by Andrew Hankinson, Wendy Liu, Laurent Pugin, and Ichiro Fujinaga
Introduction
Diva (Document Image Viewer with Ajax) is a multi-page document image viewer, designed for digital libraries to present documents as a single, continuous item, rather than the traditional method of presenting page images one at a time. Using “lazy loading” methods for only loading those parts of a document that are currently being viewed, it presents a quick and efficient way of displaying hundreds of page images from digitized books and other documents on a single web page.
The Diva project centers around Diva.js, a unique jQuery plugin that provides a user interface for viewing document images. The design of this component was informed by a survey of existing document image viewing interfaces, and from this survey a number of functional requirements for how document images should be displayed in a browser were formulated.
While the core of the Diva project is the jQuery plugin, other image processing infrastructure is required to serve the images in an efficient manner. We discuss how the components of this infrastructure work together in the “How it Works” section.
As an open-source project, we welcome feedback and code contributions. We are currently using Diva as part of an ongoing research project in digital music documents, but are interested in how it can be used for other document digitization projects in libraries and archives.
History and Motivation
Diva began as part of a project by the Swiss working group for the Répertoire International des Sources Musicale (RISM) project [1]. RISM is an international initiative, founded in 1952, whose purpose is to identify and catalogue musical sources held in libraries and archives around the world. The RISM database contains extensive information about each source in its catalogue, and is an important tool for discovery and source verification for music researchers.
In 2008, the Swiss working group for the RISM project was granted funding for an exploratory project in digitizing musical sources (prints and manuscripts) from Swiss composers held in libraries and monasteries across Switzerland. The goal of this project was to combine the extensive, research-quality metadata gathered over decades with high-quality images of the source itself, and publish these online in a freely accessible database. This would allow researchers to access the sources globally, and provides an important component for the preservation and promotion of Swiss national musical heritage [2].
At the beginning of this exploratory project, a partnership between the Swiss RISM and the Distributed Digital Music Libraries Laboratory (DDMAL) at the Schulich School of Music of McGill University was tasked with identifying the tools and interfaces that would be used for displaying the source images in a web browser. To identify the current “state of the art” we conducted a survey of 24 digital libraries. Based on this survey, we identified a list of functional requirements that we wanted in a document image viewer that was specifically designed for displaying musical sources. This survey is discussed extensively by Hankinson, Pugin, and Fuginaga (2009) [3], but we present a brief summary here.
Survey
We formulated five functional requirements from our survey in response to what we considered to be the best and worst features of current digital document image displays. While they were developed in a musical context, we think that they are broadly generalizable over all document types.
1. Preserve Document Integrity
One of the most common methods for displaying document images online is in an “image gallery” format, where users are required to click “next” and “back” hyperlinks to navigate page by page through the document. Some interfaces provide users with the ability to navigate to a specific page, either using a drop-down selection, a text box, or a series of hyperlinked page numbers. This method of display does little to preserve the original document as a cohesive entity.
There are several alternatives to this approach. The Google Books project [4], perhaps the largest and most well-known book digitization project, presents items as a single scrollable entity embedded within the webpage. This allows users to very quickly scroll and navigate through the entire work.
The Internet Archive [5] method uses a book metaphor where users are presented with images of facing pages and can navigate through the book by “turning” the pages. This method presents some usability challenges for quickly navigating through a source, but it does provide a very accurate representation of the original source layout.
2. Allow side-by-side comparison of items
Music, especially in older sources, is often published as “parts,” where each musician’s score contains only the music for their instrument or voice. These parts are bound in separate physical books or leaflets. As such, reconstructing the entire musical piece requires viewing multiple books simultaneously. Providing the ability to view two or more sources simultaneously, therefore, is important for comparing sources or co-reading a source along with its criticism or annotations.
3. Provide multiple page resolutions
For older materials, especially manuscripts, the ability to view details such as faint pencil markings or different ink colours is necessary. High-resolution images allow the user to identify small details, which is especially important in tasks such as reading cursive script or identifying faded or obscured portions of the image. On the other hand, smaller low-resolution images give users the ability to very quickly get an overview of the entire document.
