by Haley Antell, Joe Corall, Virginia Dressler and Cara Gilgenbach
Introduction
Kent State University Libraries first implemented Omeka [1] for digital collections from the Special Collections and Archives department in November of 2015. At the time, the open source application replaced a homegrown solution for three growing digital collections from the department. Omeka was able to address all of the requirements of a desired platform for the library, namely, the ability to adapt to specialized, locally-defined vocabularies, allow for customization of both the outward facing user interface and the administrative side, and provide access to a growing variety of formats in the digital archive. After a number of customizations were made in-house by a library developer, including hooking up the ingest feature to offline storage, Omeka was implemented and provided a satisfactory solution for a small group of digital collections while also providing room for growth for future additions to the digital archive.
In September 2016, the library received a matching grant from the National Historical Publications and Records Commission to digitize a large amount of mixed archival content from the May 4 collection (roughly 72,550 pages from 32 subcollections). With the award of the grant, it quickly became apparent that some further customizations would be desirable in order to address the large number of textual items to be digitized for the grant, namely to address the nature of archival organization of folders containing multiple items with a single description point.
Archival collections are typically described through a document called a “finding aid.” Finding aids describe the content of an archival collection as a whole and often include more detailed description of the component parts of a collection. Like many archival repositories, the dominant level of description applied to most archival collections by Kent State Special Collections has been at the folder level rather than to the item or sub-item level. For example, the archive of a local business might include several folders containing correspondence, organized by date. Within a finding aid associated with this archive, this would be described at the folder level with a descriptive entry such as “Correspondence: July-December, 1934.” In digital projects undertaken by repositories, description of individual items, such as photographs or artifacts, is the most common approach. For example, a collection might contain 50 photographs, each of which might be scanned and described individually within the digital repository. However, for this grant project, we are providing description at the archival folder level, a decision which impacts ingestion and display. With the aid of the library developer, our team was able to make a number of updates to our Omeka instance to display the newly ingested archival text content, and the changes have also proven to be immensely time-saving features in terms of production.
Rationale/needs statement
When work began on the grant in the Fall of 2016, our team identified the areas that deviated from our previously used single item ingest workflow. The content to be digitized for the grant differed from previous digital collections in a number of ways, for example, this group of items was comprised of a number of largely text-based archival collections. Prior to the grant project, we had ingested only a few text-based items into our Omeka instance (which previously was mainly image and audio content), each of which was a self-contained publication rather than a folder of mixed archival content. For this project, our team decided to present the content a bit differently to enable engagement with the content that could be likened to the experience of a researcher visiting the reading room in Special Collections and Archives whereby a given box of archival materials would contain folders, which in turn would contain any number of documents and other items. This approach also addressed the reality that within a two-year grant project timeframe with the available staffing for the project, it would be impossible to describe every single item as a separate digital object with full metadata specifications applied to each. Essentially, this would be akin to describing the content of every single page of a 72,500 page book as a separate digital entity.
The Head of Special Collections and Archives, along with the Digital Projects Librarian, met with a library developer and discussed the desired workflow and interface options. At the time of this meeting, our group had anticipated that we would create the archival image files to be stored offline and load an OCR’d PDF as the access copy to reflect each folder within a box. The previous approach for textual content was to create a PDF in Adobe Acrobat and use the text recognition software included in the program, and through experimentation we found the Tesseract OCR to be of a much higher quality than using Adobe Acrobat to process the files. As well, our team discussed options to provide users with a different mechanism to view archival textual content through the digital repository than our previous site allowed, providing a more interactive method to view an archival folder of materials. With recommendations from the library developer, our team altered the approach to the workflow that would prove to streamline production, and also improve the overall quality of the OCR as a consequence. This change moved from a post-production workflow that relied on Adobe Acrobat’s OCR tool, ingesting an access level PDF file to the Omeka instance and retaining the high-res archival image files on a separate storage server to a newer, streamlined workflow that entails ingesting the raw image files directly to Omeka.
The last part of the workflow that our group discussed was the role of the finding aid in relation to the digital objects. The Special Collections and Archives finding aids [2] currently reside in a Drupal-based Web presence, while the digital items themselves reside in Omeka. Initially, our team anticipated that finding aids would be manually updated once the content was published, with the addition of direct links from the folder-level description to the individual digital items. The developer devised a way for the finding aids to be updated upon publication with item URLs being applied to each folder listed in the finding aid. They also added logic to overcome any hurdles of similarly named folders, and the result is a huge time savings in the production and workflow of the project, essentially replacing a manual process with an automatic process.
