By Keith Kelley, Karlis Kaugars and Scott Garrison
Introduction and Background
University library systems departments often face support-intensive periods, such as when multiple campus and/or library systems change at once. Changes in one area can break other functions, forcing staff who are already busy to stop and resolve user-reported emergencies. These emergencies can be unpredictable, make staff all the more difficult to find, and slow helpdesk response. The ability for individual staff to find the right person to quickly respond to emergency calls can be critical to maintaining operations and quality of service, as well as easing the strain on both the department’s capacity and the staff members themselves.
How to track staff is a key issue. Dry erase, magnetic and electronic in/out boards that rely on memory, predictable staff movement patterns, and/or direct user input are not well suited to the dynamic nature of desk side support and emergency calls. Hardware solutions that require staff to carry additional devices to communicate via what can be an expensive hardware infrastructure may be unsuitable for staff tracking at a university such as WMU, which has a multimillion-square foot campus including multiple branch libraries and campuses. These solutions are not affordable for most libraries. An automated employee tracking system that detects where people are even when they have been unable to record that information is a better approach.
Many libraries such as WMU already pay for staff smartphones and it is in a library’s business interest to maximize return on smartphone investment. As of 2011, increasing numbers of students, including those who work in library systems, carry personally owned smartphones connected to campus Wi-Fi. Though smartphones’ telephone function may not work well indoors, a smartphone can be location-aware anywhere with a wireless network. An indoor positioning system (IPS) on Android with a LAMP backend is inexpensive, relatively easy to develop and deploy, and works within complex, unfamiliar and uncontrolled environments by making use of an existing Wi-Fi infrastructure with no modifications. Some have developed location systems accurate to within ten meters, which may be sufficient for a mobile in/out board.
It might seem logical to use a smartphone’s combination of built-in location services and social applications to meet helpdesk needs. Social apps such as Facebook Places, Foursquare and Google Latitude can locate smartphones, but tend to offer only public building-level accuracy. GPS-based apps may be accurate to six meters, but do not work well inside most buildings. Cellular provider network localization works indoors, but is only accurate to between 100 feet and 1000 meters. Wi-Fi signal strength, however, is primarily available indoors and can be used to estimate location within a range of a few meters. Since even Redpin, an open source indoor localization system requiring user input, would still require significant customization to use as a mobile in/out board, WMU decided to write its own system. The system consists of an Android IPS app and LAMP backend that use Wi-Fi fingerprinting and a location determination algorithm to display where smartphone-carrying staff members are within WMU. Staff and students alike use a common IPS app to locate one another. Those lacking permanently issued or owned Android phones can use the app on Library-owned used phones, in Wi-Fi only mode.
About the System
WMU Libraries’ mobile in/out board system is effectively an IPS that uses symbolic natural language locations such as rooms, floors, and buildings, rather than absolute, relative or physical locations based on coordinates. While originally developed as a self-positioning system, the current production system may be classified as an indirect remote positioning system. The system sends a received signal strength (RSS) measurement sample gathered by a mobile device to a remote localization server that computes the device’s location based on a Wi-Fi fingerprint, or a map of wireless access points (APs) in a given location. WMU’s system uses Wi-Fi fingerprinting because it is simpler, more accurate, and more reliable than other wireless indoor positioning methods (Jekabsons and Zuravlyov 2010; Ali 2011; Navarro, Peuker, Quan 2010). The system is participatory, in that the users themselves define the fingerprints in the AP map by detecting them through the mobile app.
The Argument for Wi-Fi Fingerprinting
Wi-Fi localization maps signal strength to location. The closer a mobile device is to a Wi-Fi AP, the stronger the signal generally is, but there are many factors that influence signal strength. In a perfect world, with no interference, a clear line of sight, a vacuum, and geographic location coordinates (such as latitude and longitude) for every AP, a mobile device could use simple geometry to calculate exactly where it is. This describes one class of methods for wireless indoor positioning known as triangulation (also known as trilateration). Triangulation does not work well in places like libraries, which contain books in stacks, moving people, and other signal absorbing, reflecting, and interfering artifacts.
Wi-Fi fingerprinting is a two-stage method of wireless indoor positioning. First, a training/collection (also known as offline or calibration) stage builds a radio map, or fingerprint database of all wireless APs in a given area. Second, a positioning/tracking (also known as live or online) stage measures signals and estimates a wireless device’s location by matching the measured signal to the fingerprint. Though not perfectly reliable, as AP antenna signal strength is random within a certain range, Wi-Fi fingerprinting is the primary method of wireless indoor positioning.
