By Netanel Ganin
Introduction
“What order is this in?” — Patrons
Patrons love to browse. Whether they’re at a library, retail establishment, or grocery store, serendipitous discovery always plays an important role in their selection. Our classification schemes are designed to enhance this process; by placing similar items together, a patron can scan an entire section to find resources she didn’t even know she was looking for. Unfortunately, some resource types, such as electronic resources, can’t be browsed at all on the shelves. Videos and DVDs simply aren’t suited to it.
In March of 2014, I was working at Emerson College, a small liberal arts institution with a strong communications program. The Emerson library at that time held 100,000 books and other media, including roughly 3,000 DVDs in the circulating collection. Movies are often cataloged differently depending on the institutional policy. Some institutions organize them by title, with no LC or Dewey call number, others assign them to the PN1997 (Plays, scenarios, etc.) section, then cutter them at title or director, and still others, including Emerson College, class them in the PN1995.9.A-Z (Special topics in motion pictures).
Classing this way tied each film to a single genre/form/theme, even though films can and do belong to many categories. A foreign horror film had to be classed as foreign or as horror, it couldn’t be assigned both because it had to sit in a single physical location on the shelves. This struck me as a very outmoded “video-store” mentality. Our patrons were much more accustomed to Netflix, Hulu, and Amazon streaming services which, of course, allow for multiple access points in genre, form, and theme, as well as a visual browsing interface.
I had an idea: not only would a new discovery interface allow for a better patron experience in DVD browsing, but it would also solve another problem that had stymied our patrons. Students would regularly come to the desk expecting to be able to check out a specific movie only to discover that the movie they wanted was in the non-circulating collection. There was no way limit a search to the circulating collection only. There were an additional 4000 movies in the non-circulating collection all of which could only be watched in the library. Furthermore, It was not possible to search for filmmakers within specific roles. A search for ‘Steven Spielberg’ would return movies he produced, executive produced, and wrote, whereas a patron may want Steven Spielberg as director.
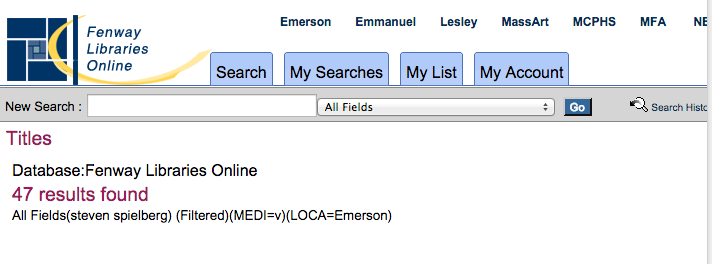
Figure 1. Screenshot of search results from Emerson’s catalog.
As Figure 1 shows, there are 47 results for a search of ‘Steven Spielberg’ filtered to only include DVDs and videos. Of those 47, 30 were false positives (i.e. Steven Spielberg is in the record but not the director), and 22 of them required an additional click to determine if the item was in the circulating collection or not.
I hoped and planned that my new interface could solve both of these issues as well. But as someone who not only hadn’t finished library school, but also hadn’t read any works about discovery interfaces, I ended up with a haphazard and erratic project. I didn’t follow any established methodology or framework, and after receiving a loose ‘go ahead’ didn’t consult with anyone at Emerson about the work, it’s goals, or the process of achieving those goals. This is my story, learn from my mistakes.
Beginnings
I want to point out that one of my stated goals was to save patrons from the frustration of getting hits from the non-circulating collection if they wanted to take the DVD home. That could’ve been solved by asking Voyager to add ‘Circulating media’ as a location along with ‘Reserves’ and ‘Reference’. That would’ve been a lot easier, but I didn’t think of that.
