by Stephen X. Flynn, Catalina Oyler, Marsha Miles
The open access movement offers academic libraries an opportunity to play an integral role in promoting and preserving faculty scholarship. Although institutional repositories (IR) are prevalent among academic libraries, one challenge identified in a 2012 Confederation of Open Access Repositories report is that populating repositories is staff intensive (COAR, 2012). Faculty are often recruited to submit their manuscripts to IRs, but this has led to low participation rates at some institutions. (Jihyun, 2011) The majority of staff work involves determining what articles faculty have published, and whether or not libraries may upload the publisher’s version of those articles to the IR. This article describes two scripts developed at Oberlin College and the College of Wooster. One script packages author affiliation database searches into a Dublin Core metadata batch load, and another identifies journal copyright policies in SHERPA/RoMEO to help staff determine which journals permit the published PDF to be uploaded to a repository. We describe how we used both scripts at the College of Wooster to streamline importing faculty article metadata and uploading the published version of a PDF into an IR.
Batch loading faculty article metadata
At the College of Wooster, we implemented a metadata batch load script developed in 2010 at Oberlin College Library. Library staff manually entered metadata into their IR, Oberlin SHARES (Sciences, Humanities, and Arts: Repository of Expression and Scholarship), from faculty curriculum vitae (CV), copying and pasting or re-keying information into an online form. This process was time intensive, and they looked to alternative sources for metadata on faculty publications, specifically reference management software, that was able to bulk ingest citations from journal databases. Eventually, Refworks was selected to gather their citations as it was already used on campus and, unlike other software considered, offered an easy XML export function. The data could then be transformed into Dublin Core using an XSLT script and ingested by DSpace.
Importing data into RefWorks involved running an author affiliation search in large index databases such as EBSCO, Scopus and Web of Knowledge, then exporting the results to RefWorks and using RefWork’s deduping feature.
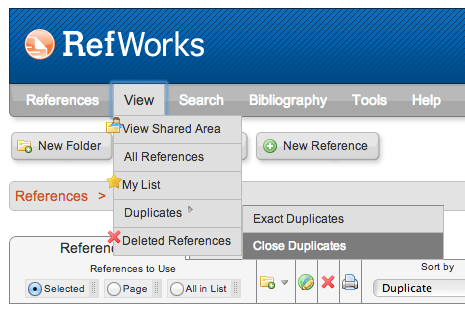
Figure 1. RefWorks’ duplicate detection feature made it possible to run author affiliation searches in multiple databases, export to RefWorks, and delete duplicates.
We first generated a schema for the RefWorks XML and then created an XSLT stylesheet to transform the XML into Dublin Core ready for import into DSpace. Once finished, these documents can be used to run the transformation multiple times to continue adding recently published articles to the database. When run, the XSLT completes three tasks: dividing the single RefWorks file into multiple Dublin Core records, mapping RefWorks elements to their equivalent Dublin Core fields, and cleaning up the exported text.
The division of the RefWorks export into multiple Dublin Core files is accomplished with a simple xsl:result-document command. To match the DSpace upload format, these documents are all titled as dublin_core.xml and placed into sequentially numbered folders, also generated by the XSLT. A blank contents folder is also generated and included in each number folder for the upload process as well.
In most cases, the map from RefWorks XML to Dublin Core is clear with a one-to-one transformation for fields such as title, contributor, abstract, publisher, digital object identifier (DOI) and others. The single field that involved multiple mappings is the citation in Dublin Core (dc.identifier.citation). The citation field brings together data from various RefWorks fields and creates a single well-formatted reference to the article despite the many variables in the metadata itself, such as number of authors and the possibility of missing fields.
In addition to mapping fields, the field contents are also transformed in this process. The text from the RefWorks export varies in quality, but the XSL transformation corrects the most common errors. These corrections include changing titles, publishers, and journals from all capitals into title case, and replacing corrupted HTML character codes. Further changes include ensuring authors are listed with their last name first, changing dates to numerical year-month-day format, translating given languages to their ISO code, checking that DOIs are correctly formatted for linking, and removing stray characters that occasionally appear. In addition, fields that are consistent for all records are written by the stylesheet, such as dc.type which is set to “article” and the institution name.
<!-- Author field -->
<xsl:for-each select="a1">
<dcvalue element="contributor" qualifier="author">
<xsl:choose> <!-- Adds a space after the comma that seperates first and last names -->
<xsl:when test="contains(.,',')">
<xsl:variable name="last" select="substring-before(.,',')"/>
<xsl:variable name="first" select="substring-after(.,',')"/>
<xsl:value-of select="concat($last,', ',$first)"/>
</xsl:when>
<xsl:otherwise>
<xsl:apply-templates/>
</xsl:otherwise>
</xsl:choose>
</dcvalue>
</xsl:for-each>
Figure 2.The XSLT script standardizes author metadata from a RefWorks XML export into Last Name, First Name (with a space after the first comma).
