The Invisibility of Digital Libraries
Seven years ago, Michael Bergman estimated that 500 times as much public information was available on the web as was accessible via web search engines, and that over half of that existed in topic-specific databases. A user is three times more likely to obtain quality results from a search of this deep web than from a search of the surface web via common search engines [Bergman, 2001]. The advent of web-accessible databases has made it possible for users to perform tailored searches over selected high-quality materials. However, traditional search engine crawlers are not equipped to create the concatenation of query parameters needed to functionally retrieve the desired objects from each of the multitude of variant databases [Sherman and Price, 2003]. Unless links are located on a static web page, crawlers won’t find them, and many such links are not followed. One study found that some “deep web” sites provide directories of static browse links to assist in accessing the database; yet no more than 32% of the holdings are indexed [He et al., 2007].
Mission: Visibility
Risvik and Michelsen outline three general methods for providing information to search engine crawlers [Risvik and Michelsen, 2002]. The most common is a pull model which permits the crawler to perform efficient selection of content, by server provision of meta-information about new or changed documents. A second approach would be to push meta-information directly to the crawler, sending notifications of new, modified, or deleted material. One variation on this could involve a client-side crawler; however, this is beyond the scope of most web server implementations [Brandman et al, 2000]. Risvik and Michelsen’s third approach is a hybrid of the first two: a proxy system checks site files and updates the crawler. In all three of these schemes, this meta-information (or sitemap) is considered of primary importance for enabling efficient communication between information providers and search engines. Sitemaps assist the crawler in identifying changed and newly-added material; however, they do not guarantee that the selected web pages will be included in search results [Google, 2007e].
A variation on the provision of sitemaps is the provision of a “gateway page” for crawlers. The DP9, an open source gateway service, was developed over the OAI (Open Archives Initiative) Protocol to provide HTML pages of links to crawlers, of which each link then would provide a metadata record containing a link to the full text [Liu et al, 2002]. However, Google has taken a strong stand against “doorway” or “gateway” pages created simply for crawlers. Violations may cause the site in question to be removed from their index entirely [Google, 2007c].
For a period of time, Google accepted the OAI 2.0 protocol method of providing Dublin Core records containing DC:identifier URLs as a method of submitting materials for indexing [Google, 2007f]; and Yahoo! agreed in 2004 to acquire OAI content from OAIster, a leading OAI service provider [Hodges, 2004]. An assessment in 2006 of the OAI results in both search engines seemed promising. Yahoo! had the highest coverage with 65% of the tested URLs, and Google (at 44%) had made an extra effort to obtain comprehensive coverage of large repositories, but not smaller ones [McCown et al., 2006].
An apache module, mod_oai, was developed under the aegis of the Mellon Foundation, to promote harvesting of a server by identifying all new and updated material for crawlers. As yet, however, it cannot extract descriptive metadata to identify each file, nor is it functional for dynamically delivered web pages [Nelson et al., 2006].
In addition, indexing of materials provided via OAI may be limited to the content of the metadata delivered, rather than the content of the pages linked in the DC.identifier field; digital libraries desiring full-text indexing may need another approach. One of the drawbacks of using OAI for this purpose is related to the URL limitations imposed by the search engines. The designers of Google have at least once stated that they will not follow URLs that clearly include the cgi-bin [Page, et al., 1999, p. 7]. Another may be the targeted documents themselves: even for acceptable URLs, the content of digital library files may also be non-textual (such as images or streaming media), which leaves nothing for a crawler to index [Sherman and Price, 2003].
An OAI repository may contain records with DC:identifier links to documents on a number of servers; however, for Google, the URLs in OAI records or sitemaps must be on the same server as the base OAI URL or the sitemap, and in a lower or the same directory [Google, 2007a]. This may also cause problems with the use of persistent identifiers, which provide a level of redirection to the current location of material. If so, Google advises the indication of permanent redirection in the http response [Google, 2007a]; however, there is no guarantee that the target URL will be replaced by the persistent identifier in the search index.
In addition, links to dynamic web pages may not be crawled; the terms “&ID=” should be avoided (a common practice of database URL responses), and the number and length of parameters should be short. Session IDs, JavaScript, cookies, applets, dynamic HTML and Flash can all prevent the crawler from indexing the site [Google, 2007a]. Web pages consisting of frames may also cause difficulty for crawlers, and alternate content in the “NoFrames” tag is recommended [Google, 2007g].
