By Ya’aqov Ziso, Ralph LeVan, and Eric Lease Morgan
Background
In order to enable OPAC users to retrieve materials by author or subject, MARC bibliographic records encode these names and subjects using pre-established authorized forms. In parallel to bibliographic records, authority MARC records encode names and subjects and trace the distinction between a preferred authorized name or subject and its traced references. The relationship between MARC bibliographic and authority record files enables library users to find the works linked to the name or subject they searched, even when the entered name or subject was a traced (non preferred authorized) name or subject. This mechanism for distinguishing and mapping names and subjects to works offers an advantage over less predictable keyword based searches used by Amazon, Yahoo, Google and their like.
Although the Library of Congress maintains global authority files for names (NAF) and subjects (LCSH), local OPACs require the use of local authority files. Keeping the local catalog’s bibliographic and authority files in sync with the global NAF and LCSH requires ongoing processes at each local library, usually accomplished via a third party vendor. Accordingly, keeping a library’s bibliographic and authority files up to date incurs additional costs each year. [1]
Since the early 1990’s, OCLC has made up-to-date NAF and LCSH files available for member institutions and their cataloging needs. Recently, these name and subject authorized files have been made available also through the WorldCat Web Services. This paper introduces and describes how to use several of these WorldCat Web Services that have the potential to help reduce the need for the local authority file maintenance by taking better advantage of OCLC’s access to centralized authority files. In the sample implementations provided, an API search of these web services links the library user’s search for a name or subject into a centralized name or subject file reliably maintained by the Library of Congress. In addition, we will also explore WorldCat’s Identifier Service, providing access to a centralized file of related ISBN numbers (xISBN) as a tool for finding bibliographic records related to each other according to the FRBR algorithm.
OCLC Web Services
WorldCat offers two kinds of authority data: 1) a collection of controlled vocabularies known collectively as WorldCat Terminology Services, and 2) a name authority file supplemented with non-authoritative names found in OCLC’s WorldCat Union Catalog known as WorldCat Identities. Through these services, WorldCat indexes are exposed to support searching for controlled terms and their traced variants as well as the identifiers for those terms. The indexes are also browsable, providing support for the ability to suggest terms. In our sample implementations, we took advantage of the browsability of the name index (Worldcat Identities) but not the browsability of the subjects index (Terminology Services).
This authority data is searchable also via a protocol called Search/Retrieve via URL (SRU) [2]. The idea behind SRU is rather simple:
- construct a URL complete with a set of standardized name/value pairs
- send the URL to a remote service (like OCLC’s WorldCat Identities or WorldCat Terminology Services)
- get search results back in XML or some other structured format
- transform the content for display or some other use.
Given such an infrastructure any number of interfaces can be created for a given index: an interface written for different audiences, an interface for different purposes, or an interface intended to be an intermediary for another service.
A cheat sheet for searching WorldCat Identities and Terminology Services is available [3].
WorldCat Terminology Services
Currently, the Terminology Services [4] offer SRU access to the following vocabularies:
- FAST – Faceted Application of Subject Terminology [5]
- TGM1 – Thesaurus for graphic materials: Subject Terms [6]
- TGM2 – Thesaurus for graphic materials: Genre & physical characteristic terms [7]
- GSAFD – Guidelines on subject access to individual works of fiction, drama, etc. [8]
- LCSH – Library of Congress subject headings [9]
- ACP – Library of Congress AC subject headings (for children’s materials) [10]
- MeSH – Medical Subject Headings [11]
A complete description of the indexes can be found online. [12] Vocabulary records can be retrieved as HTML, MARC XML, SKOS, and Zthes. For the Term Finder application described in this article, we used the FAST and LCSH databases.
WorldCat Terminology Services is still an experimental research service with no service level assurances. This means that uptime is not guaranteed and no official support is provided if the service becomes unavailable; during the course of this project it experienced several outages. In addition, the LCSH database proved to be over a year out of date. However, based on recent conversations, OCLC has established a schedule where each vocabulary should be updated once or twice a year.
