By Heather Gilbert and Tyler Mobley
Introduction
In 2009 the College of Charleston, with support from the Gaylord and Dorothy Donnelley Foundation, built the Lowcountry Digital Library (LCDL), the first digital library in the Lowcountry region of South Carolina. The goal was to create a regional scanning center and digital repository that would partner with cultural heritage institutions in the area and feed into the South Carolina Digital Library (SCDL). The University of South Carolina digital collections uses CONTENTdm and SCDL, at the time, utilized the CONTENTdm multi-site server as a means of aggregating content from across the state. Therefore, CONTENTdm and LCDL were a natural fit. Over the next two years LCDL evolved into a licensed, self-hosted installation of CONTENTdm with a homegrown content management system/PHP overlay site that allowed for the growing number of project partners to have some institution-specific branding features applied to their display pages.
By 2011, LCDL had over 12 project partners and almost 50,000 items digitized. LCDL’s current CONTENTdm license was limited to 50,000 items. CONTENTdm defines items as single scans. Compound objects are counted as the number of scans plus one for the compound object record. The next and last tier available to LCDL in licensing was the unlimited license. This license allows an organization to upload an unlimited number of items. LCDL staff and library administrators were faced with the costly decision of committing to CONTENTdm and purchasing the unlimited license, a one time cost upwards of $40,000 with annual maintenance fees upwards of $9,000, or looking for other solutions. The easy answer would have been to invest in the unlimited license; however, even at less than 50,000 items, there were already obvious problems with the existing system, including server-side software issues and inaccurate search results. The College decided the CONTENTdm upgrade was not only expensive, but also would not solve these system problems, and focused on the viability of available open source options.
Assessment
The authors of this article, Heather Gilbert and Tyler Mobley, were tasked with assessing the existing system and evaluating potential solutions. Heather Gilbert, Digital Scholarship Librarian for the College and Project Coordinator for the Lowcountry Digital Library is an experienced graphic designer and web developer who had some background in software evaluation. At the time her existing strengths were in HTML, PHP and CSS, with metadata experience in Dublin Core and VRA. Between her previous experience with web development and her current position as LCDL Project Coordinator, Ms. Gilbert was the natural choice to focus on metadata migration and front-end development. Tyler Mobley, Digital Services Librarian, focused his efforts on discovery and repository evaluation and implementation. His experience at that time focused on open source research and web development with strengths in HTML, CSS, PHP, and JavaScript. Additionally, he is the resident XML/XSLT specialist in the library after working with Special Collection’s EAD finding aids and their transformation for online access. He was also one the library’s few Linux server managers, so new software and its installation fell in his area.
After careful evaluation of the existing system, we determined that replacing the existing LCDL would require four components: a text file based data ingestion method, repository storage, a discovery layer and/or a partner-branded website. Our original system was set up as indicated in Figure 1.
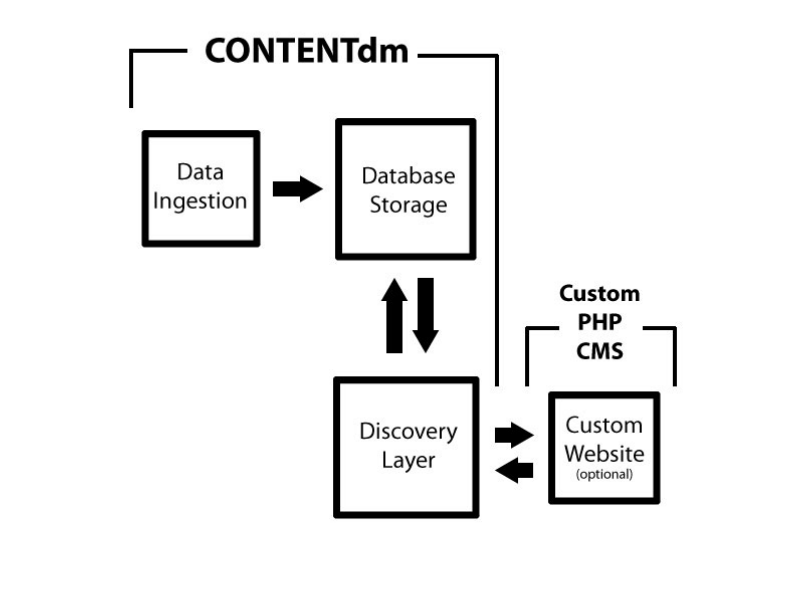
Figure 1. Original Lowcountry Digital Library system architecture.
After assessing our current system, four options were evaluated as potential replacement solutions: Omeka, DSpace, CONTENTdm’s unlimited license and the build-your-own model.
