by Nitin Arora
Introduction
In late 2009, after nearly a year supervising the digitization of audio content for our department, I had observed that most of our issues arose in the post-digitization phase of processing. Worse yet, every explored solution seemed to spawn new problems.
At the heart of the matter was the fact that digitized audio content in its virginal form often makes for poor deliverable files due to long silences, distracting peaks, and inconsistent volume levels between sections of the same audio file. Certainly, many of these characteristics can justifiably be considered to possess narrative qualities of interest to researchers, yet there still remains the practical matter of presenting content online in a presentable fashion. And to complicate matters it was, from a preservation perspective, undesirable at the least and unacceptable at the most to edit the archival file for the sake of making more suitable derivatives.
Since we seemed trapped between the mythological “rock and a hard place”, one solution considered was to essentially embrace our medial position and use a “middle man” audio file, an edited offspring of the archival file that would yield more suitable online derivatives given that the aforementioned offending audio would be removed and some additional light audio processing added. This too was problematic, however, in that retaining this intermediary file would not only increase local storage requirements but would also increase storage requirements for each of our peers in our LOCKSS [1] digital preservation network. Even if, for storage concerns, these intermediary files were to be deleted after the creation of web-deliverable files, responsibility would still require copious documentation to inform us or our predecessors of how we got from point A to point B, so to speak, in the event that the web-deliverables would have to be reconstituted at a some point – in other words, if much of the work needed to one day be repeated.
Differing from the “middle man” approach, which essentially advocates the removal of unwanted content -albeit to a new file, is the approach that advocates the extraction of desired content. In other words, the idea is to simply extract what is desired rather than delete and edit that which is undesirable. For the purposes of explanation, we can respectively call these the non-destructive and destructive approaches.
The non-destructive approach offers distinct advantages over the destructive approach. Quite simply, documentation is much simpler and there is no need for an intermediary “middle man” file. Consider, for instance, the following analogy:
If the word “computer” is analogous to our archival audio file and the word “compute” is analogous to the desired derivative, documenting either approach in terms of individual letter position would be quite simple:
Non-destructive approach: “Extract 1st, 2nd, 3rd, 4th, 5th, 6th, and 7th letters.”
Destructive approach: “Remove 8th letter.”
If, however, the desired output is the word “cute”, the situation becomes much more complicated.
Non-destructive approach: “Extract 1st, 5th, 6th, and 7th letters”.
Destructive approach: “Remove 2nd, 3rd, 4th, and 8th letters”.
At this point, one might ask “So, what’s the problem?”
The problem is that the destructive approach refers to letter positions in the original file. When one starts actually deleting these letters in the “real world”, the instructions might be more useful if they read “Remove 2nd, 2nd, 2nd, and 5th letters” as such:
computer
cmputer
cputer
cuter
cute
When considering that with audio one will use timecodes rather than simple letters, the situation extends beyond the merely trivial to the downright confusing. Therefore, we decided to adhere to a non-destructive approach. And our GUI audio editing software, Sony Sound Forge 9.0, seemed to support our needs.
GUI audio editors: solutions and limiting factors
Our audio editing software, Sony Sound Forge 9.0, allowed for us to implement the non-destructive approach by supporting both
- the extraction of multiple regions of audio from a larger whole, so as to leave out unwanted segments and
- the extraction of one derivative audio file with any offending segments of the source audio stream simply omitted.
In terms of extracting regions, Sound Forge – as well as many other GUI audio applications – supports graphically denoting these regions within audio files. These regions can subsequently be extracted via batch process as separate files, omitting anything that lies between them. Figure 1 below depicts the notation of two regions within one audio file.
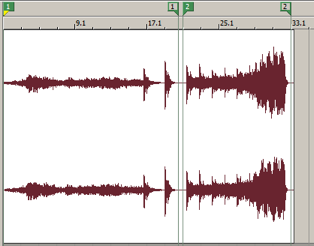
Figure 1. Two regions selected in the same audio file.
In terms of creating one audio file that omits offending segments – essentially a mirror to the process above, Sound Forge supports the implementation of playlists and cutlists which allow for the creation of a derivative audio file sans the undesired segments either by rendering only what is desired (“playlist”) or omitting what isn’t (“cutlist”).
