Introduction
Whether it is a respect for user privacy or a reluctance to give up control, libraries have traditionally shied away from harvesting or “reusing” data collected from our users. With the rise of social Web 2.0 apps, some interesting applications of user data have begun to appear. In popular web sites such as Flickr and del.icio.us, we have large-scale examples of user-generated content (e.g., the tagging systems or the social sharing functionalities that exist between the users of these systems) working to improve user access to content.
Within the library environment, we often see applications and organizational systems that focus more on the top-down approach of assigning access points a priori. At Montana State University (MSU) Libraries, we started to ask ourselves: “Does it have to work like this all the time? What kinds of access might we be restricting in forcing users to navigate and learn our strict knowledge hierarchies?” To this end, we’ve started to try to rethink the ways in which our collected user data can open up access to our collections.
The Initiative: QueryCatcher
In his account of the rise of Google, John Battelle introduces the concept of a “database of intentions” to analyze the role that search engines play as the collectors of humanity’s curiosity, exploration, and expressed desires. [1] Battelle is speaking about the search terms that we use and how these terms are recorded, logged, and then mined for insights by Google. It was exactly this idea of collecting knowledge that made me think of a new possibility for our own library search engines. [2]
In keeping with Battelle’s concept, we introduced a new component to our MSU Electronic Theses and Dissertations (ETD) web application (http://etd.lib.montana.edu/etd/view/). We created a search term recorder module, beta name “QueryCatcher,” that logs recent searches and uses those recent searches to create user access points in both a standard search list and “SearchCloud” format.
The search list view (seen in Figure 1 below) shows the most recent 50 searches recorded into the system. It includes the number of hits for each search and the number of times that the term has been browsed or searched. You can see it in action at http://etd.lib.montana.edu/etd/view/searches.php.
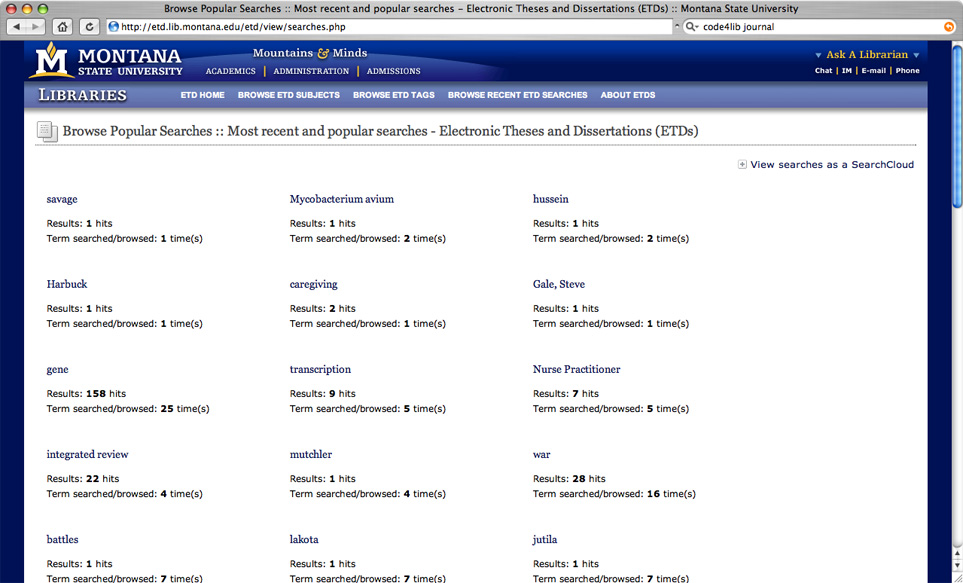
The “SearchCloud” view (seen in Figure 2 below) shows the most recent 50 searches recorded into the system. It includes a visual weighting of the terms according to the number of times that the term has been browsed or searched. You can see it in action at http://etd.lib.montana.edu/etd/view/searchcloud.php.