OCLC is seeking community feedback to gauge the level of interest in the Terminology Services; problems, questions or general interest should be directed to the WorldCat Developer’s Network email list, which is monitored by OCLC staff. [13]
WorldCat Identities
WorldCat Identities [14] is based on the Library of Congress Name Authority File (NAF) and provides a Web page for every author in the WorldCat Union Catalog. These pages provide authority information for those authors that have been controlled in the NAF, as well as information derived from the WorldCat catalog records. SRU access to WorldCat Identities is available online. [15] It is composed from three databases: Corporate names, Personal names and Subject names. [16] Indexes are also provided to support direct searching for authors by LCCN or OCLC numbers, where a link to a known author is desired from a known catalog record. Records are returned in an XML scheme [17] specific to WorldCat Identities.
WorldCat Identities is considered a production service by OCLC and had no outage or database maintenance issues during this project.
WorldCat xISBN Service
Different from the authority-controlled vocabulary files, WorldCat’s xISBN Web service [18] returns ISBNs of bibliographic records related to a given ISBN in WorldCat along with selected metadata, such as title, author, and edition. The relationship between the retrieved ISBNs is based on an algorithm conforming to the FRBR model. [19] Unlike WorldCat Identities and WorldCat Terminology Services, the xISBN service supports standard REST-based or OpenURL queries.
WorldCat xISBN is also considered a production service by OCLC and had no outage or database maintenance issues during this project
Sample Implementations
To illustrate the use of the OCLC Web Services, a few example applications have been created. Given a word or phrase, the first application, Term Finder, searches a subject authority list and returns broader, narrower and use for (cross reference) terms allowing the user to navigate the related Library of Congress Subject Headings terms and select the proper term for their search. The second application, Name Finder, works similarly; given a first and last name it returns a list of matching authorized names along with a set of subject headings for the items the author has written. The third application, Send It To Me, searches xISBN and returns related works for a given ISBN for the purposes of local delivery. Each of the three example applications functions in a similar manner. Specifically, they:
- gather input from the user (term, name, or ISBN number)
- build a URL pointing to a remote authority or bibliographic service
- send the URL to the service on behalf of the user
- get back a response in the form of an XML stream
- parse the XML
- display the result
- repeat from Step #1 until done
Source code for each application is available online. [20]. The application code can be used with any bibliographic utility as long as the remote utility supports well-defined Web-based APIs, such as SRU; all that needs to be changed are the URLs denoted at the beginning of each script.
Term Finder
Given a word or phrase, Term Finder [21] sends a search to WorldCat Terminology Services. If the search matches an authorized subject, Term Finder displays broader, narrower and use for (cross reference) terms allowing the user to navigate the Library of Congress Subject Headings. If a cross reference or non-authorized tracing term is entered, Term Finder will return no results.
