by Heidi Frank
Introduction
The tools for catalogers have traditionally included content standards, such as AACR2, LCSH, LC Classification, and now RDA, and the medium for these standards has been the MARC format. However, with more and more resources to describe and catalog, the approach of dealing with them one-by-one is not sustainable, and many catalogers who work with MARC records in traditional library settings are now finding that they may need a new approach, one that combines traditional cataloging standards and programming, in order to efficiently manage their workflows. Although the combination of these two activities can make a cataloger’s workload more manageable, many catalogers do not yet have the programming skills and find themselves needing to work with programmers to achieve their goals.
Unfortunately, there is often a disconnect when it comes to communication between the two groups, especially when dealing with legacy MARC data. Jason Thomale articulates this in his article on Interpreting MARC, stating, “Library catalogers and programmers clash (often passionately) about what constitutes ‘good library metadata.'”[1] He demonstrates how certain cataloging rules, such as the varied location of “=” within the MARC 245 title field depending on which subfields are present, as well as the complexity of the MARC format, can be a hindrance to automation. He also explains how assumptions made by a programmer who is unfamiliar with those complexities (as convoluted as they might be), also creates obstacles in technological development.
Fortunately, opportunities have become more prevalent in recent years to pull these two communities together, such as the CURATEcamp event for Catalogers and Coders [2] held as a pre-conference to the DLF Fall Forum in 2011. Other examples are the ever-growing cataloging community involved in Code4Lib, the CatCode [3] wiki space, and the number of catalogers participating in the CodeYear project.[4] In addition, programs for manipulating MARC data, such as MarcEdit, continue to be developed that make batch-cataloging capabilities more accessible to the non-coder.
While a new environment for library metadata is under development in the form of the Bibliographic Framework Initiative [5] and the Linked Data [6] model, catalogers will continue to work with MARC records for a long time to come. Therefore, a cataloger’s ability to add to their arsenal additional tools and skills to automate workflows by analyzing and correcting MARC records in bulk is becoming more critical than ever.
This article presents a look at applying some batch-processing methods – specifically using MarcEdit and the PyMARC module in Python – to automate the analysis and clean-up of large sets of collection-level MARC records generated from the Archivists’ Toolkit (AT). Although the example presented is specific to archival collections described in the AT, the ideas demonstrate how even a little bit of coding knowledge can provide a cataloger with a whole new approach towards efficiently working with any large set of MARC records, providing quality metadata for any collection.
MarcEdit
MarcEdit [7] is a Windows-based software program used for editing and manipulating MARC data, and was developed in 2000 by Terry Reese, who continues to maintain and improve it. The basic GUI interface is designed for a non-coder and provides many convenient analysis and conversion capabilities that do not require any direct knowledge of programming or scripting. For example, Brandy Klug provides some common examples for customizing the URLs for electronic resource records supplied by vendors using MarcEdit’s built-in functions for adding field data or editing subfield content.[8]
While these built-in functions are extremely powerful on their own, the workflow being described here additionally incorporates the use of complex Regular Expressions (RegExes) that are based on the Microsoft .NET Regular Expression syntax.[9] And although the use of RegExes on their own is not actually programming, it is a common method used in scripting languages when dealing with large amounts of textual data.
MarcEdit is also used to convert files between various metadata schemas, and allows for the MARCXML format generated by the AT to be converted into MARC source files (i.e., “raw MARC”), and then into the mnemonic .mrk format for readability within the MarcEditor module. Additionally, the software allows you to join multiple MARC files into a single file for convenient batch-processing and analysis and loading into a local system.
Python Scripting with PyMARC
The Python scripting language [10] has numerous applications, from web development and design to text analysis. The PyMARC Python library [11] was created in 2005 by Gabriel Farrell, Mark Matienzo, and Ed Summers. An open source project developed specifically to work with MARC record data, it provides common methods of manipulating field indicators, subfields, and field content.
Archivists’ Toolkit
The Archivists’ Toolkit (AT)[12] is a software program collaboratively developed in 2006 by the UCSD Libraries, the NYU Libraries, and the Five College Libraries through a grant awarded by the Andrew W. Mellon Foundation. The program allows archivists to describe and manage their collections, and also to generate Encoded Archival Descriptions (EAD) in an XML format for display and discovery on the Internet. The AT also has a feature that provides for the export of equivalent MARCXML records for these collections, which is useful for the cataloger who primarily deals with the MARC format and with traditional library catalogs because it eliminates the need for manual creation of the MARC data. Using the AT as the source record also keeps the MARC record in synch with the EAD description.
While the AT has definitely proven its value for archival management, it introduces errors into the MARCXML records that it is capable of exporting. Some of these errors are simply the result of incorrect settings of the MARC field data such as field indicators upon export of the record, but other errors have to do with how the data must be entered into the AT interface, such as the single-box entry for multi-level subject headings. Inconsistent data entry methods by AT users, such as the use or lack of parentheses around data elements, can also be problematic.
