by Jonathan Gorman
Introduction
As current “next-generation” catalogs attempt to overcome the inadequacies of the previous generation, they have abandoned useful techniques that have evolved in the practice of cataloging. A good example is the display of search results for works by an individual author. Many of the last generation of catalogs offered large browse lists of unique authors with little guidance for choosing between authors. The current generation lets you find all the books written by people with the same name but still offers little to those who want the works of just one author. Relatively simple changes allow authority practice to be used more effectively in the next generation. This article will show a quick enhancement to the VuFind system that improves use of its heading information to group books by particular authors. A similar technique could be applied to many of the next-generation catalogs.
Generations of Catalogs and Authority Control
Many of us can still remember working with the card catalog. Given a large enough collection, you would find yourself flipping through “Johnson, James, 1705-“, “Johnson, James, 1777-“,”Johnson, James, 1835-“, and so on. Each card would have the author’s name along with the information about a particular work. Fanning the names gave a sense of what the person wrote or created. If the titles did not seem to match the search, you could just skip ahead until the pattern changed. One could learn to quickly scan the catalog in this manner, flipping the cards in a blur.
Then came the first generation of web interfaces. This generation typically used the concept of an author browse list. Instead of seeing sequences like:
Johnson, James, 1705- Articles of visitation and enquiry Johnson, James, 1705- Sermon preached before the Right Honourable ... Johnson, James, 1777- Economy of health Johnson, James, 1777- Tour in Ireland: with meditations and reflections
You saw:
Johnson, James, 1705- Johnson, James, 1777-
Examples of such lists can be seen in many currently used systems:
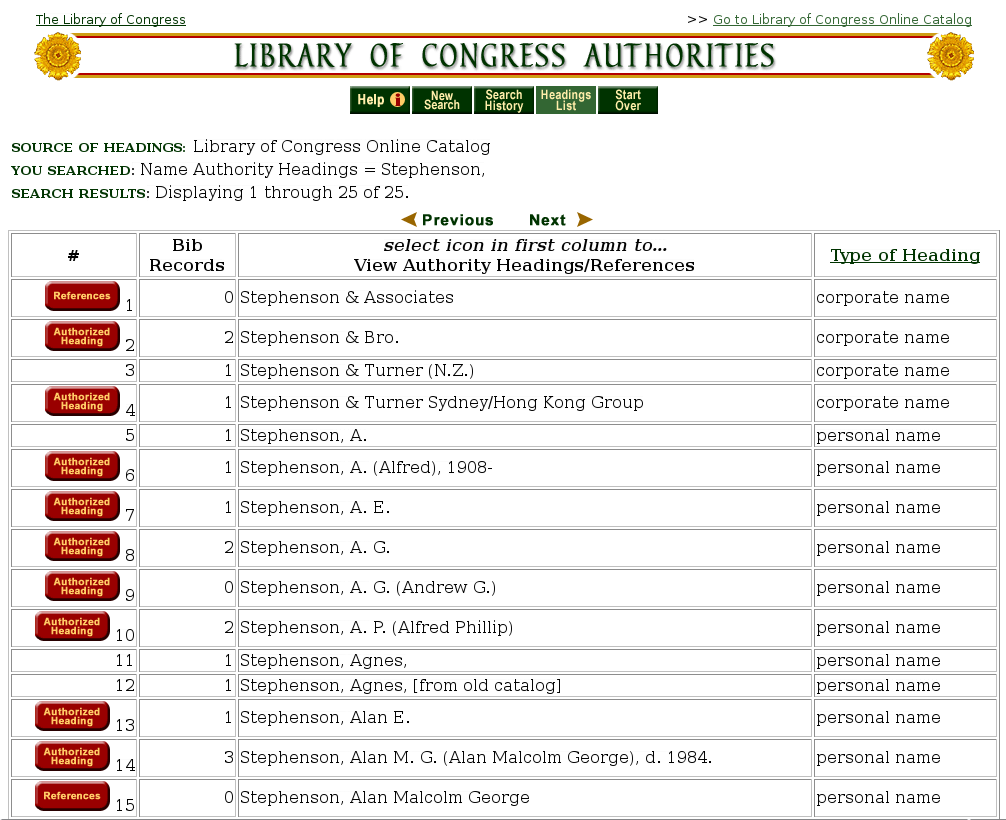 Library of Congress – Voyager catalog
Library of Congress – Voyager catalog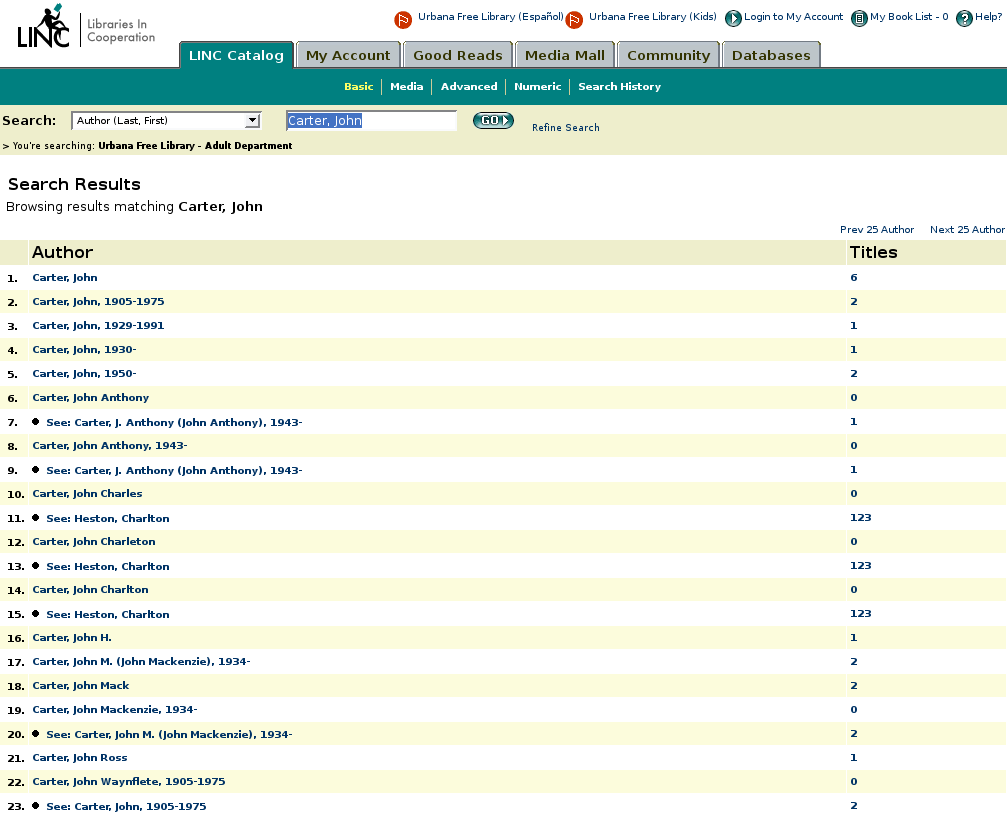 Urbana Free Library – Horizon Information Portal.
