By Austin Dixon
If done by hand, the digitization process for audio can be slow, tedious, and error prone. Thankfully, the process is benefited by the use of custom scripts that utilize open source tools. I will describe three scripts that I wrote for our department and how they have greatly improved our workflow.
Traditionally, the workflow for audio digitization involves manipulating the master .wav files manually using the flowing steps:
Step 1. Digitize the original reel tapes into master. wav files.
Step 2. Digitally optimize each file (level the volume and remove extraneous silence) using a digital audio editing suite such as Sound Forge [1].
Step 3. Split master .wav files by hand into sub-item tracks using the audio editing suite. This is done by visually selecting a portion of the audio file’s wave form, copying it, and then saving that copy as a new file.
Step 4. Convert sub-item tracks from .wav to .mp3 format using the audio editing suite. The master .wav files are then archived on a server and the .mp3 tracks are uploaded to an online database.
After initially performing this process manually for several items, I realized that the process was unnecessarily problematic. Specifically, splitting the master .wav file in step 2 was not only a very tedious task which took an ample amount of time to complete, but it introduced too much room for human error. It is difficult to visually select accurate start and end times, and this difficulty increases with the number of tracks that must be split. When done incorrectly, tracks begin too soon or end too early or unacceptable overlaps are introduced. So I began researching how we could complete this task programmatically, thus speeding up the process and removing the possibility of human error.
I knew that in order to split an audio file programmatically, I would need a reference file to identify the location of begin and end times for each sub-item track, and this reference file would need to adhere to a strict schema so my scripts could easily process it. My research revealed that there were not many readily available schema options. I considered using ADL (Audio Decision List) files, which is a form of metadata that many librarians use for this exact purpose, but ADL files were larger and more complicated then I needed for such a simple task. They also are not designed to be easily readable by humans, which becomes important if any sort of troubleshooting is ever required. I eventually decided to use cue sheets [2]. The cue sheet schema was first developed to be used with CDRWIN (a CD/DVD burning software for Microsoft Windows), and can be used by media players to determine where tracks begin and end. While not typically used by libraries for digitization purposes, using cue sheets to split our tracks appealed to me over other methods for three reasons:
- Unlike other options, cue sheets can be used by many open source tools such as Shntool, a .wav processing utility, to manipulate files [3]. Using these open source tools would save me a considerable amount of programming time.
- Cue sheets are easy for humans to read.
- Cue sheets are easy to build via a script because they follow a very simple format.
After studying up on cue sheet structure, I created a script, CueMaker [4] (using Python 3.2), that will take a text file I supply with item identifiers and track times, and use it to generate a .cue file for each item. This input text file is easy to create; in our workflow a Metadata Librarian is responsible for supplying me with item level metadata for each track, which includes the item identifiers and track times. I simply cut and paste this information into a text file in the following manner:
Filename1 Begin Time
Filename2 Begin Time
Only each track’s begin time is required, as each begin time is also the previous track’s end time. The first track’s begin time is always 00:00.

Figure 1. Sample Cue Sheet.
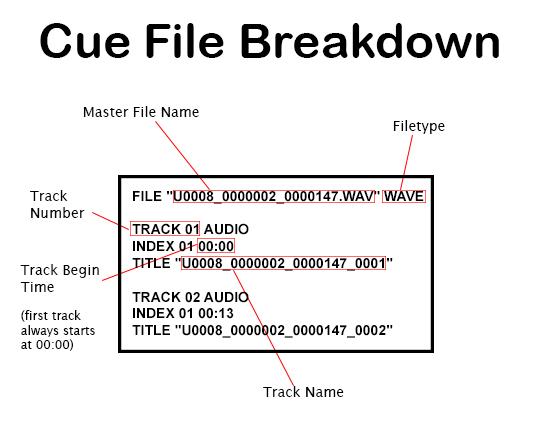
Figure 2. Understanding the parts of a Cue Sheet.