At the time of the evaluation, Omeka 1.2 was the current release with version 1.5 on the horizon. Omeka was already familiar to us, as we had been evaluating it for numerous purposes in the library. However, we could not find any instances of it “in the wild” that contained collections of our size, (50,000 items or more), and we were concerned about its scalability. We also knew that with our variety of file types and the number of partnering organizations, Omeka would not be an ideal option. We decided that while Omeka would work well as an exhibition platform, we still needed a digital asset management system (DAMS) to support the digital library. In fact, we are now using Omeka as that digital exhibition platform and we have successfully linked to our new LCDL Fedora instance.
DSpace was considered and we found that it was functional enough to serve as a secondary option if other solutions failed. We could not find examples of other cultural heritage-based digital libraries using DSpace, and we became concerned that it could not fully meet our needs. The DSpace digital library examples we found employed basic layouts that did not offer enough structural and display options for our diverse archival content. LCDL specifically requires a flexible, visually consistent image viewer that can handle both single and compound objects as well as inline transcript views and image zooming, and we could not find representative examples in DSpace. Though we considered heavily customizing DSpace, the work involved to do so would have been daunting, and not worth the effort over the other obvious options of either upgrading our existing CONTENTdm installation, or evaluating open source software elements to build out our own content management system.
As stated previously, CONTENTdm’s unlimited license would have been the obvious answer to our problems. However, there were several strong reasons against the CONTENTdm upgrade. LCDL was running CONTENTdm 5.1 and the PHP overlay site and all of its customizations were dependent upon that version. There was a very strong possibility that our homegrown CMS would break with the upgrade to CONTENTdm 6.x. Additionally, the systems librarian who had created that CMS had moved on to another position and was unavailable for consultation. We had also experienced negative performance from CONTENTdm support over the years, specifically long wait times on troubleshooting tickets and several times no solution offered to our technical issues, and found both the CONTENTdm user search interface and results display to be disappointing and inconsistent. We had received over the last year consistent complaints from users about the search interface and their search results. Often queries would retrieve zero results, inaccurate results or inconsistent results from query to query, for both amateur and experienced users (including the team members on this project). The “refine search” facets displayed on the results page were also problematic. The only refine options were subject, creator and date and not all of those results would display. In our experience, CONTENTdm provided the user with sporadically inaccurate search results and a poor ability to refine those result. We believed we could do better.
The Final System – What & Why
Eventually, we stopped evaluating whole DAMS and started looking towards filling in our system set-up diagram (Figure 1) with open-source pieces that could work together to fulfill our needs. The digital library we built was constructed from four open-source pieces that together form a complete replacement for our original system. Our final architecture for the project was comprised of OpenWMS — Rutgers’ (RUcore) Fedora ingestion client, a Fedora Commons repository, a Blacklight discovery layer and Drupal, serving as the partner-branded, functional project website.
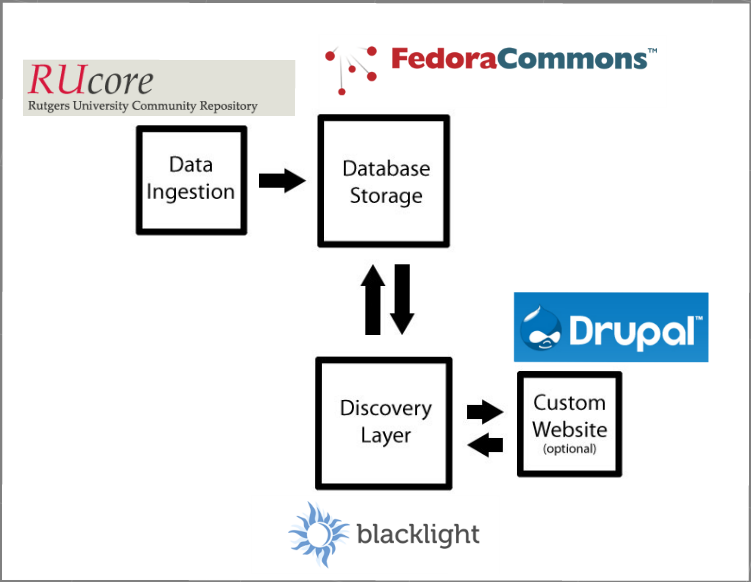
Figure 2. Replacement Lowcountry Digital Library system architecture.
Repository
We installed a Fedora Commons repository, version 3.4.2, for LCDL storage and preservation. The Fedora Commons repository architecture is scalable to millions of items and should provide the region enough room to grow for the foreseeable future. Fedora’s digital object model provided a well-organized package for metadata and accompanying digital content as we migrated from CONTENTdm. As our items continue to migrate to Fedora, we gain the flexibility to reuse them in additional applications (like Omeka’s Exhibit Builder) by pulling objects via Fedora’s web APIs. We also have future plans to pursue adding further XML formatted documents in the form of EAD finding aids. Furthermore, upon migration, we found that Fedora stored objects more efficiently than the previous system, leaving us more server storage than expected.