Urbana Free Library – Horizon Information Portal.In theory, instead of having to look through a hundred cards to find an author, the searcher need only view a screen or two. In reality, the old card based system’s speed was limited by manual dexterity and mental agility. In newer systems, though, users must wade through the tedium of multiple distinct actions, and their speed is limited by the time spent waiting for pages to load.
Compounding the problem was a maze of see, see also, and scope notes, presented in a poorly explained and unfriendly interface. Clicking an author link in an individual record may take you to a list of works by that author in some systems like Voyager, while others like Horizon took you to the appropriate place in the author browse.
Many next-generation catalogs take the opposite approach to the author browse list. Works by authors who share a name get lumped together, usually derived from the subfield a of the main entry or added entries in the MARC record. Records for “Carter, John, 1921-” will be interspersed with records for “Carter, John, 1912-“. This can be seen in implementations of VuFind, Evergreen, Worldcat.org, and Koha.
For smaller collections or less common names, this is not as big of a hurdle. There is one famous Ray Bradbury and getting all the books by him is relatively easy using just his name. However, as collections grow, more common names start colliding. In the case of large collections with works spanning centuries it becomes much more difficult to find what works a library may have by a single individual. Your search can return hundreds of volumes with no obvious way to narrow the results down to the books of just one author.
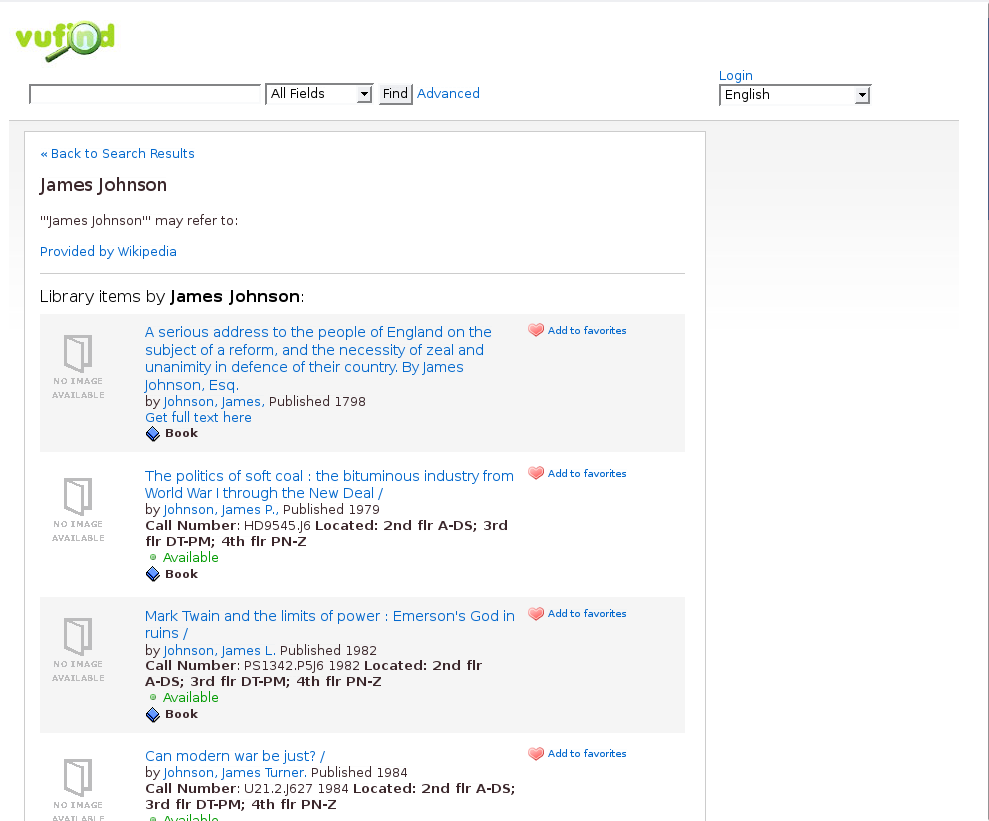 VuFind’s Author Page
VuFind’s Author PageCan we do better in the next generation? I believe so.
Modifying VuFind
Why use VuFind?
- The interface pages use PHP, the indexing and searches use Solr, and transforming the records for both indexing and display are done using XSLT. I am already familiar with all of these technologies.
- VuFind is under the GPL (version 2), so I can share my modifications.
- It’s easy to use as a stand-alone system. One just needs bibliographic records and minor modifications to the codebase to make it run without an ILS, allowing for easy experimentation.
- There seems to be a surge of local interest in central Illinois (where I work) about VuFind.
Getting VuFind
Currently, VuFind is hosted at SourceForge. VuFind 0.7, running on Kubuntu 7.10, was used while writing this article, although release 0.8 is due soon with some potential changes (VuFind is a young and active project, so details here may differ from the most current version). You can either download the files or check it out of svn (svn co https://vufind.svn.sourceforge.net/svnroot/vufind/releases/VuFind-0.7 vufind).
Setting Up VuFind.
You will want to follow the README file that comes with the VuFind distribution. See the wiki and check out the mailing lists if you have any issues.
Getting some records
For testing this system a small sample of around 2,000 records was used (catalog.xml). They were combined from two different searches using the YAZ Z39.50 client [1] and querying the z39.50 server at CARLI [2], an academic consortium in Illinois (see Appendix I for details of this process). Feel free to use the created catalog.xml file by placing it into the import directory. The file isn’t meant to be an exhaustive scientific test, just an exercise in seeing how we can treat authorities differently.
