by Luciano G. Ramalho
1. Introduction
The relational database model is well grounded in theory and well supported by the software industry. Relational database management systems (RDBMS) replaced legacy hierarchical and network database products in nearly every enterprise and became the mainstream. Object-oriented DBMS have not taken the leading role from relational systems, even after object-oriented programming became the norm, and in spite of the so-called “impedance mismatch” perceived when one needs to store nested objects into a collection of flat tables.
After resisting the object-oriented wave, relational databases became so dominant that they seemed like the only game in town, or at least the only game in most shops. But in the last five years, Google published a paper on BigTable (Chang, 2006), the proprietary, distributed non-relational database behind many of its online properties. Then Amazon.com revealed Dynamo, the non-relational database that powers some of their AWS cloud-based services (Decandia, 2007). Facebook open-sourced Cassandra, the distributed non-relational database created to enable its crucial in-box search feature. Cassandra is now also used by Twitter, Digg, Rackspace and Cisco, among many others, and has such a vibrant community that it became a top-level project of the Apache Foundation in 2010, less than three years after its initial public release (Apache, 2011a). These developments are part of a trend that became known, in 2009, as the “NoSQL” movement. NoSQL stands for “No SQL” or “Not Only SQL”, depending on who you ask; but everyone agrees it’s not really about the SQL language, but about seeking alternative answers to problems that are not amenable to relational solutions.
Meanwhile, thousands of small to medium libraries in developing countries have been oblivious to all this and continue using their ISIS databases for daily operations. ISIS is a family of non-relational database systems with a history that goes back to the 1970’s. It was developed by UNESCO – the United Nations Educational, Scientific and Cultural Organization – specifically for bibliographic data, and it is still officially distributed and widely used (Hopkinson, 2005).
ISIS had a very positive impact, allowing libraries with limited resources to computerize their catalogs on simple, stand-alone PCs. Some ISIS products became Web-enabled, but after that, progress has been very slow in the last 10 years. Meanwhile, a couple of new Open Source NoSQL databases present a possible migration path for ISIS users, a path that will not require wholesale normalization of decades of bibliographic data. This paper describes how BIREME/PAHO/WHO, a digital library that is part of the Pan American Health Organization, and a large-scale user of ISIS databases, has studied the viability of migrating one of its main databases to Apache CouchDB, a modern document database.
The rest of the paper is structured as follows. Section 2 discusses data models for bibliographic records, explains why it is tempting for librarians to look beyond the relational model and compares the structure of MARC records to the semistructured data model formalized in the 1990’s. Section 3 briefly presents ISIS, then compares two recent products that support semistructured records, CouchDB and MongoDB, and shows our criteria for choosing among them. Section 4 discusses different formats for representing ISIS records in CouchDB, then describes the tool we developed for converting records and the process used to load them into CouchDB. Section 5 talks about how indexing works in ISIS and CouchDB, and exemplifies queries on the latter. Finally, Section 6 summarizes what we have done, our conclusions and ongoing work.
2. Data models for bibliographic records
One of the defining characteristics of the relational data model, the First Normal Form (1NF), dictates that attributes must be atomic. In other words, in the industry-standard flat relational model1, fields cannot be structured into subfields nor contain multiple values.
On the other hand, multivalued fields are useful and common for representing bibliographic data. Books often have more than one author and cover multiple subjects. A publisher, while logically a single attribute of a book record, has attributes of its own, like a name and a place. It is therefore useful to split a publisher field into parts. That is why MARC supports subfields and multivalued fields through repeating tags (similar to XML). The MARC structure, or “empty container”2 carried over to the ISO-2709 standard, which describes a generic data interchange format allowing applications to attach any meaning to the tags and subfield markers. Here we will refer to the “ISO-2709 data model” as a generalization of the data model implied by the MARC record structure.
Of course, library data is often stored in relational databases, but normalization means that the description of a single item is spread over multiple records in several tables. That may work well within the context of one library, but when exchanging data, it is more practical to have just one record per item. That is one reason why MARC is still with us, and why XML became so important in a world dominated by relational databases.
If the ISO-2709 data model does not adhere to the flat relational model, then what is the theory behind it? At first there was none, but in the mid-1990s, while XML was still under development, researchers from UPenn, Stanford, AT&T Labs and the INRIA French R&D agency conceived the semistructured3 data model (Abiteboul, 1999). Their work supports reasoning about MARC and ISO-2709 records but also about the richer data models of XML and JSON4 documents.
A useful definition by Dan Suciu, a pioneer of semistructured data research, appears in the “Encyclopedia of Database Systems” (Suciu, 2009):
The semi-structured data model is designed as an evolution of the relational data model that allows the representation of data with a flexible structure. Some items may have missing attributes, others may have extra attributes, some items may have two or more occurrences of the same attribute. The type of an attribute is also flexible: it may be an atomic value or it may be another record or collection. Moreover, collections may be heterogeneous, i.e., they may contain items with different structures. The semi-structured data model is a self-describing data model, in which the data values and the schema components co-exist.
Thanks to the semistructured data model, we don’t need to feel ashamed of our denormalized bibliographic records any more. Even better, we have a framework to evaluate databases of the current NoSQL crop with regard to our needs as caretakers of denormalized datasets.
The book “Data on the Web: From Relations to Semistructured Data and XML” (Abiteboul, 1999), introduces a notation for representing semistructured data. It is called “ssd-expression” and it looks like this:
{name: {first: "Lewis", last: "Carroll"},
tel: 5553457,
email: "cld@ox.ac.uk",
email: "lcarroll@pobox.com"
}
Except for the repetition of the email key, it’s very similar to JSON (Crockford 2006a). The presence of keys describing fields like name, first etc., and the storage of those keys alongside the data, is what the encyclopedia entry means by coexisting data values and schema components (Suciu, 2009). It is a characteristic shared by ISO-2709, XML, and JSON (with the limitation that ISO-2709 fields are identified by tags composed of three alphanumeric ASCII characters, though most applications only use numeric tags). The repeated email tag could be represented similarly in XML and in ISO-2709, but in JSON the keys must be unique within an object structure, so multivalued fields are often represented as lists of values:
{"name": {"first": "Lewis", "last": "Carroll"},
"tel": 5553457,
"email": ["cld@ox.ac.uk", "lcarroll@pobox.com"]
}
The ISO-2709 record format influenced the record structure of the ISIS family of databases, introduced by UNESCO in the 1970s. ISIS records follow the structure of the ISO-2709 standard, and most ISIS systems import and export to that format. Here is the same record of the examples above, as seen in a common ISIS display format:
10 «^fLewis ^lCarroll» 20 «5553457» 30 «cld@ox.ac.uk» 30 «lcarroll@pobox.com»
In an ISIS record the field names are replaced by numeric tags. The «» delimiters are not part of the content, but a feature of the display format. Here there are two occurrences of tag #30, the e-mail field. Field #10 is split into two subfields (“f” and “l”) by special markers. Instead of the subfield delimiter control character used in MARC systems, ISIS uses the circumflex accent: ^ (ASCII 94). A subfield identifier is case-insensitive and consists of just one ASCII letter or digit. The ISIS data model is simpler than that of ISO-2709 because it does not have field indicators5 and subfields are not repeatable6.
Clearly the ISIS data model is not as flexible as the general semistructured data model. Given the syntax of subfield markers, ISIS fields are limited to one level of nesting only. In other words, borrowing from the XML jargon: subfields cannot have child elements, just character data. Also, an ISIS field may have mixed content7: some unmarked text may appear before the first subfield marker. For example, in this field:
18 «Lords of Finance^bThe Bankers Who Broke the World»
The main title, “Lords of Finance” is not preceded by a subfield marker. The semistructured data model, as described by Abiteboul et. al., has no concept of mixed content like XML has. So we will call that part “the main subfield” and pretend it is preceded by an implied “^_” (underscore) subfield marker whenever we need to refer to it in code. With this simple arrangement, any ISIS record can be represented as an ssd-expression or a JSON record.