Instead, I began to build what I came to call Emflix. I asked our systems librarian for the MARC data from our catalog for the circulating collection. Using Microsoft Access, she ran the following query:
SELECT MFHD_MASTER.NORMALIZED_CALL_NO, MFHD_MASTER.DISPLAY_CALL_NO, utf8to16([bib_text].[TITLE]) AS TITLE, utf8to16([bib_text].[TITLE_BRIEF]) AS TITLE_BRIEF, utf8to16([bib_text].[UNIFORM_TITLE]) AS UNIFORM_TITLE, utf8to16([bib_text].[AUTHOR]) AS AUTHOR, BIB_TEXT.PUBLISHER, BIB_TEXT.BEGIN_PUB_DATE, BIB_TEXT.END_PUB_DATE, utf8to16([bib_text].[PUB_DATES_COMBINED]) AS PUB_DATES_COMBINED, BIB_TEXT.PUBLISHER_DATE, BIB_TEXT.LANGUAGE, getfieldall(getbibblob([bib_text].[bib_id]),"546") AS 546, getfieldall(getbibblob([bib_text].[bib_id]),"500") AS 500, getfieldall(getbibblob([bib_text].[bib_id]),"511") AS 511, getfieldall(getbibblob([bib_text].[bib_id]),"520") AS 520, BIB_MFHD.BIB_ID, BIB_MFHD.MFHD_ID, MFHD_ITEM.ITEM_ID, ITEM_BARCODE.ITEM_BARCODE
FROM (((BIB_TEXT INNER JOIN BIB_MFHD ON BIB_TEXT.BIB_ID = BIB_MFHD.BIB_ID) INNER JOIN MFHD_MASTER ON BIB_MFHD.MFHD_ID = MFHD_MASTER.MFHD_ID) INNER JOIN MFHD_ITEM ON MFHD_MASTER.MFHD_ID = MFHD_ITEM.MFHD_ID) INNER JOIN (ITEM_BARCODE INNER JOIN ITEM ON ITEM_BARCODE.ITEM_ID = ITEM.ITEM_ID) ON MFHD_ITEM.ITEM_ID = ITEM.ITEM_ID
WHERE (((MFHD_MASTER.LOCATION_ID)="373") AND ((ITEM.ITEM_TYPE_ID) In ("19","225")))
ORDER BY MFHD_MASTER.NORMALIZED_CALL_NO;
In hindsight, I should’ve asked questions such as what specifically was being retrieved by this query, or if I could get the full descriptive data. Instead, I simply retrieved the download as an Excel spreadsheet and saved it in XML. Each entry in the resulting file looked something like this:
<row> <Heading0>PN 19959 C 55 S 68 2002</Heading0> <Heading1>[DVD] PN1995.9.C55 S68 2002</Heading1> <Heading2>1941 [videorecording] / Universal Pictures and Columbia Pictures ; A-Team production ; screenplay by Robert Zemeckis and Bob Gale ; story by Robert Zemeckis, Bob Gale and John Milius ; produced by Buzz Feitshans ; directed by Steven Spielberg.</Heading2> <Heading3>1941</Heading3> <Heading4></Heading4> <Heading5></Heading5> <Heading6>Universal Home Video,</Heading6> <Heading7>2002</Heading7> <Heading8>1979</Heading8> <Heading9>2002-1979</Heading9> <Heading10>[2002]</Heading10> <Heading11>eng</Heading11> <Heading12>English dialogue, optional subtitles in French and Spanish; closed-captioned.</Heading12> <Heading13>Originally released as a motion picture in 1979. Special features: restored footage not included in the original theatrical release; an original documentary on The making of 1941, including new video interviews with Steven Spielberg, Bob Gale, John Miliu</Heading13> <Heading14>Dan Aykroyd, Ned Beatty, John Belushi, Lorraine Gary, Murray Hamilton, Christopher Lee, Tim Matheson, Toshiro Mifune, Warren Oates, Robert Stack, Treat Williams.</Heading14> <Heading15>This comedy is set in Los Angeles days after the attack on Pearl Harbor, when the fear of a Japanese invasion hung over the city.</Heading15> <Heading16>1336944</Heading16> <Heading17>1628403</Heading17> <Heading18>1461057</Heading18> <Heading19>0113503089311</Heading19> </row>
The mappings, drawn from the first row of the Excel spreadsheet, are:
<row>
<Heading0>NORMALIZED_CALL_NO</Heading0>
<Heading1>DISPLAY_CALL_NO</Heading1>
<Heading2>TITLE</Heading2>
<Heading3>TITLE_BRIEF</Heading3>
<Heading4>UNIFORM_TITLE</Heading4>
<Heading5>AUTHOR</Heading5>
<Heading6>PUBLISHER</Heading6>
<Heading7>BEGIN_PUB_DATE</Heading7>
<Heading8>END_PUB_DATE</Heading8>
<Heading9>PUB_DATES_COMBINED</Heading9>
<Heading10>PUBLISHER_DATE</Heading10>
<Heading11>LANGUAGE</Heading11>
<Heading12>546</Heading12>
<Heading13>500</Heading13>
<Heading14>511</Heading14>
<Heading15>520</Heading15>
<Heading16>BIB_ID</Heading16>
<Heading17>MFHD_ID</Heading17>
<Heading18>ITEM_ID</Heading18>
<Heading19>ITEM_BARCODE</Heading19>
</row>
I then wrote an XSLT stylesheet to transform the Excel-as-XML data into an XML structure of my own design. The following two functions were important and complex parts of that stylesheet.
