By Meikiu Lo and Leah M. Thomas
Introduction
The Library of Virginia (LVA) is a state library and is responsible for collecting and distributing state publications to designated Virginia depository libraries.[1] Due to the increasing number of born digital publications, LVA began developing the Digital Virginia State Publications Collection in 2006 to accommodate the digital publications of over 140 state agencies, including LVA. Two full-time professional library staff are devoted to the development and maintenance of this collection. One staff member trains agency contributors, or endusers,[2] while the other is responsible for the metadata, cataloging, and management of the digital publications. DigiTool, an ExLibris product, was selected to manage the collection.
The Library of Virginia’s Depository Program
Although LVA was established as Virginia’s state library in 1823 and has been collecting government materials since that time, it was not designated as a depository library until 1981. The State Publications Depository Program’s purpose is to ensure that the public has access to government information as mandated in §42.1-92 of the Code of Virginia.[3] Because state publications were increasingly being born digital, LVA needed a way to provide the public with access to these publications and to maintain the collection in conformance with its responsibility as a government publications depository.
LVA began working with selected agencies in December, 2007, to test the digital program. The first general request for volunteer agencies was February-March 2008. In July, 2008, the program was switched to the production server. The second and third requests for volunteer agencies occurred in August and October, 2008. The general training sessions were done largely in-house due to the proximity of many state agencies to LVA and the availability of an onsite computer lab with staff to assist with training. Additionally, due to budget constraints that restricted travel during the latter half of 2008, LVA implemented alternate methods of offering training for agencies, colleges, and universities not located in the local area, which included offering one-on-one telephone training sessions. These sessions usually took about 10-20 minutes and have been as successful as the in-house training sessions, as determined by the feedback and depository submissions from these agencies. A step-by-step workflow with screenshots was sent to all trainees. Approximately ninety agencies received training.
Why DigiTool?
Prior to 2006, when LVA was considering a digital asset management system, two primary needs were taken into consideration: 1) a system’s flexibility to be used across collections and 2) system support, maintenance, and development. The foremost reason that DigiTool was selected was because of the reputed administrative and technical support that ExLibris was providing to the user community[4] and the company’s efforts toward digital preservation. ExLibris assured LVA that it would provide LVA staff assistance with any maintenance, development, and support issues for DigiTool’s implementation, operation and functionality, which it has done. LVA also considered CONTENTdm; however, at the time it was determined that this management system could not handle the governor’s records according to the needs of LVA. LVA wanted one system that would provide the functionality for maintaining every type of digital content.
LVA is a small institution without the staff infrastructure, including the assistance of graduate students, for onsite development. Consequently, open source products that LVA considered were not an option because they required onsite development. Open source systems did not have the same level of technical and development support that proprietary products had. [5] Open source products today, however, may no longer require the same level of onsite support.
DigiTool was selected to enable the Virginia State Publications Depository, as well as collection management, access, and preservation of varied digital collections. For the purposes of the Depository, DigiTool allowed LVA to create depositor profiles with email notification for off-site users, and agency login accounts so that endusers at the agencies could deposit agency publications. An enduser repository system was preferred because agency employees would know better than LVA would, when their electronic publications were available. The agencies would be able to deposit their digital publications themselves without LVA having to search for them, with the possibility of some publications being missed.
Other reasons for selecting DigiTool were customization, functionality, and synchronization with Aleph, LVA’s ILS, which is also an ExLibris product. Many of the digital publications managed by DigiTool are also cataloged in both OCLC Connexion and Aleph. Instead of cataloging these publications twice, the metadata could be transferred to Aleph through the synchronization of DigiTool and Aleph. Automated synchronization could be done selectively by transferring specific data from Aleph to DigiTool and vice versa, which was preferable to not having control over what data gets transferred to and from either program. Selective synchronization would be beneficial when modifications were made to records in either system. Both Aleph and DigiTool use Z39.50 protocol,[6] enabling the retrieval of records from different databases, such as the Library of Congress, or reciprocation between Aleph and DigiTool. The Z39.50 feature in DigiTool is essential for locating and attaching pre-existing Machine-Readable Cataloging (MARC) records from Aleph.
Although LVA chose DigiTool for the aforementioned benefits, some drawbacks have been discovered. While DigiTool can locate an Aleph record, once it is located, the record cannot be opened. It can only be linked, and is identifiable by displayed information, such as the title, call number, and year. When creating “objects,” as they are called in DigiTool, and linking to metadata and other objects, it has to be done by the persistent DigiTool internal ID (pid) numbers, rather than by title, author, or another access point. In order to locate a record in Meditor, the metadata editor utility, the pid has to be known in order to retrieve a digital object or its metadata that have been imported or created. Meditor is not a user-friendly interface for catalogers. It is not intuitive and changes to records are not made easily. An entire record may have to be deleted in order to make changes. Fields have to be deleted rather than changed.
Only limited reports can be generated. For example, instead of being able to generate a report to indicate the number of electronic publications ingested every month, a monthly collection had to be established in DigiTool in order to record the number of these publications, as elaborated below. Another drawback is only one mapping schema can exist for all collections in DigiTool, and once a schema is set, it is not easily changed, so there is little flexibility, if any, for switching Dublin Core (DC) elements. Also, no authority control exists in DigiTool’s infrastructure. Standards for metadata and access points have to be determined locally and documented for purposes of consistency and having an institutional record of what was done and the rationale for it.
Metadata Issues and Best Practices
LVA houses both library and archival collections and is required to archive and manage the governor’s communications as well, from the more traditionally scanned objects, such as photographs, maps, and manuscripts, to digitally born publications, including email and video. Both Acquisitions and Access Management (AAM)[7] and Archives are further broken down into collections: Archives includes Private Papers and Local and State Records; AAM includes Special Collections, the Map Collection, and Federal and State Documents.
