By Dianne Dietrich
Background
Cornell University Library has made 90,000 of its digitized books available as Print-on-Demand books through both its internal bookstore and Amazon.com [1]. Other libraries have also offered, or are preparing to offer, their digitized public domain works as Print-on-Demand books.
A Print-on-Demand book is, essentially, a physical object created from multiple digital sources–the digitized version of the original physical object and the metadata from the online catalog. The final new physical book should maintain the logical consistency of the original physical book: all of the pages should be in order, and the author’s name on the front cover should look like the author’s actual name.
This is reasonably easy to accomplish. Our Print-on-Demand book candidates are all out of copyright and in the public domain, so most are quite old. Some of these authors have titles attached to their names that aren’t commonly seen anymore, such as Count, Earl, and Duchess. These authors are all in our catalog in an order that makes complete sense for cataloging our holdings, but not for displaying on the front cover of a book.
In order to prepare our Print-on-Demand books, we had to create a comprehensive list of bibliographic identifiers, titles, and authors. We needed to identify the following fields for each author string–title, first name, middle name, last name, suffix, and contributor. It was not always immediately apparent from our catalog metadata which parts of the author string were associated with which of these fields.
To begin the processes of formatting the metadata, we first extracted bibliographic information from our catalog. For each work we were making available, we pulled the necessary identifiers, title information, and the author string. Some author names were in the form “Surname, Forename,” which made identifying their component parts straightforward. Other names were less straightforward. A sampling of the more complex author strings (as they were stored in the appropriate column of our spreadsheet) is listed below:
- Christina, of Bolsena, Saint
- Liljencrants, Johan, Baron
- Lennox, William Pitt, Lord
- Stanhope, Charles Stanhope, Earl
- Collingwood, Cuthbert Collingwood, Baron
- Campbell, John Campbell, Baron
- Iddesleigh, Stafford Henry Northcote, Earl of
- Sandwich, Edward George Henry Montagu, 8th earl of
- Brown, William, of Montreal
- George, William, of the St. Paul bar
- The Players, New York
- Nathan, Nathaniel, Sir
- Carriel, Mary Turner, Mrs.
- Hanson, John Wesley, Jr.
- University of California, Berkeley.
- Clarke, John, lecturer in University of Aberdeen.
- Monkswell, Robert Alfred Hardcastle Collier, 3d baron
- Moulton, John Fletcher Moulton, 1st baron
Many of these strings have three component parts to them, so it was reasonable to assume that they were of the form “Surname, Forename, Title.” The author strings for Baron Johan Liljencrants and Lord William Pitt Lenox (lines 2 and 3) follow this pattern. When we split these strings on the commas, we found ourselves with the following substrings.
| Liljencrants | Johan | Baron |
| Lennox | William Pitt | Lord |
It was then simple to identify the component parts and reorder these substrings appropriately. The third substring was the title, and should be positioned before the forename and the surname.
We ran into problems very quickly, though. Many of the author strings with three component parts included a suffix, rather than a title. We could no longer assume that the third substring should be placed in front of the forename and surname. The author string for John Wesley Hanson, Jr. (line 14) is an example of this.
We soon realized that our task was much more complicated than compiling a list of suffixes and titles, assigning the third substring to the appropriate field, and positioning it accordingly. Many of the author strings that had three component parts were unexpectedly complicated and required different parsing rules altogether. The author string for Earl Charles Stanhope (line 4) was one example of an author string (with three component parts) that required extra attention. The three component parts of the string were not in the order we were expecting.
| Stanhope | Charles Stanhope | Earl |
When we assumed that this string followed a “Surname, Forename, Title” pattern and tried to reorder it, the result was “Earl Charles Stanhope Stanhope.” In this case, the first “Stanhope” was actually part of the title and is not a surname, as it was probably meant to read something like, “Earl Stanhope, Charles Stanhope.”
Saint names were even more complicated to reconstruct. One example is the author string for Saint Christina of Bolsena (line 1). When we split the author string on commas, we had three distinct parts to the name.
| Christina | of Bolsena | Saint |
Again, when we assumed a “Surname, Forename, Title” pattern, and then tried to reorder the string, we ended up with “Saint of Bolsena Christina.” We clearly needed different rules for parsing this string, because in this case, while “Saint” was a title, “of Bolsena” was a suffix.
Manual reconfiguration of all of these author names was impractical, as we were dealing with tens of thousands of records. We decided to create a script capable of parsing as many author string variations as possible. We first identified the types of reconfigurations we were likely to encounter. Next, we worked on developing the script to automatically handle string reconfiguration. As we inspected our results, we refined and adjusted the script to suit our needs.
