By Benjamin Pennell and Jill Sexton
Introduction
In the summer of 2007, the Library at the University of North Carolina at Chapel Hill joined with our partners in the Triangle Research Libraries Network (TRLN) to create a shared catalog using Endeca software [1]. The Search TRLN consortial catalog [2] was released in March of 2008, and the UNC Chapel Hill Libraries released a locally-scoped public catalog [3] using the shared Endeca index in July of 2008.
At the time of implementation, TRLN opted not to include authority records in the shared index. The Endeca index is optimized for keyword searching, and does not include the necessary data structure to support “begins with” searching. Furthermore, we were not trying to replicate the functionality of a traditional OPAC and felt that we didn’t need to reinvent a true authority browse functionality; our traditional catalogs are optimized for that particular use. While overall feedback on the new interface was positive, one of the most common criticisms UNC’s catalog implementation team received from both patrons and staff concerned the interface’s lack of support for authority searching and browsing.
During the summer of 2009, UNC Chapel Hill Libraries began to investigate ways we could enhance our users’ search experience by reintroducing some limited authority data into the catalog. At the same time, we had been considering introducing an auto-suggest feature for the catalog interface that would provide real-time suggestions based on what the user types in the search box. Users are accustomed to auto-suggest features in most commercial search interfaces and we wanted to see if we could replicate this service using the data in our catalog. Populating the auto-suggest feature with authority data from our collection addressed both of these concerns while providing a balance between traditional library use of authority and the expectations and habits that users have formed in using the Web.
Traditional authority browse functionality accepts a user’s query and returns an alphabetical list of nearby authority headings based on a “begins with” match. Most OPACs force users to adhere to certain conventions when entering query terms: e.g., the requirement to enter author searches in “Last name, First name” format; the need to leave leading articles out of title searches; and the need for users to know something about LCSH structure in order to perform successful subject searches. Real-world experience, as well as a scan of user search terms gleaned from log data, revealed that many of our users do not follow these conventions when searching the catalog. We hoped to develop a solution that would be easier for typical library patrons to use than a traditional authority search, but at the same time would provide useful suggestions for our more sophisticated users.
The result is an auto-suggest feature that presents relevant authority-controlled author, subject, and title suggestions to the user as they type, without users having to understand traditional library OPAC syntax. We hope that this “Do you mean?” strategy of providing real-time suggestions is more useful than a similar service would be if the suggestions were presented after the initial search.
Methodology
Request Process
From the perspective of a catalog user, the process of submitting and receiving suggestions should be a seamless extension of the individual’s standard search interactions with the interface. The interface presents users with a typical search form, including a query input box, a drop down menu for indicating which type of metadata they wish to search, and a submit button. As the user begins to type, the interface displays a panel populated by suggested known entities below the query box.
A system involving JavaScript, servlets and Solr is used to provide these suggestions in real-time, following the request process outlined below:
- User begins to type a query into the search box.
- Every 150 milliseconds while the user’s query is changing the client sends an AJAX request to the Suggestion servlet, containing:
- Query as typed
- Search index presently selected (ie, title, author, subject, keyword, journal_title)
- The Suggestion servlet validates the user’s input and submits it to the Suggestion Datahandler.
- The Datahandler transforms the user’s input into a Solr query, and then submits it to the index as an HTTP request. See section “Suggestion Query Construction” for more details.
- When Solr has completed the requested search, it returns JSON results to the Datahandler. The Datahandler then processes these results and returns them to the Suggestion servlet.
- The Suggestion servlet writes a JSON response containing the results restructured as a dictionary containing a list of suggestion/index pairs and the time at which the servlet originally received this request, in milliseconds.
- User client receives the response. It compares the timestamp of the most recently displayed suggestion results versus that in the JSON response, and discards the JSON results if they are older.
- JavaScript formats the results into a list of suggestions.
- Repeat steps 2-8 until one of the following occurs:
- User stops typing.
- User continues typing, but the new results are contained within a cache of previous results in the auto-suggest user interface.
- User submits the search, either by pressing enter or clicking the search button.
- User clicks on a suggestion, causing the client to submit the selected suggestion/index pair.
- User highlights a suggestion with the up or down arrows keys, causing the client to place the highlighted suggestion in the search box. At this point the user may highlight another suggestion, begin typing again, or submit the suggestion.
