by James Powell, Harihar Shankar, Marko Rodriguez, and Herbert Van de Sompel
Introduction
EgoSystem was developed to support outreach to former Los Alamos National Laboratory (LANL) employees. As a publicly funded research organization, there are many reasons why LANL would want to maintain contact with its “alumni.” Scientific research is often collaborative. Former employees know the Lab and its work, and often have colleagues who remain employed at LANL. These relationships fuel intra- and interdisciplinary projects. Government research agencies are also encouraged to partner with the private sector. Productizing LANL output becomes an opportunity for a public-private or commercial entity via a technology transfer process. Some small businesses (and jobs) owe their existence to ideas that were first developed at LANL. Public support for the ongoing research at LANL plays a role in ensuring support for adequate funding levels for that work. Outreach to alumni can encourage them to serve as ambassadors and advocates for LANL and its mission.
Cross searching of online social networks remains an unsolved problem. These networks are, to some extent, a reflection of the ties between people in the real world. People use online social networks to establish connections with one another and to share information. They may also explore the social networks of their connections to make new connections of their own to friends, family members, co-workers, experts in a particular field, or popular celebrities such as writers, film or tv stars, politicians, etc. Users are generally limited to exploring each online social networks to which they belong within the confines of that site. For example, the social network within Twitter consists of people who follow or are followed by other users. Twitter users can explore these relationships when they are logged into Twitter to find new connections. Facebook users can use Facebook Graph Search (https://www.facebook.com/about/graphsearch) to locate other users. But aggregate comprehensive search is generally not possible. Online social networking sites remain walled gardens [1].
EgoSystem is intended to address social searching across identities for a defined population (postdoctoral students). Postdocs spend a fixed amount of time at LANL and many then move on to private sector employment. Exit interviews ensure that LANL retains some basic demographic information about the students. EgoSystem uses this demographic information to discover postdoc identities on the Web. A discovery process uses some simple, iterative heuristics to find public online network identities and the explicit networks surrounding them. It also retrieves public online information about the individual that might lead to additional connections. Person identities can be connected through co-authorship relationships, co-employment relationships, or information that reveals that two individuals work, study or perform research in similar fields. In EgoSystem’s graph, discovered identities are mapped to primitive vertex types which we refer to as platonic vertices. EgoSystem provides a Web interface with social search exploration and analysis capabilities for this graph. Platonic vertices that correspond to a person, concept, artifact, or institution each have their own profile page. Select end users can use the Web interface to search or traverse the connections among these vertices.