Ingestion
Ingestion proved to be the most difficult feature to acquire. There are surprisingly few ingestion clients available in the open-source community that allow for batch ingestion of items from tab delimited text files into a repository. With our broad range of project partners, their varying levels of technical skill, and our lack of funding for a full-time metadata librarian, it was imperative to maintain the ease and use of spreadsheets for metadata creation, review and storage. The only option we found was OpenWMS from Rutgers. We installed and are still running their beta version software for ingestion.
Website
As the LCDL is comprised of a growing number of partners from across the region, the ability to apply institutional branding styles to different sections of the LCDL website is a necessity. We chose Drupal for several reasons, not the least of which was its ability to offer easy, changeable theming based on taxonomy terms. It also allowed us the option of creating blogs for each of our partner institutions that could then feed into a single LCDL group blog. In addition, Drupal has a proven track record of stable releases, an enormous community of users, and a growing database of contributed modules that offer a wide variety of functionalities, which ensures us that this system will be capable of sustaining LCDL’s future growth.
Discovery Interface
Search and discovery features were limited and often ineffective in CONTENTdm. Known items were hard to locate, and search results retrieval was slow. Most importantly, we lacked granular control over the display fields and facet limits presented by the search results. After some exploration, we decided that the Solr-powered Blacklight discovery interface, combined with additions from the Hydra framework, would allow us to gain the kind of fast and effective searching we desired. The Hydra project is a multi-institutional collaboration that offers a customized implementation of Blacklight integrated with Fedora Commons. Hydra provides full CRUD operations and can be used as a full management solution for a Fedora Commons repository. However, as we were already using another solution for management, our instance of Blacklight primarily uses those components of Hydra that allow us to index content from Fedora Commons to the Solr search index. The greater control these systems gave us over search results and display options also allowed us to fine-tune overall discovery results. Given the regional specificity of the kinds of items currently in LCDL collections, the ability to choose facets helps us guide our users more effectively to the content they need.
Implementation — Front End
We first became aware of Drupal as a front end website option for digital libraries (specifically CONTENTdm) in 2011, when North Carolina Digital Heritage Center gave a presentation at the Southeast CONTENTdm Users Conference. They gave a compelling presentation on the benefits of Drupal, and we attended our first DrupalCamp a few months later. Despite the significant learning curve involved in setting up Drupal, this system was our first and only real candidate to replace our in-house CMS for LCDL. We did look into other content management systems, including WordPress and Concrete5, but the active user community, extreme flexibility and extensive online support network Drupal offered made the decision easy. Another benefit we found with Drupal for this project was the option to purchase an affordable support package if we needed it. This gave us options for troubleshooting in the future if the support required for Drupal proved too overwhelming for our staff.
Once we established the back end of Drupal for LCDL purposes, construction was fairly simple. We built taxonomies based on media types and institution names. We also developed custom content types for collections, institutions, lesson plans and featured image sliders. Using the Drupal module ThemeKey allowed us to apply custom themes based on taxonomy type. Our blog entries, collection home pages, and institutional home pages all have taxonomy terms applied to them, which makes theme association with our partner’s content simple to apply. Blacklight had to be styled to blend fairly seamlessly with the Drupal front-end. While we wanted to keep the website and catalog installations separate, we did not want users to feel lost in their browsing and searching routines. Our Drupal home page and institutional home pages throughout the site include custom search queries that link to Blacklight catalog search results.
The implementation of Blacklight as a discovery interface for the new system presented a number of challenges inherent to open source projects. While we wanted to improve on the item displays and search results offered through CONTENTdm, no open source project could provide a complete out-of-the-box replacement to our current system in terms of bulk features and functions. If we wanted better displays, we had to create and customize them ourselves. This lack of a proprietary system structure means that no two instances of Blacklight are entirely alike, so solutions are often specific to the institution. This aspect of open-source development is often misunderstood. Open source projects can provide you with a solid starting point and the tools to solve your problem, but you have to customize the project to meet your needs. Our difficulties were compounded by the fact that we had limited experience when it came to development in Ruby, the language used for Blacklight construction. This meant that the discovery development process regularly became an impromptu learning experience.
As our installation of Blacklight/Hydra allows us to index metadata from Fedora into a Solr search index, much of the time spent in implementation involved mapping all possible variations of object metadata that would come from Fedora. Additionally, an export from CONTENTdm does not provide the structural metadata for translating the logic required for compound objects like books, pamphlets, and postcards. Our version of CONTENTdm, 5.1, lacked the APIs available in more recent versions to export more robust data. Such objects account for a large portion of LCDL, and our users are accustomed to being able to read through such objects in a single viewer online. We had to recreate this compound object functionality as smoothly as possible. Other features like inline page transcripts and image zooming also had to be recreated. These features have all been successfully integrated into the new system without the need for Adobe Flash, which was a problem in the earlier CONTENTdm system due to Zoomify customizations that were previously implemented. These zoom features were very popular with our users, so we wanted to keep them while improving accessibility.