There have been other discussions about the formatting issues with AT-generated MARCXML records, such as the lack of subfield divisions for subject headings when trying to load records into OCLC WorldCat. [13] In that case, the records were ultimately edited manually in OCLC’s Connexion interface and the process continued to be on a record-by-record basis.
The logical approach to resolve these issues would be to update the interface and the underlying configuration of the AT program itself in order to provide fully valid MARC data and content standards directly upon export. The reason this has not happened may be twofold. First, many catalogers who need to work with AT-generated MARCXML may not have access or permissions to edit records directly in the AT, nor be able to collaborate with the archivists who do create the records in the AT, and also they may not be very involved in the archival community. So they may feel it is easier to handle corrections to the MARC data on the cataloging side of things.
Second, program development for the AT software ended in 2009 due to the fact that many of the implementers are now working on the development of a new product called ArchivesSpace, [14] which intends to supersede both the AT and a similar program, Archon. The ArchivesSpace project was funded in mid-2011, and the core development began in 2012. ArchivesSpace version 0.4 has just been released in March 2013, and includes some of the initial MARC export features. While MARC catalogers can now be involved in testing this new software in order to ensure valid formatting, [15] it may still be a while before current users of the AT have fully implemented and migrated to ArchivesSpace, leaving the need to deal with MARC data issues from the AT for some time to come.
Putting It All Together
Using MARCXML records exported from local instances of the AT, the MARC output was analyzed in depth in order to identify areas where content or MARC standards were not followed. Methods for correcting these problems using MarcEdit and a Python script that includes the PyMARC library functionality were identified. The diagram below demonstrates the basic steps in our workflow for transforming the MARCXML records exported from Archivists’ Toolkit into a single file of corrected, standardized MARC records, which is ready to be loaded into a local catalog.
Overall Workflow for Processing MARCXML Records from the AT
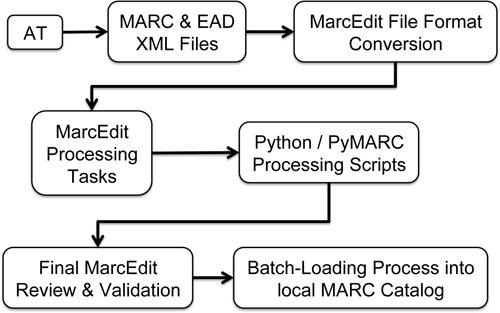
Figure 1. Diagram of Overall Workflow.
Ultimately, at the end of the workflow, the file structure will look something like this:
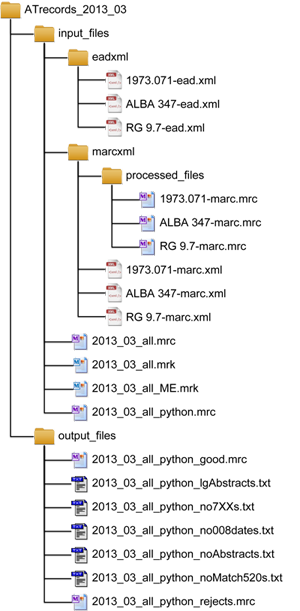
Figure 2. Sample File Structure.
Archivists’ Toolkit Application – MARC & EAD XML Files
The first step in preparing archival collection records from the AT for MARC cataloging is to export the individual EADXML and MARCXML record sets from the AT. When exporting multiple resource records from the AT, the exported files are automatically named using the resource IDs for each of the collections, followed by either “-ead.xml” or “-marc.xml”. This file-naming pattern is necessary for the Python script since it relies on the resource ID pulled from the MARC 099 field to identify the corresponding XML files. So if exporting a single record, the same pattern must be followed when manually entering the filename, using the same capitalization, spacing and punctuation found in the 099 field (e.g., RG 9.7-ead.xml).
These XML file pairs (e.g., 1973.071-ead.xml and 1973.071-marc.xml) are saved separately into the first two folders within the input_files folder, separating the EAD from the MARC. When capturing the EAD file content, the Python script looks for files in the eadxml folder that match the corresponding MARC record being processed based on the resource ID plus the extension “-ead.xml”.
MarcEdit Application – File Format Conversion
The next steps use MarcEdit tools to convert file formats and create a single file of MARC records to be modified in batch. To start, the set of MARCXML files generated from the AT are converted to individual .mrc files using MarcEdit’s Batch Process Records option in the Tools menu, pointing the Source Directory to the folder containing the MARCXML files and setting the Function to “From MARCXML to MARC”.
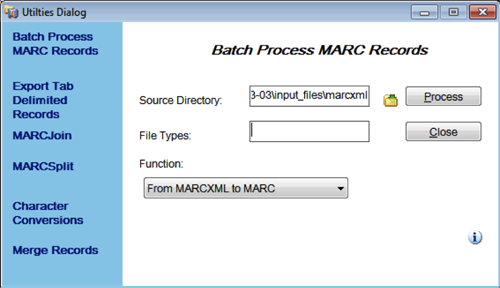
Figure 3. MarcEdit’s Batch Process MARC Records Utility Window.