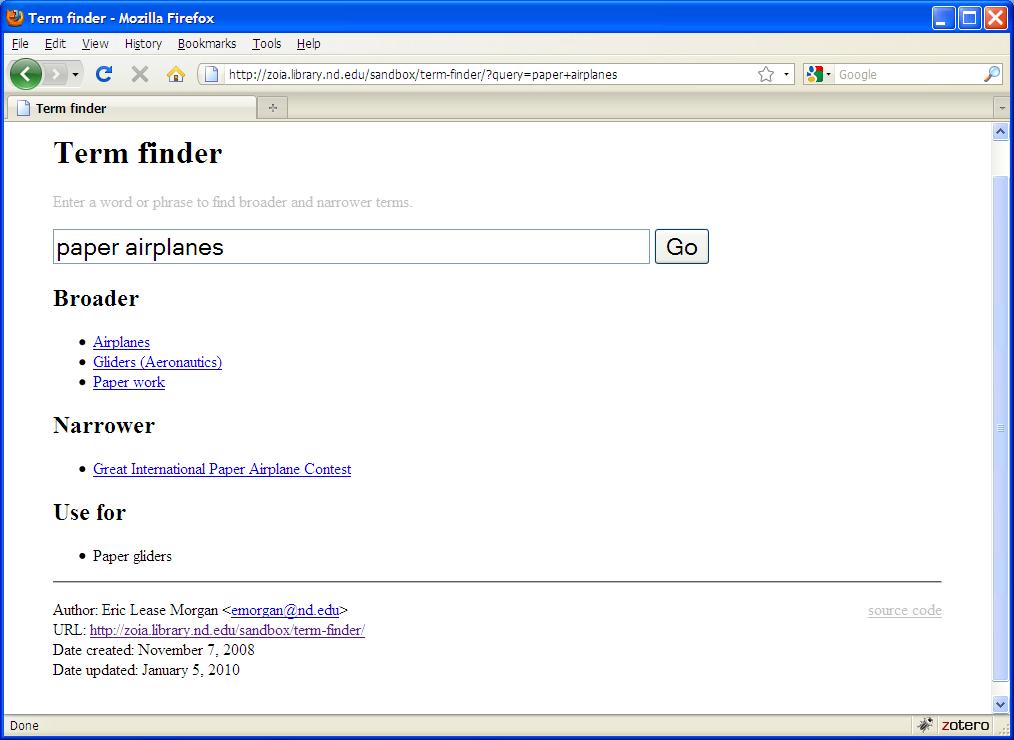 Figure 1. Term Finder search results for “Paper airplanes”
Figure 1. Term Finder search results for “Paper airplanes”
Code snippets from Term Finder illustrate the process used for these applications. First, a URL template is created pointing to an SRU-based bibliographic service: (carriage returns have been added for readability):
http://tspilot.oclc.org/lcsh/? query=oclcts.marcTags+%3D+%22150%22+ and+oclcts.preferredTerm+%3D+%22##INPUT##%22& version=1.1& operation=searchRetrieve
Next, the user’s input is captured, and is used as a replacement value for ##INPUT##. This URL is then sent to the remote host and a standard SRU response is returned. The response is parsed for broader, narrower and see terms using an XSL stylesheet. Specifically, the stylesheet loops through the MARC 550 elements whose attributes equal “w.” It looks for attributes in the same element equaling “g” or “h.” [22] If found, then the values located in attribute “a” are extracted and pushed into a simple data structure: a line of broader terms delimited by tab characters and a line of narrower terms also delimited by tab characters. The see references are simply extracted from MARC 450 subfield a. Listed here is the core of the stylesheet:
<!-- broader -->
<xsl:for-each select='//slim:datafield[@tag="550"]/slim:subfield[@code="w"]'>
<xsl:if test=".='g'">
<xsl:value-of select = '../slim:subfield[@code="a"]' />
<xsl:text>	</xsl:text>
</xsl:if>
</xsl:for-each>
<!-- delimiter -->
<xsl:text>
</xsl:text>
<!-- narrower -->
<xsl:for-each select='//slim:datafield[@tag="550"]/slim:subfield[@code="w"]'>
<xsl:if test=".='h'">
<xsl:value-of select = '../slim:subfield[@code="a"]' />
<xsl:text>	</xsl:text>
</xsl:if>
</xsl:for-each>
<!-- delimiter -->
<xsl:text>
</xsl:text>
<!-- see -->
<xsl:for-each select='//slim:datafield[@tag="450"]/slim:subfield[@code="a"]'>
<xsl:value-of select = '.' />
<xsl:text>	</xsl:text>
</xsl:for-each>
Finally, the script hyperlinks the returned broader and narrower terms back to the Term Finder application. At this point the terms could be used to query just about any type of bibliographic database/index.