Implementation – Back End
The complications of implementing a Fedora Commons repository for the new instance of LCDL were more practical than they were technical. For an installation of our size, configuration and installation of Fedora is fairly straightforward. However, given the limited level of resources we possessed, issues of storage and access proved to be the biggest headaches.
Our installation of Fedora Commons currently resides in an Apache Tomcat servlet routed through IIS 7 on a Windows 2008 server installation. This server also holds our previous CONTENTdm installation. When it came time to find a publicly accessible home for Fedora (in early 2012), the library had limited server and storage hardware. This Windows server was the largest (and most freely available) we had, so we decided to phase in Fedora as we phased out CONTENTdm on the same server.
In the Spring of 2012 we acquired new server and storage hardware in the library, so we are now in the planning stages of migrating the current installation of Fedora to a Linux server as soon as possible. While Fedora itself functions well in Tomcat on a Windows machine, we have run into complications from running Tomcat through IIS and its communication with other Linux servers.
After we determined our repository architecture and began implementation, we started to look for ingestion clients. In hindsight, this was not the ideal order that process should have taken. We had particular needs for an ingestion client that had to maintain the ease of use that CONTENTdm previously offered our project partners for ingesting diverse archival materials. This meant that one requirement for our ingestion client would be the ability to batch ingest from a spreadsheet (ie: tab-delimited text files). At this point our inexperience with DAMS construction almost created serious problems and we found the task of identifying an ingestion client more challenging than expected. When we looked for an ingestion method, we found that most ingestion clients were either designed for the 2.x Fedora release (Elated, Fez) or were still in the planning stages and would eventually become something unrelated to our project needs (e.g., Ensemble). The only ingestion client that met enough of our needs to suffice was OpenWMS from Rutgers. OpenWMS is a web-based metadata client that allows the user to ingest and export metadata and digital objects into and out of Fedora. It provides a direct, web-based interface for collection, sub-collection and single item creation as well as batch import and metadata mapping. OpenWMS allows for the ingestion of tab-delimited text files of metadata and converts those files into Fedora Object XML (FOXML) encoded records. OpenWMS then creates a packaged directory that is ready for Fedora.
Most importantly for us, and one of the reasons why we still use it as an ingestion client today, is that OpenWMS allows the user to import metadata using an in-house schema. At the time of adoption, OpenWMS only allowed the user to map from an in-house schema, MARC, or MODS (the stable release now allows a variety of schema). LCDL’s CONTENTdm metadata schema was Dublin Core based. Over the years LCDL’s Dublin Core had ballooned up to over sixty elements and upon review, it appeared that over one third of these elements were outright duplicates or variants upon existing fields. Using the OpenWMS system to ingest our items into Fedora required that our CONTENTdm metadata be made mappable from Dublin Core to MODS (OpenWMS’ underlying descriptive metadata schema). However, we viewed this requirement as both a justification and excellent opportunity to rectify the earlier metadata of our digital collections. This labor-intensive rectification (which at the time of this writing is about half-way complete, with only 25,000 more items remaining) has yielded significantly more accurate metadata. This rectification is also making our upcoming inclusion into the Digital Public Library of America (DPLA) easier as we are already correcting most of the metadata inconsistencies that early DPLA quality assessment and quality control have uncovered.
