By Gioia Stevens
Introduction
The Early American Cookbooks project is a case study in analyzing digital special collections as data by using new tools to explore trends and patterns in the metadata and the full text of a collection. The project is a useful example for librarians, technologists and researchers interested in exploring the wealth of data in the public domain corpus of HathiTrust and the computational tools available in the HathiTrust Research Center (HTRC) Portal. It is also a useful example of how analyze and visualize sets of legacy MARC catalog records and offer users new insights into the depth and breadth of library collections.
The project workflow described in this article includes: (1) creating a searchable public collection of full-text titles within the HathiTrust Digital Library and uploading it to the HTRC Portal, (2) analyzing and visualizing legacy MARC data for the collection using MarcEdit, OpenRefine and Tableau, and (3) using the text analysis tools in the HTRC Portal to look for trends and patterns in the full text of the collection.
Building a collection within HathiTrust is a way to create a searchable digital collection for a topic of particular research interest or a specialized subject area with few digital resources (such as early American cookbooks). It can also be used to create a digital collection to mirror the print holdings available in a particular library. The full text of collections is keyword searchable independently of the full HathiTrust library and basic metadata for search results can be downloaded to create new subgroups of titles.
Analyzing collections as data reveals valuable new uses for old catalog records. However, working with legacy MARC records from many different libraries over time presents complex challenges. This project developed a workflow using MarcEdit, OpenRefine and Tableau to transform, clean, and visualize MARC records. When this legacy data is cleaned up and presented as a dataset rather than as individual records, it can yield new information about a collection in aggregate. Metadata about authors, publishers, places of publication, dates, and subject content can offer insights into a collection and its significance within a broader historical scope. This information can be visualized and presented to users as a new way to gain understanding of the depth and breadth of a collection.
The HTRC Portal offers a convenient platform for importing a HathiTrust collection and then analyzing that collection using text analysis algorithms. These algorithms are built into the HTRC Portal as ready-made tools that can be run on a collection within the portal. No coding skills are required and the portal is a useful way to begin experimenting with computational methods. Topic modeling using the Meandre Topic Modeling algorithm is “a method for finding and tracing clusters of words (called “topics” in shorthand) in large bodies of texts.” [1] These topics show trends and patterns in the contents of a collection and can serve as an overview of its thematic content. Comparing two sets of text using the Meandre Dunning Log-likelihood to Tag Cloud algorithm is a useful way to trace differences in subject matter by sorting the under-represented terms and over-represented terms in each set. These results can be used to highlight how a particular subgroup of titles differs from the collection as a whole.
Early American Cookbooks Project Overview
The idea for this project grew out of cataloging hundreds of early print cookbooks for the Marion Nestle Food Studies Collection at the Fales Library & Special Collections at New York University Libraries. Most early cookbooks in printed form are accessible only in special collections libraries or private collections. These books are an incredibly important resource for food historians or anyone with a passion for old cookbooks, but there are very few searchable full text resources available online. The Feeding America Digital Archive created by Michigan State University Libraries is the largest digital collection, but it contains only seventy-six full-text titles.
The Early American Cookbooks project was designed to meet this need. The purposes of the project are to create a freely available, searchable online collection of early American cookbooks, to offer an overview of the scope and contents of the collection, and to analyze trends and patterns in the metadata and the full text of the collection. The project has two basic components: a collection of full-text titles within the HathiTrust Digital Library and a website to present a guide to the collection and the results of the analysis.
Early American Cookbooks Collection
The Early American Cookbooks collection is a separate public collection within the HathiTrust Digital Library which was created specifically for this project. It contains 1450 full text cookbooks published in the United States between 1800 and 1920. Users can browse the titles, read them online, and search the contents of each book. The collection as a whole can be searched independently of the rest of the HathiTrust. Keyword searching across all 1450 titles allows the user to find particular recipes, ingredient names, or anything else and go immediately to the results in the full text. This type of search would be very valuable for a food historian tracing something such as the history of the hamburger or when Americans first started eating spaghetti.
