by Jeremy McWilliams
Introduction
Academic visual resources are in the midst of a shift from traditional slide libraries to reliance upon digital collections. Rather than loading the slide tray for a class, instructors are turning to digital image collections like ARTstor, James Madison University’s MDID, and collection software like Insight, for teaching. Such resources tend to have higher quality and better-described images than what one might get from a Google Image Search. Yet resources like MDID and ARTStor are closed data silos and can be difficult to work with due to proprietary presentation software and copyright restrictions on the images themselves. And despite typically lower quality images found via Google Image Search, instructors often use those images because they’re easy to find and use (if not necessarily legal).
In the summer of 2007, a group at Lewis & Clark College in Portland, Oregon, decided to create an alternative image resource collection for education. Specifically, the goal was to develop a collection of contemporary ceramics images, as no such resource existed. But rather than gathering images in a closed platform like MDID or ARTstor, we wanted to develop a collection that had high quality images, was open to anyone, included a distributed model for adding and cataloging images, and was mobile/remixable in the spirit of Web 2.0.
It became clear that the photo sharing site Flickr was an intriguing, if somewhat experimental, solution to achieve these goals. Flickr already has a ‘group’ model, in which users can contribute images toward a shared collection. A Flickr group can also be moderated, so a curatorial board of designated administrators can accept/reject images submitted to the group. Flickr also allows users to assign a Creative Commons license to images they own, which permits the images to be used with fewer copyright restrictions. In addition, Flickr’s impressive application programming interface (API) lets developers easily create web sites with Flickr images and data.
With these ideas in mind, we decided to take the plunge and attempt to build a contemporary ceramics image collection for education with Flickr as the primary back-end. We figured it could end up as a failed R&D experiment, or it could provide a revolutionary model for academic image resource collections. Our results thus far are at accessCeramics.org. This article will discuss the site design and evolution of accessCeramics, Flickr machine tags, and the concept of Flickr as the database layer for an academic image collection.
accessCeramics.org: Initial Design
Our working group consisted of Ted Vogel (Assistant Professor of Art, Program Head in Ceramics, Department of Art, Lewis & Clark College), Margo Ballantyne (Visual Resources Curator), Mark Dahl (Assistant Director for Systems and Technical Services), and myself, Jeremy McWilliams (Digital Services Coordinator). We didn’t really have any extra time, resources, or additional staff to devote to the creation of the image collection, though our expertise in different areas helped to distribute the workload fairly evenly. Ted and Margo developed the metadata schema and worked directly with artists, while Mark and I handled the technological aspects, including plenty of testing within Flickr, and the development on the code base.
We hoped to rely as much as possible on the existing Flickr infrastructure for collection organization, metadata storage, and user authentication. The idea was to create a lightweight, mobile site that was little more than a thin technological layer on top of Flickr. The initial site consisted of PHP, CSS, and the JQuery JavaScript library, and handled all data storage within Flickr via the API (Figure 1). Essentially, we wanted Flickr to be the database.
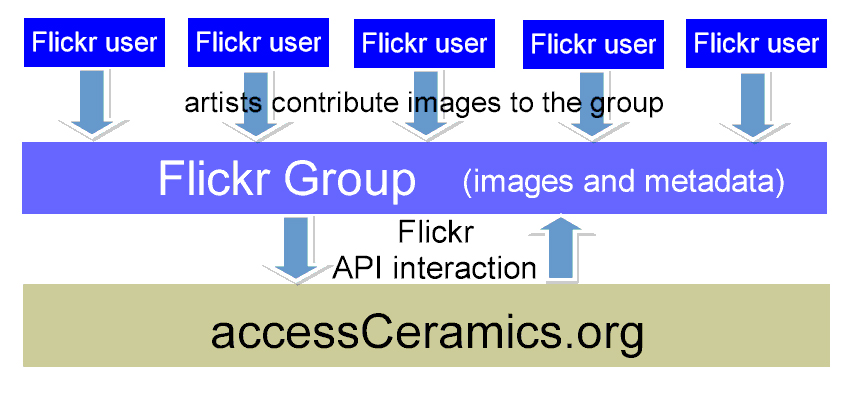
Figure 1: accessCeramics initial model [View full-size image]
During our initial development, I created a test Flickr group, and wrote PHP code to create an interface that interacted with Flickr using its API. The site was designed to work with basic Flickr API functions, including Flickr authentication, viewing Flickr image sets on our interface, adding tags to images, and submitting images to Flickr groups. Once development and test phases were completed, we invited local ceramicists to create free Flickr accounts, upload images of their works, and join our Flickr group. The artists then used our interface to catalog and submit their images to the collection. To do this, an artist would log in to Flickr through our site, select an image from their personal Flickr collection, and then add metadata to a cataloging form to describe the image (Figure 2). Upon submission, PHP scripts converted the metadata to tags, added them to the image on Flickr, and placed it in the Flickr group queue, where it awaited approval or denial by a group administrator.