All of these issues may prove to be barriers to search engine crawlers for a digital library based on common database dynamic delivery systems. Directed query engines may be the only real solution for database visibility on the web [Bergman, 2001]. These engines are configured to restate a user’s query into the terminology and parameters necessary to access multiple known databases simultaneously via the web, and return results [Warnick, et al., 2001]. While directed query engines are an area of intense research, scalable solutions to enabling on-the-fly adaptation to a multitude of unknown database structures have not yet emerged. One alternative that has been proposed is a client-side query engine based on mini-web browsers that have been specially altered to manage dynamic elements and session maintenance; yet this is limited in searching databases to those with a certain finite list of possible values for entry into forms [Alvarez et al., 2004]. Another alternative under research is simply to derive methods for web search engines to redirect users to the most relevant databases, based on information available in the database query interface form [An et al., 2007].
One possible workaround is to create surrogate static web pages that contain the information to be indexed with links into the databases, then submitting links to the static pages in a sitemap. If indeed these pages are open to the public, and useful, then this alternative bypasses Google’s rule against gateway pages, and in fact has proved very successful in at least one implementation [Breeding, 2006]. Two drawbacks to this solution are that it requires development work (and maintenance); and that this sets the stage for inconsistencies between the static and dynamic information for each page [Scherle, 2007].
Page rankings (combined with text-matching results) determine the order of retrieval of the indexed material [Google, 2007b]. According to a study of users from 1996 to 1999, 70 percent of the time a user only viewed the top ten results, and over 50% of the users did not look beyond the first page; and by 2003, general users only viewed about 5 results per query [Spink and Jansen, 2004]. Hence, the order of retrieval is of primary importance; a very low page ranking may defeat the purpose of having the usefulness of any effort to have the pages indexed in the first place.
The original Google algorithms were based on such factors as proximity, anchor text, standard information retrieval measures, and PageRank [Page et al., 1999, p. 8]. In academia, importance of a document is sometimes determined by the number of citations to it; in a similar manner, the number of links to a document can help to determine its importance. Brin and Page, the original designers of Google, weigh each of the links according to the importance of the page containing the link, and use the anchor text within the link as index terms for the target document [Brin and Page, 1998].
Some of the information which determines how important a document is may be inferred. Examples include citations, popularity or usage, reputation, quality, and update frequency [Brin and Page, 1998]. Other information within the document that may impact the level of importance of a hit within the document are whether the term desired exists in a title, anchor, URL, as well as the size and type of font used in display [Brin and Page, 1998]. Ask had their own method of determining the “subject-specific” importance of the page that does the linking, but they also weigh importance of a page based on the number of links to it from other pages deemed valuable [Ask, 2007].
A study by Zhang and Dimitroff in 2003 compared various levels and types of metadata within webpages to their placement in results lists by search engines. They determined that metadata in general was helpful, and that use of the title, subject, and description fields (containing terms that appeared elsewhere in the web page, particularly in the title) provided the best possible combination for positive search results [Zhang and Dimitroff, 2005].
Choices made
The first choice to make is the user audience: what search engines should be targeted? Nielsen NetRatings ranked search engines by popularity in 2006; Google led the way with 49.2% of searches, while Yahoo! followed with 23.8% [Sullivan, 2006]. Monopolies rarely last, so the methods chosen to support access by Google’s crawlers need to be amenable to those of other search engines as well. For this study, the secondary search engines chosen were Yahoo!, and a smaller one with a reasonable following, Ask.
To provide for crawlability by all of these, common denominators needed to be chosen. Google, Yahoo!, Ask, and Microsoft Live Search all recently agreed to support the use of the Google sitemap standard [Carlos, 2007]. Autodiscovery of sitemaps by specifying their location in the robots.txt file is also supported by these four, though this method is not recommended due to content theft; instead, direct notification to each search engine via ping URL syntax is suggested [Pathak, 2007]. In addition, each search engine allows the submission of sitemaps individually, though a login may need to be created first. Google provides feedback on the viability of the sitemaps, links, and robots.txt submitted if their webmaster interface is used for submission, so this seemed the most valuable option, as it enables identification of errors, and correction of mistakes.
