By M. Cristina Pattuelli, Matt Miller, Leanora Lange, Sean Fitzell, and Carolyn Li-Madeo
Introduction
This paper presents methods and tools created as part of Linked Jazz [1], a project that explores innovative ways to enhance the discovery and interpretation of cultural heritage through the application of Linked Open Data (LOD) technology to digital archives of jazz history. With the overarching goal to help make visible the rich and diverse network of personal and professional connections among jazz artists, the project serves as a case study of LOD creation practices and contributes to the growing body of research on LOD in libraries, archives, and museums (LODLAM) [2].
The amount of digital heritage data is growing at an exponential rate, and LOD technology has emerged as a promising approach to enhance its discovery, interpretation, and use. LOD is a recommended best practice for connecting distributed data across the web (Heath & Bizer, 2011). Developed as a W3C project and spurred on by Tim Berners-Lee, LOD has taken off as a new technology for extending the traditional web. The promise of LOD lies in its concrete functionality: it provides a unifying and open publishing framework that enables data interlinking and facilitates data interoperability, integration, sharing, and reuse. In the context of cultural heritage, LOD has the potential to open unprecedented opportunities for information discovery and new approaches to inquiry.
There is a need within the LOD community to share the results of prototype tests and lessons learned so that best practices can be refined and the rich opportunities for using LOD can be demonstrated. To this end, Linked Jazz has developed methods and tools for generating a dataset of RDF statements that represents personal and professional relationships among jazz musicians as they are described in interview transcripts from jazz history collections. The project has developed over several stages and required the creation of a series of tools to work toward our objectives. It should be noted that the Linked Jazz tools, while created in the context of digital archives of jazz history, are domain-independent and can be easily transferred to different application contexts.
Although a series of different applications were created as part of this project, this paper focuses specifically on two that served as the preparatory foundation upon which a complex dataset will ultimately be built: the Mapping and Curator Tool and the Transcript Analyzer. The methods and applications examined here deal with some of the key aspects and inherent challenges of LOD development: data preparation and analysis as well as data curation. In the crafting of LOD, these two tools and the URIs they create provide the necessary foundation for building the final dataset.
Mapping and Curator Tool
Linked Jazz employs LOD technology to reveal the social and professional relationships among the community of jazz musicians as described in interview transcripts available through digital archives. At the core of the project is the creation of an RDF dataset that describes these relationships as LOD. Publishing LOD requires a few essential components, the first of which is that each entity must have a unique resource identifier (URI) (Berners-Lee, 2006). This first step was accomplished by creating the Linked Jazz Name Directory—a directory of personal names of jazz artists paired with URIs that serves as the foundation for various applications within the project.
The Name Directory was created by ingesting extract files from DBpedia version 3.8 [3] and bibliographic name authority files into the Mapping tool. The resulting dataset can then be refined using the Curator Tool. The mapping and curation process is comprised of two parts: data processing and human curation via an interface that allows a user to interact with that data. The data processing, described in detail below, is accomplished through a series of Python scripts that ingest the LOD extracts [4].
The first step toward building the Name Directory was to extract files from DBpedia. DBpedia flat file N-Triple extracts were mined and filtered through article category titles, infobox properties, and rdf:type to create a smaller dataset of individuals in the jazz community. A detailed description of the first phase of the creation of the directory is provided in Pattuelli (2012). The resulting Linked Jazz Name Directory [5] consists of close to 9,000 individuals represented by literal triples. An example is provided in Figure 1.
<http://dbpedia.org/resource/Mary_Lou_Williams> <http://xmlns.com/foaf/0.1/name> "Mary Lou Williams"
Figure 1. Example of a literal triple describing the entity name “Mary Lou Williams.”
The process used to create the Linked Jazz Name Directory reflects the methodology the Linked Jazz team has employed whenever working with large LOD datasets. To enable flexibility in how the data is processed and utilized, we generated smaller, domain-specific datasets from large, unwieldy LOD data extracts such as the ones derived from DBpedia.
