By Tonio Loewald and Jody DeRidder, University of Alabama
At the University of Alabama, we have developed a simple, robust digital library system using PHP, MySQL, and Apache. The new system is free, easy to set up and administer, imposes no new work flows or skill set requirements on archivists, bypasses the need to create extra metadata wrappers, works in all major browsers, runs on the most common web server stack, and automatically creates and updates its own index database (while storing no valuable data inside it). Details can be seen at http://acumen.lib.ua.edu/project.
Why a new system?
Experience and frustration with our former digital collections platform had resulted in considerable discussion as to what a perfect, or at least “good”, system might look like. By the time the first author joined the project, a number of key considerations had already been settled on, for example:
- Ingestion needs to be streamlined and lossless (“what goes in comes out”)
- Lightweight web services architecture
- Modular rather than Monolithic (small, individually useful components)
- Work with the outside world (e.g. outside search engines), not against it
- Do not place new burdens on archivists (who were already on our critical path)
It seemed that what our stakeholders really wanted was something that would automatically scan repositories and then make the content searchable and readable online without requiring them to perform any extra work. No such thing appeared to exist. So we decided to build one.
Overview
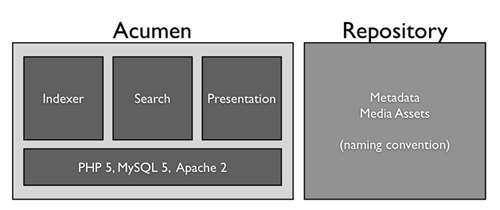
Figure 1. This is a high level view of the Acumen architecture. It’s built on the most widely deployed and inexpensive server stack and makes very few assumptions about the contents of the repository whose content it will index and display. Click here for a larger image
Our solution, which we call Acumen, is free, and built on top of other free, open source technologies such as PHP, MySQL, and Apache[1]. It comprises three main components: Indexer, which locates files and creates index entries for them; Search, which provides a user interface for searching the index database and displaying results; and Presentation, which turns XML metadata files and associated media assets into something easy to view and navigate.
Easy to Use
A free tool can quickly become expensive if it is hard to use. Our goal is for Acumen to be as easy to install as popular, well-written free web applications (e.g. WordPress or PHPBB)[2], to run on not just free but ubiquitous, popular, and well-documented server stacks (PHP, MySQL, Apache), and require no extra work or training of anyone, including the people who create and maintain metadata, system administrators, and end-users.
No special Apache configuration is required (a simple .htaccess file can redirect URLs to the PHP script directory) and the only slightly unusual PHP module we currently use is php_xsl (which is included in default installations, but may need to be “toggled on” by changing a configuration file).
Ingestion
Metadata does not need to be prepared, tweaked, or modified in order to allow Acumen to provide users with access to it; it merely needs to be valid XML. Just as Google (and other web crawlers) index the web without placing any special requirements on the creators of web pages, Acumen indexes metadata without placing special requirements on archivists. Just as Google will send users to a web page that has changed since it was indexed, Acumen shows the data in the repository, not the data it scanned when it created or updated its index.
Acumen indexes raw metadata directly by summarizing it on-the-fly using XSL. The output is a simple XML file largely consisting of some content nodes — the indexing engine parses the output and stores the content of each node as an authority record attached to the metadata file record of the specified type.
Acumen renders metadata as web pages the same way, and then builds a user interface around the results (inside the end-user’s browser) using JavaScript and CSS. All of the original data lives in the repository — Acumen does not touch it.
Workflow
Acumen makes few assumptions about how a repository is created. A repository is assumed to be a collection of metadata and digital asset files that adhere to a naming convention. How those files are created and managed is outside its purview. As such, Acumen has virtually no impact on existing workflows — produce the metadata and digital assets, name them in a specified way, and stick them on a web server where Acumen can find them. That’s it.
In practice, when we capture digital objects (e.g. by scanning or audio capture), we enter metadata into large spreadsheets. This metadata is then converted into standards-compliant XML. In the past this process was both labor-intensive and prone to errors. Furthermore, ingestion into our previous tool had left much of our data in something of an undefined state.
As of version 1.0, Acumen will only index metadata that is in a format it recognizes, i.e. EAD, MODS, and METS XML. Adding support for a new kind of XML file requires two XSL files (one for summarization and one for presentation) and a row added to the file_type table.