There are many choices to make when implementing a Wi-Fi fingerprinting solution. After having experimented with several available algorithms, including Nearest Neighbor in Signal Space (NNSS; for a detailed explanation of how NNSS works, including considerations of Euclidian distance versus Manhattan distance, see Bahl and Padmanabhan 1999, 2002, and Li et al. 2005) the authors wrote a homegrown location estimation algorithm for this system.[1] Given that WMU’s system uses room-level location that is not as precise as some applications require, it uses an average signal strength in a simple deterministic Wi-Fi fingerprinting with no filtering (Honkavirta et al. 2009).
Building the System
This system is built on the popular and open LAMP and Android platforms. Though the same functionality may be achieved and the app distributed on an iPhone, private APIs would be required, which Apple neither encourages nor supports.
Prerequisites:
- an IP-accessible server to use as a localization server and output method
- Android devices (not necessarily with a service plan) carried by every participating person
- a campus with nearly universal Wi-Fi coverage
Software components:
- a LAMP/MAMP/WAMP server
- a custom Android app
- custom PHP scripts
Hardware components (optional):
- a wall-mounted computer monitor for shared location viewing
Tools required:
- a text editor or other tool for server side development
- the Java Development Kit
- the Android SDK
- the Eclipse development environment
MySQL tables:
Only three tables are strictly necessary for a simple implementation. Two others are optional (see Figure 1).
- employee – the table of users for display on the in/out board
- location – the table of symbolic location names
- signal – the table of individual AP antenna address (BSSID) and received signal strength (RSS)[2] measurement pairs
- (optional) scan – though Kaemarungsi and Krishnamurthy (2004) indicate it should be unnecessary, WMU Libraries recommends keeping the signals from one scan together, in case it is desired for future analysis, or it is necessary to delete erroneous contributed scans or a location determination algorithm chosen in the future requires it
- (optional) logentry – allows users to see the last several places someone visited
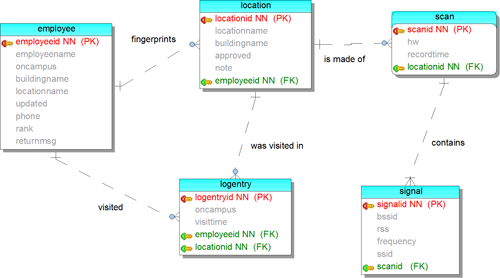
Figure 1. In/out database entity relationship diagram
PHP files
Only four scripts are necessary for a simple implementation.
- recognize.php – given the input of a measured scan or set of scans (sent as a POST request from a mobile device on a periodic basis), this script compares the observed set to the sets in the radio map, returns a symbolic location, and updates the employee table with that location
- name.php – the tracking/collection process associates a location name with a certain Wi-Fi fingerprint. The same script can be used to initially create the location and to add to the location definition if it is determined to be not well enough defined. In either case, this script is called by user interaction on the phone.
- board.php – a Web page that displays the contents of the employee table either to a wall-mounted monitor or department members’ PCs or their own phones so they can find each other in the field
- selectall.php – for the “correct” button, to provide the entire list of defined locations, containing the location name by which the current observed set of signals should have been recognized
How the System Works
Training/collection stage
The training/collection stage builds the radio map. A radio map is not a graphical map or floor plan, but a database of locations mapped to signal strengths. The primary method for building a radio map is recording samples of signal strengths at known locations (known as training points). WMU chose to use a participatory approach where users contribute their own fingerprints for the locations they visit, which both removes the initial training/collection burden normally associated with building a radio map and minimizes the database size to only the location definitions used.
Before users can use the system, they need to define at least one fingerprint (see Figure 2). The mobile app has one button that assigns a name to a single scan result set, or fingerprint, and a second that adds several scan results to that named fingerprint. In locations with less overlapping Wi-Fi coverage, a single scan may suffice. In more central locations with greater overlap, it is better to submit multiple scans in order to build up the fingerprint definition and differentiate the location from its neighbors. If there are several close locations, all of the fingerprints nearby need to be well defined through multiple button presses. A location with a single fingerprint as its definition may yield many false positive identifications (depending on the algorithm), while the user is actually elsewhere.
The training/collection stage is not really a distinct stage in a participatory approach, because the users contribute the fingerprint definitions in many small instances (even while actively trying to identify their current location). However, it is useful to think of this stage distinctly, partly because each location must be defined before it can participate in a positioning/tracking stage (this approach also helps readers of the literature better understand IPS principles). It can be useful to have a lightweight distinct training/collection stage where an assigned user defines a few fingerprints at commonly visited locations, while still allowing other users to populate the rest of the fingerprint database later. In other words, the database must contain some common locations before the system can track locations. More location scans over time iteratively refine locations, for greater system reliability.