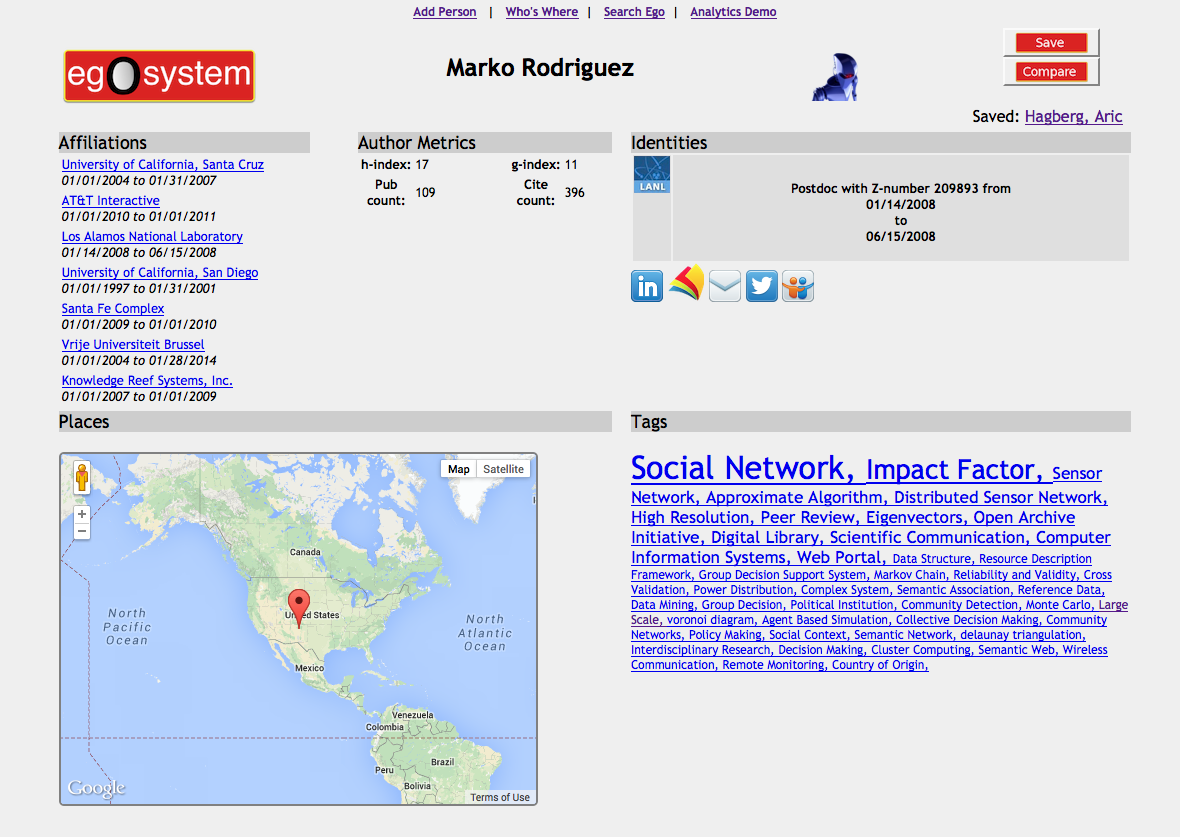 Figure 1: EgoSystem displaying profile page for Marko Rodriguez
Figure 1: EgoSystem displaying profile page for Marko Rodriguez
Discovery
The discovery process for EgoSystem is designed to find online identities of LANL’s postdoc alumni community. LANL conducts a basic exit interview of postdocs before leaving the Lab, and the discovery process uses this as seed data. It constitutes minimal data necessary to locate and validate an online identity for a person. An example seed entry for a postdoc is shown below:
Name: Rodriguez, Marko PhD university: University of California, Santa Cruz Field of study: Computer Science, Computer Networks Joining company: AT&T Title: Scientist Field of work: Graph theory, Graph databases
The discovery process searches for identities in a predefined set of social and academic Web portals. It approximates the steps a human would use to find online identities. Discovery starts with a Web search, which is based on some basic demographic information about a person. When a person identity is found, identities are also often found for related institutions and artifacts. This information is used to augment the initial seed data, and the process is repeated. During subsequent iterations of the discovery process, other person identities, affiliations, artifacts and concepts may be discovered. Concepts are discovered using the augmented data since they are based on keywords associated with affiliations and artifacts. The same is true for connections, which are discovered once person identities, institutions, and artifacts have been found. EgoSystem starts to create connections between person vertices as more concepts, artifacts, identities and institution affiliations are found.
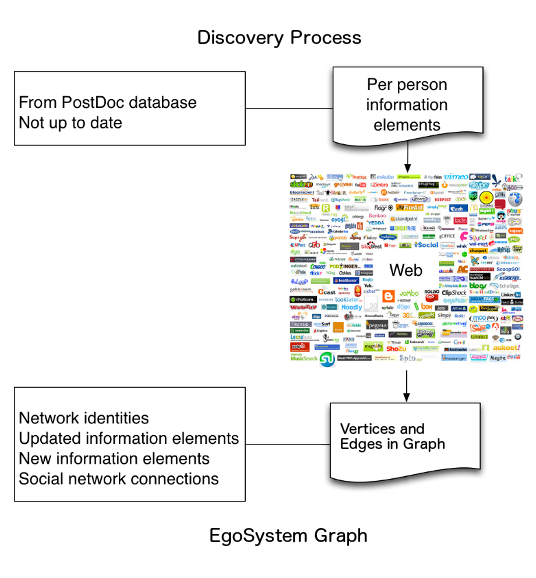 Figure 2: Discovering identities
Figure 2: Discovering identities
At this point, EgoSystem’s discovery process targets identities within Microsoft Academic, LinkedIn, Twitter, and SlideShare. It also searches for public homepages and Wikipedia pages. Institutional identities are retrieved from Wikipedia, LinkedIn, or the institutional home pages (like http://lanl.gov/). Geocoordinates for institutional locations are discovered using the Google Maps API. Concepts are retrieved from LinkedIn, Microsoft Academic and SlideShare. Artifact metadata is retrieved from Microsoft Academic, SlideShare and Twitter. Some identities are discovered through Yahoo Search using the Yahoo Boss API, which is its programmatic interface. The Yahoo Search strategy employs the same techniques a person might employ, using various combinations of seed data in conjunction with the name of a site of interest.