Archivist Utility
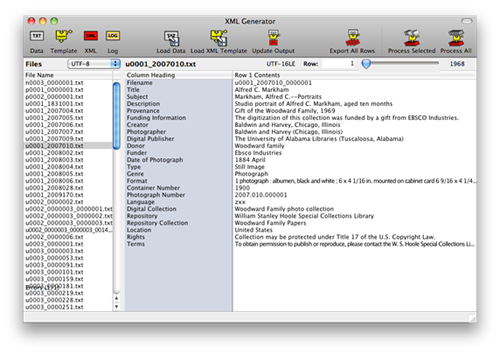
Figure 2. This is the data view of Archivist Utility. On the left is a collection of spreadsheets (exported as text) ready for batch-processing. On the right is a “database” view of the contents of the selected file. Click here for a larger image
To streamline the process of getting raw data into XML we developed a desktop application —Archivist Utility[3]— which processes spreadsheet data into XML using a flexible template system that is rather more sophisticated than, but similar in concept to, mail merge. Unlike typical mail merge, our template system supports conditional tags, repeating sections, transformations on incoming data, stores unused data from the spreadsheet in XML comments, strips empty tags from the resulting XML, and “pretty prints” its output (e.g. with nice indentation). A more complete description of Archivist Utility is beyond the scope of this article.

Figure 3. This is the Archivist Utility’s template view. The template “language” allows for conditional and looping constructs; e.g. a spreadsheet field which contains a comma-delimited set of subjects can be converted into a sequence of node hierarchies. Template insertions are marked with doubled cURLy braces, e.g. “{{if:Publisher:Data ISO}}” inserts the content of the “Data ISO” column if the “Publisher” column is non-empty. The template language also supports looping structures and error reporting mechanisms. Click here for a larger image
We should note that Archivist Utility is in no way needed to use Acumen. If, as of version 1.0, metadata is already in EAD, MODS, or METS, nothing else needs to be done for Acumen to index and display it. Adding support for additional types of metadata is straightforward and discussed earlier.
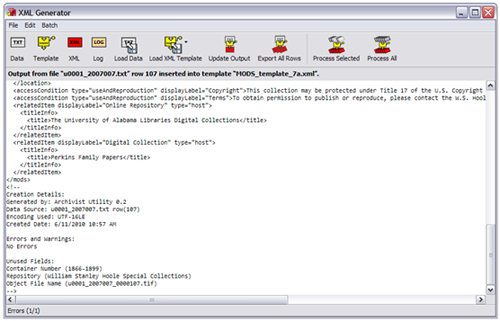
Figure 4. Archivist Utility allows the user to preview its output. Archivist Utility both strips empty sub-hierarchies out of its output, and “pretty prints” the files to make them easier for human beings to read. Click here for a larger image
Archivist Utility may also be of use even without Acumen. It is useful for both converting large spreadsheets into XML via templates that can be created and tweaked quite easily (by populating a sample XML file with tags), and for interactively editing XSL and seeing its effect on source XML files.
Acumen’s Naming Convention
Acumen’s file-naming convention comprises four simple rules, and should make sense even without formal documentation:
- A file (metadata or asset) has a name comprising a base (e.g. “foo_bar”) and a tail (e.g. “_2048.jpg” or “.ead.xml”).
- The base is assumed to be unique for a given kind of file, and files of different type with the same base are assumed to be related (assets with a given base name are assumed to be described by metadata files with the same base name). E.g. foo_bar.xml is assumed to describe foo_bar.jpg, foo_bar.ocr.txt, foo_bar.txt, and foo_bar.mp3.
- The tail denotes the file’s type, and Acumen allows types to be more specific than simple file type, e.g. “_2048px.jpg” is used to indicate an image scaled to fit inside a 2048 x 2048 pixel square.[6]
- Base names are assumed to be hierarchical, comprising a series of alphanumeric identifiers separated by underscores (“_”)[7] , with the underscores denoting hierarchical relationship. E.g. “foo” contains “foo_bar” and “foo_baz”; “foo_bar” contains “foo_bar_001” and “foo_bar_002”.
Of these rules, the only one that Acumen strictly requires is uniqueness. Acumen assumes that foo_bar.xml is foo_bar.xml regardless of where it finds it. If two or more metadata files share the same base name (e.g. two files named foo.xml, or foo.ead.xml and foo.mods.xml) then this will be flagged as a potential error, and only one file will be visible to end-users (based on a configurable order-of-precedence per file types and, for files of the same type, latest modification date). Because file base names are unique, Acumen uses them to provide stable URLs. It follows that if a metadata file is replaced by a new file of a different type, the URL will stay the same.