However, our experiences with OpenWMS were not perfect. The beta release was buggy (which is of course to be expected) and the manual was still under construction at the time we installed it. Initially metadata record creation and upload was very trial and error, and getting the FOXML to generate correctly from batch imports was somewhat difficult in the beginning. We did eventually learn how to batch populate related MODS fields, such as
Before and After – Comparison Screenshots
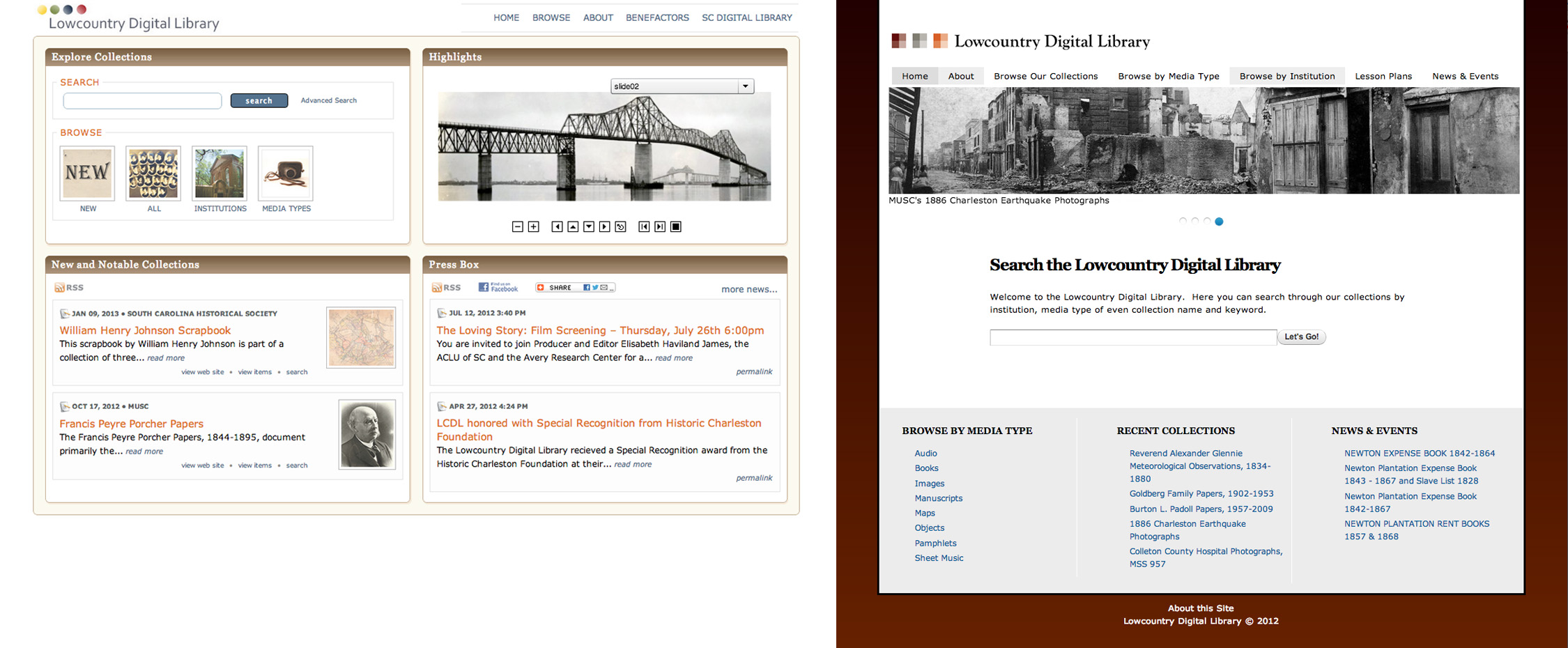
Figure 3. Home page before (left) and after (right).
The new Drupal homepage shown in Figure 3 (“After”) is cleaner and features a Blacklight search form prominently. It is also responsive and touch enabled where the “Before” version was Flash dependent and not mobile friendly.
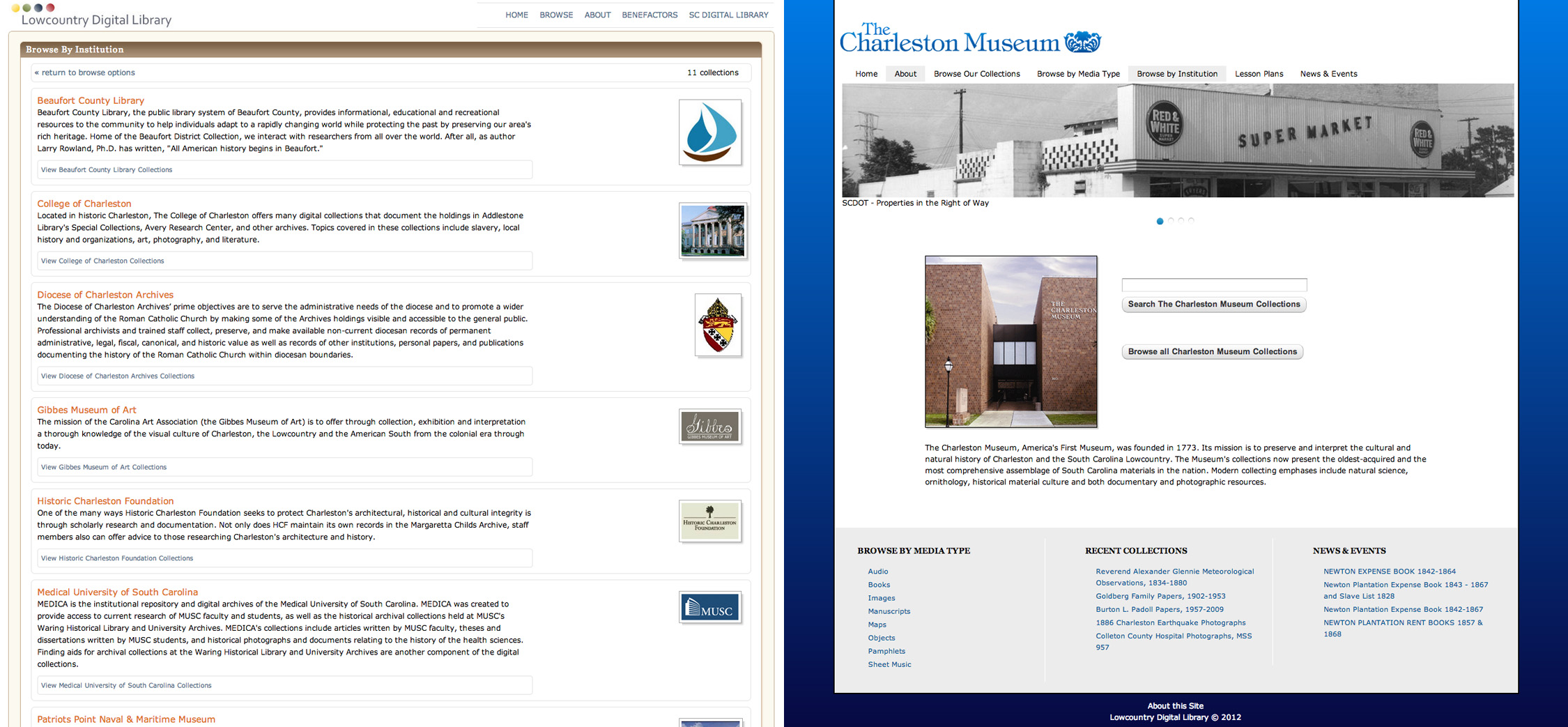
