by Thomas Johnson and Karen Estlund
Introduction
Quality metadata is a critical part of digital library and archive collections. Metadata drives both curatorial and end-user interactions with objects, playing a key role in discovery, preservation, and everything in between. Within libraries, the importance of quality description to the utility of collections enjoys broad recognition. Despite this, limited resources mean that, at best, only modest expert attention is given to ensuring quality as records are created and maintained.
Metadata is often created with inadequate training, sparse documentation, and within systems that mishandle information. Quality problems are, as could be expected, pervasive. Once created, records are rarely subject to systematic review or evaluation, which generally requires human resources and expertise on a scale that makes it impractical for most organizations. Records are left to languish.
The aim of this work is to provide practical recipes for quality control and incremental enhancement of existing digital collections metadata. The recipes rely on the RDF data model and Linked Data practices as both an underlying framework and a toolset for metadata enhancement processes. If libraries do not have systems supporting RDF or Linked Data, the recipes may still be used to clean up and normalize metadata outside the system for re-ingestion into the existing systems. By relying on a statement-centric model, using URIs for controlled vocabularies, and welcoming external sources of information, libraries can improve both data quality and collection utility.
The Role of Linked Data
Linked Data brings with it a shift from a monolithic metadata model—in which an object has a single authoritative and mostly static record—to a distributed approach centered around individual statements from diverse sources. An early expression of this shift in ethos is “Anyone can say anything about anything” (Berners-Lee, 1997). At first blush, this might not inspire confidence that improvements in quality will result from this philosophy. The opportunity, however, lies in the possibility of sourcing quality externally and reusing information with greater accuracy, reliability, and depth than could be achieved with local resource limitations and institutional priorities.
Hillmann, Dushay, and Phipps (2004) have previously demonstrated the value of a statement-centric model as it applies to enhancement outside of the Linked Data context. In discussing augmentation processes intended for use on federated collections:
[I]t allows us to expose the source of each statement, and to reassemble these statements about resources in a variety of ways and for a variety of purposes, rather than expose a mélange of records and expect the downstream users to perform complex dissociations and recombinations.
By abandoning a record-centric model, metadata providers can begin to seek information from sources other than the human effort of staff. The reuse of outside metadata allows new information to be introduced while limiting the need for internal management.
Understanding Quality
Understanding metadata quality as something that can be managed and enhanced presents a significant conceptual challenge. Various authors have attempted definitions of quality, taxonomies of errors, or frameworks for assessment and analysis (Moen et al. 1997; Stvilia et al. 2004; Bruce & Hillman, 2004; Margaritopoulos et al. 2008). Broadly, these discussions are focused on assessing information quality in terms of detectable flaws and indicators such as “completeness, accuracy, provenance, conformance to expectations, logical consistency and coherence, timeliness, and accessibility” (Bruce and Hillman 2004). In lieu of further forays into this territory, we approach quality roughly and pragmatically.
The quality of a statement, when viewed context-independently, is simply the amount and accuracy of information that can be reliably extracted from it. This falls short as a formal definition, but provides a realistic guideline for performing actual enhancement work [1]. Contextual and domain-specific quality issues introduce an additional factor in “utility”—as explained by Sutton (2008)—which is harder to intuit and important to any effort at cost-benefit analysis. Still, for the purposes of the general recipes presented here, quality enhancement can be understood as a matter of introducing statements consisting of new information and removing obfuscating factors (errors and ambiguity) from existing data.
Beyond this, we want to call attention specifically to types and sources of errors addressed by the recipes outlined in this article:
Data entry errors in the form of typos, data entered into wrong fields, and statements that, for various reasons, contain no information at all.
System limitations resulting in unintelligible or badly encoded data. This occurs most often with unicode translation errors. For example, “Akh Töbei” should be “Akh Töbei.”:
Lack of control leading to inconsistent and hard to interpret data values. This also contributes to data entry errors and other accuracy issues.
Shifting strategies between different collections, federated collections, and within individual collections over time. This problem manifests as differing use of metadata elements, inconsistent application of controlled vocabularies, and changes in data entry practice (e.g. delimited vs. repeatable fields). These issues are usually accompanied by poor documentation, making interpretation a matter of local expertise and institutional memory.
Notation
Throughout the remainder of this article, we use Turtle [2] syntax to represent RDF metadata. In our examples, curation objects are designated by the qualified name ‘:object’ (or ‘:object1’, ‘:object2’, etc… where differentiation is called for). So a set of statements about an object appears in the form:
:object <metadataTerm> "Value" ; <metadataTerm2> <valueURI> .
