by Cory Lown and Brad Hemminger
Introduction
The purpose of this paper is to demonstrate a method for harvesting, storing, and analyzing data from the transaction logs of modern, faceted, search and browse Online Public Access Catalogs (OPACs). Faceted navigation OPACs, such as the ones found at North Carolina State University (NCSU) [1] and Triangle Research Libraries Network (TRLN) [2], provide users with the ability to explore library collections by text searching and facet selection. By now, faceted OPAC interfaces are common, found everywhere from public libraries to research libraries. The interfaces of such catalogs provide a significant advancement for the OPAC, giving users access to better tools for item discovery. There is also, among libraries, an increasing need to understand how the tools it provides are being utilized. This need is driven by increasing emphasis on optimizing the user experience and demonstrating to library stakeholders how the library’s resources are being used. The method described in this paper is flexible enough that the output can be used for a one-off analysis of particular statistics of interest, stored and queried as a research database, or used to feed a larger data store for library statistics, one that might be used to store and report many other statistics about the library and its operations.
The Endeca software that powers NCSU’s faceted OPAC includes some capacity for reporting usage. The reports we examined indicated that users were utilizing facets as well as text searching. The reports also indicated the most popular facets, counts of text-search only requests, facet selection-only requests, and requests that combine navigation techniques, and other statistics. However, the reporting functionality built into Endeca had no way to track sessions. As a consequence, it was impossible to know such things as how long people were spending interacting with the site, how iterative the search process was, and whether certain features of the site were more utilized at the beginning or the end of the search process. It was also a black box, meaning we had no good way of determining the accuracy of the statistics reported, and we did not know whether robot activity on the site might be affecting the reports.
We were interested, broadly, in trying to understand how people were making use of text searching and facet selection in combination as a searching technique. We were also interested in whether certain search strategies might be more suitable to particular kinds of tasks. Answering such questions would require direct user research. As a first, exploratory step in the research, and as a means to verify and enhance the information available to us in the Endeca reports, we set out to process the server logs to generate our own reports on usage of the catalog.
The techniques described in this paper rely on server transaction logs, which are a record of requests received by a server. The format of transaction logs is relatively standard, though logging may be configured somewhat differently from server to server. Each line of text in the transaction log represents an individual request. These individual requests can be grouped into sessions, series of requests initiated from the same IP address. Once the requests in the transaction logs are grouped into sessions, the individual requests that make up each session can be analyzed as a sequence of actions performed by the user. The change in parameters applied in the request URL from one request to another within a session enables us to infer the specific action taken by the user at each step in her interaction with the OPAC. When this method of analysis is carried out programmatically on a large number of requests one can learn a great deal about how users interact with faceted navigation OPACs.
Identifying sessions, and in turn, coding each request as one of a finite set of actions the user can take on the site opens up many possibilities for tracking ways that visitors make use of the OPAC. Some of the statistics that it is possible to generate from applying this method of log analysis are:
- Number of requests
- Number of sessions
- Sessions by known IP address ranges
- Sessions by known referring pages
- Counts of each coded interaction type
- Counts of sessions that include text searches
- Counts of sessions that include browsing (facet selection)
- Counts of mixed text search and browse sessions
- Tracking the index used for searching (keyword, author, subject, etc.)
- Tracking popular search terms Statistics can also be tracked over time to show differences in use from week to week throughout the academic year, or from one year to another.