Early American Cookbooks website
The Early American Cookbooks website serves as a gateway and guide to the collection. The site gives a general introduction to the history of American cookbooks, an overview of the scope and contents of the collection, a discussion of certain interesting books or groups of titles within the collection, and links to other online resources and library collections specializing in early American cookbooks. The site presents and interprets the results of explorations in the metadata and the full text of the collection. Data visualization of the results shows trends and patterns in the collection that may add to our understanding of early cookbooks and the history of American food.
Building the Collection on HathiTrust and Uploading Worksets to HTRC
Workflow overview:
- Create public or private collection in HathiTrust from full-text search results
- Evaluate search results and edit collection contents
- Check and de-dupe individual records (multiple printings, editions, and scans)
- Download basic collection metadata and upload volume ID numbers to create a workset in HTRC
HathiTrust collections are a way to group and save a selection of titles for public or private use. Collections are searchable independently of the full HathiTrust library and are a convenient way to assemble and research a subgroup of HathiTrust materials. Collections may be created by any member of a HathiTrust partner institution or by anyone who chooses to sign up for a University of Michigan “Friend Account” login. Some examples of recent public collections include the English Short Title Catalog, Islamic Manuscripts at the University of Michigan, Patent Indexes, and Action and Adventure Fiction.
Items can be added to a collection from the full-text search results (not the catalog search results) or from the page-turner interface when looking at an individual full-text title. Members of HathiTrust partner institutions also have the option to limit the full text search results to titles held at their own libraries. This feature could be useful for a library wishing to create a digital collection to mirror specific print titles in their holdings.
Creating a collection involves evaluating and manually de-duplicating the record set. Using precise search terms and carefully evaluating the results are important to avoid adding irrelevant titles to a collection (such as books on Captain Cook or Cook County, Illinois, in a collection of cookbooks). Search results frequently contain duplicate records from different libraries and many records offer multiple scans from different libraries. It can be quite complex to compare many similar records and determine which are duplicates and which represent different editions or printings of a book. For the Early American Cookbooks collection, evaluating the initial search results and distinguishing and de-duping multiple printings, editions, and scans reduced the collection from over 2000 records to a final set of 1450.
The next step is to download the metadata for the collection. This metadata is includes the following items in a tab-delimited text file:
- htitem_id – the HathiTrust item identifier which is used to uniquely identify every HathiTrust digital item
- title
- author
- date rights – the copyright status for this item as determined by HathiTrust
- a series of identifiers commonly used by libraries: OCLC, LCCN, ISBN
- catalog_url – the url for the catalog record with which the item in question is associated
- handle_url – the permanent url for the HathiTrust digital item
The full MARC records for the collection are available from the HTRC, the research arm of HathiTrust. The HTRC Portal “provides an infrastructure to search, collect, analyze, and visualize the full text of nearly 3 million public domain works and is intended for nonprofit and educational researchers.” [2] Anyone possessing an email address from a nonprofit institution of higher education is allowed to register for a user account, including those whose institutions are not HathiTrust members. The htitem_id identifiers (also called volume ID numbers) downloaded from the HathiTrust collection can be uploaded to the HTRC Portal to create a new workset. The HTRC Portal also provides a Workset Builder tool for users who do not have a collection within HathiTrust and wish to create and analyze a workset within the portal.
Figure 1. HathiTrust Research Center home page.
Analyzing Collection Metadata with MarcEdit, OpenRefine and Tableau
Workflow overview:
- Download records in MARCXML format using HTRC Marc Downloader tool
- Convert MARCXML to MARC21 and join records into one file using MarcEdit
- Export master metadata spreadsheet as csv file using MarcEdit
- Clean up metadata using OpenRefine
- Create topical subsets of records using OpenRefine
- Upload csv files to Tableau to explore data
- Produce visualizations in Tableau
It is important to note that this workflow could be done with any set of MARC records, whether downloaded from HathiTrust or from another source. For HathiTrust records, the HTRC Portal offers the Marc Downloader tool to provide individual catalog records in MARCXML format.