Initially, three catalogers worked on three projects simultaneously: state publications, special collections, and the map collection. Each was described differently, using inconsistent DC elements and labels. State publications that were born digital were described in DC and were referred to as “native” DigiTool objects. However, digital resources that had already been cataloged in OCLC and LVA’s ILS were for the original copy, e.g. paper, not the digital reproduction. This did make it easier for catalogers because the MARC record could be imported into DigiTool and linked to the image, but the distinction between description of the original and description of the digital object needed to be made. Also, because of workload and time constraints, differences in description and punctuation in the MARC records were not modified, so the catalogers had to allow for some flexibility in standards, and thus in presentation, of metadata.
As a result of these metadata issues, especially the inconsistency in standards, an ad hoc metadata standards working group was formed from those who would be creating the metadata. Because there were different collections being entered without any centralization, they were being cataloged using different practices for each collection along with different mappings. The goal of the ad hoc metadata standards working group was to develop a mapping schema and best practices for the collections which were already in DigiTool and for future collections. The group met to determine the mapping for the MARC fields and labeling for the individual collections and for the generic overall DigiTool display, based upon the collections that had already been entered. Because it was not known what to anticipate for each collection, it was determined the best way to proceed was to be as specific as possible in the mapping and the application of DC elements, while allowing for flexibility.
Once the application of DC elements and mapping was accomplished, each cataloger devised a data dictionary for each collection. Additionally, the group had to resolve discrepancies in controlled vocabulary and abbreviations as they arose. It helped to review the best practices of other institutions. These, including crosswalks and data dictionaries,[8] were developed based upon those that already existed within the metadata community, such as those of Colorado State University,[9] Boston College,[10] Cornell University,[11] and Virginia Commonwealth University,[12] in addition to the standards established by the Open Archives Initiative (OAI),[13] and following the Dublin Core Metadata Initiative (DCMI).[14]
DigiTool’s feature for electronic submission, which was developed primarily for theses and dissertations, was utilized for the digital state documents depository. This feature allowed us to create a form which requires the submitting agency to complete the six required DC elements, including language, on the deposit form interface. The optional DC elements, in addition to the required ones, are title, creator(s), summary, keyword(s), and subject(s) as shown in Figure 1.
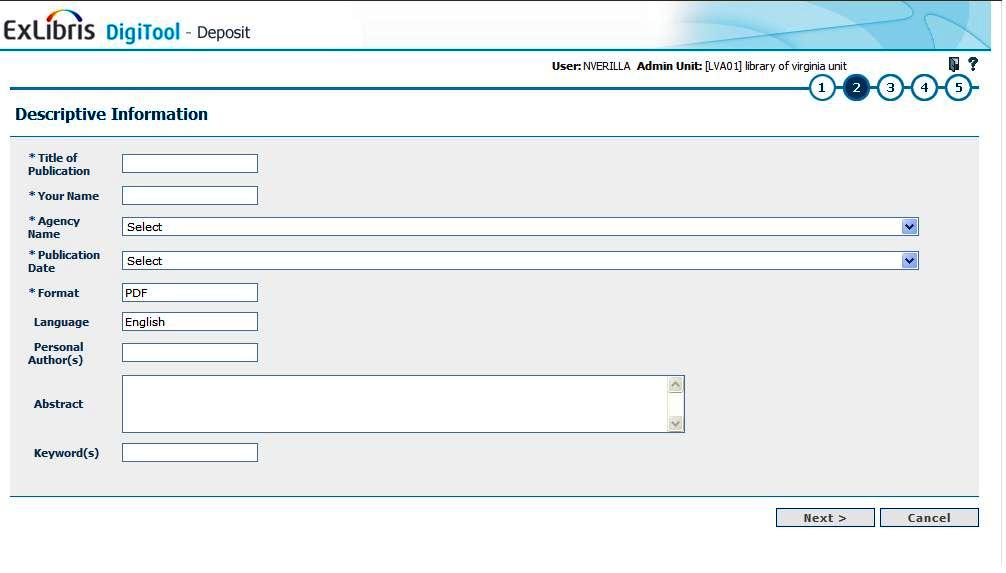
Figure 1. LVA deposit form Click here for larger image
Two sets of labels were necessary: one for DigiTool overall that applied globally to all collections and another, collection-specific set. A data dictionary was developed to define the usage of the labels so that they would be used consistently throughout all of the collections. An unanticipated mapping issue that arose was duplicate fields, a result of mapping with MARC where these mapped fields were also applied to native DigiTool records originally described in DC only. (See figure 2 for an example). Because DigiTool can handle only one mapping schema across collections, it imposes this mapping onto all collections, as shown in figure 2A, below. This issue of duplicate fields has not yet been resolved.
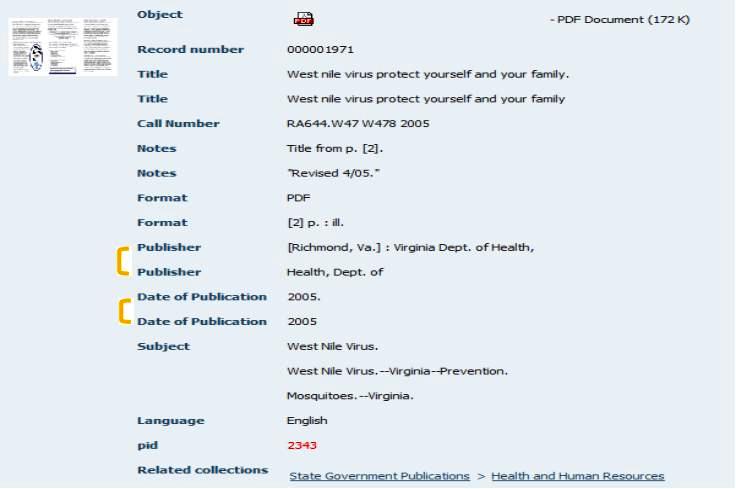
Figure 2. Issues in mappings: duplicate fields Click here for larger image

Figure 2A. Issues in mappings: duplicate fields Click here for larger image
As mentioned previously, DigiTool required one mapping schema for all LVA projects. But having only one schema caused inconsistencies in the presentation of metadata, (see Figure 3), due to the MARC mapping overriding the DC description. For sorting purposes, the agency name is used instead of division and unit as publisher.