To start to understand the data we were working with, we isolated all of the author strings, and placed them in a separate file. (Each author string was comma delimited, as in the list above.) We then printed out the contents of the third position of the string, as it was the position most likely to contain titles, suffixes, contributors, or other related words that would require special handling. We sorted our output and extracted the unique values in the resulting list. We accomplished this fairly quickly with a shell command.
awk -F "," ' { print $3 } ' full_author_list.txt | sort | uniq [2]
This list gave us a good sense of the variations we could encounter in our data, which we used as the foundation to build cases for parsing and formatting the author strings. As we continued to fine-tune the script, we viewed its output in Excel, taking advantage of the Filter options to identify outliers and special cases.
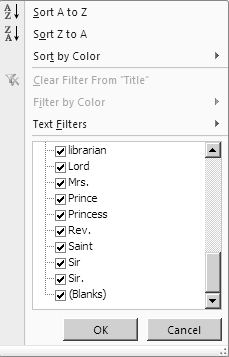
Figure 1: Probable titles, suffixes, or other non-name words requiring special handling
(As much as we might like, “librarian” probably shouldn’t be listed as a proper title, with “Prince,” “Rev.” and others.)
The following sections describe the types of author string parsing we performed on our metadata.
Corporate Names
At the outset, it was important to distinguish between personal names and corporate names. Since the spreadsheet we worked with did not capture full MARC metadata, we had to develop a set of heuristics to use to identify corporate names.
As we worked with the data, we identified a number of cases where it was highly likely that an author string was not a personal name.
- It included a geographic location, like a U.S. state name or abbreviation, or country name.
- It included words associated with government, like “Government,” “Congress,” or “Senate.”
- It was an institution name, and included words like, “College” or “University.”
- The string in the “Forename” field started with numbers, or resembled a date range.
These heuristics weren’t foolproof, but they did help us identify many of the cases where we did not want to do any parsing of the author string at all.
Lords and Ladies
It was a relatively simple case when the author string followed the “Surname, Forename, Title” pattern. Consider the following two author strings (lines 2 and 3):
Liljencrants, Johan, Baron
Lennox, William Pitt, Lord
Each string was split on commas and stored in a Python list as the variable authorstring. We wanted to correctly identify “Baron” and “Lord” as titles, while correctly identifying forenames and surnames and putting them in the correct order. To accomplish this, we used the following regular expression [3]:
isBaron = re.compile('(.* )(saint|baron|lord|countess|baroness)(\.*)$', re.I).search(authorstring[2])
We then had the following three captured groups for each of the aforementioned author strings:
| 1 | 2 | 3 |
|---|---|---|
| None | Baron | None |
| None | Lord | None |
The three captured groups formed the title, and so we simply reorganized the string as “Title Forename Surname.” The third captured group was for optional punctuation after the title. We captured any text preceding the title – in the first captured group – separately because, in some cases, it was crucial to mark the distinction between the first Baron from the third, or the fifth. The following author strings for 3d Baron Robert Alfred Hardcastle Collier and 1st Baron John Fletcher Moulton (lines 17 and 18) are examples of this.
Monkswell, Robert Alfred Hardcastle Collier, 3d baron
Moulton, John Fletcher Moulton, 1st baron
After running the above regular expression on these strings, we ended up with the following captured groups:
| 1 | 2 | 3 |
|---|---|---|
| 3d | baron | None |
| 1st | baron | None |
When the script detected a value in the first captured group, it concatenated this value – usually an ordinal number – with the rest of the captured groups to form the full version of the title. We then capitalized only the first character of the second captured group.
You might have noticed that if we transformed 1st Baron John Fletcher Moulton’s author string as we described above, we would end up with “1st Baron John Fletcher Moulton Moulton.” In fact, we found that when we applied this rule to our entire list of author strings, many of the resulting strings had this exact error, a “duplicate” surname.
Last Name Hiccups
As we saw earlier, some of the author strings we were working with were stored in such a way that, when we applied our formatting rules, the resulting string had one word duplicated.
The author strings for Earl Charles Stanhope and Barons John Campbell and Cuthbert (lines 4, 5, and 6) provide us with examples of this case.
Stanhope, Charles Stanhope, Earl
Collingwood, Cuthbert Collingwood, Baron
Campbell, John Campbell, Baron
When we used the formatting rule we described earlier, we ended up with the following author strings.