Legacy MARC data for early books held in special collections presents particular challenges. For many 19th century books, such as the ones in the Early American Cookbooks collection, these records are idiosyncratic, legacy data, much of it drawn from old catalog cards. Many of these records contain archaic information such as “Brooklyn, opposite New York” rather than “Brooklyn, N.Y.” as the place of publication. These records also contain many different forms of abbreviation, punctuation, and terminology, resulting from different cataloging standards over time and also the local practices at individual libraries. Cleaning and standardizing this legacy data is an essential step in analyzing special collections metadata as a dataset rather than as individual records.
MarcEdit Workflow
MarcEdit is an open source GUI-based application for editing and manipulating MARC data. It was developed by Terry Reese beginning in 1999 and has become “one of the more complete metadata edit suites available to librarians.” [3] This workflow uses three different utilities in MarcEdit which are all available in the same Utilities Dialog Window. The first step in the workflow is to convert the individual MARCXML records from HathiTrust to MARC records using the Batch Process MARC Records Utility. The next step is to join the individual records into one record using MARCJoin. The final step is to create a master spreadsheet for the metadata using the Export Tab Delimited Records Utility. This utility will export selected MARC fields and subfields in .csv format.
Figure 2. MarcEdit’s Utilities Dialog window showing the Batch Process MARC Records Utility
OpenRefine Workflow
The next step is to upload the master metadata spreadsheet into OpenRefine. OpenRefine, described as a “power tool for working with messy metadata” [4] is a very useful open source program for working with legacy MARC records. The program functions to explore data, clean and transform data, and reconcile and match data. For example, it was easy to find all the different forms of an author’s name (example: Fanny Farmer, Fannie Farmer, Fannie Merritt Farmer), group them together and use one transformation to change all of them to the authorized version. Dates and many different ways of recording dates (example: 1882, [1882], [1882?], ©1882) posed particular challenges. OpenRefine made it possible to group and reconcile these dates and then transform the data from number format into date format. The screenshot below shows the original date in the 260$c column and the transformed date in the Edited date column. This date cleanup work was necessary to be able to sort the titles by date and then visualize the collection metadata along a timeline.
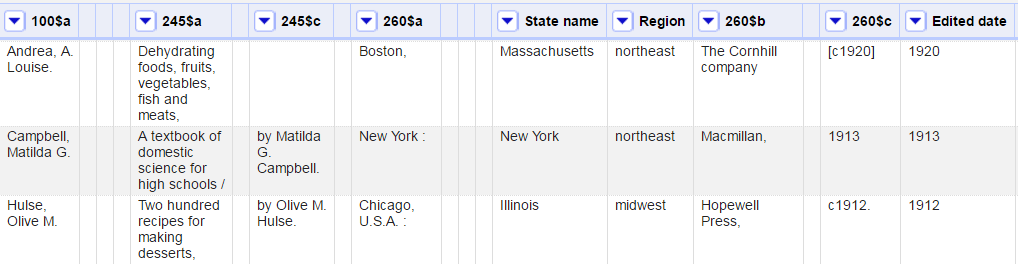
Figure 3. Collection data in OpenRefine
OpenRefine is also useful for the creation of additional metadata and sorting records into subgroups. This process was useful for preparing the data for visualization in Tableau and also for creating topical subsets of titles (examples: all books by a particular author, Southern cookbooks). In the screenshot above, the State name column was created based on the place of publication in the 260$a field. This involved grouping and transforming numerous different forms of state abbreviations (example: Mass., MA, M.A.). It was also necessary to add the state when only the city name appeared in 260$a. Sometimes this was obvious (example: Boston) and sometimes it required more examination of the MARC record or the full text of the book (example: Springfield). The full state name, rather than an abbreviation, proved to be an essential piece of metadata for creating map visualizations in Tableau. The Region column was created based off of the state name and the United States census regions. Dividing the collection into different worksets for the Northeast, Midwest, West, and Southeast regions allowed for regional map visualizations and text analysis explorations to look for regional variations in recipes.
