by Demian Katz, Ralph LeVan, and Ya’aqov Ziso
Background
Libraries have long relied on authority data to ensure consistent, accurate retrieval of information. By maintaining unique, established terms for names and subjects, it is possible to find very precise sets of associated records, assuming proper metadata maintenance and adequate cross-referencing. In recent years, discovery tools like VuFind have begun to replace the traditional browse-oriented OPAC with an environment built around keyword searching and faceted navigation. While this new keyword orientation often makes the library search environment more accessible to the casual user, it also tends to diminish the use of authority data, and by extension, to reduce the precision of name and subject searching.
Next-generation discovery and authority data need not be mutually exclusive. It is possible to augment a discovery tool with authority data, allowing users to benefit from librarianship’s data curation without having to learn a whole new skill set. In “Querying OCLC Web Services for Name, Subject, and ISBN,” Ziso et al. examined some of the ways in which authority data can be accessed programmatically through OCLC’s web services and proposed possible uses of this data in a discovery environment. This article follows up on this research, showing exactly how those ideas can be implemented in the popular VuFind discovery environment [1].
Autosuggestion
One of the simplest ways of integrating authority data into a discovery environment is to use it to provide search suggestions in real time while the user enters a query. Assuming a well-maintained set of metadata, a search for established forms of name or subject terms should yield high-quality search results from the local catalog, assuming any results exist there. Even when no results are found locally, established terms are still useful for searching external services. For example, since VuFind includes modules for searching OCLC’s WorldCat [2] and Serials Solutions’ Summon [3], it would be possible to configure the standard “no results found” message to provide links into these additional resources, preventing dead ends in a user’s search experience.
As of release 1.0.1, VuFind still had no standard autosuggestion mechanism, although the feature was occasionally requested and discussed. Implementing simple autosuggestion is almost trivial, but two factors made autosuggestion in VuFind slightly more complex than average. First of all, VuFind tries to be Javascript library agnostic; depending on the selected theme, the software may use either YUI [4] or jQuery [5], so a solution needed to be easily compatible with both libraries. Additionally, VuFind aims for extremely granular configurability – administrators should be able to customize separate autosuggest behavior for each search type (subject, author, title, etc.) and be able to easily create their own autosuggestion plug-ins; a one-size-fits-all suggester would not suffice.
Ultimately, the design did not prove especially difficult. VuFind’s final autosuggestion implementation, released in version 1.1, works like this:
- VuFind’s templates include Javascript code that passes the current contents of the search box and the current state of the search type drop-down to an AJAX handler and then renders the handler’s response as clickable suggestions. This is easily accomplished with either YUI or jQuery code, depending on which theme is selected.
- A configuration file (searches.ini [6]) allows the administrator to specify which autosuggestion classes are loaded in response to which search type requests.
- The AJAX handler loads the configuration file and instantiates an appropriate autosuggester object based on the current search type. It uses this object to obtain suggestions based on the user’s current search terms, and it renders these suggestions in a format that can be easily processed by the calling Javascript.
- The autosuggester classes used by the AJAX handler follow a common interface [7], so it is easy to write new ones. The generation of suggestions is completely separated from the implementation details of passing those suggestions back to the browser, allowing each of these problems to be solved independently.
With this infrastructure in place, it is straightforward to provide suggestions from a variety of sources, including the local Solr index or remote authority services. VuFind is packaged with simple default autosuggesters that use its default bibliographic index, but at least two search types (author [8] and subject) can potentially benefit from authority-based suggestions. Proof-of-concept name suggestion classes were written for both OCLC’s Identities autosuggester [9] and a local Solr authority index [10] (discussed in more detail below). Both solutions performed reasonably well. Using the remote service introduces the usual hazards of depending on an external service (network lag time, potential outages) while also offering a lesser degree of control over the data; however, it is very easy to utilize, and it leverages OCLC’s huge WorldCat database for relevancy ranking. Using a local index offers better control over data and behavior while requiring significantly more local resources (memory and disk space) to achieve acceptable performance.