The Batch Process MARC Records function creates the folder within the marcxml folder called processed_files, which contains the individual .mrc formatted files. These individual .mrc files are then combined into a single file using MarcEdit’s MARCJoin function.
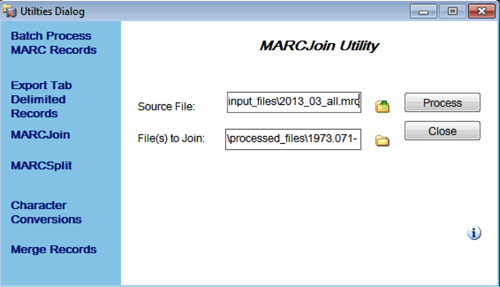
Figure 4. MarcEdit’s MARCJoin Utility Window.
In the MARCJoin Utility window, the Source File is actually set to the filename for the single .mrc file that will be created. Based on the file structure example above, this would be set to:
\ATrecords_2013_03\input_files\2013_03_all.mrc
The “File(s) to Join” is set by navigating to the processed_files folder containing the individual .mrc files and selecting all of the files in the folder. The result of this process is the single .mrc file found in the directory specified above. When this .mrc file is opened it will invoke MarcEdit’s MarcBreaker utility window to convert the .mrc file to the eye-readable .mrk mnemonic format.
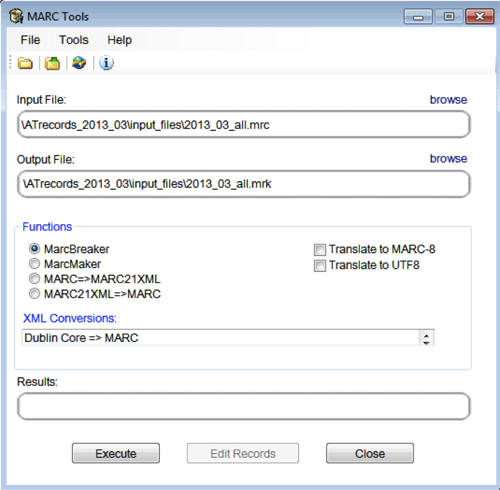
Figure 5. MarcEdit’s MarcBreaker Utility Window.
The resulting .mrk file can be accessed from the input_files folder, or upon execution of the conversion above, the Edit Records button will become active in order to immediately open the .mrk output file and begin the batch-editing tasks using the MarcEditor module.
Prior to editing the records, it is good practice to save a copy of the original .mrk file under a new filename, such as “2013_03_all_ME.mrk” shown in the sample file structure.
Cleanup of MARC data issues in records generated by the AT
A full list of the issues encountered with the MARC data due to the configuration of the AT or to data entry methods of AT users, was compiled, [16] including descriptions of the cause of the problems and resolutions implemented using either MarcEdit or Python scripting with the PyMARC library. A few examples of these issues and their resolutions are provided below.
Collection dates (MARC 008)
Problem 1:
In order to populate the Date1/Date2 bytes of the MARC 008 field, the Inclusive Begin and End dates must have been entered in the AT resource record – i.e., the Date Expression field in the AT is not sufficient. If the Inclusive dates are not explicitly specified in the AT, then the Date1/Date2 bytes export as blanks in the MARC record. Many search and discovery systems rely on these date fields for sorting and for limiting searches, so these fields are crucial for the user.
Resolution:
Since entry of the Inclusive Begin/End dates in the AT depends on the archivist creating the resource record, and not on the configuration of the AT interface, local guidelines were documented on the proper entry of dates in the AT. [17] Anticipating that these guidelines may not be followed consistently, it is desirable to check for the absence of dates in the 008 using the Find function in MarcEdit and the following RegEx:
Find: =008 .{6}i\\\\
This RegEx looks for an 008 field, followed by two spaces, then skips the first six characters of the field using “.{6}”, and finds the Date Status code “i” followed by four blank characters “\”. It identifies any records where bytes 07-10 of the 008 field (i.e., Date1) are blanks, thereby providing a list of records needing dates to be input into the AT.
This check could also be incorporated into a Python script, using PyMARC to check for records where the Date1 bytes are blanks, as follows:
for field008 in rec.get_fields('008'):
field008data = field008.value()
field008date1 = field008data[7:11]
if field008date1 == ' ':
# write record info to file
This script finds the 008 field in the given record and captures the string of data held there. Here are data string samples for four 008 fields:
120410i18051805xx eng d 120410i18561856xx eng d 120925i xx eng d 120106i16331929xx eng d
The script then creates a substring from position 7 (the first position is 0) up to position 11, which corresponds to bytes 07-10 of the 008, and checks whether those four bytes are space characters, as shown above in the third 008 data string.
If there are spaces in those positions, then the record’s descriptive information can be written to a text file, and this MARC record can be output to a “reject” .mrc file so that the AT records can be populated and re-exported.