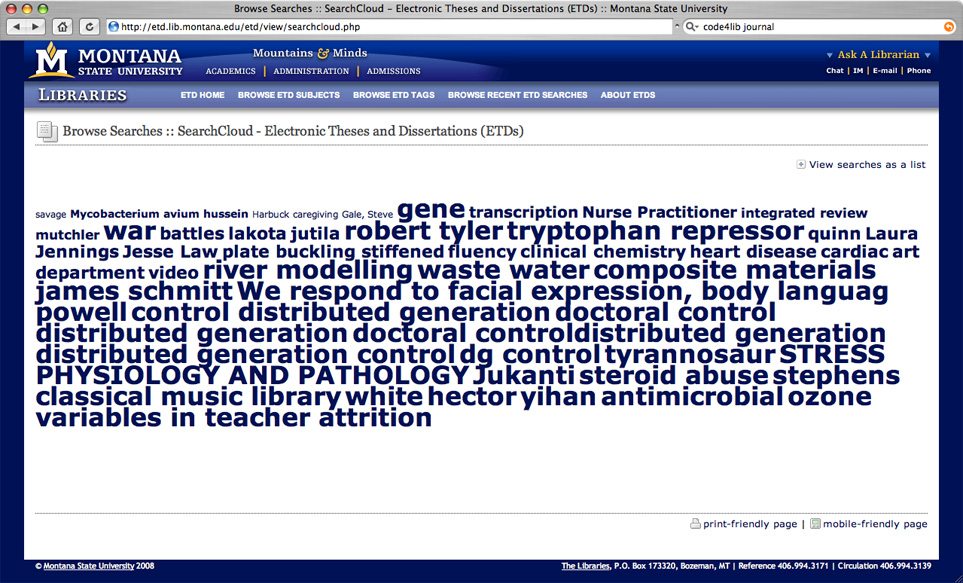
Our idea was to provide more search transparency for our users and for ourselves. Frequently, ETD searching was restricted to exploratory, single term searches. Some of this user behavior was a function of the traditional searching and browsing environment we had set up for the ETD application. (The traditional search interface is a series of web forms and browseable links based on predetermined controlled vocabularies.) We wanted to enable users to see what search terms were getting results so they could refine them for their own purposes as well as make visible the most popular terms, which are invisible to our standard web analytics for the application. Recording the actions of our users and turning that data into access points was an experiment in enabling our users to create their own browseable access to the collection.
Unobtrusive Harvesting
One of the experiments of the project has been the concept of releasing the user from any efforts to create the access points. The ETD application already has a tagging module that has met with mixed success. We are finding that ownership and real participation in tagging items can be hard to foster in a local system. With this in mind, we decided to go in a different direction with QueryCatcher. It works in the background to collect users’ search queries and places the onus on our system to make things happen. The goal was to allow users to create value without really knowing it. While this technique might raise concerns about user privacy, it is possible to take advantage of patron data in an anonymous fashion (these concerns will be addressed as part of “Complications and Limitations“). The “invisibility” of this process is a large reason it has proven much more successful than our user tagging module.
Implementation: Making It Work
At MSU Libraries, our library systems are built within the LAMP stack, so I’m going to walk you through the steps needed to create the QueryCatcher application using PHP, MySQL, CSS, and xHTML for markup. [3] I will describe the pieces of the application in terms of a data model layer, an application logic layer, and a display view layer. It’s my hope that in using these generic terms other developers will be able to understand the functions of each piece of the application and apply it to their programming environment of choice.
1. Data Model Layer
Our first step is to create the database that will log the queries. Think of this stage as setting up the data model layer. Here’s the CREATE table syntax for the table which will record the queries into the system.