- If the user submits a query, a search behavior parameter is added to the catalog search URL, indicating if the user searched for a suggestion, and if the user manually selected a search index.
- The catalog performs a search as it would normally, and returns results.
- Display results. The user’s search is displayed in the search box, and the index of the last search is selected, whether it was automatically set, manually chosen, or not selected.
- When the user clicks in the search box, if the search index of the last search was automatically set by a suggestion (if it was an author or subject search), the search index is reset to Keyword.
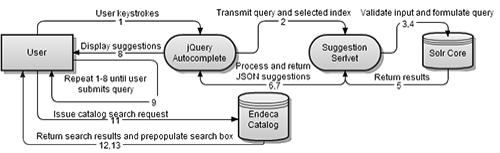
Figure 1: Request process flow diagram. (view larger)
User Interface
We implemented the user interface using a modified version of the jQuery Autocomplete plug-in [4], as well as CSS and JavaScript as necessary to style and configure the plug-in. While it would have been preferable to retain the Autocomplete plug-in as is, there were a few behaviors that we could not modify via the provided configuration options. One such change is adding verification that incoming suggestions are more recent than those currently being displayed, since network traffic or slow queries can result in responses appearing out of order.
As is mentioned in step 2 of the overview, the interface includes a drop down menu that allows users to specify whether to retrieve all available matching suggestions or to only return suggestions of a particular type. The latter option allows users to separate out suggestions categorized as “titles,” “authors” or “subjects” in order to reduce the number of unrelated matches.
For example, a user may be seeking all records authored by John C. Adams, but cannot remember the author’s full middle name. To further complicate matters, the suggestion list for an “anywhere” search for “John Adams” would be filled with works about Presidents John Adams and John Quincy Adams. By selecting “author” from the drop down menu, the user limits the suggestion results to only author entities, and can quickly locate “adams, john crawford” on the ensuing suggestion list.

Figure 2: The suggestion interface providing feedback for the query “john adams c”
Even if the user had not decided to preselect “author” from the search type drop down, selecting a suggestion labeled as an “author” (or “subject”) would have still resulted in the interface issuing an author or subject search rather than a keyword search. While this behavior helps to keep suggestion searches as relevant as possible, our test groups did find it introduced some confusion on the subsequent results page. By default, the catalog interface presets the index type on its results display to that of the last search performed so that users can easily modify their query. In the case of automatic pre-selection of the search type, however, users may have forgotten about or not been aware of the change in search type, and would therefore wonder why they were now only receiving author or subject suggestions when they were previously receiving more suggestions. Our test groups found the system much more intuitive when we altered the behavior to revert back to a generic “keyword” search type when users began editing queries that had automatically selected a search type.
Step 9 mentions one other important detail about the jQuery Autocomplete plug-in; it has a built-in result caching mechanism which avoids making additional requests for suggestions when the user’s input is an extended version of a suggestion query that was already processed and returned fewer than the maximum number of displayable results. In these cases, it instead reuses the results from its cache and limits them by the new portions of the query.
Web Service Layer & Query Construction
The web service layer is comprised of two components, the first of which is a Java servlet that directly handles interactions with user requests for suggestions. The servlet extracts and validates user input before forwarding it to the Solr datahandler, and retransmits results to the user. The second component acts as a datahandler for interacting directly with Solr. Primarily it handles the generation of Solr queries and processing of results.
The auto-suggest index is queried via a combination of begins-with, keyword, and partial keyword matching along with result filtering by search index type and collection. Additional weighting mechanisms are applied to each search, in general to weight word order matches and popularity more highly. See Table 1 for definitions of all the involved fields.
While many aspects of the suggestion query are consistent for all cases, such as the maximum number of results (M, where M=15 in the UNC implementation) or the result format, there are three attributes that allow us to adjust the suggestion query to provide more meaningful results for specific subclasses of queries:
- Number of search terms (N)
- If the last search term was a stop word (i.e., “the last of” returns true, “the last” returns false)
- If the previous search pass had fewer than M results, where there can be up to 3 search passes
Below are explanations of how these attributes interact to form actual queries, where “terms” is a list of words from the user’s query after it has been tokenized, terms[x]* indicates a partial term wildcard search, keyword indicates a match-anywhere search, and begins-with indicates a word order specific search:
Case 1: N = 1. Only a single search term provided:
- Selected by: keyword(terms[1]*)
- Weighted by: occurs + beginswith(terms[1]) + keyword(terms[1])
- In most cases while a single search term is present, that search term is an incomplete word. However, clause 3 of the weighting formula gives full word matches additional weight.
