by Scott Williams
Introduction
This article discusses one solution to a very common problem in resource discovery. How do museum professionals make it easy for the general public to benefit from the power of rigorous, discipline-specific controlled vocabularies?
Museums have confronted the issues of establishing and conforming to descriptive metadata standards and the role of controlled vocabularies in different ways. Some build their own controlled institutional standards, some rely on external standards like the Getty’s Art and Architecture Thesaurus[1], the Thesaurus of Geographic Names (TGN)[2] or the Nomenclature 3.0 for Museum Cataloging (Chenhall)[3] and others prefer the freedom and flexibility of uncontrolled descriptive metadata. These variations lead to inconsistent descriptive metadata being applied to similar objects in different institutions. When institutions make their object metadata searchable online, these variances pose significant barriers to discovery for users.
This problem is heightened in a research institution, like the University of Pennsylvania Museum of Archaeology and Anthropology (Penn Museum), where metadata for the 330,000 object records is often discipline-specific, and the vocabulary used does not overlap with terms that would be familiar to an average user. Users are then left to guess at keywords and hope that all the relevant descriptive information exists within the item they want to find. Over the last year, Penn Museum has confronted these issues as we have worked to reconcile our legacy as a research institution and the mandate to be a museum with a strong focus on public education and make the information about the objects in the collection more accessible.
In this article, I will explain how our approach utilized our internal hierarchical vocabulary and Apache Solr in order to provide a more inclusive search, resulting in improved resource discovery in our online collection (penn.museum/collections).
History
In the early 1980s, individual curatorial departments at Penn started to implement content standards for cataloging objects. Curators developed “approved terms lists,” but lacked a mechanism for enforcing these standards. In 1993, Penn Museum began using Questor Systems’ collections information management system (CIMS), Argus. In the museum world, a CIMS is a repository and cataloging management application. In addition to the standard functionality of object cataloging, it is used to manage and document a range of collections management related activities such as accessions, deaccessions, loans, insurance, inventories, exhibitions, scientific testing, and conservation. The Argus CIMS also provided a robust hierarchical vocabulary management system, a lexicon, and Penn Museum used this lexicon to develop, refine and build upon the existing approved term lists. The lexicon allowed users to add non-preferred terms and link them to a preferred term. When a non-preferred term was entered by cataloger it would be replaced by the preferred term, data entry was controlled and internal standards enforced. In addition to the lexicon, Questor provided a terms list of broad concepts and in the early 1990s, the original museum-developed approved term lists were integrated into the Questor supplied terms list. Over the last thirty years this hierarchical vocabulary has grown and today contains 62,000 local terms as well as a modified version of the 1978 Chenhall Nomenclature. Today, Penn Museum uses KE EMu[4] as a CIMS but the role of the vocabulary has remained the same.
The vocabulary controls the content in core object cataloging fields: object name, provenience (a term used by archaeologists to describe where an object was excavated), material, technique, culture, period, dynasty, subject, iconography, maker, royal name, and manufacture location. Museum staff rely heavily on the vocabulary for cataloging objects and searching. Within the CIMS, when a field that is controlled by the vocabulary is searched, the system expands the query to include all narrower, non-preferred and alternate terms. A single search term like “Greek” might actually search for hundreds or thousands of additional terms in the background without the user being aware of what terms are included in the search.
Over the last twenty years, museum catalogers have become accustomed to describing an object with limited record-level metadata. The search functionality provided by the CIMS and structured vocabularies in the lexicon allowed catalogers to only enter the most granular information in the object record and the lexicon worked in the background to help searches. For instance, if a user were to search for “Ohio” in the provenience field, the CIMS would expand the query search for all the terms organized underneath Ohio in the lexicon, e.g. “Cincinnati,” “Hamilton County (Ohio),” “Cleveland,” “Porkopolis” and “Columbus (Ohio).” Objects in the collection whose provenience was described using only one term, say “Cincinnati,” would be returned by a search on “Ohio” because of this expansion. The CIMS vocabulary management, object cataloging and search systems worked together seamlessly. Users could find objects even though the item level record did not contain the term that was searched upon.