3. Semistructured database systems
3.1. The ISIS family
In 1985, Giampaolo Del Bigio ported UNESCO’s CDS/ISIS mainframe database system to PC/DOS (Lopes, 2010). The result, called MicroISIS, was distributed free of charge and became the de facto standard for computerized library catalogs in developing countries. Its Windows version, WinISIS is still distributed by UNESCO and remains widely used in small to medium libraries (Hopkinson, 2005). Beyond local OPACs, ISIS is also used by two large regional bibliographic databases in Latin America and the Caribbean: SciELO (Scientific Electronic Library Online) and LILACS (Latin American and Caribbean Health Sciences index), both built by BIREME/PAHO/WHO, which is a specialized center of the Pan American Health Organization located in São Paulo, Brazil. Together, SciELO and LILACS routinely handle millions of bibliographic records using CISIS, a custom version of ISIS developed by BIREME/PAHO/WHO. MicroISIS, WinISIS, CISIS and the more recent J-ISIS from UNESCO are all interoperable and form the ISIS family of database systems.
The legacy ISIS codebases are showing their age, and after years of closed-source development, none of the derivations have managed to become successful Open Source projects. Meanwhile, the NoSQL movement has highlighted some Open Source non-relational databases implementing variations of the semistructured data model. This has motivated BIREME/PAHO/WHO to look for alternatives.
3.2 CouchDB and MongoDB
Among the recent crop of NoSQL systems, two products stand out for implementing the semistructured data model in a way that matches the operational needs of BIREME/PAHO/WHO: Apache CouchDB and MongoDB (Apache, 2011b, MongoDB.org, 2011). Their data model is not as flat as the key-value stores (optimized for retrieving blobs given a primary key), nor as deep as graph databases (designed to allow general queries over paths of nested objects). What they offer is somewhere in between: JSON-like records allowing nested structures, and expressive query languages to index and retrieve those records. Those rich records are called “documents”. CouchDB and MongoDB call themselves “document databases”.
In the case of CouchDB, the document format is JSON. MongoDB uses BSON, a binary format inspired by JSON but offering more data types, such as int32, datetime, and even a type called “JavaScript code w/ scope” (Dirolf, 2010). JSON can be trivially converted to BSON, but the reverse may not be so easy, depending on the data. While the difference between those formats can be considered an implementation detail, they reflect different priorities.
MongoDB is optimized for fast updating, by aggressively caching writes and by overwriting updated records in place whenever possible: the BSON structure is designed to allow updating specific fields of an existing document. The flip-side of this optimization is that a software crash can cause data loss, and a minimum deployment of two servers in master-slave configuration is recommended if durability is required8. In contrast, CouchDB is fault-tolerant: it only appends to the database file on disk, and that is an atomic operation in modern operating systems. As a result, the database file is always consistent in the event of a software crash, and backups can be made while the system is running. The drawbacks of the append-only design are the need for periodic database compaction – a time-consuming batch operation – and slower updates.
CouchDB was influenced by Lotus Notes, a networked, collaborative application suite designed to support users who are often off-line. So, CouchDB allows master-master replication, that is, synchronization between peer nodes which have received inserts and updates independently. MongoDB supports only master-slave replication: only one node receives updates and inserts, and replicates to the slaves.
While CouchDB can be used in large clusters, it is also well-suited as a database for small desktop apps. For that reason it comes pre-installed on Ubuntu Linux since 2009. It even runs on Android mobile devices (a free, one-click installer can be found in the Android Marketplace). Because CouchDB supports HTTP and JSON natively, and can run JavaScript procedures on the server, applications can be developed without any middleware: browsers communicate directly with the database, and all the logic is written in JavaScript.
The informative post “Comparing Mongo DB and Couch DB” was written by Dwight Merriman, CEO of 10gen, the company behind MongoDB (Merriman, 2010). Given the characteristics of these systems, we decided to use CouchDB for our LILACS experiments for these reasons:
- Easier deployment in a durable configuration.
- Support for master-master replication, useful for distributed cooperative cataloging applications.
- Direct support for JSON over HTTP, enabling Web Services and AJAX applications without middleware.
However, we do envision scenarios in which we would like to use both MongoDB and CouchDB. For example, the canonical store of bibliographic data could be CouchDB, while a cluster of MongoDB instances could be used for user-provided content, tracking, recommendations and other features demanding faster database writes.
4. Loading ISIS records into CouchDB
4.1. Alternative representations of ISIS records as JSON documents
The ISIS data model, a subset of the ISO-2709 model, is not as expressive as the JSON data model. There are several ways to represent the same ISIS record in JSON. Consider this abridged example of a LILACS record:
1 «BR1.1»
2 «538886»
4 «LILACS»
4 «LLXPEDT»
5 «S»
6 «as»
8 «Internet^ihttp://…/imageBank/PDF/v3n3a04.pdf?aid2=168&…»
10 «Kanda, Paulo Afonso de Medeiros^1University of São Paulo
^2School of Medicine^3Cognitive Disorders of Clinicas
Hospital Reference Center^pBrasil ^cSão Paulo^rorg»
10 «Anghinah, Renato^1University of São Paulo^2School of
Medicine ^3Cognitive Disorders of Clinicas Hospital
Reference Center ^pBrasil^cSão Paulo^rorg»
12 «The Clinical use of quantitative EEG in cognitive disorders
^ien»
12 «A utilização clínica do EEG quantitativo nos transtornos
cognitivos^ipt»
30 «Dement. neuropsychol»
31 «3»
32 «3»
35 «1980-5764»
Tag #2 is the LILACS identifier, a non-repeating, numeric field, and tag #10 is an author field in an analytic (article-level), record. The LILACS data dictionary (BIREME, 2008) defines #10 as a repeating field. In addition, it is composed of the following subfields:
| subfield | description | sample content |
|---|---|---|
| main | author name | Kanda, Paulo Afonso de Medeiros |
| ^1 | affiliation level 1 | University of São Paulo |
| ^2 | affiliation level 2 | School of Medicine |
| ^3 | affiliation level 3 | Cognitive Disorders of Clinicas Hospital Reference Center |
| ^p | country | Brasil |
| ^c | city | São Paulo |
| ^r | degree of responsibility | org (organizer) |
One way to represent such a record in JSON is shown below (only fields #10 and #2 are shown; some contents shortened for clarity):
{
"10": [
{
"_": "Kanda, Paulo Afonso",
"1": "University of São Paulo",
"2": "School of Medicine",
"3": "Cognitive Disorders of … Reference Center",
"c": "São Paulo",
"p": "Brasil",
"r": "org"
},
{
"_": "Smidth, Magali Taino",
"1": "University of São Paulo",
"2": "School of Medicine",
"3": "Cognitive Disorders of … Reference Center",
"c": "São Paulo",
"p": "Brasil",
"r": "org"
}
],
"2": [
{
"_": "538886"
}
]
}
In the representation above, the record is a JSON mapping between tags (eg. “10”) and lists of values (or occurrences in ISIS jargon). The use of lists allows any field to be repeatable, therefore any possible ISIS record fits this scheme. Also, within the list of occurrences, each one is represented by a mapping of subfield keys and values. The special key “_” (underscore) is used to denote the main subfield, and when there are no subfields that is the only key. This creates unnecessary nesting, as demonstrated by field #2 which is the LILACS identifier field, non-repeating and devoid of subfields as defined by the LILACS data dictionary. But it does make the structure homogeneous, an important feature when dealing with legacy semistructured datasets where not all records adhere to the current schema. During our research we called the representation above ISIS-JSON type 3 (BIREME, 2010).
The main drawback of ISIS-JSON type 3 is that, by definition, JSON mappings are unordered9. Therefore, neither the tag order within the record nor the subfield order within a field occurrence are preserved. In the LILACS database, tag order within a record is only relevant when there are repeating tags, such as #10 (author, analytical level). Fortunately, keeping repeated occurrences in a list does preserve their relative ordering, even if the overall field order is not kept. For example, in the original ISIS record under analysis field #2 appeared before all occurrences of field #10, while in the JSON representation the key “10” precedes key “2”. This is irrelevant in practice. But, crucially, the order of the authors is the same in both formats: first “Kanda, Paulo Afonso”, then “Smidth, Magali Taino”.
Regarding subfield ordering within a field, the LILACS data dictionary does establish a canonical ordering. For example, in the case of field #10 the order is _, 1, 2, 3, p, c, r (the main subfield is always first, by definition). However, as Jason Thomale points out in “Interpreting MARC: Where’s the Bibliographic Data?” (Thomale, 2010), subfield markers should be interpreted as textual markup, and their ordering is significant. Particularly when cleaning up or converting legacy data, maintaining the order of subfields from the original record may be important to ascertain the original cataloger’s intention, even if LILACS subfields do have a prescribed ordering.