Now, if you’re following along, you should see how VuFind normally uses the headings. Take the catalog.xml file, put it in the import directory, and follow the VuFind import steps (see the README) and experiment with it. This will make sure you have the setup correct. However, the changes we are about to make will require re-indexing. The easiest way to do this again is to simply remove the existing indexes and records in Solr. To do so, run the following curl commands while VuFind.sh is running:
curl http://127.0.0.1:8080/solr/update \ --data-binary '<delete><query>[* TO *]</query></delete>' \ -H 'Content-type: text/xml; charset=utf-8' curl http://127.0.0.1:8080/solr/update \ --data-binary '<commit />' \ -H 'Content-type: text/xml; charset=utf-8'
Later, after modifying the index you will need to run “./vufind.sh restart” and re-run the import steps described in the README.
Modifying the index
To collocate all the records by a particular author, we’re going to take advantage of the system specified by AACR2 to allow people to distinguish headings.
A heading in a catalog record, when created according to the rules of AACR2 chapter 22 [3], should provide a unique string for a given author to be used in all the records for works by that author or about that author. Many libraries keep track of these headings by using authority files, one of the most frequently referred to being the Library of Congress Authorities.
The heading is derived mostly from the most well-known or commonly published form of an author’s name. Information is also added to make sure the heading of a new author does not duplicate an existing heading. In a MARC record these headings will be found in the main entry (100), used for the main author of a work; added entries (700), used to indicate people who contributed to a work but are not the main author; and subject added entries (600), used to indicate people the book is about. The MARC record splits the heading into several subfields, such as the personal name (subfield a), titles (c), and date (d) [4].
VuFind does index author information, but only a normalized version of the subfield a. It does not include the information used to distinguish between authors. When searching for authors we can search for authors that are Jackson, Michael or by just part of the author name, but we cannot get a particular author.
This is fine for user searches where people are likely to be searching using names. However, for internal purposes something that uses a more unique identifier is needed so we can do things like describe just a particular author or show works by just one person. Why not use the heading in the record which is already functioning as an identifier?
To change VuFind to use the full heading, it is useful to understand Solr, the index engine underlying VuFind. Queries are done by passing an HTTP GET request to the index engine. That returns information in a variety of ways about the search and the search results. Similarly, the index is constructed by uploading XML files consisting of name-value pairs via HTTP POST requests. An example might look like:
<add>
<doc>
<field name="id">1</field>
<field name="author">Johnson, James</field>
</doc>
</add>
The various fields Solr will index in these uploaded documents are specified in a file called schema.xml (located in VuFind at solr/conf/schema.xml). In order to allow the indexing engine to keep track of the full heading, we’ll add a line to the schema.xml file. Find the fields element and add the line:
<field name="authornaf" type="string" indexed="true" stored="true" />
Now if the uploaded record contains the field name “authornaf” it will be added to the index. The type “string” is used since the “string” type requires a search to be an exact match in order to return a method. So search for an authornaf value of aJACKSON,_MICHAEL would not return a record that had aJACKSON,_MICHAEL,d1942-. Currently, the “author” field uses “text”, which allows for partial matches in search. So searching for Jackson would return the record “Jackson, Michael,”.
Next we will modify the import process that reads in the catalog.xml file and creates the upload files for Solr. This process is driven by the import-solr.php script in import/. This script breaks each record element in the catalog.xml file into a string. Each of these strings has an XSLT transformation, marcxml2solr.xsl, applied to create Solr upload files. These files are then posted to Solr.
To do this, I’ve added a section to marcxml2solr.xsl:
<xsl:if test="//marc:datafield[@tag=100]/marc:subfield[@code='a']">
<field name="author">
<xsl:value-of select="//marc:datafield[@tag=100]/marc:subfield[@code='a']"/>
</field>
<field name="author-letter">
<xsl:value-of select="substring(//marc:datafield[@tag=100]/marc:subfield[@code='a'], 1, 1)"/>
</field>
</xsl:if>
<xsl:if test="//marc:datafield[@tag=110]/marc:subfield[@code='a']">
<field name="author2">
<xsl:value-of select="//marc:datafield[@tag=110]/marc:subfield[@code='a']"/>
</field>
</xsl:if>
modified code (added at about line 78)
<xsl:if test="//marc:datafield[@tag=100]/marc:subfield[@code='a']">
<field name="author">
<xsl:value-of select="//marc:datafield[@tag=100]/marc:subfield[@code='a']"/>
</field>
<field name="author-letter">
<xsl:value-of select="substring(//marc:datafield[@tag=100]/marc:subfield[@code='a'], 1, 1)"/>
</field>
</xsl:if>
<xsl:if test="//marc:datafield[@tag='100']">
<field name="authornaf">
<xsl:for-each select="//marc:datafield[@tag=100]/marc:subfield">
<xsl:value-of select="@code"/>
<xsl:value-of select="translate(normalize-space(.),'abcdefghijklmnopqrstuvwxyz ','ABCDEFGHIJKLMNOPQRSTUVWXYZ_')" />
</xsl:for-each>
</field>
</xsl:if>
<xsl:if test="//marc:datafield[@tag=110]/marc:subfield[@code='a']">
<field name="author2">
<xsl:value-of select="//marc:datafield[@tag=110]/marc:subfield[@code='a']"/>
</field>
</xsl:if>
The added code joins all the subfields of the 100 field, after first removing any spaces before and after each subfield and converting the text to upper-case. For example, if $aJackson, Michael, $d1942- appeared in the 100 field of a a record, there would be a field in Solr that would be searchable with the value aJACKSON,_MICHAEL,d1942-
If you’re following along, you’ll need to restart vufind.sh (./vufind.sh restart) and re-import (php import-solr.php) at this point.