The ability to move between high- and low-resolution images is a feature of many existing digital library systems, with many choosing to display three image resolutions: “thumbnail” for overviews of the entire document, “browser safe” for displaying individual pages that fit on a users’ screen, and a “high resolution” view for detailed image study. The state of the art for this type of document viewing can be seen in systems like the World Digital Library [6] [Figure 1], where the user selects from a list of thumbnails provided in the left column to zoom in to see details in the full-page display.
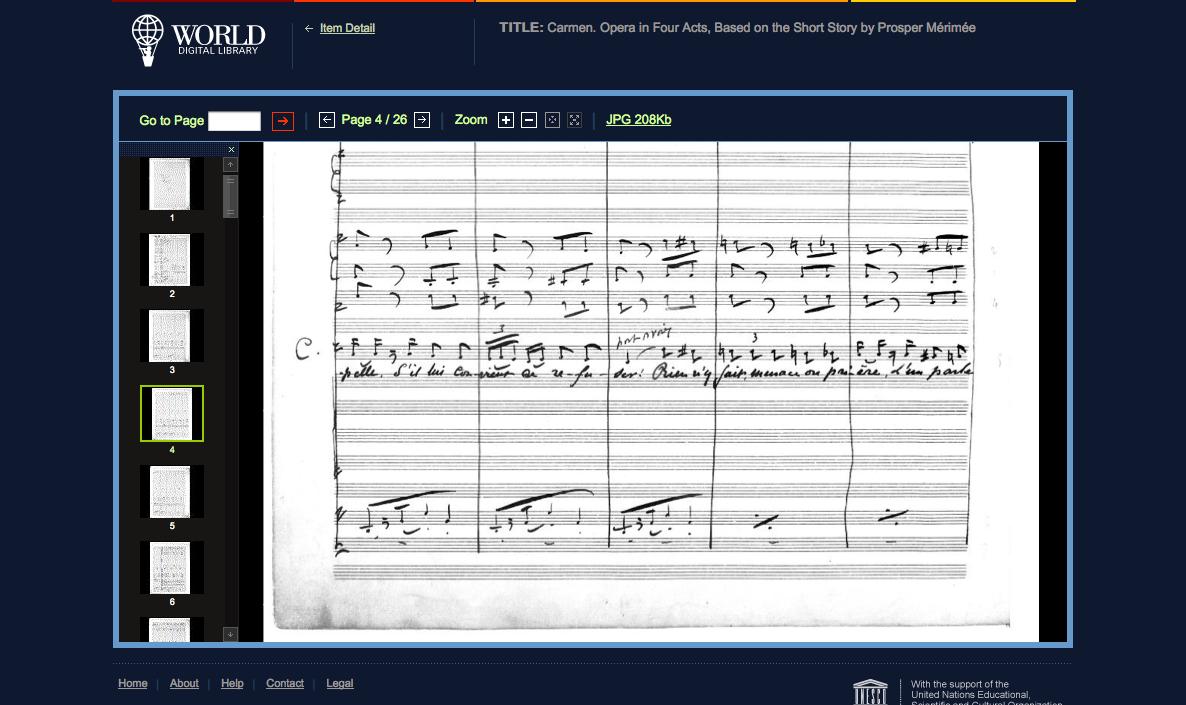 Figure 1. World Digital Library.
Figure 1. World Digital Library.
4. Optimize document loading
Presenting large page images, especially at higher resolutions, makes it difficult for users to quickly leaf through a document. Two common approaches are to allow users to download the high-resolution images one at a time, or have them download the entire document encapsulated within a container format like PDF. For ultra-high resolution documents, however, this download may involve hundreds of megabytes, and the user must wait until the entire document is downloaded before viewing it.
The Google Books and Internet Archives interfaces use optimization techniques that load page images only on demand. As a user scrolls through the document, the browser sends an asynchronous HTTP request (“Ajax”) to the server to deliver the images for the pages that the user is currently viewing. This can be further optimized for images at very high resolutions by borrowing a technique from mapping sites where high-resolution satellite photos are broken into smaller tiles, which may then be served to the user in parallel.
5. Present item and metadata simultaneously
While not part of the document viewer itself, the ability to view the item and its catalogue metadata simultaneously is a highly desirable feature. This requirement takes on a more significant role when integrating the viewer into a larger context, and points to the need for a document viewing system that can be easily integrated into existing digital library environments, including an integrated set of controls or callbacks for manipulating page zooming and scrolling.