Additionally, we make use of a number of prefixes to map URIs to shorter strings (CURIEs [3]). For example, dct:type maps to http://purl.org/dc/terms/type. The prefixes used are:
@prefix dce: <http://purl.org/dc/element/1.1/> @prefix dct: <http://purl.org/dc/terms/> @prefix dctype: <http://purl.org/dc/dcmitype/> @prefix foaf: <http://xmlns.com/foaf/0.1/> @prefix mads: <http://www.loc.gov/mads/rdf/v1#> @prefix cc: <http://creativecommons.org/ns#> @prefix prov: <http://www.w3.org/ns/prov#>
Examples of “legacy” source records are given in a simplified XML-like format. The structure typifies record-based, key-value metadata common to systems like CONTENTdm. We avoid specific schemas and element sets, preferring a general demonstration that can be broadly applied.
<record> <metadataTerm>Value</metadataTerm> <metadataTerm2>Another Value</metadataTerm2> </record>
Strategies for Mass Enhancement
Approaches to performing enhancement en masse depend somewhat on the nature of the collections in question and the quality of metadata at the start. Perhaps with undue pessimism, we assume a fairly messy state of affairs. Different collections likely use elements or value vocabularies differently, elements are probably made up ad-hoc, and ‘note’ or ‘description’ fields are almost certainly used arbitrarily, holding any data that didn’t have an obvious home at the time.
Because of these factors we recommend handling enhancement on a collection-by-collection basis. Applying generalized, but configurable, processes to individual collections helps to separate legacy records into groups that can be handled in roughly the same way. However, because practices are often poorly documented and inconsistent over time even within a collection, we also recommend a two-step approach to a Linked Data migration.
The initial step converts legacy metadata into RDF, performing cleanup operations that are ‘safe’ and applicable across collections. This process should do the following:
- Remove noise
- Normalize presentation
- Assign URIs for curation objects
- Map legacy elements to Linked Data vocabularies
Removing “noise” means eliminating valueless metadata entries. In some cases this means, quite literally, removing entries without any content. Hillmann, Dushay, and Phipps (2004) identify valueless statements as those that are empty, listed as “n/a” or “unknown” (or a variation), or consist solely of punctuation [4]. Other statements may be “valueless” because they contain meaningless or obfuscating information, e.g. duplicate or untimely entries.
<record> <title>Object with no Creator</title> <creator></creator> </record> <record> <title>Object with no Creator</title> <creator>Unknown</creator> </record> <record> <title>Object with Duplicate Information</title> <label>Object with Duplicate Information</label> </record> <record> <title>Object with Untimely Information</title> <identifier>staleId</identifier> </record>
Normalizing presentation is the process of abstracting away presentational aspects of metadata values. This includes condensing whitespace, handling encoding issues, individuating delimited values, and stripping non-semantic punctuation.
<record> <title>Object with Whitespace</title> <description> An object with extra whitespace </description> </record> <record> <title>Object with Encoding Issues</title> <description>Object depicts Khöltsöötiin Gol with accented vowels. </description> </record> <record> <title>Object with Delimited Creators</title> <creator>Johnson, T.; Estlund, K.</creator> </record>
Assigning URIs requires both a namespace and a source of unique ids. Though much effort could be given to FRBR-style entity relationship modeling, we find that a one-URI per object (“record”) methodology is the best approach where something more sophisticated isn’t necessary for a specific use case. Most digital collections already have some sort of unique record id that can be used as a simple source of identifiers. If there are perceived shortcomings with existing local identifiers, an identifier ‘minter’ like NOID is a good idea.
“Safety” of Automated Edits
Automated changes to metadata frequently raise concerns about the safety of existing information. Hillmann, Dushay, and Phipps (2004) describe an approach to “safe transforms” which carry “no risk of degradation”. The processes included in the initial step above closely align with those they outline as “safe”. Still, even under a fairly loose interpretation of “risk-free” enhancement, the changes that qualify must be severely limited in order to prevent incorrect assumptions and overwriting of good data.
More substantial enhancements, whether carried out by a machine or human, will invariably have some risk of data loss. Updated statements that are not strictly equivalent to their former expressions could always be a source of information degradation. The approach we suggest is to understand and manage this risk. A potential loss of poor quality information should not be allowed to prevent a well-understood, systematic gain elsewhere.