Other choices here, based on the research discussed above, include the types of links and the types of pages to which they link. To recap, the links within the sitemaps need to be relatively short and non-dynamic, avoiding the use of any parameters or values that would preclude indexing by crawlers, and the pages they link to must also be static and simply designed. To raise the ranking of results in searches, adding user-friendly, public browse pages that contain the same links could assist in increasing user access, and therefore linking elsewhere. The addition of useful metadata to the static web pages should also provide improved page ranking.
A further constraint is the feasibility of options given the skills and resources available. In this experiment, the database collection to be exposed is one of dynamic pages, created by cgi-bin calls using a lengthy list of parameters; the pages accessed contain JavaScript. One programmer was available for a few hours occasionally, and quick results (with little maintenance) were desired. This precludes a complete revision of the site, development of any major client-side intermediary, or migration to another software package.
With consideration to the above findings, the path chosen was to create simple, static versions of the dynamic html pages for full-text indexing by the search engines. Sitemaps needed to be created, and submitted, to direct the crawlers to these pages, while robots.txt files would be designed to prevent duplication of indexing. Metadata tags needed to be added to the static pages, and the title tag changed to reflect the collection being described. In addition, browse pages would be developed to direct users to the static pages, increasing the page ranking. Google, as the most popular, was chosen as the primary target; other search engines would be contacted later.
Implementation
By November 2006, a collection of 1081 finding aids were available online via DLXS (Digital Library eXtension Service). OAI records for the finding aids were released a week before the sitemap, though they contained temporary redirection links (in DC:identifier field) to a non-full text, dynamically rendered version of each finding aid. [1] This and other local variables would need to be considered during analysis of results, which would be primarily by parsing server httpd logs. A broader history of access statistics has been gathered for the finding aids (“fa”) collection since August 2003. After a slow beginning (15 hits in the last quarter of 2003), an average of 27 hits (or accesses) per month in 2004 and 29 in 2005, accesses jumped to an average of 109 in the first 11 months of 2006, with a huge increase to 516 in December 2006, after the influx of new finding aids and transfer to the new software. 2007 has continued the increase in hits, with 450-950 accesses each of the first four months, and over 1500 accesses each in May and June [DeRidder, 2007]. Figure 1 illustrates the monthly averages of hits and users prior to 2007, and monthly counts during 2007. The first sitemap was sent out in July 2007.
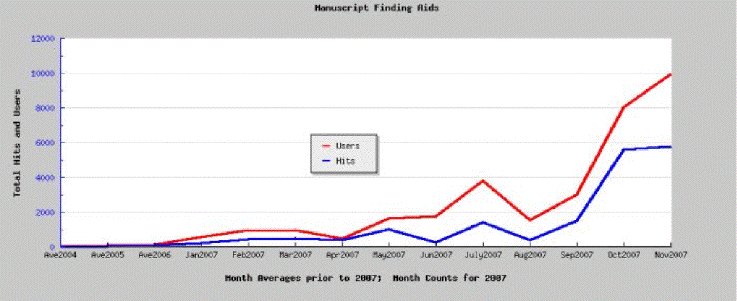
Figure 1 – Monthly average hits and users prior to 2007
Server httpd logs were gathered for analysis, beginning almost 6 weeks before a sitemap was submitted, in order to provide some base measurement. A database was created to hold the results, and a Perl script written to parse the logs and store the data for querying. Preliminary searches were performed on Google, using the site name and the collection name, as well as a selection of words which exist in each finding aid; none of these searches located the dynamic version of the finding aids, already available online for over 6 months.