Case 2: N > 1, last search term was not a stop word:
- Selected by: keyword(terms[1..N-1]) AND keyword(terms[N]*)
- Weighted by: occurs + beginswith(terms[1..N])
- All terms prior to the last word are considered to be “finished” by the user, while the last term is the active word and is most likely not complete.
Case 3: N > 1, last search term is a stop word:
- First pass:
- Selected by: beginswith(terms[1..N])
- Weighted by: occurs
- Perform the narrowest search, a begins-with.
- Second pass:
- Selected by: keyword(terms[1..N-1]) AND keyword(terms[N]*)
- Weighted by: occurs + beginswith(terms[1..N])
- The first pass did not return the maximum number of results (M), so broaden the search by treating the last term (a stop word) as a partial term. Search behavior is identical to Case 2.
- Third pass:
- Selected by: keyword(terms[1..N])
- Weighted by: occurs + beginswith(terms[1])
- Passes 1 and 2 did not get full results, so perform the broadest search possible by treating all terms as keywords.
Case 3 provides a far better match rate for queries ending in stop words by progressively expanding the suggestion selection, but only doing so by as much as is required to get a full set of M results. In our testing, multiple passes were not a common occurrence, but when employed were sufficiently helpful to warrant the extra resources.
In addition, two categories of filters are applied on top of the previous three query methods:
- Search index type, where the type can be “title,” “author” or “subject.”
- Source/collection identifiers, where each suggestion retrieved must match all the provided collections.
These filters offer a method of limiting the suggestion results based on predetermined criteria. The first filter type enforces matching based on the type field described in the data dictionary in Table 1, and provides the behavior described in the User Interface portion of this paper for limiting suggestions to particular types of entities. Similarly, filtering based on source identifiers limits by the source field, and allows for the pre-scoping of suggestion results to subsets of the data or for other applications. Both filters are applied as facet filters in order to improve result caching in Solr.
Dataset
For the implementation of this feature, the online catalog served as both the data source and the main platform into which it was integrated. The OPAC at UNC Chapel Hill is a two tiered system, where an III integrated library system provides the originating data source while an Endeca-based web application acts as the public interface. Details of the consortial Endeca-based indexing system used by the Triangle Research Library Network, of which UNC is a part, have been discussed previously [5].
While the auto-suggest enhancement was developed as a component of the UNC discovery layer, in reality it operates in parallel to the two layers of our OPAC and is not directly dependent on the current public interface. When designing this system we were interested in maintaining a platform independent infrastructure that would continue to function even if the Library migrated to different indexing software. In order to satisfy the technical requirements necessitated by user keystroke triggered suggestion requests from a large text dataset while maintaining platform independence, we selected Apache Solr [6] instead of Endeca to provide the core indexing and searching functionality, populating it with MARC data extracted from the III ILS.
We designed the dataset schema to store the minimum level of data required to make suggestions relevant to a user’s query. The data dictionary in Table 1 outlines the schema, as well as how values for each field are derived.
| Ac |
|
| Type |
|
| Occurs |
The divergence here is due to the nature of each index type, where authors and subjects are far more likely to repeat than titles. Meanwhile, circulation levels (taken from the cumulative circulation statistics in our ILS) are not available in all cases, but are useful in judging popularity when present. As a result, they are included in the occurs value for titles, but the value is normalized, using the square root, so as not to dramatically overemphasize items with circulations present. |
| Source |
|
| Ackey |
|
Table 1: Data Dictionary for Auto-Suggest Solr Schema
Data Loading
There are two variations of the Solr index loading process: full loads and partial loads. In both cases, the process is performed using Python scripts that extract the data from the MARC extract files used to populate the production Endeca index.