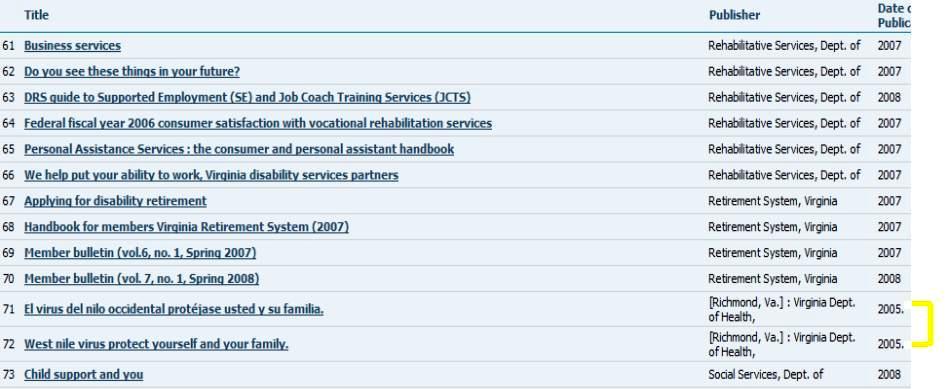
Figure 3. Issues in mappings: one mapping schema for all collections Click here for larger image
Records have to be reviewed for various unexpected problems, and documentation has to be updated as fields become obsolete. Figure 4 shows mappings, including both the DC elements and labels, for the state documents collection. The example identified in figure 4 is the 440 field, which is now obsolete. The 490 field will need to be added, as well as a footnote documenting the reason for the change so that a historical record of the changes is maintained. In addition to having changes in bibliographic standards, there are issues related to the system itself over which the cataloger has no control, as noted above in figures 2 and 3.
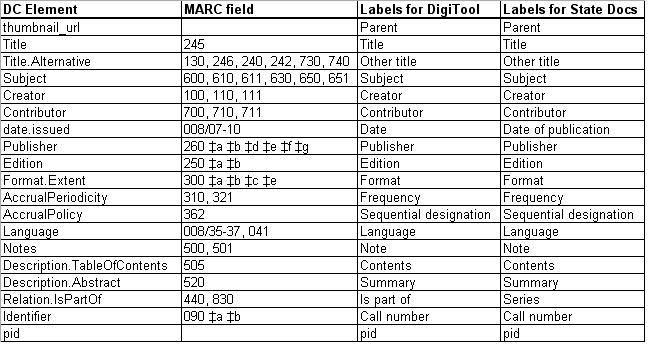
Figure 4. Mappings Click here for larger image
Like the University of Minnesota, LVA discovered that well-prepared mapping and a well-established taxonomy in the beginning may have decreased the amount of work that had to be done later. In this case, where only one mapping schema could be used for all collections, and the same practices across collections, necessary for access purposes, needed to be followed for each collection as well. Developing standards would have gone more smoothly had it been centralized with someone designated in charge. Semantic differences arose on how to use various DC elements. It was even suggested that we did not need best practices for description of resources across collections because DC allows for more flexibility than MARC with AACR2. The aforementioned documentation from the digital library community helped resolve many of these issues. Yet, there is still a tendency among different departments to apply DC elements and labels however they want due to the lack of official centralization of metadata standards.
We had thought developing the taxonomy retrospectively might actually save work because the necessary categories would not be determined until LVA started receiving the digital publications. But because the taxonomy for the state documents collection was not developed until later, thousands of records had to be re-linked. Although these records did not require re-cataloging or additional fixes, the re-linking was time-consuming. Re-linking such a considerable number of records was not anticipated, and it was not realized that DigiTool would be as difficult to manipulate as it was.
Although no authority control exists in DigiTool, the name authority used in the ILS could not be used because it would have caused problems with sorting within the State Documents Collection. If the name authority that is used in the ILS were used for the State Documents collection, for example, every one of them would begin with “Virginia.” An agency directory, as a drop-down list, was used on the depository form instead. The public is generally more familiar with the agency name and can use it for searching. However, the established authority is used in other collections because it does not cause the same types of sorting problems.
Collection Management Issues
When endusers submit digital publications, the objects are ingested into DigiTool, after the approval of the State Publications Librarian. DigiTool extracts the administrative metadata, and the State Publications Cataloger modifies metadata provided by the depositor, adds descriptive metadata, and organizes the digital content. The sample below shows administrative metadata from the ingest process: the pid (35387) for the object; the issue (no. 51, November 2009); the deposit number (441453); the name of the ingested item (“Virginia Water Central, v. 51”); the partition, or collection, (“statedoc”); as well as the date, time, and name of the person who ingested the deposited publication. Figure 5 shows the Meditor view of this metadata.