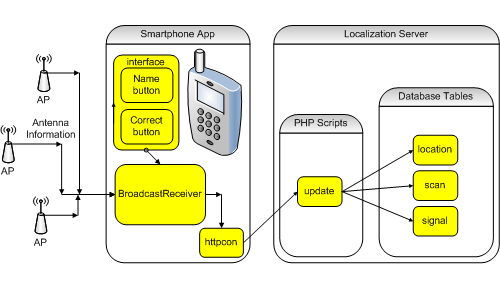
Figure 2. Defining a Fingerprint
Positioning/tracking stage
During the positioning/tracking stage, the phone app periodically measures and sends observed Wi-Fi antenna RSS values to a script on the LAMP server, which runs a location determination algorithm such as NNSS. The app does not process the data, but sends measured scan results which the localization server either uses individually or averages together, to algorithmically determine the smartphone’s location (see Figure 3).
Once the server determines location, the script checks the system’s database for any associated building name override, which has been set by a server administrator. If an override does not exist, the script identifies the building by looking up the strongest AP antenna in the signal table (lookup failure returns a value of “Unknown”). During processing, the localization server also compares each AP’s network name (SSID) to the campus SSID, determining whether the mobile device is “on campus.”
Having been given the employee’s name, return message, and a set of scan results, the localization server calculates the location name, building name, and on campus status. The server updates the employee table with these data and the current time. Once the employee table is updated, the calculated values are returned to the mobile app and board.php for display purposes.
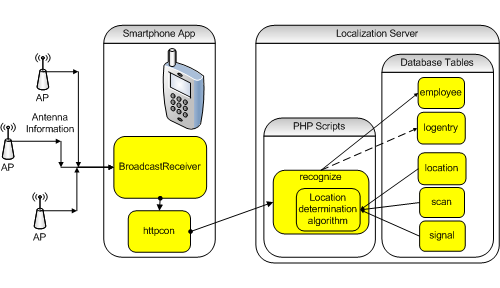
Figure 3. Determining a Location
The phone app
A locally developed Android app such as this may be deployed to any compatible phone, either through the Eclipse development environment (with the correct drivers) or by downloading it from a Web page (though some carriers prevent this). None of the app’s functionality requires rooting or jailbreaking the phone, so users do not risk losing carrier support or updates. The only real requirement is to compile the app with support for the SDK level matching the oldest participating phone and to have “USB debugging” or “Unknown Sources” options enabled on each phone.
In order for the app to be most effective:
- it must launch on boot and not be killed by any task killer
- personnel must carry their phones at all times
- the LAMP server must be available to the phones at all times, through either local Wi-Fi or a data plan if the phone has one
- the Wi-Fi antenna on each phone must be active at all times, which may be done programmatically
- each user must have a distinct username in the employee table and that username must be set in each phone’s app settings
Mobile app components
The following are the main components of the system’s Android app.
- Main user interface – It is necessary to have a simple interface to populate the fingerprint database and set simple preferences, such as username. This also starts an “alarm” that triggers the periodic actions. On Android, this class extends Activity and is the main entry point for the app.
- Name button – takes user-selected or user-entered input for a location name and associates it with one or more of the most recent previous scan results. If future apps ever use a location determination algorithm that calculates standard deviation, it is best to have at least two scans per definition.
- Confirm button – adds most recent previous scan results to refine the current location’s fingerprint definition (i.e. if the location has been correctly identified)
- Correct button – adds most recent previous scan results to a chosen location’s fingerprint if it has previously been incorrectly identified (i.e. from the server’s list of all defined locations; see Figure 4)
- Menu->Settings – allows the user to set values such as user name, location recognition frequency, return message, and match threshold (i.e. a composite percentage of all of the different perceived antennae together) at which a fingerprint is no longer considered as matching according to WMU’s specific algorithm (which strives for greater accuracy than NNSS; the authors prefer a location of “unknown” to one defined by weak AP RSS detected from nearby)
Figure 4. Correct button fed by selectall.php
- autostart – In order to be most useful, the app must start on boot. A class that extends BroadcastReceiver with an onReceive method that calls startActivity to launch the main interface accomplishes this (if properly registered and has permission for RECEIVE_BOOT_COMPLETED in the Android manifest file).
- alarmreceiver – Another BroadcastReceiver, this receives the alarms at regular intervals, does one or more Wi-Fi scans over a period of as many seconds, receives the scan results, and uses the httpcon class to send that information to the localization server. A single BroadcastReceiver on an alarm proved to be the most reliable and energy-efficient timing method. When the phone is asleep, the alarm wakes up enough to create the receiver, which does its task and destroys itself.