-- -- Table structure for table `log` -- DROP TABLE IF EXISTS `log`; CREATE TABLE `log` ( `query_id` int(16) NOT NULL auto_increment, `query_data` varchar(255) default NULL, `query_results` int(6) default NULL, `query_time` timestamp NOT NULL default CURRENT_TIMESTAMP on update CURRENT_TIMESTAMP, `query_referrer` varchar(255) default NULL, PRIMARY KEY (`query_id`), FULLTEXT KEY `full_index` (`query_data`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8;
There’s nothing too unique here as the table contains fields to collect the query, the number of hits for the query, and a timestamp to help us organize the data for display. The syntax is SQL as represented in MySQL. [4]
2. Application Logic Layer
Our second step is to create the logic and insert statement that will search and record query data. At this stage, we are talking about the application logic layer that provides the searching and recording action for the ETD application. Here’s a snippet of the processing code from the results.php file:
case 1:
if($bKeyword) {
$result = mysql_query("SELECT * FROM item WHERE item_status='a' AND MATCH (dc_title, dc_creator, dc_description, dc_contributor) AGAINST ('+$keyword*' IN BOOLEAN MODE)");
$num_rows = mysql_num_rows($result);
if($num_rows == 0) {
noMatches();
} else {
//log search term query, trim whitespace and store in "log" table of database
$logQuery = @mysql_query("INSERT INTO log SET query_data='".trim($keyword)."', query_results='".$num_rows."', query_referrer='".$_SERVER['HTTP_REFERER']."'");
if (!$logQuery) {
die('<h2>Error adding query to log: ' . mysql_error() . '</h2>');
}
echo '<h3 class="results">Your search for Keyword <strong>'.stripslashes($keyword).'</strong> resulted in <strong>'.$num_rows.'</strong> match(es).</h3>'."\n";
}
}
In this example, we use a PHP switch statement to check for the existence of the keyword variable. If the keyword variable exists and retrieves results, we record the number of results in the $num_rows variable. Next, we pass those values through some logic checks and trim functions (for cleanup) and insert into the “log” table to record the query data, referrer, and total hits. It should be noted that any variables passed to the application logic layer will be passed from a simple web form and we’ll build the form in the next section.
3. Display View Layer
Our third step is to create the display view layer, which includes hooking the ETD search form into the “log” table and providing several displays for the recorded search data.
First, the search form from the main page of the ETD application must be hooked into the “log” table. We’re talking here about basic user interface (UI) design and one of the first components of the display view layer. We use post data from an xHTML form stored as variables and pass the variables along to our processing script.
<form class="search" action="results.php" method="post"> <p> <label for="keyword"><strong>Keyword:</strong></label> <input class="text" type="text" id="keyword" name="keyword" maxlength="50" size="50" /> <input type="submit" id="submit" class="submit" value="Search" /> </p> </form>
The important piece to note here is the <input name="keyword"> as it is the glue that binds the display view layer to the application logic layer. As a user enters a search term in the web form, the data is passed as the keyword variable to the results.php file which will allow for a search of the database and the recording of the query.
The next piece of our display view layer involves showing the search query data. As mentioned earlier, we currently provide two views: a search list view that shows the number of hits and the number of times the term has been browsed or searched and a “SearchCloud” view where terms are visually weighted according to the number of times they’ve been used. The xHTML markup for the pages is pretty straightforward – a <ul> unordered list tag set to display in columns for the search list view or a <p> paragraph tag with different type size settings for the “SearchCloud” view. However, the PHP logic and the MySQL queries are a bit more involved and worth noting.
Both the search list view and the “SearchCloud” view use the same MySQL query and PHP code:
//get searches that start with the current variable, place hit number and count number $query = "SELECT DISTINCT(query_data), COUNT(query_id) AS query_count, query_results, query_time FROM log GROUP BY query_data ORDER BY query_time DESC LIMIT 0,50"; $result = mysql_query($query);
Here’s what’s happening with this code sequence: The $query variable in the code block is where we store the MySQL statement that selects all unique queries (SELECT DISTINCT), places a count on the number of queries logged into the table (COUNT(query_id) AS query_count), grabs the number of results and the timestamp for the query, orders the results according to most recent timestamps (ORDER BY query_time DESC), and limits the number of results to 50 (LIMIT 0,50). Finally, the $result variable coupled with the mysql_query() PHP function actually tells PHP to run the query and store the returned data for use later in the script.