Managing Provenance
One strategy for managing the non-safety of automated updates is to carefully track provenance of data. Current Linked Data best practice recommends doing this through the use of “named graphs” (Carroll et al. 2005). Named graphs allow metadata statements to be grouped into sets which themselves can be the subject of statements expressing, for example, the source, licensing, or versioning of included statements (Dodds 2009; Shinavier 2010).
We suggest using named graphs to track the source of each statement. The number and scope of graphs used can vary widely depending on local needs. A practical scheme might employ a graph for each external data source and one containing each of the following:
- The initial RDF expression of the original, unenhanced data.
- Statements added or altered by human workflows.
- Statements generated by automated enhancement processes.
Using Turtle (TriG) for named graphs, four named graphs (G1-4) describing a cleanup activity may look like:
G1 (:object1 dct:title "Example" ;
dct:description "Object depicts Khöltsöötiin Gol with
accented vowels." .)
G2 (:G1 prov:DerivedFrom :OregonDigitalCONTENTdmExport .
dct:date "2013-01-10" ;
:G2 dct:date "2013-01-10" .
:OregonDigitalCONTENTdmExport prov:wasAssociatedWith :ORU .)
G3 (:object1 dct:description "Object depicts Khötsöötiin Gol with
accented vowels." .)
G4 (:G3 prov:DerivedFrom :EncodingCleanupScript1 ;
dct:date "2013-11-15" .
:G4 dct:date "2013-11-15" .
:EncodingCleanupScript1 prov:wasAssociatedWith :tJohnson .)
Implementing Recipes and Digital Asset Management Systems (DAMS)
Under these strategies and assumptions, the following recipes support the goal of incremental improvement of metadata and provide practicable approaches to enhancement. These recipes are designed as intermediary cleanup steps where the metadata is extracted and re-inserted in an existing system. Linked Data is used as a cleanup mechanism; however, the ideal solution would publish the resultant metadata as Linked Data, as well.
Recipe: Learning Control
Where controlled vocabularies are used in existing metadata, they are often undocumented and represented as hand-entered text values. Accordingly, they are subject to a variety of errors. Worse, they may be so poorly used that even identifying the presence of a controlled vocabulary may require specialist or localized knowledge. Replacing these values with URIs from a managed vocabulary offers an immediate quality improvement, turning the use of controlled terms into a self-documenting practice.
The DCMI type vocabulary provides a simple example. Our goal is to find legacy records using elements from the vocabulary, and replace them with RDF statements using the appropriate URIs.
Given the legacy record set:
<record> <type>Image</type> </record> <record> <type>Text</type> </record> <record> <type>PhysicalObject</type> </record>
We should be able to derive the statements:
:object1 dct:type dctype:Image . :object2 dct:type dctype:Text . :object3 dct:type dctype:PhysicalObject .
In simple cases, this “identification” can be done with any tool capable of reasonably context aware find/replace operations. All we need is a hard-coded set of mappings between expected values and URIs. Since DCMI Types contain only 12 terms, this is a small amount of work to power a bulk enhancement operation. We can prevent false positives by limiting the search to fields that might relate to the vocabulary.
In doing similar work with DCMI Types, Hillmann, Dushay, and Phipps (2004) observed that identification scales poorly to larger and more complex vocabularies. Though fairly manageable when working with a limited set of terms, hard-coded mappings become extremely work intensive as the complexity of the vocabulary grows. These scalability limitations are substantially mitigated, however, if potential vocabularies are restricted to those published as Linked Data. Using RDF documents as a machine-actionable expression of the vocabulary, identification and enhancement becomes an automated, configurable process.
To automatically convert plain text entries to their appropriate URIs we need two things:
- An RDF graph containing descriptions of each term in the vocabulary [5].
- Knowledge of which properties are labels that can be matched against text values. We use the following set of labels, listed in order of priority, as defaults:
- skos:prefLabel
- mads:authoritativeLabel
- dct:title
- rdfs:label
- foaf:name
- skos:altLabel
- mads:variantLabel
As an example, reconsider DCMI Types. The full set of types is described in RDF/XML at http://purl.org/dc/dcmitype/ and each term has an rdfs:label. Given the limited configuration below, we can automatically identify matches and replace them with appropriate URIs.