For example, here are some variations for a query on Marko:
Marko+Rodriguez+linkedin Marko+Rodriguez+Los+Alamos+National+Labs+linkedin Marko+Rodriguez+Graph+Database+slideshare
The results of these various search strategies are analyzed, duplicates are removed, and the HTML page for each resulting URL is retrieved. This HTML page is parsed and identity information is passed to the validator for verification. This works well for locating content-rich pages such as those within Wikipedia, but less so for social networking sites that lack an API, such as LinkedIn. Screen-scraping is brittle, as even minimal changes to the underlying HTML can cause identity discovery to fail. Therefore, whenever possible, site specific programmatic APIs are used. Microsoft Academic, Twitter and Google Maps provide APIs that support searching and retrieval of data in machine readable formats such as XML and JSON. Native, service-specific APIs like Microsoft Academic provide information about the person directly, and this data can be passed on to the validation module.
Web homepages also pose a challenge. Hence, other techniques as discussed in [4] and [5] are used to retrieve information and validate this content. To determine if a webpage is indeed a homepage of a person, EgoSystem checks if the domain name in the URL is the domain name of an institution the person is associated with. Then, it checks to see if the title of the page contains the full name of the person. It also checks for the person’s name in the page’s URL (like http://public.lanl.gov/mrodriguez).
| Seed Data | First Discovery Iteration Adds | Second Discovery Iteration Adds |
| Person: Name: Rodriguez, Marko Affiliation (PhD university): University of California, Santa CruzField of study: Computer Science, Computer Networks Institution (left to work at): AT&T Title: Scientist Concepts (field of work): Graph theory, Graph databases |
New Identity: www.linkedin.com/in/markorodriguez Affiliation: worked at Graph Systems Architect Institution: Aurelius, LLC Affiliation: Visiting Researcher at Institution: Vrije Universiteit Brussel Concepts: |
New Identity: Artifact: (recent tweets) Connections: identities of people that follow, are followers of this identity |
|
New Identity: http://academic.research.microsoft.com/Author/3534935 Artifacts:
Concepts: Connections (co-authors): Johan Bollen, Herbert Van de Sompel, Jennifer H. Wakins, Alberto Pepe, etc. |
New Identity: http://www.slideshare.net/slidarko Artifact:
Connections: identities of people following this identity |
The validator component is responsible for verifying that the profile obtained by the discovery process is a correct identity for that person. It compares the seed information to the information retrieved from searches, and awards points for every correct match. If the profile scores more points than a set threshold, then it is considered a correct identity for the person.
An exact match for the last name of a person is necessary to validate a profile, otherwise the validation fails at this step. For first names, if an exact match is not found, fuzzy pattern matching is used to determine if the first names are close. For the name “James Powell”, “Jim Powell” would be accepted by the validator while “James Powel” will not be.
After the name is validated, at least one of the retrieved institution names must match the institution listed for that person in the seed data. Again fuzzy pattern matching is used to match the name of each institution. If all of the institutions in the seed information are determined to be valid, then the profile is accepted as a valid identity. If only one institution is deemed valid, then at least one area of expertise or the job title must match in order for the profile to be validated. The scoring system to validate an online profile was introduced by Northern and Nelson [2].
Twitter profiles generally do not contain professional information, so EgosSytem uses a validation technique comparing institutional Twitter identities to their immediate social neighborhood. If a candidate Twitter identity is following an institution listed in that person’s seed data, and the name for this identity also matches, then the Twitter identity is accepted as valid.
Pilot project
Seed information for 3005 postdocs were uploaded to EgoSystem and the discovery algorithms were executed for these individuals. The discovery algorithms for LinkedIn, Twitter, and Microsoft Academic only require the original seed data and can run independently of one another. These algorithms supply additional information required by the other discovery algorithms which locate homepages, Wikipedia pages, Mendeley, SlideShare, and other identities. LinkedIn and Microsoft Academic were the sites that provided the most information about the Lab’s postdoc community. Among the 3005 postdocs, the discovery modules found 1963 Microsoft Academic identities, 833 LinkedIn identities and 176 Twitter profiles.