Name Extraction Function
I used this function for extracting names from , which I determined was composed of most of the MARC 245 field. The writer, creator, and director elements were constructed by this template in my home-grown XML structure. It calls a function “extract” with three parameters
- The text to be searched (in this case the value of )
- The string markers to look for within the text
- The name of the element to construct (in this case ‘director’)
<xsl:template match="Heading2" mode="director">
<xsl:sequence
select="functx:extract(normalize-space(.),('written, directed and edited by ','director/writer, ','directed & produced by ','directors, ','direction by ','directed by ','director, ','directed and written by ','directed and produced by ','directed, written and produced by ','direction, '),'director')"
/>
</xsl:template>
<!-- Extract Function -->
<xsl:function name="functx:extract" as="element()*">
<xsl:param name="input" as="xs:string"/>
<xsl:param name="markers" as="xs:string*"/>
<xsl:param name="element-name" as="xs:string"/>
Analyze-string joins all the markers together, separated by the regular expression ‘or’ operator and scans the input text. It stores all text which occurs after a marker phrase until it finds a space-semicolon (which in a 245 would indicate change of role), or the end of the input string.
<xsl:analyze-string select="$input" regex="({string-join($markers, '|')})([^;]+)(\s;|$)">
The next analyze-string uses capture-group 2 (which would ideally be a person’s or multiple people’s names, following one of the marker phrases above) and would store any text preceding space-and-space, comma-space, or space-&-space.
<xsl:matching-substring>
<xsl:analyze-string select="regex-group(2)"
regex="([^,]+?)(((\sand|,|\s&)\s)|$)">
The element is constructed, and a sort attribute is added so that indexing could be done on the last name (you’ll note that it only builds the sort attribute if someone has a first and last name; if the person had three names, I looked it up myself to be sure which was their last name)
<xsl:matching-substring>
<xsl:element name="{$element-name}">
<xsl:if test="matches(regex-group(1),'^\w+\s\w+$')">
<xsl:attribute name="sort">
<xsl:value-of
select="string-length(substring-before(regex-group(1),' ')) + 2"
/>
</xsl:attribute>
</xsl:if>
The name is inserted into the element and any trailing spaces or a period are stripped
<xsl:value-of
select="functx:substring-before-if-ends-with(normalize-space(regex-group(1)),'.')"
/>
</xsl:element>
</xsl:matching-substring>
</xsl:analyze-string>
</xsl:matching-substring>
<xsl:fallback>
<xsl:element name="{$element-name}"/>
</xsl:fallback>
</xsl:analyze-string>
</xsl:function>
You may wonder why I didn’t simply extract names from the 700 fields. The answer is that I didn’t have any 700 fields in my data! This workaround, although complex, did teach me a lot about regex and its power for string manipulation.
Title Capitalization Function
Before calling the function, I removed trailing forward slashes, periods, and whitespace.
<xsl:template match="Heading3" mode="title">
<xsl:variable name="title"
select="functx:substring-before-if-ends-with(functx:substring-before-if-ends-with((normalize-space(.)),' /'), '.')"/>
The title is tokenized (broken down into pieces separated by a space) and each token is passed to the titleCase function. When it comes back it re-joins all the other tokens (in the same order) and the first letter of the entire title is capitalized.