<xb:digital_entity xmlns:xb="http://com/exlibris/digitool/repository/api/xmlbeans"> <pid>35387</pid> <control> <label>no. 51, November 2009</label> <note xsi:nil="true" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" /> <ingest_id>dep441453_ing3537</ingest_id> <ingest_name>Virginia Water Central, v. 51</ingest_name> <entity_type xsi:nil="true" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" /> <entity_group xsi:nil="true" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" /> <usage_type>VIEW</usage_type> <preservation_level>any</preservation_level> <partition_a>statedoc</partition_a> <partition_b xsi:nil="true" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" /> <partition_c xsi:nil="true" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" /> <status xsi:nil="true" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" /> <creation_date>2010-01-06 10:51:06</creation_date> <creator>creator:NVERILLA</creator>
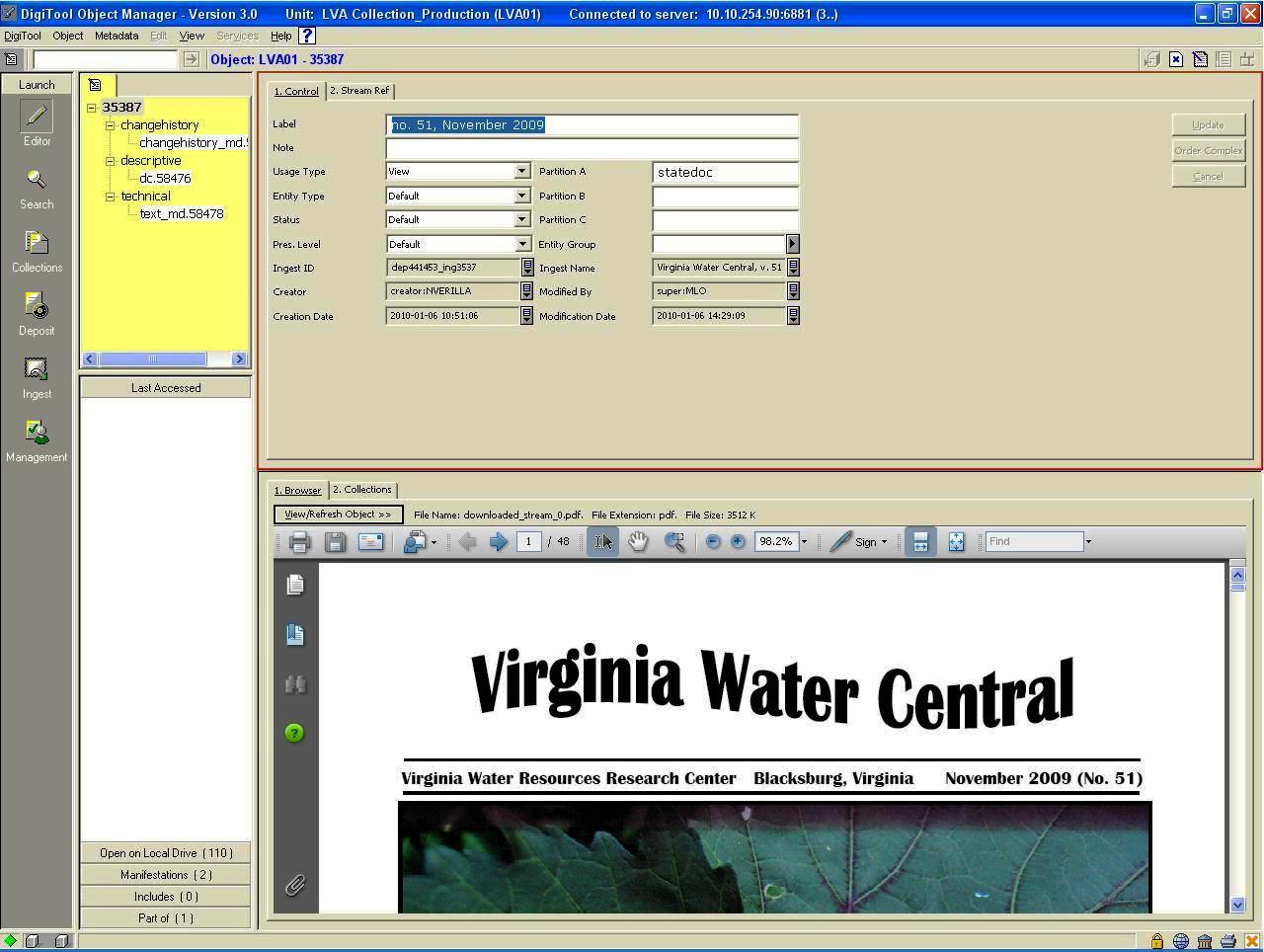
Figure 5. Meditor view: Administrative metadata Click here for larger image
The cataloger reviews the data and makes modifications, such as formalizing the title to make it consistent with the one in Aleph and adding the issue date and subjects (descriptive metadata) to the ingested object. Additionally, because the metadata submitted by the enduser is not always consistent or correct, the cataloger has to review and modify that metadata as well. The sample data below indicates changes applied (that the metadata is descriptive and in DC and when and by whom it was modified). “Water-supply – Virginia – Periodicals,” for example, is a Library of Congress Subject Headings (LCSH). The Meditor view of the added descriptive metadata is shown in Figure 5A.
<modification_date>2010-01-06 14:29:09</modification_date> <modified_by>super:MLO</modified_by> <admin_unit>LVA01</admin_unit> </control> <mds> <md shared="false"> <mid>58476</mid> <description /> <name>descriptive</name> <type>dc</type> <value> <?xml version="1.0" encoding="UTF-8"?> <record xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:dcterms="http://purl.org/dc/terms/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <dc:title>Virginia water central (no. 51, November 2009)</dc:title> <dc:stateemployee>Nathan Verilla</dc:stateemployee> <dc:publisher>Virginia Water Resources Research Center, Virginia</dc:publisher> <dc:date>2009</dc:date> <dc:format>PDF</dc:format> <dc:language>English</dc:language> <dc:subject>Water-supply -- Virginia -- Periodicals</dc:subject> <dc:subject>Water resources development -- Virginia -- Periodicals</dc:subject> <dc:subject>Water -- Pollution -- Law and legislation -- Virginia -- Periodicals</dc:subject></record> ]]> </value>
Initially, the DC element “contributor” was used to identify the state employee who deposited the digital content. However, because every digital collection in DigiTool had to have the same mapping, the cataloger would have to delete that field for each record, since the depositor was not to be displayed to the public. The “contributor” element, however, is publicly displayed. Therefore, the field “state employee,” which was unique to the State Documents collection, was created, as shown in Figure 5A. This field does not display to the public and, thus, does not have to be deleted.