A second Perl script was written to create a list of URLs to be followed to gather dynamic HTML pages, as well as a list of these with the last date modified and an identifier for the finding aid, for use in creating the sitemap. A third Perl script using the network utility wget, parsed the first list of URLs to obtain and create static web page copies in a designated directory, and then renamed them to match the identifier (for maintainability):
$url = qq{ $url };
$string = "/usr/bin/wget -nv -nd -nH -a ";
$string .= $log --no-cache -P $prefix --ignore-length $url";
# -nv (not verbose output)
# -a logfile (appends to log)
# -nd (no directories - don't create directory structure)
# -nH (no host --leaves off hostname from filename written)
# -P (prefix this to filename, to write to certain directory)
# --no-cache (don't get cached version)
# --ignore-length (prevents problems with CGI returns)
$status = system( $string );
if ( $status ne 0 ) {
# save errors for output/email later
push ( @errors, "$url could not be fetched." );
}
else {
# rename to user-friendly filename, removing cgi reference
$moveit = $path . "\*" . $filenum;
$newplace = $path . $msnum{ $filenum } . ".html";
$move = "/bin/mv $moveit $newplace";
$status = system( $move );
if ( $status ne 0 ) { push ( @errors, "$move failed." ) }
}Perl script to create static web pages from list of URLs
Since time was pressing, metadata addition to the static pages was postponed, and a sitemap was created next. Google provides a sitemap generator program, but it requires the use of FTP and Python [Google, 2007d], the former of which is locally considered a security risk. However, the sitemap protocol (available from sitemaps.org) is simple enough, and so one was created with another Perl script. Google states that all sitemap information and URLs must use entity escape codes and be UTF8-encoded; in particular, the following standards must be observed: RFC-3986, RFC-3987, and the XML standard [Google 2007e], so these restrictions were followed. Google will only allow sitemaps containing a maximum of 50,000 URLs for a total size of no more than 10MB [Google, 2007e], but multiple sitemaps may be created, and linked in a sitemap index which then becomes the file to submit [Sitemaps.org, 2007].
The first sitemap (uploaded 17 June 2007) was accepted, and a recent study of the behavior of the three largest crawlers (Google, Yahoo! and MSN) indicated a regular pattern of requesting an index page or two, then traversing the site at least 9 days later [Smith, McCown, and Nelson, 2006]. Google proved this incorrect: within 5 days, Google had attempted to crawl all 1081 files, with 5 failures. The damaged files were repaired, and the sitemap resubmitted, but Google did not immediately respond. At this point, another script was written to add Dublin Core metatags (for title, subject, and description, per [Zhang, 2005] and [Sullivan, 2007]) to all the files, containing information extracted from the finding aid itself; the title of each page was also changed to reflect the finding aid title rather than the previous shared title “Finding Aids Collection.” The sitemap was updated and again submitted.
In addition, a robots.txt file was created (protocol available from robotstxt.org) to preclude the possibility of compliant search engines duplicating indexing by harvesting both dynamic and static web pages containing the same content.
Conundrums and adaptations
By 4 July 2007, seventeen days after submission of the first site map, thirteen days after completion of the first complete crawl, the first referral to one of the static pages from a Google search appeared in the logs. A site search on Google showed that the original files were all indexed and accessible by keyword search. Page ranking was still very low. The next steps were clearly to increase user traffic and linking from other sites, in order to improve the retrieval function. The methods here were twofold: to add browsing of the static pages to public access, and to submit the sitemap to other search engines.
Submission of the sitemaps to new search engines was implemented first, while the browse system was being designed. The sitemap was submitted to both Yahoo! and Ask search engines on 18 July 2007. Within 24 hours, Yahoo! had begun crawling the site, selecting a few files each time, but visiting sporadically. Within 2 weeks, only 82 files had been crawled, out of 1081, which was disappointing.
Browse structures (by author, subject, and manuscript numbers) were created for the static pages, each of which include a link to the dynamic display for greater usability. Within 5 days of release to the public on 24 July 2007, non-bot hits on static pages increased 5 fold over the previous week. [2] The majority of these hits were referred from the new browse pages, with the subject browse clearly the most successful of the three. [3] Searches in the first month were almost 10 times greater than the highest number of searches ever recorded in a single month. [4] In addition, crawler hits (besides Google and Yahoo!) on the static pages increased phenomenally with the addition of the browse pages [5], indicating that sitemaps alone are not the answer.
Results
The development of a browse system to increase page ranking has been gratefully welcomed by our constituents, but it adds to the price of maintenance, as do the static pages themselves. However, indications show that this solution is well worth the effort. During the week following the creation of the browse pages, 4 search engines besides those contacted began to crawl the static html pages linked from the browse: MSN, page-store, authoritativeweb, and Jyxo. [6]
The Ask search engine did not begin indexing for almost five months. Yahoo began tentatively, but within 4 months had completely indexed the site. In comparison, Google’s response has been gratifying. Within five days of submission of the sitemap, Google had made their first crawl; less than 2 weeks later, the files were indexed.