The Author Home Page in VuFind
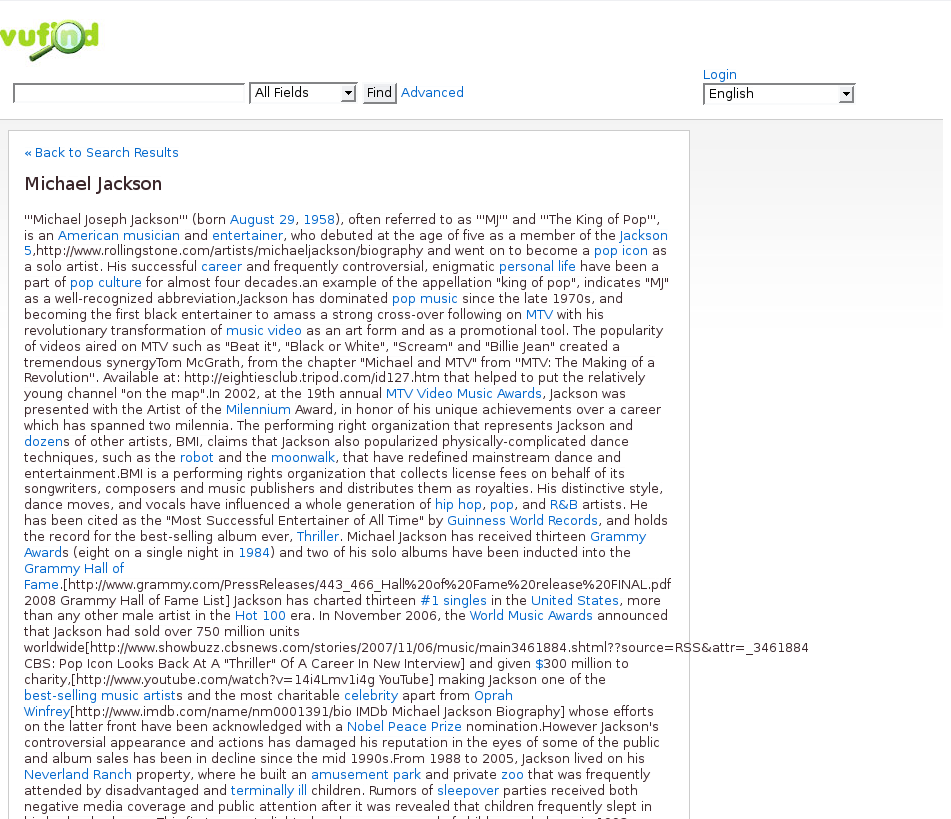
Now, in order to demonstrate how the the index can be used to improve an interface, I’ll focus on the Author page of VuFind, which provides information from Wikipedia about the author and a list of works by the author . Currently, a record or search results page will link to the Author page with a URL like http://example.com/Author/Home?author=Newman,%20Paul. The PHP page resides in web/services/Author/Home.php, and takes in just one GET parameter, author={processed subfield a}. For this information VuFind uses subfield a of the 100 field, with some slight normalizations. This author information is used in two ways within the page.
- To create a URL used to screen scrape a Wikipedia page providing information about the author.
$author = $_GET['author']; if (substr($author, strlen($author) - 1, 1) == ",") { $author = substr($author, 0, strlen($author) - 1); } $author = explode(',', $author); // some unrelated code ... $url = 'http://en.wikipedia.org/w/api.php?action=query&prop=revisions&rvprop=content&format=php&titles=' . urlencode("$author[1] $author[0]");You will notice it only uses the name, assuming it will find an entry in Wikipedia for this particular author at “first name last name”. So, for any heading that has the personal name “Jackson, Michael,” you will get the information for the pop star since his Wikipedia identifier is “Michael Jackson”.
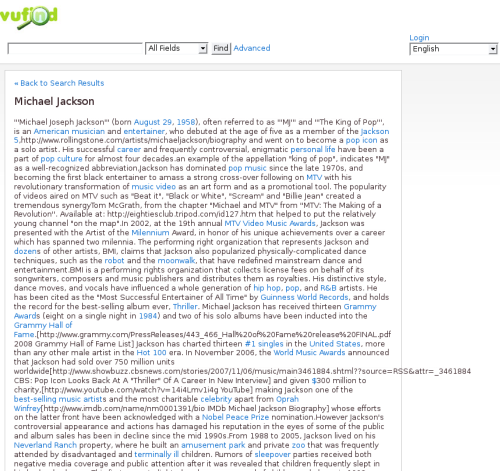 VuFind’s display of author information from Wikipedia
VuFind’s display of author information from Wikipedia - To make a Solr call to search for all books written by the author.
// Get records by this author $this->db = new SOLR($configArray['SOLR']['url']); $result = $this->db->query('author:"' . $_GET['author'] . '"', null, 0, 20); //does some things with the resulting arrays to display the resultsThis will collocate all books in the system written by authors with that name, even if they are different authors.
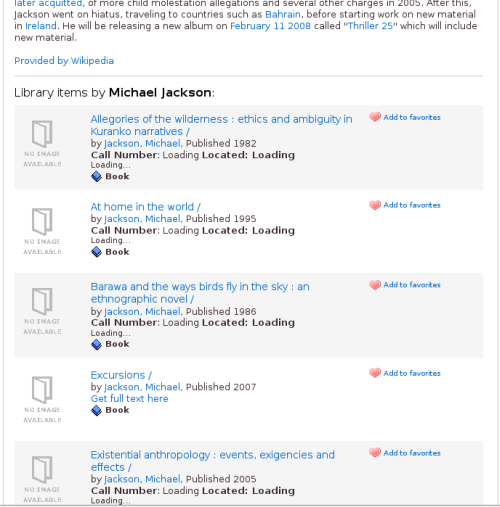 Results of an author search in VuFind
Results of an author search in VuFind
To improve both the Wikipedia search and the list of author works, we need Author/Home.php to use our indexed full heading, authornaf, so we can refer to a unique bibliographic identity. Later we will modify the Author page to use the authornaf field, but first we have to pass it in. In places where the old URL existed, it should now be formed to look like http://example.com/Author/Home?author=Newman,%20Paul&authornaf=aNEWMAN,_PAUL,d1921-.
For an example of how existing URLs in VuFind should be changed, we will look at the display of an individual record. VuFind uses the raw MARCXML file and transforms it for display, similar to how it transforms it for the Solr upload file. So in web/services/Record/xsl/record-html.xsl, I modified a section that creates the URL for the author in the record to also include the authornaf.