Figure 2: accessCeramics cataloging form[View full-size image]
Yet our code did more than just convert metadata to tags. In order to create useful metadata for images, the cataloged data was converted to machine tags, a relatively new type of tag structure that we hoped could make the ‘Flickr as database’ concept a reality.
Flickr Machine Tags
One of Flickr’s most popular features is the ability for users to describe images with tags. This creates an environment for social photo sharing, as Flickr users can easily view sets of images tagged with common keywords. But tags alone don’t provide the depth of metadata description that some image collections might require. Users of such collections should be able to search and browse by different fields, and keyword tagging simply doesn’t provide that framework.
Recognizing that need, Flickr launched machine tags in January of 2007. Machine tags have the format namespace:field=value, enabling complex image descriptions. Not only can machine tags allow field-value relationships, but similar relationships can be grouped together with a common namespace. Geotagging is perhaps the most common use of machine tags, as a simple keyword tag of ‘45.12234’ won’t have the same meaning as geo:lat=45.12234. And while there was some initial discussion to regulate the use of machine tag namespaces, the selection of a machine tag namespace in practice is largely arbitrary.
While Flickr users can create and view Machine Tags in the Flickr interface, they are intended primarily for use in the Flickr API. Since a user on Flickr is not likely to add a tag like ‘image:color=red’, it makes more sense for code in an external application to take user inputted metadata and convert them to machine tag syntax. In the case of accessCeramics, we developed a cataloging interface for artists that takes form values, converts them to machine tags, and uses the API to tag the targeted image on Flickr. Similarly, if a user wanted to browse images in which the glaze is electric oxidation, the application should convert the query to machine tag syntax, perform the query through the API, and return a formatted results set. In other words, the existence and use of machine tags should be invisible to the user, just as SQL queries are in common LAMP applications.
Flickr API Machine Tag Code Samples
Flickr’s API has over 100 methods for a variety of purposes, utilizes a REST-style format, and requires an API key. Each method has a thorough demonstration page in which users can enter sample queries, and receive XML responses (here’s an example). Developers have also created a number of API kits in a variety of languages to further simplify the API interaction process (we use Dan Coulter’s phpFlickr). For the purpose of these examples, we’ll use language-independent REST URL queries, with XML responses. We hope they will provide some insight on our attempts to store and retrieve image metadata in Flickr.
Adding a machine tag
To add a tag or machine tag to a photo in Flickr, flickr.photos.addTags is the appropriate method. In this example, we’ll add a machine tag to an image for a fictional image collection of dogs. To designate a ‘breed’ field as ‘cocker spaniel’, the machine tag could read dogs:breed=’cocker spaniel’. Below is the structure of the REST URL to add the machine tag to the Flickr image through the API:
http://api.flickr.com/services/rest/?method=flickr.photos.addTags&api_key=xxx&photo_id=2411163173&tags=dogs:breed='cocker+spaniel'&auth_token=xxxx&api_sig=xxx
This particular action requires an auth_token and api_sig to verify the write permission to add the tag (more information about Flickr API authentication can be found on the Authentication API page for Flickr Services). Also, quotes are required around cocker spaniel, as it is a multi-word tag seperated by spaces. Quotes aren’t required if the value is a single word.
