by Ross Singer
As the pursuit of the Next Generation Catalog (NGC) gains momentum, librarians and libraries are frequently looking outside of their traditional integrated library systems to achieve the kinds of functionality needed. Whether they be alternate search and discovery interfaces, such as Endeca, the University of Virginia’s BlackLight or Ex Libris’ Primo; social software applications such as PennTags or SOPAC; or combinations of the two such as Scriblio and VuFind, it becomes apparent that most libraries have a different definition of “next generation” and that few believe that “next generation catalog” has to be a component of the historical backbone of the modern library: the OPAC.
Georgia Tech’s library chose to take on many Web 2.0 concepts in its vision of the NGC: tagging, annotations, recommendations, faceted search, etc. The main focus of the project was to allow users and groups to collect their own personal libraries and use that community-based collection as the source of the central catalog: the Communicat. As users aggregate, annotate and share the resources they find and use, this in turn would expand and inform the larger Georgia Tech collection. The library and librarians would continue to add value, enhancing the metadata and content around the resources gathered that fit the scope of the institute’s mission.
Envisioning a Communicat
Roughly two years ago, the library formed a committee to work on this project. It was an informal group, with membership from Systems, Reference, Cataloging and Digital Initiatives, and had no clear objective or mandate. The main goal was to brainstorm ideas of what an ideal “catalog” would look like. A recurring theme was the rigidity of the incumbent catalog (Ex Libris’ Voyager) and the absence of any semblance of community control or input to what the library defined as its “collection”. The integrated library system had no capacity to evolve as new sources of information appeared about existing items or to build connections between items in the collection or with objects on the web. While the group did not actually produce anything substantive, it did manage to document many concepts and desires collectively via whiteboards and helped set the priority for how to proceed with such a project. Through the brainstorming, the essential services and their project names were conceived.
The major points uncovered were:
- The “catalog” does not begin to address the free web in any serious capacity.
- The de-emphasis of traditional cataloging (and subsequent de-emphasis of the cataloging department) requires a decentralized approach to metadata aggregation, composition, and maintenance.
- Relationships between items can be inferred by how they are used. If two resources are used for a particular project, there is a much stronger chance they have something in common. Explicit relationships between items should be set when appropriate: a movie version of this book; the soundtrack to this movie; the following proceedings appear in this conference. There was no intention to merge these records, but merely to make the connections between them clear.
- The scope of the “collection” is strongly dependent on the context in which the user is searching. If the user is a physics graduate student, weighting the resources that are defined as physics or sciences over, say, sociology would be desirable. There are times that searches would start “context-neutral”, but the ability to focus on particular subject areas, especially as the collection grows, could offset large result sets.
As these ideas began to take shape, some requirements for what such a system would need to be able to do became clearer. Versioning was essential; if authorship of metadata were to be distributed, a mechanism to roll back to a previous, stable snapshot would be necessary. Access control would also be important. For the integrity of consistency and discoverability in the “main” collection, some elements (such as the original MARC, Dublin Core or ONIX record metadata) would need to be controlled, but other aspects of the record would still be editable.
There also needed to be a separation between the machine-readable and highly structured elements and the public display interface. While the MARC records, et. al., would help define the display record, the public display would not merely be a literal representation of MARC (or ONIX or any other standard). The metadata records could then be preserved, without danger of being adulterated; yet the discoverability and readability of the resources could be altered as data and needs surrounding an asset changed.
Such a project also required a sense of users, groups and permissions. Not only would groups (or people) likely prefer that non-members not be able to manipulate the groups’ items and content, that sort of control would probably be necessary within the groups themselves as well, especially larger groups. This necessitated the concept of role on top of user and group. The downside of such granularity is that it generally makes interfaces to maintain resources more complicated, but the alternative, in the committee’s opinion, was too limiting.
The brainstorming work also provided a handful of desired services that could be broken out into individual projects that, together, would make up the Communicat. First, there needed to be a means to aggregate references to resources to add to the collection. Social bookmarking services, such as del.icio.us and especially Connotea and Cite-U-Like, were looked at as models to draw from. Given the need for more robust metadata, however, it was decided that utilizing the OpenURL link resolver to gather data from appropriate sources would be easiest way to meet this requirement.