<xsl:template name="citation">
<table cellpadding="2" cellspacing="0" border="0" class="citation">
<xsl:if test="//datafield[@tag=100]">
<tr valign="top">
<th><xsl:value-of select="php:function('translate', 'Main Author')"/>: </th>
<td>
<a>
<xsl:attribute name="href"><xsl:value-of select="$path"/>/Author/Home?author=<xsl:value-of select="//datafield[@tag=100]/subfield[@code='a']"/></xsl:attribute>
<xsl:value-of select="//datafield[@tag=100]/subfield[@code='a']"/>
</a>
</td>
</tr>
</xsl:if>
<xsl:template name="citation">
<table cellpadding="2" cellspacing="0" border="0" class="citation">
<xsl:if test="//datafield[@tag=100]">
<tr valign="top">
<th><xsl:value-of select="php:function('translate', 'Main Author')"/>: </th>
<td>
<a>
<xsl:attribute name="href">
<xsl:value-of select="$path"/>
<xsl:text>/Author/Home?authornaf=</xsl:text>
<xsl:for-each select="//datafield[@tag=100]/subfield">
<xsl:value-of select="@code"/>
<xsl:value-of select="translate(normalize-space(.),'abcdefghijklmnopqrstuvwxyz ','ABCDEFGHIJKLMNOPQRSTUVWXYZ_')" />
</xsl:for-each>
<xsl:text>&author=</xsl:text>
<xsl:value-of select="//datafield[@tag=100]/subfield[@code='a']"/>
</xsl:attribute>
<xsl:value-of select="//datafield[@tag=100]/subfield[@code='a']"/>
</a>
</td>
</tr>
</xsl:if>
Modifying Wikipedia Search
We can now use the authornaf field to enhance the Wikipedia search . We’ll do this using the following algorithm:
- Use the
authornafto retreive thetitlefield stored in Solr for all records that contain thatauthornaf. - Find the two most common words in these titles after a simple stop list is used to eliminate common words like “the”,”of”, etc.
- Create a Wikipedia search URL and use it to query Wikipedia.
- Extract the search results from the HTML page returned by Wikipedia
- Iterate through results in relevancy ordering until a URL is found that has all the parts of the name
- Use this URL to retrieve the page and extract the first section. We’re assuming this page is about the author.
This algorithm seems to work for many cases, but some further experimentation could involve:
- Looking for a disambiguation page
- Not counting parts of the first name as heavily
- Using subject headings as search words
- Using a local index of Wikipedia or a local DBpedia for more complex searches
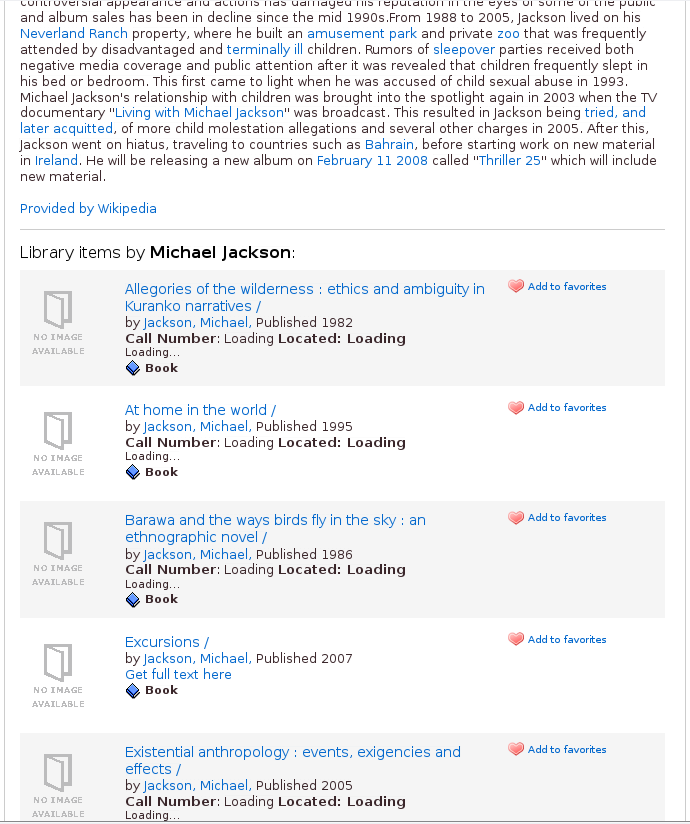
Doing this means we no longer get information about the King of Pop everytime we search Wikipedia; rather, we get information more suited to the individual or no information at all.
 Improved results from Wikipedia
Improved results from WikipediaNote: The relevant code for this can be found in Appendix II.
Modify the list of works by an author
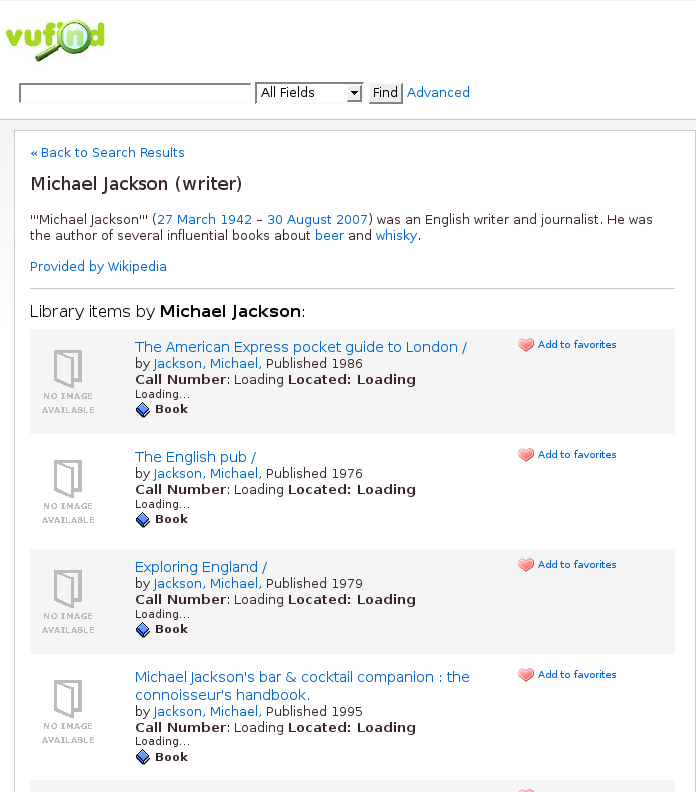
Now, let’s focus on the second part of the Author page, the list of all the author’s works. In this case, instead of doing a Solr query that will get us records that have the same 100 subfield a, we’ll do a query that finds all records with the same normalized 100. So instead of looking for all works that have Jackson, Michael we will find all the bibliographic records that have a normalized 100 that looks like aJACKSON,_MICHAEL,d1942-. The result will be a list of just the works by the well-known beer and whiskey critic Michael Jackson.