The text corrections catch the majority of errors in the exported records, but staff members still need to double check the imports. Errors that have passed through the transformation include unexpected or new stray characters and corrupt HTML character codes, typos from the original records, and incorrectly associated information, such as an abstract from a different record. In our workflow, we loaded the XSLT output into DSpace before reviewing the data for errors, but this step should be completed at an earlier point in the process. While staff time is still required to run the script, load, and review records, this process removes the largest burden of work by automating the record creation.
Automating journal copyright policies
In addition to obtaining metadata, there are copyright issues to consider when archiving faculty articles. The rights of authors to self-archive and post their work in an IR vary among publishers. Some allow authors to post their published PDF to a repository, some only permit the posting of author pre-prints (the version of an article before peer review), while others restrict all author self-archiving. Determining the copyright policy of every journal in which faculty have published would be time consuming. We created a script in Google Docs that searches SHERPA/RoMEO, a database of publisher copyright policies, to determine whether or not a journal permits authors to upload published PDFs to IRs.
Scripting journal copyright policies
After using Refworks and XSLT to batch load the College of Wooster faculty’s article metadata into our IR, we exported the resulting metadata into a Google Docs spreadsheet with columns for author, journal title, article title, and the journal’s ISSN. SHERPA/RoMEO provides an API that allows developers to link journal copyright permissions into their software, by sending an HTTP request to SHERPA’s server which then returns XML data. We used Google Apps Script, the scripting feature built into Google Docs, to write JavaScript functions that, when invoked in a spreadsheet cell, search journal copyright policies in SHERPA using the ISSN numbers from our spreadsheet.
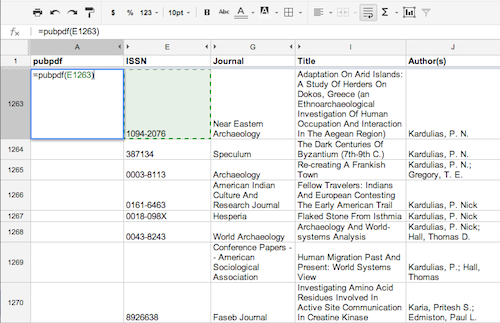
Figure 3.Invoke the pubpdf() function and select the corresponding ISSN field.
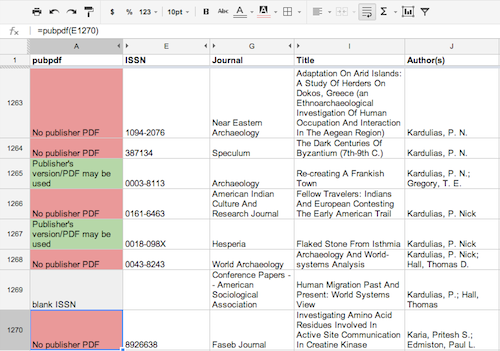
Figure 4.Copy the function down the list and pubpdf() will automatically check SHERPA/RoMEO for whether the journal permits archiving the publisher version.
The script performs the following (see Appendix A for source code):
- Inputs the journal’s ISSN.
- Sends a GET request to SHERPA/RoMEO’s API with the ISSN embedded.
- Retrieves XML from SHERPA/RoMEO containing the journal’s policies.
- Parses the XML looking for <pdfarchive>can</pdfarchive> which broadly indicates the journal’s willingness to permit uploading their published PDFs into a repository.
- Returns a “yes” or “no” statement to the spreadsheet.
- A secondary function also searches for the word “embargo” anywhere in the XML, and returns a “yes” if found. This would be run in a separate column.
With over 2700 articles written by College of Wooster faculty discovered in our library databases, this script allows us to determine which article PDFs we have permission to upload to our IR at a far greater speed than manually searching journal copyright permissions.
Limitations in the script
The script is not completely automated. Our staff must double check every article marked “Publisher’s version/PDF may be used”. For example, the American Journal of Physics permits authors to archive publisher PDFs on their personal website, but not on an e-print server or institutional repository. Other journals have similar restrictions that are not universally keyed the same way in SHERPA/RoMEO’s XML feed, and thus need to be double checked.