At the end of the pilot project, we conducted a cursory review of the discovery algorithm performance. This consisted of a manual search of a subset of postdocs which was then compared with the results of the discovery algorithms. Among the 100 postdocs that were manually searched, we found that the discovery algorithm results were correct for 86 identity searches in Microsoft Academic. More specifically the algorithm found 71 correct identities, and did not find identities for 15 other people who in fact did not have profiles. Among the 14 incorrect identities, 2 were wrongly assigned and 12 identities that existed were not found. For LinkedIn, the discovery algorithm results were correct for 88 identity searches in LinkedIn. In this case, it found 34 identities which were correct, and did not find identities for 54 other individuals who did not have LinkedIn profiles. The remaining 12 identity search results were incorrect, of which one profile was incorrectly assigned to a user, and 11 existing profiles were not discovered even though they existed. For Twitter identities, 4 of the identities found by the algorithms were incorrect and 2 existing profiles were not found. The remaining 94 people did not have Twitter identities, and the discovery algorithm correctly determined this to be the case. In this limited sample, it appears that the discovery algorithms achieve both high precision and high recall for this set of online identities in the targeted Web sites.
The graph
The data accumulated via the discovery process is mapped into a property graph model [4] defined for EgoSystem (see figure 4). A property graph contains vertices and edges which can have arbitrary key/value pairs associated with them. It is the specific key/value pairs chosen for a given property graph that refine the vertex and edge types for a given application. In the case of EgoSystem, vertices fall into two categories, platonic vertices and affiliation vertices. A platonic vertex is one of the four primitive types: person, institution, artifact, and concept. These four types share many of the same properties, as illustrated in figure 3. Affiliation vertices bind platonic nodes together in flexible ways. For example, a postdoctoral student might have both worked for and studied at a given institution for different time periods, and two affiliation vertices are used to express these distinct relationships. Edges represent the direction of a relationship and their properties are concerned with the type of relationship, including workedFor, studiedAt, authored, hasConcept, and hasAffiliation. These vertices and edges allow all the various relationships and objects discovered to be represented within EgoSystem’s graph.
 Figure 3: Example of a property graph
Figure 3: Example of a property graph
The property graph is stored in Aurelius’ Titan, a distributed graph database capable of representing and processing graphs on the order of hundreds of billion edges and sustaining tens of thousands of transactions a second over a multi-machine compute cluster. This technology enables organizations to build massive domain models that include not only the direct information of their objects of inquiry (for example, particular people), but also the periphery of information that can be leveraged to understand how these objects are embedded within a larger context (for example, other objects of interest such as other people, artifacts, organizations, and concepts). Titan enables EgoSystem to encompass not only the data in professional graphs (for example, LANL employee database, LinkedIn), but also knowledge graphs (for example, Wikipedia), artifact graphs (for example, Microsoft Academic, ArXiv, GitHub), and personal graphs (for example, Facebook, Twitter). Adding machine nodes to the cluster enables more storage and compute resources to be allocated to storing and processing the graph.
Problem-solving is accomplished via the Gremlin graph traversal language. Gremlin allows graph traversals to be represented as path expressions. For example, a request to list the names of people who Marko doesn’t know, but who are known by Marko’s friends:
g.V('name','marko').out('knows').name
To expand upon that query, a request to list the names of the people that Marko’s friends know that Marko doesn’t already know is expressed as:
g.V('name','marko').out('knows').aggregate(x).out('knows').except(x).name
Gremlin supports memory and branch structures which allow it to recognize or traverse any arbitrary path through a graph.
When Gremlin is used with Titan, sub-second local neighborhood traversals are enacted (similar in form to the traversals above). In order to do long-running, global analytics of the graph, Aurelius provides Faunus. Faunus executes parallel sequential scans of Titan graphs in order to support bulk loading, global graph analysis, bulk mutations, etc. As is the case with Titan, Gremlin is also the graph traversal language leveraged by Faunus. For example, to determine the distribution of age within the graph, the following global scan can be enacted:
g.V('type','person').age.groupCount
We chose Titan over other currently available property graph databases (such as OrientDB, Neo4j, DEX, and InfiniteGraph) because of its Apache2 license, horizontal-scalability, global analytics package (via Faunus), and direct support of the standard Blueprints graph API (analogous to JDBC but for the graph database community).