 Results of an
Results of an authornaf searchTo accomplish this, we modify line 152 in web/services/Author/Home.php from
$result = $this->db->query('author:"' . $_GET['author'] . '"', null, 0, 20);
to
$result = $this->db->query('authornaf:"' . $_GET['authornaf'] . '"', null, 0, 20);
Note: All of the changes from this article can be implemented with a patch file [5].
Issues
Authority Complexity
A flaw in the use of the heading to collocate author works is that it makes the assumption that a person’s entire works will be represented by a particular heading. This assumption is fundamentally flawed. In certain cases there will be multiple headings for one person, as when an author writes under a pseudonym or a changed name, or writes as a government officer. Since we do not examine the authority records, each of these headings will be treated in our modified VuFind as if it is for a different author.
Take, for example, Bill Clinton, the 42nd President of the United States. He has one authorized heading as “Clinton, Bill, 1946-“, but he also has writings as:
- Arkansas. Governor (1979-1981 : Clinton)
- Arkansas. Governor (1983-1992 : Clinton)
- United States. President (1993-2001 : Clinton)
Ideally, there would be some way to find all the writings of an individual but still be able to distinguish between writings done by separate “bibliographic identities”. This would require a much higher level of processing, including use of the authority records.
The lack of descriptions regarding the nature of a connection between two authority headings is also problematic. US practice does not give enough information to identify the relationship between two authority records. If this information existed in a machine-readable form it would be possible to display, for example:
Material by Stephen King writing under pseudonym Richard Bachman
or
Works created as President by George W. Bush
Lack of Authority Control.
One of the largest stumbling blocks to implementing this system is the simple fact that not all libraries practice authority control. It appears a large majority of academic libraries do use some name authority control. According to a survey of libraries with a Carnegie Classification of either Doctoral/Research Extensive or Intensive level, 95% of those who responded (75%) do some form of authority control. For in-house work, 88% of new and maintence cataloging had the personal name headings verified. For vendor work 95% of new cataloging involved verifying personal name headings and 90% of maintence work verified personal name headings [6].
However, that leaves many libraries that do not practice any authority control. In fact, some may even practice a mixture by keeping the headings on records they import from external systems such as OCLC but not adding any to their internal records. This would prevent the association of some books with their authors. In these cases, grouping all the records by authors with the same name may be the only solution.
Possible future directions:
Don’t use all the subfields
The modification given in this paper is a simple algorithm that uses all the subfields of the 100 field of the bibliographic MARC record. In the future, it would make sense to restrict the fields indexed to subfields a, b, c, d, q, and u.
Use added entry as well as main entry
In the future, treat added entries and headings used as subjects in a similar way. This might allow for some more sophisticated interfaces.
User Testing
Far more user testing is needed, looking at when people look for items by particular authors and what can help them get appropriate results. With this technique we can take some different approaches than those currently offered by many next-generation catalogs.
System Testing
What impact does having more unique headings have on the performance of large production systems? Perhaps previous next-generation catalog developers have purposely avoided using the full heading for this reason.
Facets
There is a need to try to improve the faceting of results. Right now the interface will “group” all the authors with the same normalized subfield a together. However, this makes this particular facet useless when people are searching for books by an author’s name. If one clicks on a link in a record, they’ll just see the exact same search they performed.
The identifier information could be used to populate the facet display with unique authors, even if they have the same subfield a. Distinguished information could be added such as titles of works created by the individual or common subject headings assigned to the person.
Authority Files
Briefly mentioned earlier, incorporating the authority files into a separate index could allow for interesting possibilities, such as multiple levels of searching by author (i.e., all works or just works written under a particular pseudonym).
Better Linking to External Projects
If we can identify a person and the works they created, we can use that information to try to connect with other sources of information. We already link to Wikipedia; we could also link to similar projects.
Static Dumps of External Projects
Wikipedia can be downloaded as a static file and re-indexed to focus more on information boxes, persons, and works. DBpedia and similar projects also offer RDF tags and a chance to search Wikipedia information.
Using static dumps when possible allows for more intensive automated searching. For example, there are several works by Michael Jackson, an anthropologist in my current collection. The algorithm of using the most popular two words fails in this case. Few of the words in his titles overlap and the highest ranking words do not appear in the Wikipedia article. Having a local source would reduce concerns of over-use and abuse of Wikipedia bandwidth and other resources, allowing experimentation with different algorithms to find the most appropriate article.
Conclusion
We have room for improvement in the next generation of catalogs. It may be that there are some cataloging pratices that could be changed to make automation easier, but there are also existing techniques that developers are not using to their full potential. The new generation of open systems brings new opportunities for experimentation. This does not have to be complex or intimidating; by changing just a few lines of code, we can create lists of the works of individual authors and improve the retrieval of author information from Wikipedia. Go experiment, and make our catalog interfaces better than they have ever been.
Notes
- This was run with the YAZ-client version 2.1.18, from the Ubuntu package. YAZ-client is a client that is included with the YAZ library
- Consortium of Academic and Research Libraries in Illinois. For information on connecting to the Z39.50 server hosted by CARLI, read “I-Share via Z39.50“. I-Share is a catalog that contains all the records of most of the CARLI members.
- Anglo-American Cataloguing Rules. Second Edition. Revision 2002. American Library Association, Chicago; 2002. (COinS)
- For more information about the details of these MARC fields, see the Library of Congress Bibliographic Data pages, in particular Main Entry — Personal Name, Added Entry — Personal Name, and Subject Added Entry — Personal Name. Or, see the OCLC Bibliographic Formats and Standards.
- Apply the patch file to recreate the modifications to VuFind described in this article.
