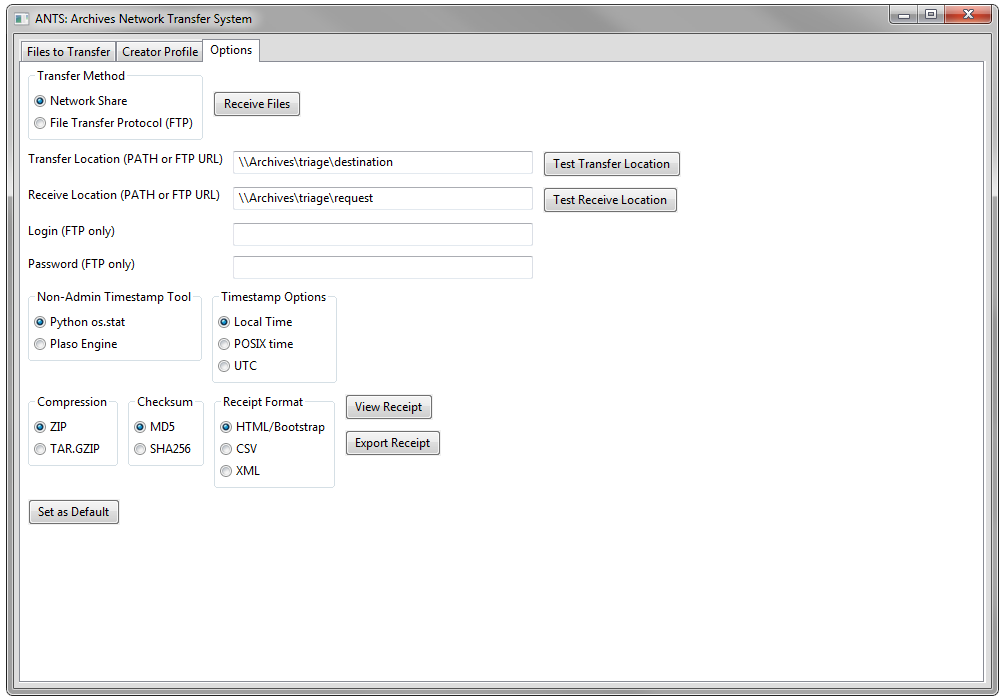 Figure 3. ANTS options tab
Figure 3. ANTS options tab
When ANTS is set up using the installer that is provided, there is an option to place a shortcut to ANTS in the Windows context menu – the “right-click” menu. This allows records creators to simply right click any file or folder in Windows Explorer, omit the splash screen, and transfer records in two clicks.
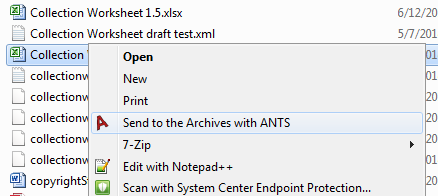 Figure 4. ANTS context menu
Figure 4. ANTS context menu
Packaging Files with Digital Forensic Tools
A number of free and open-source forensic tools have emerged in recent years and most of them are distributed with permissible licenses. This permits us to use python’s subprocess library to run these tools from within ANTS and parse their output. Right now, there are two tools that we can utilize to perform digital forensics at accession: Joakim Schicht’s MFTRCRD and the Plaso timeline engine developed by Kristinn Gudjonsson and Joachim Metz. There is also hope that these and other tools will continue to evolve where they can further support archivists and gather more record-events at accession.
Forensics tools are designed for digital forensics investigations not archives. In most cases, tools choose to extract large bodies of contextual metadata from disk images, not—as we require—to gather metadata on individual files. This means that most forensic tools available today often take too long to gather record-events for individual files. A second problem is that we need records creators to run these programs on their own computers, so they need to be able to access live filesystems instead of disk images. This is possible on modern Windows operating systems, by accessing a disk as a device rather than through the filesystem. To do this we just need to use the device namespace in the command line with the \\.\ prefix. So the C drive would be accessed as \\.\c: instead of c:\. [12] We can use this prefix as part of a command wrapped in a Python application using the subprocess module. The only problem with this is that Windows requires elevated privileges to access disks as devices, privileges that many records creators may not have. This is the reason why ANTS requests elevated privileges before browsing for a directory, though even privileged users will not have privileges for shared network drives, likely leaving us with only a portion of our records creators that can use this method. With these restrictions in mind, ANTS must be able to run different tools based on the privileges it has been granted.