Obviously, a system to store, index and manage these resources was also needed. It had to be able to deal with a variety of metadata schemes and flexible enough to accommodate data that it might not understand or be able to use. This data store also needed to be accessed through several different interfaces and act upon or display its contents accordingly. This repository was the largest and most important decision, since it influenced much of the direction of the project.
The other major service the group envisioned was the means to be able to organize one’s resources into various lists or categories. This would open the door for faculty to create their own reserves lists; librarians to create subject and course guides; and users to be able to make web-accessible bibliographies and reference lists. A possible outcome of this service was a concept the committee called Research Trails in which, as a user compiled and annotated resources for a given assignment or project or article, he or she created a bucket of information of all the resources discovered while researching their topic. While only a subset of these items would appear in the bibliography, the resources that led to the discovery of the actual materials cited would still be associated with the final product. The researcher in essence would, through the course of their work, make associations between our resources for us.
The goal was for any service to be independent of any other. The library could enable the personal library space without the community collection piece or the link resolver or any combination thereof. If the repository became too demanding to implement, it could be replaced with a simpler incarnation that met the revised needs of the users.
Putting the Vision into Place
Prioritizing the pieces of a project like this was non-trivial. There was only one developer, me, that could work on this project. It was difficult to commit significant resources towards it given its highly experimental nature, size, complexity and, frankly, its potential for failure. To devote time and people to a project that ultimately might not work or be largely ignored by our users runs counter to the traditional risk-averse culture of libraries. Also, like so many other libraries, Georgia Tech has a backlog of needs that also must be addressed, further straining the commitment that the committee could make on the Communicat.
With these conditions in mind, it was decided that it would make the most sense to begin with a piece of the project that solved other library needs outside of the requirements of the Communicat. The link resolver enhancements, known internally as the übeResolver, were targeted as a good starting point, since they also addressed problems we had resolving print materials and, possibly even more importantly, solved a major issue with conference proceedings. If this service was successful and obvious benefits could be seen in its development, then its success could be used to garner the political capital needed to prioritize development of the rest of the project.
Putting the Ü in OpenURL
The link resolver seemed the logical place for users to enter their data into the Communicat. The preferred variety of resources submitted to the system were scholarly (at least for the sake of the larger goals of the project), and theoretically, the OpenURL link resolver (at Georgia Tech, Ex Libris’ SFX) should be a nexus for citations as the researcher searches in the library’s licensed databases. Quite a bit of information can be gathered from the resolving process: where the user came from, what the user wants (eliminating the need to enter detailed metadata by hand or via screen scraping) and where they went. In practice, however, OpenURLs’ metadata can be rather spotty, so one of the goals of this service was to improve that as well as enable discovery of open access materials in repositories on the web.
What Tech developed was the Ümlaut (the name übeResolver was deemed too self-aggrandizing): an OpenURL middleware layer written in Ruby on Rails. The goal of the Ümlaut was not to replace SFX, since it handled the task of linking to full text resources quite well, but to enhance it, accessing SFX via its XML interface.
The Ãœmlaut queries Crossref, Pubmed, Georgia Tech’s catalog, the state union catalog, Amazon, Yahoo, Google and a host of social bookmarking sites for each incoming OpenURL to gather the most complete metadata snapshot of a given citation. Through Google’s and Yahoo’s web search APIs, it also analyzes the links to determine if any point to free manifestations in open access archives and present its findings along with the vended full text links.
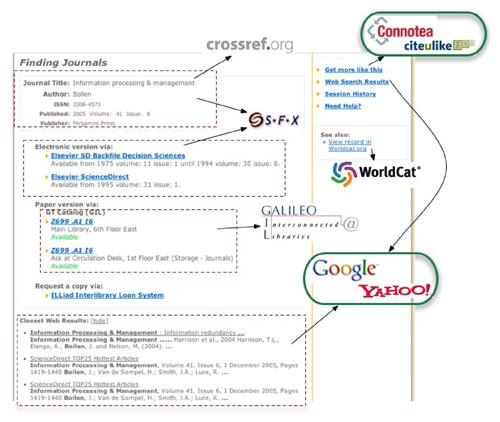 Figure 1. Diagram of Ãœmlaut Workflow
Figure 1. Diagram of Ãœmlaut WorkflowFrom the catalogs, it pulls MODS records (if the item was found), which offer much richer metadata than what is generally available in the OpenURL context object. By leveraging OCLC’s xISBN service, other manifestations of a particular work could also be found rather than relying on the exact ISBN sent in the OpenURL request. More sophisticated searches can be performed for different objects, further increasing the success rate for items such as conference proceedings.