Name Finder
Name Finder [23] works similarly to Term Finder. [24] Given a first and last name this application returns a list of matching authorized names along with a set of subject headings for the items each author has written. Unlike Term Finder, should a cross reference or non-authorized tracing to a name be entered, the results will point the user to the main authorized form of the name.
After the user enters the name of an author, the input is inserted into a URL template which is sent off to an SRU server. As with Term Finder, a response is returned, parsed, and presented to the user. However, in this particular case, the authorized subject terms associated with the works written by the author are also displayed, anticipating the user’s need to find the subjects that the name is associated with. These authorized subject terms are then hyperlinked to the Term Finder application for possible followup.
 Figure 2. Name finder search results for “Melville Dewey”
Figure 2. Name finder search results for “Melville Dewey”
Send It To Me
The third application, Send It To Me [25], first takes an ISBN number as input and searches a local catalog for the given item. If the ISBN is found in the local catalog, it allows the user to request local delivery of the item. If not found, it uses OCLC’s xISBN web service to generate a list of similar items. If xISBN fails, ThingISBN is queried as well. Using the ISBN numbers returned from these services, new searches are applied against the local catalog to determine whether these related items are available for local delivery. None of these catalog searches use SRU, but rather the proprietary X-Services of Ex Libris. [26] If none of these ISBNs are available locally, it allows the user to search for similar books by author or subject (see Figure 3). If xISBN and ThingISBN do not return any ISBN numbers, then the application fails gracefully asking the user to validate their input.
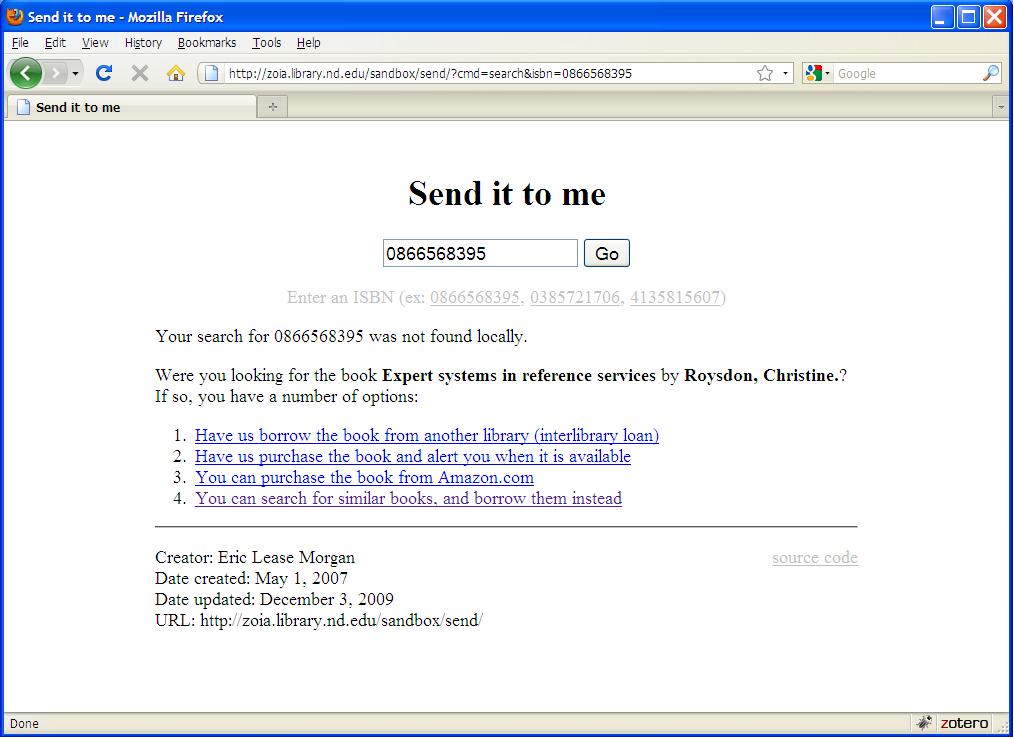
Figure 3. Send It To Me search results for 0866568395
Recent WorldCat Services Enhancements
Since the beginning of our research, OCLC Research has continued its ongoing refinements of the WorldCat Identities and Terminology Services and expanded the options for name and subject queries. These new tools are additional options that could be used in applications like the sample implementations described in this article.
