by Janifer Gatenby, Richard O. Greene, W. Michael Oskins and Gail Thornburg
Introduction
The project GLIMIR (Global Library Manifestation IdentifieR) was initiated by Stu Weibel of OCLC Research to create a reliable manifestation identifier that could be freely diffused globally for common usage. Whilst a series of ISO manifestation level identifiers already exist (ISBN for text, ISSN for serials, ISMN for music, ISRC for sound recordings, V-ISAN for audio-visuals and DOI for electronic texts) studies of WorldCat revealed that they were only present in 30 percent of library records. ISO identifiers are applied by trade organisations to resources of commercial interest. Libraries also collect cultural resources that are outside the scope of ISO identifiers. (Gatenby 2008).
“We need identifiers that are globally scoped, business neutral, usable by all, and managed in either a centralized or federated manner. To the extent that such identifiers are canonical – that is, become the dominant identifier for a given asset, they increase the ‘URI equity’ for library assets and will strengthen the library presence on the Web.” (Weibel 2008)
WorldCat, as the largest union catalogue, including more than 256 million records representing the holdings of more than 72,000 libraries world-wide (OCLC 2012) was proposed as the best source for creating and, just as important, maintaining a globally valid identifier. However, although WorldCat record identifiers once had a nearly one-to-one relationship with manifestations, this is no longer the case. The main reason for this is that since OCLC released its open WorldCat and WorldCat.org platforms in 2003, an increased number of libraries world-wide provided records for loading, resulting in parallel records describing the same resource but in different languages and scripts. Before manifestation identifiers could be created, it was necessary to create clusters of records describing the same manifestation of a work.
Early internal studies examined some work sets with 30 or more records and noted not only multiple records for the same resource in different languages of cataloguing, but also records described in the same language where OCLC’s duplicate detection program was not confident to demand de-duplication and merge. It was then noticed that from the end user’s viewpoint, it would also be helpful to cluster records where the content was the same, e.g. original text, microform, electronic reproduction, reprint (but not a new edition) or an original film and a DVD release. This potential higher level cluster serves the user well, as usually users are more concerned with content and less with actual imprints.
The project’s focus started to move from identifiers to record clustering. The project was approved in early 2009, tasked with creating the clusters but working within the current database and system architecture.
Existing system environment of WorldCat
The WorldCat database has at its heart bibliographic records in MARC21 format extended with additional data including coding for format, work identifiers and with links to authority and holding records. As new records are added or modified, some updating is done in real time and some in the background or overnight. There are two processes that are relevant to the GLIMIR project: the FRBR algorithm that creates work clusters and assigns the OCLC work identifier (OWI), and Duplicate Detection and Resolution (DDR). The FRBR algorithm works in real time and operates via examining author and title data elements of the record and making an author/title key. All records with an equivalent author/title key are clustered and given the same OWI. DDR works as an offline process, launching queries to find candidate duplicates, and then comparing records in pairs. A level of certainty is assigned to a match. If the match confidence is below the threshold, the records are left untouched. A resolution program examines the records themselves in multiple match cases to determine the retained record in a merge. Matching techniques in DDR are discussed in more detail elsewhere (Thornburg and Oskins 2007). It was decided to develop GLIMIR starting with DDR, adjusting the matching algorithms and using the resulting matches to drive the indexing which creates clusters and then seals the clusters with identifiers. This was a radically different application of matching from the existing DDR application.
GLIMIR Processing Overview
A team at OCLC worked for more than 18 months adapting and testing the duplicate detection algorithms and devising procedures for assigning the identifiers and making the content and manifestation clusters. The development was heuristic, that is sample works with hand-crafted expected groupings were compared against actual program test results and the algorithms honed and re-tested until optimal results were achieved. Tests were conducted several times a week cumulating in seven major baseline tests. More than 40 sets were hand created, most with around 60 members with a range of characteristics and material types. Very large sets and smaller sets were also included. Testing proved an intricate process; unlike DDR testing where a single match result is evaluated, not only the match itself but the ensemble of matches for all records in a work set and the resulting clusters are evaluated.
Records dealing with music posed particular challenges that have been discussed in detail by Thornburg and Oskins.
“Describing musical pieces, whether sound recordings, scores, librettos, videos, has always involved cataloger interpretation and judgment. There is considerable variation in records created for exactly the same item. And there is never ‘proof’ that two records which seem to describe the same item actually do” Thornburg and Oskins (2012)
The major achievements of the project included detecting equal content, and defining improvements to DDR and to FRBR work-set clustering. Detecting equal content involved two major components: defining compatible and incompatible formats from the typical user’s perspective, such as sound recording and text, and coping with inconsistent format encoding within records. Maintaining two streams of analysis for the manifestation and content levels in the one process was also an achievement.