Figure 5A. Meditor view: Descriptive metadata Click here for larger image
The parent-child relationship, or complex object, is used to manage continuing assets, such as periodicals. Figures 6 and 6A illustrate an example of a complex object in Resource Discovery (RD), the user interface that displays searchable digital content and metadata, while figure 6B shows the Meditor view.

Figure 6. Parent-child relationship, or complex object Click here for larger image
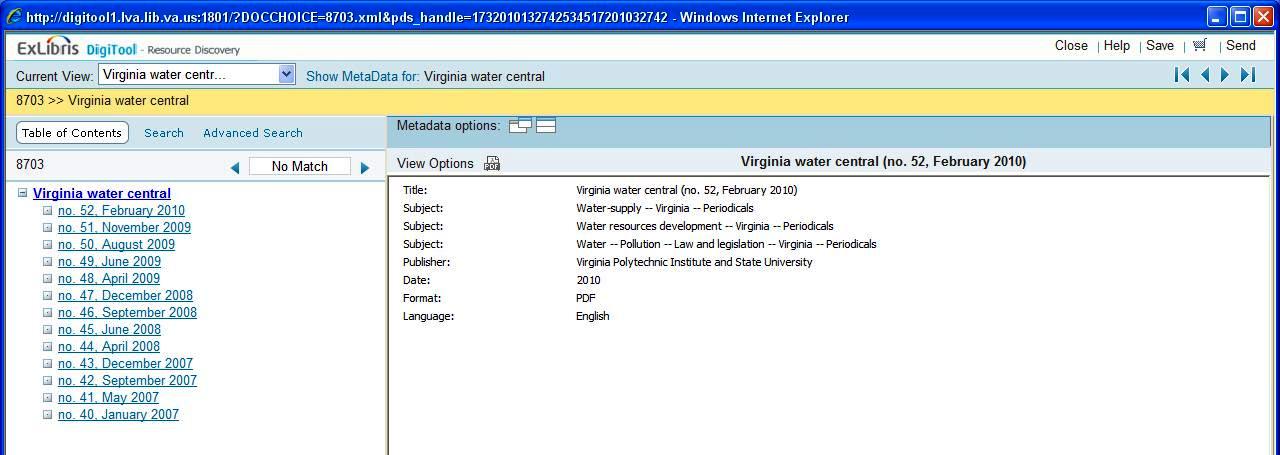
Figure 6A. Parent-child relationship, or complex object Click here for larger image
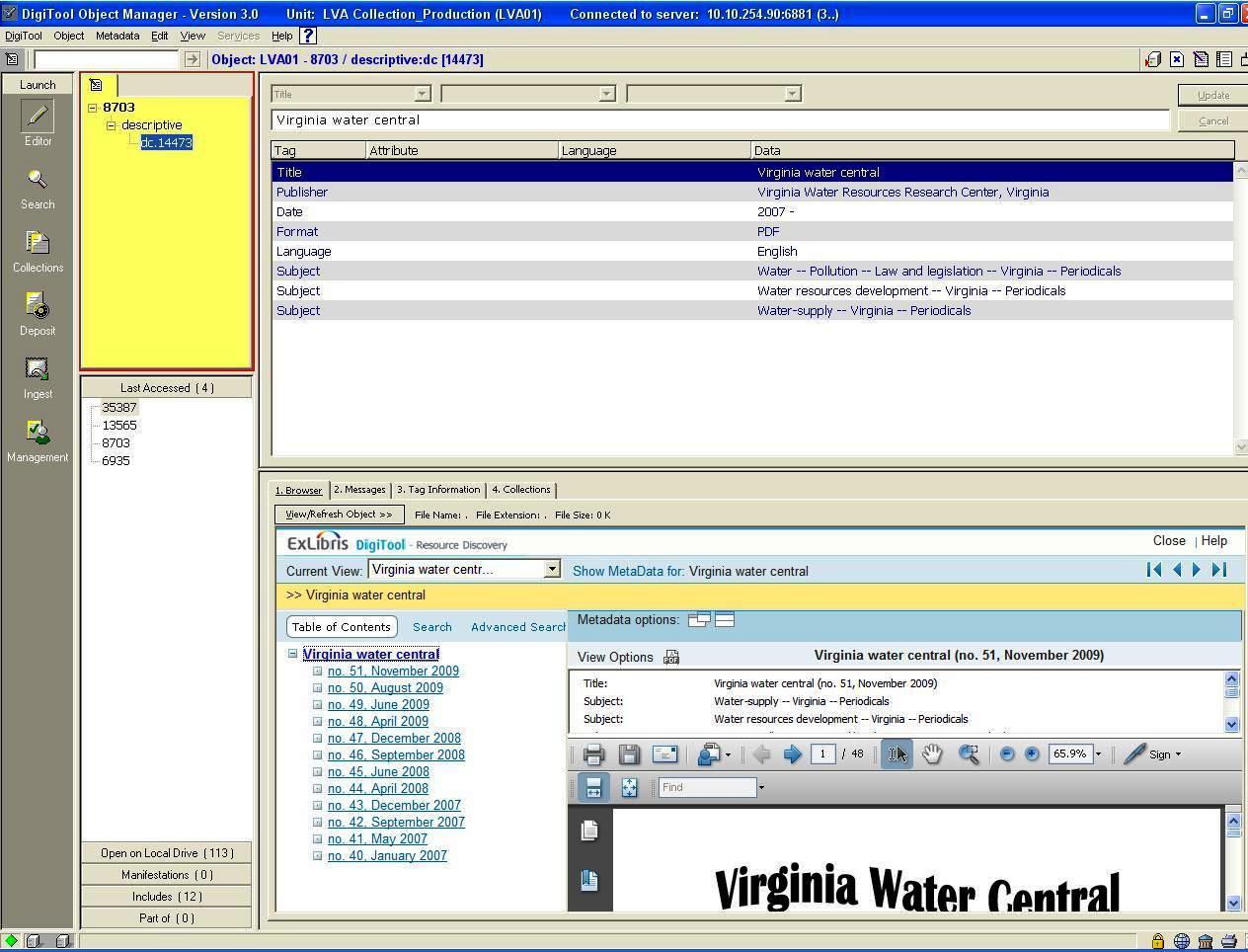
Figure 6B. Meditor view: Parent-child relationship, or complex object Click here for larger image
The administrative metadata for a complex object shows the object is “part of” another object and provides the pid for the child. The child is given a separate label, “Virginia water central,” and shows both the creation and modification dates and times. The entity type is identified as “complex,” meaning “complex object.” LVA uses either the Complex Object feature in DigiTool or a staff member converts a multi-file PDF into a single file using Acrobat Adobe Professional.