To preserve subfield ordering, two alternative JSON representations have been tried at BIREME/PAHO/WHO. The first is ISIS-JSON type 1 (line breaks added within long strings for clarity):
{
"10": [
"Kanda, Paulo Afonso de Medeiros^1University of São Paulo
^2School of Medicine^3Cognitive Disorders of Clinicas
Hospital Reference Center^pBrasil ^cSão Paulo^rorg",
"Smidth, Magali Taino^1University of São Paulo ^2School
of Medicine^3Cognitive Disorders of Clinicas Hospital
Reference Center^pBrasil ^cSão Paulo^rorg"
],
"2": ["538886"]
}
In this format, each field occurrence is a single string, with the subfield delimiters embedded. This essentially “punts” on the issue of how to represent subfields, leaving the parsing to be done by the database. Because CouchDB uses JavaScript as its default language for creating indexes, it is a viable approach. Another possibility is ISIS-JSON type 2:
{
"10": [
[
["_", "Kanda, Paulo Afonso"],
["1", "University of São Paulo"],
["2", "School of Medicine"],
["3", "Cognitive Disorders of … Reference Center"],
["p", "Brasil"],
["c", "São Paulo"],
["r", "org"]
],
[
["_", "Smidth, Magali Taino"],
["1", "University of São Paulo"],
["2", "School of Medicine"],
["3", "Cognitive Disorders of … Reference Center"],
["p", "Brasil"],
["c", "São Paulo"],
["r", "org"]
]
],
"2": [
[
["_", "538886"]
]
]
}
Here each field occurrence is an association list10, that is, a mapping represented as a list of lists, where each inner list contains a key-value pair. The advantage of an associative list over a JSON object mapping is that the order of items is preserved, but at the cost of a linear search to locate a key within a field occurrence. Because of how indexing works in CouchDB, this is not as costly as it may seem, as will be seen in the next section. For MARC-style records, the association list has the added advantage of allowing repeated mappings to represent repeating subfields.
4.2. The isis2json conversion tool
To convert ISIS records into JSON structures, we developed a Python script called isis2json.py (BIREME, 2010b). It can be executed with both the Python and Jython interpreters, versions 2.5 through 2.7. When running under Python it can read only ISO-2709 files, but as a Jython script it leverages the Bruma Java library (Barbieri, 2011) and can also read binary ISIS files in .MST format directly. Several options control the structure of the JSON output. For example, the command line below generates output suitable for batch importing to CouchDB:
$ ./isis2json.py cds.iso -c -t 3 -q 100 > cds1.json
The arguments used in the above example are:
-c to generate records within a “docs” list, as required by the CouchDB _bulk_docs API;
-t 3 for ISIS-JSON type 3 export (fields as dictionaries of subfields);
-q 100 to output only 100 records;
Here is the help screen of isis2json.py:
$ ./isis2json.py -h
usage: isis2json.py [-h] [-o OUTPUT.json] [-c] [-m] [-t ISIS_JSON_TYPE]
[-q QTY] [-s SKIP] [-i TAG_NUMBER] [-u] [-p PREFIX] [-n]
[-k TAG:VALUE]
INPUT.(mst|iso)
Convert an ISIS .mst or .iso file to a JSON array
positional arguments:
INPUT.(mst|iso) .mst or .iso file to read
optional arguments:
-h, --help show this help message and exit
-o OUTPUT.json, --out OUTPUT.json
the file where the JSON output should be written
(default: write to stdout)
-c, --couch output array within a "docs" item in a JSON document
for bulk insert to CouchDB via POST to db/_bulk_docs
-m, --mongo output individual records as separate JSON
dictionaries, one per line for bulk insert to MongoDB
via mongoimport utility
-t ISIS_JSON_TYPE, --type ISIS_JSON_TYPE
ISIS-JSON type, sets field structure: 1=string,
2=alist, 3=dict
-q QTY, --qty QTY maximum quantity of records to read (default=ALL)
-s SKIP, --skip SKIP records to skip from start of .mst (default=0)
-i TAG_NUMBER, --id TAG_NUMBER
generate an "_id" from the given unique TAG field
number for each record
-u, --uuid generate an "_id" with a random UUID for each record
-p PREFIX, --prefix PREFIX
concatenate prefix to every numeric field tag (ex. 99
becomes "v99")
-n, --mfn generate an "_id" from the MFN of each record
(available only for .mst input)
-k TAG:VALUE, --constant TAG:VALUE
Include a constant tag:value in every record (ex. -k
type:AS)
4.3. Interacting with CouchDB
HTTP is the main protocol for interacting with CouchDB11. Most database administration is done via Futon, its built-in web interface.
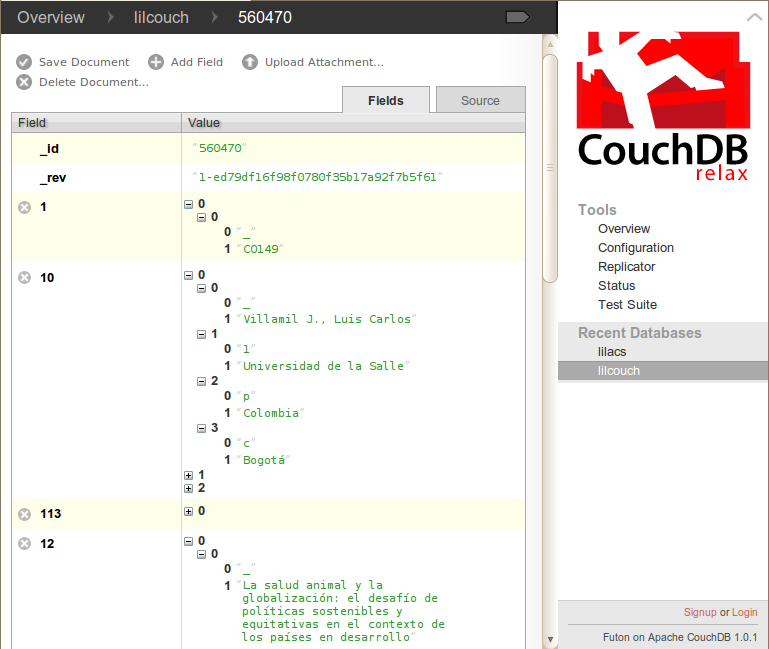
Figure 1. CouchDB Futon web interface showing a LILACS record in ISIS-JSON Type-2 format.
Nearly every task which can be done via Futon can also be automated using the RESTful API of CouchDB via any HTTP client. In fact, interacting with CouchDB is a great way to learn, in practice, what REST and RESTful interfaces are all about. Here we use cURL, a command-line HTTP client available for many systems. For example, a database is created with a simple PUT request:
$ curl -X PUT http://admin_user:password@127.0.0.1:5984/lilacs
One operation that cannot be done via Futon is uploading records in bulk. Continuing the previous example, we could convert an ISO-2709 file to JSON, then upload it to CouchDB using cURL in two steps:
$ ./isis2json.py cds.iso -c > cds1.json
$ curl -d cds1.json -H"Content-Type: application/json" \
-X POST http://127.0.0.1:5984/lilacs/_bulk_docs
When used together, the -q and the -s (skip) options allow splitting the output into several batches, which results in faster loading for large datasets on multi-core servers. For example, loading 20,000 full LILACS records, totaling 64MB, took 147 seconds using this shell command:
$ isis2json.py -c -p v -i 2 -q 20000 lilacs100k.iso | \
curl -d @- -H"Content-Type: application/json" \
-X POST http://127.0.0.1:5984/lilacs/_bulk_docs
Loading the same data in two 10,000-record batches took 100 seconds when taking advantage of two cores with a simple shell script like this one:
#!/bin/bash
isis2json.py -c -p v -i 2 -q 10000 lilacs100k.iso | \
curl -d @- -H"Content-Type: application/json" \
-X POST http://127.0.0.1:5984/lilacs/_bulk_docs &
isis2json.py -c -p v -i 2 -q 10000 -s 10000 lilacs100k.iso | \
curl -d @- -H"Content-Type: application/json" \
-X POST http://127.0.0.1:5984/lilacs/_bulk_docs
If an _id attribute is not present in an inserted document, CouchDB provides one with a UUID (Universally Unique Identifier) like "ead3af23a4459b2d7a1aef05cb0012a9". It is highly recommended that an _id is given when adding documents to prevent inadvertent duplication of records if a bulk loading process is interrupted and restarted. Therefore isis2json.py provides the -i option, used in the examples above, to fetch the value of one field in the ISIS input and use it as the _id attribute.