The Name Directory was generally accurate and extensive for common or preferred names of jazz artists, which tend to be consistently present in DBpedia. Variant forms of names (e.g., nicknames, aliases, birth names) were largely missing, however. To enrich the Name Directory with alternate names, we mapped the URIs in our Name Directory to a large LOD name authority, the Library of Congress Name Authority File (LC/NAF). By mapping to LC/NAF, we also connected our Name Directory to the Virtual International Authority File (VIAF) [6], which contains further alternate names from libraries across the globe. Authority files play a key role in LOD development as they provide reliable identifiers for entities, which otherwise would be hard to identify and disambiguate. Mapping URIs between authorities, however, is a difficult task.
To make the mapping manageable, we downloaded the LC/NAF dataset and then trimmed the large data extract (30GB) to include only Simple Knowledge Organization System (SKOS) data for personal name entities. This was accomplished through filtering on rdf:type of madsrdf:PersonalName. Next, we examined entities based on personal name, birth date, and death date. Two entities—a DBpedia entity and an authority file entity—that matched in all three of these values were considered an exact or perfect match. Because our Linked Jazz Name Directory is domain specific and only a subset of DBpedia, perfect matches were limited. When a perfect match was not available, the Mapping tool took additional steps to find a partial match. To optimize matching, we relied on a whitelist of domain specific terms such as “jazz,” “blues,” and related terms associated with a full LC record, using the datasets represented in both Metadata Authority Description Schema (MADS) and SKOS. We did this by dynamically downloading the full record through the Library of Congress Linked Data Service API [7] for the targeted individual. This method eases the whole process by sensibly reducing computational space and the power required in the mapping process. The full matching process is shown in Figure 2.
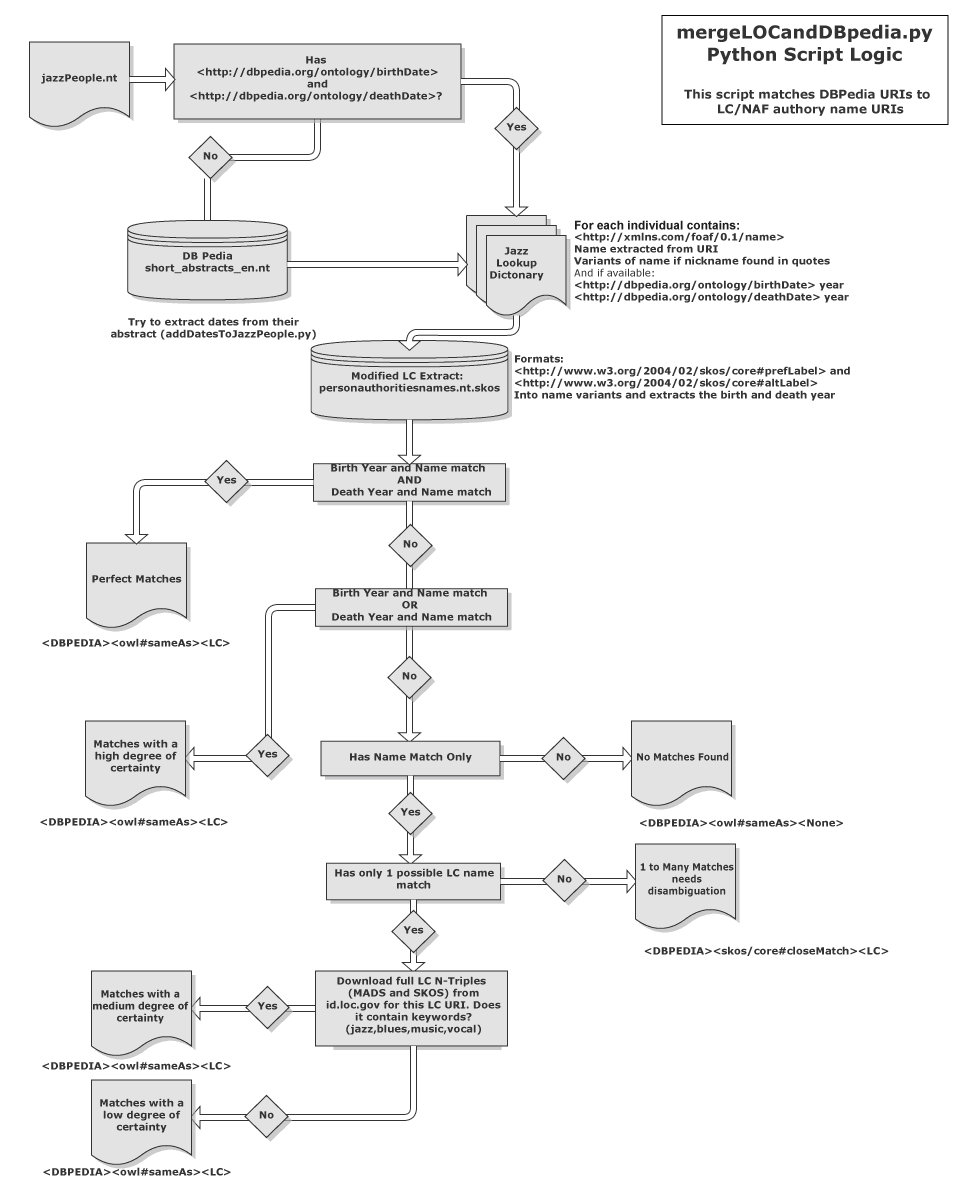
Figure 2. Flowchart of the backend mapping process used to create and refine the Linked Jazz Name Directory.