In addition to such capabilities, the software can produce an easy-to-read text output denoting the region list, playlist, or cutlist details such as the name given to a region as well as the relevant time markers. In considering the need to document the process of creating web-deliverables from a master file, the retention of this text output addressed our needs in this one regard but created a new problem.
Specifically, the potential inclusion of this data into larger XML-based technical/preservation metadata would prove bothersome, given the non-standardized formatting of the output. Furthermore, it was not desirable or even feasible to spend time experimenting with alternative and likely expensive software which may or may not have supported better options for exporting such data.
In mulling over these solutions and the new problems they spawned it became clear that
- it seemed risky to rely on embedded region metadata which may or may not be detectable by our future audio applications and
- the text records exported by our software were insufficient in regard to our long-term documentation needs.
A simple XML-based alternative needed to be devised to address both concerns.
SimpleADL
SimpleADL (Simple Audio Decision List) is small-footprint XML structure for defining regions within an audio file. [2]
By using a “home-grown” XML format to record region locations within the audio file, the aforementioned problems of eventually migrating the data into other XML-based metadata would become sufficiently easier. SimpleADL is currently schema-less.
The example below depicts the <region> and <outputAsTracks> elements, the respective “bread and butter” of SimpleADL:
<region id="_01">
<in unit="seconds">0.5</in>
<duration unit="seconds">601</duration>
</region>
<region id="_02">
<in unit="seconds">612</in>
<duration unit="seconds">299.05</duration>
</region>
<outputAsTracks>true</outputAsTracks>
Simple enough for unencumbered human reading, SimpleADL’s <region> element provides an easily retained record of what portions of an archival audio file we want to present online. Meanwhile, the <outputAsTracks> element informs future users, be they man or machine, whether these portions should be extracted as multiple audio files per region or as one audio file which would essentially be a concatenation of each region. Specifically, this means that the <outputAsTracks> element value if “true” informs one of the desire to output one audio file per region, while an element value of “false” would tell of the desire to output only one audio file consisting of all regions spliced together.
Currently, the creation of SimpleADL files is initiated via a small Python script called “SimpleADLmaker”. This small command-line program prompts the user to input the name of the corresponding WAV file as well as the number of regions to define and the desired value of the <outputAsTracks> element. For the file foo.wav, this little helper script would make a file called foo.adl.xml, a skeletal XML file housing the document tree appropriate to the user-inputted data. Given the simplicity of SimpleADL, the element and attribute values can then easily be entered with no more than a basic text editor.
SimpleADL provides enough documentation for reliable reconstitution of online derivatives from the master should the need arise to do so – for example, if we later switch from MP3 to OGG format for online audio delivery. But in the endless cat-and-mouse game of problem-solution-problem, this begged the question, “If the need to remake web-deliverables arises, who wants to open up every SimpleADL file and manually extract regions from the archival audio files?”. Doing so would entail endless and costly hours of mind-numbing work, ripe for human error. In other words, the very reasons for devising SimpleADL were rearing their proverbial, ugly heads once more.
For the last pieces of our audio workflow puzzle, we looked to our experience with image-based collections. For our image collections, we use the open-source image processing toolkit ImageMagick [3] to batch process web-deliverable JPEG files from our archival scans. It only seemed logical to seek a similar toolkit for audio processing.
SoX
SoX (“Sound eXchange”) is an open-source, cross-platform command-line audio editor, aptly referred to on the project website as “the Swiss Army knife of sound processing programs”. [4] Highly powerful, its capabilities to split, splice, and apply post-production effects to audio files seem almost limitless. SoX is ideally suited to the digital library environment.
For an imaginary audio file, “foo.wav”, the following SoX commands would produce Ogg Vorbis [5] audio files for each region notated in the SimpleADL example above:
$ sox foo.wav foo_01.ogg trim 0.5 601 $ sox foo.wav foo_02.ogg trim 612 299.05
After learning about the existence of SoX, it became evident that a GUI audio editor would only be needed to help a technician identify the location of desired regions within each archival audio file. After the starting point and duration of each region was manually entered into a SimpleADL file, the extraction of audio regions and the application of light audio processing to them could then be automated by simply “feeding” the element values from a SimpleADL file to SoX. For this, a Python script was created.