So, for example, using the -i 2 option this (partial) ISIS structure:
1 «BR1.1» 2 «538886» 4 «LILACS» 4 «LLXPEDT»
Can be converted into this JSON document record, ready to import into CouchDB:
{
"_id": "538886",
"1": [
[
["_", "BR1.1"]
]
],
"2": [
[
["_", "538886"]
]
],
"4": [
[
["_", "LILACS"]
],
[
["_", "LLXPEDT"]
]
]
}
Note how the content of the first occurrence of the #2 tag was used as _id.
5. Indexing and querying
5.1. Building indexes
For efficient retrieval, records must be indexed. It is useful to distinguish between a primary index and secondary indexes. A primary index allows retrieval via the primary key. Every NoSQL database uses a primary index to allow queries on the primary key. In fact, “key-value” databases often provide only this means of retrieval. Document databases also support secondary indexes, allowing fast access via arbitrary attributes of the records. In order to index those attributes, some form of data extraction must be performed on the records. By default, JavaScript is the language used for data extraction in CouchDB12. In ISIS databases, a simple but terse “ISIS Formatting Language” is used to generate secondary indexes, also called inverted files.
Index definition in ISIS is done in a special file called the “Field Select Table” (FST). Here are just a few lines from the large FST used to generate indexes for the LILACS database:
98 0 v1,"-"v2 10 8 ,mpl,'|AU_|'(v10^*|%|/), 38 0 if s(mpu,v38^a,mpl):'CD' then 'SP_CD-ROM' fi,
Without going into all the details, here is what those lines do (the numbering is not relevant to this discussion13):
- line 98 indexes the contents of tags #1 (cooperating center code) and #2 (record id) concatenated with an hyphen;
- line 10 indexes each word of the main subfield of field #10 (author), concatenated with an
'AU_'prefix; - line 38 indexes the string ‘SP_CD-ROM’ if field 38, subfield ^a contains the string ‘CD’;
To generate an inverted file, an ISIS system applies each line of the FST to each record in the database, generating one or more index entries (or postings) per record. Documents can also be indexed incrementally, but BIREME/PAHO/WHO does a lot of batch processing and usually does “full inversion”, that is, regenerating inverted files from scratch.
The overall process is very similar in CouchDB. Instead of an FST, CouchDB allows us to define “views”, which are the result of running JavaScript functions to generate indexes. The simplest view contains only one function, the map function, which receives a document as an argument, extracts some data from it, and calls a special emit function to add entries to the index.
The emit function takes two arguments: key and value. The key argument is the one actually indexed; queries will be made on it. It is usually unstructured, like a string, but sometimes it is useful to have an array as a key, for instance [country, province], to allow multi-level grouping of results. The value may be any JSON structure, and it is used to display the results of a query. For example, in an OPAC application we may have an index where each entry has an ISBN as a key, and the book title and year of publication as the value.
If you know some SQL, you may find it easier to think in terms of a simple SELECT statement:
SELECT title, year FROM books WHERE isbn='9781594201820'
Here we have a books table with title, year and isbn fields. To support a query like the one above we would need an index on isbn. The title and year fields have no influence on the search, but they are mentioned in the query because we want to display them in the search result.
In CouchDB terms, to support a similar query we would need a view with a map function emitting the ISBN as key, and the value would be a structure like {"title":"Lords of Finance", "year":2009}. The map function for that view would look like this:
function(doc) {
if (doc.type == "book") {
emit(doc.isbn, {title: doc.title, year: doc.year});
}
}
Because CouchDB has no concept of tables like SQL databases have, it is common to have different types of records mixed in the same database. Therefore, map functions often have an if statement to select which records to index. In the example above, we index only documents of type "book". For each book, the key will be the ISBN and the value will be an object with the title and year attributes.
In addition to a map function, CouchDB views may have a reduce function, which is used to aggregate results. Views with reduce functions will be discussed later.
Indexing ISIS-JSON type 2 records: first approach
Being able to use a powerful language like JavaScript to create map functions gives a lot of flexibility when creating views. We can dig as deep as necessary into the structure of our documents, and massage the data we find in sophisticated ways. For one report, we created an index of all the LILACS records containing fields with repeating subfield markers. That would not be viable in an ISIS FST. However, one important limitation of map functions is that we have no access to data that is not part of the document being indexed. It is impossible, for example, to look up some value in another record, like a join operation in an RDBMS (ISIS also allows this, via the l/lookup function of the ISIS Formatting Language).
To start with a simple example, let us create a view to index LILACS records by tag #1 (cooperating center code), the id of the cataloging institution which created the record. From the LILACS data dictionary we know that tag #1 is non-repeating and has no subfields, which means all the content of that field resides in the main subfield (the first one) and only the first occurrence matters (because there are no repetitions). Here is a view function that would create an index with field #1 as key and field #12 (title, analytic) as value:
function(doc) {
emit(doc["1"][0][0][1], doc["12"][0][0][1]);
}
Here we begin to see the price we pay for the generality of the ISIS-JSON type 2 structure. The LILACS field #1 is non-repeating and has no subfields, so it could be represented like this:
{
"1" : "UY6.1",
...
}
And then we could reach it within a map function with the simple expression doc["1"]. Even better, we could add an alpha prefix to the field name (the --prefix option of isis2json.py does that). Then we could use dot notation (doc.v1) to access tag v1 in the following:
{
"v1" : "UY6.1",
...
}
However, to deal with ISIS records of any kind in the absence of schema information, we must assume that every field may have more than one occurrence, therefore its value cannot be just a string, but an array of occurrences. In addition, we must assume that every field may have subfields, therefore each occurrence must be structured as an associative list (ISIS-JSON type 2) or a dictionary (ISIS-JSON type 3), unless we want to parse the subfields every time when indexing. In an ISIS-JSON type 2 record, field #1 is represented as:
{
"1": [
[
[
"_",
"UY6.1"
]
]
],
...
}
And to access its value we must write doc["1"][0][0][1]. Here is why:
doc -> {"1": [[["_", "UY6.1"]]]} # entire document
doc["1"] -> [[["_", "UY6.1"]]] # list of occurrences of field #1
doc["1"][0] -> [["_", "UY6.1"]] # list of subfields of occurrence 0 of #1
doc["1"][0][0] -> ["_", "UY6.1"] # subfield 0 of occurrence 0 of #1 (key "_")
doc["1"][0][0][1] -> "UY6.1" # value of subfield 0 of occurrence 0 of #1
This quickly becomes tedious, and very burdensome in more complex cases, for instance, to retrieve a specific subfield aside from the main one we would need to iterate over the subfield keys. We will soon show a library to make it easier to handle ISIS-JSON type 2 records, but first let’s return to our simple map function:
function(doc) {
emit(doc["1"][0][0][1], doc["12"][0][0][1]);
}
This function is part of a view in a “design document” in CouchDB. A design document is written in JSON, stored in CouchDB as other documents are, but its identifier starts with _design/. It may contain JavaScript functions for creating views as well as formatting output, validating document inserts/updates, etc. Each CouchDB database may have several design documents, and each design document may have several views.
When trying out CouchDB initially, the easiest way to create a view is by using the “Temporary view…” option of the view dropdown in the top right area of the Futon interface. Then you can run the map/reduce functions and quickly see their results (if your dataset is not too large). To save your work to a permanent view, you will be prompted to provide a design document name and a view name.
For any serious work, the CouchApp tool is highly recommended (Anderson, 2009). With it you can develop your design documents in your local filesystem, using your favorite editor and version control system, then push your code to a local or remote CouchDB instance with a command. All of the views for this article were developed in this manner. The code is in Bitbucket (Ramalho, 2011).
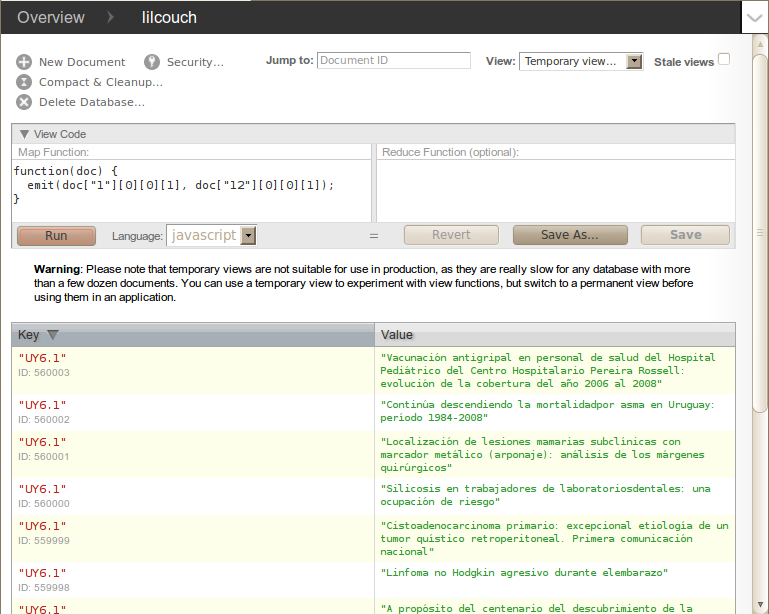
Figure 2. Editing and running a temporary view in CouchDB Futon.