Because our dataset was relatively small and domain-specific, we could achieve a fairly high rate of success. We were able to automatically match about 85% of the entities in our Name Directory to the corresponding authority records. Mapping results were automatically grouped into six different levels of confidence:
- Perfect: Preferred name, birth, and death dates all match.
- High: Preferred name, birth, or death dates match.
- Medium: Preferred name matches and whitelisted terms found.
- Low: Preferred name matches, no whitelisted terms found.
- One to many: Preferred name matched to many other names, disambiguation needed.
- None: No possible matches found.
The more assumptions the process needed to make to achieve a successful match, the lower the level of confidence the mapping result was assigned.
Another fundamental aspect of the development of Linked Jazz is the use of human intervention to complement algorithm-based methods. While the Mapping Tool is highly automated, we also provide the ability to manually refine the dataset through the Curator component of the tool. The Curator is a collaborative, web-based interface, which sits on top of the Name Directory (see Figure 3). This interface enables the curation of the personal names included in the Name Directory through their mappings to LC/NAF and LC/NAF’s intrinsic connection with VIAF. Using this interface a user can disambiguate individuals by connecting them to the correct LC/NAF authority record, verify their mapping, or remove names of individuals from the directory entirely. A public demonstration of an early version of the prototype is available at http://linkedjazz.org/public_demo_mapping.
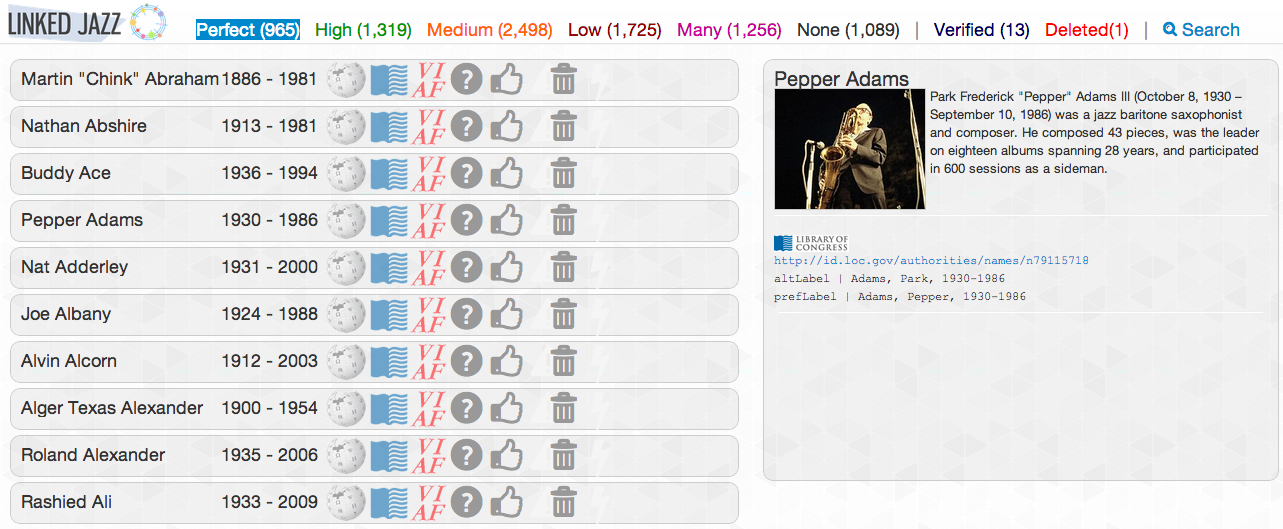
Figure 3. Curator Tool showing the mapping of the Pepper Adams entity name to the Library of Congress Name Authority.
