By Michael Carlozzi
Introduction
As a technology librarian I am responsible for implementing technical solutions to enhance library experiences for both patrons and staff. Since I also work the reference desk, I noticed an intersection of two seemingly unrelated problems: 1) we do not track informative reference statistics, and 2) I have trouble meeting patrons’ technology needs because of time spent covering reference. As I was soon to find, these problems were connected.
In preparation for submitting annual reports, my library would traditionally sample reference statistics by using “clickers” or “hash marks” over a three-week period. The purpose of these samples was to meet state requirements and thus reported only the volume of transactions. As they provided no details on these transactions, several questions lingered: With what specific reference services did patrons need help? How could staff respond best to those needs? How should we staff reference in response to these data?
Canton Public Library employs three full-time librarians in the reference department—a reference services librarian, a teen librarian, and me. Staffing the reference desk consumes a considerable amount of our time and prevents us from providing specialized services. We average 19 hours/week at the desk per staff member, although the amount varies due to overlap and availability; some weeks, for example, I spend over 30 hours covering reference. In those weeks especially, I am handicapped in my ability to provide technology services and to maintain and improve our library’s technical infrastructure.
Anecdotally, I felt that most of the reference transactions we processed were directional, capable of being handled by paraprofessionals and volunteers. The directional nature of reference work has been addressed extensively in the literature (Aluri and St. Claire 1978; Summerhill 1994), with many librarians “transforming” reference in response to this and other pressures (Meldrem et al. 2005; Sonntag and Palsson 2007). But without data, all I had were conjectures—and no clarity on how to proceed.
In order to improve our traditional sampling methods, I decided to implement reference tracking software (RTS). Many librarians use RTS such as LibAnswers (Flatley and Jensen 2012), Desk Tracker, and Gimlet (Chan and Johns-Masten 2014). Librarians often record transactions to make organizational decisions: Bravender, Lyon, and Molaro (2011), for instance, used LibStats to conclude that “it is not cost effective to use reference librarians to answer [virtual] chat questions” (see also Garrison 2010). Thus RTS seemed to solve my two problems by enabling us to collect informative reference statistics and to make informed organizational decisions based on those statistics.
Many RTS programs come with downsides. Some of the issues are:
- They may be proprietary, limiting customization and/or requiring a monetary commitment.
- They may be inconvenient; for instance, users may need to select multiple options from a drop down menu. As Goodsett (2013) observed, “if your staff has to answer a slough[sic] of questions every time someone comes to the reference desk or sends an email, they may be discouraged enough to just skip recording reference data altogether.”
- They may be unsupported or unavailable; LibStats, a popular solution in the mid-late 2000s (see Jordan 2008), cannot be found easily, and its code — hosted on Github – has not been updated in over four years.
Google Forms has been used as RTS to some acclaim, but it has been criticized for lacking customizability and “reporting functionality” (Goodsett 2013). For example, Google Forms requires the manual entry of dates and times because its timestamp feature does not translate well to analytical platforms like Excel, SPSS, SAS, or R.
Finding the available RTS unsatisfactory for the above reasons, I coded in PHP—and released under GNU’s General License 3.0—a web-based program (TrackRef) built on an SQL database. This program seeks to address the above limitations by providing librarians with RTS that is free, open source, convenient, and powerful. In February of 2016 I launched the program in my library and we have been logging transactions ever since.

Figure 1. TrackRef’s homepage.
I wanted the program to facilitate efficient, comprehensive, and customizable data analysis. With that goal in mind, I programmed TrackRef to allow administrators the ability to manipulate whole categories of data (renaming, deleting, and creating) and to enable qualitative input. The ability to input qualitative data has proven useful. After data collection began, we formulated additional “research questions”—for example, 7% of all transactions within the first month related to “technology help.” But the kinds of technology help that people were seeking remained unclear. I could have added additional transactions for specific concerns (e.g. transactions of “Email” and “Browser Printing”), but adding new transactions for each concern seemed unsustainable in the longer run. Thus I coded TrackRef to enable a feature (called “detailed mode”) that allowed the entry of textual input for select transactions. Now staff can identify the kind of “technology help” they provided when logging.
What We Learned From Tracking Reference Statistics
As suspected, we discovered a low frequency of bona-fide reference transactions; 94% of our transactions were directional. Consistent with national trends, few patron requests required a librarian’s research skills. Further, most research questions required basic fact retrieval: i.e. identifying local news, retrieving phone numbers, accessing websites. These results suggested that staffing the reference desk with three full-time librarians was not the best use of the librarians’ expertise.