Tableau Visualizations
The next step in the workflow is to upload the metadata spreadsheet into Tableau, a data visualization software program which is available in both licensed versions and in a free online version called Tableau Public. Tableau offers “drag and drop visual analytics” [5] designed for users without prior experience in data analysis. Using Tableau to experiment with graphing metadata is an interesting way to explore a collection and think about MARC records in aggregate as a dataset. Tableau offers a wide range of visualizations and there are numerous different ways to display information, such as the number of titles per author, publisher, state, or year.
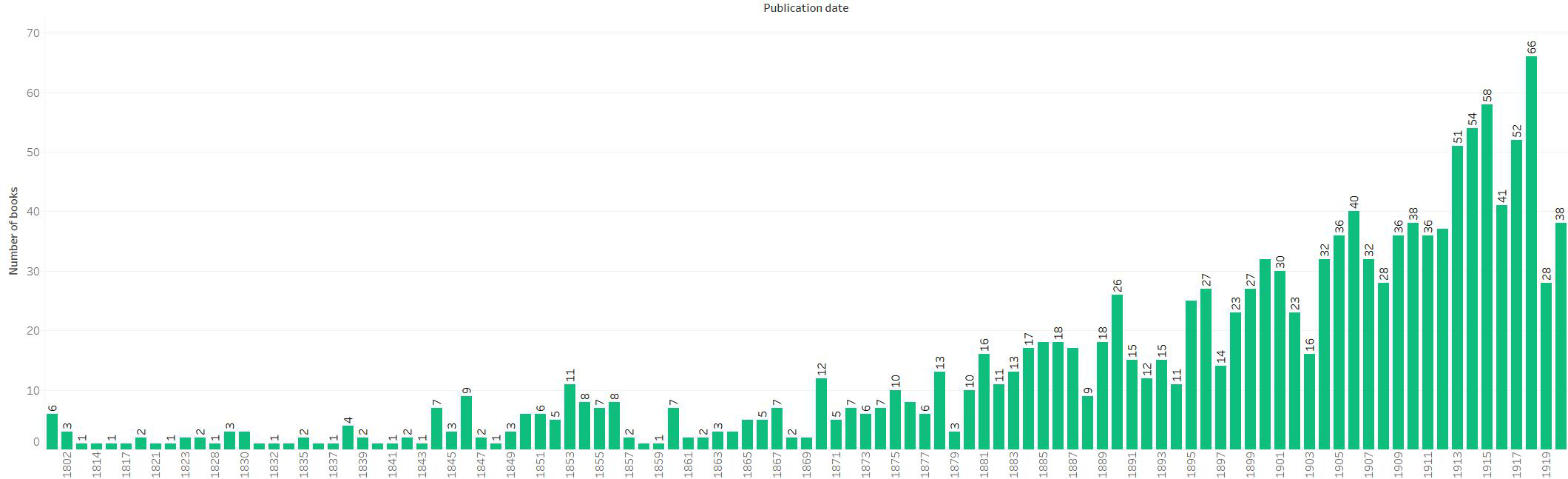
Figure 4. Number of cookbooks in collection published each year (1800-1920)
The Tableau bar chart in Figure 4 shows the number of books published each year for the full collection of 1450 books. Creating this chart required cleaning and transforming the dates in the 260$c field in OpenRefine prior to loading the spreadsheet into Tableau. The chart gives a useful overview of the collection because it shows that the number of cookbooks published per year grew steadily during the 19th century and bounded upwards in the early 20th century. In the early 19th century, most families used collections of handwritten recipes, often handed down through generations and shared with neighbors and friends. The publishing industry in the United States expanded rapidly during the late 19th century and commercially produced cookbooks became widely available.