AudioRegent
AudioRegent [6] is a command-line Python script that essentially serves as a moderator between archival audio files in WAV format and their corresponding SimpleADL files.
After starting AudioRegent the user enters the path in which WAV files and their corresponding SimpleADL files are to be found. AudioRegent then iterates over every SimpleADL file within the path, sending command-line arguments to SoX, thus producing derivative audio files for each master WAV file per both the instructions within the corresponding SimpleADL file and the AudioRegent settings, which can be changed by editing a simple XML setup file called AudioRegent.xml.
AudioRegent.xml allows one to control things such as the derivative output audio format and what we call the “SoX Options” – the effects, if any, that SoX will add to the derivative audio files. These effects can include leveling the recording or padding the ends with a second of silence, etc.
Following batch conversion of the derivatives to MP3 format, the files are distributed to our servers and our delivery platform for users to access.
It should be noted that even though our desired output format is MP3, we currently have AudioRegent.xml set so that AudioRegent creates WAV derivatives. We then convert these WAV derivatives in batch to MP3 file using the LAME encoder. [7] This step is external to the AudioRegent workflow and must be done because our pre-compiled Windows binary of SoX does not output to MP3. We could eliminate this extra step if we were to build SoX from source to include the LAME libraries as this would allow MP3 files to be created natively by SoX.
Example
For a “real world” example of the combined usage of AudioRegent, SimpleADL, and SoX consider the following full example of a SimpleADL file for an item from the Harald Rohlig Organ Music collection [8] at The University of Alabama.
The item identifier for the example below is “u0008_0000002_0000089”, hence the 1:1 archival WAV file is named u0008_0000002_0000089.wav.
After a metadata librarian creates the basic metadata, including the timecodes for the beginning of each track, a member of our Digital Services staff would use the SimpleADLmaker script to create a skeletal SimpleADL file, shown below. Note, the <statistics> and <text> blocks are not required as they do not constitute the core elements of SimpleADL and are ignored by AudioRegent. We simply prefer to capture statistical metadata about the audio file from Sound Forge and house very basic descriptive metadata about the item to help the technician keep track of the tracks, so to speak.
<audioDecisionList filename="u0008_0000002_0000089.wav">
<statistics>
<channel position="mono">
<minimumSamplePosition unit="seconds"/>
<minimumSampleValue unit="dbfs"/>
<maximumSamplePosition unit="seconds"/>
<maximumSampleValue unit="dbfs"/>
<RMS_level unit="dbfs"/>
</channel>
<length unit="seconds"/>
</statistics>
<region id="">
<in unit="seconds"/>
<duration unit="seconds"/>
<text type="xhtml">
<p type=""/>
</text>
</region>
<region id="">
<in unit="seconds"/>
<duration unit="seconds"/>
<text type="xhtml">
<p type=""/>
</text>
</region>
<region id="">
<in unit="seconds"/>
<duration unit="seconds"/>
<text type="xhtml">
<p type=""/>
</text>
</region>
<outputAsTracks>true</outputAsTracks>
</audioDecisionList>
With both the SimpeADL file onscreen alongside an instance of Sound Forge, accurate start and duration times are determined and typed into the SimpleADL file using the Notepad ++ text editor [9] for Windows. Given that the care required in determining and documenting this data by hand essentially builds in some quality control measures, we have not found the manual entry of timecodes to prove troublesome.
This procedure results in the corresponding SimpleADL file below, u0008_0000002_0000089.adl.xml. Note that the last region is commented out. It was considered undesirable for delivery, yet it is still documented.