<xsl:sequence
select="functx:capitalize-first(string-join(for $x in tokenize($title,'\s') return functx:titleCase($x),' '))"
/>
</xsl:template>
The titleCase function takes a single parameter, in this case a token of the title. If the token (converted to lowercase) matches any of these lower-cased-title-words, it returns the token in lowercase. If the token is entirely uppercase it returns unchanged (based on my assumption that that word is being treated differently in the title). If neither of those are true, the first letter of the token is capitalized.[1]
<xsl:function name="functx:titleCase" as="xs:string">
<xsl:param name="token" as="xs:string"/>
<xsl:choose>
<xsl:when
test="lower-case($token)=('a','aboard','about','above','absent','across','after','against','alongside','amid','amidst','among','amongst','an','and','around','as','aslant','astride','at','athwart','atop','barring','before','behind','below','beneath','beside','besides','between','beyond','but','by','despite','down','during','except','failing','following','for','from','in','inside','into','like','mid','minus','near','next','nor','notwithstanding','of','off','on','onto','opposite','or','out','outside','over','past','per','plus','regarding','round','save','since','so','than','the','through','throughout','till','times','to','toward','towards','under','underneath','unlike','until','up','upon','via','vs.','when','with','within','without','worth','yet')">
<xsl:value-of select="lower-case($token)"/>
</xsl:when>
<xsl:when test="$token=upper-case($token)">
<xsl:value-of select="$token"/>
</xsl:when>
<xsl:otherwise>
<xsl:value-of
select="concat(upper-case(substring($token, 1, 1)), lower-case(substring($token, 2)))"/>
</xsl:otherwise>
</xsl:choose>
</xsl:function>
Fun fact about titles: the way the data I had was structured, all non-filed articles were stripped. So I had to add back every ‘The’, ‘A’, and ‘An’.
Through the full XSLT transformation (inevitably followed by some clean up), the example record above became my home-grown XML structure:
<media id="1336944" dateCreated="2014-07-18">
<title>1941</title>
<director sort="8">Steven Spielberg</director>
<actor sort="5">Dan Aykroyd</actor>
<actor sort="5">Ned Beatty</actor>
<actor sort="6">John Belushi</actor>
<actor sort="10">Lorraine Gary</actor>
<actor sort="8">Murray Hamilton</actor>
<actor sort="13">Christopher Lee</actor>
<actor sort="5">Tim Matheson</actor>
<actor sort="9">Toshiro Mifune</actor>
<actor sort="8">Warren Oates</actor>
<actor sort="8">Robert Stack</actor>
<actor sort="7">Treat Williams</actor>
<genreWrap>
<genre>Comedy</genre>
<subGenre>Spoofs and Satire</subGenre>
</genreWrap>
<summary>This comedy is set in Los Angeles days after the attack on Pearl Harbor, when the
fear of a Japanese invasion hung over the city.</summary>
<LCSpecialTopics>Comedy</LCSpecialTopics>
<writer sort="8">Robert Zemeckis</writer>
<writer sort="5">Bob Gale</writer>
<language>English</language>
<year>1979</year>
<callNumber href="http://endeavor.flo.org/vwebv/holdingsInfo?bibId=1336944">[DVD] PN1995.9
.C55 S68 2002</callNumber>
<coverArt href="Pics/1941.jpg"/>
</media>
At this point I’d add the genres, subgenres and sub-subgenres to the film. I knew that genre analysis of over 3000 films would be the biggest challenge, and it certainly turned out to be the most tedious. Rather than have to analyze them all myself, I decided to use a pre-existing database of films with genre analysis already complete: Netflix. For every film that we owned, I’d enter its name into the Netflix DVD database (not the streaming database) and manually entered the genres that Netflix assigned into my structure. It was necessary to be logged in as a registered user to find this data.
As our collection was fairly small relative to theirs I saw that I didn’t actually need all of Netflix’s possible genres,[2] lest a single category be populated with 1 or even 0 items. To that end I made myself a thesaurus mapping all of Netflix’s genres to the ones I’d actually be using. I also made many modifications to the Netflix genre, some for hybrid-genre consistency, others for inclusion reasons.
Interface
What I now had was a lot of movies in my own home-grown XML structure, and I needed to convert it into something patrons could search and browse. Because I didn’t know how to use relational databases (and I didn’t even know that that’s what I should have been doing at this step), I decided to turn the entire structure into static html pages, one for each genre, subgenre, and sub-subgenre.
XSLT 2.0’s for-each-group functionality was invaluable at this point for grouping each set of films. I had struggled with trying to understand Muenchian grouping [3] which was the technique used in XSLT 1.0 for grouping sets.