Existing implementations
Although we compiled our list of functional requirements by examining features from existing implementations, we could find no single existing implementation where all features were present. As part of our survey, we examined some standalone document viewing frameworks, including Zoomify [7], the IIPMooViewer (and variants) [8], and the Seadragon Ajax viewer [9]. We determined that these viewers were designed as generic high-resolution image viewers, and as such did not present a document as a complete cohesive entity. Google Books has a promising document image viewer, but it is currently not available as an open-source project.
At the time of our survey, the Internet Archive used the DjVu format and a page-turning book interface that ran in the browser as a Java applet. They have since developed a new BookReader [10] interface, currently the only other open-source implementation known to encapsulate many of our functional requirements. Their interface offers many interesting features, such as contact sheet and facing-page views. However, their implementation does not use a tiling system for downloading page content, meaning that at higher resolutions the entire page is downloaded to the browser as a single image.
Towards Diva.js
Our first implementation was written as a component to a larger ExtJS interface for managing digital images, part of an in-house image system for the Swiss RISM. It was not released publicly, but it has been adopted by a number of other projects related to the RISM.
While the ExtJS component worked very well, it required loading the entire ExtJS library, including superfluous components, which added significantly to the loading time for pages. The decision was made to port the existing system to jQuery, a widely used JavaScript framework that is smaller and more modular in design, with faster load and execution time than ExtJS.
Development on the jQuery plugin began in February 2011, using the same design requirements as the original ExtJS component. In the next section we describe the components of a complete Diva.js installation, including image processing, server infrastructure, and the features of the jQuery plugin.
How It Works
The most visible and unique component of this project is the JavaScript-based document viewer itself, but this must be backed by efficient server software to process and deliver multi-resolution images to the user. A brief overview of how these components fit together is given in Figure 2.
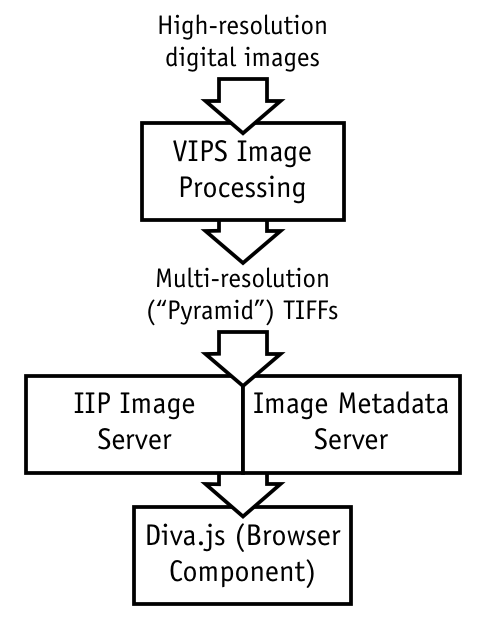 Figure 2. The components of the Diva.js infrastructure.
Figure 2. The components of the Diva.js infrastructure.
Image Processing
To switch between multiple sizes of page images, Diva uses a multi-resolution, or “pyramid” image format [Figure 3], where the original high-resolution image files are pre-processed into several sizes of smaller resolution images that are themselves sub-divided into an array of tiles of a given size. We have found tiles of 256×256 pixels work best. These images can be created by several open-source image-processing utilities. We have found that the VIPS [11] image processor is the most efficient and provides the most reliable results, but ImageMagick [12] could also be used.
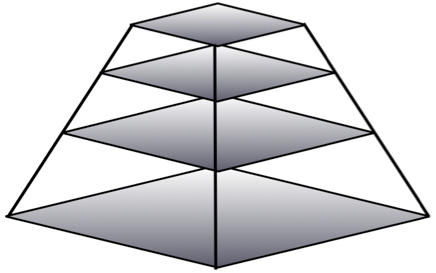 Figure 3. Multi-resolution, or “pyramid” image structure.
Figure 3. Multi-resolution, or “pyramid” image structure.
There are two popular image formats that provide multi-resolution image capabilities, TIFF and JPEG2000. While JPEG2000 is more modern and arguably provides more fine-grained control over the number of image resolutions that can be served, there are no open-source libraries for JPEG2000 image processing and serving. The Kakadu [13] library, currently the most efficient and best supported JPEG2000 library, requires a licensing fee for implementers. For version 1.0 of the Diva project we chose to support only multi-resolution TIFF images, but JPEG2000 support is scheduled as a desired feature for the next version.