A property graph is known in academic circles as a directed, attributed, multi-relational, binary graph:
- directed: an edge has a tail and a head vertex.
- attributed: vertices and edges can have an arbitrary number of key/values pairs.
- multi-relational: edges are types to support multiple types of relationships
- binary: an edge connects only two vertices
Another popular graph representation is the RDF graph data model of the Semantic Web effort. There are two primary distinctions between these two models: in RDF, vertices and edge labels are identified by URIs; and property graphs support properties on edges. A major modeling benefit of the property graph model is that edges can support properties and thus, edges can have, for example, timestamps, weights, provenance information, etc. In RDF such edge reification is solved using “blank nodes” and typically leads to a graph structure that is difficult to query. Another major distinction between RDF and property graphs is the means by which they are queried. SPARQL is a Prolog-like language for RDF where patterns are specified and those resources that bind to the pattern are returned. Conceptually, SPARQL queries a graph using pattern matching and Gremlin queries using traversal. For example, “Who are the friends of Marko that have also been employed by the Los Alamos National Laboratory?”
In SPARQL:
SELECT ?y WHERE {
lanl:marko foaf:knows ?x
?x foaf:workedFor lanl:LANL
?x foaf:name ?y
}
In Gremlin, the above is written as:
g.V('name','marko').out('knows').as('x')
.out('workedFor').has('name','LANL').back('x').name
Gremlin supports complex path traversals as well as property value matching and filtering on both vertex and edge properties. Free-form text searches against property values use ElasticSearch, which is bundled with Titan. ElasticSearch uses Lucene to build a full text index for the name property value for each platonic vertex. This enables users to search for person and institution names, artifact titles, and keywords. ElasticSearch is also used to build a geospatial index of points representing locations for institutions. Geospatial searches against this index return items that fall within a circle that represents the user query. ElasticSearch makes it possible to search for person vertices that have institutional affiliations within a certain distance to a given location. Gremlin works transparently with ElasticSearch. Here is a traversal which expands on a previous example to determine the distribution of the ages of people in the Santa Fe area:
g.V('type','person').has('location',Geo.WITHIN,Geoshape.circle(35.6843,-105.961,20)).age.groupCount