URI: http://purl.org/dc/dcmitype Source: dce:type Target: dct:type Replace: true
In addition to a URI for the vocabulary graph, the configuration consists of only a handful of optional fields. We limit the transformation to a set of source fields appropriate to the vocabulary. We may set a target predicate to use in generated triples if semantics are improved by the change. We can specify label URIs. And, finally, we set a replace flag to determine whether old triples should be deleted as derivatives are added.
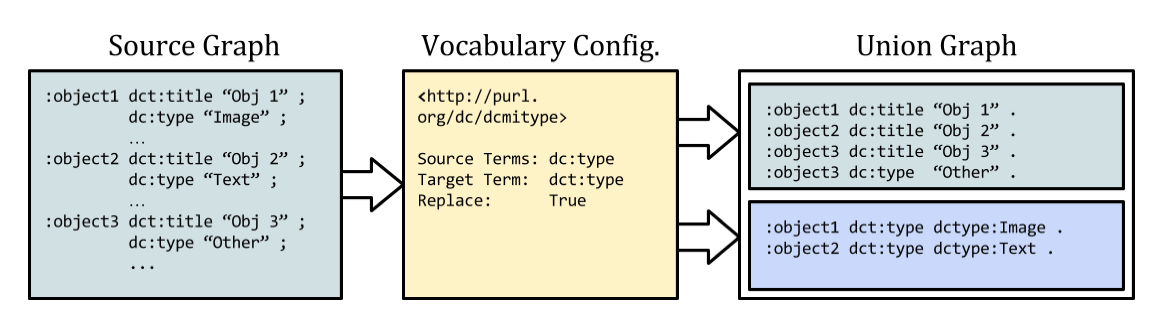
Figure 1: Transforming DCMI Type values into URIs. Unmatched values are ignored. Following the named graph convention, we may choose to segregate and describe the resulting triples.
The process now takes a defined set of steps which can be applied independently of vocabulary size.
- Dereference the graph URI.
- Parse the resulting graph [6].
- Generate a list of URIs and their labels.
- Search for legacy values across desired fields.
- Map elements and values, adding statements to a named graph.
Recipe: Drawing Connections
Discovering New Links
Perhaps the most powerful aspect of this configurable interaction with external vocabularies is that it need not be limited to working with vocabularies already used in source records. A minor addition to the process allows more complex transformation logic to be applied on a per-vocabulary basis. This can be used to implement Linked Data vocabularies in place of ad hoc terms where a relationship can be identified between existing data and RDF labels.
The transformation logic replaces the normal text-to-label matching with arbitrary code specified in the vocabulary configuration (we implement this as a dynamic method call in Ruby). Generally, this code runs some combination of preprocessing source values, identifying full or partial text matches, and adding new statements.
We have used this approach to transform text entries referring to Creative Commons licenses into links to appropriate URIs.
:object1 dce:rights "CC BY-NC-ND 3.0" . :object2 dce:rights "CC BY 3.0" . :object3 dce:rights "Public Domain" .
These rights statements give us enough to go on to identify URIs for the licenses. The logic, in this case, is a simple process breaking out the aspects of the license (‘BY’, ‘NC’, ‘3.0’, etc…), recombining them, and mapping them to the license in the Creative Commons ‘controlled vocabulary’. It generates a single statement defining the relationship between the digital object and the license URI, then dereferences the latter, adding appropriate statements further describing the license.
:object1 dct:license <http://creativecommons.org/licenses/by-nc-nd/3.0> .
<http://creativecommons.org/licenses/by-nc-nd/3.0/>
cc:permits cc:Reproduction;
cc:requires cc:Attribution;
cc:prohibits cc:CommercialUse;
dct:title .
"Attribution-NonCommercial-NoDerivs 3.0 Unported" .
:object2 dct:license <http://creativecommons.org/licenses/by/3.0> .
<http://creativecommons.org/licenses/by/3.0/> cc:permits cc:Reproduction;
cc:requires cc:Attribution;
cc:permits cc:DerivativeWorks;
dct:title "Attribution 3.0 Unported" .
:object3 dct:license <http://creativecommons.org/publicdomain/mark/1.0> .
<http://creativecommons.org/publicdomain/mark/1.0>
cc:permits cc:Reproduction;
cc:permits cc:DerivativeWorks;
cc:permits cc:Distribution;
dct:title "Public Domain Mark 1.0"@en .

Figure 2: Adding Creative Commons licenses as Linked Data. The “Union Graph” contains the statements in the source data, as well as those generated by the configuration and logic.