- Wolverton, Robert E., Jr. Authority Control in Academic Libraries in the United States: A Survey. Cataloging & Classification Quarterly. 41 (1), 2005. p 111-131. (COinS)
Appendix I – Getting Records Using YAZ-client
First, I issue the command to log into the I-Share z39.50 server and start creating an outputfile. ($ indicates command line prompt). Any records that I “show” during the session will also be recorded into the output file.
$ yaz-client -u I-SHARE auth.carli.illinois.edu:210/voyager -m somefile.marc
If I wanted to narrow it just to a particular institution, I could use a different user name. For example, to search just Urbana-Champaign.
$ yaz-client -u UIU auth.carli.illinois.edu:210/voyager -m somefile.marc
I actually searched I-Share for records with Michael and Jackson in the author fields, but only searched Urbana-Champaign for the graphic novels. It should be noted that results from running YAZ-client are always appended to the filename given with the -m flag (somefile.marc in the example). It is not overwritten. This means you can build up a file from several different institutions and sessions.
You will get a response that contains some information about the server and then another command prompt (Z>). Now you can do some searches and retrieve records. The search should return the number of hits, which you can then “show 1+number of hits” to retrieve. One word of warning, for larger return sets you may wish to do them in batches by doing “show 1+500; show 501+500” and so on. Otherwise you risk timing out with busy servers.
Getting records by people named Michael Jackson
Z> find @and @attr 1=1003 Jackson @attr 1=1003 Michael Sent searchRequest. Received SearchResponse. Search was a success. Number of hits: 483 records returned: 0 Elapsed: 3.119026 Z> show 1+483
Getting records that might be comic books/graphic novels/comic strip collections
Z> find @and @attr 1=21 "Comic Books" @attr 1=21 strips Sent searchRequest. Received SearchResponse. Search was a success. Number of hits: 5605 records returned: 0 Elapsed: 4.772098 Z> show 1+500 ... lots of files go zipping by Z> show 501+500 ... lots of files go zipping by Z> show 1001+500 ... lots of files go zipping by Z> close Z> exit
Finally, you will need the MARC records to be in MARCXML. Another YAZ tool can help here.
yaz-marcdump -X somefile.marc > catalog.xml
Appendix II – Modified Wikipedia Code for Retrieving Author Information
The instructions below apply to web/services/Author/Home.php (see the original code):
Add the following function at line 29 (before the launch function):
/*
Return: array consisting of word => number of times words appears
Input: $string - the string to analize
$words - an array consisting of word => number of times words appear
if there are existing values, they will be added to.
This means you can pass in a series of strings and
get the overall totals
*/
function countWords($string,$words) {
foreach(explode(' ',$string) as $word) {
//print("$word <br />");
$word = strtolower($word);
$word = str_replace(array(':',
';',
',',
"\'",
'"',
'(',
')',
'|',
'/',
'?',
'!',
'@',
'#',
'$',
'%',
'^',
'&',
'*',
"\\",
'.',
'+',
'=',
'_',
'~',
'`',
'"'),
'',
$word);
/* - not removed/kept out because hypens might be important probably could just focus on beginning and end of strings */
/* simple stop list */
if($word != '' &&
$word != 'the' &&
$word != 'a' &&
$word != 's' &&
$word != 'of' &&
$word != 'on' &&
$word != 'in' &&
$word != 'an' &&
$word != 'if' &&
$word != 'to' &&
$word != 'and') {
$words[$word]++;
}
}
return($words);
}
Then replace lines 113-209 (after adding the above function):
Original code
// Clean up author string
$author = $_GET['author'];
if (substr($author, strlen($author) - 1, 1) == ",") {
$author = substr($author, 0, strlen($author) - 1);
}
$author = explode(',', $author);
$interface->assign('author', $author);
// Connect To Wikipedia
if (!isset($_GET['page']) || ($_GET['page'] == 1)) {
$url = 'http://en.wikipedia.org/w/api.php?action=query&prop=revisions&rvprop=content&format=php&titles=' . urlencode("$author[1] $author[0]");
$client = new HTTP_Request();
$client->setMethod(HTTP_REQUEST_METHOD_GET);
$client->setURL($url);
$result = $client->sendRequest();
if (!PEAR::isError($result)) {
$body = unserialize($client->getResponseBody());
//Check if data exists or not
if(!$body['query']['pages']['-1']) {
$body = array_shift($body['query']['pages']);
$info['name'] = $body['title'];
$body = array_shift($body['revisions']);
$body = explode("\n", $body['*']);
$done = 0;
while(!$done) {
if($body[0] == '') {
array_shift($body);
continue;
}
switch(substr($body[0], 0, 2)){
case "[[" :
case "{{" :
case "}}" :
case "]]" :
case "| " :
//echo " sub : '" . substr($body[0], 0, 2) . "' ";
$stpos = stripos($body[0], "image:");
if(!$stpos)
$stpos = stripos($body[0], "image");
if($stpos) {
$len = 4;
$endpos = stripos($body[0], ".jpg");
if(!$endpos) {
$len = 4;
$endpos = stripos($body[0], ".gif");
}
if($endpos) {
$image = substr($body[0], $stpos,
$endpos + $len - $stpos);
}
}
array_shift($body);
break;
default :
$done = 1;
break;
}
}
$desc = "";
$done = 0;
while(!$done) {
if(substr($body[0], 0, 2) == "==")
$done = 1;
else {
$desc .= $body[0];
array_shift($body);
}
}
//Create links to wikipedia
$pattern = array();
$replacement = array();
$pattern[] = '/(\x5b\x5b)([^\x5d|]*)(\x5d\x5d)/';
$replacement[] = '<a href="http://en.wikipedia.org/wiki/$2">$2</a>';
$pattern[] = '/(\x5b\x5b)([^\x5d]*)\x7c([^\x5d]*)(\x5d\x5d)/';
$replacement[] = '<a href="http://en.wikipedia.org/wiki/$2">$3</a>';
// Removes citation
$pattern[] = '/({{)[^}]*(}})/';
$replacement[] = "";
$desc = preg_replace($pattern, $replacement, $desc);
$info['image'] = $image;
$info['description'] = $desc;
$interface->assign('info', $info);
}
}
}
}
Modified code
// Clean up author string
$author = $_GET['author'];
if (substr($author, strlen($author) - 1, 1) == ",") {
$author = substr($author, 0, strlen($author) - 1);
}
$author = explode(',', $author);
$interface->assign('author', $author);
$authornaf = $_GET['authornaf'];
//We'll now search to see if we can find
//a wikipedia article that seems associated with the
//author by using common title words
// Connect To Wikipedia
if (!isset($_GET['page']) || ($_GET['page'] == 1)) {
// Get records by this author
$this->db = new SOLR($configArray['SOLR']['url']);
$result = $this->db->query('authornaf:"' . $_GET['authornaf'] . '"', null, 0, 20);
/* The result will have some information about
the SOLR query and also information about
each record. Issue is this is an array of arrays,
unless there's only one result, then it's just
an array with values */
if (is_array($result['record'][0])) {
$records = $result['record'];
}
else if (is_array($result['record'])){
$records = array($result['record']);
}
$titles = array();
$words = array();
for($i = 0;$i < count($records);$i++) {
$words = $this->countWords($records[$i]['title'],$words);
}
asort($words);
/* now the words should be sorted from most frequent to least */
$words = array_keys($words);
/* now we search for the author words (from
earlier processing) and the two most common
words. Why? Some rouging testing seem to
indicate this was a good number. */
$url = "http://en.wikipedia.org/w/index.php?title=Special:Search&search=" . urlencode("$author[1] $author[0] " .array_pop($words) . " ". array_pop($words) );
//Now we examine the results.