The response XML is:
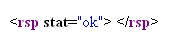
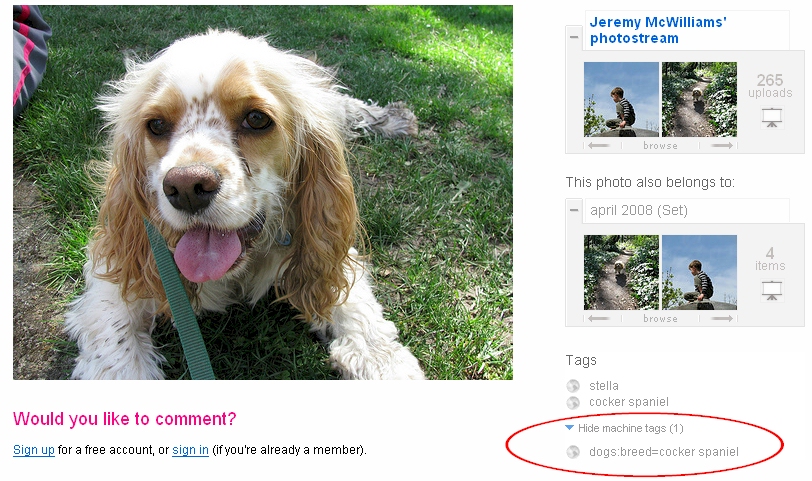
which just confirms the addition of the machine tag. The screenshot below shows the addition of the machine tag in Flickr. Notice that machine tags are grouped separately from normal tags.
Retrieve results via machine tag
An effective method to perform a machine tag search is flickr.photos.search (for more information on machine tag query syntax visit the flickr.photos.search page). This method has an optional machine tag parameter, and can also be narrowed to a group. Here is a query of the accessCeramics Flickr group for images in which the object type is a wall piece:
http://api.flickr.com/services/rest/?method=flickr.photos.search&api_key=xxx&machine_tags=Ómachine_tagsÓ+=>+Óceramics:object_type=wall_pieceÓ&group_id=511711%40N24
The machine_tags value in the URL is slightly different than the rest of the parameter / value pairs. Also, notice the underscore between wall and piece. It is important to note that this is not machine tag query syntax, but rather a decision we made for accessCeramics in handling multiple word machine tag values. This practice seemed to yield better success, and we used PHP to convert underscores to spaces when preparing the HTML view. The quotes around machine_tags and ceramics:object_type=wall_piece are part of the REST syntax for machine tags used in flickr.photos.search.
This yields the response:
<?xml version="1.0" encoding="utf-8" ?> <rsp stat="ok"> <photos page="1" pages="1" perpage="100" total="16"> <photo id="2319784593" owner="24450244@N03" secret="88ec9f4fe0" server="2199" farm="3" title="Still Life with Yellow Chick" ispublic="1" isfriend="0" isfamily="0" /> <photo id="2320601654" owner="24450244@N03" secret="0dcf641ce1" server="3012" farm="4" title="Storm Cloud Monkey" ispublic="1" isfriend="0" isfamily="0" /> <photo id="2320594270" owner="24450244@N03" secret="84aa5ba8f4" server="3062" farm="4" title="Seeds" ispublic="1" isfriend="0" isfamily="0" /> <photo id="2319787077" owner="24450244@N03" secret="f6df10ca19" server="3273" farm="4" title="Turkey Bird" ispublic="1" isfriend="0" isfamily="0" /> <photo id="2319775315" owner="24450244@N03" secret="8d5937fa27" server="2227" farm="3" title="Ghost (Ascending)" ispublic="1" isfriend="0" isfamily="0" /> <photo id="2319770783" owner="24450244@N03" secret="ff80d3c3cb" server="3230" farm="4" title="Ghost (Welcoming)" ispublic="1" isfriend="0" isfamily="0" /> <photo id="2304747377" owner="9379045@N05" secret="e175505f03" server="2005" farm="3" title="Kylix on Pedestal" ispublic="1" isfriend="0" isfamily="0" /> <photo id="2304496875" owner="9379045@N05" secret="26fdd69e4d" server="2361" farm="3" title="3 vessels" ispublic="1" isfriend="0" isfamily="0" /> <photo id="2305280568" owner="9379045@N05" secret="083726cfeb" server="3003" farm="4" title="Untitled" ispublic="1" isfriend="0" isfamily="0" /> <photo id="2177056856" owner="64194819@N00" secret="e55793c0ce" server="2165" farm="3" title="cy and chocolate" ispublic="1" isfriend="0" isfamily="0" /> <photo id="2152075599" owner="64194819@N00" secret="9ec34040be" server="2254" farm="3" title="shortbus" ispublic="1" isfriend="0" isfamily="0" /> <photo id="1800274987" owner="64194819@N00" secret="89c46a7fb0" server="2176" farm="3" title="Marley's Halloween mural" ispublic="1" isfriend="0" isfamily="0" /> <photo id="1748821816" owner="15388497@N02" secret="bee45ef0ca" server="2103" farm="3" title="Silver Branch" ispublic="1" isfriend="0" isfamily="0" /> <photo id="1747965855" owner="15388497@N02" secret="b4f53d6853" server="2150" farm="3" title="Black Sky" ispublic="1" isfriend="0" isfamily="0" /> <photo id="1747972271" owner="15388497@N02" secret="caca4951e7" server="2017" farm="3" title="White Branch" ispublic="1" isfriend="0" isfamily="0" /> <photo id="1748817406" owner="15388497@N02" secret="1db24ed5ab" server="2275" farm="3" title="Stump Roost Target" ispublic="1" isfriend="0" isfamily="0" /> </photos> </rsp>