Within 4 weeks following the creation of the static finding aids, users began to access them via Google. Over the following 5 weeks, 208 users accessed these pages; a small increment. However, after 5 months, 15 known search engines are now crawling the site. This indicates a major shift, and a major success in achieving visibility. [7] As the location of the static files have become better known, the page ranking has improved markedly [8] and our accesses have continued to grow.
Conclusion/Summary
The popularity of commercial web search engines among users indicates the benefits of leveraging their services for access to digital libraries. With the use of the sitemap method of communication with these search engines, the freely available wget software, and a few Perl scripts, dynamically delivered digital library items can be captured statically and provided functionally via web searches. Although the full-text version of the static files is less user-friendly than the dynamically-delivered versions, an added link to the latter can help to ameliorate the pain of this trade-off. In addition, browse indexes which serve to increase page ranking in search engine results, also increase usability to consumers. A surprise benefit of the static browse pages has been their success in channeling other crawlers to the static finding aids, which serves to further advertise their existence via various search engines. Thus, the static browse system enables crawling and indexing even by search engines which do not support sitemaps, and hence complements the sitemap method. Within three months of completion of this project, over 4 times as many hits and over 5 times as many users were recorded in a month as had ever been previously measured. Indications are clear that this dual implementation, even with the added processing work for new files, has been a winning strategy.
Footnotes
[1] Only 2 referrals from the persistent link to an associated finding aid were recorded during this 8-week study. Hence, the OAI record use of persistent identifiers has not (yet) enhanced the site’s access via web search engines.
[2] From 20 to 107.
[3] 85 referrals from browse pages; 66 from subject browse, 11 from MS number browse, 8 from author browse.
[4] 4045 searches were recorded in July 2007; the highest recorded previously was 463 in February 2007.
[5] Prior to the creation of the browse pages, there was only one bot hit on the static finding aids (besides Google and Yahoo); during the 5 days after, there were 60 such accesses. The following week, there were 997; the week after that, 1622.
[6] An open-source crawler (nutch) had located the static finding aids without apparently accessing the sitemap, and before the browse pages were created. However, the accesses were few and insignificant.
[7] Google, Yahoo, MSN, Ask, Nutch, page-store, authoritativeweb, SnapPreviewBot, YaCy-bot, MSRBot, AcceloBot, Majestic12Bot, YetiBot, PSBot, and Jyxo.
[8] 36 Google queries in the past 7 days (from 2 December 2007) have ranked our finding aids in the top 10 responses.
Bibliography
Ãlvarez, Manuel, Alberto Pan, Jaun Raposo, and Angel Viña. (2004) “Client-Side Deep Web Data Extraction.” Proceedings of the IEEE International Conference on E-Commerce Technology for Dynamic E-Business (CEC-East’04). (COinS)
An, Yoo Jung, James Geller, Yi-Ta Wu, and Soon Ae Chun. (2007) “Semantic Deep Web: Automatic Attribute Extraction from the Deep Web Data Sources.” The 22nd Annual SCM Symposium on Applied Computing (SAC’07), March 11-15, 2007, Seoul, Korea. Copyright 2007 ACM. (COinS)
Ask. (2007) “Web Search.” Webmasters documentation, copyright 2007 IAC Search & Media. http://about.ask.com/en/docs/about/webmasters.shtml Viewed 8 June 2007.
Bergman, Michael K. (2001) “The Deep Web: Surfacing Hidden Value.” Journal of Electronic Publishing, University of Michigan Press. 7:1, August 2001. http://www.press.umich.edu/jep/07-01/index.html Viewed 12 July 2007.
Brandman, Onn, Junghoo Cho, Hector Garcia-Molina, and Narayanan Shivakumar. (2000) “Crawler-Friendly Web Servers.” ACM SIGMETRICS Performance Evaluation Review, Volume 28 Issue 2. http://doi.acm.org/10.1145/362883.362894 Viewed 2 July 2007.
Breeding, Marshall. (2006) “How We Funneled Searchers From Google to Our Collections by Catering to Web Crawlers.” Computers in Libraries, April 2006. http://www.librarytechnology.org/ltg-displaytext.pl?RC=12049 Viewed 3 June 2007.