In response to these data, we began to implement a more “on-call” model of reference, where paraprofessional and volunteer staff answered most questions and directed difficult queries to librarians who otherwise spent their time on more specialized work. This approach is relatively uncommon; Miles (2013) found that only 10% of surveyed academic librarians used an on-call model of reference. Public library figures are likely lower than academic libraries’, as public libraries often lack the staffing surplus to allow their librarians “office time.” But our data show that most reference transactions can be handled by paraprofessionals; other researchers, even in academic contexts, have reached similar conclusions (see Dinkins and Ryan 2010; Faix et al. 2010). We are fortunate that a library of our (small) size has three pages and numerous volunteers, who have helped to cover the reference desk and “free up” the librarians to work within their specializations.
As an example, consider that patrons were not approaching the reference desk for assistance with eReaders (1.2% of TrackRef’s transactions), in stark contrast to national claims that patrons needed help in this area (Library Journal 2014). As the technology librarian, I was particularly interested in this problem since my job is to train patrons in using modern technology yet our patrons were not visiting the reference desk for eReader guidance. But with fewer hours at the reference desk, I have had time to market and offer guided technology instruction: each week I reserve two hours (30 minute appointments) for one-on-one assistance at times when I would ordinarily have worked reference. Every timeslot has been filled through July, with many patrons clamoring for additional hours—which I have been adding slowly. Of these appointments, 30% concern eReaders.
I also aim to offer classes based upon the needs of those attending my one-on-one sessions. Excel, for example, which accounts for 24% of booked appointments, suits the classroom environment in a way that eReaders—with so many idiosyncratic devices—do not. I have had more time to build a technology-centered curriculum, something for which many librarians unfortunately lack time, and I am also planning information literacy classes. Although a core tenet of librarianship, instruction is too often neglected because of other concerns. Even in academia, the predominant model of library instruction is the problematic “one-shot” (Fister 2013; Helms and Whitesell 2013). With more time to build engaging lessons built on data-supported curriculum, I can implement stronger pedagogy.
The Library has also used TrackRef’s data to improve staff efficiency. We noticed that several patrons needed help “accessing” our computer network: “access” was the largest category of transactions in TrackRef at 16%. We discovered more efficient ways to grant computer access. Rather than manually creating user sessions through our time management software, taking upwards of two minutes per action, we now batch print 90-minute guest passes. And although this does not solve the “problem” of needing to provide guest access (as we will always offer guest access for privacy-conscious patrons), it optimizes our process. We also created better signage and instructional materials to help patrons with common problems encountered when trying to access library resources, as identified by additional information entered alongside “access” transactions in detailed mode.
TrackRef revealed that almost 25% of patrons needed help with office services (faxing, printing, copying, and scanning). We decided to upgrade our reference department’s infrastructure by purchasing an easy to use, touchscreen Library Document Station that consolidates these functions. When we learned that so many transactions concerned the copy machine, I flagged the “photocopy” transaction to prompt detailed information (see the section “Installation and Configuration” for details). By flagging these transactions we found that most of the problems were related to: 1) a misleading “key card” error message on the display for which there was no fix; 2) very particular positioning requirements that resulted in photocopies coming out “wrong”; or 3) a coin-bill acceptor that only took coins. The Library Document Station solves these problems by eliminating the confusing error messages, allowing successful copies regardless of where patrons place documents on the scanner, and installing a new currency acceptor that takes bills, as well as coins.

Figure 2. Details on the “photocopy” transaction.
Finally, 13% of our reference transactions involved staff members booking the study room. In response, I am currently improving our in-house study reservation software by coding an online version which will allow patrons to book their own appointments. This way, reference staff will be responsible only for granting patrons access to the physical room (which we decided not to track separately in TrackRef).
Installation and Configuration
This section presents step-by-step instructions on installing, configuring, and launching TrackRef. Instructions on using the program are covered in the following section, “Using TrackRef: Process and Analysis.”
1) TrackRef requires a webserver. Unless you already use an online webserver, or you plan to implement the program across multiple networks/subnets, I recommend installing Wampserver. Wampserver brings the program’s essentials: Apache’s webserver (for hosting), mySQL (for database storage), and PHP (for querying the database). Mac users can use MAMP, though it has not been tested with this software.