The most common open-source forensic tools currently used by archivists is The Sleuth Kit (TSK), written by Brian Carrier. TSK is a set of over 20 command line tools used to analyze disk images. TSK can access live systems, but only with administrator privileges. TSK metadata layer tools (i- prefix) at first seem to be particularly useful to us. ifind.exe produces the Master File Table identifier for a file and istat.exe displays that Master File Table (MFT) Record. The MFT is where most filesystem metadata is found in NTFS systems, and contains a file’s MAC times or MACE times—for modified, accessed, and created—these primary timestamps are called the $STANDARD_INFORMATION attribute on NTFS systems. In addition to the primary $STANDARD_INFORMATION timestamps, the MFT record also contains at least one other additional set of MAC times, the $FILE_NAME attribute, that are typically hidden from the common user and are not as volatile. According to Corey Altheide and Harlam Carvey, the $FILE_NAME timestamps, “…are not affected by normal system activity or malicious tampering…” and are generally more stable than the $STANDARD_INFORMATION MAC times. [13] Brian Carrier goes even further to claim that the $FILE_NAME timestamps, “…frequently correspond to when the file was created, moved, or renamed.” [14] In addition, the $FILE_NAME attribute also identifies its parent directory, and that directory will also have a set of MAC timestamps for its child files. If nothing else, these different sets of timestamps can support or complicate the standard MAC times, and together they can help future archivists and researchers better understand how records were used.
TSK’s ifind.exe’s speed was a concern for this project. In basic, unscientific tests, ifind.exe took about 13 seconds per file to obtain the MFT identification number. Running as a subprocess within a python script, looping through 25 files took about 334 seconds, or just over five and a half minutes. For comparison’s sake, using BagIt to run MD5 checksums on those files—taking up a fairly small 178 megabytes—takes less than a third of a second. Users will not expect ANTS to take over five minutes to package this small number of files, and that time does not include transferring that data. Fundamentally, TSK’s ifind takes too long to identify MFT identifiers for individual files, so we sought a better option.
At first glance, Joakim Schicht’s Mft2Csv tool appeared to meet our needs, but instead we encountered similar issues – namely that forensic tools are often focused on the disk level. As the name states, Mft2Csv decodes the MFT of a NTFS disk image or live filesystem to a CSV file. Users have a wealth of options and may employ Mft2Csv with a GUI or via the command line. The problem with this tool is that we would have to dump a disk’s entire MFT to a CSV or SQL file before parsing it for individual records. This is the same for similar tools such as pyMFTGrabber, analyzeMFT.py, and INDXParse. While this method would not be difficult to write, for large disks it would take up additional resources and time while records creators are making the transfer.
Schicht has developed another tool that better fits our needs. MFTRCRD can extract an individual file’s MFT entry from a live system by providing both that file’s path and the device namespace method discussed previously. Using the same methods we used to test TSK tools, MFTRCRD ran at about 0.7-0.8 seconds per file to total just over 19 seconds to loop though the entire directory of 25 files.