Since the Ãœmlaut was to have fit into the broader context of the Communicat, machine-readable XML and JSON interfaces were created and exposed via unAPI. This allowed the Ãœmlaut’s services to be consumed by the OPAC or other applications. When the time came to develop the bookmarking service, resources could be enriched in the background without user intervention.
Development of the application proceeded quickly, going from proof-of-concept to production service in fewer than five months. Outside of the expected fits and starts of launching a new, heavily used resource, the Ümlaut was generally considered a success and the value it added over SFX offset its somewhat sluggish performance. The few months after its August 2006 launch were largely consumed with enhancements and bug fixes, and by January of the next year, planning had already begun on the next version, dubbed Ü2. The successful implementation and subsequent national attention of the Ümlaut (it was the winning entry in the 2006 OCLC Software Contest) gave us the credibility with the rest of the library needed to proceed with the next phase of the project.
In Search of a Repository
Now that we had a means to collect metadata, it seemed appropriate to find a place to store it. The challenge was to locate an existing system that was both extensible, versatile and, ultimately, replaceable if the needs or direction of the Communicat were to shift dramatically. As a last resort, the metadata store could be built from scratch, but we felt this was less desirable given the time it would take to design and develop and the fact that it would simply be easier to modify an established project and possibly alter our expectations than make something new.
Early in the process, before the more inspired goals from the whiteboard were drafted, the library considered using Unalog, a Python-based social bookmarking engine based on the Quixote web framework. While Unalog’s current implementation was rather modest in scope, Dan Chudnov, the project’s creator, had a desire to redesign its data model to utilize more detailed metadata, such as MODS. While appealing, the scalability of such an endeavor was unclear and, ultimately, the necessary refactoring never was made.
The nascent design ideas through this point had an assumption that the data would be stored as MODS, since it was more detailed than Dublin Core, but considered easier to work with than MARC. The Evergreen ILS was also briefly considered for the data store; Tech was interested in it as an ILS and it used MODS internally as its data model. The shortcomings of Evergreen (lack of acquisitions module or serials support) were a non-factor, since it was only going to be used as a bibliographic database. It, too, was eventually considered inappropriate for the expanding requirements of the project and was abandoned.
Through continued discussion, the expectation of using MODS was dropped and focus turned to more flexible repository frameworks. Georgia Tech’s Digital Initiatives department had considerable experience with MIT’s DSpace, but its architecture was deemed too monolithic to apply to all of our use cases. Fedora looked more attractive, as did the JSR-170 based repositories, such as Apache’s Jackrabbit. Either of these solutions would have required a considerable amount of development time to implement.
In the end, we finally settled on Outerthought’s Daisy Content Management System. While a CMS may seem an odd choice at first for such an application, Daisy has a unique design that suits itself well for alternative uses outside of traditional web page publishing. It actually is two separate Cocoon-based services: a backend XML document repository using MySQL and an optional front-end wiki interface. The document repository can be used entirely on its own and has Java, Javascript and HTTP APIs to access and manage its collection. The documents themselves are defined by schemas which are made up of various internally defined types: parts, where content is defined and stored, and fields, which are basically triples defined as strings, booleans, dates, long integers, etc. These are combined with document metadata, such as title and identifier to define the schema. Schemas can be changed after data has been entered using them, but fields cannot be deleted if any document is using them (although they can be marked deprecated).
Daisy maintains every version of a document, making it possible to roll back to a previous iteration. It also has the concept of branching a document, which is intended for having multiple editable versions of the same document if, say, the content of a document needs to be different based on the context in which it is being viewed. Coupled with yet another axis that Daisy documents can branch on, language, this can make for quite a complicated model. For our purposes, however, simple versioning would be sufficient.
Pushing Daisy
Now that we had identified our repository backend, it was time to build a framework to interact with it and model our data to make it work effectively within said framework. Since we wanted a layer of abstraction between the Communicat and its underlying data, we created another Ruby on Rails application named Cortex to interact with Daisy’s ReSTful HTTP API and manage the documents for indexing and display. Cortex was also tasked with manipulating MARC data to enter into Daisy, harvesting and ingesting Dublin Core records from OAI-PMH servers as well as normalizing and storing data from other sources (i.e. ONIX from the publishers). This made for a rather complicated metadata model.