The latest release of Wampserver when I wrote this, 3.0, requires numerous Windows Visual C++ packages, and users on 64-bit machines must install both the 32-bit and 64-bit packages. This is quite a headache, and some users report that installing packages “out of order” causes the entire installation to fail. Because Wampserver 2.5 does not require nearly so many packages and has functionally similar to 3.0, I recommend using Wampserver 2.5.
Additional configuration outside of selecting a default browser shouldn’t be required, although password protecting the SQL database is recommended (that is beyond this guide’s scope). For further help on configuring Wampserver, consult this thread on http://forum.wampserver.com/read.php?2,123606.
2) Download TrackRef’s code from http://www.activelibrarians.com/trackref and extract it to your webserver’s directory: in WAMP, the default is C:/wamp/www. As Wampserver’s authors note, this directory should not be changed from default.

Figure 3. Correctly extracted TrackRef folder in Windows 7.
3) On the machine hosting TrackRef, test the installation by navigating in a web browser to http://localhost/trackref. TrackRef’s homepage should be displayed, not a “Not Found” error (SQL connection errors are to be expected, as TrackRef has not yet been configured). Because TrackRef is hosted on a webserver, all computers within the same network can access its webpage. For example, my library uses the 192.168.1.0/24 address space for its internal network. The particular computer hosting TrackRef has an IP address of 192.168.1.76. Thus for other staff members to access TrackRef, they visit http://192.168.1.76/trackref. Consult your library’s information technology representative if you are unsure of your library’s network layout.
4) Once TrackRef is online, its settings must be configured. TrackRef’s folder contains numerous PHP files, each responsible for handling different program functions. The settings.php file is used to configure TrackRef. The settings.php satisfies many work environments—those that want quick, easy, and strictly quantitative data. If you want to use TrackRef in detailed mode, which allows staff to enter descriptive information for select transactions, you will need to replace the settings.php file with settingsdetailed.php. When choosing this option, first delete or rename the original settings.php and rename settingsdetailed.php to settings.php. This now becomes the file that you will edit in order to configure TrackRef’s settings.
Which file is for you? All else being equal, I recommend using detailed mode (settingsdetailed.php) unless you absolutely do not want textual input. With detailed mode, the administrator can “flag” transactions when needed (see below), allowing for additional data. Librarians interested in purely aggregate data may prefer the simpler version.
5) TrackRef stores all of its data in an SQL database and must have credentials to access that database. Edit settings.php with your database’s login information, as you had determined when installing Wampserver. By default, the username is “root,” the host is “localhost,” and the password is “” (blank). Those using external web hosting can retrieve this information from their web host. Web hosting may require changing the database’s name from “reference” to something else, in which case the administrator must change the database’s name in settings.php, settingsdetailed.php, and create.php (all the files that create a database connection).

Figure 4. Database settings in settings.php.
In settings.php you create the transactions you wish to track; the program supports up to 14 distinct transactions. With detailed mode enabled, staff members are prompted for additional qualitative (textual) input after recording transactions. This option is configured through an array called $total in the settings.php page (renamed from the settingsdetailed.php file): for each transaction type, “0” will not prompt additional information whereas “1” will.

Figure 5. The $total array in detailed mode: ‘1’ indicates detailed information requests. Here, for example, “Catalog” will not request additional information but “Faculty” will.
Other options managed in settings.php are time zone, the ability for staff to delete their transactions, the times to appear on hourly transaction charts, and the requirement to confirm transactions.
6) Once settings.php is saved, visiting http://localhost/trackref/create.php will run a script that creates a database called “reference” with all the required tables as well as an “admin” user. In case the script fails, TrackRef includes the database.txt file outlining the database’s structure. Administrators can add these tables by using an interface like PHPMyAdmin, which comes with Wampserver and can be accessed through http://localhost. See PHPMyAdmin’s documentation for further guidance.
7) With the database created, the program administrator can now log into TrackRef with the admin user, whose default credentials are “admin/admin”; the admin account has special privileges, enabling the creation of additional users and library locations as well as the ability to structure the database. After logging in with these credentials, the administrator should change the account’s password under the Settings tab located in the top navbar; this is not the settings.php page. The admin should also create a library location and associate it with him/herself by clicking “Update User Settings.”
TrackRef can be configured to add support for “roving reference” by including the following meta element on index.php:(you may need to tweak the content parameters for your devices). This addition makes the homepage mobile-friendly when recording transactions; it is not enabled by default because, absent customization, it may distort the homepage.