EgoSystem was initially populated with data about 3005 postdoctoral students, which were represented as platonic person vertices. The discovery process found 116,466 non-LANL people which were connected to these postdocs in some way, of which 38,111 represented Twitter identities and 78,355 were author identities from Microsoft Academic. It also found 1,395 institutions through LinkedIn. The total number of vertices in the resulting property graph for EgoSystem was 9,015,844, and the total number of edges was 19,399,683.
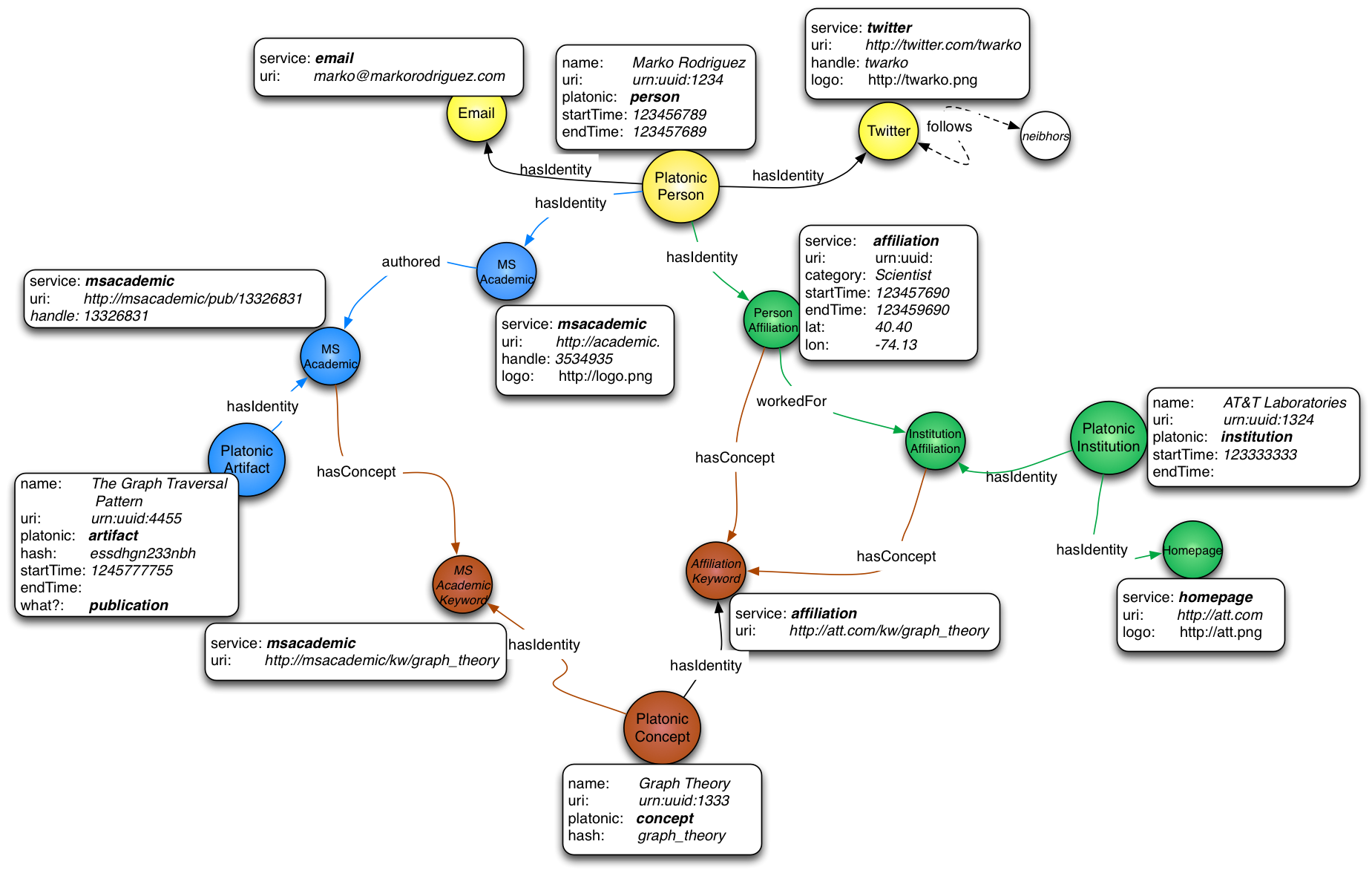 Figure 4: EgoSystem property graph model
Figure 4: EgoSystem property graph model
The user interface
The property graph can be explored using EgoSystem’s Web interface. The default starting point is a simple, Google-like search page with a single input field and a search button. This search executes four searches against properties for all four platonic vertex types. Results are organized by platonic vertex type: people, institutions, artifacts and concepts.
EgoSystem’s Web interface is implemented in Javascript and runs in the user’s browser. It makes extensive use of AJAX technologies to communicate with the server hosting the property graph, and to dynamically generate Web content. The interface makes calls to a server side REST API, implemented in Groovy, which uses the Blueprint API [5]. The backend accepts JSON requests and returns vertex and edge information as JSON objects. When a user searches for a person by name, the following steps occur:
- Their query is converted to a JSON object
- The JSON object is submitted to a REST request called
getThingByName - The service responds with a JSON object that contains all of the information for matching platonic vertices
Here is an example of a JSON client request, and a JSON server response:
Request:
{"name": "Marko"}
Response:
{
"properties": {
"platonic": "person",
"name": "Rodriguez, Marko",
"startTime": null,
"endTime": null,
"frame": "gov.lanl.egosystem.frames.platonic.Person",
"locked": 1374698679437,
"uri": "urn:uuid:e92925c5-91d1-4b26-a67b-48c561643edf",
"alias": null
},
"methods": [
{
"method": "discoverTwitter",
"parameterTypes": "[EgoSystemGraph]",
"returnType": "Boolean",
"canExecute": true,
"description": "Execute the Twitter discovery algorithm for this platonic"
}
...
],
"identities": [
{
"properties": {
"location": null,
"handle": "twarko",
"service": "twitter",
"logo": "http://a0.twimg.com/profile_images/395313322/exterminator_normal.png",
"name": "Marko A. Rodriguez",
"startTime": null,
"endTime": null,
"frame": "gov.lanl.egosystem.frames.identities.twitter.TwitterPerson",
"locked": null,
"uri": "http://twitter.com/twarko"
},
"methods": [
{
"method": "getFollowers",
"parameterTypes": "[]",
"returnType": "Iterable",
"canExecute": true,
"description": "No description is available"
},
...