An auto-suggester [27] has been created for WorldCat Identities whereby a user typing in a search is instantly given the list of name options from which they can, ‘on-the-fly’, choose the desired entry. After searching for this entry, they will see WorldCat.org results for this author. A similar FAST auto-suggester [28], has been established also for subjects, enabling searchers to choose the proper subject term from a list and then display all available WorldCat.org results for that subject. Both of these tools are powered by underlying web services with more concise responses than their SRU counterparts described and utilized in this article.
Next Steps
Based on the methodologies explored in this article, a next logical step would be to embed auto-suggesters in the local library’s Web page, enabling a direct ‘on-the-fly’ lookup of authorized names and subjects. Once the user selects an authorized name or subject, it can be then sent to a followup search interface, such as the local catalog or another WorldCat Service. Research in that direction has already been broached [29] in the development of a next generation discovery portal (VuFind’s 1.0) in support of the following workflow:
- the user enters a search term in the VuFind interface. While the user types, data may be sent to an “AutoSuggest” plug-in specific to the current search type. This plug-in may be used to help the user choose the proper name or subject entry.
- the selected search term is sent to VuFind’s Solr index for normal searching, and it is also sent to a “Recommendations” plug-in specific to the current search type for WorldCat global and/or consortial recommendations.
- A “Recommendations” box appears at the top of the search results containing links to possible alternative searches that may yield additional or better results.
Finding the proper name or subject using the auto-suggesters would maximize the benefit of using WorldCat’s consistently maintained and up-to-date NAF and FAST files. At the same time, this would further minimize the need to process and maintain the institution’s local NAF and LCSH.
Conclusion
The sample implementations described in this article function similarly in that they:
- exploit centralized external indexes that could be used to enhance searches in the local catalog and
- provide references for users to follow up initial searches, following a logical workflow for the user’s queries.
By expanding the scope of searching a name, subject, or ISBN beyond the local catalog, all three implementations go outside the local catalog to retrieve information that can be used within the local context. This takes advantage of the consistent upkeep and accuracy of information in the WorldCat databases. When integrated with the local catalog, tools like these could possibly provide a new context for reviewing the costs required to maintain local authority files and might enable institutions to reduce local costs by relying on existing centralized services.
Notes
[1] For example loading the updated files requires additional local labor and costs around $6,000 yearly for a collection of about 600,000 titles. After an initial setup of $30,000 for 600,000 records (@$0.10 a record – see http://www.authoritycontrol.com/RATES.html) our library sent every month records for about 1,000 newly acquired books (@$0.10 a record = $100 monthly, $1200 yearly – see http://www.authoritycontrol.com/aexinit.php) and updated the whole database 4 times a year (@$1200 per run – see http://www.authoritycontrol.com/aupinit.php).
[2] For more information about SRU see the Library of Congress’s website: http://www.loc.gov/standards/sru/ or an introductory article in Ariadne, http://www.ariadne.ac.uk/issue40/morgan/.