Transcript Analyzer
After completing the directory of jazz musicians’ names and enhancing it through the mapping and curation processes, the next stage of the project entailed the preparation of the digital text of interview transcripts from jazz history collections. This was carried out through our next tool, the Linked Jazz Transcript Analyzer (Figure 4).
The Linked Jazz Name Directory played a key role in preparing these interview texts: it was used for identifying connections among jazz artists through string matching of the names mentioned in the interviews. Name citations found in the transcripts provided the basic units for creating a first layer of linkages between musicians. These connections were recorded as RDF triples using the predicate rel:knows_of. The assumption underlying this strategy was that if a musician mentions another musician in an interview, this musician at least knows of the other musician in some way, be it as a friend or acquaintance or just by having knowledge of the other musician.
Identifying the nature of relationships among the musicians and representing them semantically is the next step in the development of Linked Jazz. A crowdsource-driven approach was chosen to assist with the analysis and classification of relationships. To enable this, the crowdsourcing application Linked Jazz 52nd Street [8] was developed. This tool provides an interface for users to analyze excerpts of text from interview transcripts and discern the social relationships shared by the musicians mentioned.
A few preliminary activities need to be performed on the text of the interview transcripts to allow them to be processed by the crowdsourcing tool: named entities must be identified in interview transcripts and the document must be structured into discrete segments of questions and answers. To support the preparation of the text, the Transcript Analyzer was developed to automatically identify personal names cited in interview transcripts and map them to the Linked Jazz Name Directory and name authority files.
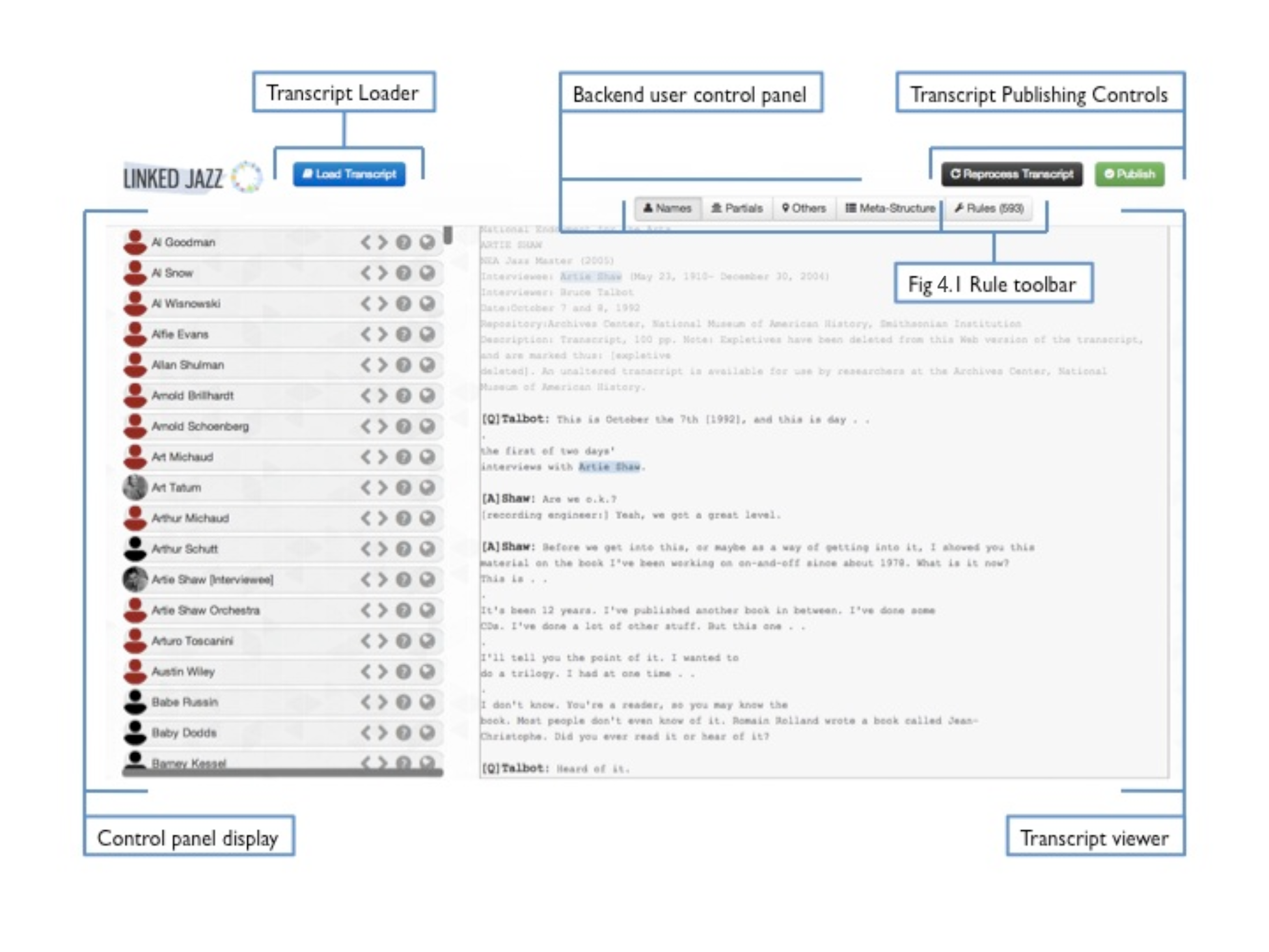
Figure 4. Interface of the Transcript Analyzer with the names identified in the transcript shown on the left, the text of the transcript on the right, and the backend user tool bar above.
At its core, the tool performs automated named-entity recognition enabled through the use of the Natural Language Toolkit (NLTK 2.0) platform [9]. Along with detecting personal names, the Transcript Analyzer is also capable of recognizing other types of entities. These entities, such as locations, businesses, and even song and album titles, can be manually marked as “other names” if the automated name recognition did not already do so.