- httpcon – As there is no remote database support on Android, it is common to use an http layer to transfer data from the app to the server as this system does. The httpcon class in this object uses JSON objects and HTTP POST to transfer information between Android Java and the PHP on the localization server in the place of remote database connectivity APIs.
Data presentation
As stated above, board.php displays current employee locations both on phones running the app and in a Web browser. WMU Libraries Systems removed a dry erase in/out board near their office entrance and mounted a computer monitor on the wall in its place to display employee locations. The monitor continuously displays a full screen Web browser using an add-on to automatically refresh location information from the LAMP server (see Figure 5).
The system’s Web output is styled after the layout of the board that the wall-mounted monitor replaced. The name column contains the username of each participating cell phone owner (as entered into the app and database). Below the name is the user’s cell phone number, entered into the database by the system administrator (i.e. not from the phone, as the user may be using a device without cellular phone service). The second column contains a color-coded circle indicating whether the user was last seen on or off campus (green for on, or red for off) and whether they checked in during the last fifteen minutes (light for yes, or dark for no). The third column contains the name of the building, either from an added column in the location table or simply based on the strongest antenna observed during the training/collection stage. The fourth column, labeled department, contains the user-entered location name (e.g. a department, a room, a desk, or anything else). The fifth column contains a free form text message set by the user, often containing an intended return time or the name of the meeting after which they will be returning. The last column contains a timestamp so that the reader can tell how current the information is, with particularly old information displayed in gray text.
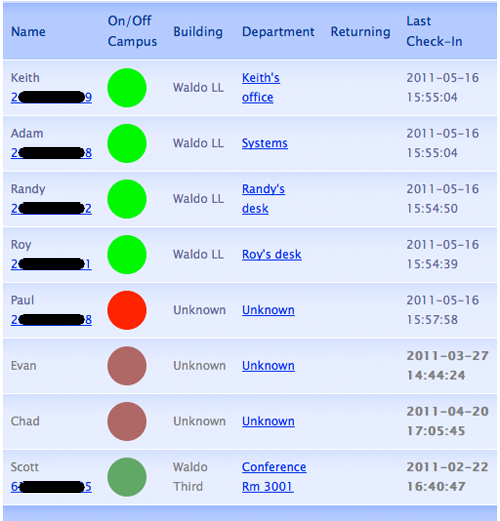
Figure 5. In/out board web display
Please see the appendix for a list of detailed technical considerations (in the form of questions and answers) the authors recommend to others wishing to implement a system like WMU Libraries’ mobile in/out board.
Lessons Learned
As stated above, how a Wi-Fi fingerprinting application functions depends heavily on the location determination algorithm it uses, and the local environment. Readers should refer to the growing body of Wi-Fi fingerprinting application literature when considering which algorithm to use or adapt. Given WMU’s specific requirements, the authors wrote their own algorithm using Manhattan distance.
In general, users have found the system easy to use, and far preferable to and much more accurate than the previous physical in/out board. One user-suggested modification that has been implemented is to log a user’s last several locations, so that staff may identify and discount the occasional false locations that are recorded. The authors are also considering displaying the past several recently recorded locations through board.php to help those seeking a particular user. However, leaving aside the question of how best to do this, recent locations may not always be useful, because the app allows varying device check-in frequency (ranging from manual and only periodic, to automatically, every twenty to sixty seconds). A typical user checks in every thirty seconds, which the authors consider a best practice. Different check-in times (ranging from every twenty seconds, leading to a long list of redundant locations, to once per hour, leading to a much more reasonable list) are appropriate for different users, and the log of recently recorded locations is most useful if the user has chosen appropriately.
The mobile in/out board is built to store and display names and phone numbers, but the system also includes support for contacting each phone not using cellular service (e.g. through a VoIP or text function such as Skype). This may be useful given that Wi-Fi signal strength is typically much more robust than the highly variable cellular signal strength in WMU’s main library, and given the use of some no-service cellular phones.
Library administrators, who mostly also use Android smartphones, also have busy calendars that keep them moving all over campus, sometimes unpredictably. They have expressed interest in implementing a separate mobile in/out board so they may keep track of each other. WMU Libraries has also discussed using this system for roving reference librarians, as well as offering the system to other support units on campus. No matter the job, if someone wants to be more available, using smartphones (even personally-owned or without service) on existing Wi-Fi is a low-cost option.