Detecting Parallel Records
At the manifestation level, GLIMIR is clustering records in different description languages and also detecting records that are probably duplicates but could not be safely de-duplicated for various reasons; either the cataloguing style was too different for the records to be merged, or there were too many candidates for merging which is often the case for sparse records, or the software returned a confidence level that was not sufficient for merging. Use of the DDR software in a large de-duplication project during 2009 and 2010 removed more than 7 million duplicate records from WorldCat, but there are still many records that seem duplicates to the human eye. Because GLIMIR is clustering records but not merging and deleting, it can be more aggressive in determining duplicates and bringing them into the manifestation clusters. If it is found that records have been incorrectly clustered, undoing a cluster is considerably easier than undoing a merged record.
The project started with the DDR programs and removed the test for language of cataloguing.
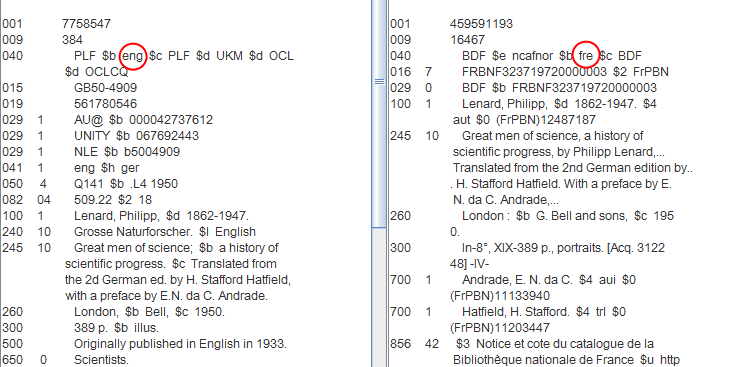
Figure 1: Two records in a manifestation cluster with different language of cataloguing
The two records above describe the same manifestation; the one on the left is catalogued in English and the one on the right in French.
In the process, many improvements were made to duplicate detection itself, particularly in relation to matching records in different languages of cataloguing and created with differing cataloguing rules. Examples of some new tests that benefitted DDR directly are:
- Creation and employment of extensive tables of language equivalents of words such as “stories”, “contents”, “volume” etc. These are often used in subtitles in some but not all records, preventing matching.
- Matching titles containing abbreviations using specially developed title comparison methods for German patterns of abbreviation and detection/deletion of nontitle information.

Figure 2: Two records clustered by special title analysis
- Matching publishers with short and long versions and abbreviated versions using tables and other equivalence checks and trigrams
- Inferring language where none was coded in the 008 field by, for example, examining title keywords and publishers.
- Detecting size equivalents, e.g. 8 ° = 22 cm = 8gr. = 8 inches

Figure 3: Two records clustered by detection of equivalence in size expression and by publisher matching
- Detecting banal collation information within titles
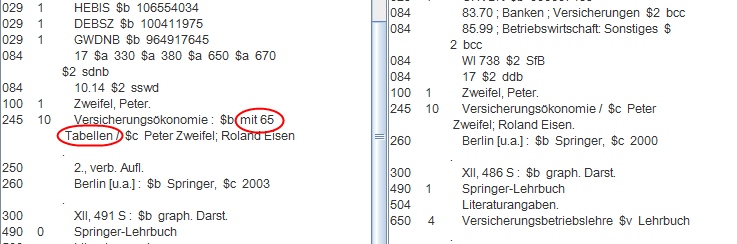
Figure 4: Two records clustered by ignoring collation information in the title
Not all tests were adopted by DDR. GLIMIR was able to be more tolerant, as mentioned earlier. Because the matching software running GLIMIR was guided by programmatic metatype, enhancements could be applied generally or restricted to GLIMIR with relative ease. Examples of GLIMIR-specific routines:
- Tolerating minor errors in extent, e.g. 288 p. versus 228 p.
- Allowing minor variations in edition statements, especially where the edition statement is non-numeric
Machine comparison can approximate but never equal human judgment. Automatic comparison cannot be on a case by case basis, meaning that each rule employed must reasonably apply to all records in the database. Where there is uncertainty, it is not safe to de-duplicate, or sometimes even to cluster.