Brin, Sergey and Lawrence Page. (1998) “The Anatomy of a Large-Scale Hypertextual Web Search Engine.” WWW7 / Computer Networks 30(1-7): 107-117 (1998). http://dbpubs.stanford.edu/pub/1998-8 Viewed 7 July 2007.
Carlos, Sean. (2007) “Google Sitemap Standard Adopted by Three of the Leading International Search Engines.” Antezeta, 16 November 2006, updated 11 April 2007. http://www.antezeta.com/google/sitemap-standard.html Viewed 8 June 2007.
DeRidder, Jody (2007) “Metrics Displays for UT Digital Libraries.” University of Tennessee Libraries, Digital Library Center. http://diglib.lib.utk.edu/metrics/ Updated monthly. Viewed 16 July 2007.
Google. (2007a) “What are URLS not followed errors?” Google Webmaster Help Center. http://www.google.com/support/webmasters/bin/answer.py?answer=35156&topic=10080 Viewed 1 July 2007.
Google. (2007b) “How can I create a Google-friendly site?” Google Webmaster Help Center. http://www.google.com/support/webmasters/bin/answer.py?answer=40349&ctx=sibling Viewed 1 July 2007.
Google. (2007c) “Cloaking, sneaky Javascript redirects, and doorway pages.” Google Webmaster Help Center. http://www.google.com/support/webmasters/bin/answer.py?answer=66355 Viewed 1 July 2007.
Google. (2007d) “Using the Sitemap Generator.” Google Webmaster Help Center. https://www.google.com/webmasters/tools/docs/en/sitemap-generator.html Viewed 15 July 2007.
Google. (2007e) “Webmaster Tools.” https://www.google.com/webmasters/tools/docs/en/protocol.html Viewed 1 July 2007.
Google. (2007f) “How do I submit my OAI-PMH path?” Google Webmaster Help Center. http://64.233.167.104/search?q=cache:4jeq_Rim664J:
www.google.com/support/webmasters/bin/answer.py%3Fhl%3Dsl%26answer%3D34655+
Webmaster+Help+Center+-+How+do+I+submit+my+OAI-PMH+path%3F&hl=en&ct=clnk&cd=1&gl=us&client=firefox-a Viewed 14 January 2008.
Google. (2007g) “Does Google index sites with frames?” Google Webmaster Help Center. http://www.google.com/support/webmasters/bin/answer.py?hl=en&answer=34445 Viewed 6 June 2007.
He, Bin, Mitesh Patel, Zhen Zhang, and Kevin Chen-Chuan Chang. (2007) “Accessing the Deep Web.” Communications of the ACM, 50:5, May 2007, pp 95-101. (COinS)
Hodges, Pat. (2004) “U-M expands access to hidden electronic resources with OAIster.” University of Michigan News Service, 10 March 2004. http://www.umich.edu/news/index.html?Releases/2004/Mar04/r031004 Viewed 13 July 2007.
Huuhka, Petteri. (2006) “Google: data structures and algorithms.” http://www.cs.helsinki.fi/u/linden/teaching/irr06/papers/petteri_huuhka_google_paper.pdf Viewed 1 July 2007.
Liu, Xiaoming, Kurt Maly, Mohammed Zubair, and Michael L. Nelson. (2002) “DP9: An OAI Gateway Service for Web Crawlers.” Proceedings of the 2nd ACM/IEEE-CS joint conference on Digital libraries JCDL ’02, July 13-17, 2002, Portland Oregon. Copyright 2002 ACM. (COinS)
McCown, Frank, Michael L. Nelson, Mohammed Zubair, and Xiaoming Liu. (2006) “Search Engine Coverage of the OAI-PMH Corpus.” IEEE Internet Computing, March-April 2006, 1089-7801. (COinS)
Nelson, Michael L., Joan A. Smith, Ignacio Garcia del Campo, Herbert Van de Sompel, and Xiaoming Liu. (2006) “Efficient, Automatic Web Resource Harvesting.” In Proceedings of Web Information and Data Management 2006 (WIDM’06) , November 2006, Arlington VA. Copyright 2006 ACM. http://www.modoai.org/pubs/widm140-smith.pdf Viewed 12 July 2007.