Finally, systems like WMU’s are susceptible to local network and other conditions. For example, WMU campus IT is currently in the process of replacing the main library’s network switches, wireless network, and wired phones. Were an entire wireless network to be replaced at once, this system’s entire database would need to be retrained. Given other concurrent campus network projects, campus IT is replacing the network in phases (adding a switch, then adding new wireless APs, then replacing phones, and finally removing old switches and APs), one floor at a time over an approximately one-year period, requiring only that staff add to the fingerprints of locations as they visit them. In addition, given differences in performance that seem to coincide with changes in weather and building HVAC conditions, the authors suspect that variability in signal strength may be influenced by environmental conditions such as relative humidity (given that water can absorb radio signal).
Notes
[1] WMU’s local custom algorithm is not included. Instead, the pseudo-code for NNSS, which is the most straightforward starting point can be found in the appendix. Readers interested in WMU’s algorithm or source code are welcome to e-mail keith dot kelley at wmich dot edu.
[2] It is important when reading this article to understand what an RSS value is. A chipset manufacturer actually calculates and reports an arbitrary integer that may be an average of the signal strength it detects over a specific time period that can definitely be as long as a full second. The 802.11 specification places few requirements on Received Signal Strength Indicator (RSSI). RSSI does not necessarily map to distance, power, or the same number on different devices nor is it necessarily calculated in real time. Also, RSSI is not a constant and interference from multiple access points has a strong negative impact on positioning accuracy (Chan et al. 2010).
Similar systems
Navarro et al. (2010) describe a senior project that tracks children on a playground.
The system discussed by Lee et al. (2010) is participatory and room-level.
Bolliger (2008) describes Redpin, a participatory and room-level system, but which also uses KNN and x and y coordinates.
Ching et al. (2010) describe Uniwide, which provides room-to-room accuracy at a university via fingerprinting.
Suggested Reading
Liu et al. (2007) provide a good place to start reading about methods of indoor positioning including Wi-Fi fingerprinting and symbolic (referred to as semantic) locations.
References
Ali S. 2011. Indoor geolocation for wireless networks [dissertation]. Cranfield (UK): Cranfield University. 271p. Retrieved from http://dspace.lib.cranfield.ac.uk/handle/1826/4721
Bahl P. and Padmanabhan V. 1999. User location and tracking in an in-building radio network. Microsoft Research. Retrieved from http://research.microsoft.com/en-us/um/people/padmanab/papers/msr-tr-99-12.pdf
Bahl P. and Padmanabhan V. 2002. RADAR: An in-building RF-based user location and tracking system. INFOCOM 2000. Nineteenth annual joint conference of the IEEE computer and communications societies. IEEE. p. 775-84. Retrieved from http://research.microsoft.com/en-us/um/people/padmanab/papers/infocom2000.pdf
Bolliger P. 2008. Redpin-adaptive, zero-configuration indoor localization through user collaboration. Proceedings of the first ACM international workshop on mobile entity localization and tracking in GPS-less environments; 19p. Retrieved from http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.155.205&rep=rep1&type=pdf
Chan E, Baciu G, and Mak S. 2010. Effect of channel interference on indoor wireless local area network positioning. IEEE 6th international conference on wireless and mobile computing, networking and communications (WiMob); p. 239-45. Retrieved from http://www.cse.ust.hk/~csclchan/paper/effectofchannelinterference.pdf
Ching W, Teh R, Li B, and Rizos C. 2010. Uniwide WiFi based positioning system. 2010 IEEE international symposium on technology and Society (ISTAS); p. 180-89. Retrieved from http://www.gmat.unsw.edu.au/snap/publications/ching_etal2010.pdf
Liu H, Darabi H, Banerjee P, Liu J. 2007. Survey of wireless indoor positioning techniques and systems. IEEE Transactions on Systems, Man and Cybernetics. Part C, Applications and Reviews 37(6):1067-80. Retrieved from http://www.sis.pitt.edu/~dtipper/2011/Survey1.pdf
Dawes B and Chin K. 2011. A comparison of deterministic and probabilistic methods for indoor localization. J Syst Software. 84(3):442-51. (COinS)
Hansen R, Wind R, Jensen C, Thomsen B. 2009. Pretty easy pervasive positioning. Advances in Spatial and Temporal Databases: 11th International Symposium; p. 417-21. Retrieved from http://books.google.com/books?id=aBV0uH7AIEAC&printsec=frontcover&source=gbs_ge_summary_r&cad=0#v=onepage&q&f=false
Honkavirta V, Perala T, Ali-Loytty S, and Piche R. 2009. A comparative survey of WLAN location fingerprinting methods. IEEE 6th workshop on positioning, navigation and communication; p. 243-51. Retrieved from http://math.tut.fi/posgroup/honkavirta_et_al_wpnc09a.pdf
