by Kyle Banerjee and David Forero
Introduction
The needs that digital repositories serve are at least as diverse as the objects they contain, but virtually all libraries must provide: Preservation, to store digital items securely and reliably; Context, to maintain descriptive, structural, and administrative (fixity, integrity, and provenance) metadata; and Continuity, to migrate objects and metadata across systems when technology and needs change without imposing complexity on the user. (This list is adapted from Gladney, H. M. (2006). Principles for digital preservation. Communications of the ACM, 49(2), 111-116. doi:10.1145/1113034.1113038)
It’s expensive and time-consuming to perform these tasks within individual repositories because methods are particular to each installation. This article describes a simple but powerful method for supporting these functions using the DOI system. Although the implementation details will vary between individual libraries, the method is simple enough that it can be used in manual as well as heavily automated environments. We describe a way to use the DOI system with Amazon’s Glacier service to protect assets and metadata currently provided to users by our Omeka and Bepress systems, but it could be used with virtually any system.
Libraries have used identifiers to improve services for decades. OCLC numbers, ISBN (International Standard Book Numbers), and ISSN (International Standard Serial Numbers) simplify ordering, processing, and requesting. As people have come to rely more heavily on electronic information, other identifiers such as PMCIDs (PubMed Central IDs) and DOIs (Digital Object Identifiers) have become more relevant.
These identifiers are typically used as unique strings to simplify locating resources and serve as matchpoints to facilitate maintenance. Though important, these uses represent only a portion of the value identifiers can deliver. In fact, some identifiers have the potential to deliver functionality that goes well beyond a findable string in a search engine or matchpoint for maintenance tasks.
For example, DOIs can easily track a wide variety of administrative, structural, descriptive, and technical metadata. Unlike other types of identifiers, they can connect people directly to resources, track derivative and archival copies, and be easily maintained using automation. Combining the power of DOIs with third party storage solutions, such as AWS, allows repository managers to build systems that are relatively cheap and easy to use, maintain, and migrate to new platforms. Because of the high level of redundancy these systems provide, better levels of protection are introduced compared to those achieved with local solutions.
What are DOIs and how do they simplify repository administration?
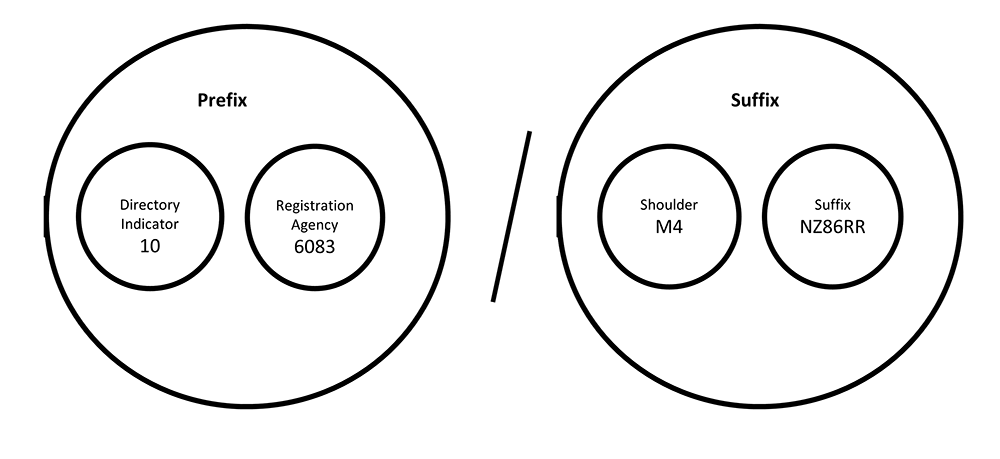
Nominally, a DOI is a string of case insensitive alphanumeric characters that uniquely and permanently identify a digital or physical item. DOIs have a simple structure designed to allow for independent creation without the risk of overlap. Consider the DOI 10.6083/M4NZ86RR
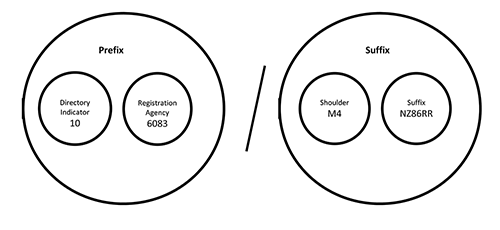
Figure 1. The DOI Structure (enlarge)
The portion before the slash is known as the prefix which is composed of a directory indicator and Registration Agency (RA) which services as namespace so suffixes do not overlap. The shoulder also provides a namespace function and allows the registrant to create as many namespaces as necessary. The length and format of both the shoulder the suffix are arbitrary and can contain any textual characters. This system allows DOIs to be generated in a distributed environment without any risk of collision. The DOI standard is defined by ISO 26324 (https://www.iso.org/standard/43506.html).