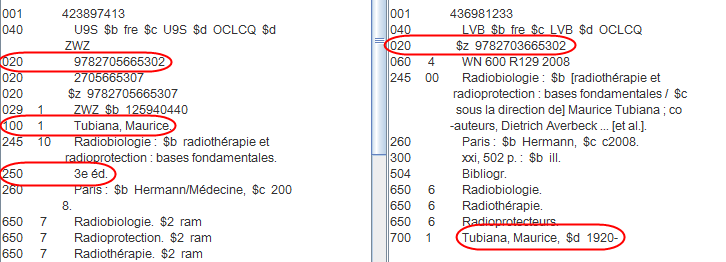
Figure 5: Two records that have not matched
The two records above are a case where GLIMIR has not been able to determine a match. The records disagree on ISBN, the one on the right saying 9782703665302 is false, and the one on the left coding it as good and a different one as false. GLIMIR would have accepted the small differences in publisher and coding of the author, but the presence of a strong edition statement in one, coupled with the disagreement on ISBN, caused the failure.
Determining equal content
The GLIMIR algorithms detect equal content by a two-pronged approach. Firstly the duplicate detection tests are relaxed such that differences in the publisher, publication date and format are tolerated, where they are not for the manifestation level, and thereby making candidates for a content cluster.
Second, a further set of tests will overrule and deny a match based on cast, language of work and format analysis. Cast analysis looks for the major contributors (directors, conductors, soloists and major actors of a musical, film or theatrical performance or readers of a talking book). Only the major contributors are sought as the cast detail in records varies greatly. A multi-lingual table for cast terminology was developed and deployed.
For language of item, most records have correct codes that can be used, but for many records without such codes, it was necessary to attempt to infer the language using a variety of indicators such as distinguishing common words in the title, ISBN prefix and publisher. Format analysis prevents incompatible formats from clustering, e.g. a film and a book, talking book and printed text.
The GLIMIR content level is aimed at achieving useful clustering of existing records from a user perspective. Whilst librarians are traditionally focused on the accurate description of the actual manifestations they own or have access to, users are more typically seeking at the work and content level; if a particular edition is not readily available an alternative with equal content is usually acceptable for all but elite researchers. In terms of the Functional Requirements for Bibliographic Records (FRBR) model (IFLA 1998), the GLIMIR content clusters are achieved by parallel links among manifestations. The GLIMIR content cluster is not the equivalent of the FRBR expression layer. However, by clustering content within a work set, the real differences among its manifestations, such as translations, cast differences or editions with different prefaces, are made more apparent. Sherry Velluci (2007) gives a good discussion of the complexities of the FRBR expression level in music.
Studies have concluded that effectively generating the FRBR expression level from existing MARC records is not possible.
“Our experience, which reportedly has been the experience of other groups as well [ELAG], has led us to concentrate on the identification of works and, to a great extent, to abandon our experiments on identification of expressions for now.” (Hickey 2002)
Coincidentally, the GLIMIR content level is similar to the concept of clusters in the ISTC (International Standard Text Code).
“An ISTC does not ‘belong’ to a single author/publisher; rather, it ‘belongs’ to the work it identifies. This means that the same ISTC number should be used to identify the same content even when it is being published by a different publisher and/or in a different publication format.” (ISTC 2012)
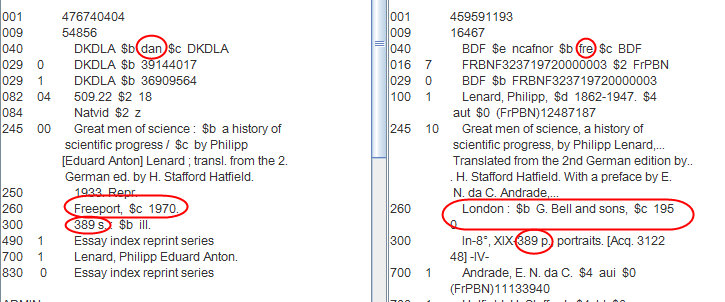
Figure 6: Two records in a content cluster
The two records above have the same content but they are not equivalent manifestations, having different imprints.
Clustering
A new resolution process was written for GLIMIR. Instead of the DDR resolution process that chooses a record to retain and may incorporate fields from the record being deleted, the process makes clusters of records and assigns an identifier. Because of the diversity of detail and cataloguing styles within the records in WorldCat, matching among records is not always symmetrical. Record A may be determined to have the same content as records B, C and D but record B may in addition have the same content as record E but not have been matched with record D. However, where A matches with B, B will always match with A. The clustering allows for asymmetry by applying the “friends of a friend rule.” The same clustering principles are employed in VIAF as is illustrated below.