Problem
When the object catalog data was put online in January 2012 (penn.museum/collections), long-time users of the CIMS were frustrated to find that their search would only return records that contained the exact terms in their search — not narrower representations or alternate forms. For instance, a search for “Egypt” wouldn’t return an item that had been cataloged as being excavated in “Misr” (the Romanized spelling of the Arabic name for Egypt) or “Mit-Rahina” (a town in Egypt).
This was a complete departure from how the CIMS search has worked for twenty years. It was as though huge portions of the collection had been un-cataloged because the data was now in a context where resource discovery required all the relevant object metadata needed for discovery to exist in each record.
In the months following the initial site launch, we analyzed search logs and found that 83% of the top 400 search terms matched an existing term in our vocabulary. Of those matching terms, the median number of search results was forty-five objects. However, each term had, on average, thirteen narrower or alternate terms, and if those additional terms were included in the query the median number of results jumped to 123. The benefit of expanding queries was made particularly clear for the search “Greek,” which is one of the most frequently run searches. With the old full text search system only 1,400 objects were returned, but if narrower terms like “Aegean,” “Late Minoan,” and “Mycenaean” were included, nearly 7,000 objects were returned. This expanded result set is much closer to the actual size of our Greek collections than 1,400 objects and presents a much more complete picture of “Greek” objects in the collection.
We were able to use the existing vocabulary structure and Apache Solr to create a search field that would replicate the functionality already present in the CIMS and return objects that matched the searched-for term, alternate forms, and narrower terms.
How?
The typical implementation of Solr’s SynonymFilterFactory involves indexing equivalent but variable formats of a term or normalizing searched-for-terms to a standard form. In our implementation, the SynonymFilterFactory was used to index the occurrence of each Thesaurus term with all of its broader and alternate forms.
<!-- For query expansion searching --> <fieldtype name="queryExpansion" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.KeywordTokenizerFactory"/> <filter class="solr.SynonymFilterFactory" synonyms="index.hierarchy.txt" ignoreCase="true" expand="true" tokenizerFactory="solr.KeywordTokenizerFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.KeywordTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldtype>
The first step in the process of creating the index.hierarchy.txt file is to move the vocabulary data from KE EMu to Solr. EMu comes with an API, iMu, and using in-house developed scripts and this API, the entire vocabulary is exported into Solr. Each term record in EMu is added as a record to Solr as well as the term metadata (description, broader terms, etc.) This is done for two reasons. First, having the data in Solr makes the process of creating the index.hierarchy.txt file for SynonymFilterFactory much faster. Second, one of our future development goals is to make the vocabulary a more visible and tightly integrated component of the online collections and having the data in Solr would be required to implement those features.
<doc> <str name="term">Athena</str> <str name="description">Goddess of Wisdom</str> <str name="emuIRN">12786</str> <str name="key">upmaa_emu_ethesaurus_12786</str> <arr name="termHierarchy"> <str>1:48288:42506:45572:2385:5750:12101:29968:3917:47172</str> <str>28673:3917:47172</str> </arr> </doc>
Solr record for the term record representing the Greek goddess Athena
After all of the terms are inserted into Solr, the index.hierarchy.txt file is created using the vocabulary data in Solr. The values in this file explicitly index each occurrence of a term with its alternates, non-preferred versions, and parent terms, up to and including the root term of the vocabulary. For the purposes of query expansion, the order of these terms does not matter. Using the previous example, this is the row for Athena in index.hierarchy.txt which indexes every occurrence of “Athena” with the broader terms “Greek God,” “Greek Mythology,” and “Olympian.”
Athena=>Athena,Athena (uncertain),Base Lexicon,Belief and Tradition,Classical Mythology,God,God (uncertain),Gods,Greek God,Greek Mythology,Greek Pantheon,Mythology,Mythology By Culture,Olympian,Olympians,UPMAA Lexicon
With the original full text search, a query for “Greek god” would not return any object records because we do not describe iconography or subjects at such a broad level. However, with query expansion 1,096 object records are returned because the more specific terms that are used in the catalog records have been indexed with all of their broader parent terms.