<relation> <type>part_of</type> <pid>8703</pid> <label>Virginia water central</label> <note xsi:nil="true" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" /> <usage_type>VIEW</usage_type> <creation_date>2008-08-27 13:55:59</creation_date> <modification_date>2010-01-06 14:31:38</modification_date> <file_extension xsi:nil="true" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" /> <mime_type xsi:nil="true" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" /> <external_type>0</external_type> <directory_path xsi:nil="true" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" /> <entity_type>COMPLEX</entity_type> <file_id xsi:nil="true" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" /> </relation>
To set up a periodical, a parent object is created and four or five DC elements, e.g. title, publisher, date, language and/or subject(s), are added. The child objects are then linked to the parent object, and the parent object is linked to the periodicals collection. Finally, the URL is added to the MARC records in both OCLC and Aleph, which could be done using a separate program. Currently it is being added manually.
After the object has been modified with additional descriptive metadata, it is incorporated into the appropriate subcollection or collections. The main collection of depository documents, State Government Publications, is subdivided into three categories: 1) Browse by Topics, 2) Depository Submissions by Date, and 3) Periodicals, as shown below in figures 7 and 7A. The topics were devised taxonomically, by the State and Federal Publications Cataloger, because this was the only collection requiring this level of sub-categorization at the time. Figure 8 displays the general collections as seen in RD.
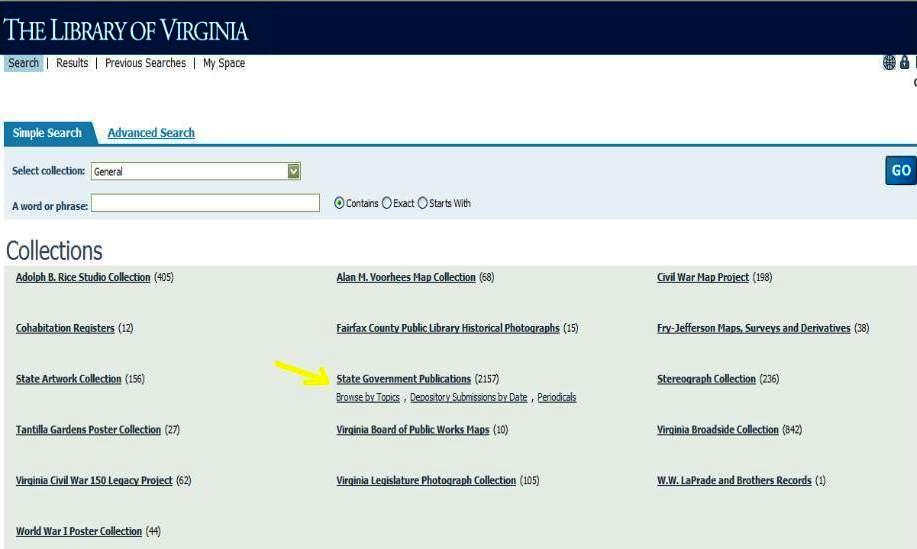
Figure 7. Collection in Resource Discovery (RD) Click here for larger image
There are two collection levels with ten main categories and subcategories. The two collection types are nodes and itemized. Each object is assigned one subcategory. The subcategories can be seen in the State Government Publications view in figure 7A.
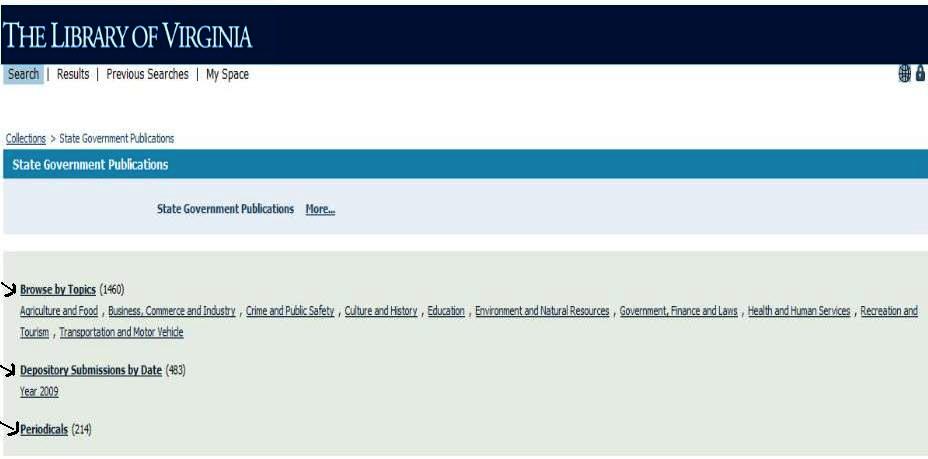
Figure 7A. Subdivisions of main collection Click here for larger image
The statistics that are kept track the publications and the number received. The total number of publications displayed in the RD of DigiTool is misleading, however, because it combines all subcollections within the State Government Publications collection. These subcollections contain items that overlap other subcollections in the State Government Publications collection in DigiTool, thus inadvertently inflating the number of records in the collection. In order to retrieve the accurate number of digital publications that have been deposited in DigiTool, a collection of depository submissions, entitled “Depository Submissions by Date,” was created (see figure 8) showing the number of items deposited by year on the first level then further subdivided by month so that the number of items can be identified and calculated monthly. To retrieve the number of deposited digital state documents in Aleph, the local note MARC field 590 is used to indicate the submission date of the digital object, which can be used to create a report in Aleph to retrieve the number of items deposited by date.