Figure 7: VIAF clustering using the friend of a friend method
In the picture above, the VIAF cluster for Smith, Martin Cruz, 1942- includes 13 sources. Most sources are cross matching, except the Israeli source is only matching with the Library of Congress NACO record. (VIAF 2012)
Early in the project it was noticed that special treatment was needed for sparse records to prevent over-clustering. Sparse records, for example those without a date or without publisher and imprint information exist in WorldCat, most often representing retrospective records converted from paper sources that had been batch loaded to WorldCat over the years. Performances without cast are also considered sparse. DDR is not able to successfully de-duplicate and merge these records because it is not able to determine with confidence which of two or more records would be the best candidate. As most sparse records only have one holding, GLIMIR places these records into one manifestation cluster and neutralizes their matches so that the “friend of a friend” rule does not take effect for them.
GLIMIR clustering can be more aggressive than DDR as correction is an easy process, usually achieved by upgrading a record that has been wrongly clustered. Clustering also brings other benefits:
- Relevant holdings can be viewed at any level – work, content, manifestation
- At each viewing level the metadata displayed can be selected from the most appropriate record, either the most complete record or the most complete record in the relevant description language as determined from information about the viewer, such as IP address range
- More accurate statistics are available on the numbers of works, manifestations and records within WorldCat
- WorldCat will be better structured to support web linking and better analysis of collective global library resources (the so-called “collective collection”)
FRBR work level improvements from the GLIMIR project
Improvements to duplicate detection were expected; what was not expected were the considerable improvements that GLIMIR was able to bring to FRBR work sets. The improvements are significant, especially to interfaces like WorldCat.org where the initial displays of result sets are based on representative records from the existing work groups. It is important that records are not split erroneously among work sets, else users will see duplication, even where DDR and GLIMIR have produced correct results.
The FRBR algorithms work on examining author, title and uniform title. GLIMIR works on many more elements of the record and can find outliers that should be in the same work but aren’t. Example:
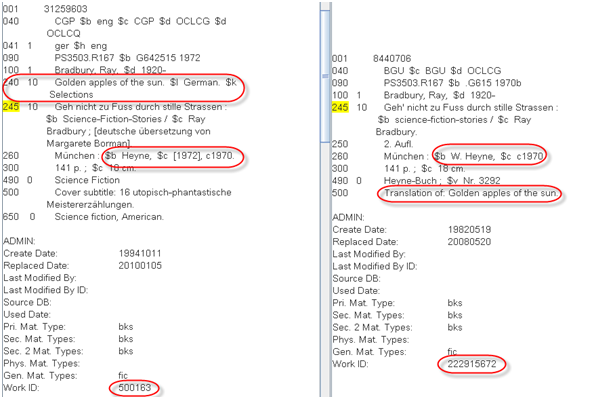
Figure 8: Two records in a content cluster in different work sets
In this example GLIMIR has determined that these two have equal content, though they are not the same edition. The record on the left is a reprint of the one on the right, indicated by the identical number of pages (both are German translations). The record on the right has coded the original English title in a note where the current FRBR algorithm cannot find it. GLIMIR will pull these into the same work set.
More than 30 work algorithm improvements have been identified by GLIMIR. Some of these include:
- Locating author in separate places within the record (e.g. in 700 or 720 rather than field 100)
- Locating original title of translations (11 coding variations detected)
- Normalising titles by
- ignoring such things as extraneous collation information
- using trigrams to tolerate abbreviations
- ignoring banal qualifications, e.g “a novel” (using multi-lingual table)
GLIMIR matches will also bring together works where it finds a match at either a content or manifestation level, in cases where the FRBR algorithm cannot determine a match. An example is where one record for a translation contains an original title and another only contains the translated title.
Thus GLIMIR and FRBR routines are complementing one another. FRBR takes a top down view of the records, examining selected fields and generating an author / title key that is used in conjunction with authority records and some hand crafted author/title pairs. GLIMIR comes along in a second, independent pass, selecting candidate records via a series of queries and examining a larger range of fields. As a result, sometimes it is able to identify outliers for a work set. By bringing outliers into the work set, GLIMIR will ensure that there will be records retrieved that were not previously retrieved, depending on the search criteria. All enquiry interfaces will benefit from this. In the case of WorldCat.org, it will also mean that the initial search result which displays one record from each work set, will be able to display fewer records as they will be correctly grouped.