$client = new HTTP_Request();
$client->setMethod(HTTP_REQUEST_METHOD_GET);
$client->setURL($url);
$result = $client->sendRequest();
if (!PEAR::isError($result)) {
$xmlstring = $client->getResponseBody();
}
else {
print("<html><head><title>Error</title></head><body>error</body></html>");
}
//need to suppress warnings
//errors about id
$xmldoc = new DOMDocument();
//see http://www.mutinydesign.co.uk/scripts/problems-encountered-with-php-dom-functions---3/ on suppressing warnings -> bad html
@$xmldoc->loadHTML($xmlstring);
$docXpath = new DOMXPath($xmldoc);
//for some reason I haven't quite yet figured out,
//registering the namespace isn't working,
//the dom class seems to ignore it in the source
//document
$query = '/html/body/div[@id="globalWrapper"]/div[@id="column-content"]/div[@id="content"]/div[@id="bodyContent"]/ul[1]/li/a';
$links = $docXpath->query($query);
$goodlink = '';
//Now, I'll iterate through the results
//I'm looking for the first result that
//has all the parts of the author name in it
//
//This could definitely be improved
foreach($links as $link) {
$firstname = $author[1];
$firstname = str_replace(array('.',','),'',$firstname);
$firstname = trim($firstname);
$lastname = $author[0];
$lastname = str_replace(array('.',','),'',$lastname);
$lastname = trim($lastname);
if (stripos($link->nodeValue,$firstname) > -1 &&
stripos($link->nodeValue,$lastname) > -1)
{
//print("good link <br />");
$goodlink = $link->attributes->getNamedItem('href')->nodeValue;
break;
}
}
$title = substr($goodlink,6);
$interface->assign('info', $info);
$url = 'http://en.wikipedia.org/w/api.php?action=query&prop=revisions&rvprop=content&format=php&titles=' . $title;
//if we found something, display the wikipedia info
//(in final version we'd want to have something displayed
// if there wasn't a match or a more strict
if ($goodlink != '') {
$client = new HTTP_Request();
$client->setMethod(HTTP_REQUEST_METHOD_GET);
$client->setURL($url);
$result = $client->sendRequest();
if (!PEAR::isError($result)) {
$body = unserialize($client->getResponseBody());
//Check if data exists or not
if(!$body['query']['pages']['-1']) {
$body = array_shift($body['query']['pages']);
$info['name'] = $body['title'];
$body = array_shift($body['revisions']);
$body = explode("\n", $body['*']);
$done = 0;
while(!$done) {
if($body[0] == '') {
array_shift($body);
continue;
}
switch(substr($body[0], 0, 2)){
case "[[" :
case "{{" :
case "}}" :
case "]]" :
case "| " :
//echo " sub : '" . substr($body[0], 0, 2) . "' ";
$stpos = stripos($body[0], "image:");
if(!$stpos)
$stpos = stripos($body[0], "image");
if($stpos) {
$len = 4;
$endpos = stripos($body[0], ".jpg");
if(!$endpos) {
$len = 4;
$endpos = stripos($body[0], ".gif");
}
if($endpos) {
$image = substr($body[0], $stpos,
$endpos + $len - $stpos);
}
}
array_shift($body);
break;
default :
$done = 1;
break;
}
}
$desc = "";
$done = 0;
while(!$done) {
if(substr($body[0], 0, 2) == "==")
$done = 1;
else {
$desc .= $body[0];
array_shift($body);
}
}
//Create links to wikipedia
$pattern = array();
$replacement = array();
$pattern[] = '/(\x5b\x5b)([^\x5d|]*)(\x5d\x5d)/';
$replacement[] = '<a href="http://en.wikipedia.org/wiki/$2">$2</a>';
$pattern[] = '/(\x5b\x5b)([^\x5d]*)\x7c([^\x5d]*)(\x5d\x5d)/';
$replacement[] = '<a href="http://en.wikipedia.org/wiki/$2">$3</a>';
// Removes citation
$pattern[] = '/({{)[^}]*(}})/';
$replacement[] = "";
$desc = preg_replace($pattern, $replacement, $desc);
$info['image'] = $image;
$info['description'] = $desc;
$interface->assign('info', $info);
}
}
}
}
}
(Final modified code for web/services/Author/Home.php)
About the Author
Jonathan Gorman spends his days shifting bits and bytes through the Voyager system, among several other duties, as a Research Information Specialist for the University of Illinois. His nights are spent playing around with library technologies in hopes of constructing tools he would actually enjoy using. Jonathan is grateful for the love and support of his wife, Colleen; this article would not have been possible without her. He can be contacted at jonathan.gorman at gmail dot com.

Daniel Lovins, 2008-04-21
This article addresses a concern we’ve been discussing at Yale for several weeks. Thanks so much for sharing the results of your investigations.
Jonathan Gorman, 2008-04-21
Hi Daniel,
Glad my article was of some help. In case you check back, do you mind giving a summary of the concern you have at Yale? You made me curious.