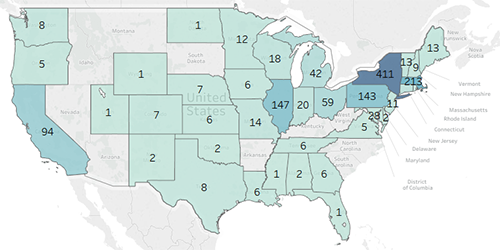
Figure 5. Number of cookbooks in collection published per state
The Tableau map in Figure 5 shows the number of books published per state for the full collection of 1450 cookbooks. The map is a filled map with the darker shades of color representing the states with the greatest numbers. Tableau has a user-friendly mapping function and is able to plot latitude and longitude coordinates based on certain common sets of geographic identifiers such as countries, states, and zip codes. This automated feature is helpful because it eliminates the need to geocode data in order to create a map. Adding a column with full state names to the spreadsheet in OpenRefine made it possible to create a basic map in Tableau without any prior experience in visualizing geographic data.
This map visualization of the metadata is useful because it shows how the collection reflects the history of cookbook publishing in the United States. New York has the greatest number of books published, followed by Massachusetts, Illinois, Pennsylvania, and California. These numbers align with the growth of the book publishing industry in the United States. New York City, traditionally the publishing center of the United States, published the greatest number over time, followed by other publishing centers in Boston, Philadelphia, Chicago, San Francisco, and Los Angeles. The trend in the numbers also shows the history of westward expansion from 1800 to 1920, with the greatest total numbers in the East and much lower numbers in the West.
Analyzing Full Text Using HTRC Portal Tools
Workflow overview:
- Search selected terms as keywords in full text and download metadata for results
- Upload new worksets in HTRC for these keyword search sets
- Upload new worksets in HTRC for topical subgroups of titles created using OpenRefine
- Run HTRC algorithm on selected worksets
- Evaluate results, look for errors in data, and re-run as needed
- Export results from HTRC
This workflow moves beyond analyzing metadata to look at the full text of the books as a corpus. Analyzing the full text can be done using the full collection of titles or it can be done by creating subsets of titles and uploading them as separate worksets in HTRC. OpenRefine can be used to create subgroups based on the metadata (examples: all books by a particular author, Southern cookbooks) and then the HathiTrust volume ID numbers can be uploaded to create worksets for each of these subgroups. Another way to create a subgroup is to use the full text keyword search feature on the collection in the public facing HathiTrust Digital Library to look for works containing a particular term. The basic metadata with the volume ID numbers for titles in the search results can be downloaded and then uploaded to HTRC as a new workset.
Metadata analysis of the worksets created by keyword search can offer another window into the contents of the collection. The timeline below was created by searching for the word “vegetarian” in the collection and then visualizing the number of titles per year in Tableau. The number of books which contain the word “vegetarian” in the text is near zero until 1850, increases slowly in the late 19th century, and then grows substantially in the years from 1900 to 1920. The American Vegetarian Society was founded in New York in 1850 and the vegetarian movement in the United States grew over the same time span. [6]
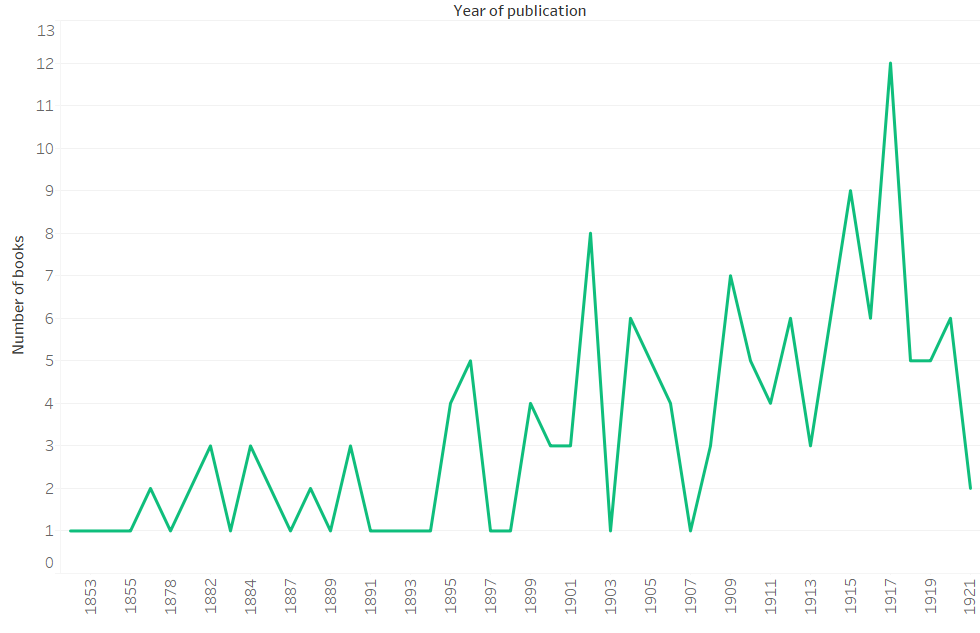
Figure 6. “Vegetarian” keyword over time (1850 to 1920)
HTRC Algorithms