Problem 2:
For collections that span only a single year, the AT still requires that both an Inclusive Begin and End date be entered (i.e., you are not allowed to leave the End date blank if there is a value entered in the Begin date field). In these cases, the Date Status field (DtSt – byte 06 of the 008 field) is still coded upon export as “i” for inclusive dates, and the same year is entered in both Date1 and Date2 of the 008 field. The correct MARC format for single year spans would be to have the Date Status coded as “s” for a single date and the year entered only in Date1.
Resolution:
A simple Find/Replace function can be used in MarcEdit to convert the 008 field to a single date format, as follows:
Find: (=008 .{6})i(\d{4})\2
Replace: $1s$2\\\\
This Find RegEx looks for 008 fields that have the same set of 4 digits consecutively after the Date Status code “i”, where “\d{4}” finds the first 4 digits and “\2” finds that same pattern directly after. The Replace syntax then copies the content of the first parenthetical section using the reference $1, replaces the Date Status code with an “s” (for single date), followed by the first set of 4 digits (Date1) referenced by $2, and replaces the second set of 4 digits (Date2) with blanks (“\\\\”).
Non-filing characters of titles (MARC 245, 630)
Problem:
The 245 main title field of the MARC record exports from the AT with default indicators of “1\”, whereas in actual cataloging practice the second indicator is meant to indicate the number of non-filing characters at the beginning of titles, allowing systems to skip leading articles such as A, An or The. For example, the second indicator would be a “4” if the title begins with “The”. Most of the time, this second indicator should be a zero, but in cases where there is a leading article, the title would not appear correctly in an alphabetical listing of titles (unless the search interface is already programmed to recognize common articles).
Resolution:
The first step would be to use MarcEdit’s Edit Indicator function to change all of the second indicators of the 245 fields to zero, setting Field=245, Indicators=1\, and Replace With=00. (Note: The first indicator, which designates whether the 245 field is used as the main entry, can also be changed to a zero or left as a 1, depending on local decisions for handling main entries.)
Once all of the second indicators are set to zero, then a series of Find/Replace commands can be used to change indicators for those titles that begin with a common article, as follows:
| Find | Replace |
| (=245 .)0(\$aA ) | ${1}2$2 |
| (=245 .)0(\$aAn ) | ${1}3$2 |
| (=245 .)0(\$aThe ) | ${1}4$2 |
The Find RegEx looks for a 245 field with the second indicator equal to zero and the first letters of the subfield $a equal to either A, An, or The. You must include a single space following the article in the Find RegEx. The Replace syntax references the first and second parenthetical sections of the Find RegEx using “${1}” and “$2”, and the middle number is changed to reflect the correct indicator value (2, 3, or 4, respectively).
The presence of non-English articles, such as La, Las, or Le, must also be taken into account. These articles may or may not need to be skipped – as in the case of a title such as “Las Vegas.” One could also write a Python script that would first determine the language of the material based on the Lang code in bytes 35-37 of the 008 field, and then modify leading articles accordingly. Given the presumed rarity of these occurrences, however, it may be acceptable to ignore them or to search for them separately on a case-by-case basis.
The indicators of the 630 fields for uniform titles pose a similar problem to those in the 245 main title field and can be fixed analogously.
Abstract versus Scope and Contents notes (MARC 520)
Problem:
Although the notes for both the Abstract and the Scope and Contents are specified as such in the AT interface, upon export to MARCXML, these notes both get entered into MARC 520 fields without the proper indicators to identify which one is which. They are both assigned blanks as their first indicator, rather than either a 3 or 2 for the Abstract or Scope and Contents, respectively. The Scope note is often too large for the maximum size of the local catalog’s record fields, so if one wanted to delete the Scope note from the MARC record, but keep the Abstract, there is not a way to easily identify which one needs to be deleted.
Resolution:
The PyMARC and Python scripting is used to extract the 520 fields from the MARC record and both the Abstract and Scope and Contents notes from the corresponding EADXML record. It then normalizes the content of each down to basic alphanumeric characters (i.e., deleting any HTML coding, extra spacing, etc.), and compares the 520 content with each of the notes from the EAD using a text-comparison analysis tool to determine whether or not they match.
The getEADdata Python method below opens and reads the EADXML file that corresponds to the MARC record under review using the resource ID as the filename, and then parses the EADXML data to capture the resource ID from the <num> tag, plus the <scopecontent> and <abstract> tags. The content of these three fields is normalized using the normalizeText method to remove extra white space, non-alphanumeric characters, HTML tagging, etc., and then they are copied into the eadData variable, a Python dictionary structure, as key/value pairs.