Methods
This method of analysis of user behavior relies on the availability of standard Apache server logs, which track user requests in chronological order. A single line from a typical server log will be similar to this:
www2_search-access.log.1169596800: 44.154.268.143 www2.lib.ncsu.edu - [24/Jan/ 2007:00:03:04 -0500] "GET /catalog/?N=0&Nty=1&Ntk=Author&view=full&Ntt=pettersmann HTTP/1.1" 200 23888 "http://www2.lib.ncsu.edu/catalog/?N=206417" "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.0.9) Gecko/20061206 Firefox/1.5.0.9"
| Definition | Log Segment |
|---|---|
| Host | www2_search-access.log.1169596800: 44.154.268.143 www2.lib.ncsu.edu |
| Date and Time | [24/Jan/2007:00:03:04 -0500] |
| Request | “GET /catalog/?N=0&Nty=1&Ntk=Author&view=full&Ntt=pettersmann HTTP/1.1” |
| Status Code | 200 |
| Bytes Sent | 23888 |
| Referring Page | “http://www2.lib.ncsu.edu/catalog/?N=206417” |
| User Agent | “Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.0.9) Gecko/20061206 Firefox/1.5.0.9” |
Table 1: Typical Transaction Log Components
Of primary importance for this log analysis technique are the IP address present in the host information section, the Date and Time stamp, the complete Request, and the Referring Page (Table 1). The parameters supplied in the Request URL must also be tracked. The possible request parameters for this analysis, which was conducted against an Endeca powered OPAC, are listed in Table 2.
| Parameter | Meaning |
|---|---|
| N | unique ID of facet applied to query |
| No | the offset, used for pagination |
| Ntk | the index for text searching (Author, Keyword, etc.) |
| Ntt | text search terms applied to query |
| Ne | overrides the default sort order for displaying results |
| sort | request to expand a facet group |
| Ns | applies a sort to the results |
| view | request to switch result view from brief to full, or vice versa |
Table 2: Query Parameters (Endeca/NCSU Specific)
The parameters present in the request will vary depending on the software used to power faceted search and text search, however the same basic principles should apply.
Request parameters are used to code the action the user took that generated the request to the OPAC.
For this log analysis we chose to define a “session” as a series of consecutive requests from a single IP address with no more than 30 minutes passing between each request. The literature related to transaction log analysis provides little consensus about what time to use for distinguishing sessions. Generally, researchers using transaction log analysis have used times from 5 to 60 minutes. We chose 30 minutes because it falls near the center of the range of typical times used in studies. For more information about this issue see Silverstein (1999) [3], Göker (2000) [4], Hert (1997) [5], Marchionini (2002) [6], Mat-Hassan (2005) [7], and Chau (2005) [8].
The IP address and date/time stamp are used to group discrete requests into sessions. Some catalogs may themselves assign http cookies to users to identify a session. Where possible, configuring apache to include cookie information in its logs may allow one to use the catalog’s own session tracking mechanism. This may be preferable as a means to track users because it avoids potential problems where an IP address does not in fact uniquely identify a user due to proxy servers or other network configurations.
In our log analysis study, we used already captured historical logs which did not include any cookies which the catalog application might apply. We do not think proxy servers or other network configurations that would render the IP address meaningless as a unique identifier of a computer affected our results significantly, since we expected most of the requests to come from NCSU’s campus, dorms, and from homes. It is also possible for users to share computers, which could result in requests from two or more different users appearing in the logs from a single IP address. Additional measures we took to remove robot activity (discussed later) also have the effect of removing heavily used public computers from the log, so we think the effect of public computers is small.
The term “dwell time” refers to the difference in time between two requests from the same IP address. By “action” we mean the user’s interaction with the search interface. There is a user action generated for each request recorded in the transaction log. “Action code” refers to the one action the user took that generated a request. This is deduced by comparing the present set of request parameters with the previous set of request parameters. The difference between these two requests reveals the action the user took to generate the current request.
For the OPAC used in this analysis, there were 12 possible user actions of interest. The codes possible for other systems will vary depending on the parameters available for modification by the user interface. We also assume a stateless system, in which each action generates a separate request to the server handling requests for the OPAC. Table 3 illustrates the action codes possible in the NCSU OPAC at the time it was analyzed. It is worth noting that only searches, and not item record views, were captured by the log files we examined. Additionally, website interactions that include the use of a browser’s “back” or “forward” button are not captured in the logs if the browser uses a cached version of the page. The logical rules in Table 3 define how the action codes are determined.