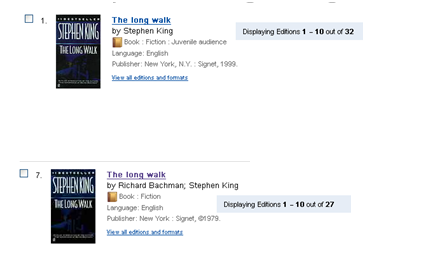
Figure 9: Two records in pre-GLIMIR WorldCat.org display (each is in a different work set)
The figure above shows the results of a search in WorldCat.org as it was before GLIMIR for the novel The Long Walk. Two separate non adjacent lines were shown in the search results on different screens because there were 2 different work sets, one with the author as Stephen King and another with the author by his, now deprecated, pseudonym Richard Bachman. Each work set has different holdings; the so called “holdings scatter” problem. GLIMIR has found record content pairs from across these work sets (and a couple more) and has caused the work sets to merge. For WorldCat.org, this is a double benefit. Firstly only one line will show in this display. Secondly, when “view all editions and formats” is clicked, it will display all and not just some editions and holdings.
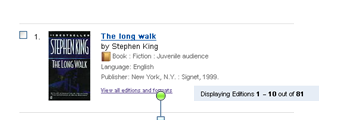
Figure 10: The search result after GLIMIR processing (condensed work sets)
Further improvements will come when WorldCat.org is able to show a work landing page. The following screen shows a possible work landing page with GLIMIR.
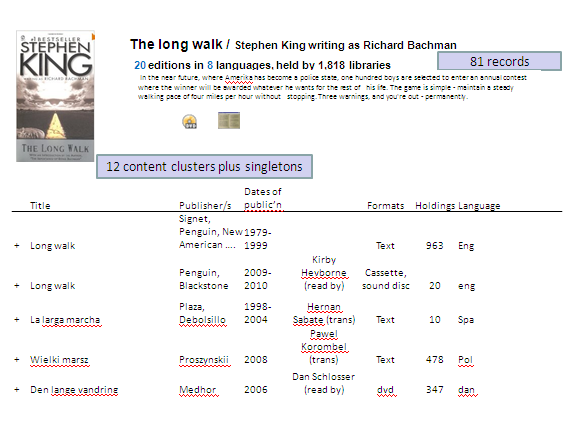
Figure 11: Mock-up of possible work set display with GLIMIR clusters
For the first line, the original English edition, there are cataloguing descriptions in English, French and Slovenian. Behind the scenes, WorldCat.org will be able to use the most appropriate record, depending on the IP address of the user. GLIMIR has made 12 content clusters (of which 5 are displaying) within this work and has also condensed several work sets into one. This will enable WorldCat.org to initially present the work in approximately 20 lines (12 clusters and 8 or so singles) instead of 81 as that is the number of records in the work set.
It should be recognized that machine evaluation will not always be perfect, just as the records being compared have been catalogued in many different styles, converted by many different programs and created by many persons. Regardless of the level of sophistication of any machine-matching algorithms, the matching decisions will not always mimic the decisions humans might make when comparing records. As a result, allowance has been made for both forced merging and forced splitting of GLIMIR content clusters and of work sets in the architecture.
From extensive testing, GLIMIR merges work sets correctly. The OCLC FRBR work set algorithm currently does not handle works without authors well at all and GLIMIR is correctly bringing these together, particularly for films and serials. The FRBR work set algorithm also consistently misses translations and records catalogued in languages of cataloguing other than English. GLIMIR is bringing serials into the same work set, though, like the FRBR work set algorithm, it cannot differentiate and hence cannot solve incorrectly coded latest entry and successive entry records with reliability. So in the case of serials GLIMIR may cause over-consolidation, but this is far better than leaving scores of work sets where there should only be 3 or 4. GLIMIR also does not solve the problem of collective works for FRBR. If the FRBR algorithm has combined single and collected works into one work set, GLIMIR matches may consolidate outliers into the set for both the single and the collected work. In this case, at least the GLIMIR content clusters will differentiate these within the set. Another problematic area was where a FRBR work set erroneously contains records with clashing formats; examples were noted where existing work sets contain films and books. The FRBR algorithm has since been corrected and erroneous work sets are in the process of being corrected prior to GLIMIR processing while GLIMIR processing is proceeding on sets of records that are unaffected.