When a view is first visited via HTTP, CouchDB indexes all of the documents by applying the map function to each of them. CouchDB also incrementally updates the indexes if documents are inserted or updated. The indexing is only done on demand, when a view is actually requested, and not when documents are created or changed.
To install the map function above, we created a design document called lilacs and within it a view called center (for “cooperating center”). Here is part of the result of requesting that view with the cURL utility:
$ curl -s http://ramalho.couchone.com/lilcouch/_design/lilacs/_view/center | head -5
{"total_rows":926,"offset":0,"rows":[
{"id":"559682","key":"AR1.1","value":"Hemorragia digestiva baja: [revisi\u00f3n]"},
{"id":"559683","key":"AR1.1","value":"La radiolog\u00eda del colon por enema en el siglo XXI"},
{"id":"559684","key":"AR1.1","value":"El s\u00edndrome an\u00e9mico en las neoplasias del colon derecho"},
{"id":"559685","key":"AR1.1","value":"Met\u00e1stasis cerebrales del carcinoma epidermoide del ano: comunicaci\u00f3n de un caso"},
Note that the result comes as a JSON object with three properties: total_rows, offset and rows, the latter being an array of map function results. Besides the key and value generated by the emit function, each result row also has an id attribute, which carries the _id property of the corresponding indexed document. By default, the result is sorted in ascending key order. Here we used the head shell command to crop the displayed results; we will soon see a way of limiting the results actually sent by CouchDB.
By the way, the URL shown here is public and you should be able to access it to try the examples by editing the URL:
http://ramalho.couchone.com/lilcouch/_design/lilacs/_view/center
However, please note that the lilcouch database there contains only a sample of 1000 records, not the full LILACS database.
5.2. Querying a view
As we have just seen, CouchDB queries are executed by making HTTP requests on views. If no arguments are passed, all rows of the result are returned. However, there are several arguments that can be used to filter the results. For example, the following query uses the descending and limit arguments. Note the use of single quotes around the URL, necessary because “&” is a shell operator and we are using the command line. In this case the head shell command was not used. The total_rows property still counts 926, but only the last three rows are returned because of the limit=3 option.
$ curl -s 'http://ramalho.couchone.com/lilcouch/_design/lilacs/_view/center?descending=true&limit=3'
{"total_rows":926,"offset":0,"rows":[
{"id":"560003","key":"UY6.1","value":"Vacunaci\u00f3n antigripal en personal de salud del Hospital Pedi\u00e1trico del Centro Hospitalario Pereira Rossell: evoluci\u00f3n de la cobertura del a\u00f1o 2006 al 2008"},
{"id":"560002","key":"UY6.1","value":"Contin\u00faa descendiendo la mortalidadpor asma en Uruguay: per\u00edodo 1984-2008"},
{"id":"560001","key":"UY6.1","value":"Localizaci\u00f3n de lesiones mamarias subcl\u00ednicas con marcador met\u00e1lico (arponaje): an\u00e1lisis de los m\u00e1rgenes quir\u00fargicos"}
]}
Another possibility is to filter by key. The next query returns only the documents created by the cooperating center with code “CO113”:
$ curl -s 'http://ramalho.couchone.com/lilcouch/_design/lilacs/_view/center?key="CO113"'
{"total_rows":926,"offset":744,"rows":[
{"id":"559986","key":"CO113","value":"De serendipia al tratamiento quir\u00fargico de la diabetes mellitus tipo II"},
{"id":"559987","key":"CO113","value":"La Academia Nacional de Medicina se pronuncia sobre la emergencia social, la medicina y la salud"},
{"id":"559988","key":"CO113","value":"Presentaci\u00f3n inicial de las pacientes con diagn\u00f3stico de c\u00e1ncer de seno en el Centro Javeriano de Oncolog\u00eda, Hospital Universitario San Ignacio"},
{"id":"559989","key":"CO113","value":"\u00bfEs la diabetes mellitus tipo 2 una enfermedad de tratamiento quir\u00fargico?"},
{"id":"559990","key":"CO113","value":"P\u00f3lipos de la ves\u00edcula"},
{"id":"559991","key":"CO113","value":"Ruptura espl\u00e9nica espont\u00e1nea asociada a linfoma perif\u00e9rico de c\u00e9lulas T, presentaci\u00f3n de un caso y revisi\u00f3n de la literatura"},
{"id":"559992","key":"CO113","value":"Diverticulosis del yeyuno: complicaciones y manejo; reporte de caso y revisi\u00f3n de la literatura"},
{"id":"559993","key":"CO113","value":"Actinomicosis abdominal y p\u00e9lvica: reto diagn\u00f3stico y quir\u00fargico para el cirujano general"}
]}
It is also possible to limit by starting and ending keys. For example, this query returns the documents created by centers starting with the “CO” prefix (for Colombia), up to and including the “CO149” center. Note that the offset property tells us that 744 rows were skipped to get to the first one with key="CO":
$ curl -s 'http://ramalho.couchone.com/lilcouch/_design/lilacs/_view/center?startkey="CO"&endkey="CO149"'
{"total_rows":926,"offset":744,"rows":[
{"id":"559986","key":"CO113","value":"De serendipia al tratamiento quir\u00fargico de la diabetes mellitus tipo II"},
{"id":"559987","key":"CO113","value":"La Academia Nacional de Medicina se pronuncia sobre la emergencia social, la medicina y la salud"},
[... several rows omitted ...]
{"id":"560469","key":"CO149","value":"Diagn\u00f3stico sanitario de diversos zoocriaderos helic\u00edcolas en Colombia: determinaci\u00f3n de los principales agentes pat\u00f3genos que afectan el caracol Helix aspersa (O.F. Muller, 1774) en cada etapa de ciclo biol\u00f3gico"},
{"id":"560470","key":"CO149","value":"La salud animal y la globalizaci\u00f3n: el desaf\u00edo de pol\u00edticas sostenibles y equitativas en el contexto de los pa\u00edses en desarrollo"}
]}
5.3. Indexing ISIS-JSON type 2 records: using an API
Now we will develop a view called au_countries to list the countries of origin of the authors cited in the sample. This entails fetching the value of the “^p” subfield of field #10. A first stab at the map function came out like this:
function(doc) {
var occur, subf;
if (doc.hasOwnProperty('10')) {
for (occur=0; occur<doc['10'].length; occur++) {
for (subf=0; subf<doc['10'][occur].length; subf++) {
if (doc['10'][occur][subf][0] === 'p') {
emit(doc['10'][occur][subf][1], 1);
break;
}
}
}
} else {
emit(null, 1);
}
}
Yes, that is quite ugly. Much of the ugliness comes from the fact that ISIS-JSON type 2 arranges subfields in a associative list, where a key can only be found through a linear search.