One feature of the Transcript Analyzer critical to the preparation of the transcripts is its capability to identify partial names (e.g., first names or nicknames) and link them to the appropriate entity mentioned within a certain proximity, typically a sentence or two before. For example, if “Dizzy” appears a sentence after the full name “Dizzy Gillespie,” that instance of “Dizzy” will be automatically considered a reference to be associated with the entity “Dizzy Gillespie.” However, partial matches can be reviewed for accuracy, and suspected partial name matches that do not have a full name in proximity are presented to the user for manual matching.
There are a variety of instances, however, where a name cannot be detected or correctly identified. For example, the name might be misspelled or a variant form of it might be used. Some automated processes are used to correct these errors, such as Levenshtein distance comparison, yet most are beyond the scope of automated fixes. In these instances, the system allows for manual intervention, and the incorrect or alternate name can be selected and associated with the appropriate entity in the Linked Jazz Name Directory. Through the Transcript Analyzer, a user can add or remove names and correct any spelling errors. The system remembers user input (addition, modification, or deletion of entities) and leverages this information to process future transcripts more efficiently.
The Transcript Analyzer is also able to identify names that are not yet in the Linked Jazz Name Directory and therefore have not yet been mapped to an authority. In this case, the Transcript Analyzer enables the user to locate a URI associated with the name and enter it into the Name Control “Authority” panel (see Figure 5). Commonly used sources for URIs include DBpedia, the Library of Congress Linked Data Services dataset, or the domain-specific MusicBrainz. The user can also search these sources for the name in question directly from the Name Control panel. When obscure artists are cited in interviews whose names cannot be found in these external sources, a new URI can be minted for that entity that will be hosted on the Linked Jazz namespace. The Name Control panel makes it possible to enter the URL to the information source where the name in question was identified, such as an online encyclopedia. The user can also add notes if clarification is needed.