Figure 1. WorldCat Identities-based autosuggestions in VuFind’s default theme
The current proof-of-concept authority-based autosuggesters work on the assumption that the bibliographic data in VuFind’s index has headings consistent with the authority source being used. Libraries whose Integrated Library Systems support authority control features should have little trouble ensuring that this is the case. When working with authority and bibliographic records exported from the same ILS, consistency of headings between records is assured. When using an external API, there is less of a guarantee that the remote headings will correspond to the local records. Bibliographic records that have been subjected to regular name and subject authority work have a good chance of consistency with OCLC’s Identities records or the latest subject headings from the Library of Congress, but many libraries are not committed to this ongoing maintenance due to the time and money involved. Research is currently underway to investigate the possibility of using open data and open source tools to improve consistency between authority records and bibliographic records; this is discussed in more detail below.
Context-Sensitive Recommendations
The search suggestions offered in an autosuggestion box are inherently limited in their ability to convey information. Fortunately, the use of authority data need not be limited to autosuggestions. Starting with version 1.0, VuFind also provides a mechanism for displaying context-sensitive suggestions as part of the search results screen, either above or beside the list of matching documents. These suggestions are most commonly manifested as a box containing links to alternate searches or resources related to the current query, but the design is flexible enough to allow other creative applications.
The “recommendations module” feature is designed like this:
- Like autosuggesters, recommendation modules are built using a standard interface [11]. Each recommendation module is a class that obtains information about the user’s current search from VuFind, performs its own internal processing and then returns all of the information necessary to render suggestions on the search results screen. Since VuFind internally represents searches as objects, recommendation modules have access to many details (search query, search type, current filters, etc.) without requiring a lot of parameters in the interface.
- Whenever a search is performed, VuFind checks a configuration file (searches.ini, the same file used for autosuggestion settings) to see if any recommendation modules are relevant to the current search type (title, author, etc.). It is possible to set a default recommendation module for use across multiple search types, and it is also possible to load multiple recommendation modules for a single search. All relevant recommendation modules are instantiated and used to provide suggestions.
- The recommendations interface is not just a handy way to extend VuFind; it is also a key element of its core design. For example, VuFind’s prominent facet display (used for narrowing searches) is actually a recommendation module.
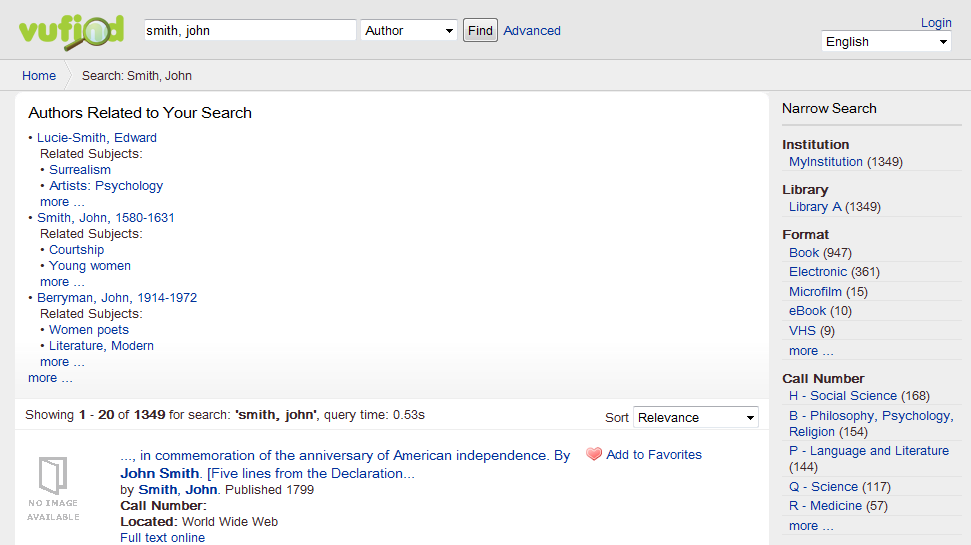
Figure 2. Context-sensitive author recommendations in VuFind
In their article, Ziso et al. presented demo Perl applications (Name Finder and Term Finder) which queried OCLC’s WorldCat Terminologies and Identities services for related, broader, and narrower terms. This code was easily translated into PHP recommendation modules [12], allowing author and subject searches to be augmented with context-sensitive suggestions for related avenues of investigation. In practice, the Identities suggestions generally seem more effective than the Terminologies suggestions, since the Identities API offers relevance ranking based on frequency data from the WorldCat database, while the Terminologies service for Library of Congress Subject Headings returns records in arbitrary order. This may improve in the future if improved sort functionality is added to the Terminologies LCSH search or if VuFind’s recommendations module is adjusted to use the FAST index [13] instead of LCSH (since FAST now supports a “recordcount” sort key). Implementing recommendation functionality based on a local Solr index is also reasonably straightforward, offering similar trade-offs to those discussed under Autosuggestion above. Also as with autosuggestion, the effectiveness of these tools relies on consistency between recommended headings and those actually found in bibliographic records.