When parsed, reformatted, and augmented with additional data using the Flickr API method flickr.photos.getInfo, a results screen like this can be created (Figure 3):

Figure 3: Formatted results screen from machine tag query [View full-size image ]
‘Flickr as Database’
Flickr has an excellent infrastructure for developing image collections, both on the site itself, and with external applications using the API. However, in some ways, it may not be quite ready as an exclusive database layer for an academic image resource. By default, anyone can add tags to images in Flickr, and changing tagging permissions is not entirely a straightforward process. This is analogous to permitting anyone to have ‘write access’ to the database. Perhaps in the context of sites like Wikipedia, this isn’t necessarily a deal breaker. Nonetheless, it’s difficult to ignore potential cases of sabotage. For example, if a user didn’t like a particular piece of art in our collection, he/she could find the image on Flickr, and tag it with ceramics:title=’i_am_not_fond_of_this’.
While machine tags have potentially expanded Flickr as a resource, they still lack a couple important features. Perhaps most important is the inability to perform truncated machine tag searches. For example, a search of ceramics:material=clay will return only exact matches; machine tags disallow wild card variables in the value portion of the tag. Creating a search interface without this feature would likely create a frustrating experience for the user. Also, as mentioned previously, there is currently no authority to regulate machine tag use. This is probably fine for now, but could become an issue if more developers use machine tags.
The ‘Flickr as database’ model also lacks a degree of centralized control to handle tedious details, like spelling variations on metadata tags. By exclusively using Flickr to store metadata, artists would be required to make corrections to their own tags in order to adhere to bibliographic control. This isn’t very practical, as tasks like this should be performed centrally. In our case, we’re indebted to our artists for taking the time to upload and catalog their images; we don’t want to hassle them with nitpicky metadata problems.
While the Flickr API is quite possibly the web services standard by which other APIs should be judged, it lacks certain methods that would be useful for our project. If we wanted to create a ‘browse by field’ screen, for example, there currently isn’t an API method to gather all possible machine tag values in an image collection for a given field. It would require an API call to retrieve a list of images in the collection, another API call per image to retrieve the machine tags, some code to select the desired tags via regular expressions and place them in an array, and finally some processing of that array prior to displaying on the interface. This sequence of events just isn’t practical. A comparable action to retrieve the same result set from a MySQL database would require just a single query and some basic conversion of the results to HTML.