Enhancements/extensions of Omeka
Mirador
When visitors to the Omeka site view an item, we wanted the view to reflect the physical organization of archival materials within their corresponding physical folders. Omeka’s built-in model of a single item containing multiple files provided the necessary software architecture to create the physical archival folders in our system. In order to digitally represent the physical archival folder, we needed to show one or more images associated with an item in a single, unified image viewer. After evaluating some possible image viewers, our team decided to integrate the Mirador IIIF Image Viewer [3] into our Omeka instance. Adding an IIIF Image Viewer to our technology stack implicitly meant an IIIF Image server was required, too; for that we chose the Loris IIIF Image Server [4] . Finally, we integrated Omeka, Mirador, and Loris to tie all the pieces together. Omeka’s plugin system made this possible by way of their Model-View-Controller Pattern [5] . Using this software pattern we created an endpoint (controller) in Omeka that generates IIIF manifests [6] for items. This manifest endpoint is used by the Mirador Viewer frontend to receive the metadata for the item it is rendering images for. The viewer is added to Omeka using the add_file_display_callback [7] function. Implementing those two plugins completed the integration, and Mirador was fully integrated into our Omeka instance. Other institutions interested in adding this piece of technology stack to their Omeka site can find instructions for installing the required software and the code described here in the Omeka Mirador Plugin [8] .
The Mirador IIIF Image Viewer allows the user to scroll through the contents of an archival folder, while displaying the metadata record for each folder below. The viewer includes zoom and rotation features, and provides users with several options for viewing images: book view, gallery view, image view, and scroll view. Each of these choices shows the image in the context of the other image thumbnails in the Omeka item. In other words, users are unable to view a single image without seeing the other related images that make up the folder. Because our metadata records are created at the folder level, it is imperative that the image viewer unmistakably represents a given image’s connection to the others in its folder. The Mirador IIIF Image Viewer accomplishes this goal.

Figure 1. Sample view of the contents of an archival folder using Mirador
Leaflets, memos, and statements from Black United Students and Students for a Democratic Society regarding the Oakland Police protest and the Black Student Walkout at Kent State University in 1968, http://omeka.library.kent.edu/special-collections/items/show/3133
OCR/PDF Creation
In addition to the display of images using the Mirador viewer, we wanted to allow users to easily download all of the images they are viewing from a particular item. To accomplish this goal, we chose to aggregate the images into a single, searchable PDF file. To automate the process, the server running our Omeka instance required two pieces of server-side software: Ghostscript to create a single PDF from multiple TIFFs, and Tesseract to create the OCR from the TIFF images. Ghostscript was an easy install on our operating system (Red Hat Enterprise Linux 7) with the “yum” package manager. Tesseract, and its dependencies, needed to be installed from source. The exact versions currently running in production for all the required software can be found under the “Install” section in our plugin’s README file [9] .
Once the server-side software was installed, a mechanism was needed to trigger when the PDF generation should occur. The Omeka plugin system provides a method to execute code when an item or file is edited or published. This allowed the two tasks, the OCR processing and PDF creation, to occur as separate steps. The OCR generation is performed when a TIFF file is first ingested into Omeka. The OCR generation creates a one page OCR’d PDF and a text file containing only the OCR for the TIFF. The PDF file representing the TIFF file(s) is created, so when it comes time to aggregate all the TIFFs into a single PDF, most of the work is already done. The text file is used to insert the OCR into the Omeka database to provide full searching on the extracted text.
Once the item is published in Omeka, all of the individual PDF files created for the item images are aggregated into a single PDF/A-1b file. The aggregated PDF file is created by a call to Ghostscript. An override in our Omeka item view adds a link to the PDF/a-1b file on the interface.
Previously, library staff created PDFs and performed OCR on the PDFs using Adobe Acrobat Pro. This required staff to select the correct files to combine into PDF format, the process of which could take several minutes depending on the size and number of image files. After saving the combined files as a single PDF using the correct file naming convention, staff ran the OCR conversion through Acrobat Pro (a process which could also take several minutes or more depending on the size and number of files), and saved the output as a separate PDF file. These processes required over ten steps and additional processing time to complete, and the automation of these processes via the programming described above, significantly shortens the digitization workflow from our initially conceived plan of work. Essentially, the new workflow removes the steps involved in separately uploading the high res archival image files to a separate storage location and automates both the OCR and PDF processes.
Additionally, the files within each Omeka item are arranged in a specific order, usually chronologically. They are scanned and uploaded according to this order, and it is imperative that the PDF reflects this. In the past, when staff created the PDFs, the software would sometimes auto-rotate the images incorrectly, or change the order of the files. These problems have been eliminated thus far through the automation process. The possibility of incorrectly naming the PDF files is also removed. Both the reduction in time and decreased chance for human error have a sizeable impact on the time requirement to complete the digitization of each subcollection for the grant project, making goals and deadlines easier to meet.