Nelson, Michael L., Herbert Van de Sompel, Xiaoming Liu, Terry Harrison, and Nathan McFarland. (2005) “mod_oai: An Apache Module for Metadata Harvesting.” Proceedings of the 9th European Conference on Research and Advanced Technology for Digital Libraries (ECDL), LNCS 3652, Springer, pp. 509-510. http://public.lanl.gov/herbertv/papers/ecdl-mod_oai-submitted.pdf Viewed 7 July 2007.
Page, Lawrence; Brin, Sergey; Motwani, Rajeev; Winograd, Terry. (1999) “The PageRank Citation Ranking: Bringing Order to the Web.” Stanford InfoLab Publications. http://dbpubs.stanford.edu/pub/1999-66 Viewed 1 July 2007.
Pathak, Vivek. (2007) Sitemaps Autodiscovery. Posted to Ask.com by Ken Grobe, 11 April 2007. http://blog.ask.com/2007/04/sitemaps_autodi.html Viewed 16 July 2007.
Riskvik, Knut Magne, and Rolf Michelsen. (2002) “Search engines and Web dynamics.” Computer Networks 39 (2002) 289-302. (COinS)
Scherle, Ryan. “Web Spiders.” Indiana University Digital Library Infrastructure. Online document updated 3 May 2007. http://wiki.dlib.indiana.edu/confluence/display/INF/Web+Spiders Viewed 12 July 2007.
Sherman, Chris, and Gary Price. (2003) “The Invisible Web: Uncovering Sources Search Engines Can’t See.” Library Trends, 52:2, pp 282-98. (COinS)
Sitemaps.org. (2007) “Sitemaps XML format.” http://www.sitemaps.org/protocol.php Updated 11 April 2007. Viewed 8 June 2007.
Spink, Amanda, and Bernard J. Jansen. (2004) “A Study of Web Search Trends.” Webology 1:2, December 2004. http://www.webology.ir/2004/v1n2/a4.html Viewed 1 July 2007.
Sullivan, Danny. (2007) “How to use HTML Meta Tags.” Updated by Claudia Bruemmer. SearchEngineWatch.com, 5 March 2007. http://searchenginewatch.com/showPage.html?page=2167931, viewed 23 June 2007.
Sullivan, Danny. (2006) Nielsen NetRatings Search Engine Ratings. Search Engine Watch, Incisive Interactive Marketing, LLC. http://searchenginewatch.com/showPage.html?page=2156451 Viewed 27 June 2007.
Warnick, Walter L., Abe Lederman, R.L. Scott, Karen J. Spence, Lorrie A. Johnson, and Valerie S. Allen. (2001) “Searching the Deep Web: Directed Query Engine Applications at the Department of Energy.” D-Lib Magazine, 7:1, January 2001. http://www.dlib.org/dlib/january01/warnick/01warnick.html Viewed 12 July 2007.
Zhang, Jin, and Alexandra Dimitroff. (2005) “The impact of metadata implementation on webpage visibility in search engine results (Part II)”. (2005) Information Processing and Management 41 (2005) 691-715 (COinS)
Useful Link References
Ask. http://www.ask.com/ Accessed 12 July 2007.
Browse Structures for the University of Tennessee Special Collections Finding Aids. By Author: http://dlc.lib.utk.edu/f/fa/browse/author/a.html Accessed 27 July 2007. By Subject: http://dlc.lib.utk.edu/f/fa/browse/subject/a.html Accessed 27 July 2007. By Manuscript Number: http://dlc.lib.utk.edu/f/fa/browse/MS/150.html Accessed 27 July 2007.
DLXS (Digital Library eXtension Service). Product of the Digital Library Production Service, University of Michigan. http://dlxs.org/ Accessed 16 July 2007.
Encoded Archival Description (EAD). Version 2002 Official Site, Library of Congress Standards, updated 16 April 2007. http://www.loc.gov/ead/ Accessed 16 July 2007.
Google. http://www.google.com/webhp?hl=en Accessed 12 July 2007.
Jyxo.com. http://jyxo.com/ Accessed 5 August 2007.