Using TrackRef: Process and Analysis
On TrackRef’s homepage, staff members click a word to record its represented transaction; a Javascript alert box (which can be disabled) asks for confirmation; when using detailed mode, they are instead asked to provide detailed information for flagged transactions. Once confirmed, the transaction and its corollary information enter the database: year, day, time, month, transaction type, staff member, and location. Staff can also enter data retroactively under the navbar tab Manual Entry. With Manual Entry, TrackRef stores the last-entered date so users do not need to keep changing it when, say, “catching up” at week’s end.
In detailed mode, I recommend standardizing input because the program does not offer controlled vocabulary; for instance, instruction librarians may want to determine the distribution of classes visiting reference. If enough of one class visits the desk, then librarians may contact the relevant faculty and offer course-based instruction (if using this instructional model). Data become easier to visualize and code elsewhere (such as in Excel) when standardized. A listing of transactions with information like “ENL 240,” “BUS 101,” and “NUR 331” is more manageable than one with “English 240 intermediate lit. class,” “Introduction to business studies” and “upper-div nurse class.”
The program offers two analytical methods: 1) graphs for quick and aesthetic analysis and 2) CSV exportation for deeper analysis. The Analytics tab uses FusionCharts to render data. By default, these charts display usage by month, weekday, and hour. Basic customization is also allowed, where users can specify certain days of the week (or years), which are then analyzed on the custom.php page; for instance, my library opens from 10:00 AM to 9:00 PM three days a week, so when analyzing hourly statistics I might compare only those three days.

Figure 6. FusionCharts’ rendition of our hours for days open from 10:00 AM to 9:00 PM.
For further analysis, use the program’s second analytical method: database extraction. Under the Settings tab, click the “Export” button under “Export Database to CSV.” This exports the transactions table to a CSV file, where data can be freely manipulated. The graphs provided within TrackRef are meant to visualize common analytical functions and are not meant to be exhaustive. Experienced users should not be discouraged from tweaking the source code to add additional graphs, but consider exporting the database to a CSV file instead; analysis is often easier within a statistical package than through programming.
Issues Encountered and Further Work
The largest hurdle has been getting all staff members to log transactions. As other librarians have noted (Flatley and Jensen 2012), RTS only works when used. Once logging begins, forgetfulness becomes “declining usage”—everyone enthusiastically logs in September and then neglects to do so in November. Thus I have had to qualify all analysis; for example, when comparing transactions by time of day I have to consider that some workers log more diligently than others.
Security may also be a concern. Web-based (HTTP) limitations apply to this program as they would to any other; absent encryption, data (e.g. login credentials) can be sniffed by network users. I do not regard this as a serious enough risk in terms of likelihood or severity to implement encryption in my own library network, but be aware of the risks. Concerned librarians should be able to encrypt their networks with the help of computer support services.
Finally, as a work in progress TrackRef is far from perfect. Its advantage over commercial products is that it is free, easy to use, open source, and customizable. Unfortunately, as it is the work of one developer, it has some limitations, listed below:
- Web hosting may break some of the code’s query structuring. Although I have not tested this particular program online, other programs I have written failed when hosted online. In one case, I had to change every SQL query from single to double quotation marks. In another, my web hosting’s peculiar PHP configuration required extensive troubleshooting.
- The programming for “hourly rate” statistics in the Analytics tab is lackluster. TrackRef divides total transactions (for each hour block) by the number of distinct dates in the database, yielding a “per hour” rate statistic. This works poorly with unequal operating hours. For example, because my library closes at 5:30 on Friday and Saturday, the hourly rates for 5:00 PM to 9:00 PM will be slightly lower than reality. I am working on an improved hourly rate version, but for now that statistic represents an approximation, not the actual value.
- Staff members can only be associated with one location at a time. This can be annoying when working physical and virtual reference simultaneously, so administrators might consider creating a shared account called “Virtual” (because the program does not prevent multiple logins for one account, administrators can create the virtual account as they would any other). Multiple staff members can then log into the virtual account to record transactions.
- On the custom.php page between lines 380 to 507 is some code which presents a pie chart of transactions received in a given hourly period. The code is “commented out” to prevent SQL errors. Librarians may wish to know at what times certain kinds of transactions come to the reference desk and thus staff accordingly. Unfortunately this feature is not yet release-ready and requires manipulation of the source code. To change the current time from the default of 8:00 PM, edit the following code on line 390, changing the times (e.g. 7:00 PM would be $newTime > = 700 && $newTime < 759). This code currently does not work for mornings.