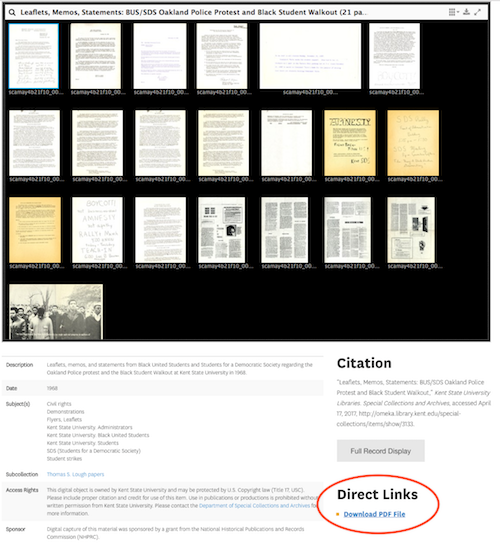
Figure 2. Sample view ‘Direct Link’ PDF file
Leaflets, memos, and statements from Black United Students and Students for a Democratic Society regarding the Oakland Police protest and the Black Student Walkout at Kent State University in 1968, http://omeka.library.kent.edu/special-collections/items/show/3133
Finding Aid Auto-Link
All of the Special Collections and Archives finding aids are housed in University Libraries’ Drupal site. When an item is digitized and published in Omeka a link to the item is added to the item’s title in the respective finding aid. Previously, when a new item was added to Omeka, that prompted a manual process for Special Collections staff to find the description of that item in the corresponding finding aid, and create a link to the item in Omeka. Since our staff was adding the finding aid URL to the Omeka item, automating the process was extremely beneficial to implement into the workflow.
The technical requirements for automating this linking consisted of two components: (1) a trigger on Omeka’s end to send metadata about the individual Omeka item to an endpoint on our public site, and (2) an endpoint on the public site that could ingest that information, and update the finding aid accordingly. To fulfill both of these needs custom code was added to both environments (Omeka and Drupal) using the respective plugin and hook architecture. The Omeka plugin sends an HTTP request to Drupal whenever an item is published. This process is triggered using Omeka’s after_save_item [10] hook. The request includes some metadata about the item being saved: its internal ID, title, date, and the URL of the finding aid.
The Drupal module awaits this request from Omeka using a custom menu callback, which creates the endpoint. When the endpoint is accessed with the required metadata, an attempt is made to update the related finding aid. Since the finding aid URL is provided, a query can be done in Drupal to find which finding aid needs to be updated. Once the finding aid is located, a search is performed on the finding aid’s HTML for a unique instance of the Omeka item’s title concatenated with the date. If a unique instance is found, the string in the finding aid is updated to link to the Omeka item. If that string was not found, the same search/update is performed with only the item’s title. For security reasons, the Drupal endpoint is locked down to only allow requests from the IP address of our Omeka server. Additionally, a secret key is required in the HTTP request using Drupal’s key contrib module [11]. The Omeka plugin and Drupal module are both available on GitHub [12] in case others have a similar environment, and would like to add this feature to their technology stack.
In the case of a future migration from Omeka to another system, the URLs in our Drupal finding aids would need to be updated. To help keep our links persistent, we use Drupal’s linkchecker module [13] to automatically update any HTML links that return a 301 HTTP response to update to their new location. With this functionality in place on the Drupal end, we would then just need to return a 301 code on the Omeka end for each item to ensure our links persist.
Similar to the automated PDF creation, the automatic link between the Omeka item and the finding aid saves staff a significant amount of time. Many of the finding aids contain dozens of items or more, so manually creating links between the finding aid and the Omeka items would add a great deal of time to the digitization workflow. Instead, the automation of the links means that staff needs only to spot check links, and ensure that the target of links is correct. Occasionally, the logic to create the links will fail, so it is necessary to check each subcollection upon completion to ensure the links are created and point to the correct item.
Conclusion
The NHPRC grant project being implemented at Kent State Special Collections, like most grant projects, includes a pre-defined group of materials and scope of work as well as clear benchmarks for progress such as the total number of items and collections to be digitized within a set timeframe. Unlike other digital projects previously completed at our institution, this project has pushed our team to a new level of digital production, and has the added complexity of taking a “file or folder” approach to digital object description, in line with how many archivists described materials in these physical collections. These elevated parameters forced us to take a creative approach to solving the problems of public display of multi-file “items” in Omeka as well as searching for ways to make our workflow more efficient. The key to our ability to implement changes that would address these challenges was having a team that was comprised not only of archivists and a digital librarian with deep experience with physical archival collections, but also a developer who has been able to leverage the flexibility and extensibility of Omeka by integrating additional open-source software into our system. All of the Omeka plugins and the Drupal module are running in our production environment, so they should work out of the box for any institution that can install and configure the necessary open-source software (Omeka, Drupal, an IIIF server, Tesseract, Ghostscript). All of the code provided on GitHub will continue to be maintained as Omeka 2 and Drupal 7 updates are released to ensure compatiblity with the latest versions of the respective software by a Kent State library developer. While some of the work entailed in our project was funded in part with the NHPRC grant, our institution will maintain a commitment to the longevity of the project at large through a permanent library developer position.