Note that GLIMIR only causes work sets to merge. It does not split them. Also, as it is now, GLIMIR cannot replace the FRBR algorithm as explained earlier. There is, however, another unexpected gain that GLIMIR brings for existing FRBR processing concerning response time. The FRBR algorithm works in real time and GLIMIR works in background. There is a system constraint that requires a work id for every record, but it would be ideal if GLIMIR processing could precede FRBR processing. For inserted records, the sequence will remain FRBR-GLIMIR, but for all changed records the sequence will be reversed and GLIMIR will only refer changed records for FRBR re-processing where GLIMIR determines that the content has changed. Thus, the load in real time caused by FRBR processing will be lessened.
The following table shows some of the test work sets. Extensive and aggressive testing was also done on random sets, including sets for particular languages, large sets, a set for Hathi Trust and other specific formats.
| Work set | Number of records | Content clusters | Work sets consolidated * | Notes |
| Double indemnity | 47 | 7 | 6 | |
| Love (Morrison) | 73 | 20 | 6 | |
| Ravens gate | 46 | 23 | 1 | 2 other records in 2 different work sets; GLIMIR didn’t fix |
| Remember (Bradford) | 68 | 16 | 5 | |
| Taking Pelham | 29 | 6 | 8 | |
| Time and again | 41 | 16 | 8 | |
| Zhiznyi | 73 | 27 | 8 | |
| Curculio (Plautus) | 86 | 26 | 13 | |
| Goya Caprichos | 73 | 19 | 22 | |
| Golden apples | 75 | 16 | 6 | |
| Great men of science | 59 | 6 | 10 | |
| Long walk | 36 | 11 | 6 | |
| Common law (Broom) | 60 | 11 | 1 | |
| For kicks | 75 | 35 | 4 | 1 other record in different work set; GLIMIR didn’t fix |
| ERIC | 50 | 16 | 34 | |
| Library Journal | 83 | 1 or 2 | 47 | |
| Science News | 56 | 4 | 25 | should be 3-4 work sets |
| Lancet | 71 | 3 | 53 | plus 8 other regional national editions |
* During GLIMIR processing if GLIMIR determines 2 records in different work sets have equal content, the work sets will be merged.
GLIMIR processing started on WorldCat in September 2011. It started slowly, so that results could be evaluated and improvements implemented. By December 2011, processing had started to accelerate so that at the end of the month just under 500,000 records had been processed. Records coded with language of work German were selected for priority treatment as it was expected that GLIMIR would have a significant impact on them. The results confirmed this expectation:
| Records processed | Works sets merged | % work sets merged | Content clusters | Manifestation clusters |
| 475,556 | 287,066 | 60.3% | 422,208 | 426,308 |
Deployment of the clusters
The first phase of the GLIMIR project generates the clusters and corrects the work sets. A follow-on phase will create internal services to be used by all products that will deliver clustered results with holdings totals at all levels and summaries, e.g. of publishers, formats and dates of publication per cluster. It is envisaged that the manifestation cluster will enable services to display only one record from the cluster, the selection depending on the user. No matter which record is displayed, all holdings of all records in the cluster will be displayed. The manifestation cluster will also give a new, reasonably accurate count of the number of manifestations held by WorldCat libraries. The content cluster will enable services to display a summary line for the cluster in initial short list displays which will improve the experience of browsing a short list and making a selection.
Aslo, in the first phase, GLIMIR identifiers will be included in externally facing web services, xOCLCNUM and the WorldCat API. OCLC is considering expanding its beta OWI/OCN table service to include content and manifestation identifiers and metadata. Currently, just a table containing selected work (OWI) and record (OCN) identifiers is provided to two library networks corresponding to their subset of WorldCat. Diffusion options and formats are also being evaluated, including XML and RDF/linked data, as part of a general evaluation of export services. A separate paper is envisaged to discuss the various business cases for GLIMIR metadata and identifier services.