Figure 4. Institutional home page before (left) and after (right).
The “Before” image in Figure 4 shows our original system display for participating institutions. This was only a list comprised of a short description of the institution and a thumbnail image. The “After” image shows an example of our new single institution homepage with an embedded search function that links directly to Blacklight. You can also see the custom branding elements that are in place, including a customized background gradient and logos.
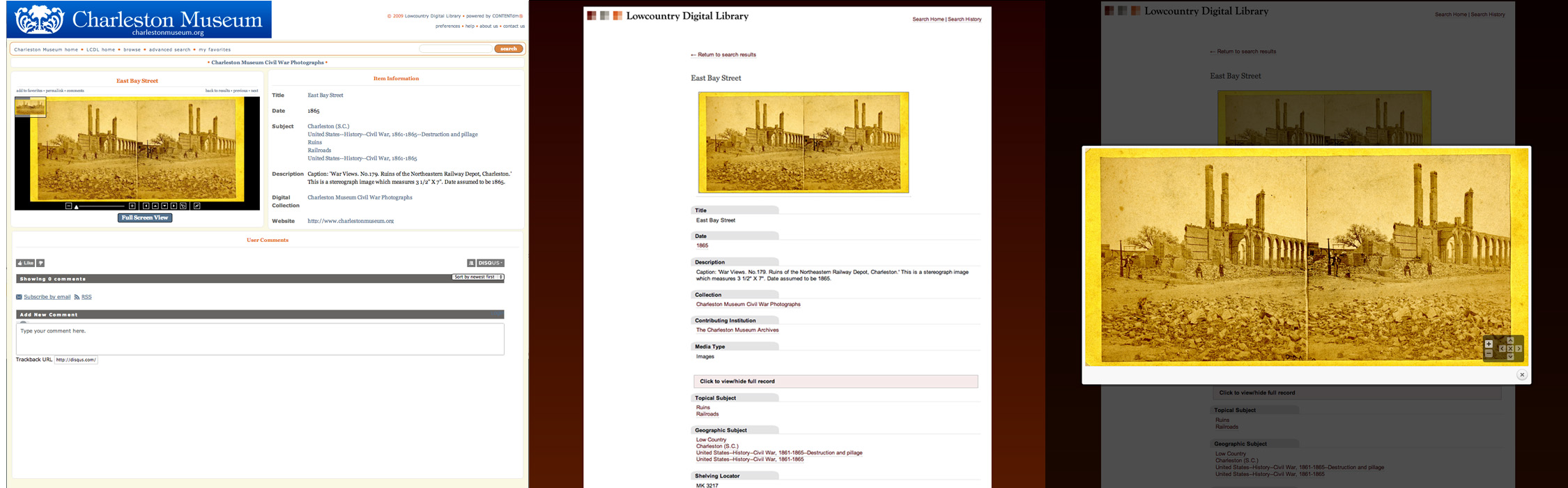
Figure 5. Single item display before (left), after (center), and zoom (right).
Figure 5 shows an example of our efforts to streamline the image viewer and metadata display in the new system and add an enhanced zoom function. The “Zoom” view is completely tablet and mobile friendly.