Automatic Indexing
The following snippet of code (from our config.php source file) shows how Acumen can be configured to handle local and remote repositories. A repository must have a specified web root; if no file system root is provided, Acumen indexes the repository by crawling web directories (by parsing the default “index.html” listing produced by Apache, and most other web servers, by default), otherwise it uses the file system (which is faster and provides better information).
// $REPOSITORIES is a global array of repository instances $REPOSITORIES = array(); // ‘Test Files’ is local so we provide a file-system path to it $REPOSITORIES []= new repository( 'Test Files', 'http://localhost:8888/repository/', '/Users/tal/Sites/repository/' ); // ‘Acumen Content’ is remote repository so we simply provide a URL $REPOSITORIES []= new repository( 'Acumen Content', 'http://acumen.lib.ua.edu/content/' );
Assuming the metadata follows a specified naming convention and resides on a web server, simply point Acumen at the repository and its content automatically gets indexed. Once indexed, it is automatically searchable and automatically rendered for end-users. For fully-automatic indexing, one further step is needed: a cron task somewhere that periodically requests auto.php (wherever it is installed) via http. Our system uses cron to request auto.php once per minute. Acumen can also perform index passes interactively via its admin interface, and for testing purposes we’ve also created a simple desktop app which can poll auto.php as well.
For all of this to work, Acumen requires that:
- Files in the repository adhere to Acumen’s naming convention. The naming convention allows hierarchical relationships to be encoded in names (e.g. foo contains foo_bar contains foo_bar_baz) and file types and purposes to be consistently represented at the end of file names (e.g. .XML indicates an XML file, .ead.XML specifically indicates an EAD, and _2048px.jpg indicates an image that fits inside a 2048×2048 pixel square).[4] In our repository, the first portion of a name reflects provenance, the second collection, the third item number, and the fourth is sequence.[5]
- The indexer is schema-agnostic (and can identify XML files either by naming convention or by “sniffing” for signature strings). To support a given kind of metadata one need simply provide two XSL files (one to summarize it and one to render it). We have thus far implemented XSL to support METS, MODS, and EAD.
- The digital assets exposed to end users will need to be in certain formats and also follow certain (customizable) naming conventions. These assets can be created automatically from whatever archival formats are being used.
Thumbnail and web-distributable images may need to be created from archived images files. Again, this can be done automatically and fairly easily. As noted above, the indexing engine can be invoked manually (via a web admin interface) or automatically (via a cron job or similar). There is also the desktop application that can drive automatic indexing from any computer with web access.
The indexer performs a complete scan in three stages:
Scanning. The indexer recursively walks each repository one folder at a time. Each folder encountered is added to a task list, while files are categorized as metadata (generally XML), digital assets (e.g. JPEG, MP3, MPEG4), or something else (ignored or logged). Each metadata file is summarized using XSL and the results stored in a database. Each asset is simply recorded in the asset table.

Figure 5. Assets are associated with metadata via our naming convention. In this case page one of chapter one of austen_pride has three associated assets, an image, some OCR text, and some text (the latter presumably a hand-edited version of the OCR text). Click here for a larger image
Asset Assignment. Assets are assigned to metadata files based on naming convention. An asset with the same base name as a metadata file is assigned to that file; if no such file exists then it is assigned to the file which would be that file’s “parent” if it existed, and so on. E.g. austen_pride_01_01.txt has the base name austen_pride_01_01, which is identical to that of the metadata file austen_pride_01_01.xml and thus is assigned to it. If austen_pride_01_01 did not exist, the assets currently assigned to it would instead be assigned to austen_pride_01.
Assets with no parents are considered “orphans”. Orphan assets are not visible to end-users because access to content is via metadata (and an orphan, by definition, has no metadata). During the indexing process, an asset indexed before its corresponding metadata file will temporarily be an orphan. When an indexing pass is complete, the presence of any remaining orphans is recorded, since these may be errors or omissions.