Homographs
How did we deal with the problem of homographs producing false or misleading results? We didn’t address this problem directly because the problem is mitigated by requiring primary and alternate terms to be unique. If a new term is added to the vocabulary and it is a homograph of an existing term, the CIMS and internal data standards force the user to disambiguate the new term by appending some clarifying term (e.g. “Memphis (Egypt)” and “Memphis (Tennessee)” and “Memphis (Greek goddess)”). While this can make fully utilizing the query expansion tool more difficult for users because they won’t know how the term has been disambiguated, it reduces the frequency and number of false homograph matches. But in the end the problem of searching “Memphis” and getting all three types of Memphis is the same as what happens with a typical full text search. In the previous example search of “Greek god,” object number 16706 (http://www.penn.museum/collections/object/67074), was included in the result set because it contains the word “Atlas” in the description and iconography fields. When that data was indexed by the queryExpansion field, “Atlas” was indexed to multiple parentings because the term was never disambiguated and exists as a homograph for what should be three distinct terms in EMu. The term is tripled parented in EMu as type of map, Greek deity, and cervical vertebra. In our testing we found that the number of false hits are relatively small compared to the increase in relevant, useful results and the overall accessibility to our collections data outweighs these inaccurate cross-references.
Notes on testing
At the time of writing, we were providing 332,025 object records online but a search for “UPMAA Lexicon” returns 331,884 objects. This means that those 141 objects which are not returned by the search “UPMAA Lexicon” have only been catalogued with terms that are not parented to the root term, “UPMAA Lexicon”. Identifying these records and unparented terms within the CIMS would be impossible but with Solr we can, and we are working to fix those problem records and terms.
Additionally, excluding branches of the hierarchy can be achieved by adding a minus sign (the standard Lucene negation operator) in front of the term you want to exclude. For example, to search for baskets from North America but not from the state of California enter:
“North America” -“California (state)” basket
Penn Museum’s vocabulary is not exempt from bad legacy data and contains some terms that have a comma as a part of the term. This creates a problem for the index text file because the SynonymFilterFactory uses a comma to separate terms and having a comma in the term creates very real problems for searches. We are addressing this through data cleanup (removing commas and other punctuation from terms) and revised internal data standards.
As noted in the Solr documentation for the SynonymFilterFactory[5], a common pitfall of expanding synonyms is inaccurate relevancy rankings for synonymous terms because the default behavior of Solr is to treat less frequently used terms with more weight that more commonly used terms. This ranking strategy is known a inverse document frequency (idf). We have attempted to mitigate this problem by combining our queryExpansion fields with standard full text fields in a Dismax[6] query parser. Dismax is a customizable feature in Solr that makes searching across multiple fields much easier. It also allows users to specify how those searches are ranked. Our implementation of Dismax boosts the results from the full text search fields, especially the object name, material and provenience fields over those from the queryExpansion fields. Without heavily weighting the results of a full text fields the top results of a search for “vessel” would be records that use the less commonly used terms like phiale, larnax or balsamarium and records that use more common term “vessel” would be at the bottom of the results list. By boosting searches on the full text fields the top results are records that contain the term “vessel” and not the less frequently used forms of “vessel.” While this strong-armed manipulation of the Dismax query parser may not be ideal, this method has mitigated the idf problem inherent with expanding synonyms.
Future development
The next steps for improving resource discovery will certainly involve our vocabulary, exposing more of the structure to the public and making it a more visible part of our online collections. Users would benefit from seeing the terms in context (what are the broader or related terms?). Providing the vocabulary in a clickable, browsable tree structure would allow users to see what the top level terms are because currently there is no way for them to know they need to search for “Armament T&E” and not “weapon” to find all weapons.
Another possible supplement to the existing user interface would be to provide users with the search results of the vocabulary along with their object results (prototypes shown below). Showing them terms in the vocabulary that are similar to their searches as well as all of the narrower terms of their search (if their searched-for-term matches a term in the vocabulary) could provide useful indirect exposure to our content standards and make discovery more “clickable.”