Starting MFTRCRD by Joakim Schicht Version 1.0.0.37 Target is a File Filesystem on C: is NTFS File IndexNumber: 418561 BytesPerSector: 512 SectorsPerCluster: 8 ReservedSectors: 0 SectorsPerTrack: 63 NumberOfHeads: 255 HiddenSectors: 206848 TotalSectors: 976564223 LogicalClusterNumberforthefileMFT: 786432 LogicalClusterNumberforthefileMFTMirr: 16 MFT Record Size: 1024 Record number: 418561 found at disk offset: 0x0000001BC8E89400 $LogFile sequence number (LSN): 13711955478 ... $STANDARD_INFORMATION 1: File Create Time (CTime): 2015-10-20 13:40:47:010:6144 File Modified Time (ATime): 2015-10-20 13:57:12:762:9689 MFT Entry modified Time (MTime): 2015-10-20 13:57:12:762:9689 File Last Access Time (RTime): 2015-10-20 13:40:47:027:6178 DOS File Permissions: archive Max Versions: 0 Version Number: 0 Class ID: 0 Owner ID: 0 Security ID: 2866 Quota Charged: 0 USN: 3219407008 $FILE_NAME 1: Parent MFTReference: 397315 ParentSequenceNo: 7 File Create Time (CTime): 2015-10-20 13:40:47:010:6144 File Modified Time (ATime): 2015-10-20 13:40:47:027:6178 MFT Entry modified Time (MTime): 2015-10-20 13:40:47:027:6178 File Last Access Time (RTime): 2015-10-20 13:40:47:027:6178 AllocSize: 0 RealSize: 0 EaSize: 0 Flags: archive NameLength: 8 NameType: DOS+WIN32 NameSpace: 3 FileName: test2.py
Condensed example of MFTRCRD’s output
The output includes some filesystem information such as the type of the filesystem and the sizes and number of sectors and clusters. More importantly, it includes the four primary $STANDARD_INFORMATION timestamps and the four additional $FILE_NAME timestamps. Also included is the file’s $LogFile sequence number and the Update Sequence Number (USN) journal number – both of which may be useful in the future to gather record-events from files that have been more recently accessed. While this output is unstructured text, it was fairly easy to run it as a subprocess like the example below, parse it with Python, and add the timestamps to ANTS’s XML directory file.
readMFT = subprocess.Popen("MFTRCRD.exe " + path + "-d indxdump=off 1024 -s",\ shell=False, stdin=subprocess.PIPE, stderr=subprocess.PIPE, stdout=subprocess.PIPE)
out, err = readMFT.communicate()
Using the MFTRCRD tool is currently the most effective method to gather contextual metadata at accession, but the Plaso timeline engine may be a more intriguing tool for the future. Unlike MFTRCRD, it can be run without the elevated privileges that many records creators may not have. Here the Plaso engine may offer a helpful backup plan by enabling us to gather at least the primary MAC timestamps.
Plaso is different than the forensic tools discussed previously as it is more user-focused – designed more for ease of use and at-a-glance information. Forensics tools need to be effective and comprehensive, yet Plaso is not designed to gather all forensic artifacts, but to gather the most readily available evidence of activities and display them in a useful and intuitive timeline. Plaso has evolved from a single Perl tool, called log2timeline, to an “engine” that amalgamates a number of useful forensic processes to produce “super timelines.” This is particularly intriguing for archivists who would benefit from using a number of smaller and more obscure tools and producing a simple and standardized output format. Plaso’s functionality matches the needs of institutional archivists by gathering a variety of record-events from different sources in a simple and user-friendly manner.
However, for archivists Plaso offers more hope for future gains than current productivity. It does not access live disks as devices, so the only way it can run on live systems is to read a directory and gather the $STANDARD_INFORMATION MAC times that are available. While it still gathers artifacts from sources other than the filesystem, in practice this means that in rare cases it may be able to gather record-events embedded within a file itself – most often with Microsoft’s Office Open XML files (.docx, xlsx, etc.). Additionally, Plaso does take a significant amount of time to run through a directory at just over 23 seconds for 25 files. This is not much more than MFTRCRD, yet since it is run with a single process it was a challenge showing progress to the user. Running Plaso, ANTS’s progress bar dialog freezes for that 23 seconds, giving users the appearance that ANTS itself is frozen. It is possible, although challenging, to show progress as Plaso updates the console, but Plaso does not provide feedback to the console during most of its run, so updates to the progress bar dialog would likely be intermittent at best.
For uses without elevated privileges, ANTS can employ both Plaso and Python’s os.stat library. Unlike Plaso, os.stat runs nearly instantaneously and can show progress for each file. It gathers the basic $STANDARD_INFORMATION MAC times that are available to the operating system. This makes it a realistic minimum for performing digital forensics at accession. Plaso is still included with ANTS as a proof of concept and a tool for future experimentation. It runs effectively, yet for now there seems to be little tangible benefit to using Plaso over os.stat.