Jekabsons G and Zuravlyov V. 2010. Refining Wi-Fi based indoor positioning. Proceedings of the International Scientific Conference Applied Information and Communication Technologies; p. 87-95. Retrieved from http://www.cs.rtu.lv/jekabsons/Files/Jek_AICT2010.pdf
Kaemarungsi K and Krishnamurthy P. 2004. Properties of indoor received signal strength for WLAN location fingerprinting. The first annual international conference on mobile and ubiquitous systems: networking and services (MOBIQUITOUS); IEEE; p. 14-23. Retrieved from http://www1.cs.columbia.edu/~andreaf/downloads/01331706.pdf
Lee M, Yang H, Han D and Yu C. 2010. Crowdsourced radiomap for room-level place recognition in urban environment. 8th IEEE international conference on pervasive computing and communications workshops (PERCOM workshops); IEEE; p. 648-53. Retrieved from http://academic.csuohio.edu/yuc/papers/smarte2010_submission_2.pdf
Li B, Wang Y, Lee H, Dempster A and Rizos C. 2005. A new method for yielding a database of location fingerprints in WLAN. Communications, IEE proceedings-IET; 580p. Retrieved from http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.70.5053&rep=rep1&type=pdf
Navarro E, Peuker B, Quan M. 2010. Wi-fi localization using RSSI fingerprinting [senior project]. San Luis Obispo (CA): California Polytechnic State University. Retrieved from http://digitalcommons.calpoly.edu/cgi/viewcontent.cgi?article=1007&context=cpesp&sei-redir=1
Tsui A, Chuang Y, Chu H. 2009. Unsupervised learning for solving RSS hardware variance problem in WiFi localization. Mobile Networks and Applications. 14(5):677-91. Retrieved from http://140.112.30.160/papers/UnsupervisedLearningForSolvingRSSHardwareVarianceProblemInWiFiLocalization.pdf
About the Authors
Keith Kelley is Director of Systems at Western Michigan University Libraries and a Ph.D. student in Computer Science at Western Michigan University.
Scott Garrison is Associate Dean for Public Services and Technology at Western Michigan University Libraries.
Karlis Kaugars is Chief Information Officer at SUNY College at Oneonta.
Appendix: Decisions Implementers Need to Consider
As this article points out, there are many possible ways to implement and configure a Wi-Fi fingerprinting location system, depending on local preferences and environment, algorithm, and many other factors. This appendix offers a list of questions that those who wish to deploy such a system should consider, and the authors’ suggested answers from their own experience.
Training locations
How many scans, over what period of time, are needed at each department or desk to train/collect a location (define a fingerprint)?
The practical answer is that the app can train for as long as the user has patience to wait until fingerprint definition is complete. Ten scans over ten seconds on the confirm or correct operation is the most the app should add to a definition at once, but the app can actually start a fingerprint definition with a single scan result. For an isolated location with a fingerprint that has little in common with other fingerprints in the database, one scan result is all that is needed, and it saves space and processing time for all location recognition operations.
Note that due to high variability of antenna RSS values even for a stationary object, no single train/collect session will record every possible value, or the full characteristics of the probability distribution.
How many scans over what period of time are needed on the mobile device to match that fingerprint?
As noted above, RSS values fluctuate considerably and an app will definitely have mixed results if it tries to match on just one measured sample. Actual impact on accuracy will depend on choice of location determination algorithm.
Like WMU’s own testing, Honkavirta et al. (2009) showed accuracy improvements as more scan results were sent from a fixed location, but noted that there were no dramatic increases beyond ten seconds. Since a mobile device is likely to be moving, scan results over a period of even ten seconds may be from several locations, which will decrease accuracy by supplying bad data to the algorithm. WMU’s live tests have shown that too few scans resulted in false positives from distant locations, and too many in a noticeable lag in location detection. A practical compromise is three scan results taken over three seconds.
| No of measurements sent | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Correct identifications | 86.7% | 90.0% | 91.5% | 92.2% | 92.8% | 93.2% | 93.4% | 93.8% | 94.1% | 94.3% |
Table 1. Effect of number of measurements observed on correct location identifications.
Initial testing of WMU’s algorithm showed two scans were much better than one, but while there can be improvements from including four or more scan results sets, each additional set only resulted in a correct match less than 1% more often. This is just a guideline; results will be implementation specific.
An app will generally need “a lot” of measured signals to build the fingerprints in a radio map in the training stage and “a few” to recognize the location in the positioning stage.