So here is the next solution, much simpler thanks to the use of a custom library:
function(doc) {
// !code vendor/isisdm_t2/_attachments/isisdm.js
var i, occurs = ISIS.getallsub(doc, 10, "p");
for (i=0; i<occurs.length; i++) {
if (occurs[i] !== undefined) {
emit(occurs[i], 1);
}
}
}
The first line of the function is a special !code comment that works as an include, and is processed by the CouchApp utility. This is actually a workaround because at this time CouchDB does not support the use of the CommonJS require function to import modules in map or reduce functions (require is supported elsewhere in CouchDB, in show and list functions for example). The isisdm.js module used here is part of the ISIS Data Model APIs we are developing at BIREME/PAHO/WHO to handle ISIS records in JavaScript and Python. Currently isisdm.js defines four main functions:
get(record, tag, missing)- returns first occurrence of
taginrecord; iftagis not found, returns the value of the last argument orundefinedif that is not given; getall(record, tag)- returns an array with all occurrences of
taginrecordor an empty array iftagis not found; getsub(record, tag, key, missing)- returns subfield identified by
keyin the first occurrence oftaginrecord; iftagorkeyare not found, returns the value of the last argument orundefinedif that is not given; getallsub(record, tag, key, missing)- returns an array with contents of subfield identified by
keyin all occurrences oftaginrecord;
We are using QUnit (JQuery, 2011) to perform unit tests on the isisdm.js module. Here is the the test page:
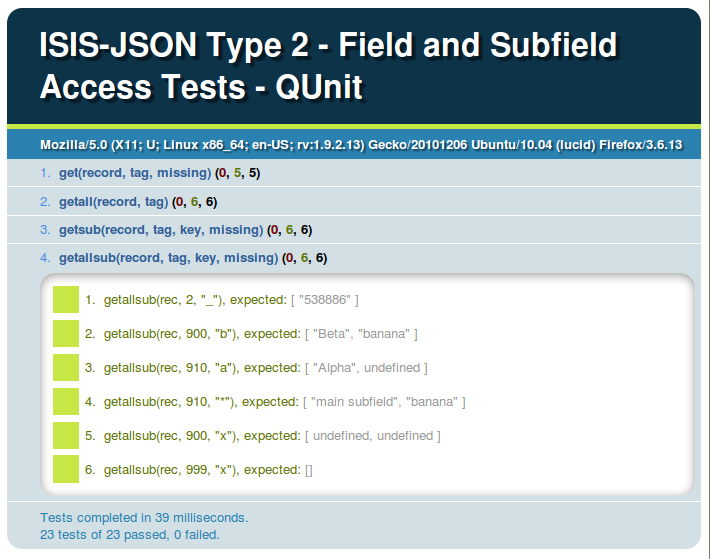
Figure 3. QUnit test results page, showing that all tests are passing. The tests for the getallsub function are expanded. This page is live at http://ramalho.couchone.com/lilcouch/_design/lilacs/tests.html
Now, back to the map function, note that the call to emit uses the subfield occurrence as key and the value is just a number 1: emit(occurs[i], 1);. This is because the intent of this view is to produce an aggregate count of each different key. To achieve this, we need a reduce function to sum the values emitted, like this:
function(keys, values, rereduce) {
return sum(values);
}
Now that our au_countries view has both a map and reduce function, we can query it:
$ curl -s 'http://ramalho.couchone.com/lilcouch/_design/lilacs/_view/au_countries'
{"rows":[
{"key":null,"value":2368}
]}
The simplest, no-argument request returns null as the key and 2368 as the value. This is the result of the reduce function: 2368 is the sum of all the 1’s emitted by the map function. In other words, there are 2368 occurrences of the #10 tag with a ^p subfield.
The reduce function can be disabled if the reduce=false option is given in the request. Below are the first 5 and the last 5 lines of querying the au_countries view without applying the reduce. What you see is just the result of the map function:
$ curl -s 'http://ramalho.couchone.com/lilcouch/_design/lilacs/_view/au_countries?reduce=false' | head -5
{"total_rows":2368,"offset":0,"rows":[
{"id":"560162","key":"\u00c1frica do Sul","value":1},
{"id":"560162","key":"\u00c1frica do Sul","value":1},
{"id":"560013","key":"Alemania","value":1},
{"id":"559596","key":"Algeria","value":1},
$ curl -s 'http://ramalho.couchone.com/lilcouch/_design/lilacs/_view/au_countries?reduce=false' | tail -5
{"id":"560034","key":"USA","value":1},
{"id":"560325","key":"USA","value":1},
{"id":"559604","key":"Venezuela","value":1},
{"id":"559957","key":"Venezuela","value":1}
]}
A more interesting result can be obtained if we pass the group=true option:
$ curl -s 'http://ramalho.couchone.com/lilcouch/_design/lilacs/_view/au_countries?group=true&limit=10'
{"rows":[
{"key":"\u00c1frica do Sul","value":2},
{"key":"Alemania","value":1},
{"key":"Algeria","value":1},
{"key":"Argentina","value":289},
{"key":"Austr\u00e1lia","value":2},
{"key":"Bolivia","value":1},
{"key":"Brasi\u00e7","value":1},
{"key":"Brasil","value":1185},
{"key":"Brazil","value":26},
{"key":"Brsil","value":1}
]}
The result set above, limited to 10 rows, shows the number of occurrences of each key. Obviously there are four entries for Brazil, with alternate and incorrect spellings. This would have to be dealt with elsewhere. The key point here is that the reduce function and the group option work together to produce aggregate results, similar to the ones we can produce with the SQL GROUP BY clause in a relational DBMS.
6. Results and Conclusion
6.1. Results
We have identified in CouchDB and MongoDB two modern, Open Source database systems which are suitable for semistructured records like those defined by the ISO-2709 standard and the ISIS family of systems, serving the needs of MARC and LILACS datasets.
Furthermore, we created a tool to convert ISIS records from the ISO-2709 format to JSON documents suitable for loading into CouchDB (or MongoDB, though we have not shown that in this paper).
We considered a number of alternative representations for ISIS data in JSON format. In this paper we used the type 2 representation which, though somewhat awkward to work with, preserves subfield ordering and allows for repeated subfields, a feature of MARC records. ISIS fields do not have indicators, so we have not discussed how to represent them in JSON. One possibility would be to use special subfield markers, like “_1” and “_2”, attached to field occurrences where the indicators are present.
Finally, we developed a JavaScript library to make it easy to handle ISIS-JSON type 2 records when creating CouchDB views.
6.2. Conclusion
These experiments and developments have shown that it is easy to import ISO-2709 data into a document database like CouchDB or MongoDB. After doing so, it becomes almost trivial to create Web services to publish the data, using just JavaScript, particularly in CouchDB thanks to its native support for JSON over HTTP.
While the semistructured data model was only formalized in the mid 1990’s, the ISO-2709 and ISIS record formats have always been concrete, albeit limited, examples of it. Research into that model includes results such as algorithms to extract a formal schema from actual datasets, methods for dealing with shared or duplicate data, and a normal form adapted to semistructured schemas (Tok, 2005). We have much to learn and apply from semistructured data research into our daily work with bibliographic records.
At BIREME/PAHO/WHO we continue investigating the challenges and opportunities of converting from the ISIS legacy systems to modern Open Source document databases. Meanwhile, we are also developing new applications – not limited to the ISIS data model and legacy data – using CouchDB, JavaScript, Python and the Pyramid framework. Pyramid is a new web framework resulting from the merger of the Pylons and Repoze projects, and it includes Deform, a form generation and validation library with strong support for repeating fields and nested forms, important features when building interfaces for semistructured data entry (Pylons, 2011). These new developments allow us to think about how we want the LILACS bibliographic database to operate in the year 2015, when its 30th anniversary will be celebrated.
Notes
1 The qualification “flat relational model” is used here because there is actually a controversy about the meaning of the First Normal Form. C. J. Date states that the atomicity requirement of the 1NF is pointless, and that since “types can be anything” it follows that “all relations are in first normal form by definition” (Date, 2005, p. 37). But E. F. Codd did define normalization as the process of removing non-simple domains from relations (Codd, 1970), and current database textbooks define the 1NF as Codd did (Elmasri, 2006; Silberschatz, 2006). Leaving aside the theory, although some RDBMS – like PostgreSQL and Oracle – support array values and even user-defined composite field values, modern database-independent access methods, such as the Ruby on Rails ActiveRecord ORM, often target the lowest common denominator, and that is the flat relational model.
2 “The structure, or ’empty container’, the content designators (tags, indicators, and subfield codes) used to explicitly identify or additionally characterize the data elements, and the content, the data itself (author’s name, titles, etc.) are the three components of the [MARC II] format.” (Avram, 1975)
3 The term “semistructured” often appears as “semi-structured” in the literature. Searching for both spellings is recommended because Google returns more results for the hyphenated spelling, but some key proponents of the model use just one word (Abiteboul, 1999; Tok, 2005; Suciu, 2001). Here I use one word, but kept the source spelling in quotations.
4 JSON is JavaScript Object Notation, a data exchange format described as a light-weight alternative do XML (Crockford, 2006b). Since 2006 JSON is an Internet standard, formalized by RFC4627 (Crockford, 2006a).
5 In MARC records, indicators are two single-digit positions located between the tag number and the field content, which have different uses depending on the tag number.
6 ISIS datasets sometimes contain repeated subfields due to typos and processing errors. However, the ISIS Formatting Language, used to generate indexes and displays, is only capable of extracting the first occurrence of a subfield.