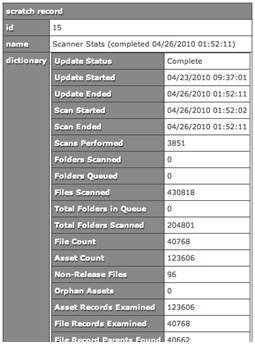
Figure 6. Our admin interface provides access to current and past scan results. The presence of orphan assets is immediately apparent in the results.Click here for a larger image
When a user views a metadata file, the presentation system looks for assets already in the index that ought to belong to a metadata file and assigns them “just in time”; if no one looks at that file, the assets will still be assigned when the indexing engine gets to that file as a matter of course.
Because we can infer relationships between metadata files and assets purely from our naming convention, the need to create XML metadata wrappers (such as METS) for individual elements of complex objects (e.g. pages of a book) is eliminated.
This system works admirably for objects that are ordered sets of things (as books are of pages or record albums are of tracks), but not all relationships between assets and metadata can be inferred purely from naming convention. We are in the process of ironing out how to handle some more complex examples, such as:
- Assets which themselves contain metadata which might need to be assigned to the metadata file that owns the asset (e.g. text transcripts of an image or audio track)
- Assets which are in themselves “more than one thing,” such as concert recordings which comprise performances of several different pieces.
Ultimately, if a relationship can be represented in XML in some satisfactory way then it can be parsed out via XSL, but we certainly haven’t covered every possible case.
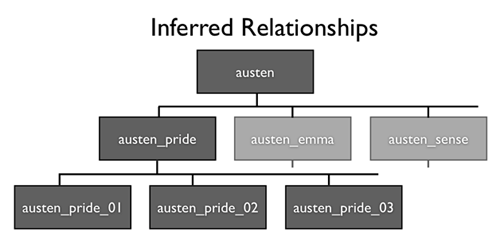
Figure 7. If metadata files in a repository follow Acumen’s naming convention the indexer can infer hierarchical relationships between them. This diagram shows how our naming convention would represent a hierarchy of related items. (File extensions have been omitted for clarity, and our actual names are not in themselves meaningful, e.g. u0003_000345_000002.) Click here for a larger image
Metadata Hierarchy. Each metadata file not already owned by the “obviously correct” parent is assigned (if possible) to a parent metadata file. Metadata files with no parents are considered “apical” (i.e. they are the top of a hierarchy — which makes them more prominent in collection listings). Metadata files with no children (“leaves”) are suppressed in collection listings, unless they also happen to be apical.
It is important to note that a complete scan against an empty database rebuilds the index from scratch while a complete scan against an existing database updates it (including flagging missing files as missing, moved files as moved, obsolete files as obsolete, and so on).
Search
Once a repository has been indexed by Acumen (and during the indexing process itself) it may be searched Acumen’s search interface, which allows users to create arbitrarily specific queries, refine existing queries, and exchange stable query URLs.
Owing to our very simple database architecture (three main tables), search queries are both simple and efficient. The user interface restricts queries to ANDs, which keeps searches very fast. Our search back end is completely flexible and allows queries to be built from URLs in Polish notation[8], defined thus:
/s/{/[_and|_or/]_contains(_all|_any|_exact)[_considercase]//{+}}
In concrete terms this UI:
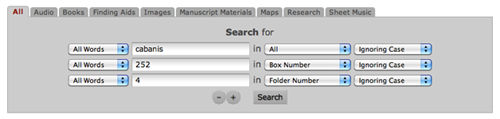
Generates (and is generated by) this URL[9]:
/s/all/_and/_contains_all/All/cabanis/_contains_all/box_number/252/_contains_all/folder_number/4
Which becomes this SQL fragment:
INNER JOIN authority as a0 ON file.id = a0.file_id INNER JOIN authority as a1 ON file.id = a1.file_id INNER JOIN authority as a2 ON file.id = a2.file_id WHERE ((a0.authority_type_id = '17' AND (a0.value LIKE '%4%') AND a1.authority_type_id = '16' AND (a1.value LIKE '%252%') AND (a2.value LIKE '%cabanis%')))
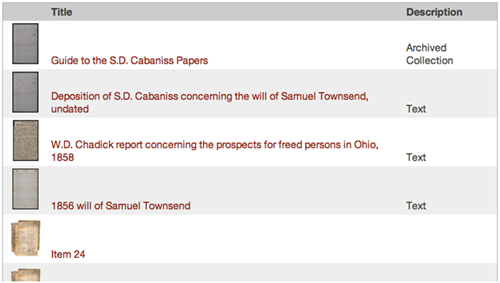
Search results are rendered conventionally on the server, but an obvious (and planned) refinement of this would be to allow XSL rendering of search listings so that different kinds of records can be rendered more flexibly. Here is an example of what our search results currently look like:
Other Features
Categories. Acumen allows for categories to be specified simply by providing a category name and a query that will specify members of that category.