Transferring Records to the Archives
After employing basic forensic tools to read filesystem metadata, ANTS runs the python version of Bagit to package files with checksums. An unexpected problem was that using the existing Bagit tool required ANTS to move and hash the files twice – a redundant and time-consuming step for large transfers. In order to prevent the unwitting modification of the original files, ANTS makes a copy of the entire transfer directory after running the forensics tools. ANTS then runs Bagit, which again moves the directory to a “data” folder according to the Bagit standard. ANTS later adds an XML metadata file to the bag, which requires updating the manifest to make it valid again – running checksums on the data for a second time. This redundancy could be eliminated by creating the Bagit package before transferring the files and running the checksums, but creating an empty bag raises an error. Fixing this issue would require reworking the Python Bagit tool or building the bag framework from scratch, and the latter option will probably be implemented in future versions.
Another improvement that may be made in the future is the use of Robocopy. Currently, ANTS uses Python’s native shutil library to move files, which is significantly slower than native Windows utilities. ANTS could instead run Robocopy as a subprocess, which would greatly improve performance, but in practice, this caused similar issues as running Plaso. Robocopy provides a large amount of feedback in unstructured text though both the console and a log file. This would have to be parsed to show progress to the user and raise an exception if the process failed.
After the records are packaged, ANTS creates an XML directory of the folder and file hierarchy that includes identifiers, paths, and any descriptions and access concerns that were entered by the user. Here ANTS adds all of the record-events it was able to gather from the files, and logs all of the actions it took on the files as curatorial events. If a user opted to compress the accession, ANTS then compresses the directory either in zip or gzip formats.
ANTS does not use major metadata standards for its output. After initial plans to incorporate PREMIS or METS, we found that the information provided by ANTS was different enough that mapping to these standards would be very imprecise and serve only to add unnecessary complexity. The XML provided by ANTS also lacks namespaces or a stated schema. Namespaces can be difficult to deal with in lxml, and since ANTS creates standardized XML, a schema seemed unnecessary. Archivists are welcome to map the data provided by ANTS to their favorite standards upon receipt, and omitting namespaces and schemas makes this easier to do. Here is an excerpt from ANTS’s output that depicts a single file:
<file name="dutchesscountyre00cook.pdf">
<id>418f3945-d66d-494a-a352-146ba45e0053</id>
<path>F:\Libraries\Documents\DCHS\dutchesscountyre00cook.pdf</path>
<description>Listing from promotional event.</description>
<access/>
<curatorialEvents>
<event timestamp="2015-12-19 15:17:16">ran MFTRCRD to gather NTFS timestamps</event>
<event timestamp="2015-12-19 15:17:20">ran Bagit-python to package accession</event>
<event timestamp="2015-12-19 15:17:20">ftp transfer</event>
</curatorialEvents>
<recordEvents>
<timestamp source="NTFS" timeType="local+4:00" parser="MFTRCRD" type="STANDARD_INFORMATION" label="File_Create_Time">2015-11-07 17:54:09</timestamp>
<timestamp source="NTFS" timeType="local+4:00" parser="MFTRCRD" type="STANDARD_INFORMATION" label="File_Modified_Time">2013-07-13 11:50:48</timestamp>
<timestamp source="NTFS" timeType="local+4:00" parser="MFTRCRD" type="STANDARD_INFORMATION" label="MFT_Entry_modified_Time">2015-11-07 17:54:10</timestamp>
<timestamp source="NTFS" timeType="local+4:00" parser="MFTRCRD" type="STANDARD_INFORMATION" label="File_Last_Access_Time">2015-11-07 17:54:09</timestamp>
<timestamp source="NTFS" timeType="local+4:00" parser="MFTRCRD" type="FILE_NAME" label="File_Create_Time">2015-11-07 17:54:09</timestamp>
<timestamp source="NTFS" timeType="local+4:00" parser="MFTRCRD" type="FILE_NAME" label="File_Modified_Time">2015-11-07 17:54:09</timestamp>
<timestamp source="NTFS" timeType="local+4:00" parser="MFTRCRD" type="FILE_NAME" label="MFT_Entry_modified_Time">2015-11-07 17:54:09</timestamp>
<timestamp source="NTFS" timeType="local+4:00" parser="MFTRCRD" type="FILE_NAME" label="File_Last_Access_Time">2015-11-07 17:54:09</timestamp>
</recordEvents>
</file>
Ideally, ANTS is designed to transfer files over shared network storage. The transfer directories do not need to be mapped to a drive letter, and users may not even be aware that the directory exists – ANTS just requires a local or UNC path. It is expected that archivists will remove accessions from the transfer directory and not store them there. This can be automated with a simple script that can also send a notification email drawn from the metadata included with the files. By transferring records over network shares, users are authenticated by their Windows login. The advantage of this method is that it leverages network protocols which may already be in use by an organization, such as Window’s Active Directory or other forms of Lightweight Directory Access Protocol (LDAP).
