by LIM Chee Kiam, Balakumar CHINNASAMY
What is Apache Mahout?
Apache Mahout [1] is a scalable open source machine learning library with implementations of a wide range of algorithms supporting use cases such as clustering, classification, collaborative filtering and frequent pattern mining.
Clustering takes a collection of documents and groups them into sets of related documents. Classification learns from documents in existing groups and assigns new documents to an existing group. Collaborative filtering recommends items based on user behavioural patterns, e.g. “people who borrowed this book also borrowed these other books”. Finally, frequent set mining takes item groups (such as shopping cart contents) and identifies which items usually appear together.
Many commercial and academic organisations make use of Apache Mahout [2] . For example, Foursquare uses Apache Mahout for its recommendation engine [3] .
For this paper, we will only focus on its ability to allow us to link content together by finding other similar content.
Why Use Apache Mahout?
Unstructured content, such as text articles, is a huge and growing portion of the data to which we all have access. However, unstructured content has always been a tad more challenging to work with.
Even for a small collection of a few hundred articles, the amount of time and effort needed to read and relate articles is already quite substantial. As the number of articles grows into the thousands and beyond, this gets exceedingly difficult. This difficulty is compounded when there is only minimal metadata on the articles in the collection.
New articles and updates to existing articles pose the additional challenges of having to create a new recommendation list and update previously completed recommendation lists.
It was precisely this problem that we first set out to address with our Proof-of-Concept on Apache Mahout.
The Singapore “Infopedia” [4] (http://infopedia.nl.sg) is a popular electronic encyclopedia on Singapore’s history, culture, people and events. With less than 2,000 articles, it attracted an average of over 200,000 page views a month in 2012.
Even for this small collection of articles, only a subset of the articles had recommendations to other related articles. (Note: This is no longer the case now as we have successfully utilized Apache Mahout to supplement the manual recommendations from the librarians.)
Apache Mahout generates recommendations for the full Infopedia collection in less than 5 minutes.
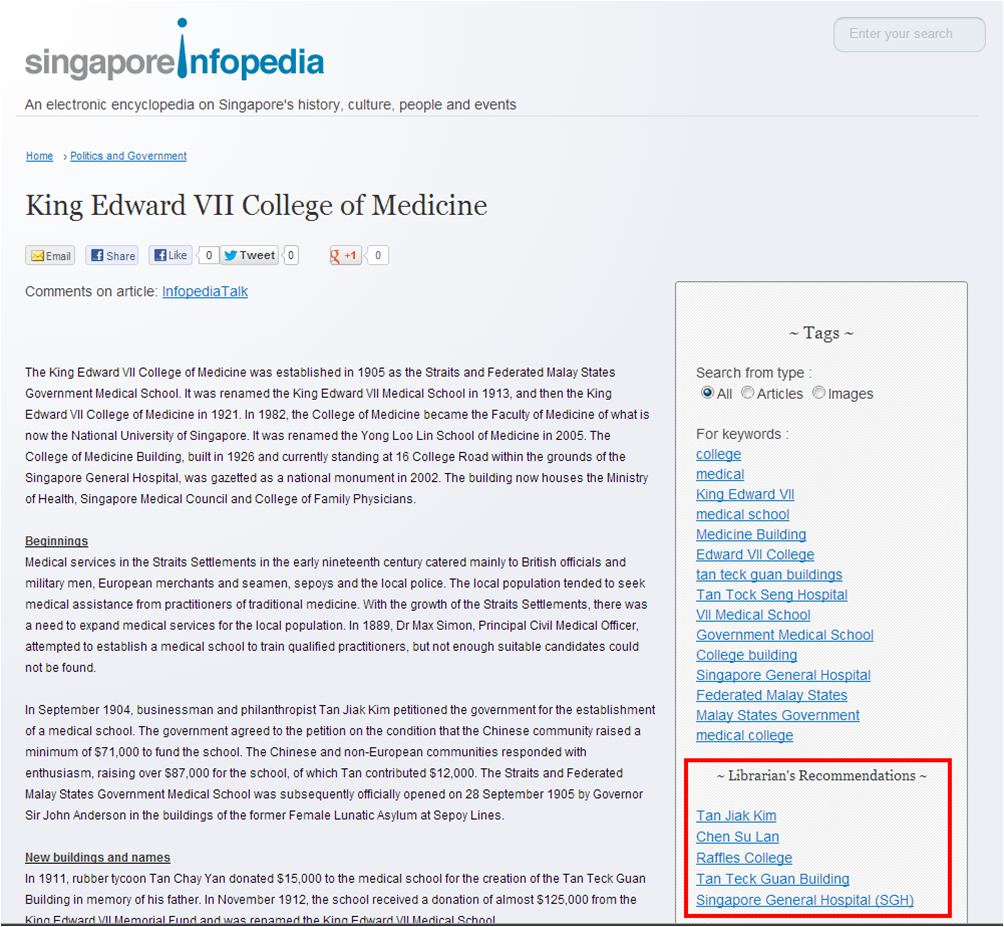
Figure 1:Infopedia article with manual librarian recommendations
Figure 1 is a sample article from Infopedia. The 5 manual recommendations for the article are highlighted in a red box.