In the multi-resolution TIFF format, the number of image resolutions available for a given image is determined by the maximum resolution of the original file and the size of the individual tiles. The formula for calculating the number of resolutions (n) available for a given image size is given in Equation 1.
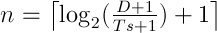 Equation 1. Calculating the number of resolutions based on image and tile sizes.
Equation 1. Calculating the number of resolutions based on image and tile sizes.
The largest dimension, D, of the image (width or height) and the tile size, Ts, are both given as pixels. For example, an image with the largest dimension of 4120 pixels and a tile size of 256 pixels would be processed into six zoom levels. A Python script, process.py, is available in the Diva repository that will process a directory of images into multi-resolution TIFF files using the VIPS Python module.
Tile Image Server
The tile image server takes a request for a segment of the image at a given resolution and returns that portion of the image as a tile. It runs as a FastCGI process and can be integrated into most popular web servers. An example request to the tile server might look like:
http://example.com/iipsrv.fcgi?FIF=/tmp/image-75.tif&JTL=2,0
The JTL parameter in the request specifies (resolution,tile) which, in this case, is the first tile from the third resolution (resolution numbers are zero-indexed) for image-75.tif.
Although there are several potential image tile servers, we currently only support the IIP Image Server [14]. While the IIP Image Server presents a very fast method of processing and serving image regions, we found that a single FastCGI process could not provide an adequate response time when dealing with the highest resolution images. Our current setup uses the Nginx web server as a front-end and load balancer, providing round-robin balancing across five FastCGI processes. The IIP Image Server also has the ability to utilize a Memcached database for caching tiles. Our current implementation uses five Memcached stores. We have found that this setup provides acceptable performance, even on slower connections.
Data Server
The data server is responsible for sending information about the entire document to the browser component. This information is used by the browser to construct the container HTML elements required to display the entire document and its constituent pages.
This data server has access to a number of stored properties about the document, and can then construct a JSON response to send to the browser containing information about the total document height at a given zoom level (i.e., the total height of all images in the collection), the average and maximum heights and widths of the images (for the inter-page margins and ensuring the document is centred in the browser) and the dimensions of each page at a given zoom level.
The data server may be implemented in any server-side language. We are currently using a Django web application with a SQLite database for storing image information. However, we are also bundling a basic PHP script, divaserve.php, for providing filesystem-based image serving. This PHP script caches the required information for each image as a plain text file, which is then read and served when the user requests a document. This has the advantages of running on any PHP-equipped web server, and not requiring a complete database setup for serving small collections of image files.
jQuery Plugin
The Diva.js jQuery plugin consists of a small number of JavaScript, CSS, and image files used for displaying the images in the browser. The core jQuery and the jQuery UI libraries are both prerequisites for the plugin, and we bundle the Dragscrollable [15] plugin with Diva.js.
The following code block shows a typical instantiation of the Diva.js component.
<script type="text/javascript" charset="utf-8">
var dv;
$(document).ready(function() {
$('#diva-wrapper').diva({
adaptivePadding: 0.5,
enableZoomSlider: true,
enableGotoPage: true,
iipServerBaseUrl: "http://example.com/iipsrv.fcgi?FIF=/path/to/imgs/",
backendServer: "http://example.com/divaserve.php?d=imgs",
});
dv = $("#diva-wrapper").data('diva');
});
</script>
...
<body>
<div id="diva-wrapper">
</div>
</body>
...
At instantiation, the iipServerBaseUrl and backendServer parameters point to the location of the tile image server and the data server, respectively. Other options, like a visible zoom slider and a text box for entering specific page numbers, may be enabled here.
When a page is loaded, the Diva.js plugin uses the data server to gather information about a document and display it in a continuous, scrolling <div> element on the page. The layout is calculated from the information returned by the data server, and the appropriate tile numbers are then requested from the tile image server. As the user scrolls through the document and zooms in and out from the page images, the JavaScript component continuously sends off requests for new pages of the document from the tile image server. Some pages at higher resolutions do not fit into the users’ browser, and Diva will optimize the page loading by only requesting the tiles for the portion of the image that the user is currently viewing.