For the searching, I learned about php’s SimpleXML functions, and decided to separate results by where they were found in the record. Searching a person’s name would return movies divided by their role in the film. The most important piece of code in the search functionality was another tokenizing function. By separating the inputted string into tokens I was able to use XPath’s contains() function to see if any given field contained the whole search phrase regardless of term order.
$initialSearch = $_GET["searchTerm"];
$contains = array();
$str = $searchTerm;
$str_arr = explode(' ',$str);
$i=0;
$contains[0] = 'contains(translate(., "'.$upper.'","'.$lower.'"), "'.$str_arr[0].'")';
for($i=1; $i < count($str_arr);$i++){
$contains[$i] = ' and contains(translate(., "'.$upper.'","'.$lower.'"), "'.$str_arr[$i].'")';
}
$csv_var = implode('', $contains);
$directorCheck = $xml->xpath('/mediaList/media[director['.$csv_var.']]');
$writerCheck = $xml->xpath('/mediaList/media[writer['.$csv_var.']]');
$actorCheck = $xml->xpath('/mediaList/media[actor['.$csv_var.']]');
$mediaCheck = $xml->xpath('/mediaList/media['.$csv_var.']');
Phase 4 – Use Testing and Leaving Emerson
I sent a URL of the site to the entire staff and student employees of the library to gather feedback. In my original implementation there were neither summaries of films nor actors of the films. Both of these were heavily requested, so I went back to include them. Before the testing was complete and the site was set to be launched, I accepted a position at another institution.
I left my successor with a 23 page document detailing the idiosyncrasies of how to maintain and update Emflix in my absence. Many of the particulars and rules I had come up with were incredibly complicated. For example, because my thesaurus would deauthorize any genre, subgenre or sub-subgenre which had fewer than 5 films, as new films were added to the database, I maintained a separate spreadsheet marking how many films could fit in a deauthorized genre in case sufficient films bearing that genre were added to authorize it.
Another idiosyncrasy was the structure of the element itself. Each had to hold one element and then as many elements as necessary. Every element added to the element had to immediately follow a element. Therefore if adding two elements from the same hierarchy, the element which was its broader term would have to be repeated. E.g., If a film were to be assigned ‘Dramas Based on Bestsellers’ and ‘Dramas Based on Contemporary Literature’ the structure would have to look like:
<genreWrap> <genre>Drama</genre> <subGenre>Dramas Based on the Book</subGenre> <subSubgenre>Dramas Based on Bestsellers</subGenre> <subGenre>Dramas Based on the Book</subGenre> <subSubgenre>Dramas Based on Contemporary Literature</subGenre> </genreWrap>
Despite my efforts to facilitate continuation of the project, in my heart I didn’t expect that anyone who hadn’t invested as much time as I had would be willing or able to maintain the project. Every new entry required a certain amount of manual entry, and I’d estimate that it could have taken an average of 5 minutes per movie. At the rate at which movies were acquired, that would have meant an extra 8-10 hours of work a month. In truth, I did most of my entries at home, off-work time. Not only is that bad work-life-balance, but it also created a false sense of time requirements to others who saw my progress. To date, no new films have been added, and the project has languished.
Lessons Learned
The primary take-away from this project was that I did too much alone. By this I mean that I wasn’t participating in any larger conversations in library communities. Partially this is because I didn’t feel that I was ready to join those conversations as someone who was still a student in library-school. Mostly however, it was that I’d been struck with an idea, and I didn’t think I needed to ask anyone else. I thought I’d invented the ‘simple’ solution that no one else had ever thought of for media discovery, and I ran with it. The more I worked on it and the more it grew, the less I felt I could stop and ask questions because I’d already invested so much time in what I’d done. If I’d researched vendor platforms, asked how other libraries were handling the issues I saw, or even asked peers if they wanted to work on it with me, I could have avoided many of the mistakes I made that led to the project’s current (and future) stagnation. I highlight some of those mistakes here.
I should not have made my own XML structure. I spent a great deal of time designing and re-designing a schema when many metadata schemas already existed which would’ve served my purposes just fine. Designing my own schema also meant that the data I was creating had interoperability with neither our own catalog, nor anyone else’s. It meant having to write lengthy documentation on the meaning of each attribute and element, and what values to enter into them.