| Coded Action | Explanation | Logical Rule |
|---|---|---|
| Text Search | First appearance of a search string within a session | Ntt has a value. Value is different from previous Ntt value. Ntt value has not appeared previously in the same session. If multiple values have changed, Ntt change takes precedence. |
| Facet Search | Refines the result set by selecting a facet | N has a value other than “0”. N value is different from previous N value, or N has an additional value that was not present in the previous N value. If multiple values have changed, takes precedence over all but a change in Ntt value. |
| Begin Text Facet Search | Begins a search with a facet and a text string | First step in a session. N has a value other than “0” AND Ntt has a value. |
| Refresh | No change in search state; suspect user reloaded/refreshed the page | Not the first step in a session. Present and previous parameters have the same values. |
| Switch Field | Switches the index used for text search | If none of the previous conditions are met, Ntk has a value, and that value is different from the previous Ntk value. |
| Next Page | Views a different page of results | If none of the previous conditions are met, No has a value and that value is different from the previous No value. |
| Sort | Changes the sorting of the results | If none of the previous conditions are met, sort has a value, and that value is different from the previous sort value. |
| Switch View | Switches record view from brief to full, or vice versa | If none of the previous conditions are met, view has value, and that value is different from previous view value. |
| Begin Full Set | Begins a search by selecting search without entering a search string; this returns all possible results | First step in a session. N has a value of “0” AND Ntt is not present in the URL or has a value of “-“. |
| Previous Term | Searches on a term again | Ntt has a value. Ntt value has appeared previously in the same session. |
| Remove Facet | Removes a facet from the search (either by clicking the “X” in the interface, or by clicking the “back” button in the browser) | Determined by counting the number of concatenated facet ids in N value. If present count is less than previous count, then this condition applies |
| Expand Facet Group | Expands a facet group by clicking “Show More …” | None of the other conditions are met, Ne has a value, and that value is different from previous Ne value. |
Table 3: Example Coded User Actions
The primary benefit of this method over other simpler methods, such as searching for instances of parameters in the log, is the addition of the concept of a session, so that statistics can be generated on a per session rather than just per request basis. An additional benefit of this method is that one can track session characteristics, such as sessions that include only certain kinds of queries. Also, because each request is coded, one can eliminate duplicating counts of parameters after they are applied. In effect, this is a way of eliminating counts of parameters still present in the request url that were applied earlier in the session. To illustrate, if a user begins a session by searching for the string “photography,” then applies a facet, applies another facet, and then views 3 pages of results, the initial parameter that holds the query string “photography” would be present throughout all 6 requests of this user’s session. A simple count of the parameters present in this set of requests would count the “Ntt=photography” parameter 6 times rather than 1 time. By counting logically derived codes instead of parameters we are able to provide a more accurate count of user interactions with the site.
The basic method applied in this approach of parsing a standard server log was adapted from Callender’s Perl for Web Site Management [9], which includes an excellent description of log formats and approaches to parsing them.
Some pre-processing of the logs may be required to eliminate requests not related to search (such as requests for images). If there is known robot activity present in the logs, and the IP address of the robot making requests is known, these requests may be eliminated as well. Further automated techniques will be used later in the log processing to eliminate most non-human activity from the logs.
We processed the transaction logs in several passes. In total, three scripts were written to process the logs. All the scripts, a sample log file, and sample output files may be downloaded from the web [10]. The first script parses the raw log file to prepare it for further processing. This includes converting the date to Unix Epoch time for time calculations, extracting parameters from the request URL, and coding the referring page to track how users are entering into the faceted OPAC.
The second script takes as input the output from the first script. This script’s primary purpose is to parse separate requests into sessions. Requests from a single IP address with not more than 30 minutes passing between a request are counted as being part of the same session. Each session is assigned a unique identifier and each request within a session is assigned a number from 0-N to capture the order of the requests within each session. The time elapsed between each request within a session is also recorded by the second script.