The Diva.js component also provides a number of convenience methods for navigating through a document. It supports double-click to zoom in, control-click to zoom out, and click-and-drag to scroll the document. Also present is a full-screen view that will expand the document viewport to take up the entire width and height of the users’ browser window.
Diva.js has been tested to work with most modern browsers. We are also targeting Mobile Safari on the iPad, iPhone and iPod Touch, and provide platform-specific navigation like single-finger scrolling, and pinch-to-zoom gestures. We will likely support more mobile browsers in future releases.
We believe that this setup provides a sufficiently modular and self-contained infrastructure for implementing a continuous scrolling, multi-resolution document image viewer into new and existing digital document initiatives.
Applications
Although the core functionality of the Diva project is drawn from a variety of existing document and image viewing technologies, we believe Diva represents a unique method of displaying document images to users in a seamless interface. Diva presents users with a number of unique features, including continuous scrolling through large documents, high-resolution image viewing, and an optimized method for asynchronously loading page images using an image tile approach.
We are currently using the Diva infrastructure as part of the Optical Music Recognition for Plainchant project [16]. This project is exploring methods of using optical music recognition (i.e., optical character recognition for printed music) for automatically transcribing text and music from books with printed square note notation and making it searchable in an online web application. As a pilot study for this project, we are transcribing the Liber Usualis, a 2340-page service book used primarily by the Catholic Church. We are using the Diva infrastructure to serve all pages in five resolutions, representing a total book size of 3.2 GB.
One further advantage of using a tile image approach is that libraries and archives can make their high-resolution document image collections available for viewing online without providing a readily-accessible means of downloading the image. This may be important for situations where organizations want to publish their collections online, but want to maintain copyright control over their images. Although it is not impossible to reconstruct an entire high-resolution document from the component tiles, it is not as simple as downloading the page images.
We have set up a demonstration site [17] to illustrate how Diva.js may be used. The combined size of the images for the manuscript featured in this demo totals 4.7 GB. Figure 4 shows two screen captures from this manuscript illustrating the lowest and highest resolutions available.
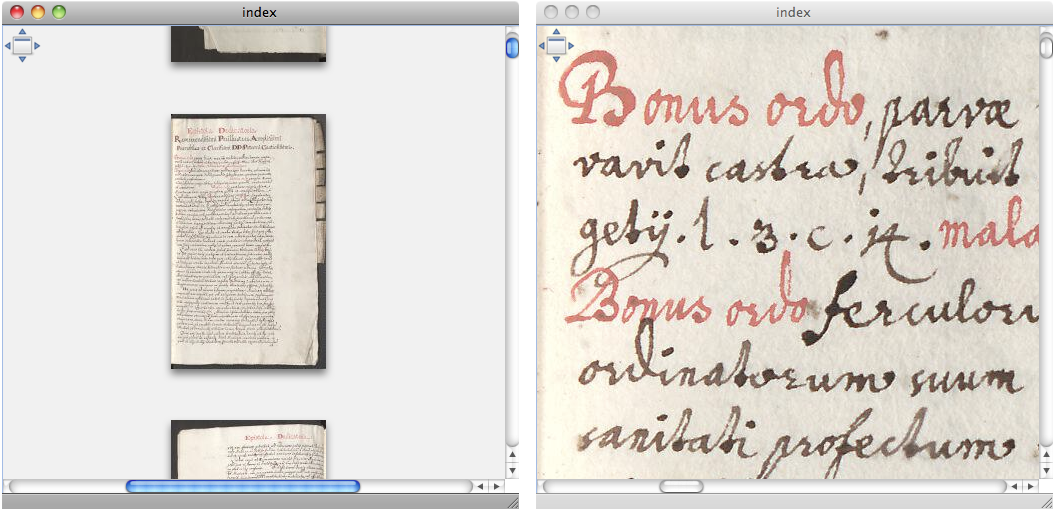 Figure 4. Lowest (left) and highest (right) resolutions for a sample page.
Figure 4. Lowest (left) and highest (right) resolutions for a sample page.
Feedback and Contributing
The Diva project is part of a larger research program in digital music archives and libraries being conducted at McGill University. Individuals or projects that find this work valuable are encouraged to let us know where Diva is being used.