Earl Charles Stanhope Stanhope
Baron Cuthbert Collingwood Collingwood
Baron John Campbell Campbell
These would look somewhat strange on the front cover of a book. Instead of following the pattern “Surname, Forename, Title,” these cases followed the pattern “Word associated with title, Forename Surname, Title,” where the surname was the same word as the “Word associated with title.” To account for these cases, we set up a regular expression to match the value in the first position of the authorstring list. If it matched, we removed the duplicate surname from the forename [4].
tmp = r'(%s)'
isDuplicate = re.compile(tmp % authorstring[0]).search(authorstring[1].lstrip(' '))
if isDuplicate:
title = "%s%s" % (isBaron.group(1).lstrip(' '), isBaron.group(2).capitalize())
firstname = re.compile(isDuplicate.group(1)).sub('',authorstring[1].lstrip(' ')).rstrip(' ')
lastname = authorstring[0]
We could then reorder the author string and display the names properly.
Dukes of Earl
Some authors were Countess or Baron of a particular place. The author strings for Stafford Henry Northcote and Edward George Henry Montagu (lines 7 and 8) were examples of this case. (In Montagu’s case, there is a number and place associated with his “Earlness.”)
Iddesleigh, Stafford Henry Northcote, Earl of
Sandwich, Edward George Henry Montagu, 8th earl of
The pattern here was the same, “Words associated with title, Forename Surname, Title.” The difference between this case and the one that came before was that there was no redundant information–no “duplicate” surnames. The “Words associated with title” needed to be placed with the title, to create the complete author name. To reformat these author strings, we used the following regular expression and code.
isBaronOf = re.compile('(.* )(baron|lord|countess|baroness) (of|de|von|de|d\'|di)$', re.I).search(authorstring[2])
if isBaronOf:
firstname = authorstring[1].lstrip(' ')
lastname = '%s%s %s %s' % (isBaronOf.group(1).lstrip(' '), isBaronOf.group(2).capitalize(), isBaronOf.group(3), authorstring[0])
This associated the component parts of the author strings with the proper fields, and the strings appeared in the right order.
Stafford Henry Northcote, Earl of Iddesleigh
Edward George Henry Montagu, 8th Earl of Sandwich
Place Names
What about the authors who weren’t Earls or Barons of some place, but were simply, “of” that place? The author strings for William Brown and William George (lines 9 and 10) both included place information in addition to the personal name.
Brown, William, of Montreal
George, William, of the St. Paul bar
In the previous cases, we saw that when the string in the third position of the author string ended in some form of the word “of,” it was often part of a title. In this case, when the string in the third position started with “of,” these strings were suffixes, and were placed after the forename and surname.
The following code identified this case and parsed the author name accordingly.
isOf = re.compile('of (.*)$', re.I).match(authorstring[2].lstrip(' '))
elif isOf:
firstname = authorstring[1].lstrip(' ')
lastname = authorstring[0]
suffix = isOf.group(0)
Miscellaneous Saints
Finally, in some cases, we didn’t have a “Surname” at all. The author string for Saint Christina of Bolsena was an example of this.
Christina, of Bolsena, Saint
In this case, this string matched the isBaron regular expression, because it resembled the pattern “Surname, Forename, Title.” We added the following code to check if the string that typically denotes the “Forename” started with some form of the word “of,” indicating it was not a true forename, but rather a suffix. Any substring that matched this pattern was reassigned to the suffix field so that the full author string could be reorganized appropriately.
if authorstring[1].lstrip(' ').startswith('de') or authorstring[1].lstrip(' ').startswith('of'):
title = "%s%s" % (isBaron.group(1).lstrip(' '), isBaron.group(2).capitalize())
firstname = authorstring[0]
lastname = authorstring[1].lstrip(' ')
Re-Imagining Our Process
When we originally exported all of our bibliographic metadata, we did not include MARC fields, subfields, or delimiters. After we examined our cases, we realized that if we had the MARC metadata, some of our processing would have been simpler.
Identifying corporate author names would have been far simpler if we pulled the MARC field out of our catalog. It is rather easy to flag the corporate author strings in this list:
100 1_ |a Brown, William, |c of Montreal.
100 1_ |a George, William, |c of the St. Paul bar.
110 2_ |a The Players, New York.
111 2_ |a Continental Congress for Economic Reconstruction |d (1933 : |c Washington, D.C.)
Fields 110 and 111 denote “Corporate Name” and “Meeting Name,” respectively. Our script would not have to use our “best guess” for determining corporate names if we had this information at the outset.