The third script takes as input the output from the second script. With requests grouped into sessions and ordered sequentially, the request parameters can be analyzed for the purpose of assigning a coded action to each request. The code associated with a request is determined by comparing the current state with the previous state. For instance, consider this sequence of two requests:
Previous state: /catalog/?N=0&view=full&Ntk=Keyword&Ntt=photography Current state: /catalog/?view=full&Ntt=photography&Ntk=Keyword&N=201015
| Previous State | Current State |
|---|---|
| N=0 | N=201015 |
| view=full | view=full |
| Ntk=Keyword | Ntk=Keyword |
| Ntt=photography | Ntt=photography |
Table 4: Query Parameter State Comparison
In this case, the difference between the previous state and the current state is the “N=” value, which in the first state is “0” and in the second state is “201015”. Because only the “N=” value has changed, the current state is coded as Facet Search (Table 4). It is necessary to account for any default parameters, which apply to the request whether or not they are applied explicitly in the request URL.
Although requests from known robot IP addresses were eliminated prior to processing, there is also an automated way of minimizing the presence of robot activity in the processed logs. Jansen found that eliminating sessions with over 100 requests was effective for removing most robot activity, while not excluding most human activity [11].
Processed data may be stored and used in multiple ways. We chose to store the processed data in a MySQL database for ease of querying the data, and also the ability to output the data in other formats. Queries can be written to output the processed log data from a database in a format suitable for analysis in a statistical package, such as SAS. The database we created consists of a single table with the fields listed in Table 5:
| Field | Explanation |
|---|---|
| Request ID | An auto incremented ID assigned to each request. |
| IP Address | The IP address originating the request |
| Date | Human-readable date |
| Time | Human-readable time |
| Epoch Time Stamp | Unix Epoch time stamp |
| URL | The complete request URL |
| Search Term | The search term (if any) extracted from the request URL |
| Index | The index (Author, Subject, Keyword, etc.) applied (if any) extracted from the request URL |
| Facet | The ID of the facet applied (if any) extracted from the request URL |
| View | The current view applied (full or brief) extracted from the request URL |
| Page | The offset for viewing results extracted from the request URL |
| Expand Facet Group | The ID of a facet group (id any) extracted from the request URL, indicating a request to view the full list of possible values |
| Visit Number | An ID assigned by the processing script to every request that belongs to the same session |
| Visit Step | A number from 0-N that maintains the order of requests within a session. |
| Elapsed Time | The difference in time between the present request and the previous request within the same session. |
| Referring Page | The referring page URL (if any) that indicates the URL of the page that originated the request. |
| Action Code | The code assigned to the request, determined by the processing script by deducing the change in state between the current request and the previous request. |
Table 5: Output from Log Processing
Results
Originally, the techniques described in this paper were developed to conduct a one-time analysis of the transaction logs of NCSU’s OPAC from a four month period. For a more complete overview and discussion of the statistics generated see Lown’s master’s paper [12]. The following statistics illustrate the range of data it is possible to generate from the processed logs.
First, general observations about user behavior can be made. From the four month period there are 938,848 requests. After removing robot activity and excluding sessions with over 100 requests, there are 130,482 separate sessions. Most sessions are short, consisting of a median of 2 requests and lasting about 45 seconds, with just over 22 seconds passing between each request. The most frequent actions are Text Search (39%), Next Page (25%), and Facet Search (18%) (Figure 1).
It is notable that “Refresh” accounts for 7% of requests. A request was counted as a Refresh if the present URL contained the same parameter values as the previous request. An examination of the data shows that in these cases the unprocessed server logs recorded two consecutive requests from the same IP address with the same parameters applied. Because Refresh is the correct code for this circumstance, the log processing logic appears to be working as expected. We cannot be sure whether the high number of refreshes present in the logs represents users actually refreshing the page, a problem with the way the server was logging requests, or some other anomaly.