[3] WorldCat Identities / Terminologies cheat sheet, http://worldcat.org/devnet-real/images/8/8b/Terminologies.pdf
[4] WorldCat Terminology Services, http://www.oclc.org/research/activities/termservices/default.htm
[5] Terminology Services – FAST, http://tspilot.oclc.org/fast/
[6] Terminology Services – Thesaurus for graphic materials: TGM I, http://tspilot.oclc.org/lctgm/
[7] Terminology Services – Thesaurus for graphic materials: TGM II, http://tspilot.oclc.org/gmgpc/
[8] Terminology Services – Form and genre headings for fiction and drama, http://tspilot.oclc.org/gsafd/
[9] Terminology Services – Library of Congress Subject Headings, http://tspilot.oclc.org/lcsh/
[10] Terminology Services – Library of Congress AC subject headings (for children’s materials), http://tspilot.oclc.org/lcshac/
[11] Terminology Services – Medical Subject Headings, http://tspilot.oclc.org/mesh/
[12] Terminology Services – Indexing Information, http://tspilot.oclc.org/resources/indexing-information.html
[13] See http://worldcat.org/devnet/wiki/Main_Page for more information about the WorldCat Developer’s Network and a link to subscribe to the email list.
[14] WorldCat Identities, http://www.oclc.org/research/activities/identities/default.htm
[15] WorldCat Identities SRU search, http://WorldCat.org/identities/search/Identities
[16] Search Corporate names: http://worldcat.org/identities/search/CorporateIdentities
Search Personal name: http://worldcat.org/identities/search/PersonalIdentities
Search Subject name: http://worldcat.org/identities/search/SubjectIdentities
[17] Although no official schema has been issued, information on the retrieved metadata is available in this presentation from WorldCat Hackathon in November 2008: http://www.oclc.org/research/presentations/levan/hackathon-identities.ppt (see slides 10-22) and at http://worldcat.org/devnet/wiki/Identities.
[18] WorldCat xISBN web service, http://www.worldcat.org/affiliate/webservices/xisbn/app.jsp
[19] Functional Requirements for Bibliographic Records, http://en.wikipedia.org/wiki/FRBR
[20] Source code for each application is available both as a single text file and a package including all supporting files.
[21] Term Finder, http://zoia.library.nd.edu/sandbox/term-finder/
[22] According to MARC21 Format for Authority data, the value ‘g’ in field 550 subfield w stands for an established broader term, and the value ‘h’ for an established narrower term.
[23] Name Finder, http://zoia.library.nd.edu/sandbox/name-finder/
[24] Our Name Finder application is different from WorldCat’s NameFinder service that can be used to submit fuzzy queries to WorldCat Identities. See http://outgoing.typepad.com/outgoing/2008/06/linking-to-worl.html for more information about WorldCat’s NameFinder service.
[25] Send it To Me, http://zoia.library.nd.edu/sandbox/send/
[26] The X-Server provides access to Ex Libris’ Aleph Integrated Library System via web services. Available documentation is proprietary.
[27] Identities auto-suggest page, http://orlabs.oclc.org/identities/autosuggest.html
[28] Fast auto-suggest page, http://orlabs.oclc.org/FAST/autosuggest.html
[29] “Embedding Name and Subject auto-suggesters in VuFind’s search template” by Demian Katz & Ya’aqov Ziso (work in progress).
About the Authors
Ya’aqov Ziso (yaaqovz@gmail.com) has been working with bibliographic, holding, and authority records and services since 1989, in the US and overseas. He has been chiefly involved with API queries and recent OpenSource venues on the semantic web. Currently, he is digital archivist for the Herbert Brun Society.
Ralph LeVan (levan@oclc.org) is a Senior Research Scientist in OCLC Research. Lately he has been working on Identity issues and authority databases in general. He is a member of the SRU standards group within OASIS and seems to find a way to put an SRU server at the bottom of all his technology stacks.
Eric Lease Morgan (emorgan@nd.edu) works at the Univesity of Notre Dame where he is the Head of the Digital Access and Information Architecture Department. He considers himself to be a librarian first and a computer user second. His professional goal is to discover new ways to use computers to provide better library service.

Jonathan Rochkind, 2010-11-01
It should be noted that the FAST auto-suggester has been discontinued by OCLC as of this writing.
The Identities auto-suggester seems to still be available; I’m not entirely sure whether OCLC considers this an experimental service which could be discontinued at any time, or a production service which is unlikely to be discontinued, and for which notice would be given for discontinuing.