Indexing Authority Data
As previously discussed, it is often useful to have a local index of authority data. In addition to protecting against external service outages, a local index also offers greater control over both content and ranking behavior. For example, suppose it would be helpful to highlight headings that pertain to a particular local collection. As long as the data being indexed contains enough detail to identify which headings apply to which collections, records outside of the target collection could be excluded with filter queries, or else the target collection could be given higher relevancy rankings through boost queries. With access to enough data, it would be possible to store headings for a local library, a consortium, and all of WorldCat in a single index, retrieving the most appropriate suggestions for any given scenario through context-sensitive filtering and boosting [14]. This sort of functionality is not available solely through use of OCLC’s Identities and Terminologies services, which currently reflect a single global, collection-neutral pool of headings.
VuFind is well-equipped to index authority data. It is packaged with the SolrMarc [15] indexing tool, which quickly maps MARC records into a Solr index, and its default multi-core Solr configuration includes a separate repository specifically intended for authority data. However, even though VuFind’s authority core has existed for quite some time, it was not until release 1.1 that its use began to mature with a more functional Solr schema and well-defined import scripts [16].

Figure 3. Abbreviated sample MARC authority record
The Solr schema used by the latest version of VuFind relies on a convenient fact: although the MARC authority specification [17] defines a plethora of fields, most of them boil down to the same things: main headings, see also references and see from tracings. Within the 1xx, 4xx and 5xx groupings, many tags are defined, but they all have the same basic meanings; the different numbers exist solely to distinguish the types of heading being referenced. Rather than defining separate fields for every heading type, VuFind’s authority schema instead takes a faceted approach: it has just one field each for “heading,” “use_for” and “see_also,” but it uses “source” and “record_type” fields to facet out where records came from and what types of headings are involved. SolrMarc properties files and a handful of custom BeanShell indexing scripts [18] are used to get the right data into the right places. Once the index is built, it becomes possible to search across all authorities or to narrow in on a particular type of heading from a particular source.
It is also important to note that even though the authority index currently focuses on 1xx, 4xx and 5xx fields, the remainder of the record is also used. An “allfields” catch-all indexes keywords from other places in the record that are not directly mapped to their own fields, improving findability [19], and a “fullrecord” field stores the original MARC data in full, allowing it to be easily displayed to the end user and offering flexibility for as-yet-unforeseen purposes.
Harvesting Authority Data
If you have local authority data in your ILS, you can easily export it and load it into VuFind using SolrMarc. However, if you do not maintain local authority data, it is necessary to obtain it from another source. Fortunately, a lot of authority data is government-generated and thus public domain, so it is possible to collect it from online sources.
As a proof of concept, VuFind is packaged with a command-line PHP script which is capable of incrementally harvesting the entirety of the Library of Congress Name Authority File through an SRU interface provided by OCLC [20]. Using the browse by modification date feature of the OCLC SRU interface, this script collects all of the NAF records in order of modification and saves them to a directory on disk in MARC-XML format. It can be re-run periodically to harvest new records modified or created since the last run. These harvested records can then be batch-indexed using the same tools that VuFind provides for dealing with OAI-PMH harvests [21].