A DOI can be assigned to only one object, and each object can have only one DOI. However, DOIs can be issued for any entity that needs to be identified at any level of granularity. For example, a dataset could have its own DOI, subsets within that dataset could have their own DOIs, and individual files with the subsets could also have their own DOIs.
DOIs differ from other identifiers such as ISBNs in that DOIs:
- are associated with metadata that can be changed as the object changes.
- are designed to be created and maintained independently in a distributed environment.
- are intended to be resolvable so they connect people directly to the resource.
- can be assigned to any digital object rather than a specific type of object, such as books (ISBNs), journals (ISSN), and articles (PMCIDs).
- can be easily created and maintained with automation.
These distinguishing factors make DOIs much more useful than other identifiers that functionally are little more than unique strings. The ability to store metadata [1] that can be modified using automated processes makes it possible to simplify migrations in the following ways:
- DOIs are platform agnostic because they operate and store metadata independently. Therefore, developing interfaces between each type of repository and the DOI system is all that is necessary, rather than creating tools for each specific migration.
- Changes to any specific type of metadata from a single element or combination of elements can be made without retrieving the object or the entire metadata record.
Why use third party storage providers?
Many institutions seek out “cloud” services as they are perceived to be safer and more reliable than locally provided services. However, despite high profile organizations trying to create formal definitions [2] in recent years, from its inception the term “cloud computing” is virtually meaningless from a technical perspective and is really a marketing term [3] — the way many people use the term is to mean a service is provided somewhere else by someone else and delivered over a network. As such, they aren’t inherently better than locally hosted options so some institutions have chosen to maintain their own local clouds. A local cloud might imply one or more clusters of computers that offer some sort of redundancy or fault tolerance.
Having said that, vendor maintained cloud services on encrypted systems hosted in secure data centers may prove cheaper, easier to use, more secure, and more reliable than what can be provided locally — particularly if a major vendor commits significant resources to develop services that address very specific use cases. For example, Amazon, Dropbox, Google, Microsoft, Box, and other entities offer robust storage solutions. The capabilities of these and other services differ, so selection should be based on specific needs. For our purposes, we examine Amazon’s S3 and Glacier services (AWS). AWS was chosen because Glacier offers functionality that is of particular interest to libraries — namely secure offline storage intended for permanent archives, thus guaranteeing file integrity that is cheaper than other alternatives. S3 is an online storage service that can be used to deliver files of any type over the Web. S3 and Glacier offer the following benefits that are difficult to achieve using local resources alone:
- robust Application Programming Interface (API) that allows automation of any function the service provides.
- file integrity guaranteed through cryptographically signed transfers supported by monitoring and repair.
- excellent access controls and protection against modification and deletion.
- meets stringent security and privacy requirements.
- geographically distributed and high availability.
- scales as needed; only resources consumed require payment.
What’s the connection between DOIs and third party storage providers?
In three words: metadata, reliability, and portability. DOIs allow you to store virtually any kind of metadata. This means you can configure the metadata so the DOI
- directs the user to an access copy of a resource.
- contains information to retrieve derivative and preservation copies as well as locations on local systems.
- contains descriptive, structural, and administrative information needed to use and manage the resource.