The Daisy document schemas were divided into two groups: component documents, which stored the original metadata records; and page documents, containing the publicly viewed data as well as the association of the viewable record to its components. Page documents also defined the relationships between themselves and other page documents. Component documents held the original metadata, whether they were MARC21, Dublin Core, ONIX, OpenURL or whatever was available. For data for which no Component schema had been created, there was a GenericComponent so the resource could be preserved until it could be identified.
To aid with indexing and retrieval, important metadata – such as author, subject, ISSN/ISBN etc. – was stored in fields in the Component document. The page document held more high-level data about the resource, such as what its item type might be (serial, book, etc.) or whether or not it was a conference or a government publication. All pages stored the title, this being a requirement of Daisy. The relationship to the component documents was kept in a repeatable link field. In many ways, the page documents were very similar in philosophy to RDF, making connections between documents through URIs.
This architecture meant that for each item in the catalog, there had to be at least two Daisy documents. Phase II would require at least one more document per record as authors were to be split from the item records as Identity records. Communicat user records would also be Identity documents, so users could be associated with any works they may have created.
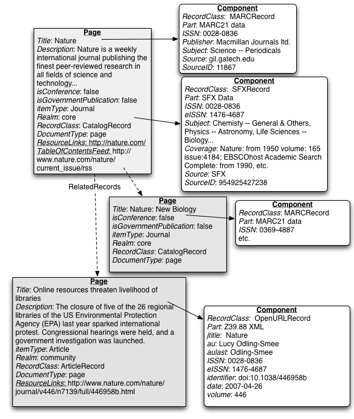 Figure 2: Schematic of Daisy table design.
Figure 2: Schematic of Daisy table design.The relevant documents surrounding a particular resource (a public Page document, its requisite component documents and identity records) were merged and indexed in Solr. The individual components were also indexed in Solr, so besides powering the main catalog search, Solr could also be used for administrative and maintenance tasks. Managing the relationship between Solr documents and Daisy documents was another responsibility of Cortex.
A fourth planned document type was the BookmarkPage, essentially a page to a page document. These documents would be associated with users (Identities) and contain annotations, tags and comments. Through BookmarkPages, users would be able to organize and share the item level page documents. Public bookmark annotations would be searchable alongside the standard bibliographic data, allowing dialog about resources to aid in their discoverability.
In an effort to allow users to control the scope of their searches, Communicat documents are assigned one of three Realms: core, community or world. The realms break down rather simplistically. Core resources are purchased or created by Georgia Tech. These would be items in the catalog; in DSpace, the institutional repository; databases; journals; or other sources across campus that serve the university’s mission. Community resources are those added by users actively enrolled or employed by Georgia Tech. This way a user’s search could include materials that their peers are vetting and commenting upon. Lastly, documents in the world realm are anything created by users outside the Georgia Institute of Technology. Searching these resources is optional, since they may or may not have any relevance to Tech users.
It was determined early that for maximum effectiveness, GaTher (as the social bookmarking/citation management service was called internally) would need to be open to people outside of Georgia Tech. Researchers frequently work with colleagues from other institutions, making this a necessity. This philosophy of openness also prevailed in the institution’s Sakai implementation, with each site receiving 50 guest logins for membership outside campus.
After a bit of development, some limitations in Daisy became apparent. Daisy had never been intended to scale to the numbers of documents we were proposing (which would be in the hundreds of thousands or much more, depending on popularity).
The first flaw we came across concerned the retrieval of large numbers of documents. Daisy has a very SQL-like query language that allows for retrieval of documents by structured queries. However, because of the access control lists, which must be determined post-query, Daisy returns all matching documents before sorting them by relevance and applying any query limits. For queries that could produce an extremely large number of documents (such as “select the ID for every CatalogRecord page document”, which would be required to delete them), the load on Jetty, MySQL and Cocoon overwhelms Daisy and the only way to keep all system resources from being consumed is to kill the Daisy repository server. An alternative to this method would be necessary since large maintenance tasks would be inevitable, especially during the development process.
It also was discovered that there was no capability to create or modify document schemas via the HTTP API. For these sorts of administrative tasks, the Daisy Wiki would need to be run in order to access the administrator interface. Fortunately, this would only be necessary in very specific cases.