import re
from xml.dom.minidom import parseString
######################################################################
## Method - getEADdata
## Get resource ID <num>, scopecontent & abstract from EAD XML file
######################################################################
def getEADdata(resID):
eadData = {} # dictionary variable to hold EAD field data
eadFilename = foldername+'/input_files/eadxml/'+resID+'-ead.xml'
eadFile = open(eadFilename, 'r')
eadStr = eadFile.read()
eadFile.close()
xmlDOM = parseString(eadStr)
# Get the resource ID from the EAD <num> tag
if xmlDOM.getElementsByTagName('num'):
numTag = xmlDOM.getElementsByTagName('num')[0].toxml()
numData = numTag.replace('<num>', '').replace('</num>', '')
numData = numData.encode('ascii', 'ignore')
else: numData = ''
# Get the Scope note from the EAD <scopecontent> tag
if xmlDOM.getElementsByTagName('scopecontent'):
scopeTag = xmlDOM.getElementsByTagName('scopecontent')[0].toxml()
scopeData = normalizeText(scopeTag)
else: scopeData = ''
# Get the Abstract note from the EAD <abstract> tag
if xmlDOM.getElementsByTagName('abstract'):
abstractTag = xmlDOM.getElementsByTagName('abstract')[0].toxml()
abstractData = normalizeText(abstractTag)
else: abstractData = ''
# Create an entry in the eadData dictionary for this record
eadData['id'] = numData
eadData['scope'] = scopeData
eadData['abstract'] = abstractData
return eadData
######################################################################
## Method - normalizeText
## Strip and normalize text, removing extra white space, non-Alpha chars, html codes, etc.
######################################################################
def normalizeText(text):
# Create variables for RegEx patterns that need removed
headTag = re.compile(r'<head>[^<]*</head>')
htmlTags = re.compile(r'<[^>]+>')
htmlAmpCodes = re.compile(r'&[^;]+;')
nonAlphaNum = re.compile(r'[^\sa-zA-Z0-9]')
newLineChar = re.compile(r'\n')
whiteSpace = re.compile(r'\s+')
# Remove or replace any HTML tags, non-Alpha chars, and extra white space, etc.
text = headTag.sub('', text)
text = htmlTags.sub('', text)
text = htmlAmpCodes.sub('', text)
text = nonAlphaNum.sub(' ', text)
text = newLineChar.sub(' ', text)
text = whiteSpace.sub(' ', text)
text = text.strip()
text = text.encode('ascii', 'ignore')
return text
Once the eadData dictionary is created, the following Python script then loops through the 520 fields for each record using the PyMARC library, normalizes the text of the 520 note using the normalizeText method above, and then uses the difflib library [18] to compare this text to both the Abstract and Scope notes captured from the EAD. If the difference ratio is greater than 0.9, then the 520 text is considered a match, and the first indicator of the 520 field is modified accordingly. If the 520 text does not reach this comparison ratio level for either note, then it is identified as not a match and the record information is again written to a text file for manual analysis.
import pymarc
from pymarc.field import Field
import difflib
marcRecsIn = pymarc.MARCReader(file(foldername+'/input_files/'+mrcFilename), to_unicode=True, force_utf8=True)
# Iterate through all the MARC records in the specified .mrc file
for record in marcRecsIn:
resID = record['099']['a']
eadDict = getEADdata(resID)
for field520 in record.get_fields('520'):
field520a = field520.get_subfields('a')[0] # get the first item in the list of all subfields $a (there should be only 1 in list)
altField520a = field520a # capture a copy of the 520 text that will be altered for comparison
altField520a = normalizeText(altField520a) # strip and normalize the 520 text for comparison
diffRatioAbstract = difflib.SequenceMatcher(None, altField520a, eadDataDict['abstract']).ratio() # returns a value of the similarity ratio between the 2 strings
diffRatioScope = difflib.SequenceMatcher(None, altField520a, eadDataDict['scope']).ratio() # returns a value of the similarity ratio between the 2 strings
if diffRatioAbstract >= 0.9: # this 520 matches the abstract
if len(altField520a) <= 1900: # this 520 is within 1900 characters
new520abstract = Field(tag='520', indicators=['3',' '], subfields=['a', field520a]) # create a new 520 field for the abstract with 1st indicator=3
else:
abstractTooLg = lgAbstracts(rec=record, text=altField520a) # write to file when abstract is greater than 1900 characters, and return True
elif diffRatioScope >= 0.9: # this 520 matches the scope
if len(altField520a) <= 1900: # this 520 is within 1900 characters
new520scope = Field(tag='520', indicators=['2',' '], subfields=['a', field520a]) # create a new 520 field for the scope note with 1st indicator=2
else:
noMatch520 = noMatch520s(rec=record, eadData=eadDataDict, alt520=altField520a, diffAbstract=diffRatioAbstract, diffScope=diffRatioScope)
record.remove_field(field520) # remove the old 520 field that has blank indicators
if new520abstract:
record.add_field(new520abstract)
if new520scope:
record.add_field(new520scope)
Subject heading subfields (MARC 6XX)
Problem:
The interface in the AT for entering subject headings is not granular, and there is only a single text box for entry, so it is not possible to distinguish MARC subfield codes for subject headings that include any form of subdivision.