7 From the XML standard (W3C, 1998): “An element type has mixed content when elements of that type may contain character data, optionally interspersed with child elements.” Mixed content also exists in HTML and in SGML, their common ancestor.
8 Here we mean “durability” as in the “D” in the ACID database properties, meaning that once an insert or update is committed, it is written to disk. For a discussion on why the designers of MongoDB initially compromised on single-server durability, see “What about Durability?“ (MongoDB, 2010). Update: as of March 16, 2011, MongoDB 1.8 is released and includes write-ahead journaling. “With journaling enabled, crash recovery is fast and safe” (MongoDB, 2011).
9 “An object is an unordered collection of zero or more name/value pairs” (Crockford, 2006a).
10 Association lists should not to be confused with associative arrays, such as those in PHP. A PHP associative array is like a hash in Perl or Ruby, a Python dictionary or a JavaScript or JSON object. In contrast, an association list, or alist, is not a primitive type in those languages, but can be built as an array or list of key-value pairs, where each pair is also an array or list. In Python, a more readable and convenient representation would be a list of tuples: [(key1, value1), (key2, value2), ...]. Association lists originated in Lisp and are common in Scheme (MIT, 2010).
11 As far as we know, apart from HTTP, the only other way to interact with CouchDB is via Hovercraft, an Erlang library which provides direct access to the database.
12 CouchDB indexes are generated by “view servers” which can be written in any language. An Erlang view server is bundled with recent versions of CouchDB, but is not enabled by default. Python can be easily configured for that purpose, and Java is also known to be used. A list of view server implementations can be found at http://wiki.apache.org/couchdb/View_server.
13 The numbers in the first column (98, 10, 38 in the example) identify a specific index, usually coinciding with the indexed tag number, but not necessarily. Some versions of ISIS support advanced querying using those numbers, others do not.
References
ABITEBOUL, Serge; BUNEMAN, Peter; SUCIU, Dan. Data on the Web: From Relations to Semistructured Data and XML. San Francisco: Morgan Kaufmann, 1999.
ANDERSON, C.; CHESNEAU, B. CouchApp: Standalone CouchDB Application Development Made Simple, 2009 [cited 2011 Mar. 26]. Available from: https://github.com/couchapp/couchapp/.
APACHE FOUNDATION. The Apache Cassandra Project [cited 2011 Mar. 26]. Available from: http://cassandra.apache.org/.
APACHE FOUNDATION. The Apache CouchDB Project [cited 2011 Mar. 26]. Available from: http://couchdb.apache.org/.
AVRAM, Henriette D. MARC: Its History and Implications. Washington, DC: U.S. Government Printing Office, 1975.
BARBIERI, Heitor. Bruma (Java library source code). São Paulo: BIREME/OPAS/OMS, 2010 [cited 2011 Mar. 26]. Available from: http://reddes.bvsalud.org/projects/isisnbp/browser/Bruma.
BIREME/OPAS/OMS. Diccionario de Datos del Modelo LILACS Versión 1.6a. São Paulo: BIREME/OPAS/OMS, 2008 [cited 2011 Mar. 26]. Available from: http://bvsmodelo.bvs.br/download/lilacs/LILACS-5-DicionarioDados-es.pdf
BIREME/OPAS/OMS. ISIS-JSON types. São Paulo: BIREME/OPAS/OMS, 2010 [cited 2011 Mar. 21]. Available from: http://reddes.bvsalud.org/projects/isisnbp/wiki/ISIS-JSON_types.
BIREME/OPAS/OMS. ISIS-DM: The ISIS Data Model API. São Paulo: BIREME/OPAS/OMS, 2010 [cited 2011 Mar. 29]. Available from: http://github.com/bireme/isisdm.
CHANG, Fay; DEAN, Jeffrey; GHEMEWAT, Sanjay; et al. Bigtable: A Distributed Storage System for Structured Data. In: OSDI’06: Seventh Symposium on Operating System Design and Implementation, Seattle, WA, 2006 [cited 2011 Mar. 21]. Available from: http://labs.google.com/papers/bigtable.html.
CODD, E. F. A Relational Model of Data for Large Shared Data Banks. Communications of the ACM, v. 13, n. 6, p. 377-387, jun. 1970 [cited 2011 Mar. 26]. Available from: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.98.5286&rep=rep1&type=pdf.
CROCKFORD, D. RFC4627: The application/json Media Type for JavaScript Object Notation (JSON). The Internet Society, 2006 [cited 2011 Mar. 21]. Available from: http://tools.ietf.org/html/rfc4627.
CROCKFORD, D. JSON: The Fat-Free Alternative to XML. JSON.ORG, 2006 [cited 2011 Mar. 21]. Available from: http://www.json.org/fatfree.html.
DATE, C. J. Database in Depth: Relational Theory for Practitioners. Sebastopol: O’Reilly Media, 2005.
DECANDIA, Giuseppe; HASTORUN, Deniz; JAMPANI, Madan; et al. Dynamo: Amazon’s Highly Available Key-Value Store. In: Proceedings of the 21st ACM Symposium on Operating Systems Principles, Stevenson, WA, 2007.
DIROLF, M. Binary JSON. BSONSPEC.ORG, 2010 [cited 2011 Mar. 21]. Available from: http://bsonspec.org/#/specification.
ELMASRI, R; NAVATHE, S. B. Fundamentals of Database Systems. 5th ed. Reading, MA: Addison-Wesley, 2006.
HOPKINSON, Alan. CDS/ISIS: The second decade. Information Development. February 2005 vol. 21 no. 1 p.31-37 [cited 2011 Mar. 26]. Available from: http://eprints.mdx.ac.uk/2700/3/isisseconddecade.pdf.
JQUERY PROJECT. QUnit, 2011. [cited 2011 Mar. 21]. Available from: http://docs.jquery.com/Qunit
LOPES, Francisco. Historia_ISIS.doc (internal memo). São Paulo: BIREME/OPAS/OMS, 2010.
MERRIMAN, Dwight. Comparing Mongo DB and Couch DB. MongoDB.org. [cited 2011 Mar. 21]. Available from: http://www.mongodb.org/display/DOCS/Comparing+Mongo+DB+and+Couch+DB”>.
MIT. MIT/GNU Scheme – Association Lists. Cambridge, MA: Massachusetts Institute of Technology, 2010 [cited 2011 Mar. 22]. Available from: http://web.mit.edu/scheme_v9.0.1/doc/mit-scheme-ref/Association-Lists.html.
MONGODB.ORG. What about Durability? MongoDB Blog, 2010 [cited 2011 Mar. 22]. Available from: http://blog.mongodb.org/post/381927266/what-about-durability.
MONGODB.ORG. MongoDB 1.8 Released. MongoDB Blog, 2011 [cited 2011 Mar. 22]. Available from: http://blog.mongodb.org/post/3903149313/mongodb-1-8-released.
PYLONS PROJECT. Deform. Agendaless Consulting, 2011 [cited 2011 Mar. 22]. Available from: http://docs.pylonsproject.org/projects/deform/dev/.
RAMALHO, L. LILACS on CouchDB, 2011 [cited 2011 Mar. 26]. Available from: https://bitbucket.org/ramalho/lilcouch
SILBERSCHATZ, A.; KORTH, H.; Sudarshan, S. Database System Concepts, 5th Ed. New York: McGraw-Hill, 2006.
SUCIU, Dan. Managing XML and Semistructured Data – Lecture Series (digital slides). Seattle: Department of Computer Science & Engineering, University of Washington, 2001 [cited 2011 Mar. 21]. Available from: http://www.cs.washington.edu/homes/suciu/COURSES/590DS/
SUCIU, Dan. Semi-Structured Data Model. In: LIU, L.; ÖZSU, M. T. Encyclopedia of Database Systems: Springer, 2009. p. 2601-2605.
THOMALE, Jason. Interpreting MARC: Where’s the Bibliographic Data? Code4Lib Journal, Issue 11, 2010-09-21 [cited 2011 Mar. 26]. Available from: http://journal.code4lib.org/articles/3832.
TOK, Wang Ling; LEE, Mong Li; DOBBIE, Gillian. Semistructured Database Design. Boston: Springer Science, 2005.