The HTRC also offers an array of text analysis tools to explore trends and patterns in the full text of a collection. The algorithms offer a range of functions as described in the documentation. [7]
- Meandre Classification Naive Bayes: Classify the volumes in a workset into categories of your choosing
- Meandre Dunning Log-likelihood to Tag Cloud: Compare and contrast two worksets by identifying words that are more and less common in one workset
- Meandre OpenNLP Date Entities To Simile: Visualize the dates in a workset on a timeline
- Meandre OpenNLP Entities List: Generate a list of people and places in a workset
- Meandre Spellcheck Report Per Volume: Find misspelled words that are the result of OCR errors
- Meandre Tag Cloud: Create a tag cloud visualization of the most frequently occurring words
- Meandre Tag Cloud with Cleaning: Performs cleaning of the text before it allows you to create a tag cloud visualization of the most frequently occurring words
- Meandre Topic Modeling: Identify “topics” in a workset based on words that have a high probability of occurring close together in the text
- Simple Deployable Word Count: Identify the words that occur most often in a workset and the number of times they occur
All of these are built into the HTRC portal as ready-made tools that can be run on a workset within the portal. No coding skills are required and the portal serves as a single platform for managing worksets, analyzing them, and exporting the results. The HTRC algorithms that proved most fruitful for the Early American Cookbooks project were the Meandre Topic Modeling algorithm and the Meandre Dunning Log-likelihood to Tag Cloud algorithm.
Meandre Topic Modeling Algorithm
Topic modeling is an automated text mining technique that offers a “suite of algorithms to discover hidden thematic structure in large collections of texts.” [8] Topic modeling is a methodology developed in computer science, machine learning, and natural language processing that has recently become very popular in the digital humanities and related fields. [9] Tools such as MALLET [10] generate “topics” or groups of related words through statistical analysis of word occurrences in a corpus. The Meandre Topic Modeling algorithm in the HTRC Portal (created by Loretta Auvil at the University of Illinois) creates a topic model using Mallet and displays the top 200 tokens in a tag cloud as well as exporting the topics in an XML file.
The Meandre Topic Modeling algorithm shows some interesting trends and patterns in the text for the Early American Cookbooks collection. The selected tag clouds below show different topics or clusters of words that recur across all of the texts. The names of the topics were not generated by the algorithm, but rather devised by the researcher as a way to label and interpret the clusters. While it is impossible to draw definitive analytical conclusions, the topics do provide an interesting snapshot of the subject matter. Early American cookbooks had many common themes, largely because the diet and cookery techniques in the 1800 to 1920 period were far more homogeneous than they are today. Nearly every cook used salt, pepper, and butter as the primary methods of seasoning (Figure 7), prepared meat most frequently with gravy or sauce (Figure 8), and baked cake (Figure 9). The “Food and family” tag cloud (Figure 10) reaches beyond the ingredients and instructions into the how and why of cooking and homemaking. Words such as food, time, good, made, great, people, work, body, give, family and years are commonly present in the forewords and introductions to cookbooks which sought to provide inspiration for readers.