We were also hesitant to strip out dates from all author strings because we did not have a foolproof way of distinguishing between corporate and personal names. If we had the MARC fields, we could have easily removed the subfield $d from the personal names only.
With MARC metadata, we would have been better able to identify those author strings that don’t follow the “Surname, Forename” pattern. To correctly parse “Saint Christina of Bolsena,” remember that we had to test what we thought was the “Forename” to see if it started with the word “of” (or “de”). That was our only clue that we had a name that wasn’t in inverted order. If we had the MARC first indicator along with the author string, we would have known for sure that we were encountering a special case.
100 0_ |a Christina, |c of Bolsena, Saint,
Including full MARC metadata would not have eliminated the need for a custom script, but it is clear to see how it may have helped us handle certain cases.
Script
The complete Python script is available at Amazon POD Processing Script. A file of the sample author names discussed in this article and designed to accompany the code is also available.
Conclusion
Our goal was to create a script that would automatically process the majority of predictably formatted author strings so that only a small percentage would have to be corrected manually. We still conducted a human review of the metadata before we sent it out, and we estimated that we needed to hand-correct no more than 5% of the metadata after running the script.
Thank you
Fiona Patrick, Bronwyn Mohlke, and Liz Muller provided invaluable help deciphering MARC metadata, identifying cases, and refining the results of this script.
Notes
[1] Bill Steele. “Cornell and Amazon.com join to resurrect 90,000 rare books via print-on-demand.” Cornell Chronicle Online (February 26, 2009) http://www.news.cornell.edu/stories/Feb09/AmazonPOD.ws.html
[2] It is also possible to get all of the unique values by using the “text to columns” feature in Excel and then filtering the results on the third column.
[3] For the sake of brevity and clarity, only a few of the strings we used to match this case will be in the code snippet. See the full script and the appendix for the full list of strings.
[4] It seems overkill to do the surname like this, but the first naive matching inexplicably chopped off too much of certain authors’ names (see “Sir Nathaniel Nathan,” line 12), so a more rigorous solution was needed.
[5] Place names that are also common personal names have been deliberately excluded from this list.
About the Author
Dianne Dietrich (dd388 at cornell dot edu) is the Research Data & Metadata Librarian at Cornell University.
Appendix
The following tables include lists of the strings that we used in our script to match the various cases. These lists were generated as we developed our script using our own metadata, and will, most likely, be expanded when necessary.
Corporate Names
| Strings we used to test for the presence of a corporate (not personal) author string [5] | State abbreviations |
|---|---|
| Association Atlanta Boston College Confederate Congress Democratic England Florida Great Britain Halifax Massachusetts Missouri New York Ontario Pennsylvania Republican Rhode Island United States University Washington D.C. |
Ala. Ark. Ariz. Calif. Colo. Conn. Del. Fla. Ga. Ill. Ind. Kan. Ky. La. Me. Mass. Md. Mich. Minn. Mo. Miss. Mont. N.C. N.D. Neb. N.H. N.J. N.M. Nev. N.Y. Okla. Ore. Pa. R.I. S.C. S.D. Tenn. Vt. Va. Wash. Wis. W.Va. Wyo. |
Lords and Ladies
| Titles (generally found without “of” attached) |
|---|
|
Abbe Abp. Baron Barone Baroness Bp. Cardinal Chaplain Colonel Compte Comtesse Conte Contessa Count Countess Dame Duc Earl Father Freiherr Graf Hon Hrabe Kniaz Lady Lord Mme. Mrs. Prince Princess Rev. Saint Sir Viscount Viscountess |
Dukes of Earl
| Titles (generally found with “of” attached) | Variations of “of” |
|---|---|
|
Apb. Baron Bishop Bp. Compte Comte Conte Conti Count Countess Duc Duchess Duchesse Duke Earl Freifrau Freiherr Furst Graf Grafin Lady Marchioness Marquess Marquis Marquise Prince Vicompte Vicomte Viscount |
d’ de de di of von |

Dorothea Salo, 2009-11-23
Why do regex matching instead of string matching for the duplicate-surname situation?
Dianne Dietrich, 2009-11-23
An earlier version of the script handled the duplicate-surname situation using string matching. When we reviewed the results, there were cases where that code inadvertently garbled certain author strings, which is why I decided to try using a regex. It worked — that is, it didn’t garble strings the way my first attempt did — and so I kept the code as it was. That said, I’m sure it’s possible to accomplish the same thing using only Python string operations.