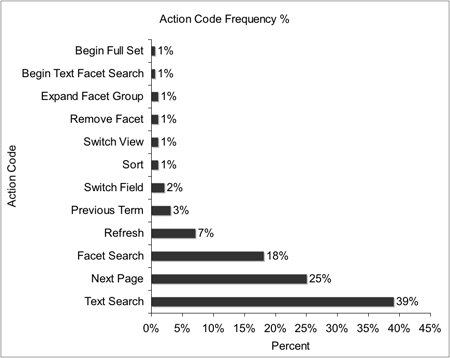
Figure 1: Action Code Frequency Percent
Text searching is the most frequent request parameter applied to a search on the OPAC. When users text search they have the option of selecting a specific index to search against. The default index is keyword, which searches across a range of fields. Figure 2 illustrates the most frequently searched indexes.
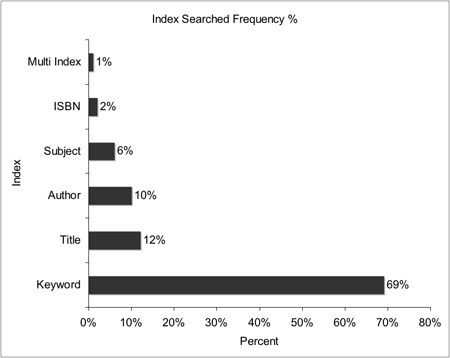
Figure 2: Index Searched Frequency Percent
The average number of terms used when searching particular fields can also be determined (Table 6).
| Search Index | Average # Terms Applied |
|---|---|
| Title | 3.01 |
| Multi Index | 2.87 |
| Keyword | 2.51 |
| Subject | 1.97 |
| Author | 1.90 |
| ISBN | 1.09 |
Table 6: Average Terms Applied Per Index
These findings are consistent with studies that indicate the average number of terms applied to Web searches. For instance, Jansen reports that Internet searchers use an average of 2.21 terms per query, which is close to the 2.51 average terms applied to the Keyword index of the NCSU OPAC [13].
One can also determine the average number of facets applied to queries that include at least one facet parameter (Table 7).
| Number of Facets | Frequency % |
|---|---|
| 1 Facet | 58% |
| 2 Facets | 23% |
| 3 Facets | 12% |
| 4 Facets | 6% |
| >4 Facets | 1% |
Table 7: Average Number of Facets Applied
Because requests are grouped into sessions, one can also categorize sessions based on the kinds of requests they include or exclude. For instance, Figure 3 compares the percentage of sessions that include at least one Text Search with the percentage that include at least one Facet Search.
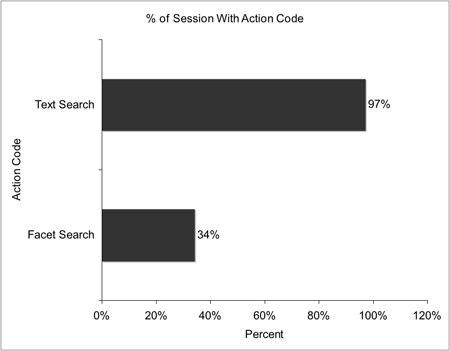
Figure 3: Percent of Sessions Including Action Code
Figure 4 shows the distribution of action codes by the order in which they occur within sessions. This reveals that text searches decrease and next page views increase over the course of a session. There is also a slight trend that facet searches decrease over the course of a session. Note that the first step is excluded because the interface studied provided different options for entry into the OPAC interface.
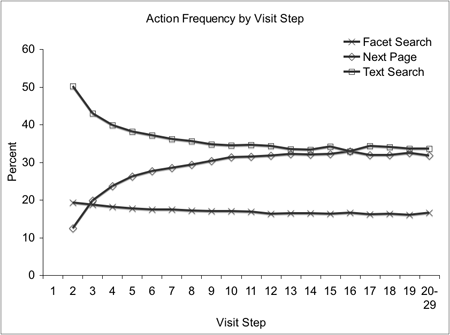
Figure 4: Action Percent By Visit Step Within Sessions
The Endeca software used to provide search and navigation on the NCSU OPAC includes some reporting capability built-in. However, the reporting features are essentially a black box; data goes in and reports come out, but it is not possible to examine how the reports are generated. Additionally, building custom log analysis tools enables data cleansing to remove most robot activity. Studies of user behavior benefit from minimizing non-human activity. Figure 5 compares relative usage of different groups of facets. Both the Endeca-generated statistics and the data generated from this log analysis are shown. While it is not possible to know how Endeca’s reporting function is generating its numbers, we can explain the differences in the numbers generated by our reporting techniques and the Endeca reports. For instance, if we calculate facet group usage without eliminating robot activity and without filtering for actions that are coded as facet searches, we find that our numbers are much closer to those in Endeca’s reports. We think this illustrates both the value of eliminating robot activity and of coding user actions by comparing URLs.