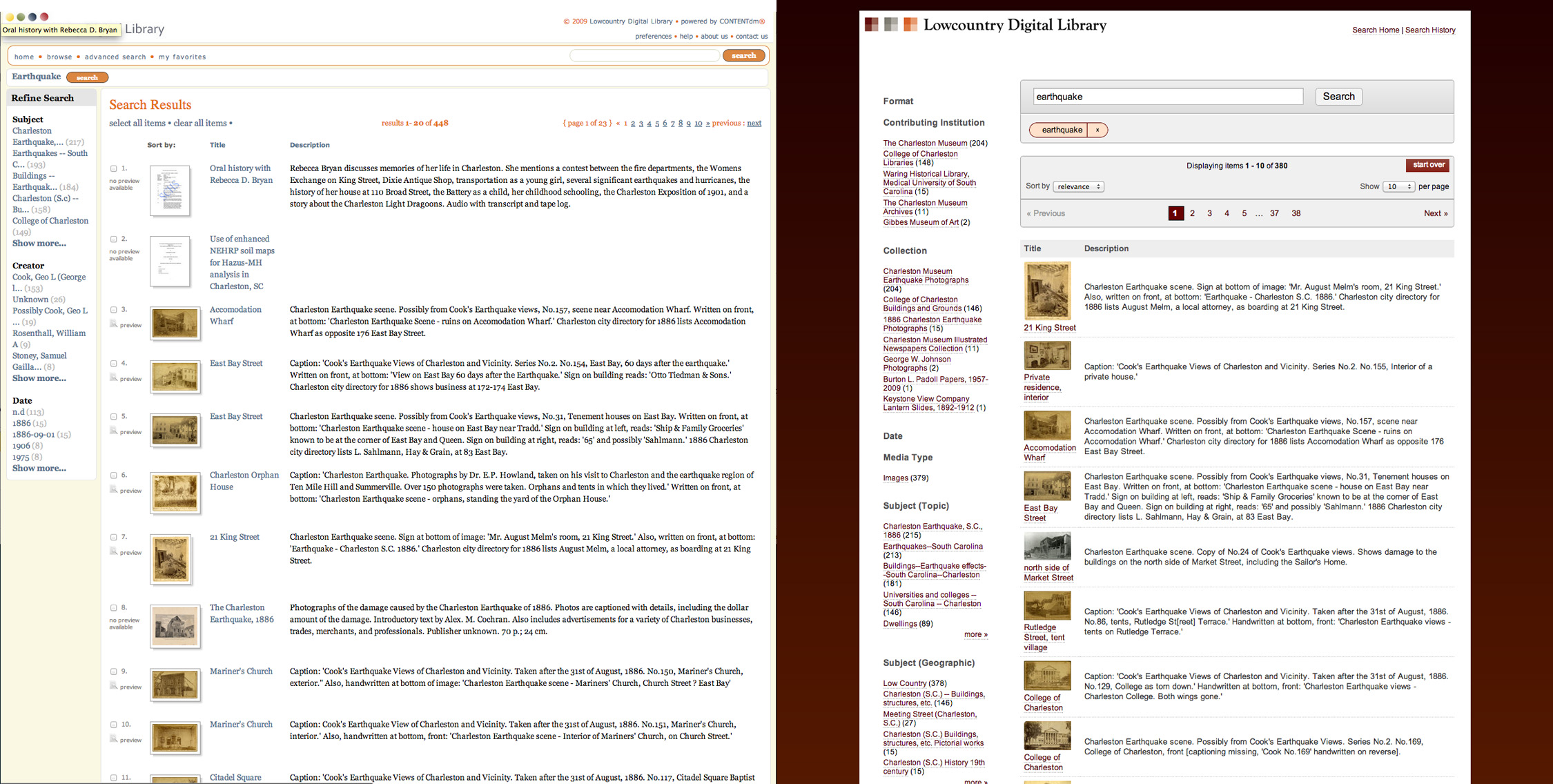
Figure 6. Search results before (left) and after (right).
Figure 6 shows a comparison screenshot of both systems’ search results display page after searching for the term “Earthquake”. While the new system is still missing just over half of the original system’s content, we are yielding more accurate search results and have little doubt that the addition of the remainder of our content will only continue to add to this improved accuracy. The “After” image also displays truly useful facets as opposed the facets displayed in our original system.