The pattern can be applied to more expansive vocabularies or cases where matches between existing values and URIs are less straightforward. Using GeoNames, for example, we have been able to connect uncontrolled place names across our collections and, in the same stroke, access an external and authoritative source of geographic coordinates.
It must be said that the human effort needed in this process is more substantial, both in terms of metadata specialist and programmer time. The complexity of the ‘logic’ step and the need for care in provenance management grows as enhancements get more sophisticated. Quality gains must be weighed pragmatically against their associated costs. The effort required is justified only when a clear use case for the new data has been identified.
Recipe: Tidying Up
Identifying controlled vocabularies can only provide a partial solution to quality issues arising from their undocumented or inconsistent use. Unfortunately, identification works best where the data quality already meets a minimum standard. Poor data quality in the form of typos, encoding issues, and inconsistent use over time presents a barrier to identifying a URI with a clear relationship to the existing text value. Cleaning up, then, must happen as a gradual, incremental process.
Identifying Exceptions
Searching for and marking exceptions to the use of controlled vocabularies can be a powerful tool for identifying poor quality data. Generating a list of terms used outside the vocabulary allows for quick analysis. Returning to DCMI Types as an example, consider the following records:
<record> <type>Image</type> </record> ... <record> <type>IMG</type> </record> <record> <type>Text</type> </record> ... <record> <type>TXT</type> </record> <record> <type>Special Object</type> </record> <record> <type>Other</type> </record>
If we have gone through the previous recipes, the result is a set of statements with two distinct predicates: the source statements (dce:type) and the enhanced ones (dct:type).
:object1 dct:type dctype:Image . :object2 dce:type "IMG" . :object3 dct:type dctype:Text . :object4 dce:type "TXT" . :object5 dce:type "Special Object" . :object6 dce:type "Other" .
Values from outside the controlled vocabulary can be identified trivially by querying for statements with the original predicate. Outputting a list of these values lets us review bad data at a glance and map values for normalization. In the example, mapping “IMG” to dctype:Image and “TXT” to dctype:Text, yields a more consistent output. Data that continues to evade normalization can be left alone or identified as ‘valueless’ and deleted:
:object1 dct:type dctype:Image . :object2 dct:type dctype:Image . :object3 dct:type dctype:Text . :object4 dct:type dctype:Text . :object5 dce:type "SpecialObject" .
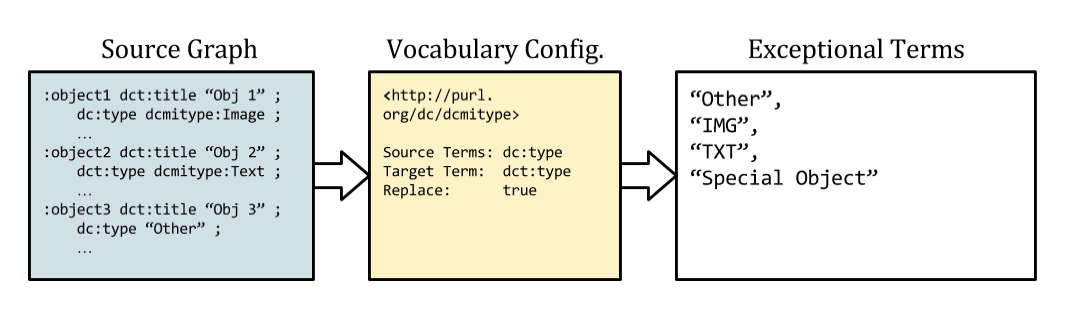
Figure 3: Identifying exceptional terms
Conclusion
We view these recipes as providing a starting place for the continual improvement of metadata statements. Using the statement-centric approach, the willingness to link to outside information sources, and the named graph provenance strategy, metadata records are no longer held static by their pretensions to “authority”. Instead, they become mutable and flexible, subject to a quality feedback loop through reuse and sharing.
Footnotes
[1] Bruce and Hillmann (2004) compare quality to pornography: “We know it when we see it”.
[2] Terse RDF Triple Language. A primer for RDF in Turtle can be found at: http://www.w3.org/2007/02/turtle/primer/
[3] http://www.w3.org/TR/curie/
[4] Generally, this is a simple matter of ignoring the field as the record is processed. An exception may arise when a value of “unknown” is intended to explicitly state that a property’s value is unknown universally, not only locally, which occurs often within our artwork collections. The distinction arises from the Open World Assumption, which is core to Linked Data. Under this assumption, we may read empty values as unknown locally, but potentially known externally.