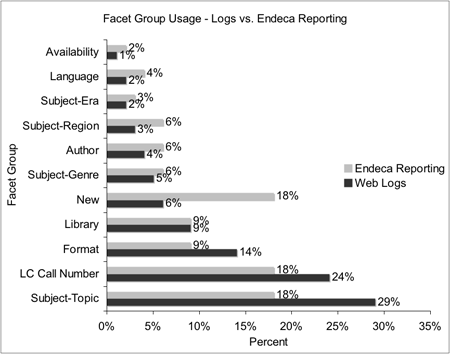
Figure 5: Facet Group Usage – Logs vs. Endeca Reporting
Discussion
The results generated from our log analysis work are an improvement over the Endeca-generated statistics in that they eliminate activity attributable to robots. Additionally, the statistics are a more accurate representation of user behavior because they can account for sessions. More specifically, a few results are worth discussion as they will help inform research questions for further studies, especially observational studies, in which we will be able to control search task types and rate the relative success of different search strategies for different tasks. One of the significant limitations of log analysis is that it is impossible to know how successful the user’s search was from the logs.
The results show that while users do make use of facets, they do so less than text searching. This holds whether one looks at overall usage of search features as in Figure 1 (where text searching occurs 39% of the time and facet searching occurs 18% of the time), or whether one looks at occurrences within sessions as in Figure 3 (where text searching occurs at least once in 97% of sessions and facet searching occurs at least once in 34% of sessions). Future research studies would be required to explain why text searching occurs more frequently. It may be that text searching is a more effective strategy in more common search tasks, while facet application only helps under different, less frequent circumstances. It is also possible that text searching is more iterative and requires more trial and error and so requires more individual requests to retrieve an acceptable result set.
Additionally, we know that use of text searching tends to decrease over the course of a session (Figure 4). It appears that text searching decreases in proportion to an increase in next page views. It is possible that this is explained by increased exploration of results and less modification of search strategy over the course of a session. However, facet search use decreases less dramatically. This may also indicate a difference in search behavior between shorter and longer sessions. We would have to observe real users to uncover why text searching is used less frequently in later stages of searching.
The results also show that some facet groups are used significantly more frequently than others. Subject-Topic, LC Call Number, and Format together account for about 67% of all facet selections (Figure 5). In a future user study we could test whether the placement of these facets on the page affects their usage, whether particular kinds of tasks influence which facet groups are more likely to be used, or whether some facet groups are confusing to users and so are applied less frequently. Testing such questions could help designing future interfaces in terms of which facet groupings should be displayed and how they should be displayed on the page.
Derek Rodriguez of the Triangle Research Libraries Network (TRLN) adapted the scripts for use with the TRLN log format, and also to continually update a database with new log activity for ongoing analysis of user behavior on the TRLN OPAC. A Web-based interface (under development) enables TRLN administrators to view statistics within a user-specified date range. (The reporting interface is not accessible publicly.) TRLN plans to share the logging scripts and database schema with all TRLN member libraries so that usage statistics can be shared and compared across the TRLN libraries.
These scripts have been enhanced further by Hemminger and Xi Niu at UNC Chapel Hill to process the UNC and TRLN data into a finer grained set of actions. They are performing clustering analysis with their revised coding scheme against the complete log history of Endeca searches at UNC. Their aim is to determine the different types of search behaviors in use, and to better understand how facets are used in conjunction with text searching.