Collections. Acumen provides support for collections, currently based on naming hierarchies. The logic which determines relationships could easily be modified by other institutions to handle other methods of representing hierarchies and other relationships, such as folder hierarchies or explicit links.
Discovery. Acumen provides a simple discovery interface comprising randomly selected thumbnails picked from the currently selected search category. We plan to substantially improve our discovery interface and add curatorial tools.
Immediate Indexing. In addition to automatic indexing, Acumen allows archivists to index a specific directory interactively and out-of-order so that it immediately becomes available.
URL Stability. Providing stable, clean URLs is a core design goal of Acumen. Because we require metadata files and assets to have unique names, our URLs are completely independent of repository structure (so repositories can be restructured without changing object URLs).
Exposure to Search Engines. Acumen automatically generates site maps and complete listings of all its content in the form of stable URLs.
Presentation
Once Acumen is installed on a web server and has completed indexing a repository (or repositories) it will allow users to search and view the repository’s content in any modern web browser (we’ve tested it with IE7 and IE8, as well as current and recent releases of Firefox, Safari, Chrome, and Opera).
When a user clicks a link, the original metadata file is located in the repository, its type is retrieved from the index database, and the appropriate XSL stylesheet is located to render it into human-readable form. At this point the original metadata is then rendered to HTML on the server “just in time” and sent to the user’s browser or — if the link ends in “.xml” — the stylesheet is linked to the metadata file and the file itself is sent to the user’s browser which then renders it to HTML in the browser.
It follows that changes made to metadata files are immediately reflected on the end-user’s browser, even if the indexer hasn’t scanned them yet.[10]
Data Access API
No data access API is needed — Acumen does not ingest data, and the raw data is made available to anyone.
By default we create HTML representations of raw metadata files (such as EAD and MODS files) via XSLT on the server, and then pass the resulting HTML to a user’s web browser. But if “.XML” is added to one of our metadata URLs, we send the original XML with an XSL stylesheet tag inserted to the end user’s browser, which (a) gives end users complete access to raw data with no intermediate translation or loss, and (b) looks just like a regular web page.[11]
Moreover, we make our entire repository — both metadata and digital objects — available via the web (Apache can be configured to block access to files by type, if desired, or a repository may simply be a mirror of an archive which omits some files), allowing third-party software, web crawlers, agents, and web applications to access our data.
It follows that any changes to existing metadata files become available to end-users as soon as they are placed in the (web-accessible) repository and are searchable as soon as the indexer scans them. One of the fields we store as a matter of course is the full content of each metadata file stripped of tags. Searching for content contained in a tag which is not handled by the existing XSL is always possible (by searching metadata file content).
Furthermore, if we want to store data in a new searchable field we can simply add it in the XSL (e.g. we might want to add a new field named “medium” which we could do simply by outputting in our XSL summary). When the indexing engine parses this tag it will simply create a new entry in the authority_type table for “medium” and the search interface will immediately pick this up and make it searchable.
As a final note, the indexing engine skips metadata files which it has already scanned if neither they nor the summary XSL file has changed since the last time they were scanned. Thus, changing a summary XSL file will force all metadata files of the type it summarizes to be reindexed.
Summing up and moving forward
The system described has been in development for slightly more than twelve months to reach release (“1.0”) quality, having been in usable “beta” form for six of those months. Moving forward we plan to make it more modular and easier to configure and use, while adding functionality.
This is a project that can be infinitely refined, but our goal has always been to do as little as possible while asking as little as possible of everyone else. While we have not chosen to use an off-the-shelf product, we have made use of some very powerful off-the-shelf components, including XSLT — which does most of the heavy lifting in our indexing and presentation components, and affords us almost limitless opportunities to improve both without writing another line of “code” — and jQuery — which vastly simplifies the client-side interactivity layer.
In essence, Acumen is a lightweight wrapper around XSLT, and a great deal can be achieved (e.g. different or more attractive presentation, customization, improved indexing) simply by adding to and refining our XSL.
“In the long run,” to quote John Maynard Keynes, “we’re all dead.” It is worth considering what will be left behind when our software is no longer there.