How many locations should be trained? One per room with solid walls? One per desk? One every ten feet?
The answer to this question also depends on specifics of the implementation and the environment. To avoid the upfront cost in training time, WMU uses a participatory approach, which works well largely because all users have the same model of mobile device (all mobile devices will not see the same RSS values at the same location). If the app uses a participatory approach, users will add as many locations as they like based on either their needs or the perceived performance of the system. They will likely want to add many more than are needed.
The room-level system in Hansen et al. (2009) suggests taking a fingerprint every two to three meters, but WMU’s experience suggests that the answer really depends on desired results and the chosen algorithm’s accuracy. In a tracking system like this, just being a nearest neighbor in signal space may not be near enough, so WMU set a threshold at which a user’s location is considered unknown and leaves this as a configurable option on the mobile app. A higher unknown threshold generally means a smaller radius is considered as part of the location definition and a larger portion of the real world is considered to be an unknown location.
It may be beneficial to define one fingerprint facing each cardinal direction at each location and consider them separate locations with the same or similar names. However, the user may not value that benefit highly enough to willingly do such detailed fingerprinting, and instead consider the single orientation results as good enough. Likewise, a user can take similarly named fingerprints at different times of day. Both are more realistic than trying to have one fingerprint definition that matches under all orientations at all times of day. As a user, this translates into adding, confirming, or correcting fingerprint definitions when the user happens to be at the location, so that the system works the way the user does, with the user contributing more information to the fingerprints of more frequently visited locations. In practice, the user is both the producer and consumer of the location definition, defining and using fingerprints.
Choosing an algorithm
The article very briefly covers what a good fingerprint recognition algorithm is, but what else should implementers consider about the algorithm?
Not all algorithms are suited to symbolic locations (many require x and y coordinates to function). Of the static (unfiltered) algorithms tested in Honkavirta et al. (2009), some perform better than others at different levels of training effort. However, considering the small impact on accuracy (0.2m error), the app may as well use straight NNSS for the sake of simplicity. Symbolic locations generally represent a room or a desk or a cubicle; a change of 0.2m still puts the device in the same location.
Many articles exist comparing appropriate algorithms. Lee et al. (2010), for example, compared a deterministic KNN method with k=1 and a probabilistic method, finding slightly less accurate but vastly more efficient results from the latter. This offers license to go either deterministic or probabilistic. Dawes and Chin (2011) and Honkavirta et al. (2009) are recent articles among the many that have compared a large number of different algorithms. All of the ones that do not rely on having x and y coordinates will perform the task, so the implementer can make an informed decision about the benefits and drawbacks of each.
Something close to NNSS with Manhattan distance is a good place to start because it is simple, it works well enough, and articles improving NNSS use in similar applications appear continually in the literature. Using an average of a representative size training set (depending on number of nearby APs and location) can be adequate, while using a single scan result can be next to meaningless in a densely populated radio map.
The following is pseudocode for the simplest case location determination algorithm using a fairly straightforward implementation of NNSS with Manhattan distance.
initialize location distances to MAXINT
foreach location in database
foreach expected_antenna in fingerprint
foreach observed_antenna in scan result set
if expected_antenna == observed_antenna
location[distance]+=
abs(expected_antenna.average_rss - observed_antenna.average_rss)
return location with shortest distance
In the end, the authors wrote their own algorithm (which is somewhat more complicated and more efficient) based on local environment and field tests, but something as simple as the above can be a functional starting point for a location determination algorithm. Note that the above method implicitly ignores new and dropped APs, which is not specified in the original algorithm and has some impact in those cases, but none in the ideal case.
Matching
How much of a match is a match?
A partial fingerprint match, such as seeing one of seven antennas at -92dBm instead of -33dBm may make a certain location the nearest neighbor, but also may mean the mobile unit is a building away. In these situations, it may be better to return a value of “Unknown.” For this reason, the implementer may choose to use a percentage score when configuring the system instead of (or in addition to) a distance in signal space or using a maximum allowable distance in signal space.
The final answer depends on the chosen algorithm, and will have to be discovered through usage, but it may be more generous than expected. WMU has users that use thresholds between a 10% and 40% match on score.
Should the app use a percentage match or just a score or distance units?