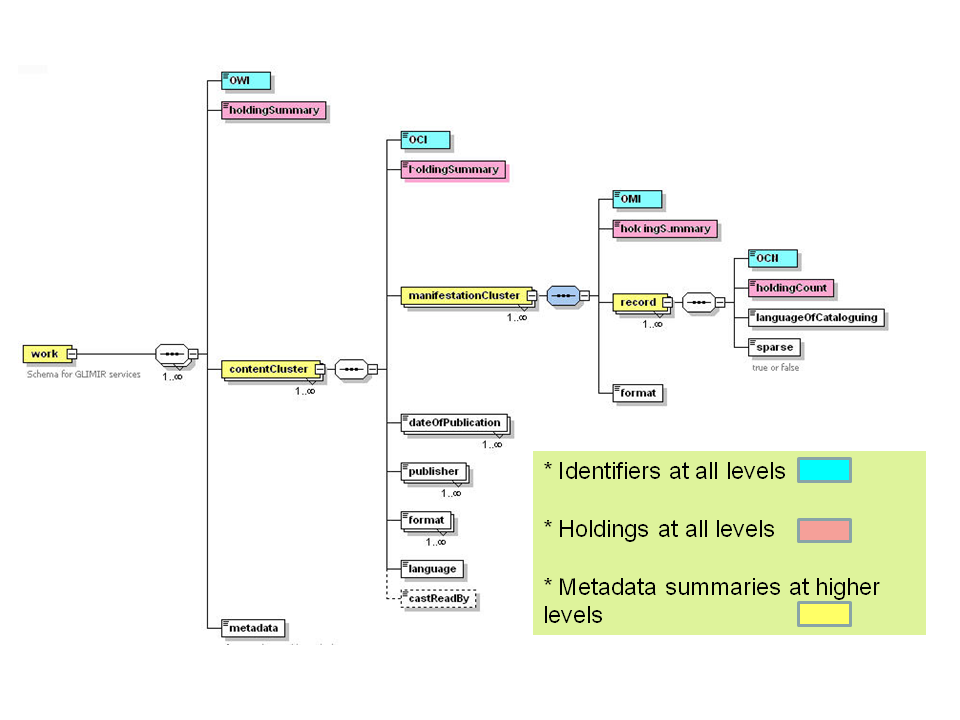
Figure 12: Diagrammatic schema of OCLC’s metadata and identifier structure
Further work
Follow on work is bringing DDR, GLIMIR and FRBR processing closer together, further improving the work level clustering and improving the clustering and linking of multi-part works, for example by allowing a compendium manifestation to link to multiple work records, namely the compendium work and individual works for the components, and by allowing links among works.
Research work is also underway to reconsider the data architecture. Many existing parallel records were made by copy cataloguing. One typical example is below where the record coded Swedish has Swedish subject headings (and also English headings not shown), “p” substituted by “s” to represent pagination, which was probably done by a macro, but with a note about bibliographic references in English.
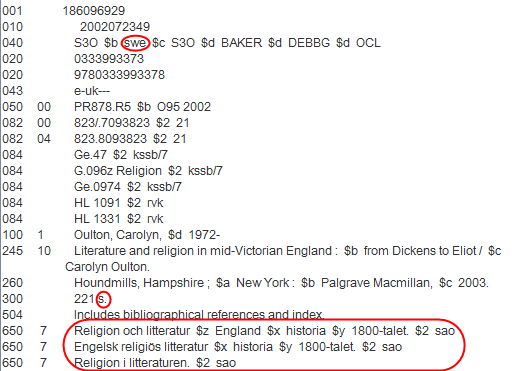
Figure 13: Example of a parallel record made by copy cataloguing
Only certain parts of a typical MARC record will differ when the resource is described in a different language. The description fields (title, imprint, extent, edition) have no significant content that varies with the cataloguing language and what content of this nature that there is can in most cases be generated programmatically using the subfield encoding. For example the statement of responsibility subfield code within the title (MARC21 245 $c), which is rendered as a slash in ISBD, could be rendered as “by” in English, “par” in French, etc. Even the table of contents will not change when the language of cataloguing changes. The parts of a parallel record that can vary by language and cannot be generated by an algorithm are:
- Author – there are linguistic variants in the name form
- Subject headings
- Summary and other non-descriptive notes
These are all work or expression level data, but they are currently held at the record level and as such are valuable access points and information that are not easily available to other records in the work. Moreover, the author and subject headings can be better managed as multi-lingual authority records. This leaves basically only the summary as having any real value in the parallel record and that too is most often work level information. The rest of the record is redundant storage. The majority of the parallel records do not have these summaries.
OCLC research is now working on a new project entitled “Moving beyond MARC: rethinking the architecture of bibliographic description.” One of the objectives is to explore the storage and linkage of bibliographic components to enable the assemblage of a record in a particular language from authority records and from macros working on the subfield coding. It would allow different language versions to be produced for all records, not just those for which parallel records have been loaded and the records would be richer as they could be assembled from all relevant fields in all records in the cluster. Relevant fields include language sensitive fields in the relevant language and all those that are not language sensitive.