Resolution:
Local guidelines [19] were developed directing the AT user to separate subject subdivisions with ” |x ” (space–vertical bar–subfield code–space) when entering subject headings in the AT that include subdivisions (i.e., MARC subfields), such as these headings:
Actors |x Labor unions |z United States
Cemeteries |z New York (State)
Upon processing, MarcEdit is able to use the Find/Replace function to convert the ” |x ” syntax to “$x”, using this Regular Expression (RegEx) combination:
Find: ( \|)([0-9a-z])( )
Replace: $$$2
This Find command looks for a space followed by the vertical bar, followed by either a digit or lowercase letter, followed by another space, and then replaces that combination with a dollar sign using the escape syntax “$$”, followed by the content of the second parenthetical section of the Find RegEx using the reference “$2”, which is the alpha-numeric subfield code. The subject heading examples above would become:
Actors$xLabor unions$zUnited States
Cemeteries$zNew York (State)
While this fix satisfies MARC standards, it becomes a problem for the EAD, which is usually formatted with double-dashes separating the subject heading subdivisions (e.g., Cemeteries — New York (State)). The CSS managing the EAD display was changed to convert the new syntax back to double-dashes.
Name heading punctuation (MARC 600/610, 700/710)
Problem:
When name headings are exported from the AT, they are lacking the appropriate punctuation between subfields, and in some cases, the subfields are not in MARC order. For example, when subfield $q is present in a 600 or 700 field, it is not enclosed in parentheses (unless the parentheses are explicitly added into the name record in the AT), and it appears after subfield $d when present, instead of before.
Another issue that had to be dealt with locally was with records that were originally ingested into the AT database, which had the complete content of each of the personal name headings (i.e., both last and first names, dates, fuller forms of names, etc.) entered into the single field for Primary Name (i.e., Last Name). So upon export, the full name headings would be in subfield $a, and there was no easy way to parse the subfield content.
These non-standardized name headings prevent collocation with their authorized versions, which affects faceting and searching and becomes an issue for the front-end user.
Resolution:
The first step locally was to retrospectively go through all of the personal name headings in the AT, manually moving the different parts of the headings into their appropriate fields – such as the dates, the first and middle names to the “Rest of Name” field, etc. Local guidelines were written on the proper entry of name headings in the AT [20] and were provided to the AT users for this retrospective cleanup of the headings and for new headings to be added.
To address the punctuation issues, a long series of Find/Replace commands were constructed that look for various subfield combinations and reorder and replace them with the appropriate punctuation. Here is a sample:
| Find | Replace |
| (=700 ..)(\$a[^\$]+)(\$d[^\$]+)(\$q)([^\$]+)(\$e.*$) | $1$2$4($5),$3,$6 |
| (=700 ..)(\$a[^\$]+)(\$d[^\$]+)(\$e.*$) | $1$2,$3,$4 |
| (=700 ..)(\$a[^\$]+)(\$c[^\(][^\$]+[^\)])(\$d[^\$]+)(\$q)([^\$]+)(\$e.*$) | $1$2,$3$5($6),$4,$7 |
The three Find/Replace commands above address the following subfield combinations:
| Find 700 Subfield Pattern: | Convert To: |
| $a $d $q $e | $a $q (), $d, $e |
| $a $d $e | $a, $d, $e |
| $a $c $d $q $e | $a, $c $q (), $d, $e |
A similar set of Find/Replace commands were written to insert the appropriate punctuation into the 600, 610 and 710 fields.
MarcEdit Application – Processing Tasks
Many of the resolutions to the MARC data problems involve the use of MarcEdit functions, which can be automated using the Manage Tasks tool of the MarcEditor module. This tool provides the ability to combine editing tasks into a list that can be initiated in a single step.
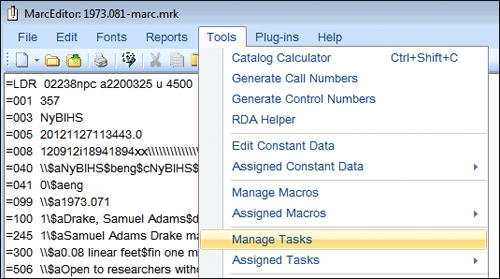
Figure 6. MarcEdit’s MarcEditor Tools Menu – Manage Tasks.
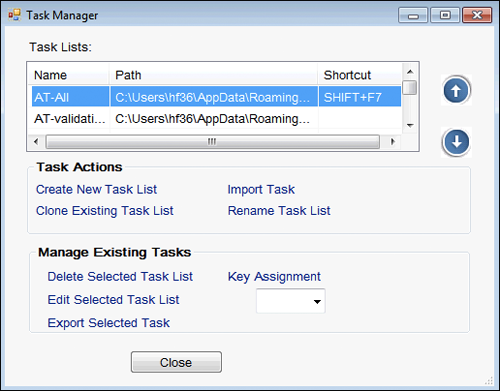
Figure 7. MarcEdit’s Task Manager Tool.