In addition to collecting incremental additions to the index, the harvesting tool is also able to detect deleted records, a feature necessary since NAF records are sometimes removed when they are discovered to be redundant or obsolete. The tool identifies unwanted records by comparing LCCN values on the remote SRU server against LCCN values in the local Solr index. Since this requires a full SRU index scan and extraction of many terms from the Solr index, detecting deletes is a time-consuming and processor-intensive task. If the SRU interface is enhanced in the future to provide data on deleted records by date, it may be possible to achieve the same effect more efficiently. For now, at least the harvester serves its purpose: it produces a text file containing a list of records to delete, which can be processed by another of VuFind’s standard OAI-PMH tools to clean up the local index.
OCLC’s LCNAF index was chosen as a proof of concept for harvesting because of its convenient API and its use of MARC data, which is especially easy for VuFind to index. By constructing similar tools, other authority sources could also be loaded into VuFind’s index. A particularly good starting point for future research would be the Library of Congress Subject Headings (LCSH), which are freely provided in linked data format [22]. The potential application of LCSH to VuFind is fairly obvious, but there is also broader potential in developing tools for working with linked data; this may be a first step toward enabling VuFind recommendations based on much larger pools of semantic data such as Freebase [23].
Utilizing Authority Data
In addition to the autosuggestion and recommendation applications mentioned above, VuFind’s local authority index currently has two other applications. First of all, VuFind includes a simple Authority module which allows direct searching and faceted browsing of the authority data, offering direct access to the original MARC data. While authority records have traditionally been the domain of library staff rather than library patrons, exposing them through VuFind broadens their functionality and usefulness. The tremendous research effort that has gone into collecting the data they contain is thus made accessible to a broader audience.
Even more significantly, VuFind (starting with version 1.1) includes an Alphabetical Browse module [24] that implements structured heading exploration within VuFind, providing a useful alternative to keyword search for power users familiar with traditional early-generation OPAC functionality. The Alphabetical Browse module works by loading all titles, authors, and subjects from VuFind’s bibliographic index. It does not require an authority index, but can access authority data to incorporate see and see also references for names and subjects into its results.
Future Work
As suggested earlier, exploring user-friendly contexts in which locally indexed authority records could be presented (for example, in an “author information” module) may be worthy of further research. In order to justify its continued creation and maintenance, the value of rich authority data should be shared with everyone, not just catalogers.
Additionally, more powerful applications may be possible with the help of the eXtensible Catalog project’s Metadata Services Toolkit [25], a tool for bulk processing of metadata. Starting with VuFind 1.1, VuFind’s authority and bibliographic indexes are harvestable via OAI-PMH [26]. This makes it possible to export records from VuFind into the MST and augment them in various ways – flipping obsolete headings in bibliographic records, identifying authority records that are used in a particular collection, etc. Research on the optimal workflow for authority processing with the MST and VuFind is currently ongoing. Once completed, this research will help reduce inconsistencies between authority and bibliographic records in libraries that do not currently have access to expensive authority processing services, expanding access to all of the benefits provided by authority data while reducing the costs of having to outsource work to private authority vendors.
Conclusion
Using authority control during cataloging can benefit even a non-authority-aware discovery environment by, for example, ensuring that facets are applied consistently. However, by making the discovery environment directly aware of authority data, it is possible to tap into power beyond these basic passive benefits. So far, this area has not been explored to its full potential, and there is plenty of room for deeper research in the future. In the meantime, the various tools discussed above already demonstrate some of the potential of combining authority data with the discovery environment.
Notes
[1] VuFind: http://vufind.org/
[2] WorldCat: http://www.worldcat.org/
[3] Summon: http://www.serialssolutions.com/summon/
[4] YUI: http://developer.yahoo.com/yui/
[5] jQuery: http://jquery.com/
[6] searches.ini: https://vufind.svn.sourceforge.net/svnroot/vufind/trunk/web/conf/searches.ini
[7] VuFind autosuggester documentation: http://vufind.org/wiki/autocomplete
[8] What VuFind calls an “author” search could be more accurately described as a “contributor” search, since it may also turn up results matching editors and other types of contributors. The label “author” is used by common convention. The label “name” is avoided because it implies a broader scope; a “name” search might reasonably be expected to turn up works about a person as well as those contributed to by that person. Throughout this article, the term “author” is used to refer to a contributor-oriented search, while the term “name” is used to refer to authority data that could be used as either contributor or subject headings.