In addition, Google limits how often you can run the script. Google’s UrlFetchApp() function, which we used to fetch the XML from SHERPA/RoMEO’s API, is limited to 20,000 calls per day. We encountered errors running the script on all 2700 articles at once. An ideal solution would be to cache multiple responses coming from the same journal. Right now, if a spreadsheet contains 20 articles published in Journal of Chemical Physics, the script will retrieve and parse the XML for each of those articles, twice over if we’re also checking for embargo language. Using Google’s ScriptDb() function, we could cache a journal’s policies so that the lookup only occurs once, greatly increasing the speed. We haven’t yet developed this capability.

Figure 5.Google Script doesn’t permit running a call excessively in a short period of time.
Finally, Google spreadsheet cells containing a function will recalculate if the browser is refreshed or the sheet resorted, which would increase the likelihood of exceeding the daily limit. The workaround we use is to copy the results into their own cells by copying and pasting the values under the Paste special menu, or creating a “static” column to paste the values.
Implementing the script using student assistants
After testing the script on a small list of faculty publications, we ran it on a complete list with the help of our student assistants. We sorted the Google spreadsheet by ISSN, which groups multiple articles from the same journal together. Due to some bad metadata on initial import, such as combining an ISSN and ISBN number in the same field, we couldn’t determine the journal copyright policies of certain articles, and skipped over them with the goal of cleaning up metadata during a second phase of our project. Attempting to run the script on more than approximately 100 articles at a time resulted in a “Service invoked too many times” error message described above. Our student worker completed the steps in Appendix B in small batches.
We created a second sheet in the spreadsheet to collect what we term “green” articles, or the articles that SHERPA/RoMEO says can be archived (pre-print, post-print or publisher’s version/PDF). The student sorted the spreadsheet by the permission column and copied the “green” articles to the new sheet.
As stated previously, we double-checked the permission language of “green” articles. Also, language inconsistencies prevent the script from being accurate enough to catch all of the embargoed articles. Because we have to check the articles manually on SHERPA/RoMEO to determine if the article is in fact a “green” article, we saved time by not having the student copy and paste the embargo detection script.

Figure 6.We double check permissions on the SHERPA/RoMEO website, since some journals attach conditions to the use of their published PDF, such as requiring that you link to the journal’s home page.
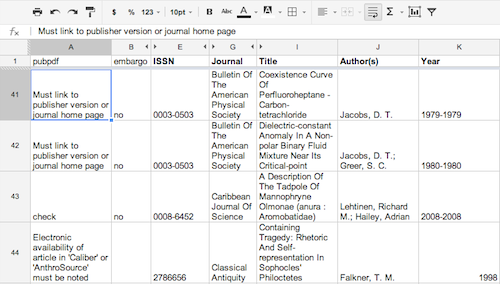
Figure 7.We insert copyright caveats into our spreadsheet.
Ideally, the script would automatically load the “General Conditions” section from each SHERPA/RoMEO record into the spreadsheet to eliminate having to manually check each one on the website. However, using the script as currently written still saves time. By ignoring journals that do not permit archiving published PDFs, we can focus on journals that do. After double checking the permission language, we add articles to a new sheet called “Articles to Find,” and the student searches for and downloads article PDFs from library databases.
Local PDF archiving file naming
When article PDFs are downloaded, we give them a more meaningful file name. The College of Wooster adapted the file naming structure used in Oberlin College’s SHARES collection. The file name is built using the first-listed local author’s last name and a brief part of the article title. The volume number and issue number (or year if used by the journal in place of issue number) are included to prevent the possibility of any duplicates if the author published an article with a similar title.
Because we batch load article metadata in our repository independently as a first step, adding PDFs to DSpace is as simple as attaching the corresponding publisher PDFs as bitstreams to the item records. For a second phase, we plan to fill in missing ISSNs and fix other metadata issues, an inevitability when working with automated data. Finally, in future years we will batch load that year’s faculty publications and check SHERPA/RoMEO for PDFs we can upload.
Conclusions
Our goal at the College of Wooster was to streamline the process of populating our IR. The Refworks XSLT script developed at Oberlin College helped us quickly create Dublin Core metadata for our faculty’s articles to batch load into DSpace, and our SHERPA/RoMEO script helped us determine the articles published in journals that allow PDFs to be uploaded to an IR. Despite being slightly cumbersome to use, it is a significant improvement over completing these tasks manually.
Our workflow is specific to some products, such as Refworks 2.0, DSpace 1.6 and Google Docs, but this process could be altered to work with other systems. One could first perform an author affiliation search in Web of Knowledge, upload the resulting spreadsheet to Google Docs, identify your “green articles” using the SHERPA script and then batch load those PDFs directly into a repository, with metadata attached. An upgrade to DSpace 3.0 would allow the ability to batch import metadata from common bibliographic formats including Endnote, RIS and .csv files directly into a repository.