Acumen specializes in discovery and presentation, effectively modularizing digital delivery so that maintenance and archiving remain outside of the system, under the direct control of the implementers. This simplifies workflows and reduces time and effort in metadata remediation, migrations, and content management.
To deploy Acumen, repository content must adhere to a self-explanatory naming convention, and the contents of metadata files must adhere to standards and be kept in good order, and all of this must reside on a web-accessible server.
Remove Acumen, and what remains is repositories of standards-compliant metadata with consistent file names.
Notes
[1] Acumen requires (or at least has only been tested with) PHP 5.2.x, MySQL 5.x, and Apache 2.x. It works with current and recent installations of Ubuntu Linux, MAMP (on the Mac), and WAMP (on Windows).
[2] Our installation and hot fix processes are both documented and will be available for download. The installation process is comparable in complexity to WordPress or PHPBB.
[3] Although this tool will be made available for free along with its source code, it was developed in Realbasic (http://realbasic.com/) which is not free or open source (although the basic Linux version is free). Archivist Utility runs on Mac OS X, Windows, and Linux. We plan to port this tool to our web platform.
[4] Names are assumed to be unique in the sense that if multiple things (e.g. a metadata file and an image) have the same “base name” (i.e. not including file type “tail”) then the system considers them to be part of the same object.
[5] This naming convention reflects the LOCKSS journal hierarchy, and also works well with our automated LOCKSS system.
[6] We use unique tails for the various specific types of metadata files, e.g. “.ead.xml” for EADs, but because Acumen started being used before these conventions were in use it is also able to identify XML files by examining their contents.
[7] Different characters may be used with a change to the configuration file.
[8] Best known for being used, backwards, in HP calculators. See http://en.wikipedia.org/wiki/Polish_notation
[9] Note that the URL explicitly conjoins the search criteria with AND (rather than OR, or some parenthesized combination). As of version 1.0, the back end supports arbitrarily complex searches, but the UI only supports AND.
[10] A metadata file’s type could (and probably should) be determined on-the-fly just as it is during scanning, which would allow a metadata file to be replaced by a new type of metadata file and the new information to be correctly presented even if the changes had not yet been scanned by the indexer. We will probably revisit this issue when we implement a caching mechanism for rendered HTML.
[11] Until supporting older versions of Internet Explorer became a requirement, Acumen emitted XML by default and only sent HTML by request. It turns out that IE6 and 7 do not correctly handle even moderately large XML files.
About the Authors
Jody DeRidder (jlderidder@ua.edu) is Head of Digital Services at the University of Alabama Libraries. She is interested in developing and supporting practical, low-cost, scalable solutions to digital library problems, from capture and description, through improved usability, to long-term access and preservation.
Tonio Loewald (taloewald@ua.edu) is an Analyst/Programmer at the University of Alabama Libraries. He has developed educational and game software for both small children and large ones with advanced degrees, as well as a program for creating and deploying electronic questionnaires for social science research (RiddleMeThis). He believes that bad user interfaces are a kind of bug that manifests when software runs on people.

How does this Acumen thing work? | Digital Services @ the University of Alabama, 2011-05-19
[…] live as open source. Tonio Loewald is the developer, and we published an article about Acumen in Code4Lib last year, which will contain more detail than this blog […]
Jody DeRidder, 2011-05-23
Acumen has FINALLY been released open source:
http://sourceforge.net/projects/acumendls/
The long-awaited day has finally arrived. After many trials and tribulations, we have at long last released Acumen Digital Library Software open source!!!
This software is light-weight, easy to install (intended for Linux or OSX), easy to use, and it does *not* require munging your XML metadata into some software-specific form. You can load multiple kinds of content into it — finding aids in EAD, images with simple Dublin Core, TEI transcribed documents, audio with XML play lists, any kind of digital content you want with your OWN form of XML metadata.
You can have Acumen index content all together from multiple sites!! Thus this is an option for those wanting to set up state-wide digitization projects — or wanting to move away from CONTENTdm multi-site server software. Just include the base of the web-accessible directories in the configuration file.
The file naming is the key to organization and to delivery. But besides that — you can add, remove, change content at will in the web directory where you put it, and Acumen will automatically update the display during the next round of indexing.
How easy can it get? Acumen. Finally out there for free!! :-)
http://sourceforge.net/projects/acumendls/