Conclusion
The initial goal of the program was to create manifestation clusters and identifiers. Twice, the scope was broadened, firstly to create content clusters and identifiers and secondly to improve FRBR work clusters. The increased scope resulted in considerable challenges such as detecting equal content, defining compatible and incompatible formats and coping with inconsistent format encoding within records. Maintaining two streams of analysis in the one program was also a challenge. The initial visible impact of GLIMIR will actually be from improved work level displays. This will improve the perception of duplicates at the work level which is usually users’ first impression. Once WorldCat has been fully processed, estimated to be in the third quarter of 2012, and services start to use the GLIMIR clusters, the direct benefits of GLIMIR will become apparent and diffusion of the identifiers can commence.
References
Gatenby, Janifer (2008). The Importance of Identifiers. Metalogue, 22 August 2008 [cited 2012 March 5]. Available from: http://community.oclc.org/metalogue/archives/2008/08/the-importance-of-identifiers.html
Hickey, Thomas B., O’Neill, Edward T., and Toves, Jenny (2002). Experiments with the IFLA Functional Requirements for Bibliographic Records (FRBR). D-Lib Magazine, v. 8, no. 9 [cited 2012 March 5]. Available from: http://www.dlib.org/dlib/september02/hickey/09hickey.html
IFLA Study Group on the Functional Requirements for Bibliographic Records (1998). Functional Requirements for Bibliographic Records: Final Report. — München: K.G. Saur, 1998. — (UBCIM publications; new series, vol. 19). — ISBN 3-598-11382-X [cited 2012 March 5]. Available from: http://www.ifla.org/en/publications/functional-requirements-for-bibliographic-records
ISTC (2012). [cited 2012 March 5]. Available from: http://www.istc-international.org/html/about.aspx
OCLC (2012). [cited 2012 March 5]. Available from: http://www.oclc.org/uk/en/worldcat/statistics/default.htm
Thornburg, Gail, and Oskins, W. Michael (2012). Matching Music: Clustering Versus Distinguishing Records in a Large Database. OCLC Systems and Services, v. 28, issue 1 [cited 2012 March 5]. Available from: http://www.emeraldinsight.com/journals.htm?articleid=17006810
Thornburg, Gail, and Oskins, W. Michael (2007). Misinformation and Bias in Metadata Processing: Matching in Large Databases. Information Technology and Libraries, v. 26, no. 2, 15-22 [cited 2012 March 5]. Available from: https://www.ala.org/ala/mgrps/divs/lita/publications/ital/26/2/thornburg.pdf
Vellucci, S. L. (2007). FRBR and Music. In Taylor, A.G. (ed.). Understanding FRBR: What It Is and How It Will Affect Our Retrieval Tools. Westport, CT: Libraries Unlimited, 2007. p. 131-151. (COinS)
VIAF (2012). Display for Smith, Martin Cruz, 1942- [cited 2012 March 5]. Available from: http://viaf.org/viaf/95175916/#Smith,_Martin_Cruz,_1942-
Weibel, Stu (2008). A GLIMIR of the Future. Weibel Lines. 12 February 2008 [cited 2012 March 5]. Available from: http://weibel-lines.typepad.com/weibelines/2008/02/a-glimir-of-the.html
Acknowledgments
The authors would like to thank the following members of the GLIMIR team for their work and input to this paper: Robert Bremer, Ted Fons, Ying Li, Pat Schuette, Jay Weitz and Kelly Womble.
About the Authors
Janifer Gatenby (janifer.gatenby_at_oclc.org) is EMEA Program Metadata Manager at OCLC in Leiden. She is currently researching a new bibliographic architecture related to the FRBR model following on from the GLIMIR project and is working on the implementation of the database and management system for ISNI (International Standard Name Identifier).
Richard Greene (greener_at_oclc.org) is a Senior Consulting Database Specialist at OCLC in Dublin, Ohio. He is currently working on enhancements to bibliographic record matching for those categories of records not currently de-duplicated and on improvements to batch processing.
W. Michael Oskins (w.oskins_at_att.net ) has worked as a developer and researcher at OCLC in Dublin, Ohio for over twenty years.
Gail Thornburg (thornbug_at_oclc.org ) has taught at the University of Maryland and elsewhere, and is now a senior-level developer and researcher at OCLC in Dublin, Ohio.

Subscribe to comments: For this article | For all articles
Leave a Reply