Figure 8. Depository submissions by date Click here for larger image
Another aspect of collection management outside of DigiTool, yet based on the collection of depository submissions by date in DigiTool, is the online shipping lists, created by the State Documents Cataloger. The lists are derived from OCLC Connexion export reports that are entered into Microsoft Word, which is then translated to a pdf. The shipping lists identify items cataloged monthly. They are listed numerically with different lists for monographs and serials as shown in figure 9. In this way LVA can easily notify depository libraries of newly available titles. LVA creates monthly online shipping lists to display on its website so that other state agencies can get access this way as well.
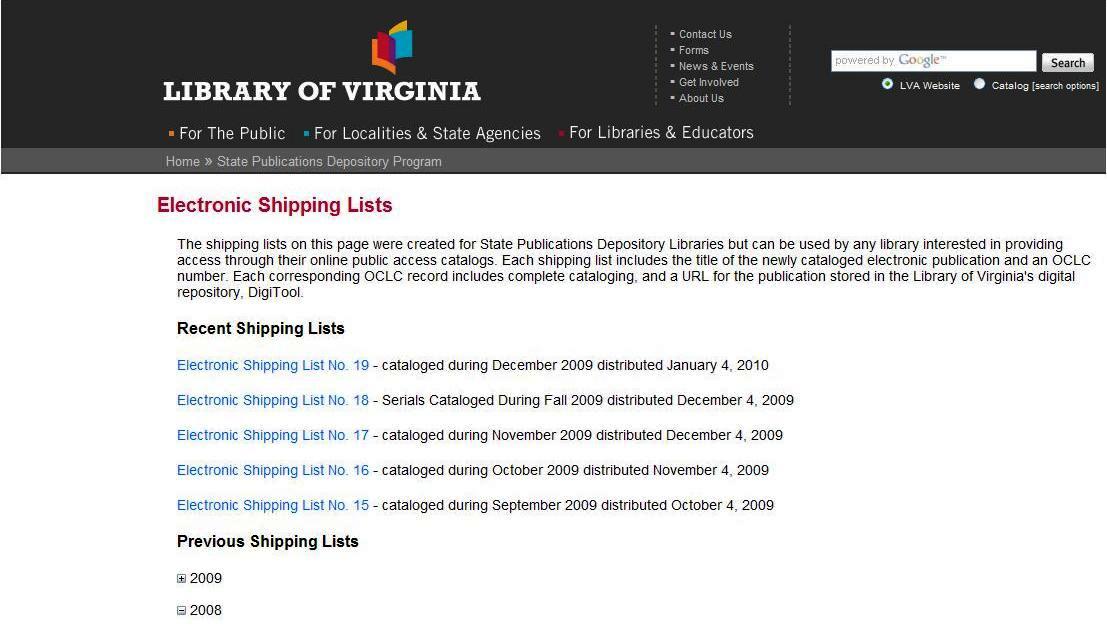
Figure 9. Electronic shipping lists Click here for larger image
Conclusion
DigiTool has provided the functions for a successful digital repository program for the Virginia State Publications Depository through its facility of digital publication deposit, email notification, and agency login accounts. Yet, the success of the program has been limited due to DigiTool’s requiring management by a systems person or department and inability to be manipulated by catalogers. Fields cannot be easily changed across the system, much less for individual collections. This lack of support infrastructure has prevented LVA from taking advantage of Digitool’s full functionality. While support from ExLibris has been excellent, response time to questions from ExLibris can take anywhere from thirty-six and forty-eight hours or longer. Communicating in real-time has not been possible due to their being headquartered in Israel. There also has not been the level of synchronization between Aleph and DigiTool as we had hoped and anticipated. We have also realized that DigiTool cannot handle newspapers very well and offers a limited text searching capability. For this reason, LVA will have to use another system for its extensive digital Virginia newspaper collection. While DigiTool was a good choice at the time for what was needed, unless it can be manipulated and better utilized by catalogers, the system will continue to be a laborious and time-consuming product with much potential but limited functionality for smaller institutions.
The most challenging aspects of developing the program were the mapping, and metadata standards, both developing these locally as well as enabling them in DigiTool. The mapping, metadata standards, and taxonomy would have been more successful had they been developed at the beginning. Metadata in libraries needs to be understood as cataloging requiring standards, and digital asset management systems like DigiTool need to be intuitive and practical for purposes of functionality, display, and most important, efficiency.
Notes
[1] See Library of Virginia State Publications Depository Program, accessed 1/7/10, http://www.lva.virginia.gov/agencies/StateDocs/.
[2] For the purposes of this article, enduser will refer to the agency contributor, the person who manages the agency’s publications and has the responsibility to submit electronic publications to LVA.