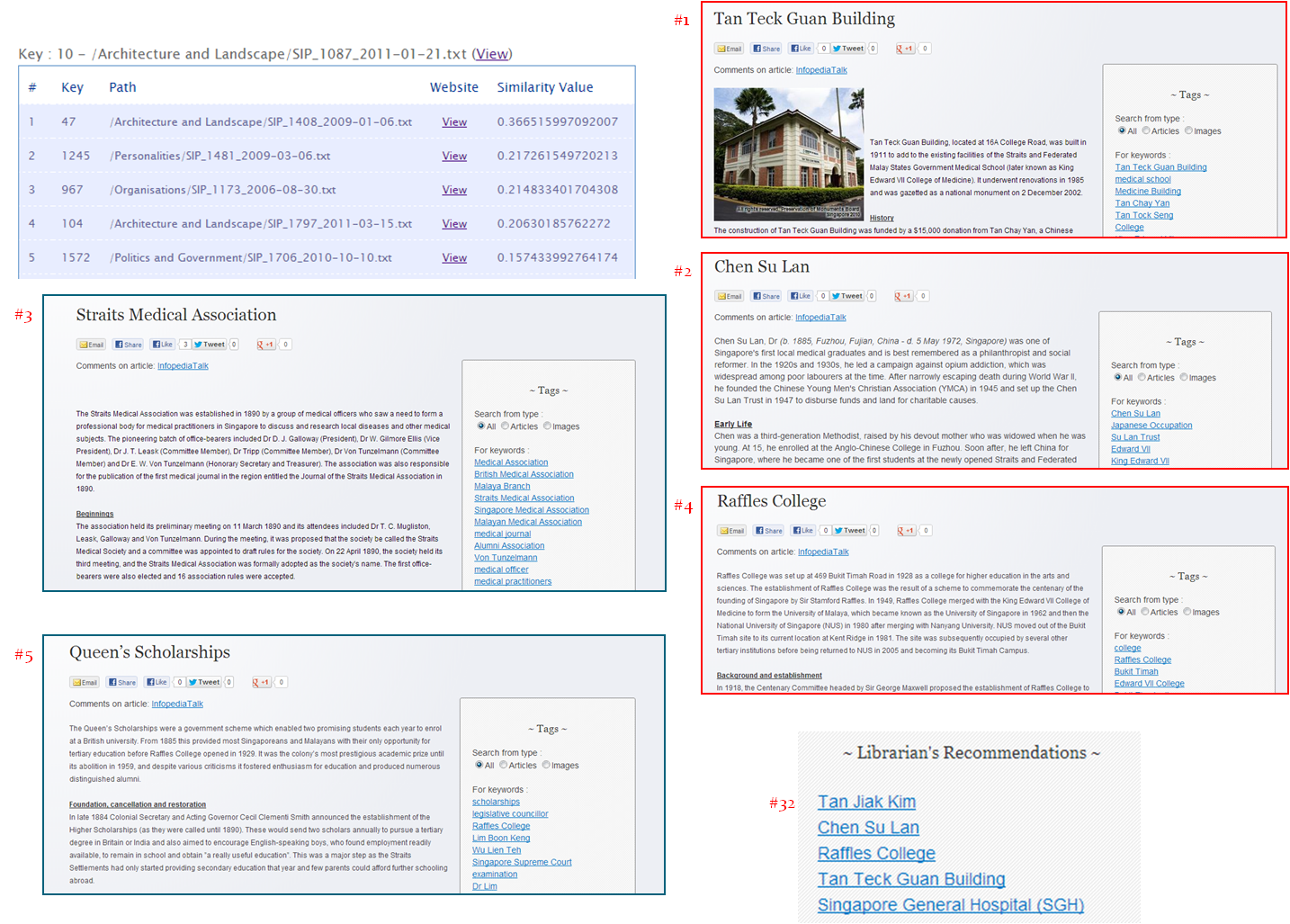
Figure 2: Infopedia text analytics sample result
The corresponding sample result in Figure 2 shows that 3 of the manual recommendations were among the top 4 recommendations automatically generated by Apache Mahout. In addition, Apache Mahout unearths a whole new set of relevant related articles.