The Javascript interface is implemented as a set of objects representing platonic types, the results of a query, or the results of a path traversal. These objects are implemented using Prototype functions [7]. For example, instances of the EgoPlatonic object encapsulate platonic vertex properties, regardless of the platonic type, as well as set and get methods. When an instance of an EgoPlatonic object is created, values from properties of a vertex returned by a getThingByUri request are mapped to fields in the object. The object can then be inspected via its get methods.
function EgoPlatonic(jsonPlatonic) {
this.uuid = jsonPlatonic.properties.uri;
this.name = jsonPlatonic.properties.name;
this.hash = jsonPlatonic.properties.hash;
this.kind = jsonPlatonic.properties.platonic;
...
EgoPlatonic.prototype.getName = function() {
return this.name;
}
EgoPlatonic.prototype.getKind = function() {
return this.kind;
}
EgoPlatonic.prototype.getServices = function() {
return this.services;
}
The Web interface dynamically constructs a profile page using vertex data contained in an instance of an EgoPlatonic object, in combination with a set of simple rules represented as a JSON object. A platonic person profile is a dynamically generated Web page that incorporates all of the affiliations and identities in the property graph for that individual. A profile page is permanently addressable via a persistent and shareable URL. Much of the profile page information depends on the identities associated with the particular platonic vertex. Each identity vertex includes properties which define the kinds of services it supports. A rule set matches service types with graphical components that can render them.
{
"antecedent": {
"methodName": "getPlatonic",
"returnType": "Platonic",
"parameterTypes": "[]",
"canExecute": true,
"uri": "http://academic.research",
"service": [ "msacademic" ],
"renderAs": "*",
},
"consequent": {
"component": "author.html"
}
},
All platonic types have their own distinct representation in the Web client. An institution page includes institutional identities such as the organization’s homepage and Wikipedia page, if found, as well as clickable lists of concepts and people associated with that organization. Concept pages (shown in figure 5) and artifact pages are built in a similar fashion. EgoSystem constructs a concept or profile page by first retrieving information about the concept or artifact’s platonic vertex, and then traversing outgoing edges to gather information about identity vertices to which the platonic vertex is connected. When a user clicks on concepts, people or artifacts, they are actually navigating the underlying graph via identity and platonic vertices. If a user clicks on a link for an identity, EgoSystem will attempt to resolve that identity to a platonic vertex and display a profile page. If no platonic vertex exists (for example, a non-LANL person identity), EgoSystem will redirect the user to an external Web page for that identity.
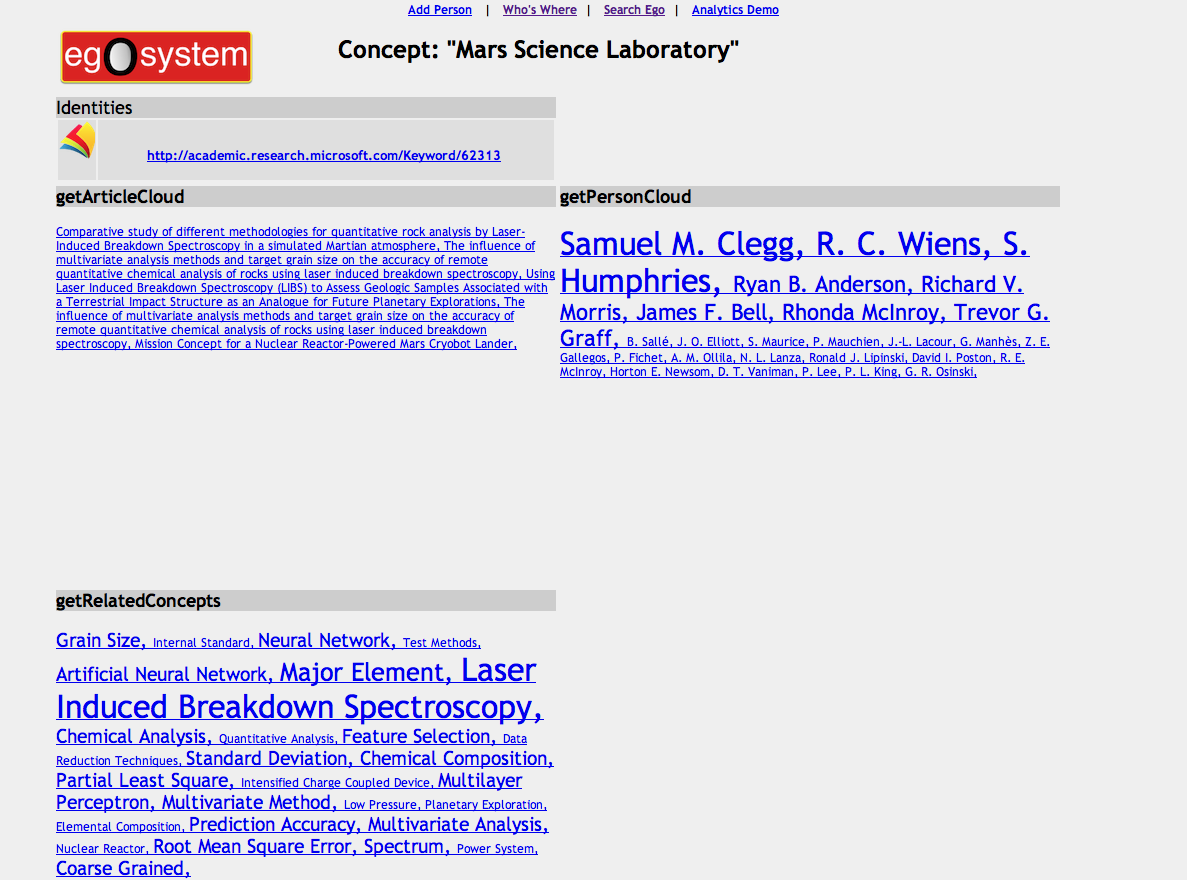 Figure 5: EgoSystem concept profile page
Figure 5: EgoSystem concept profile page