ANTS can also serve as an FTP client using individual user credentials. The problem here is coordinating credentials between ANTS and the FTP server. Credentials are stored in the user’s AppData directory, encrypted with CryptProtectData from the Windows API using Python’s Win32 Library. While this is similar to how many applications store user credentials, it is not very secure, and it still requires manual entry of credentials into the FTP server.
Conclusion
Employing digital forensics at accession is and will always be an imperfect and challenging method of managing digital records. Unlike disk imaging, employing these tools at accession requires proactive planning and the preemptive use of resources. If we do not use disk imaging, all contextual metadata outside of file content must be gathered in advance – actions that must be performed by the records creators themselves in records’ native environment.
Yet, institutional archivists may choose not to accept disk images for the problems they pose to records retention schedules and public records laws. Here, gathering record-events at accession may be the most effective way to maintain some basic context without retaining additional information that may conflict with retention scheduling.
While we have to employ digital forensic at accession under a number of constraints, forensic tools have developed to a point where it is now a feasible option. ANTS should act as proof of this viability and serve as a tool for future experimentation. Right now we are able to only gather some of the many possible record-events that may exist in the form of filesystem timestamps. Still, each timestamp documents a point of action that may help tell a more complete story. Every little bit helps, and if we can gather even this basic information systematically with limited barriers for records creators, the cost of digital forensics at accession can be small enough that archives can significantly benefit.
There is always the potential for future growth that may enable us to gather more information at accession. Digital forensic tools are evolving – getting more effective and easier to use. There is a strong potential for performing more sophisticated forensic analysis at accession, particularly for records creators who have administrative privileges.
Digital forensics at accession will never be able to gather all of the contextual information that disk imaging can, yet it can preserve the record-events that are most likely to be useful to future archivists and researchers. With reasonable future advances in tools, gathering record-events at accession can empower archivists to appraise and preserve the contextual information with the greatest value and minimum risk. For many repositories, particularly institutional archives which manage public records in a relatively controlled environment, employing digital forensics at accession can be viable and effective approach to managing digital records.
About the Author
Gregory Wiedeman is the University Archivist in the M.E. Grenander Department of Special Collections & Archives at the University at Albany, SUNY where he is charged with developing a digital records program.
Notes
[1] InterPARES Project Authenticity Task Force, “Requirements for Assessing and Maintaining the Authenticity of Electronic Records,” March 2002.
[2] Matthew G. Kirschenbaum, Richard Ovenden, and Gabriela Redwine, Digital Forensics and Born-Digital Content in Cultural Heritage Collections, (Washington, D.C.: Council on Library and Information Resources, 2010): 8, 21, 32.
[3] Kam Woods and Christopher A. Lee, “Acquisition and Processing of Disk Images to Further Archival Goals,” in Proceedings of Archiving 2012 (Springfield, VA: Society for Imaging Science and Technology, 2012), 148. & Kam Woods, Christopher A. Lee, and Simson Garfinkel, “Extending Digital Repository Architectures to Support Disk Image Preservation and Access,” in JCDL ’11: Proceeding of the 11th Annual International ACM/IEEE Joint Conference on Digital Libraries, (New York, NY: ACM Press, 2011).
[4] Christopher A. Lee, Kam Woods, Matthew Kirschenbaum, and Alexandria Chassanoff, “From Bitstreams to Heritage: Putting Digital Forensics into Practice in Collecting Institutions,” September 30, 2013.