Once we have made the call to the database and recorded all the different information, we need to loop through the info and print it out to the screen as xHTML. Here’s the code from the search list view page that makes it happen:
Search List View (source: searches.php)
while ($row = mysql_fetch_object($result)) {
$search = rtrim(stripslashes($row->query_data));
$searchResults = $row->query_results;
$searchCount = $row->query_count;
if ($search != "") {
echo '<li><h2><a href="./results.php?keyword='.urlencode($search).'">'.$search.'</a></h2>'."\n";
echo '<p>Results: <strong>'.$searchResults.'</strong> hits <br/>Term searched/browsed: <strong>'.$searchCount.'</strong> time(s)</p>'."\n";
echo '</li>'."\n";
}
}
In this particular code block, the first line uses a while loop coupled with the $result variable from the previous code snippet to provide the resulting database rows from the query. As the while loop is working, we take the different field values by using the PHP function mysql_fetch_object() and format them into different variables for display ($search, $searchResults, and $searchCount). Before attempting to output, we check to make sure the $search variable is not empty using the simple if statement: if ($search != ""). Finally, we print out the different variable values as xHTML using the PHP echo() function. The key here is the while loop which will execute until it evaluates to false; in this case, false occurs when there are no more query results to print out. [5]
Finally, the display needs to be finished with CSS. At this point, I assume you know what CSS is and does. If not, there are many excellent tutorials available online. [6] However, I wanted to point out a few special CSS rules that are used to create our final view of the query data.
ul#block {float:left;width:100%;margin:0;padding:0;list-style:none;text-align:left;}
ul#block li {position:relative;float:left;width:25em;margin:0;padding:15px 0 15px 15px;}
ul#block li h2 {font:1.1em georgia,times,serif;color:#444;margin:0 0 15px 0;}
p#tagCloud {padding:25px 0;}
p#tagCloud a.size1 {font-size:.95em;}
p#tagCloud a.size2 {font-size:1.1em;font-weight:bold;}
p#tagCloud a.size3 {font-size:1.2em;font-weight:bold;}
p#tagCloud a.size4 {font-size:1.3em;font-weight:bold;}
p#tagCloud a.size5 {font-size:1.5em;font-weight:bold;}
p#tagCloud a.size6 {font-size:1.6em;font-weight:bold;}
p#tagCloud a.size7 {font-size:1.7em;font-weight:bold;}
p#tagCloud a.size8 {font-size:1.8em;font-weight:bold;}
p#tagCloud a.size9 {font-size:2.5em;font-weight:bold;}
The first CSS snippet, ul#block, creates the columns effect for the search list view (source: ). The second CSS snippet, p#tagCloud and the a.size class, creates the wrapper element and font sizes for the “SearchCloud” view (source: searchcloud.php).
Complications and Limitations
There are always complications in the process of implementation. MSU Libraries has not contacted parties to let them know of our “reuse” of the query data. We are careful not to log IP addresses or personal info in our recording processes, but some libraries may wish to be more transparent with their patrons. A simple note on the homepage of an application using this technique briefly explaining the process could go a long way to alleviating any patron concerns. Another complication is the growing datasets that go along with logging each and every query into the system. Since the introduction of QueryCatcher in October 2007, we have logged over 37,000 queries into the system. [7] As the mountain of data has grown, there became a need for a cronjob specifying a mysqldump of the log table along with a DELETE and new table CREATE statement to start the process over again. We are currently running this cronjob to create a query log archive once a month. A related limitation is that the size of the recorded data informs the amount of data that can be displayed at any given time. We’re restricting the display views to the last 50 queries recorded to alleviate some of this pressure.