I’m particularly chagrined at how little thought I gave to enhancing the records already in our catalog. Though I made thousands of genre assignments in my own XML, I never thought to explore the possibility of adding Library of Congress Genre/Form Terms to our catalog’s records. Emflix may not be in use anymore, but Emerson’s catalog certainly is and if I’d focused on enhancing those records while working on the side-project, that data would still be useful today. I should have directly contacted the people responsible for our visual materials cataloging and collaborated with them to make the data I was generating reusable in the main library catalog. Another area I wish I’d explored more was bringing in end-user (primarily student) opinions earlier. I think I spent so long building the site I lost sight of what it was supposed to be for.
I wrote an XSD file to handle the basic validation of the XML, but because I didn’t know about any other XML validation languages, I also wrote XSLT ‘error-checkers’ to validate some pieces that XSD cannot do but other languages like RelaxNG can. This created some code-bloat and increased the load for anyone hoping to take over the project.
I also should have pressed harder to get the full bibliographic records in my dataset downloads. Having access to the 7XX fields would have made retrieving the names of people associated with each film significantly easier.
I never should have brought Netflix into the equation. Using a commercial database which requires a subscription to log-on is not a good model on which to sustain a library project.
Each genre (or subgenre or sub-subgenre) page of films was a static list that was manually generated by an XSLT transformation and then uploaded to the server. I was expecting people to browse by genre and then drill down as needed, each subgenre nested inside its parent genre, etc. It was only after I learned some php (which wasn’t until I was working on the search functionality) that I realized that each genre ‘link’ could have actually passed a search term to the server to retrieve all the same films with that genre. It would have saved me a tremendous amount of time because I was actually duplicating all hybrid genres. For example, if a movie were assigned ‘Action Thriller’ as a subgenre, that movie’s structure would contain:
<genreWrap> <genre>Action and Adventure</genre> <subGenre>Action Thrillers</subGenre> </genreWrap> <genreWrap> <genre>Thrillers</genre> <subGenre>Action Thrillers</subGenre> </genreWrap>
Notice that ‘Action Thriller’ has to appear twice because I couldn’t know if a user would browse through ‘Action and Adventure’ or through ‘Thrillers’ and I had to be sure that they’d find the same set of movies regardless. Some sub-subgenres were actually repeated three times, e.g. ‘Foreign Classic Dramas’. If I’d known how to use php when building the browse functionality, I would’ve written a simple line of code like:
$genreCheck = $xml->xpath("/mediaList/media[genreWrap[* = '$initialSearch']]");
So that when a user would click a genre (or sub-genre or sub-subgenre) it would retrieve all the films that had been assigned that term, regardless of its parent element. Therefore I wouldn’t have had to add all those reciprocal subgenres.
Conclusion
Emflix may be dead, for all intents and purposes, and though I have many regrets — I’m not sorry that I embarked on the project. I learned a tremendous amount about XSLT and its capabilities. I wrote my first lines of php, and more CSS than I ever had before. I’ve already been able to apply those skills to other projects. I’m not nearly ready to serve as a mentor to another eager cataloger, but I am equipped to provide advice and warnings. If I got wind of someone else jumping headlong into creation of an entirely new tool, I’d be there to tell them to slow down. Having been through the experience myself, I’d make sure they spoke to peers, consulted the literature, and brought others into the work. It’s on this reflection that I see these as the largest places I went astray, the many important steps I missed or neglected to explore. But most importantly, I know that I can avoid those mistakes in the future, because the most valuable thing I learned over the course of the Emflix project was that I had the ability to realize an idea. I imagined a ‘Netflix-style’ discovery interface for Emerson’s circulating media collection and, though imperfectly, I made one. [4] So on to the next–a little more slowly, and a lot more wisely.
Notes
[1]List drawn from here: http://libraryguides.lanecc.edu/c.php?g=391380&p=2658274
[2]http://dvd.netflix.com/AllGenresList
[3]For more on this method, see the brilliant Jeni Tennison, http://www.jenitennison.com/xslt/grouping/muenchian.html
[4]Full copy of site: http://netanelganin.com/projects/emflix/genrephp/index/index.php
About the Author
Netanel Ganin
Netanel is the kind of person who would make an authority record for his cat, and he did. He can be reached at NetGanin@gmail.com and can be found at @OpOnions.

Subscribe to comments: For this article | For all articles
Leave a Reply