[5] Ben Goldman, “Bridging the Gap: Taking Practical Steps Toward Managing Born-Digital Collections in Manuscript Repositories,” RBM: A Journal of Rare Books, Manuscripts, and Cultural Heritage 12:1 (2011) & AIMS Work Group, AIMS Born-Digital Collections: An Inter-Institutional Model for Stewardship, January 2012 & Ricky Erway, You’ve Got to Walk Before You Can Run: First Steps for Managing Born-Digital Content Received on Physical Media, (Dublin, Ohio: OCLC Research, August 2012) & Cyndi Shein, “From Accession to Access: A Born-Digital Materials Case Study,” Journal of Western Archives 5:1 (2014) & Joseph A. Williams and Elizabeth M. Berilla, “Minutes, Migration, and Migraines: Establishing a Digital Archives at a Small Institution,” The American Archivist 78:1 (2015).
[6] Julianna Barrera-Gomez and Ricky Erway, Walk This Way: Detailed Steps for Transferring Born-Digital Content from Media You Can Read In-house, (Dublin, Ohio: OCLC Research, June 2013) & Sam Meister and Alexandria Chassanoff, “Integrating Digital Forensics Techniques into Curatorial Tasks: A Case Study,” The International Journal of Digital Curation 9:2 (2014) & John Durno and Jerry Trofimchuk, “Digital Forensics on a Shoestring: A Case Study from the University of Victoria,” Code4Lib Journal 27 (January 21, 2015).
[7] The National Archives’ capstone email model comes to mind as an example. National Archives and Records Administration, “Email Management,” retrieved from https://www.archives.gov/records-mgmt/email-mgmt.html.
[8] New York State’s Freedom of Information Law states definitively that, “…government is the public’s business and that the public, individually and collectively and represented by a free press, should have access to the records of government…” New York (State) Legislature, “Freedom of Information Law,” Public Officers Law Article 6 (S 84-90), 2008. Exceptions to FOIL requests include records that, if made available, “…would constitute an unwarranted invasion of personal privacy…,” impede collective bargaining processes, contain certain trade secrets, or “…interfere with law enforcement investigations or judicial proceedings.” All other records must be made “available for public inspection and copying.”
[9] Lee, Woods, Kirschenbaum, and Chassanoff, 5-6.
[10] ANTS was developed primarily for Windows and has only been tested on Windows 7 and later. The PyInstaller executable should run on Mac OSX and Linux machines, yet ANTS is only written to read NTFS filesystems and non-Windows users are warned of this when running ANTS.
[11] ANTS envisions that records creators will have both a transfer and a request directory. It is designed that after a request is make, through the receipt or otherwise, an archivist can place the requested materials in the request directory temporarily and creators can download them through ANTS using either shared network folders or FTP. The transfer process is detailed further in the article.
[12] Pär Österberg Medina, “How to acquire ‘locked’ files from a running Windows system,” Open Security Research Blog, October 25, 2011, retrieved from http://blog.opensecurityresearch.com/2011/10/how-to-acquire-locked-files-from.html.
[13] Cory Altheide and Harlan Carvey, Digital Forensics with Open Source Tools (Walthan, MA: Syngress, 2011), 73-74.
[14] Brian Carrier, File System Forensic Analysis (Addison-Wesley: Upper Saddle River, NJ, 2005), 318.
Bibliography
AIMS Work Group. AIMS Born-Digital Collections: An Inter-Institutional Model for Stewardship. January 2012. Retrieved from http://dcs.library.virginia.edu/aims/white-paper/.
Altheide, Cory and Harlan Carvey. Digital Forensics with Open Source Tools. Walthan, MA: Syngress, 2011.
Barrera-Gomez, Julianna, and Ricky Erway. Walk This Way: Detailed Steps for Transferring Born-Digital Content from Media You Can Read In-house. Dublin, Ohio: OCLC Research, June 2013. Retrieved from http://www.oclc.org/content/dam/research/publications/library/2013/2013-02.pdf.
Carrier, Brian. File System Forensic Analysis. Addison-Wesley: Upper Saddle River, NJ, 2005.
Durno, John, and Jerry Trofimchuk. “Digital Forensics on a Shoestring: A Case Study from the University of Victoria.” Code4Lib Journal 27 (January 21, 2015). Retrieved from http://journal.code4lib.org/articles/10279.
Erway, Ricky. You’ve Got to Walk Before You Can Run: First Steps for Managing Born-Digital Content Received on Physical Media. Dublin, Ohio: OCLC Research, August 2012. Retrieved from http://www.oclc.org/content/dam/research/publications/library/2012/2012-06.pdf.