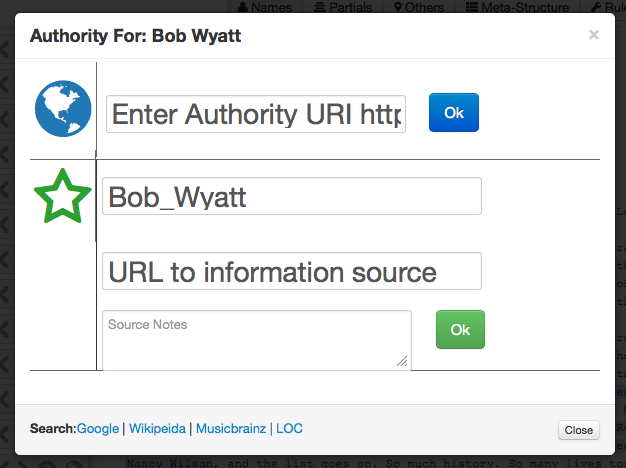
Figure 5. The Transcript Analyzer’s Name Control panel with a field to enter an authority URI, mint a new URI, and search authorities.
In addition to performing named-entity recognition tasks, the Transcript Analyzer also breaks interview content down into meaningful question and answer segments, which are later employed in the Linked Jazz 52nd Street crowdsourcing tool. Based on regular expression patterns, the Transcript Analyzer splits the transcripts into a question and answer format, attributing blocks of text either to the interviewer or the interviewee. The tool can be dynamically trained on different document layouts, allowing it to process transcripts with multiple interviewees. The Transcript Analyzer tags each question and answer section with the names that were mentioned within each text segment. If a name occurs multiple times in the same question and answer segment, all mentions will be attributed to the same entity. This data is stored on the server in a configuration file for each transcript as well as at the global level. This allows for a stateful incremental workflow.
Project team members can easily interact with the Transcript Analyzer as a collaborative web-based tool, as no programming skills are required to fulfill basic tasks. Once an analysis is complete (i.e. all instances of names have been mapped to authorities, all URIs have been minted where necessary, and the text has been broken down into questions and answers), the final step is to publish the transcript, which immediately becomes available on the Linked Jazz 52nd Street website and is viewable by the public. Although crowdsourcing users can now begin to work on these transcripts, it is always possible to access published transcripts in the Transcript Analyzer to modify, update, and reprocess them if necessary.
The Transcript Analyzer demonstrates once again that Linked Jazz’s method of enhancing automated processes with human curation is effective for developing high quality LOD semantics. By combining automated and manual efforts, the Transcript Analyzer performs several important curatorial tasks within the Linked Jazz project. The mapping performed through the Transcript Analyzer enables the user to enrich the Linked Jazz Name Directory with accurate personal names that would be missed if only relying on the Mapping tool. The edits made by Transcript Analyzer users are formatted as rules, which the user can edit via the backend user toolbar (see Figure 4.1). These rules range from simple text strings flagged for the processer to ignore, to full <owl:SameAs> statements informing the system of the authority mapping of a newly coined URI for an individual added to the Linked Jazz namespace. After a transcript is processed, all rules—with the exception of local “Ignore” rules—become global rules that are then applied to the entire project. Thus, manual work complements and informs the automated process, making the entire flow of text processing more efficient over time. Manual intervention makes it possible to overcome the typical limitations of precision and recall common to traditional named-entity recognition tools. Human contribution through the creation of rules enables the Transcript Analyzer to incrementally improve its capacity to recognize names. Over time it fosters the ability to: locate new identities, semantically enhance the dataset through mapping to authorities, and, create reputable new URIs.
As a result of this combined method of processing transcripts, a more extensive set of names will be available to the crowdsourcing user, which will ultimately enhance the completeness and accuracy of the project’s outcome, the RDF dataset and the representation of the social network of jazz musicians.
Moreover, the Transcript Analyzer’s ability to track and apply user-generated rules, both locally and globally across transcripts, facilitates an easy working environment for teams to collaborate on backend processes remotely and independently of each other. This versatile tool could be applied to different domains and be beneficial to a wide range of LOD initiatives, provided the documents for analysis are rich in text that is in a readable, digital format. This tool opens up new possibilities for scholars, historians, and students to interact with and utilize open access transcripts. By employing different or multiple vocabularies, the Analyzer could be used to create RDF triples representing a variety of entities beyond just personal names, thus offering a tool that can support rich and heterogeneous interlinking.