[5] Best practice for publishing Linked Data dictates that resource URIs return RDF serializations via HTTP content negotiation (Bizer et al. 2007). Many vocabularies return a full graph of their terms from a single URI as in the example. Larger vocabularies are often published as compressed “dumps” which can be downloaded, decompressed, and used locally.
[6] We use Raptor (http://librdf.org/raptor/) to parse the graph. In Ruby, the rdf-raptor gem will do the work of steps 1 and 2:
require ‘rdf’
require ‘rdf/raptor’
graph = RDF::Graph.load(“http://purl.org/dc/dcmitype”)
References
Berners-Lee, T. 1997. Web architecture: Metadata [internet]. [cited 2014 January 2]. Available from: http://www.w3.org/DesignIssues/Metadata.html
Bizer, C., Cyganiak, R., Heath, T. 2007. How to Publish Linked Data on the Web [internet]. [cited 2014 January 2]. Available from: http://wifo5-03.informatik.uni-mannheim.de/bizer/pub/LinkedDataTutorial
Bruce, T.R, and Hillmann, D.I. 2004. The Continuum of Metadata Quality: Defining, Expressing, Exploiting. In: D. Hillmann & E. Westbrooks, editors. Metadata in Practice. ALA Editions. Available from: http://hdl.handle.net/1813/7895
Carroll, J.J., Bizer, C., Hayes, P., Stickler, P. Named graphs, provenance and trust. In: WWW ’05 Proceedings of the 14th International Conference on the World Wide Web. New York, NY: ACM. p. 613-622. Available from: doi:10.1145/1060745.1060835
Dodds, L. 2009. Managing RDF Using Named Graphs [internet]. [cited 2014 January 2]. Available from: http://blog.ldodds.com/2009/11/05/managing-rdf-using-named-graphs/
Hillmann, D.I., Dushay, N., Phipps, J. 2004. Improving Metadata Quality: Augmentation and Recombination. In: Metadata Across Languages and Cultures. Proceedings of the 2004 DCMI International Conference on Dublin Core and Metadata Applications. Available from: http://dcpapers.dublincore.org/pubs/article/view/770
Margaritopoulos, T., Margaritopoulos M., Mavridis I., Manitsaris A. 2008. A Conceptual Framework for Metadata Quality Assessment. In: Proceedings of the 2004 DCMI International Conference on Dublin Core and Metadata Applications. Available from: http://dcpapers.dublincore.org/pubs/article/view/923
Moen, W.E., Stewart, E.L., McClure, C.R. (1997). Assessing metadata quality: Findings and methodological considerations from an evaluation of the US Government information locator service (GILS). In: Proceedings of the Advances in Digital Libraries Conference, 1998. IEEE Computer Society. p. 246. Available from: doi:10.1109/ADL.1998.670425
Shinavier, J. 2010. Position Paper: Named Graphs in Linked Data [internet]. [cited 2014 January 2]. Available from: www.w3.org/2009/12/rdf-ws/papers/ws25.pdf
Stvilia, B., Gasser, L., Twidale, M.B., Shreeves, S.L., Cole, T.W. 2004. Metadata Quality for Federated Collections. In: Proceedings of ICIQ04 – 9th International Conference on Information Quality. Cambridge, MA. Available from: http://hdl.handle.net/2142/721
Sutton, S.A. 2008. Metadata Quality, Utility and the Semantic Web: The Case of Learning Resources and Achievement Standards. Cataloging and Classification Quarterly. 46(1). Available from: doi:10.1080/01639370802183065
About the authors
Thomas Johnson is Digital Applications Librarian at Oregon State University Libraries and Press, where he works on digital curation, scholarly publication, and related metadata and software issues.
Karen Estlund is the head of the Digital Scholarship Center at the University of Oregon Libraries, where she provides support for faculty and student digital scholarship projects and vision and leadership for the growth of the library’s digital collections and scholarly communication activities.

Eric Lease Morgan, 2014-01-20
This is very interesting. Dirty metadata is most certainly a problem that needs to be dealt with in Library Land, and I certainly like the idea of making it available as linked data, but alas, I was hoping for some code or demonstrations on how one or more of these recipes were put into practice. For example, how might one go about “preparing one of these meals”? Any suggestions? Maybe I should just dump my library catalog as MARC, serialize it into RDF, process each triple, and reverse the process? –ELM