Our librarians sampled 50 random articles and their recommendation results. They noted that 48% of the recommendations were highly relevant and another 27% were of medium relevance. The other 25% were of low relevance.
As of 13th June 2013, Infopedia articles are now supplemented with Apache Mahout generated recommendations in production.
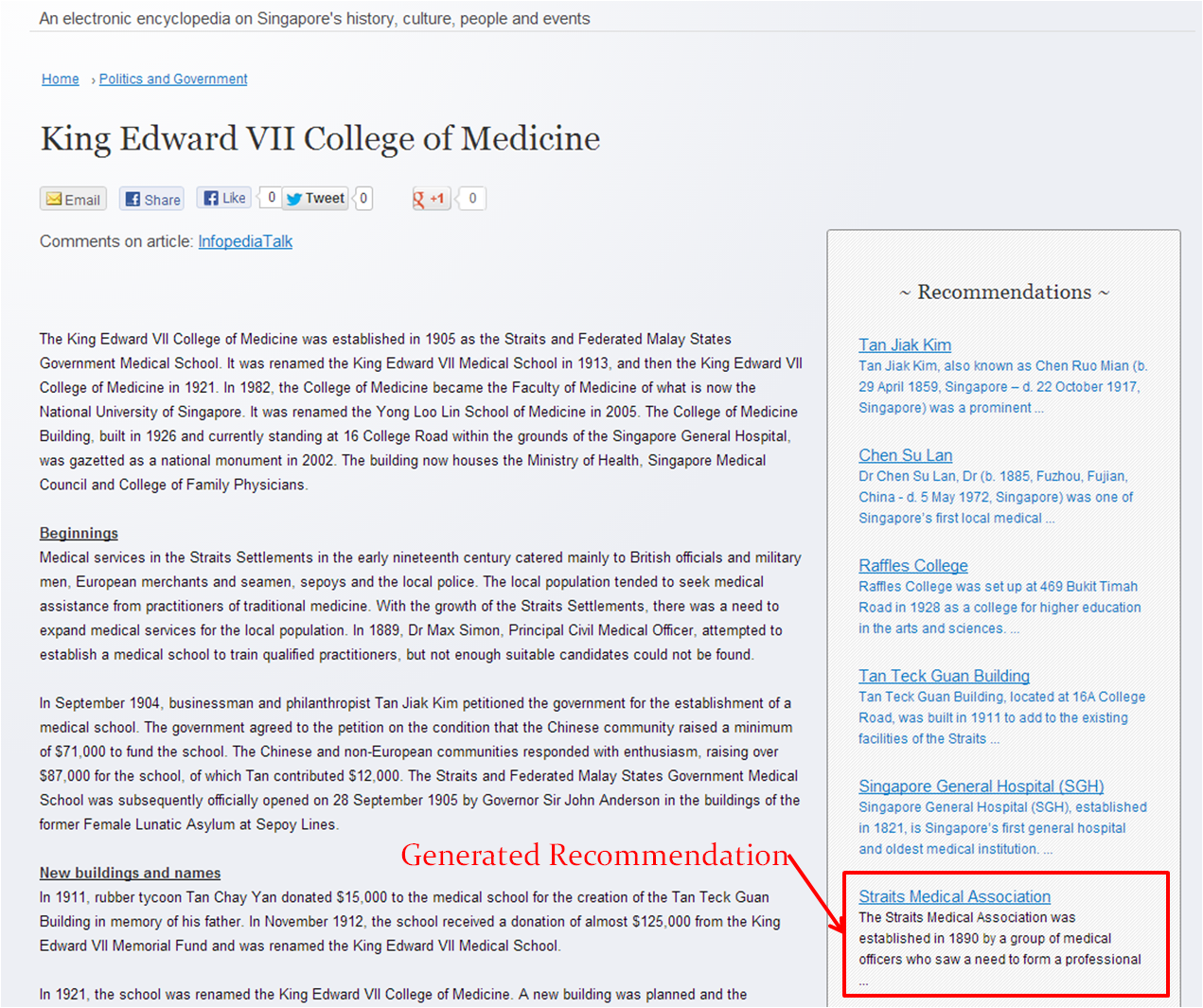
Figure 3: Infopedia article supplemented with Apache Mahout recommendations
The Apache Mahout results were generated by simply using the Apache Mahout command line. The next section delves into how this is done.
How to use Apache Mahout
Apache Mahout comes with a command line interface [5]. Our Proof-of-Concept was accomplished simply through the use of the command line.
The main steps are
- Obtain the text files
- Create the sequence files
- Create TFIDF weighted vectors
- Get the similarity results
- Integrate the results
Obtain the text files
We wrote a simple program to extract our Infopedia collection from our Content Management Server running Alfresco Community Edition.
Each Infopedia article is extracted into its own file. The file is named with the article’s unique identifier and contains the article title and text.
Create the sequence files
The next step is to create the sequence files to be used by Apache Mahout. To do that, we use the Apache Mahout command line as follows:
mahout seqdirectory \ -c UTF-8 \ -i datafiles/ \ -o seqfiles
The above command simply takes in UTF-8 encoded files from the datafiles folder as input and outputs the results into the seqfiles folder.
Create TFIDF weighted vectors
From the sequence files, we create TFIDF weighted vectors.