Conclusion
As the amount of digital cultural heritage data continues to grow at an exponential rate, there is a call for new strategies and applications to enhance their discovery, interpretation, and use. The application of LOD technology to cultural heritage content holds enormous potential to answer this call.
Linked Jazz explores and develops methods and tools that can open new pathways for the use of cultural heritage materials in the digital age. With the goal of sharing our experience so far, this paper showcased a set of innovative analytical and curatorial tools that facilitate the creation of sound and rich LOD semantics and serve as the basis for building effective LOD applications. A key part of our approach to the development of these tools is to complement automated processes with human contributions and curation. While the tools described here were created to support the development of Linked Jazz, they are domain-agnostic and thus can be transferred and used in a wide range of application contexts. Our next step is to conduct performance testing on the tools and to later make them freely available to developers and the general public. As LOD technology continues to mature and more stable tools become available, it will be possible to streamline methods and continue to explore the unprecedented opportunities that LOD offers for cultural heritage data discovery and interpretation.
Acknowledgements
The Linked Jazz Project was initially funded through an OCLC/ALISE grant. We gratefully acknowledge our former team members Chris Weller and Ben Fino-Radin for their contributions to the project.
Notes
[1] http://linkedjazz.org/
[2] Linked Open Data in Libraries, Archives, and Museums (LODLAM) is a community of information professionals working to bring Linked Open Data into libraries, archives, and museums and make it usable for the larger Web community. More information can be found at http://lodlam.net.
[3] http://dbpedia.org/Downloads38
[4] These scripts and instructions on their use are available at https://github.com/thisismattmiller/linked-jazz-name-directory.
[5] http://linkedjazz.org/data/jazz_directory_aug_2012.nt
[6] http://viaf.org
[7] http://id.loc.gov/techcenter/searching.html
[8] http://linkedjazz.org/52ndStreet
[9] http://nltk.org/
References
Berners-Lee, T. (2006). Linked Data. Design Issues. Retrieved 9 April 2013 from http://www.w3.org/DesignIssues/LinkedData.html
Heath, T. & Bizer, C. (2011). Linked Data: Evolving the Web into a global data space. Synthesis Lectures on the Semantic Web: Theory and Technology, 1:1, 1-136. Morgan & Claypool. Available from: http://dx.doi.org/10.2200/S00334ED1V01Y201102WBE001
Pattuelli, M.C. (2012). Personal name vocabularies as Linked Open Data. A case study of jazz artist names. Journal of Information Science, 38(6), 558–565. Available from: http://dx.doi.org/10.1177/0165551512455989
About the Authors
M. Cristina Pattuelli (mcpattuel@pratt.edu) is the Project Director of Linked Jazz and an Associate Professor at the School of Information and Library Science at the Pratt Institute, New York. Her research focuses on information organization and knowledge representation methods and tools applied to information systems. Her current area of research is semantic web technologies applied to cultural heritage resources.
Matthew Miller (thisismattmiller.com) is a Developer for the NYPL Labs at the New York Public Library. He holds a dual master’s degree in Library and Information Science and History of Art from the Pratt Institute.
Leanora Lange (llange@cjh.org) is a processing archivist for the Center for Jewish History and Library Associate for Teachers College, Columbia University. She holds a MS in Library and Information Science from the Pratt Institute and an MA in German from the University of Illinois.
Sean Fitzell (sfitzell@pratt.edu) is currently working towards a Master of Library and Information Science at Pratt Institute with a focus on information architecture, knowledge management, and the creation of platforms for efficient information sharing. He’s also written about jazz, film, history, and other topics for many publications.
Carolyn Li-Madeo (cmadeo@pratt.edu) is a MLIS candidate at Pratt Institute. She holds a BA in History, Poetry and Book Arts from Hampshire College in Amherst, Massachusetts. She currently works at a college library in Brooklyn, NY and has worked on archival processing projects in academic and private collections.

Subscribe to comments: For this article | For all articles
Leave a Reply