AWS is particularly well-suited for this task. Although most interfaces to their S3 service look like a filesystem, S3 is an object store where the objects can be given names that look like directory paths. Consider the following:
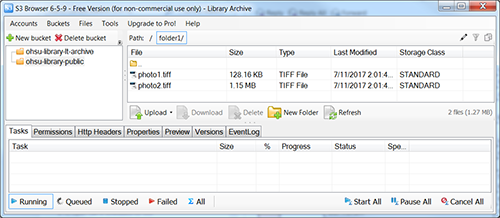
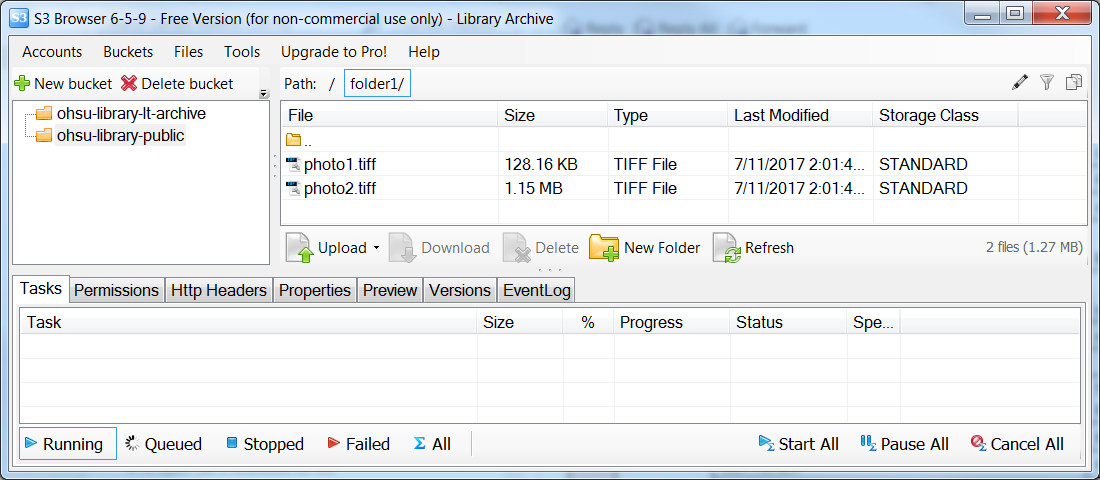
Figure 2. Displaying Objects as Files and Folders in Amazon S3 (enlarge)
What appears to be two files named photo1.tiff and photo2.tiff are not files and what appears to be a directory named folder1 containing them is not a folder. Rather, folder1 does not exist, and the only thing that exists are two objects with the 20 character names “/folder1/photo1.tiff” and “/folder1/photo2.tiff”, respectively. These objects have no relationship to each other as far as S3 is concerned. The software interface makes it appear that folder1 exists and that it contains two files, but this is an abstraction which has the sole purpose of providing a familiar metaphor to users.
The distinction is important because it has implications for operations such as renaming directories or files because directories and files are abstractions. Commands that appear to rename a directory actually copy all the objects that begin with the same string to new objects and then delete the old ones. On a personal computer, such an operation is not a matter of concern. However, when working with large numbers of objects in a data center designed to meet a different set of needs, this can be an expensive and time-consuming operation. It also means it is impossible to download a “directory.” Rather, all objects that begin with the same string must be retrieved individually, which also has performance cost and data structure implications. Likewise, all operations that presume relationships derived from filesystem relationships must be synthesized by other software acting through Amazon’s API.
The lesson here is that it’s risky to think of all systems in terms of familiar metaphors (e.g., object stores are different than filesystems and need to be interacted with differently). Relationships between objects are better maintained using metadata which allow any desired relationship to be expressed rather than file hierarchies, which are inflexible and only allow for the expression of specific types of relationships. Virtual hierarchies expressed with metadata can be converted to a traditional filesystem structure and can be more readily analyzed, modified, or extended as necessary.
Even on traditional filesystems, files and directories don’t exist in a literal sense. Rather, both are metaphors that make it easier for humans to interact with digital objects. Directory paths and file properties (such as the file name) are really metadata about an object that is kept separate from the object itself in a way that makes working with them more user friendly. By storing all object metadata in a single place (e.g., within DOI metadata) rather than splitting it between databases and filesystems, libraries are able to manage resources more easily, cheaply, and with more flexibility. For example, within metadata, a “file” can have as many names and belong in as many hierarchies as desired, rather than just exist in a single place like a real paper file.
Leveraging the complementary functionality of DOIs and third party storage providers, such as AWS, libraries can simplify repository administration and lower costs by:
- storing descriptive, structural, and administrative information in the DOI metadata where any element or combination of elements can be easily maintained and remains unchanged if the library moves to another repository platform.
- using the DOI as a key to derivative copies in S3. Different types of derivatives are stored in special purpose S3 buckets.
- using the DOI as a key to a special bucket that connects to Glacier where the preservation copy is stored.
- syncing DOI metadata with repository descriptive, structural, and administrative metadata, which protects it, makes it more actionable, and simplifies migrations.
Be aware that DOI Registration Agencies’ graphical interfaces are designed to capture and display certain types of metadata. If you need metadata supported by the underlying architecture that the interface was not designed to handle, you may find that you can only create, modify, and extract it via an API.
A Practical Example
For purposes of using DOIs as part of a preservation strategy, we have the following expectations about items needing to be preserved:
- They may or may not have been processed.
- They may or may not be publicly accessible.
- They may or may not have metadata associated with them.
- The metadata associated with them may or may not change after they are archived.
- They may or may not have DOIs already assigned to them when they are processed.
- It may be necessary to process thousands of files at once using automation.
- They can be of any size or complexity.
- They must be preserved unmodified.