Here is a sample of the Python code I used to build the. cue file:
def main():
fileName = getFile()
trackTitle, trackTime = timecode(fileName)
makeCue(fileName, trackTitle, trackTime)
def getFile():
f = open("cue.txt","r")
fileName = f.readlines()
f.close()
return fileName
def timecode(fileName):
trackTime = []
trackTitle = []
num = 1
while (num < len(fileName)):
s = fileName[num].split(' ')
time = s[1]
title = s[0]
trackTime.append(time)
trackTitle.append(title)
num = num + 1
return trackTitle, trackTime
def makeCue(fileName, trackTitle, trackTime):
t = 1
num = 0
q = '"'
header = 'FILE ' + q + fileName[0].rstrip() + q + ' WAVE'
file = open("file.cue","w")
file.write(header)
file.write('\n\n')
while (num < len(trackTime)):
if (t < 10):
trackName = "TITLE " + q + trackTitle[num] + q
ts = "0" + str(t)
track = "TRACK " + ts + " AUDIO"
index = "INDEX 01 " + trackTime[num].rstrip()
file.write(track)
file.write('\n')
file.write(index)
file.write('\n')
file.write(trackName)
file.write('\n\n')
t = t + 1
num = num + 1
else:
trackName = "TITLE " + q + trackTitle[num] + q
track = "TRACK " + str(t) + " AUDIO"
index = "INDEX 01 " + trackTime[num].rstrip()
file.write(track)
file.write('\n')
file.write(index)
file.write('\n')
file.write(trackName)
file.write('\n\n')
t = t + 1
num = num + 1
file.close()
main()
Once the CueMaker script was functional, I created another script, CueSplitter [5](this time using Perl 5.16.1), that sends a command line argument to the system evoking Shntool. Shntool is an open-source WAVE data processing utility. I choose to use it in my script because it handles .wav files very well, and can perform complicated tasks with one-line commands. I can also use it in conjunction with Lame, an open-source software codec used to encode/compress audio into .mp3 file format [6]. The command I use in my script makes Shntool read the generated .cue file and use it to split the master .wav file into sub-item tracks. Once split, the sub-item tracks are converted from .wav to .mp3 format using Lame. Here is the command:
shntool split -f cue_file -t%t -o “cust ext=mp3 lame --quiet - %f” -d output_file wav_file
The script also names the files correctly by using the item identifier (title) in the .cue file. Then I created a graphic user interface, Cue GUI [7] (using Perl 5.16.1 and Tkx, a Perl module that “provides yet another TK interface for Perl” [8]), that could launch both scripts with the push of a button.
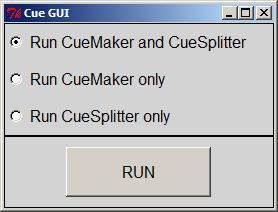
Figure 3. Screenshot of the graphic user interface.
So our new workflow now consists of:
Step 1. Digitize the original reel tapes into master .wav files.
Step 2. Digitally optimize each file (level the volume and remove extraneous silence) using a digital audio editing suite.
Step 3. Run CueMaker and CueSpliter scripts by using Cue GUI. Then archive the master .wav files to our server and upload the resulting .mp3s to our online database.
As you can see, steps one and two have not changed. I am working on a script that will level the audio automatically. When it is complete, I will build it into the CueSplitter script. Unfortunately, the extraneous silence removal will (probably) always require human intervention.
To test these new steps, we used them to process 18 new items, consisting of 207 audio tracks. The time and effort it took to upload these tracks using the scripts instead of our old workflow was significantly lower since the most labor intensive tasks are now completed instantly with one button press. We have gauged that this process saves us approximately one hour per item. Other libraries that are digitizing audio in a manner that results in a concatenated master file should be able to use the method I have outlined here to help them split and convert the audio tracks quickly and easily. I have made the code for my cue scripts open source so other libraries can use them in their workflow as needed. The scripts can also be easily customized by anyone with some basic programming knowledge.
References
[1] Sound Forge Product Family Overview [Internet]. Middleton (WI): Sony Creative Software; [cited 2014 Jan 13]. Available from: http://www.sonycreativesoftware.com/soundforgesoftware.
[2] Wikipedia contributors. Cue sheet (computing) [Internet]. Wikipedia, The Free Encyclopedia; 2014 Jan 7, 0:13 UTC [cited 2014 Jan 13]. Available from: http://en.wikipedia.org/wiki/Cue_sheet_(computing).
[3] Jason Jordan. Shntool [Internet]. Etree.org; [cited 2014 Jan 13]. Available from: http://www.etree.org/shnutils/shntool/.
[4] CueMaker [Internet]. University of Alabama Libraries Digital Services; 2013 Jun 11, 14:10 EDT [cited 2014 Jan 13]. Available from: http://www.lib.ua.edu/wiki/digcoll/index.php/CueMaker.
[5] CueSplitter [Internet]. University of Alabama Libraries Digital Services; 2013 Jun 11, 14:09 EDT [cited 2014 Jan 14]. Available from: http://www.lib.ua.edu/wiki/digcoll/index.php/CueSplitter.
[6] Roberto Amorio and Sebastian Mares. LAME MP3 Encoder [Internet]. The LAME Project; [cited 2014 Jan 14]. Available from: http://lame.sourceforge.net/index.php.
[7] Cue GUI [Internet]. University of Alabama Libraries Digital Services; 2013 Jun 11, 13:58 EDT [cited 2014 Jan 14]. Available from: http://www.lib.ua.edu/wiki/digcoll/index.php/Cue_GUI.
[8] Tkx [Internet]. CPAN; [cited 2014 Jan 14]. Available from: http://search.cpan.org/~gaas/Tkx-1.09/lib/Tkx.pm.
About the Author
Austin Dixon (ardixon1@ua.edu) is the Digitization Technologist for the University of Alabama Libraries’ Digital Services department.

Subscribe to comments: For this article | For all articles
Leave a Reply