The Task Manager is the most powerful component used to resolve the majority of the problems that have been described with AT MARCXML records. For this workflow, a single task list was created which incorporates all of the Find/Replace commands mentioned, as well as a number of other minor corrections and enhancements to the records. The full list of tasks and descriptions of the modifications being made are maintained in a spreadsheet [21], but a portion of this task list when viewed in the Task Manager is shown below.
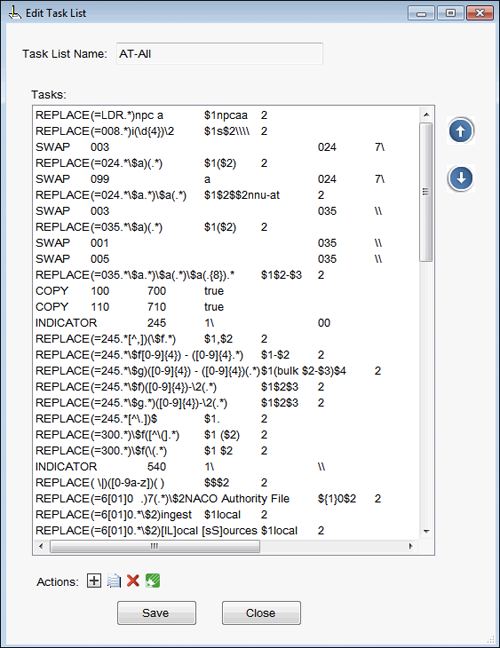
Figure 8. Sample Task List in MarcEdit’s MarcEditor Task Manager.
Once the task list has been applied to the .mrk file of MARC records, the file is then converted back to .mrc format for Python processing by choosing “Compile File into MARC” in the File menu of the MarcEditor module, and saving the file in the input_files folder. In the file structure example, this file is the one named “2013_03_all_python.mrc” and is the filename that will be entered when running the Python script.
Python Processing Scripts with PyMARC
The key functions of the full Python script [22] are to identify records that may need to be edited in the AT. Among other things, the script looks for records missing dates in the 008 field, lacking an abstract, or not having any named creator (i.e., no 1XX or 7XX). It also analyzes the 520 notes to identify which are Abstracts and which are Scope notes, as well as deleting any 520 or 545 notes that are too long for the field size limitations in the local system. It finally evaluates the 7XX fields to de-duplicate any name headings that have multiple roles assigned.
When the script is run, it prompts for a folder name and then a filename. The folder name will be the top level folder in the file structure, and the filename is the name of the .mrc file of MARC records to be processed – in the sample file structure shown above, the folder name is “ATrecords_2013_03” and the filename is “2013_03_all_python.mrc”.
Once the analysis is complete and the modifications are made, the script outputs the following list of files to the output_files folder shown in the sample file structure:
- 2013_03_all_python_good.mrc
- 2013_03_all_python_lgAbstracts.txt
- 2013_03_all_python_no7XXs.txt
- 2013_03_all_python_no008dates.txt
- 2013_03_all_python_noAbstracts.txt
- 2013_03_all_python_noMatch520s.txt
- 2013_03_all_python_rejects.mrc
The five .txt files provide lists of records identified as having problems, which can be given to a cataloger or archivist to check and modify in the AT as needed. All of the records having no dates in the 008 field, or either an abstract that is too long or not having an abstract at all, are output to the rejects.mrc file. Lists of these records are found in the three corresponding .txt files – lgAbstracts.txt, no008dates.txt, and noAbstracts.txt. The lists of records in the no7XXs.txt and the noMatch520s.txt files are used as alerts for records that may need reviewed, but the records are not considered rejects. The rest of the records are output to the good.mrc file. The file of “good” MARC records can then be re-analyzed and validated again in MarcEdit if desired, and then used for batch-loading into a local catalog.
Conclusions
While this paper presents a very specific example for batch-editing AT-generated MARC records, the concepts are applicable to any large set of MARC data, from ebook vendor records to collections of MODS records (or those conforming to other standard descriptive metadata schemas) that can be converted to MARC and vice versa using appropriate crosswalks. The key idea is that the use of some minimal knowledge of Regular Expression syntax, and possibly some scripting language – be it Python, XSLT, JavaScript, Ruby, or any other language – would prove beneficial to any cataloger.
From the perspective of a traditional MARC cataloger who has had the opportunity to learn a little bit of programming on the side, it is now hard to imagine a world of cataloging that does not incorporate some of the methods and tools that have been described. Furthermore, the more catalogers are able to speak the language of coding, the better they can communicate with the technologists who have the deeper skills to develop the systems that represent the bibliographic data catalogers hold so dear. Catalogers who truly understand the long-standing rules and standards of traditional MARC cataloging will be able to contribute this knowledge to the larger objective to bring bibliographic data into the technological capabilities of the 21st century. The increase in collaborations between catalogers and coders, as well as the increase in catalogers who are coders, is proving to be the next logical direction for the field of bibliographic description and access.