Uploading our faculty’s published PDFs to our IR is one step we are taking to promote open access to faculty scholarship. We will eventually recruit author pre-prints from the faculty, and our SHERPA/RoMEO script can easily be retooled to look for faculty articles in journals where pre-print and post-print archiving is permitted. Using this information, libraries could focus their recruitment efforts on faculty with large numbers of pre-print eligible articles.
We haven’t yet formally assessed the impact of our fledgling IR on faculty attitudes towards the role of libraries in scholarly communications, but we look forward to reading comments and suggestions from faculty, librarians and technologists who might use our two scripts to streamline populating an IR.
References
“Preliminary Report – Sustainable Best Practices for Populating Repositories” Confederation of Open Access Repositories. 2012 [http://www.coar-repositories.org/working-groups/repository-content/preliminary-report-sustainable-best-practices-for-populating-repositories/]
Jihyun, Kim. “Motivations of Faculty Self-archiving in Institutional Repositories” The Journal of Academic Librarianship. 37:3. 2011
“Batch import from basic bibliographic formats (Endnote, BibTex, RIS, TSV, CSV)” DuraSpace Issue Tracker. [https://jira.duraspace.org/browse/DS-1226]
Appendix A – Source Code
RefWorks XML to Dublin Core transformation script
Download the .zip file which contains detailed PDF instructions and the original source code:
https://sites.google.com/site/drmcbackup/documentation/batch-submission-from-refworks
SHERPA/RoMEO Script source code
Copy the code here – http://pastebin.com/sXknBHDq
In Google Spreadsheets, go to Tools -> Script Editor, and paste the entire script, replacing the myfunction() placeholder. If you plan on using the script in a project, you will need to register an API key with SHERPA/RoMEO (link included in the source) and insert it into the script as indicated, or else your XML requests may time out. If you experiment with a small number of records, an API key won’t be necessary.
Appendix B – IR script instructions provided to students
In addition to the metadata fields imported from RefWorks, we added “pubpdf” and “embargo” columns to run the pubpdf() and embargo() functions, and columns next to each where we paste the static values to prevent the script from running excessively.
Phase I
1. Open the IR_collection spreadsheet on Google Drive
2. Select cell A2 and type: =pubpdf(
3. Click on cell E2 (ISSN column) and hit return
4. Copy cell A2 down approximately 100 rows
5. Copy the results and select cell C2 in the “PDF static” column
6. Go to the Edit menu and select Paste special ? Paste values only
7. Delete the results from the “pubpdf” column
8. Continue steps 2-7 for the rest of the spreadsheet
9. Sort by the “PDF static” column
a. Add the green rows to the “Green Articles” sheet
10. Sort by the “Journal” column
11. Double check the permission language
a. Update the “PDF static” column if needed
12. Search for PDFs for articles on the “Green Articles” sheet
a. Rename the files
i. Lastname_Partoftitle_vol#_iss#.pdf
b. Add the file name to the “Green Articles” sheet
13. Add PDFs to the corresponding metadata in the IR collection
Phase II
1. Find ISSNs for articles on the spreadsheet that were missing ISSNs
2. Fill in other missing information (journal titles, etc.)
3. Complete steps 2-9 above for these articles
About the Authors
Stephen X. Flynn (http://www.sxflynn.net) is Emerging Technologies Librarian at the College of Wooster in Wooster, Ohio. He also created OpenCoverLetters.com, a repository of successful cover letters for library jobs.
Catalina Oyler is a Technical Support Specialist for ORCID (Open Researcher and Contributor ID). Previously she worked as Digital Initiatives Coordinator for The Five Colleges of Ohio.
Marsha Miles is the Digital Initiatives Librarian at Cleveland State University in Cleveland, Ohio. Previously, she was the Visual Resources Curator and Digital Services Associate at the College of Wooster in Wooster, Ohio.

Tom at ISO15926, 2013-11-13
Excellent, I wasn’t aware of the SHERPA API – exactly what I need. Thanks for such a thorough write up.
Lilly, 2014-06-26
Hi there,
I am very interested in this article. The link to the code, specifically, “RefWorks XML to Dublin Core transformation script” doesn’t work anymore, could you please email me the code?
Thank you very much,
Lilly
Stephen Flynn, 2014-07-21
A backup of the file can be found here https://sites.google.com/site/drmcbackup/documentation/batch-submission-from-refworks
Thanks for bringing this to my attention.
Steve Johnson, 2014-11-18
The backup site is available, but Google returns the same 415 error when one attempts to download the scripts.
Thank you,
Steve Johnson
Stephen Flynn, 2015-02-23
I apologize for the links being down. Here is a mirror copy – https://archive.org/details/refworks2dc