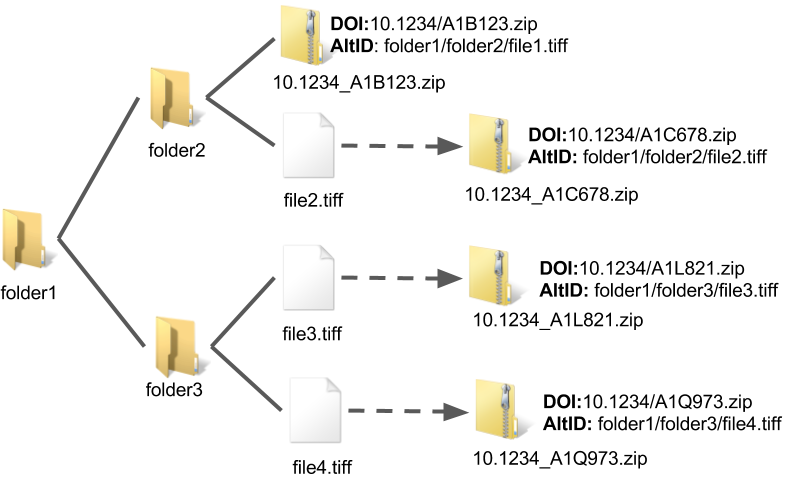
Figure 3 demonstrates the process for using the DOI system in tandem with a third party storage provider, such as Amazon. The basic mechanism is simple and has the following attributes:
- If an object lacks a DOI, one is automatically created for it.
- Objects are placed in zip files where the filename is the DOI. An underscore is substituted for the slash in the DOI to simplify processing and retrieval on regular filesystems.
- An alternate ID is added to the DOI metadata that matches the full file path to the object.
- If an object lacks a title, the title in the DOI metadata is the full file path.
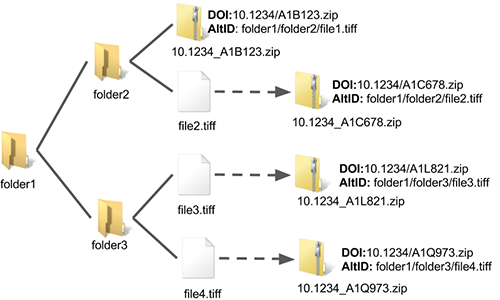
Figure 3. Preparing Objects for Archiving with DOIs (enlarge)
In Figure 3, we assume that an automated or manual process put file1.tiff in the zip archive 10.1234_A1B123.zip and assigned the full file path as an alternate identifier. As such, this object requires no further processing and can be transferred directly to the archival storage system — in this case, Amazon Glacier.
Meanwhile, file2.tiff, file3.tiff, and file4.tiff have not been processed, so DOIs are automatically created for them with the full file path stored both as the alternate identifier and title. If these are processed at some later date, the metadata for the DOI will be modified — for example, a real title will replace the file path which serves as a placeholder. These files are automatically zipped using the DOI as the archive name. All DOI zip files are then transferred to a special Amazon S3 bucket where they are later transferred to Glacier. The intermediate S3 bucket is used rather than transferring items directly to Glacier, because this mechanism allows files to be recovered using DOIs instead of Glacier IDs which would need to be managed separately.
Zipping the objects lowers storage and bandwidth costs while providing a predictable mechanism (namely the DOI itself) for accessing them without altering any file attributes. If different types of access copies, thumbnails, etc. are desired, these can be created and referenced through DOI fields.
Any file or combination of files can be recovered from Glacier using the DOI keys in a GUI interface as shown in Figure 4 or via API.
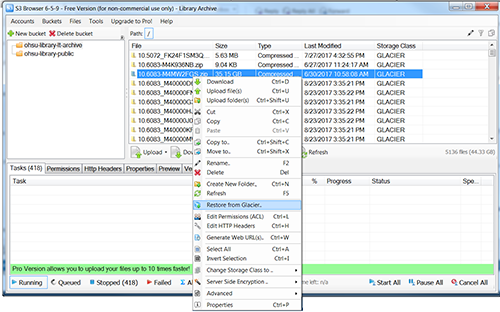
Figure 4. Recovering an Archive from Glacier (enlarge)
This scheme lacks the compelling metaphor of a traditional file system. However, both systems are conceptually simple and have been designed with an eye to compatibility into the future. We use the DOI system and Glacier to protect assets and metadata in our Omeka and Bepress systems, and a migration to Samvera (https://samvera.org) next year will be made easier because we can migrate metadata directly from the DOI system rather than developing separate methods to migrate from each repository system.