Endnotes
[1]. Thomale, Jason. 2010 Sept. 21. “Interpreting MARC: Where’s the Bibliographic Data?” Code4Lib Journal [Internet], Issue 11. [cited 2013 March 7]. Available from: http://journal.code4lib.org/articles/3832
[2]. CURATEcamp: Catalogers + Coders; 2011 Oct. 30; Baltimore, MD [Internet]. [cited 2013 March 7]. Available from: http://curatecamp.org/content/welcome-curatecamp-catalogers-coders
[3]. CatCode Wiki [Internet]. [cited 2013 March 7]. Available from: http://catcode.pbworks.com/w/page/49328692/Welcome%20to%20CatCode%21
[4]. McDanold, Shana. 2012 Jan. 3. CodeYear Catalogers [Internet, blog post]. [cited 2013 March 7]. Available from: http://slmcdanold.blogspot.com/2012/01/codeyear-catalogers.html
[5]. Library of Congress. 2013 Feb. 25. Bibliographic Framework Transition Initiative [Internet]. [cited 2013 March 7]. Available from: http://www.loc.gov/marc/transition/
[6]. Heath, Tom (site administrator). Linked Data [Internet]. [cited 2013 March 7]. Available from: http://linkeddata.org/
[7]. Reese, Terry. MarcEdit [Internet]. [cited 2013 March 7]. Available from: http://marcedit.reeset.net/
[8]. Klug, Brandy. 2010 March 22. “Wrangling Electronic Resources: A Few Good Tools.” Code4Lib Journal [Internet], Issue 9. [cited 2013 March 7]. Available from: http://journal.code4lib.org/articles/2634
[9]. MSDN. Microsoft .NET Regular Expression Language: Quick Reference [Internet]. [cited 2013 March 7]. Available from: http://msdn.microsoft.com/en-us/library/az24scfc.aspx
[10]. Python Programming Language [Internet]. [cited 2013 March 7]. Available from: http://www.python.org/
[11]. PyMARC [Internet]. [cited 2013 March 7]. Available from: https://github.com/edsu/pymarc
[12]. Archivists’ Toolkit [Internet]. [cited 2013 March 7]. Available from: http://www.archiviststoolkit.org/
[13]. Audra. 2010 Nov. 23. Touchable Archives : Sharing marc from archivists’ toolkit [Internet, blog post]. [cited 2013 March 7]. Available from: http://librarchivist.wordpress.com/2010/11/23/sharing-marc-from-archivists-toolkit/
[14]. ArchivesSpace [Internet]. [cited 2013 March 7]. Available from: http://www.archivesspace.org
[15]. ArchivesSpace: Get Involved [Internet]. [cited 2013 March 7]. Available from: http://www.archivesspace.org/get-involved/
[16]. Frank, Heidi P. 2013. Archivists’ Toolkit generated MARC : A Compilation of Issues and Resolutions [Internet]. [cited 2013 March 7]. Available from: https://github.com/hfrank71/AT_MARC/wiki/AT-documentation
[17]. Frank, Heidi P. 2012. Archivists’ Toolkit Documentation: Guide on entering Collection Dates in the AT [Internet]. [cited 2013 March 7]. Available from: https://github.com/hfrank71/AT_MARC/wiki/AT-documentation
[18]. Python Software Foundation. 2013. Python Documentation, 7.4 difflib: Helpers for computing deltas [Internet]. [cited 2013 March 7]. Available from: http://docs.python.org/2/library/difflib.html
[19]. Frank, Heidi P. 2010. Archivists’ Toolkit Documentation: Guide on entering Subject Headings in the AT [Internet]. [cited 2013 March 7]. Available from: https://github.com/hfrank71/AT_MARC/wiki/AT-documentation
[20]. Frank, Heidi P. 2009. Archivists’ Toolkit Documentation: Guide on entering Name Headings in the AT [Internet]. [cited 2013 March 7]. Available from: https://github.com/hfrank71/AT_MARC/wiki/AT-documentation
[21]. Frank, Heidi P. 2013. MarcEdit task list for modifying Archivists’ Toolkit MARC records [Internet]. [cited 2013 March 7]. Available from: https://github.com/hfrank71/AT_MARC/wiki/AT-documentation
[22]. Frank, Heidi P. Python script for modifying Archivists’ Toolkit MARC records [Internet]. [cited 2013 March 7]. Available from: https://github.com/hfrank71/AT_MARC/blob/master/ATmarc.py
About the Author
Heidi Frank (hf36@nyu.edu) is the Electronic Resources & Special Formats Cataloger at New York University Libraries. While she has primarily dealt with cataloging non-print materials, such as videos and CD/DVD-ROMs, she also works on metadata projects involving the mappings of MARC to EAD and MODS, MARC data analysis for ebooks, the development of workflows to assist in automating the cataloging process, and resolving display and navigation issues found in the library’s Aleph and Primo front-end interfaces.

Subscribe to comments: For this article | For all articles
Leave a Reply