Lessons Learned
Migrations from proprietary to open source technology occur for a number of reasons in library systems, and can be both beneficial and challenging. Migration projects are at times initiated not because they present significant improvement of services for library staff or users, but because the lack of licensing fees appears attractive. Of course, these projects just incur a different set of costs considering the staff time, learning, and adaptation processes involved. When LCDL entered into this migration process, we knew that an open source replacement for our digital library would give us the flexibility we needed in a DAMS system, and we knew that it would not be an easy task. We had essentially two people to work on the project, very little programming experience, and minimal financial support. However, the scale of what a small group can do in open source library projects has exploded in recent years. Thanks to the work of the likes of the Fedora, Rutgers’ OpenWMS, Drupal, Blacklight, and Hydra development groups, we knew the tools existed to produce the digital library we wanted.
Still, we were optimistic about the existence of ready-made solutions to specific issues. While other developers had created impressive compound object viewers in Blacklight, their systems were not always comparable to ours as metadata standards and workflows vary between instances. Open source projects of this nature lack the benefit of one standardized CONTENTdm installation being able to contact another standardized CONTENTdm installation for development assistance. We did receive great help and advice from the Hydra and Blacklight user groups. In fact, we would not have gotten past many initial hurdles in understanding the logic and structure of the discovery interface without them. However, we ultimately found that our migration would take a certain amount of creative and often difficult problem solving that would be specific to our own circumstances.
The need to not only migrate our metadata, but also to rectify it, was challenging and time consuming, but will ultimately yield positive results. We did not realize how inconsistent our legacy metadata was until we began to evaluate systems for this project. Identifying that weakness in our workflows was an important, unexpected benefit of this project. Metadata rectification would have been necessary regardless of the system we chose to implement. Still, spending the staff hours to transform Dublin Core into MODS may not have been the best idea at the time. This transformation is extremely labor intensive and is a process that cannot be entirely automated. For example, in a metadata spreadsheet, separating the dc:subject field into the MODS
The loss of structural metadata incurred in exiting a CONTENTdm environment provided an additional challenge. Prior to exiting CONTENTdm, we never had to give structural metadata significant consideration. The system’s project client allowed us to create compound objects, and handled everything else behind the scenes. When exporting compound object metadata, we wound up with single item metadata for each page, and Fedora and Blacklight understandably could not process if these page items had any functional relationships. Our ingest workflow in OpenWMS had to be adjusted accordingly, and a custom method was written for Blacklight to treat certain items appropriately. Ultimately, our new approach to loading compound objects leverages our Solr index of object metadata. Each compound object is a Fedora object of model type ‘Compound’. As we treat each compound object as a sort of sub-collection, this Fedora object has a unique collection identifier in a MODS datastream that is indexed into Solr. When a compound object is accessed in Blacklight, our method queries Solr for indexed objects of model ‘Page’ that have the same collection identifier. The Solr result is then parsed into a hash and delivered to the Compound view to be used as a page index. This process bears little resemblance to the way CONTENTdm constructed compound objects, but it serves our current needs well, especially given our limited knowledge of other structural metadata formats like RDF. In migration projects, those interested in pursuing open source systems should understand the system they are leaving as well as the system they are building. In our case, we learned more about the original system only as we tried to leave it.
Conclusion
Despite several pitfalls in the migration and construction process, we now have a functional digital library that performs exceptionally better than our original system in display features, search accuracy and load times. Our new system is highly sustainable and scalable enough to easily manage our growth for the foreseeable future. While this project could have been made much less difficult with a programmer and/or a stronger set of programming skills by both authors, the learning experience alone was invaluable and we can readily say that our coding repertoire has increased exponentially. With this new system and these new skills, we can ensure the continued growth of our own vision of what the Lowcountry Digital Library can be, rather than a vision set forth by a propriety system.
About the Authors
Heather Gilbert is the Digital Scholarship Librarian for the College of Charleston and the Project Coordinator for the Lowcountry Digital Library. Tyler Mobley is a Digital Services Librarian for the College of Charleston.

Ray Matthews, 2013-04-19
When is the new site going public?
John White, 2013-04-19
It is beta-testing at http://lcdl.library.cofc.edu
Mohamed, 2013-07-08
Did you consider Islandora – the drupal based front-end for Fedora Commons?
Peter Murray, 2013-07-15
I heard a presentation at ALA on this, and as I recall they said that Islandora was not mature enough at the time they were considering making the move.
Heather Gilbert, 2013-07-23
Thanks for coming to our presentation Peter!
At the time of construction, Islandora had recently been released for Drupal 6 and there wasn’t a release date for the Drupal 7 version. While we were very impressed with what we saw of Islandora, we did not want to spend the time building out D6 when D7 had already been released. D7 was much easier to learn than D6 and since we were Druapl noobs, it made sense for us to stick with D7, even if that meant forsaking Islandora.
Timothy Barrett, 2013-08-07
Have you performed benchmarking on the database performance of Fedora? If so, how does Fedora scale both with physical (hardware resources) and with processing data? Is this linear? Have you tried to benchmark the actual limit of Fedora (have you tried to break it)?