Every effort was made to ensure that each component in the diva infrastructure was available under an open-source license. The VIPS system and the IIP Image Server are both licensed under the GPL, and the data server component may be implemented in any freely available server-side language. All components of the Diva project, including the image processing script, the JavaScript plugin and the divaserve PHP script are available under the MIT license.
We welcome participation from interested individuals. The project code, documentation, and issue tracker are hosted on GitHub [18]. We also encourage developers to fork the project and contribute any modifications or features back to the core repository.
Conclusion
In this article we presented the Diva project, an efficient continuous document image viewer designed to present a unified view of a document while simultaneously providing users with the ability to view high-resolution versions of each image. We believe that Diva represents a unique approach to document image representation. Although it is inspired by features available in many other document image viewing interfaces, Diva provides a novel combination of these features. It is our hope that others will find this work valuable, and will be interested in helping us grow and extend Diva.
Acknowledgements
The authors would like to thank the Swiss National Science Foundation and the Social Sciences and Humanities Research Council of Canada for their generous support of this project.
References
[1] Répertoire International des Sources Musicales. http://www.rism.info
[2] Pugin, L., A. Hankinson, and I. Fujinaga. 2011. Digital preservation and access strategies for musical heritage: The Swiss RISM experience. OCLC Systems & Services. Forthcoming
[3] Hankinson, A., L. Pugin, and I. Fuginaga. 2009. Interfaces for document representation in digital music libraries. In: Proceedings of the Conference of the International Society for Music Information Retrieval (ISMIR), Kobe, Japan. http://ismir2009.ismir.net/proceedings/OS1-3.pdf
[4] Google Books. http://books.google.com
[5] Internet Archive. http://archive.org
[6] World Digital Library. http://wdl.org
[7] Zoomify. http://www.zoomify.com
[8] IIPMooViewer. http://iipimage.sourceforge.net/documentation/iipmooviewer
[9] Seadragon Ajax. http://gallery.expression.microsoft.com/SeadragonAjax
[10] Internet Archive BookReader. http://openlibrary.org/dev/docs/bookreader
[11] VIPS Image Processing System. http://www.vips.ecs.soton.ac.uk
[12] ImageMagick. http://www.imagemagick.org
[13] Kakadu Software. http://www.kakadusoftware.com
[14] IIPImage. http://iipimage.sourceforge.net
[15] Dragscrollable jQuery Plugin. http://plugins.jquery.com/project/Dragscrollable
[16] Optical Music Recognition for Plainchant. http://ddmal.music.mcgill.ca/wiki/Optical_Music_Recognition_for_Plainchant
[17] Diva.js Demonstration. http://ddmal.music.mcgill.ca/diva/demo/
[18] Diva.js Code Repository. http://ddmal.music.mcgill.ca/diva/
About the Authors
Andrew Hankinson is a PhD candidate in the Department of Music Research at the Schulich School of Music, McGill University. He holds a Bachelor’s degree in Music Theory/History from Acadia University and a Masters in Library and Information Studies from McGill University.
Wendy Liu is an undergraduate Computer Science and Biology major in the Faculty of Science at McGill University.
Laurent Pugin is Co-Director of the Swiss Office of the Répertoire International des Sources Musicales (RISM) in Bern, Switzerland. He has Bachelor’s degrees in Music (Viola), in Musicology, and in Computer Science, and a Master’s degree and a Ph.D in in Musicology from the University of Geneva, Switzerland.
Ichiro Fujinaga is an Associate Professor and the Chair of the Music Technology Area at the Schulich School of Music at McGill University. He has Bachelor’s degrees in Music/Percussion and Mathematics from University of Alberta, and a Master’s degree in Music Theory, and a Ph.D. in Music Technology from McGill University.

Asteko laburpena — Zeruak eta urak, 2011-08-29
[…] Shared Diva.js: A Continuous Document Viewing Interface – The Code4Lib Journal. […]
R Hariharan, 2012-04-08
Hi,
I am quite impressed with the DIVA technology for viewing images seamlessly. I am looking at this DIVA without having tightly coupled with IIP Image server and meta data server.
Please help me to understand, if this is possible so.
Thanks
R Hariharan (Hari)
Andrew Hankinson, 2012-09-03
Hi Hari,
Currently it is not possible to do this. Diva requires the IIP image server to serve the image files, and the metadata server for performing measurements of the entire document image collection so that the JavaScript can lay the document out properly.