Due to a shift of institutional priorities at Georgia Tech (largely due to my position being assigned to support the campus Sakai initiative and a massive reorganization within the library), development had to be stopped shortly after the capability to parse and insert records into Daisy and Solr was written. It is unclear whether or not this project will be completed.
GaTher: Bringing it all Together
The last component of the Communicat project, GaTher, was to be the public interface. This was the means that people would add items to their personal or group libraries and it was the way they would search within them. The concept is modeled strongly after social bookmarking sites such as del.icio.us or Connotea but with the capability of much richer metadata. It would also serve as a very crude citation manager, but merely for storage and organization of references. For formatted bibliographies, GaTher would export to applications more suited for that purpose, like EndNote, Zotero or BibTex.
The preferred path to add citations would be through the Ãœmlaut, which would have a link to the user’s preferred bookmarking service. If it is a service other than GaTher, the user will have the choice of adding it to both places, including a syndication feed in GaTher to harvest their public links or bypass GaTher altogether. We felt it important that the functionality did not interfere with the users’ normal workflows, so efforts would be made to allow them to retain the status quo.
Since it is likely that users will desire to add resources that would not fall in the typical OpenURL resolving chain, bookmarklets or browser extensions would need to be generated to jumpstart the process. It would also be desirable for GaTher to work with the LibX and Zotero extensions. As there was no desire to maintain a suite of screenscapers to pull metadata from the HTML pages, piggybacking on the screenscrapers used by Cite-U-Like, Connotea, or Zotero would lessen the burden, as would COinS (Context Objects in Spans) and UnAPI support.
Users would be able to organize their bookmarks any way they wish. They may annotate them, share them and open them for comments. Since users are members of groups, they also can comment on other’s entries. The bookmarks are associated with groups, it becomes possible to weight the Solr queries: resources saved by a group, or similar groups, would be ranked more highly than other materials. As such, the groups become a focused portal into the larger community collection.
The Future of Communicat
Sadly, with my departure from Georgia Tech, it is unlikely that the library will complete this project. There are not the resources to enable such a project. With the proposed launch of VuFind in the Spring 2008 Term, the library will be addressing its next generation catalog needs.
Now that I am currently employed by Talis, it is possible that the Communicat could become a Talis Platform application. Since the Platform is an RDF triple store, the data model would only need minor tweaking to apply. It was this sort of scenario, the Daisy component being replaced, that inspired development of Cortex, so architecturally, the design would not need to change. It would most likely have to become much simpler to be marketable from a vendor standpoint, however.
Observations
While several next generation catalog projects attempt to address some or part of the Communicat’s goals, none seemed to be quite as ambitious as Georgia Tech’s vision; perhaps pragmatically so. This was an extremely large project with each individual piece itself a noteworthy endeavor. Institutional support was imperative, but the goals of the initiative were difficult to comprehend. This, in turn, made it difficult to prioritize.
Daisy, despite its limitations, was a strong choice. It would have provided a flexible backend for a host of future services. Since it was primarily being used as a data store, however, possible alternatives could be a native RDF database or a document-centric database, such as CouchDB. Daisy has a very strong user community, though, and its natural capability to strongly define documents and create links between them is functionality that would need to be duplicated.
A project such as this is difficult to manage within a committee. When the concept is abstract and the end-result could change dramatically from week to week, an agile process is necessary. Many library cultures have a difficult time subscribing to that philosophy. It might be better for a core team of developers and implementers to design a proof-of-concept before a larger committee is formed.
The ideals of the Communicat, an organic organization of resources, collected by the library’s users and expanded and enhanced by librarians from every department, and not just cataloging are quite revolutionary and require considerable commitment from an organization. The benefits, however, are enormous: a catalog that reflects the actual research performed by those in the constituent community with current and topical added value layered on top by professionals within the library. Instead of shoehorning these services into our existing data silos or export the data from our silos verbatim into a third party search and discovery interface, wholesale revision of how data acts and interacts is necessary. Georgia Tech was unable to see this vision through completely, but perhaps a few of its goals can see their way into other library’s projects.
About the Author
Ross Singer is Interoperability and Open Standards Champion at Talis. He may be reached by email at rossfsinger@gmail.com.

Subscribe to comments: For this article | For all articles
Leave a Reply