“Metrics Displays for UT Digital Libraries.” http://diglib.lib.utk.edu/metrics/ Jody DeRidder, University of Tennessee Libraries, Digital Library Center. Updated monthly. Subpage links: “Finding Aids: Hits and Users.” (2003) http://diglib.lib.utk.edu/metrics/2003/collections/fa.html “Finding Aids: Hits and Users.” (2004) http://diglib.lib.utk.edu/metrics/2004/collections/fa.html “Finding Aids: Hits and Users.” (2005) http://diglib.lib.utk.edu/metrics/2005/collections/fa.html “Finding Aids: Hits and Users.” (2006) http://diglib.lib.utk.edu/metrics/2006/collections/fa.html “Finding Aids: Hits and Users.” (2007) http://diglib.lib.utk.edu/metrics/2007/collections/fa.html Accessed 16 July 2007.
OAIster. http://www.oaister.org/ Digital Library Production Service / Digital Library eXtension Service, University of Michigan. Accessed 13 July 2007.
Open Archives Initiative (OAI). http://www.openarchives.org/ Accessed 16 July 2007.
RFC3986: Uniform Resource Identifier (URI): Generic Syntax. T. Berners-Lee, R. Fielding, L. Masinter. (January 2005) http://www.ietf.org/rfc/rfc3986.txt Accessed 12 July 2007.
RFC3987: Internationalized Resource Identifiers (IRIs). M Duerst, M. Suignard. (January 2005) http://www.ietf.org/rfc/rfc3987.txt Accessed 12 July 2007.
Robotstxt.org. http://www.robotstxt.org/wc/norobots.html Accessed 16 July 2007.
Sitemaps.org. http://www.sitemaps.org/protocol.php Accessed 16 July 2007.
University of Tennessee Special Collections Online Finding Aids. http://dlc.lib.utk.edu/f/fa/ Accessed 12 July 2007.
Wget – Retrieves files from the Web. http://directory.fsf.org/wget.html Copyright 2005, Free Software Foundation. Accessed 16 July 2007.
XML standard: “Extensible Markup Langage (XML) 1.0 (Fourth Edition).” http://www.w3.org/TR/REC-xml/ Accessed 12 July 2007.
Yahoo! http://www.yahoo.com/ Accessed 12 July 2007.
About the Author
Jody L. DeRidder first became interested in digital libraries while developing repositories for the Open Archives Initiative in its alpha phases, as a graduate student. After completing her M.S. in Computer Science in 2002, she was hired as the lead developer for the Digital Library Center of the University of Tennessee Libraries. Now nearing completion of her M.S. in Information Sciences, her research interests have broadened to include interoperability between systems, usability, sustainability, and the potential capabilities of ontology applications.

Joseph Shubitowski, 2008-03-25
Jody – most interesting as are working through all the same issue here with our DLXS collections. We have version 13 up now and find that we can submit sitemaps to Google with URLs in the form of:
http://archives.getty.edu:8082/cgi/f/findaid/findaid-idx?c=utf8a;idno=US::CMalG::90.R.11
that go directly to the correct dynamic page in DLXS. We have tweaked the title tags so that we get the title we want Google to see and index, and after a week, we are seeing good results and relatively high rankings.
Previously, we were on version 11a and had generated static cached pages that we used for both indexing and retrieval (as DLXS speed was a problem). The switch to 13 allowed us to dump all that staic work. Tom Burton-West did all that work here at GRI before going to UMich last year to join the DLPS/DLXS team.
Great article! Thanks for sharing all the detail and the research.
Joe Shubitowski
Jody DeRidder, 2008-03-25
Hi Joe!
Very cool. I’m surprised you’re not having them index the full text, however. Why not? It will maximize the access to your information. Ours was using DLXS12. Is Google using your browse pages at all? Our static ones really made a difference in our hits, and I think the hidden metatags helped too, though I know it’s difficult to add those using the dynamic system.
I’d also thought about using rewrites of URLs to redirect the crawlers…
Laurie Phillips, 2008-12-15
You say:
“While directed query engines are an area of intense research…”
I am doing some research on the deep web and can’t find any recent references to the term “directed query engine”. Is this a common concept that is usually called by another name?
Thanks in advance.
Matthew Theobald, 2008-12-15
The deep, invisible and hidden web are the common terms. More recently the idea of the “structured” web has risen. ISEN.org has a solution for cataloging digital libraries coming from a library and information science perspective. You might investigate our project and feel free to ask questions.
The Code4Lib Journal – Googlizing a Digital Library » Web Design, 2012-03-14
[…] The Code4Lib Journal – Googlizing a Digital Library […]