[3] “FAQ About the State Publications Depository Program,” Library of Virginia website, accessed 1/12/ 2010, http://www.lva.virginia.gov/agencies/StateDocs/FAQstate.asp. Code of Virginia, Legislative Information System website, accessed 2/22/10, http://leg1.state.va.us/000/src.htm.
[4] See Valerie Stevenson and Sue Hodges’s article (2008) “Setting Up a University Digital Repository: Experience with DigiTool” in OCLC Systems & Services: International Digital Library Perspectives, 24:1, p. 48-50 for Liverpool John Moores University (LJMU) case study on DigiTool. LJMU also developed a “process for self-deposit” (p. 49) and determined that the “main advantages in choosing DigiTool . . . have been the guaranteed level and availability of support available from ExLibris and the purchase of a single product . . . to create and manage the full range of digital collections at LJMU” (p. 50).
See also “DigiTool Implementation and Documentation” on Boston College’s website accessed via Internet Archive, accessed 2/22/2010, http://web.archive.org/web/20070809040644/http://www.bc.edu/bc_org/avp/ulib/staff/digilib/digitool/digitool.html and Este Paskausky’s (2004) “DigiTool at Boston College” in North American Aleph User Group Fifth Annual Meeting, June 13-16, 2004, Massachusetts Institute of Technology, Cambridge, MA, accessed 1/7/10, http://documents.el-una.org/77/1/NAAUG04-present_Digitool-BC.pdf.
[5] See Valerie Stevenson and Sue Hodges’s article (2008) “Setting Up a University Digital Repository: Experience with DigiTool” in OCLC Systems & Services: International Digital Library Perspectives, 24:1, p. 48-50.
[6] “’Z39.50’ refers to the International Standard, ISO 23950: ‘Information Retrieval (Z39.50): Application Service Definition and Protocol Specification,’ and to ANSI/NISO Z39.50. The Library of Congress is the Maintenance Agency and Registration Authority for both standards, which are technically identical (though with minor editorial differences),” Z39.50 International Standard Maintenance Agency, The Library of Congress Network Development & MARC Standards Office website, accessed 1/31/2010, http://www.loc.gov/z3950/agency/.
[7] Acquisitions and Access Management (AAM) is a department at LVA that resulted from the merging of Technical Services, which included Acquisitions, and Government Documents.
[8] Network Development and MARC Standards Office, Library of Congress, “Dublin Core to MARC Crosswalk,” Library of Congress website, accessed 1/31/2010; see Carol Jean Godby, Jeffrey A. Young, and Eric Childress’s article (2004) “A Repository of Metadata Crosswalks” D-Lib Magazine, 10:12, accessed 1/7/10, http://www.dlib.org/dlib/december04/godby/12godby.html.
[9] Hunter, Nancy Chaffin, et al., “Phase One Report: Core Metadata Elements for CSU Electronic Theses and Dissertations, Faculty Papers, and University Historic Photographs Collection (Glass Plate Negatives),” accessed via CSU’s digital repository, 1/31/2010, http://hdl.handle.net/10217/3146; CDP Metadata Working Group, “Dublin Core Best Practices, version 2.1.1, September 2006, accessed 1/31/2010, http://www.bcr.org/dps/cdp/best/dublin-core-bp.pdf; Rettig, Patricia J., et al., “CSU core data dictionary: version 1.1 (July 2008),” accessed via CSU’s digital repository 1/31/2010, http://hdl.handle.net/10217/3147; Rettig, Patricia J., et al., “CSU core data dictionary: version 1.0 (October 2007),” accessed via CSU’s digital repository 1/31/2010, http://hdl.handle.net/10217/3150; Rettig, Patricia J., et al., “Developing a Metadata Best Practices Model: the Experience of the Colorado State University Libraries,” Journal of Library Metadata, vol. 8, no. 4 (2008): 315-339, accessed via CSU’s digital repository 1/31/2010, http://hdl.handle.net/10217/9025.
[10] Paskausky, Este, “DigiTool at Boston College,” 2004, accessed 2/1/2010, http://documents.el-una.org/77/1/NAAUG04-present_Digitool-BC.pdf.
[11] Cornell University Library Metadata Standards & Tools, accessed 2/1/2010, http://lts.library.cornell.edu/lts/dm/ms/mst; see also Metadata Services : Resources from Cornell University, accessed 2/1/2010, http://metadata.library.cornell.edu/resources.html.
[12] Mary Anne Dyer, Metadata Librarian at VCU, provided authors with examples of VCU’s crosswalk and data dictionary for one of VCU’s online repository collections via email, 3/9/2009.
[13] “Implementation Guidelines for the Open Archives Initiative Protocol for Metadata Harvesting,” Open Archives Initiative website, accessed 1/31/10, http://www.openarchives.org/OAI/2.0/guidelines.htm.
[14] “Library Application Profile,” Dublin Core Metadata Initiative website, accessed 1/31/10, http://dublincore.org/documents/library-application-profile/index.shtml.
About the Authors
Mei Kiu Lo (meikiu.lo@lva.virginia.gov) is State and Federal Publications Cataloger and Leah M. Thomas (leah.thomas@lva.virginia.gov) is Cataloging Coordinator at the Library of Virginia. Mei Kiu developed the taxonomy for the State Publications Collection. In tandem, they started the ad hoc Metadata Standards Committee and devised the crosswalk for DigiTool.

BeanWorks » Comparing Digital Library Systems, 2011-04-11
[…] expertise in varying levels in order to realize full functionality of their features (see, e.g., Creating an Institutional Repository for State Government Digital Publications). For another, as the number of libraries implementing Digital Libraries with resource discovery […]
Manoj, 2012-05-16
I wish to undertake project of digital library of state governemnt publications for government of Maharashtra. How to go abut it
Manoj, 2012-05-16
it is aggod article