Figure 7. Seasoning tag cloud

Figure 8. Meat tag cloud

Figure 9. Cake tag cloud

Figure 10. Food and family tag cloud
Meandre Dunning Log-likelihood to Tagcloud Algorithm
The Meandre Dunning Log-likelihood to Tagcloud Algorithm was useful for comparing and contrasting two worksets. The Dunning Log-likelihood statistic was developed by Ted Dunning at the University of New Mexico. It employs a statistical measure based on likelihood ratios that can be applied to the analysis of text. [11] The statistic has been employed by digital humanities researchers as a way to compare corpuses of text and discover “subtle differences between closely related sets.” [12] The Meandre Dunning Log-likelihood to Tagcloud algorithm (also created by Loretta Auvil) calculates Dunning Log-likelihood based on two worksets provided as inputs: an “analysis workset” and a “reference workset.” The “overused” words and the “underused” words in the analysis workset (relative to the reference workset) are displayed in a tag cloud and made available via a csv file.
This tool has been very useful in analyzing different subsets of the Early American Cookbooks collection. One example shows how the content of books by Fannie Merritt Farmer (1857-1915) differs from the collection as a whole. Farmer was a major figure in American cooking in the late 19th and early 20th centuries. Her most successful cookbook, The Boston Cooking-School Cook Book, was first published in 1896 and sold millions of copies in many subsequent printings and editions. The book was the first to introduce precise measurement and Farmer later became known as “the mother of level measurements.” [13] The Dunning Log-likelihood to Tagcloud algorithm results clearly illustrate her emphasis on precise measurement. In the tag clouds below, the over-represented terms (Figure 11) are the more precise terms tablespoons, teaspoons, and cup. The under-represented terms (Figure 12) are the more vague terms teaspoonful, tablespoonful and cupful which were frequently used in cookbooks of the era.

Figure 11. Fannie Farmer over represented terms

Figure 12. Fannie Farmer under represented terms
Challenges and Solutions
This project encountered several problems in the course of its development. The HTRC Portal algorithms sometimes failed to work or created poor results. Tracing the cause of these problems meant questioning the validity of upload data, the suitability of the tool, and/or the composition of the dataset. Sometimes the answer was simple, such as when an algorithm repeatedly failed to process a workset because a library call number had been substituted for a HathiTrust volume ID number in the upload metadata. Other problems seemed to stem from a mismatch between the chosen algorithm and the dataset. For example, the OpenNLP Entities algorithm is designed to generate lists of people and place names, but the results included terms such as “Brown Sauce” and “Butter Taffy” as if these were names of individuals.
More complex problems involved the composition of the dataset and how decisions made in subdividing the data had influenced the results. For example, the word “feces” was a valuable clue in interpreting and correcting a problem with one of the datasets. The word first appeared in a Meandre Dunning Log-likelihood tag cloud of over-represented terms for books published in the Southern census region of the United States. It seemed hard to believe that cookbooks on Southern cuisine featured feces, so a re-examination of the dataset was in order. Washington, D.C. is part of the Southern census region, but it is also the place of publication for large numbers of government documents. Separating out the books published by government agencies from the larger Southern set proved to be the answer to the problem. Running the Meandre Dunning Log-likelihood algorithm and the Meandre Topic Modeling algorithm on the government documents alone (see Figure 13 below) showed that these cooking publications were concerned with scientific approaches to human nutrition. Feces along with other terms describing digestion were prominent in this dataset. Rerunning the algorithms on the set of Southern books without the government publications created results that did not contain the word feces and that were more consistent with the subject matter of the titles in the set.