References
[1] Omeka [Internet]. [updated 2017 Jan 30]. Fairfax (VA): George Mason University, Omeka.org; [cited 2017 Apr 14] Available from http://omeka.org/
[2] Special Collections and Archives Finding Aids [Internet]. [updated 2017]. Kent (OH): University Libraries, Kent State University; [cited 2017 Apr 14] Available from http://www.library.kent.edu/special-collections-and-archives/browse-collections
[3] Mirador IIIF Image Viewer [Internet]. [updated 2017 Apr 13]. Project Mirador.org; [cited 2017 Apr 14] Available from http://projectmirador.org
[4] Loris IIIF Image Server [Internet]. [updated 2017 Apr 3]. GitHub, Inc.; [cited 2017 Apr 14] Available from https://github.com/loris-imageserver/loris
[5] Omeka MVC Pattern [Internet]. [updated 2011 Oct 10]. Fairfax (VA): George Mason University; [cited 2017 Apr 14] Available from https://omeka.org/codex/MVC_Pattern_and_URL_Paths_in_Omeka
[6] IIIF Presentation API Manifest Specification [Internet]. [updated 2017]. International Image Interoperability Framework; [cited 2017 Apr 14] Available from http://iiif.io/api/presentation/2.0/#manifest
[7] Omeka ‘add_file_display_callback’ Documentation [Internet]. [updated 2014 Jun 25]. Fairfax (VA): George Mason University, Omeka.org; [cited 2017 Apr 14] Available from http://omeka.readthedocs.io/en/latest/Reference/libraries/globals/add_file_display_callback.html
[8] Mirador Omeka Plugin [Internet]. [updated 2017 Mar 2]. Kent State University Libraries, GitHub. Inc.; [cited 2017 Apr 14] Available from https://github.com/kent-state-university-libraries/Mirador
[9] PDFCreate Omeka Plugin [Internet]. [updated 2007 Feb 27]. Kent State University Libraries, GitHub. Inc.; [cited 2017 Apr 14] Available from https://github.com/kent-state-university-libraries/PDFCreate
[10] Omeka ‘after_save_item’ Documentation [Internet]. [updated 2013 Jan 28]. Fairfax (VA): George Mason University, Omeka.org; [cited 2017 Apr 14] Available from http://omeka.readthedocs.io/en/latest/Reference/hooks/after_save_%3Cmodel%3E.html
[11] Drupal Key Contrib Module [Internet]. [updated 2017 Feb 22]. Drupal.org; [cited 2017 Apr 14] Available from https://www.drupal.org/project/key
[12] Finding Aid Auto-Link [Internet]. [updated 2017 Feb 16]. Kent (OH): Kent State University Libraries, GitHub, Inc.; [cited 2017 Apr 14] Available from https://github.com/kent-state-university-libraries/finding-aids-auto-link
[13] Drupal Linkchecker Module [Internet]. [updated 2017 Apr 26] Drupal.org; [cited 2017 Jun 1] Available from https://www.drupal.org/project/linkchecker
About the Authors
Haley Antell (http://www.library.kent.edu/profiles/hantell) is the Digital Project Archivist at Kent State University Special Collections and Archives. She manages a project, funded by a grant from the National Historical Publications and Records Commission (NHPRC), to digitize a large portion of the May 4 Collection.
Joe Corall (http://www.library.kent.edu/profiles/jcorall) is a Senior Applications Developer at Kent State University Libraries. He primarily works on the library’s Drupal and Omeka systems.
Virginia Dressler (http://www.library.kent.edu/profiles/vdressle) is the Digital Projects Librarian at Kent State University Libraries. She holds a Master in Library and Information Science from Kent State University and a Master in Art Gallery and Museum Studies from the University of Leeds, and has over ten years experience managing digital initiatives within the library and museum settings.
Cara Gilgenbach (http://www.library.kent.edu/profiles/cgilgenb) is Head of Special Collections and Archives at the Kent State University Libraries and has worked with the May 4 Collection for over twenty years.

Subscribe to comments: For this article | For all articles
Leave a Reply