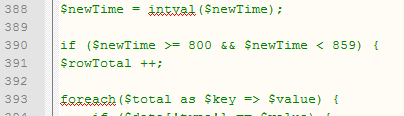
Figure 7.
Conclusion
TrackRef has allowed our library to make data-driven organizational decisions. I have been able to offer more technological instruction and plan to provide even more in the future. We have also improved overall staff efficiency and have made a large (for our institution’s size) evidence-based purchase for the reference department: the Library Document Station. Going forward, I plan to use these data for organizational rather than strictly departmental analysis (e.g. our operating hours).
Not all of our goals have been met, unfortunately. Full-time degreed librarians still primarily cover reference. Our reference librarian in particular still spends considerable time staffing the reference desk and has not been able to develop a genealogy center as originally planned. She has, however, been relieved from the desk enough to reorganize our archival/local history room in preparation for launching such a center. Nevertheless, data from TrackRef have helped us to move in a positive and progressive direction that will hopefully continue.
References
Aluri, R., & St. Clair, J. 1978. Academic reference librarians: An endangered species? Journal of Academic Librarianship: 82-4.
Bravender, P., Lyon, C., & Molaro, A. 2011. Should chat reference be staffed by librarians? An assessment of chat reference at an academic library using LibStats. Internet Reference Services Quarterly 16(3): 111-127.
Chan, T., & Johns-Masten, K. 2014. A Study of Gimlet Use in Reference Transactions. Internet Reference Services Quarterly 19(2): 73-87.
Dinkins, D., & Ryan, S. 2010. Measuring referrals: The use of paraprofessionals at the reference desk. The Journal of Academic Librarianship 36(4): 279-286.
Faix, A., Bates, M., Hartman, L., Hughes, J., Schacher, C., Elliot, B., & Woods, A. 2010. Peer reference redefined: New uses for undergraduate students. Reference Services Review 38(1): 90-107.
Fister, B. 2013. The library’s role in learning: Information literacy revisited. Library Issues: Briefings for Faculty and Administrators: 33(4).
Flatley, R., & Jensen, R. 2012. Implementation and use of the reference analytics module of LibAnswers. Journal of Electronic Resources Librarianship 24(4): 310-315.
Garrison, J. 2010. Making reference service count: Collecting and using reference service statistics to make a difference. The Reference Librarian 51(3): 202-211.
Goodsett, M. 2013. No more tallies: Comparing web-based reference statistics tools. Persona website [Internet]. [cited 2016 May 4]. Available from:
https://mandigoodsett.com/2013/10/21/no-more-tallies-comparing-web-based-reference-statistics-tools/
Helms, M., & Whitesell, M. 2013. Transitioning to the embedded librarian model
and improving the senior capstone business strategy course. The Journal of Academic Librarianship 39(5): 401-413.
Jordan, E. 2008. LibStats: An open source online tool for collecting and reporting on statistics in an academic library. Performance Measurements and Metrics 9(1): 18-25.
Library Journal. 2014. Ebook usage in U.S. public libraries. [cited 2016 May 8]. Available from: https://s3.amazonaws.com/WebVault/ebooks/LJSLJ_EbookUsage_PublicLibraries_2014.pdf
Meldrem, J., Mardis, L., Johnson, C. 2005. Redesign your reference desk: Get rid of it! Currents and Convergence: Navigating the Rivers of Change Proceedings of the Twelfth National Conference of the Association of College and Research Libraries. Ed. Hugh A. Thompson. Chicago: Association of College and Research Libraries, 2005.
Miles, D. 2013. Shall we get rid of the reference desk? Reference & User Services Quarterly 52(4): 320-324.
Sonntag, G., & Palsson, F. 2007. No longer the sacred cow—no longer a desk: Transforming reference service to meet 21st Century user needs. Library Philosophy and Practice 45(2): 104-107.
Summerhill, K. 1994. The high cost of reference: The need to reassess services and service delivery. The Reference Librarian 20(43): 71-85.
About the Author
Michael Carlozzi (michael@activelibrarians.com) is the Library Director at Wareham Free Library in Massachusetts. Previously, he was Technology and Information Services Librarian at the Canton Public Library in Massachusetts. He dreams of a world that takes cribbage more seriously.

Beeresh, 2023-09-28
Hi,
Mr Michael Carlozzi,
Greetings!!
TrackRef is really helpful and appreciate your kind efforts in this regard. I am also trying to use TracRef for my library. This is to say thanks to you.,
Request you to mail me your further thoughts. I may need your help making use of this tool.
Thank You,
Beeresh, Bangalore, India