Conclusion
Transaction log analysis provides a scalable means to study and monitor how visitors to a faceted navigation OPAC make use of interface features. Programmatically grouping requests into sessions and eliminating non-human requests produces more accurate and more realistic statistics than some out-of-the-box reporting tools. Additionally, by coding changes-in-state between consecutive requests within sessions, each request can be reduced to one of a finite set of possible user actions. Logs may be parsed and analyzed for one-time studies to inform research questions, or can be continually processed and stored in a database for ongoing monitoring of how users are interacting with the OPAC. Storage in a database table enables querying for customized analyses, as well as building standardized reports viewable through a data dashboard.
Notes
[1] NCSU’s OPAC, http://www.lib.ncsu.edu/catalog
[2] TRLN’s OPAC, http://search.trln.org/search.jsp
[3] Silverstein, C., et al. (1999). “Analysis of a Very Large Web Search Engine Query Log.” SIGIR Forum, 33(1), 6-12
(COinS)
[4] Göker, A., & He, D. (2000). “Analysing Web Search Logs to Determine Session Boundaries for User-Oriented Learning.” Proceedings of Adaptive Hypermedia and Adaptive Web-Based Systems, 319-322.
(COinS)
[5] Hert, C. A., & Marchionini, G. (1997). “Seeking Statistical Information In Federal Websites: Users, Tasks, Strategies, and Design Recommendations.” Final Report to the Bureau of Labor Statistics. http://ils.unc.edu/~march/blsreport/blsmain.htm
[6] Marchionini, G. (2002). “Co-Evolution of User and Organizational Interfaces: A Longitudinal Case Study Of WWW Dissemination of National Statistics.” Journal of the American Society for Information Science and Technology, 53(14), 1192-1209.
(COinS)
[7] Mat-Hassan, M., et al. (2005) “Associating Search and Navigation Behavior through Log Analysis.” Journal of the American Society for Information Science and Technology. 56(9), 913-934.
(COinS)
[8] Chau, M., Fang, X., & Sheng, O. R. L. (2005). “Analysis of the Query Logs of a Web Site Search Engine.” Journal of the American Society for Information Science and Technology, 56(13), 1363-1376.
(COinS)
[9] Callender, J. (2001). Perl for Web Site Management. O’Reilly Media, Inc.
(COinS)
[10] Log processing scipts: http://www.lib.ncsu.edu/staff/cwlown/ncsu_log_proc.php
[11] Jansen, B. J. (2006). “Search Log Analysis: What Is It; What?s Been Done; How to Do It.” Library and Information Science Research, 28(3), 407-432.
(COinS)
[12] Lown, C. (2008). “A Transaction Log Analysis of NCSU’s Faceted Navigation OPAC.” SILS-EDT: http://hdl.handle.net/1901/488
[13] Jansen, B. et. al. (2000). “Real life, real users, and real needs: a study and analysis of user queries on the web.” Information Processing and Management, 36, 207-227.
(COinS)
About the Authors
Cory Lown is a Library Fellow in Digital Library Initiatives and Collection Management at North Carolina State University Libraries, where he contributes as a designer and developer of a variety of digital library services and applications.
Brad Hemminger is an associate professor at the School of Information and Library Science at the University of North Carolina at Chapel Hill. He is the director of the Informatics and Visualization Research Laboratory and the Center for Research and Development of Digital Libraries. His research interests include scholarly communications, information seeking, user interface design, information visualization and bioinformatics.

Google Analytics pour Primo : étudier le comportement des internautes « Bibliothèques [reloaded], 2011-07-07
[…] méthode est celle déjà décrite (plus élaborée) dans cet article de 2009, utilisée à la North Carolina State University pour leur opac […]
Continued adventures in integrated article search | Bibliographic Wilderness, 2013-09-04
[…] searches and boolean connectors were used very rarely, in only about 5% of searches. There are other studies that exist of this sort of thing too, based on analytics, with roughly compatible […]