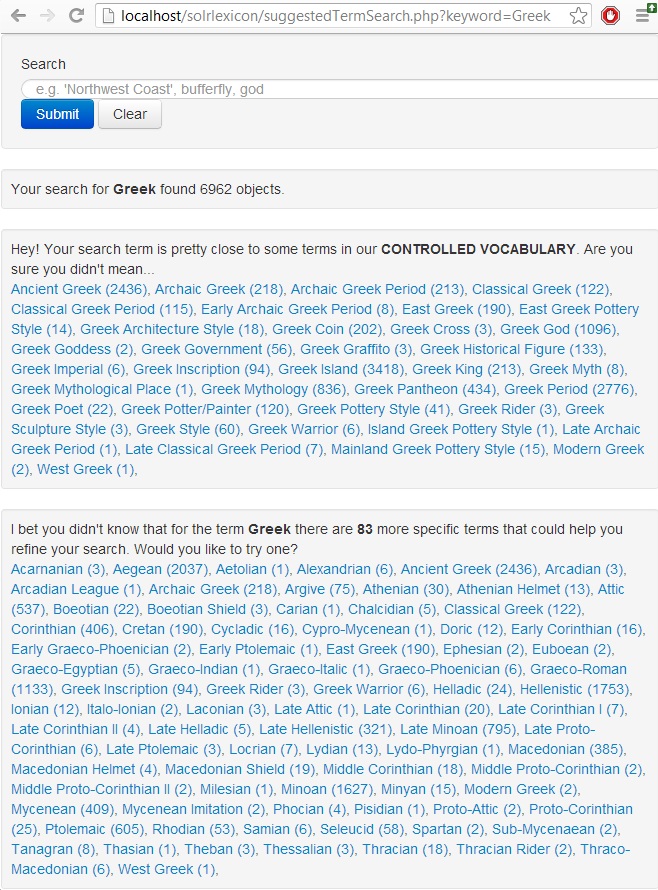
Figure 1. Suggesting similar and more specific search terms using the controlled vocabulary.
This type of interface would also help address the problem of homonyms. When a user searches for a homonym, like “Memphis,” they would then be prompted choose the most appropriate term from the vocabulary and by using the more specific term be able to take full advantage of the query expansion functionality.
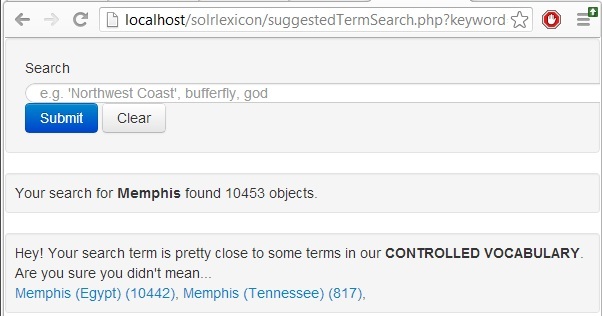
Figure 2. Using the controlled vocabulary to differentiate between homonyms.
Conclusion
While there is certainly room for improvement, our approach to the problem of resource discovery in a diverse museum collection was built upon existing content and functionality. We took a feature that has been at the core of our museum practice and replicated it online with little cost or overhead and improved the discovery process for users searching our online collections.
End notes
[1]. http://www.getty.edu/research/tools/vocabularies/aat/
[2]. http://www.getty.edu/research/tools/vocabularies/tgn/index.html
[3]. http://aaslhcommunity.org/nomenclature/
[4] http://www.kesoftware.com/emu
[5] http://wiki.apache.org/solr/AnalyzersTokenizersTokenFilters#solr.SynonymFilterFactory
[6] http://wiki.apache.org/solr/DisMaxQParserPlugin
About the Author
Scott Williams (scottwi@upenn.edu) is the Collections Database Administrator at the University of Pennsylvania Museum of Archaeology and Anthropology.

Subscribe to comments: For this article | For all articles
Leave a Reply