Updates and Future Work
So, how is the experiment working out? There has been some measurable success in the use of the QueryCatcher pages to access the ETD collection. Both the searchcloud.php and searches.php have continually appeared in the top 15 urls for the ETD site. Both pages have also appeared as 2 of the top 8 entry pages to the ETD collection for the last five months. This indicates that transparency of search terms can be a useful access point and the trends within our statistics suggest that continued use and growth is likely.
Continued growth brings new challenges and motivation to enhance these tools. One of our first steps will be to write a programming function to “de-dupe” the query log and only record unique searches. 37,000 logged queries shows some impressive use of the system, but the number of duplicate queries make for a lot of noise. We’d also like to create a more long term view of our most popular searches over time as a query archive for users to browse and use. Other possibilities include using the collected data to suggest possible search terms in real time via an Ajax autosuggest solution and building “did you mean?” functionality that looks for successful searches using similar terminology when users get few or no results.
We feel we are just getting started and the possibilities for the query data remain to be fully tapped.
Conclusion
Libraries and their corresponding organizational systems and applications are complex because the information that we collect and represent is complex and varied. That’s a fact and it’s not going away. While we need to respect this complexity, it is also beneficial for us to recognize that giving up some control over “how” users access our collections can create added value that we couldn’t build on our own. Experiments like QueryCatcher where users are allowed to contribute their own terms as browseable access points are small steps in this direction. Let’s see what else our development community can imagine.
Code
There are six files available. Download zip (25.2 K)
- querycatcher.sql – the database CREATE statements
- form.php – the xHTML form for querying the database
- results.php – the search processing and query recording instructions
- searches.php – the search list display view
- searchcloud.php – the SearchCloud display view
- styles.css – the master styles
Notes
[1] Battelle, John. (2006). The Search: How Google and Its Rivals Rewrote the Rules of Business and Transformed Our Culture. Portfolio Trade. ISBN: 1591841410. pp. 2-5.
(COiNS)
[2] The most perfect expression of Battelle’s “Database of Intentions” is the Google Zeitgeist available at http://www.google.com/press/zeitgeist.html. It includes trends and analysis of queries logged into the Google systems.
[3] There are always other scripting languages and database engines. Ruby on Rails, ASP, PostgreSQL, even SQLite could be used as the backbone for this application. It’s really up to you.
[4] See W3C schools for a nice intro to SQL: http://www.w3schools.com/sql/. The MySQL documentation is available at: http://dev.mysql.com/doc/
[5] I’m not including the code snippet from the “SearchCloud” view as the similarities make it a bit redundant. The only real difference is the added $searchWeight variable which is used to provide the different font sizes for the weighted “SearchCloud”. Here’s the code for those that are interested:
“SearchCloud” View (source: searchcloud.php)
while ($row = mysql_fetch_object($result)) {
$search_id = $row->query_id;
$search = rtrim(stripslashes($row->query_data));
$searchCount = $row->query_count;
$searchWeight = $searchCount;
if ($searchWeight > 9) { $searchWeight = '9'; }
if($search != "") {
echo '<a id="'.$search_id.'" class="size'.$searchWeight.'" title="'.$search.' has been searched/browsed: '.$searchCount.' time(s)" href="./results.php?keyword='.urlencode($search).'">'.$search.'</a>'."\n";
}
}
[6] If you aren’t sure and want to learn more about CSS (Cascading Style Sheets), visit the W3C tutorial at http://www.w3schools.com/css/
[7] Data recorded on June 3, 2008.
About the Author
Jason A. Clark builds library web applications and sets digital content strategies for Montana State University Libraries. He writes and presents on a broad range of topics ranging from open source applications to interface design and metadata. When he’s not thinking about APIs and other geeky stuff, Jason likes to hike the mountains of Montana with his wife, Jennifer, and their dog, Oakley. If you would like to contact him, his Web site is http://jasonclark.info/.

Subscribe to comments: For this article | For all articles
Leave a Reply