Figure 13. Government documents over represented terms
Conclusion
The Early American Cookbooks project workflows may prove useful for librarians, technologists and researchers interested in exploring small scale approaches to digital special collections and digital humanities methods. Institutions with limited budgets and staff time may not have resources to devote to large digital projects. The Early American Cookbooks project was planned and completed by one person working several hours per week over the course of six months. There was no need to find funding for the project because access to the HathiTrust Digital Library, the HTRC Portal, and all of the tools discussed in this article are available at no cost. The tools and the workflows can be adapted to suit many different types of projects, including those not using HathiTrust. For example, visualizing sets of MARC records offers a useful overview of any library collection. The workflow using MarcEdit, OpenRefine, and Tableau could be used to visualize all of a library’s holdings or to highlight the contents of a particular collection. Visualizing catalog records in aggregate can offer users a valuable new way to understand the depth and breadth of a collection.
References
[1.] Posner M. Very basic strategies for interpreting results from the Topic Modeling Tool. Miriam Posner’s Blog. 2012. [Internet]. [cited 2017 May 15].
Available from: http://miriamposner.com/blog/very-basic-strategies-for-interpreting-results-from-the-topic-modeling-tool/
[2.] HTRC Home. HathiTrust Research Center. [Internet]. [cited 2017 May 15]. Available from: https://analytics.hathitrust.org/
[3.] Reese T. About MarcEdit. MarcEdit Development. 2013. [Internet]. [cited 2017 May 15]. Available from: http://marcedit.reeset.net/about-marcedit
[4.] OpenRefine. [Internet]. [accessed 2017 May 15]. Available from: http://openrefine.org/
[5.] Tableau for Teaching. Tableau Software. [Internet]. [cited 2017 May 15]. Available from: https://www.tableau.com/academic/teaching
[6.] Shprintzen AD. The vegetarian crusade: the rise of an American reform movement, 1817-1921. Chapel Hill: University of North Carolina Press, 2013.
[7.] Description of the HTRC Portal Algorithms – Documentation – HTRC Docs. [Internet]. [accessed 2017 May 15]. Available from: https://wiki.htrc.illinois.edu/display/COM/Description+of+the+HTRC+Portal+Algorithms
[8.] Blei DM. Topic Modeling and Digital Humanities. Journal of Digital Humanities. 2012. [Internet]. [cited 2017 May 15]. Available from: http://journalofdigitalhumanities.org/2-1/topic-modeling-and-digital-humanities-by-david-m-blei/
[9.] Weingart SB, Meeks E. The Digital Humanities Contribution to Topic Modeling. Journal of Digital Humanities. 2012. [Internet]. [cited 2017 May 15]. Available from: http://journalofdigitalhumanities.org/2-1/dh-contribution-to-topic-modeling/
[10.] McCallum AK. MALLET: A Machine Learning for Language Toolkit. MALLET: A Machine Learning for Language Toolkit. 2002. [Internet]. [cited 2017 May 15]. Available from: http://mallet.cs.umass.edu
[11.] Dunning T. Accurate Methods for the Statistics of Surprise and Coincidence. Computational Linguistics. 1993:19(1):61–74.
[12.] Schmidt B. Sapping Attention: Comparing Corpuses by Word Use. Sapping Attention. 2011 [Internet]. [cited 2017 May 15]. Available from: http://sappingattention.blogspot.com/2011/10/comparing-corpuses-by-word-use.html
[13.] Longone JB. Feeding America: The Historic American Cookbook Project. Feeding America: The Historic American Cookbook Project. [Internet]. [cited 2017 May 15]. Available from: http://digital.lib.msu.edu/projects/cookbooks/html/authors/author_farmer.html
About the Author
Gioia Stevens is Special Collections Cataloger at New York University Libraries. She holds an MLIS from Pratt Institute and recently completed an MA in the Digital Humanities track of the Master of Liberal Studies program at City University of New York Graduate Center.

Subscribe to comments: For this article | For all articles
Leave a Reply