TFIDF stands for Term Frequency Inverse Document Frequency. TF measures the frequency of a term in a document while IDF measures the rarity of the term across the collection.
TFIDF gives a high value for a highly occurring term in a document that rarely occurs in the collection. This effectively filters out common terms.
mahout seq2sparse \ -i seqfiles/ \ -o vectors/ \ -ow -chunk 100 \ -x 90 \ -seq \ -ml 50 \ -n 2 \ -s 5 \ -md 5 \ -ng 3 \ -nv
The above command reads the sequence files created in the previous step and creates the TFIDF weighted vectors into the vectors folder. The created vectors are again sequence files that are used in the next step.
The important options to note in the command are as follows:
-x Max document frequency percentage -s Min support of the term in the entire collection -md Min document frequency -ng Maximum size of the n-grams
The first 3 options listed above help to reduce the number of terms to be considered. The -ng option instructs Apache Mahout to look beyond single words and consider “phrases” of up to 3 words.
In order to see all of the options and a brief note on their usage, execute the following command:
mahout seq2sparse --help
Note: The –help option works for the other mahout commands as well.
Get the similarity results
To get the similarity results, we first need to create a matrix from the vectors. Each row in the matrix is a document’s vector representation.
mahout rowid \ -i vectors/tfidf-vectors/part-r-00000 -o matrix
The above command will create the matrix in the matrix folder.
The actual computation is invoked with the following command.
mahout rowsimilarity \ -i matrix/matrix \ -o similarity \ --similarityClassname SIMILARITY_COSINE -m 10 -ess
This command generates the 10 most similar articles for each article into the similarity folder.