Because of these various issues, we ultimately decided to abandon using Flickr as the exclusive database layer, and began storing metadata in a MySQL database (Figure 4). Not only does this give us more control over the data, but it will make the development of site tools easier, as we won’t necessarily have to depend upon the existence of certain Flickr API methods to add functionality. In our new model, artist-entered metadata is stored in the MySQL database, and machine tags are generated by an accessCeramics ‘super user’ Flickr account. We’re still creating machine tags on Flickr images, with the hope that functionality will improve in the near future, or that Flickr will build a true collection feature to fit cases like ours. The shift to a MySQL database will give the site administrator more control of the metadata, make the site run faster, and will catalyze the development of site tools and functionality.
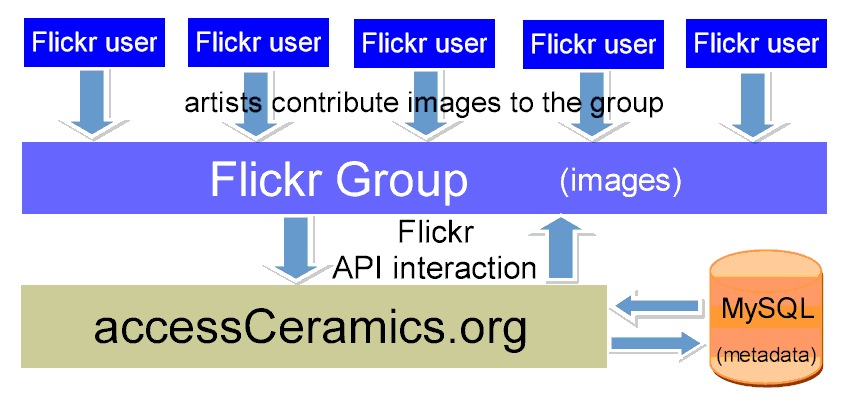
Figure 4: accessCeramics current model [View full-size image]
Future Directions
As of spring 2008, accessCeramics has a little over one hundred images contributed by about a dozen artists. We’re hoping that volume might be a typical weekly yield in the very near future. We are also attempting to procure grant funding to accelerate the development of the project; up to this point, all work on the project has been squeezed in amongst our other various duties. With additional funding, we would hire a coordinator to help artists with the image submission process, and enlist technical expertise to better design and develop the site.
Aside from increasing the volume of the collection, we plan to develop tools to facilitate educational use of the images. Our short term laundry list includes the creation of better searching and browsing capabilities, and facilitating the use of the images and metadata in slideshow and presentation software. We also hope ceramics educators will use the accessCeramics collection in the Flickr interface, as Flickr has a track record of unveiling new tools for users, some of which may be useful in an educational setting.
While Flickr has ruffled some feathers by now supporting video, the development has added some intriguing possibilities for enhancing accessCeramics and similar Flickr-based collections. Our site could eventually include videos showing comprehensive views of a given piece of art, tours of ceramics exhibits, interviews with contributing artists, and actual lectures or teaching tips that could be useful for education. And videos work seamlessly with the Flickr API; this post by Flickr’s Kellan Elliott-McCrea includes further description and code samples for embedding Flickr videos within a web application.
We hope other developers will continue to discover ways to use Flickr for education and digital collections. While some in the academic community might view Flickr as little more than a variation of MySpace, perhaps the recently added Library of Congress collection will help change perceptions and encourage more experimentation and development with Flickr. Peter Brantley of the Digital Library Federation and Mark Dahl from our accessCeramics group have discussed the notion of an ‘academic Flickr’, theoretically provided as a sub-service of Flickr itself. While this may or may not come to fruition, we should take advantage of what Flickr has already offered: a free set of wonderful tools to help us redefine what a visual resources collection can be.
Acknowledgments: Thanks to Ted, Margo, and Mark for your hard work, to Watzek Library director Jim Kopp for letting us library people work on this, to the contributing artists, and to Flickr for being Flickr.
Note: accessCeramics is not an open source project, though we would be happy to share our code. Email Jeremy (jeremy2443@gmail.com) if you’re interested.
About the Author
Jeremy McWilliams is the Digital Services Coordinator at Lewis & Clark College’s Watzek Library in Portland, OR. He has been at Lewis & Clark for 10 years, and enjoys creating public and staff-side library web applications.

{kind=link}
Subscribe to comments: For this article | For all articles
Leave a Reply