[9] Identities autosuggester code: https://vufind.svn.sourceforge.net/svnroot/vufind/trunk/web/sys/Autocomplete/OCLCIdentitiesAutocomplete.php
[10] Solr Authority index autosuggester code: https://vufind.svn.sourceforge.net/svnroot/vufind/trunk/web/sys/Autocomplete/SolrAuthAutocomplete.php and https://vufind.svn.sourceforge.net/svnroot/vufind/trunk/web/sys/Autocomplete/SolrAutocomplete.php
[11] Recommendation module documentation: http://vufind.org/wiki/building_a_recommendations_module
[12] OCLC recommendation modules: https://vufind.svn.sourceforge.net/svnroot/vufind/trunk/web/sys/Recommend/WorldCatIdentities.php and https://vufind.svn.sourceforge.net/svnroot/vufind/trunk/web/sys/Recommend/WorldCatTerms.php
[13] FAST (Faceted Application of Subject Terminology) search interface: http://tspilot.oclc.org/fast/?operation=explain&version=1.1
[14] Although his work does not deal directly with authority data, David Walker’s screencast on his award-winning Bridge project (http://library.calstate.edu/bridge/) discusses the value of distinguishing between different layers of availability (not just the simple binary of “local” and “in WorldCat”). Going into depth on this idea is beyond the scope of the current article, but this idea is important to think about when designing search workflows that incorporate authority data – the user may have several different search contexts, and it is important to make these easy to understand and navigate between.
[15] SolrMarc: http://code.google.com/p/solrmarc/
[16] VuFind authority import documentation: http://vufind.org/wiki/importing_records#importing_authority_records
[17] MARC Authority Specification: http://www.loc.gov/marc/authority/
[18] See lcnaf.bsh and get*LCCN.bsh in this directory: https://vufind.svn.sourceforge.net/svnroot/vufind/trunk/import/index_scripts/
[19] For example, note how the 360 and 680 fields contain potentially useful keywords in this example subject authority record: http://fred.lcsubjects.org/lccn/sh85070835
[20] LCNAF harvest script: https://vufind.svn.sourceforge.net/svnroot/vufind/trunk/harvest/harvest_naf.php
[21] VuFind OAI-PMH harvesting documentation: http://vufind.org/wiki/importing_records#oai-pmh_harvesting
[22] LCSH download: http://id.loc.gov/download/
[23] Freebase: http://www.freebase.com/
[24] VuFind Alphabetical Browse documentation: http://vufind.org/wiki/alphabetical_heading_browse
[25] XC MST: http://code.google.com/p/xcmetadataservicestoolkit/
[26] VuFind OAI-PMH server documentation: http://vufind.org/wiki/tracking_record_changes#oai-pmh_server_functionality
References
Ziso Y, LeVan R, Morgan EL. 2010. Querying OCLC Web Services for Name, Subject, and ISBN. Code4lib Journal [Internet]. [cited 2010 December 21]; 9. Available from: http://journal.code4lib.org/articles/2481.
About the Authors
Demian Katz has a B.S. in Computer Science from West Chester University and an M.L.I.S. from the University of Pittsburgh. As Villanova University’s lead VuFind developer, he is greatly enjoying the opportunity to apply all of his education to one job and to collaborate with an enthusiastic open source community. In his Copious Spare Time, he maintains a bibliography of paper-based interactive fiction at http://gamebooks.org (please pardon the Lynx-friendly interface).
Ralph LeVan is a Senior Research Scientist in OCLC Research. Lately he has been working on Identity issues and authority databases in general. He is a member of the SRU standards group within OASIS and seems to find a way to put an SRU server at the bottom of all his technology stacks.
Ya’aqov Ziso has been involved with bibliographic control and maintenance of authority headings for both corporate and academic sectors. Currently he directs the digital archiving of the School for Designing a Society and composes experimental music.

dlovins, 2011-07-27
Great article. Thanks! I was just wondering who’s experimenting with VuFind and the eXtensible Catalog MST (mentioned in the “Future Work” section).