W3C. Extensible Markup Language (XML) 1.0 (Fifth Edition), 2008. [cited 2011 Mar. 26]. Available from: http://www.w3.org/TR/REC-xml/#sec-mixed-content
About the Author
Luciano Ramalho was designing large-scale Web publishing systems before the Netscape IPO and the first release of Internet Explorer. He has a B.S. in Library Sciences from the University of São Paulo, and is a software development supervisor at BIREME/PAHO/WHO, a digital library that is part of the Knowledge Management and Communication area of the Pan American Health Organization. His English-language blog is at http://standupprogrammer.blogspot.com.

jrochkind, 2011-04-12
It’s interesting to compare the JSON format you have arrived at to an attempt from Ross Singer to standardize a Marc-in-json format:
http://dilettantes.code4lib.org/blog/2010/09/a-proposal-to-serialize-marc-in-json/
I have personally not yet compared them to see how they differ.
Since the ISIS format you are working with is based on ISO-2709, like Marc, it is a similar domain, although different in some ways. It might be nice to try and arrive at a standard that meets both needs.
Miles Fidelman, 2011-04-12
Would not Z39.50, or Dublin Core be a better starting point for mapping bibliographic records into JSON – particularly for human readability?
Ross Singer, 2011-04-12
To follow up on Jonathan’s comment, there are a few proposals floating about to serialize MARC in JSON, all of which have their own relative merits.
Bill Dueber came up with marc-hash: http://robotlibrarian.billdueber.com/new-interest-in-marc-hash-json/ which is extremely similar to ISIS-JSON Type 2. The rationale was that serialization/parsing would be extremely fast and it was 100% roundtrippable (which is a big deal in MARC circles).
Andrew Houghton created MARC-JSON: http://www.oclc.org/developer/content/marc-json-draft-2010-03-11 which is very heavily inspired by marcxml. It is also very well documented and 100% roundtrippable (ok, all of the current proposals are).
Both of these proposals have their advantages, but neither lend themselves terribly well to JSONPath type queries (which is useful for the JSON-based document stores), which is why I drafted MARC-in-JSON: http://dilettantes.code4lib.org/blog/2010/09/a-proposal-to-serialize-marc-in-json/. It’s considerably more verbose than Bill’s a little less (maybe) than Andrew’s.
I’m not sure Andrew’s is supported in any openly available MARC parsers; marc-hash and MARC-in-JSON are both available in File_MARC (PHP) and ruby-marc.
I definitely second Jonathan’s statement that, since the formats are so similar, it would be really nice to find some common ground between the two formats in JSON.
That said, there didn’t seem to be much interest in formalizing a MARC-JSON serialization in this (extremely long) CODE4LIB mailing list thread: http://www.mail-archive.com/code4lib@listserv.nd.edu/msg08077.html
Luciano Ramalho, 2011-04-12
@jrochkind and @ross: thanks for the pointers. I found out about MARC-JSON only after I had submitted the paper. It is highly relevant, I will study the proposals and I will present a virtual lightning talk http://wiki.code4lib.org/index.php/Virtual_Lightning_Talks about handling one of the MARC-JSON variants in CouchDB.
Luciano Ramalho, 2011-04-12
@miles: thanks for your comment. We hate numeric field tags as much as anyone else. But our goal was not to map bibliographic records in general to JSON, but to convert a legacy database with a well documented schema and 25 years of records in it. We have quite a few databases like that one. The idea is to map as directly as possible the original records to JSON, so that we can import it all into CouchDB and then have a much richer set of tools to work with the data and eventually convert it to some new schema which will not have numeric field tags. Like I mentioned in the last paragraph, we are also developing new projects that do not depend on supporting legacy schemas, and in those cases we are using schemas that are much more human readable as you can see here: http://reddes.bvsalud.org/projects/scielo-books/wiki/DataModel
Miles Fidelman, 2011-04-13
@luciano: Point taken. On the other hand, there are
fairly direct mappings between numeric MARC fields and various human-readable Dublin Core attributes – it seems like there would be a lot of utility in adding in the human-readable attributes when importing into CouchDB. It would make the resulting database a lot more useful – e.g., if you did it right, adding an SRU/CQL query interface would be pretty straightforward in CouchDB.
Mapping bibliographic record subfields to JSON « Jakoblog — Das Weblog von Jakob Voß, 2011-04-13
[…] current issue of Code4Lib journal contains an article about mapping a bibliographic record format to JSON by Luciano Ramalho. Luciano describes two approaches to express the CDS/ISIS format in a JSON […]
Jakob Voss, 2011-04-13
Thanks for the interesting article! I compared several methods to encode ordered subfields in a short blog article.
Ross Singer, 2011-04-13
Miles, I’m not sure the advantage that storing human readable attribute keys in the data store brings: to use Dublin Core, you’d be flattening the model, changing semantics and (as a result) losing round-tripability.
Since (I think) the intention is to still be able to share ISIS records amongst organizations, this would be lost by mapping to some other metadata format.
You can’t “search” CouchDB (without a map/reduce function), anyway, so you’d need some abstraction layer to translate SRU/CQL to something usable in the first place. At that point you can translate human readable terms into whatever your local representation uses without introducing any lossiness into your data model.
Gabriel Farrell, 2011-04-13
Stepping away from MARCJSON formats for a sec (though I will say MARC-in-JSON has my vote — well done Ross), my plan for MARC imports into CouchDB is to create each document with Dublin-Corish fields as required (“title”, “author”, etc.) and attach the original MARC record to the document as a binary. I figure that way I don’t have to care about round-tripability — if I ever need another piece of metadata I can re-parse the original.
Miles Fidelman, 2011-04-13
@Gabriel – that’s sort of what I was thinking.
@Ross – maybe it’s my background in protocol engineering – one of the primary tenets of early protocol design was to make everything BOTH human and machine readable – makes for good error messages and diagnostics (e.g., you can telnet to a web site and, at least to an unencrypted port, and exchange commands and read the protocol responses) – the same principle is implicit in RESTful APIs as opposed to SOA-style web service interfaces – generally simplifies things all around
as to searching CouchDB – I was thinking that if the database is pre-processed, once, then writing map-reduce functions (e.g., for SRU/CQL queries) becomes pretty trivial
though, in thinking it all through, I’d think that something like Cassandra would be a better way to handle metadata
Luciano Ramalho, 2011-04-15
@Miles: implementing SRU/CQL in CouchDB would be a very interesting project. It would require some (a lot) of preprocessing of the database, but then again any indexed dataset is preprocessed by definition. As for Cassandra, it is an order of magnitude mode complex than CouchDB, and it would require lots of additional coding and processing to make it support flexible queries as well. The best thing about CouchDB is that it is very simple, but it does what it is designed to do very well.
Miles Fidelman, 2011-04-16
@Luciano: Point taken re. the complexity of Cassandra. CouchDB certainly has all a nice feature set, and it’s easier to write RESTful applications on top of it.
I was thinking that a key-value datastore might scale better for larger datasets. If not Cassandra, maybe RIAK (RESTful interface, fairly straightforward to deploy).
MySipisis Pro with NoSQL Database « Bayu-beIT, 2011-05-13
[…] kutipan salah satu artikel yang mendiskusikan NoSQL bakal cocok untuk digunakan sebagai pangkalan data bibliografis […]
De la base de datos clásica al NoSQL | tramullas.com, 2011-05-17
[…] que ofrece una NoSQL. Recientemente, Ramalho ha publicado en la recomendable Code4Lib Journal un trabajo en el cual han exportado registros bibliográficos desde ISIS a CouchDB, con buenos resultados. En un entorno cada vez con mayor cantidad de información etiquetada en […]
MySipisis » MySipisis Pro with NoSQL Database, 2011-05-31
[…] kutipan salah satu artikel yang mendiskusikan NoSQL bakal cocok untuk digunakan sebagai pangkalan data bibliografis […]
MySipisis Pro with NoSQL Database | Sistem Perpustakaan Digital, 2011-06-05
[…] kutipan salah satu artikel yang mendiskusikan NoSQL bakal cocok untuk digunakan sebagai pangkalan data bibliografis […]
Luciano Ramalho, 2011-07-16
I just moved the isis2json utility to a new repository, with all needed dependencies, to make it easier to install and use:
https://github.com/bireme/isis2json
mace, 2011-09-20
Thanks, this is the coolest article about NoSQL for librarians i know of, thanks mate :) Helped me grasp the concepts very well.
Ismael K. Isikel, 2013-10-03
Thank you Luciano G. Ramalho for this article.It is a great help in learning MARC that am reading from the Library of Congress. The title of the article from the Library of Congress website is “What is a MARC Record, and why is it Important?”
Cheers