The location determination algorithm will determine the metric used to judge whether one location is a better match than another, and this may differ widely. It is important to consider that a straight score based on the training set won’t work well with unevenly defined fingerprints (larger fingerprint definitions will always beat better matches). An algorithm based on a percentage match of observed signals against expected signals will have the problem that weakly defined fingerprints can outweigh well-defined ones, which is also a problem. A percentage of expected signals that match over observed signals will not give too much advantage to large (well defined) fingerprints, but will sometimes give too much advantage to small fingerprints (i.e. a 100% match to a single scan result probably shouldn’t be considered a better match than a 90% match to 400 scan results). Luckily, for the most part, an implementer can browse the research, pick a location determination algorithm that has a combination of strengths and weaknesses that suit a particular implementation, and plug it in on the localization server without having to update the mobile clients (which is more difficult once users have them in the field).
How many APs should I consider when matching?
Honkavirta et al. (2009) report that the optimal choice is no more than five APs. However, Jekabsons and Zuravlyov (2010) found that there is benefit from using all available APs, including the weakly sensed ones. In WMU’s tests, it depends on the algorithm used to match the observed set to the expected fingerprint. If the chosen algorithm does not include a recommendation, use every antenna observed.
Miscellaneous
Should I use filtering?
No, the application does not demand it. Many location determination algorithms use filtering to improve accuracy at the cost of simplicity and processing time. Filtering is generally a good thing, but adds complexity and isn’t necessarily good in every application. Honkavirta et al. (2009) conclude that “all filters improved results significantly over static methods” in their testing, but Dawes and Chin (2011) noted that in their testing, at one second of observation data (four samples), performance was better with an unfiltered algorithm. The authors estimate that most of the articles published on Wi-Fi localization are not considering symbolic locations, so their findings do not necessarily apply.
What devices should I use?
Have all system users on the same model of device if possible, or the app will have to adjust for differences or the users will have to live with some fairly poor matching. WMU’s tests show that a fingerprint made by one device may vary more from a fingerprint made by a different device, than from a fingerprint made at a different location.
The scatter plots in Figure 6 show the mean RSS of an antenna as observed from two phone models (an HTC Aria and a Motorola Citrus) at the same location over the same period of time. The pattern of clustering shows that while there is some correlation between what two devices perceive it is not a simple task to translate between fingerprints on two different model devices.
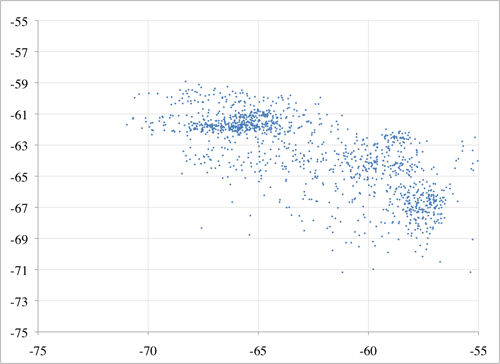
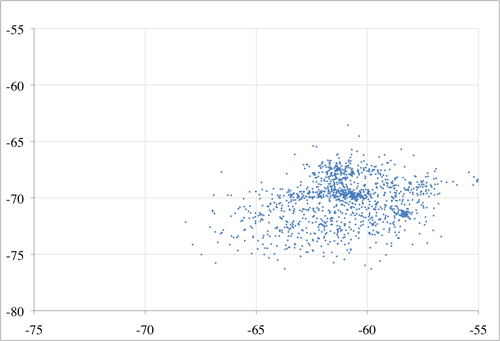
Figure 6. Two phones’ observations of the same environment: perceived RSS from Aria vs Citrus phones for antenna 1 (top) and antenna 2 (bottom)
Tsui et al. (2009) describe one way of addressing the problem that different devices see different RSS values in the same circumstance, but the effort, complexity, and uncertainty can be saved if users simply use the same devices.
How often should I scan for signals and recognize my location?
Users will notice significant battery usage if the device uses the Wi-Fi excessively, so be prudent. While Wi-Fi does not use as much battery as GPS, it can still be the largest cause of battery drain. If users have different movement habits, it makes sense to make this a configurable option, with staff who move less often checking in less often.
Should I use the GPS location when it’s available to use because I can?
Definitely not. Polling GPS will drain users’ batteries faster than any other activity, potentially rendering phones dead that are primarily used for keeping in emergency contact. Using GPS is worse than not having a phone at all, because it gives the user a false sense that they are available (when in reality, the phone is unlikely to last half the workday).
Can I use Wi-Fi fingerprinting in multi-floor environments?
Yes, many implementations are multi-floor, including WMU’s. The more APs that are visible, the more likely the implementation is to work well (up to the point where channel interference becomes a problem; Chan et al. 2010). A lateration method would need three antennas to determine a location in two-dimensional space and four for three-dimensional space, so it is reasonable to assume a fingerprinting method will need at least that many.

mikey, 2012-04-20
cool thing thx.