Gengenbach, Martin, Alexandria Chassanoff, and Porter Olsen. “Integrating Digital Forensics into Born-Digital Workflows: The BitCurator Project.” Proceedings of the American Society for Information Science and Technology 49:1 (2012). Retrieved from https://www.asis.org/asist2012/proceedings/Submissions/343.pdf.
Goldman, Ben. “Bridging the Gap: Taking Practical Steps Toward Managing Born-Digital Collections in Manuscript Repositories.” RBM: A Journal of Rare Books, Manuscripts, and Cultural Heritage 12:1 (2011).
Gudjonsson, Kristinn. “Mastering the Super Timeline with log2timeline.” SANS Institute Information Security Reading Room. June 29, 2010. Retrieved from https://www.sans.org/reading-room/whitepapers/logging/mastering-super-timeline-log2timeline-33438.
InterPARES Project Authenticity Task Force. “Requirements for Assessing and Maintaining the Authenticity of Electronic Records.” InterPARES Project. March 2002. Retrieved from http://www.interpares.org/book/interpares_book_k_app02.pdf.
Kirschenbaum, Matthew G., Richard Ovenden, and Gabriela Redwine. Digital Forensics and Born-Digital Content in Cultural Heritage Collections. Washington, D.C.: Council on Library and Information Resources, 2010. Retrieved from http://www.clir.org/pubs/reports/reports/pub149/pub149.pdf.
Lee, Christopher A. “Archival Application of Digital Forensics Methods for Authenticity, Description and Access Provision.” Comma 2:14 (2012). Retrieved from http://ils.unc.edu/callee/p133-lee.pdf.
Lee, Christopher A. “Digital Forensics Meets the Archivist (And They Seem to Like Each Other).” Provenance 30 (2012). Retrieved from http://digitalcommons.kennesaw.edu/cgi/viewcontent.cgi?article=1023&context=provenance.
Lee, Christopher A., Kam Woods, Matthew Kirschenbaum, and Alexandria Chassanoff. “From Bitstreams to Heritage: Putting Digital Forensics into Practice in Collecting Institutions.” September 30, 2013. Retrieved from http://www.bitcurator.net/docs/bitstreams-to-heritage.pdf.
Meister, Sam and Alexandria Chassanoff. “Integrating Digital Forensics Techniques into Curatorial Tasks: A Case Study.” The International Journal of Digital Curation 9:2 (2014). Retrieved from http://www.ijdc.net/index.php/ijdc/article/view/325.
National Archives and Records Administration. “Email Management.” Retrieved from https://www.archives.gov/records-mgmt/email-mgmt.html.
New York (State) Legislature. “Freedom of Information Law.” Public Officers Law Article 6 (S 84-90), 2008. Retrieved from http://www.dos.ny.gov/coog/foil2.html.
Medina, Pär Österberg . “How to acquire ‘locked’ files from a running Windows system.” Open Security Research Blog October 25, 2011. Retrieved from http://blog.opensecurityresearch.com/2011/10/how-to-acquire-locked-files-from.html.
Shein, Cyndi. “From Accession to Access: A Born-Digital Materials Case Study.” Journal of Western Archives 5:1 (2014). Retrieved from http://digitalcommons.usu.edu/westernarchives/vol5/iss1/1/.
Williams, Joseph A., and Elizabeth M. Berilla. “Minutes, Migration, and Migraines: Establishing a Digital Archives at a Small Institution.” The American Archivist 78:1 (2015).
Woods, Kam and Christopher A. Lee. “Acquisition and Processing of Disk Images to Further Archival Goals.” Proceedings of Archiving 2012. Springfield, VA: Society for Imaging Science and Technology, 2012. Retrieved from http://ils.unc.edu/callee/p147-woods.pdf.
Woods, Kam, Christopher A. Lee, and Simson Garfinkel. “Extending Digital Repository Architectures to Support Disk Image Preservation and Access.” JCDL ’11: Proceeding of the 11th Annual International ACM/IEEE Joint Conference on Digital Libraries. New York, NY: ACM Press, 2011. Retrieved from http://ils.unc.edu/callee/p57-woods.pdf.

Subscribe to comments: For this article | For all articles
Leave a Reply