What limitations and risks are there to using this method?
Administrative limitations
To use the DOI system, you must work through a Registration Agency (RA). As of this writing, there are only ten registration agencies, each of which determines its own policies, so methods described here for the DataCite RA may require modification when used with other RAs.
DOIs can theoretically be assigned to anything, but in practice are assigned to documents, articles, datasets, and other specific types of information resources. This means the metadata schemas supported by the DOI RAs are optimized to support specific use cases that may be difficult to adapt for significantly different purposes. Regarding the DataCite metadata schema, it is extensible, but it is heavily influenced by a bibliographic data model and academic citation needs. In practice, data fields can be used for many purposes. For example, an alternate identifier field is the natural location to store file paths that indicate where an item belongs in a structure. Multiple options exist for maintaining metadata not explicitly provided for in the schema:
- Metadata may be encapsulated in other fields, such as Description, which limits neither content nor length; however, this complicates use, analysis, and maintenance of metadata. Storing wildly different kinds and amounts of data in the same field makes it difficult to process metadata efficiently.
- Metadata may be kept in a totally separate file, such as an Archival Information Package (AIP), and referenced by another DOI. This too complicates use, analysis, and maintenance of metadata. Having a separate location and set of files to parse and correlate will introduce new hurdles to overcome for systematic processing.
- Our tests indicate that at least one RA supports arbitrary metadata. This provides extraordinary functionality, ease of use, and maintenance. However, relying on such functionality may be risky as long-term support is in question.
Security limitations
Network-based archival solutions present inherent security challenges — objects are not safe if a program or human can destroy them. The safety of archived objects can be ensured by implementing access controls that allow objects to be created but not modified or deleted. Destructive credentials and cryptographic keys must be kept in a safe and unconnected space and protected by robust procedures. In the event object deletion is desired as a part of normal workflow, it can be handled through S3 and Glacier’s transparent and easily auditable retention schedule functionality.
Summary
We have presented you with a lot of detail and background. This may seem like yet another scheme to manage files, but certain aspects of this scheme make it especially noteworthy.
First, since the advent of personal computing, the dominant metaphor for managing digital objects mimics standard paper filing systems where documents are placed in folders. From a technical perspective this is a strict and unique hierarchy of categorization combined with limited strings of text as identifiers. This is a helpful metaphor, but it doesn’t reflect what actually happens on a computer, nor is it robust enough to support some of the more powerful ways computers can handle data. Computers operate more like databases than hierarchical file systems despite the dominance of that particular abstraction. Databases allow relationships to be defined arbitrarily and non-exclusively. This means that a single digital object can belong to many groups of digital objects. Filesystems have attempted to provide this functionality with pointers, symbolic links, shortcuts, and aliases. Pointers allow an object to be part of multiple groups, but the relationship tends to be only one way. The pointer lets us find the file but the file does not let us find the pointer.
Second, separating files from the method by which they are categorized and organized is key to how our scheme works. Amazon Glacier excels at reliable, simple, and inexpensive storage of data, but it is neither fast nor dynamic. Glacier’s simplicity improves longevity by not tethering objects to a complicated and perhaps ephemeral file structure. Rather, our method separates storage from the filesystem (we store the “filesystem” along with other critical metadata within DOIs). By separating where we store files and the data about the files, we leverage the strengths of both systems.
At the OHSU Library we are currently using this method to retrospectively organize and protect archival, scholarly, and image collections. By storing all our metadata and objects using the same predictable mechanism, we hope to simplify a migration from our Omeka and Bepress systems to Samvera next year as well as position us for future migrations.
This scheme lacks the compelling metaphor of a traditional file system. However, both systems are conceptually simple and have been designed with an eye to compatibility into the future. It is very probable that these two technologies will be easy to integrate into whatever future technologies present themselves.
Notes
[1] Metadata elements as well as the container used to transmit them depends on the Registration Agency (RA) and the mechanism for populating the DOI system (e.g., object within API, file (XML/JSON/text) transmitted via HTTP POST, etc.)
[2] Mell, P., & Grance, T. (2011, September). The NIST definition of cloud computing. doi:10.6028/NIST.SP.800-145.
[3] Regalado, A. (2011, October 31). Who Coined ‘Cloud Computing’? – MIT Technology Review. Retrieved from https://www.technologyreview.com/s/425970/who-coined-cloud-computing/
About the authors
Kyle Banerjee (banerjek@ohsu.edu) is the Digital Collections and Metadata Librarian at OHSU Library.
David Forero (forero@ohsu.edu) is the Technology Director at OHSU Library.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Subscribe to comments: For this article | For all articles
Leave a Reply