So how does Apache Mahout decide what is similar? In the above command, we instruct Apache Mahout to use cosine similarity as the distance measure between the various document vectors. Cosine similarity is commonly used when handling text articles.
The following command will extract the results into the similarity.txt file as text.
mahout seqdumper -i similarity > similarity.txt
The similarity.txt file contains records like the one below:
Key: 0: Value:
{14458:0.2966480826934176,11399:0.30290014772966095,
12793:0.22009858979452146,3275:0.1871791030103281,
14613:0.3534278632679437,4411:0.2516380602790199,
17520:0.3139731583634198,13611:0.18968888212315968,
14354:0.17673965754661425,0:1.0000000000000004}
...
The above record says that the article with key 0 has the following similar articles: article with key 14458 scored 0.297, article 11399 scored 0.303, and so on.
So how do we know which articles the key values are referring to? The next command extracts the document index into a text file named docIndex.txt.
mahout seqdumper -i matrix/docIndex > docIndex.txt
The docIndex.txt file contains records as follows:
Key: 0: Value: datafiles/SIP_254_2005-01-24.txt
Key: 1: Value: datafiles/SIP_690_2005-01-20.txt
...
Integrate the results
The final step involves enhancing our Infopedia website to process the similarity results and display the recommendations.
Coming Next
With the Infopedia recommendations in production, we have moved on to applying what we have learnt to our other collections. This includes a collection of photographs, where Apache Mahout processes text files containing the metadata associated with the photographs.
In addition, we have also experimented with cross-collection recommendations and will be pushing that out soon.
Conclusion
The discoverability of a library’s collections increases with the number of links within and across collections.
| Month | Pages |
|---|---|
| Jan 2013 | 227,241 |
| Feb 2013 | 217,004 |
| Mar 2013 | 243,081 |
| Apr 2013 | 226,199 |
| May 2013 | 272,715 |
| Jun 20131 | 282,878 |
| Jul 2013 | 341,485 |
| Aug 2013 | 349,923 |
1Infopedia with Apache Mahout recommendations launched on 13th June 2013
The table above shows the monthly page counts for Infopedia in 2013. It may not be conclusive that the improved discoverability of the articles is the cause of the increase in the monthly page counts but the numbers are definitely encouraging.
The ability to link content automatically is therefore essential for libraries to unearth the hidden values in their collections, especially for sizable collections that go beyond thousands of items.
Apache Mahout is an example of a technology that seems esoteric and obscure but is now readily available and accessible. The time is ripe for libraries to leverage such technologies to bring out the enormous values in their collections.
References
[1]. Apache Mahout, “Apache Mahout,” [Online]. Available: http://mahout.apache.org/. [Accessed 14 Aug 2013].
[2]. Apache Mahout, “Powered By Mahout,” 30 July 2013. [Online]. Available: https://cwiki.apache.org/MAHOUT/powered-by-mahout.html. [Accessed 26 August 2013].
[3]. J. Moore, “Building a recommendation engine, foursquare style,” 22 March 2011. [Online]. Available: http://engineering.foursquare.com/2011/03/22/building-a-recommendation-engine-foursquare-style/. [Accessed 26 August 2013].
[4]. National Library Board, Singapore, “Singapore Infopedia,” [Online]. Available: http://infopedia.nl.sg. [Accessed 15 August 2013].
[5]. P. Ferrel, S. Marthi. “Quick tour of text analysis using the Mahout command line,” 1 August 2013. [Online]. Available: https://cwiki.apache.org/confluence/display/MAHOUT/Quick+tour+of+text+analysis+using+the+Mahout+command+line. [Accessed 15 August 2013].
About the Authors
LIM Chee Kiam (chee_kiam_lim@nlb.gov.sg) is a Senior Solution Architect at the National Library Board in Singapore. Chee Kiam is responsible for doing the initial proof-of-concept on Apache Mahout and continues to drive related projects in this area.
Balakumar CHINNASAMY (balakumar_chinnasamy@nlb.gov.sg) is a Solution Architect at the National Library Board in Singapore. Balakumar is the key person bringing the Apache Mahout cluster and related services into production.

Subscribe to comments: For this article | For all articles
Leave a Reply