<audioDecisionList filename="u0008_0000002_0000089.wav">
<statistics>
<channel position="mono">
<minimumSamplePosition unit="seconds">69.73</minimumSamplePosition>
<minimumSampleValue unit="dbfs">-6.094</minimumSampleValue>
<maximumSamplePosition unit="seconds">226.145</maximumSamplePosition>
<maximumSampleValue unit="dbfs">-6.939</maximumSampleValue>
<RMS_level unit="dbfs">-25.421</RMS_level>
</channel>
<length unit="seconds">539.779</length>
</statistics>
<region id="_0001">
<in unit="seconds">8.591</in>
<duration unit="seconds">83.948</duration>
<text type="xhtml">
<p type="title">Harald Rohlig: Nun danket all und bringet Ehr'</p>
</text>
</region>
<region id="_0002">
<in unit="seconds">97.059</in>
<duration unit="seconds">123.315</duration>
<text type="xhtml">
<p type="title">Harald Rohlig: Gott der Vater wohn uns bei</p>
</text>
</region>
<!--
<region id="">
<in unit="seconds">221.727</in>
<duration unit="seconds">318.052</duration>
<text type="xhtml">
<p type="title">Johann Sebastian Bach: Fugue in D major</p>
<p type="comment">(incomplete; do not use)</p>
</text>
</region>
-->
<outputAsTracks>true</outputAsTracks>
</audioDecisionList>
Figure 2 below shows the AudioRegent workflow for this item after the SimpleADL file is created. [10] The aforementioned extra step involving the LAME encoder and the subsequent transfer to online delivery is also depicted. After MP3 files are successfully delivered online, the WAV files in AudioRegent’s final output folder are deleted, the files in AudioRegent’s temp folder having already been deleted automatically. After SimpleADL files are made for a batch of items in the manner described above, we run AudioRegent.
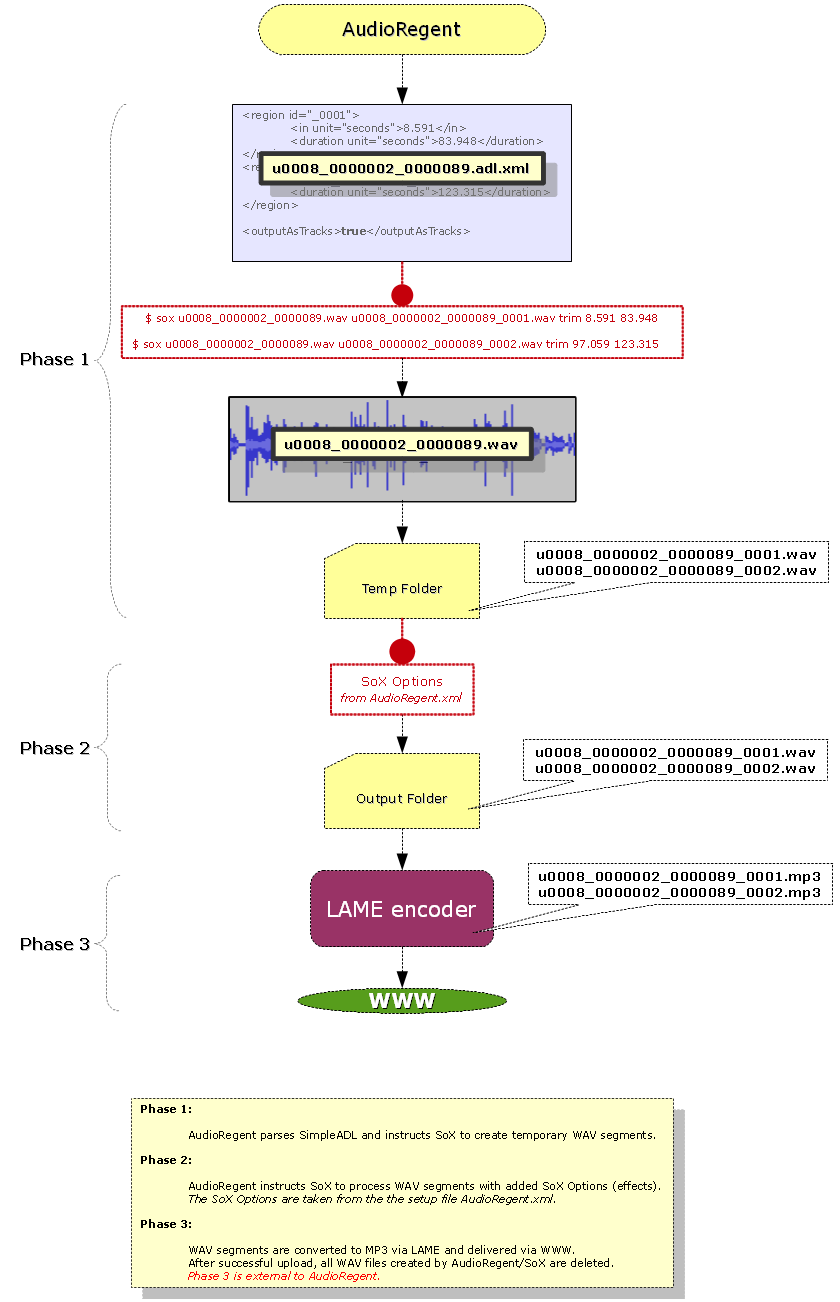
Figure 2. AudioRegent workflow. (full-size image)
The first batch we ever used AudioRegent on consisted of roughly 25 items from the Rohlig collection, approximately 10% of the current total of digitized items for the collection. With the SimpleADL files already in place, batch processing nearly 150 derivative tracks from these 25 archival items took approximately 90 minutes on a Windows computer (64-bit XP Professional, 3 GHz Intel Core 2 Duo processor, 8 Gigabytes of RAM). This included the added use of the LAME encoder as described above, which comprised approximately one-third of the total time.