For both load methods, the selected fields are: 100 for authors, 245 for titles, and 6** for subjects. Subject headings are only loaded in their complete forms, rather than as individual subcomponents. Internally, each type of data is stored and de-duplicated in an index specific dictionary, which also contains the occurs field as described in the data dictionary. De-duplication is performed as data are retrieved by temporarily storing the selected fields as the keys of a Python dictionary data structure, meanwhile tracking the number of collisions in the occurs field. In the case of titles, circulation data are extracted and added to the occurs value
In the partial extract script, only records newly cataloged since the previous update are included. Deletions and modifications to existing suggestions do not factor into partial loads; these changes can only take place in full reloads. To enable either of these functions would have required a large expansion of the data set stored in Solr in order to recognize if a record edit should result in the removal of a suggestion from the index. In our implementation, we perform partial updates twice daily in accordance with the update schedule for the catalog. Full reloads are performed when catalog reloads occur, but this is not a scheduled event.
In order to export the data from a Python dictionary to a format readable by Solr, the loading script generates pipe delimited files containing the full set of properties contained in the data dictionary: ac, type, occurs, source, and ackey. It should also be mentioned that for partial loads, if a suggestion previously existed, the occurs value is retrieved from Solr and combined with the new value. As the pipe delimited data are generated they are segmented into X number of files, where X is the total number of suggestions by index type divided by the maximum number of suggestions per file (300,000 in the UNC implementation). In our testing, attempts to load more than a gigabyte of data at once slowed down the insert process considerably. As a result we limited the file length to 300,000 lines to keep the file size below 100 megabytes each. These pipe delimited files can then be loaded directly into Solr via a POST request to a built-in servlet that handles delimited inputs rather than XML.
Development Process
Early in our development cycle, we attempted to use MySQL for storing and searching the suggestion collection. We started with this approach because MySQL is the standard package used for custom database applications at our institution. While the system did work under this arrangement in a development environment, we worried that a 7 million item database performing multiple text searches per catalog query would exceed the scope of MySQL. At that point, we began to investigate the use of Solr.
This decision carried with it some additional benefits, namely the speed with which Solr allows for mixing text search methods and other weighted ranking metrics. We did briefly experiment with alternative search methods, such as double metaphone phonetic matching [7] to compensate for spelling errors, but concluded that this introduced too much noise into the results. After considerable tweaking and research into the behavior of other similar suggestion features in commercial websites, we settled on the mixed begins-with and keyword model described in this paper. The adoption of this model allowed for easier suggestion of unknown or partially known items than a begins-with only model, particularly for LCSH subjects where users often do not know the proper syntax and formatting.
Aside from these concerns, refinement of the Solr query structure to accommodate more difficult cases, such as stop word heavy inputs or author names that commonly appear as titles, required a significant amount of development time. Ultimately, there were additional refinements that, while beneficial to the quality of the suggestions, resulted in a performance hit. If the system were not required to provide users with immediate feedback, as in a more traditional synchronous query and response model, these enhancements likely would have been reasonable inclusions. It should be mentioned that some tweaking of rank weightings would likely need to be done at any institution implementing this feature to best match their own datasets, even if the algorithm were consistent.
Additionally, in our original design we had planned to include user queries as well as suggestions extracted directly from our catalog data, merging the two sets in a method similar to that described by Yang et al. [8]. However, concerns over privacy, index maintenance, and development time eventually led us to include only bibliographic and circulation data.
Analysis
To determine the effectiveness of the auto-suggest feature we have performed periodic access log analysis since the feature’s launch in January 2010. Based on this information, we found that users began using the feature immediately upon its implementation, with 18.99% of queries issued in the first week using suggestions from our index. Since then, the usage rate has averaged 18.06% of searches from forms that offered the service. Some pages, such as our advanced search pages, do not at present employ the suggestion feature, but 88.68% of all searches are made from forms that do offer it. Users perform on average 7682 new searches in the catalog per day, which generate an average of 38426 requests to the auto-suggest service, an average of about 5 requests per search performed.
One of our primary interests in implementing this feature was to determine what effect it would have on users’ utilization of authority data. As a result, we focused much of our attention in statistics gathering on tracking the changes in usage of index specific searching and how these related to which suggestions users selected.