Future Work
Now that AudioRegent has successfully been integrated into our digital audio workflow we can begin thinking about developing a formal schema for SimpleADL. One of our metadata librarians at the university, Shawn Averkamp, has agreed to spearhead this effort given that SimpleADL contains metadata of interest to metadata librarians and not just audio technicians. As long as the aformentioned “bread and butter” of SimpleADL remains intact, the format is highly mutable given that AudioRegent ignores all but the <region> timecode and <outputAsTracks> values. With long-term preservation in mind, a schema would seem a requisite next step in the process.
In addition to the desire for a schema, we will also look to further ways in which to help automate the creation of SimpleADL files from pre-existing descriptive metadata.
We shall also look for an open-source replacement for Sound Forge as our eventual goal is a completely open-source audio workflow. While good open-source audio editors exist, we ideally want to find an application that can conjure up the same statistical technical metadata about the audio file as Sound Forge.
Finally, given the added external step involving the LAME encoder for the purposes of making MP3 files, it would behoove us to go ahead and build SoX from source to include LAME’s MP3 encoding functionality. This would not only allow us to directly create MP3 derivatives from our master WAV files, but would also make the entire batch process cycle less time-intensive.
Conclusion
Balancing preservation and practical delivery concerns in terms of digital audio content can be a win-win situation without the need for impractical overhead and complexity. By using simple technologies – AudioRegent and SimpleADL – that utilize a powerful, open-source audio editor in SoX, the University of Alabama Libraries’ Digital Services is able to implement an easy, transparent, and effective workflow to help manage digital audio content.
About the Author
Nitin Arora is a Digitization Specialist at the University of Alabama Libraries’ Digital Services. He recently completed his Master’s in Library and Information Studies at the University of Alabama. His email address is “nitaro74 AT gmail DOT com”.
Notes
[1] LOCKSS. Retrieved June 2, 2010, from http://lockss.stanford.edu/lockss/Home/
[2] SimpleADL. Retrieved June 2, 2010, from http://blog.humaneguitarist.org/projects/audioregent/#SimpleADL
[3] ImageMagick Studio LLC. ImageMagick. Retrieved June 2, 2010, from http://www.imagemagick.org/
[4] SoX – Sound Exchange. Retrieved June 2, 2010, from http://sox.sourceforge.net/
[5] Xiph.org Foundation. FAQ. Retrieved June 2, 2010, from http://www.vorbis.com/faq/#what
[6] AudioRegent. Retrieved June 2, 2010, from http://blog.humaneguitarist.org/projects/audioregent/
[7] LAME MP3 Encoder. Retrieved June 2, 2010, from http://lame.sourceforge.net/about.php
[8] University of Alabama. Selections for organ by Harald Rohlig. Retrieved June 2, 2010, from http://acumen.lib.ua.edu/u0008_0000002_0000089/
[9] Notepad++. Retrieved June 2, 2010, from http://notepad-plus.sourceforge.net/uk/site.htm
[10] For an image depicting how AudioRegent can produce either many or one derivative audio file/s per SimpleADL, see http://blog.humaneguitarist.org/projects/audioregent/#HowWorks. (Retrieved June 2, 2010.)

Getting my hands dirty | What Jody's been up to..., 2014-10-04
[…] brings this to mind is the audio transformation software that was built by one of my previous employees (a professional musician), who left us for a […]