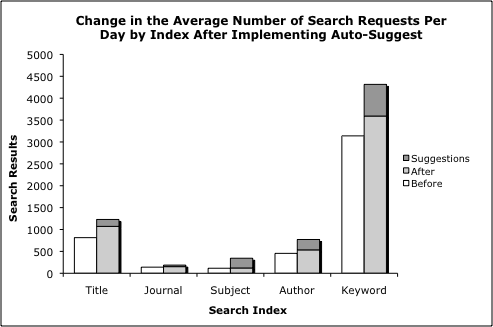
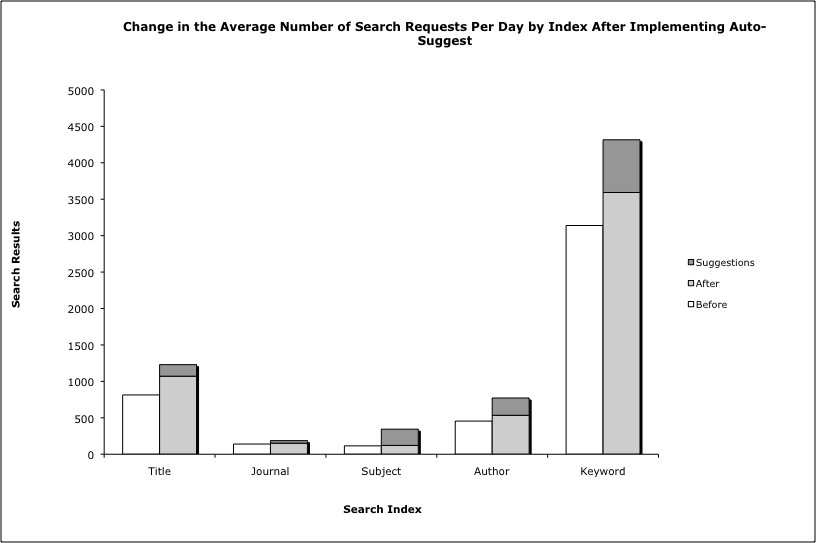
Figure 3: Change in the average number of search requests per day by index after implementing auto-suggest. (view larger)
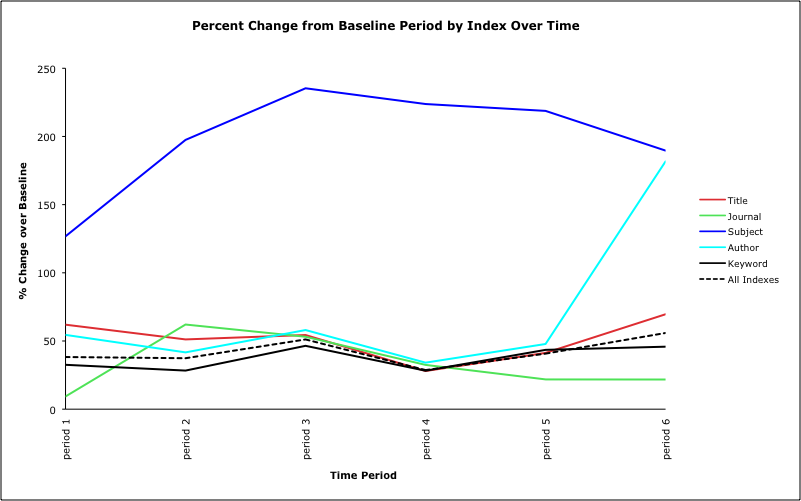
In doing so, we discovered that the largest change in search behaviors was in the rate of subject index searching. Although subject searches are a relatively minor portion of the overall queries performed in the catalog each day, just 3.92%, they have seen the largest percentage increase in use. During the baseline period before enabling real-time suggestions, there were on average 115 subject searches in the catalog per day. After implementation, the average number increased to 343.8, a 198.6% increase, of which 222.7 were from the suggestion service.
Similarly, author searches increased 69.64% over the same period. Overall, the total number of searches in this period increased 42%, so the changes for subject and authors are significantly higher than that of the overall set. It is not clear how much of the total search increase is related to the time of the academic year and how much is related to changes in the catalog, but both are likely factors. We attempted to minimize the impact of the former by choosing a baseline during moderate to heavy traffic periods during the 2009 fall academic semester, but we did not have log information available far enough back to compare year over year changes.
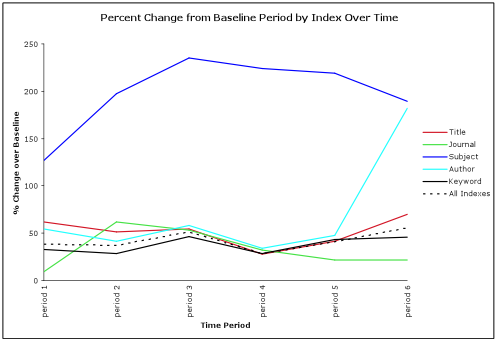
Figure 4: Percentage change in the average number of searches issued by index per sampling period versus the baseline period before the implementation of the auto-suggest feature. The All Indexes series represents the change in the average number of searches across all indexes. (view larger)
Users choosing to preselect a search index made up 14.52% of suggestion searches. The increase in subject and author suggestion searches are mainly due to the automatic index selection feature described in the User Interface portion of this paper. On the other hand, generic keyword searching, which makes up 56.89% of all searches, saw a 3.01% decrease in usage during this period.
The impact of the service on system resources has so far been minor. As of the launch of the service at UNC there were 7244000 suggestion entries, including 1131000 Authors, 3933000 Titles, and 2179000 Subjects. These suggestions were derived from around 4.95 million individual records in the UNC catalog. The actual memory usage of the index was roughly 115mb, excluding caching, and suggestion queries average around 200ms execution times. It should be noted, however, that the implementation of this feature resulted in an increase in the average number of terms per catalog query, which can have an impact on performance of the catalog itself.
Conclusion
Providing users with real-time feedback in the form of query suggestions provides unique opportunities for presenting users with catalog authority data in a familiar and helpful manner. Since doing so, the UNC Libraries’ discovery layer has seen a significant increase in the rate of subject and author searches, where almost 2/3 of subject searches are selected directly from the suggestion service. The use of Apache Solr has offered a scalable and flexible back-end for implementing a feature that has been adopted by users for 18% of all searches in a major research library’s online catalog. JQuery’s Autocomplete library allowed for a heavily configurable user interface experience, while only requiring a minor time investment to establish the basic functionality needed to enable the user’s interaction with a query suggestion web service.
The success of this project has led us to consider other potential applications for the auto-suggest service. We are currently investigating the possibility of integrating the service into tools used for local non-MARC metadata creation, such as for digital collections materials, or items in the institutional repository. In these collections, which often depend on student labor for metadata creation, we face challenges in normalizing descriptive metadata within and across collections. A tool that would allow users to enter a descriptive term and receive a list of possible authorized forms of the term would both improve the accuracy of descriptive metadata and speed the description process.
We invite your comments and questions about this service, and would welcome your ideas for other useful applications of this tool.
References
[1] Endeca Information Access Platform: http://www.endeca.com/products-information-access-platform-mdex-engine.htm
[2] Search TRLN: http://search.trln.org/
[3] UNC Chapel Hill Library’s Online Catalog: http://search.lib.unc.edu/
[4] Jquery Autocomplete Plugin: http://docs.jquery.com/Plugins/Autocomplete
[5] Apache Solr: http://lucene.apache.org/solr/
[6] Hemminger, B. & Lown, C. (2009). Extracting user interaction information from the transaction logs of a faceted navigation OPAC. Code4lib Journal, (7). http://journal.code4lib.org/articles/1633
[7] Wikipedia: http://en.wikipedia.org/wiki/Double_Metaphone
[8] Yang, J., et al. (2008). Search-based query suggestion. Proceeding of the 17th ACM conference on Information and knowledge management, 1439-1440. (COinS)
About the Authors
Benjamin Pennell (bbpennel@email.unc.edu) is Applications Analyst and Jill Sexton (jill@email.unc.edu) is Information Infrastructure Architect at the University Library at the University of North Carolina at Chapel Hill. Together they are UNC’s catalog implementation team.

{kind=link}
{kind=link}
{kind=link}
Technical skills for LIS professionals « Librar*, 2011-06-25
[…] on June 25th, 2011 I am pretty fascinated by some of the really great developments to library web interfaces I’ve seen recently. I am also a bit disillusioned at times by the lack of IT flexibility […]