The user interface provides two other types of search. A user can search for individuals who are or were located within a certain distance of a particular geographic location. This interface uses an AJAX-based location lookup service to suggest and resolve place names to latitude and longitude coordinates, which are then searched against location information associated with identities in the graph. Results are overlaid onto Google maps. Users may also search for individuals who were associated with an institution during a certain time range. The results are presented as a list of person names which point to the profile page for their platonic vertex.
Graph visualizations and textual list-based representations of first degree social networks are available from a person’s profile page. The graph visualization is generated using the Javascript D3 libraries [8]. Users may interact with the graph, rearrange vertices, or click through to profile pages just as they can from the text view of the social network. Both LANL and non-LANL identities are included in these social networks.
Path discovery is also supported through the interface. A user may “save” a person as they search or browse EgoSystem. From another person profile, the user can locate identity-specific paths that might exist between these two people, including institution, Twitter, co-authorship, etc. If a path exists between these two people, the traversal can be viewed as a graph visualization or a list of links for the vertices that connect them.
The “save” function also supports a rules-based comparison tool. A user may compare the person they are currently viewing with a saved person. During the compare process, EgoSystem’s interface iterates through the identities for each person. When both individuals possess a given identity, rules determine which services associated with those identities should be called. If both people have a given identity, say a Twitter identity, then service requests (such as getFollowers) are made for each Twitter identity, and the results are merged and displayed. The comparison view shows shared social connections, concepts linking two people, and a combined timeline of employment history.
Figure 6 shows the results of an EgoSystem compare request for two LANL alumni. Starting at the top left, EgoSystem presented their combined publication metrics as a textual summary and as a bar chart. Since both people have a Twitter account, EgoSystem called the getFollows and getFollowers methods to construct a pair of graph visualizations to show their combined follows and followers networks respectively. Next, EgoSystem displayed a combined employment and education timeline. Since both people have LinkedIn identities, EgoSystem called the getConcepts method for each to construct a combined concept graph. Both people also have Microsoft Academic identities, so EgoSystem called the getTagCloud method for each to generate a combined tag graph from that data. Finally, EgoSystem called two other methods associated with Microsoft Academic identities, getCoauthorPaths and getCoauthors, to generate a shared co-authorship path visualization and a combined co-authorship graph.
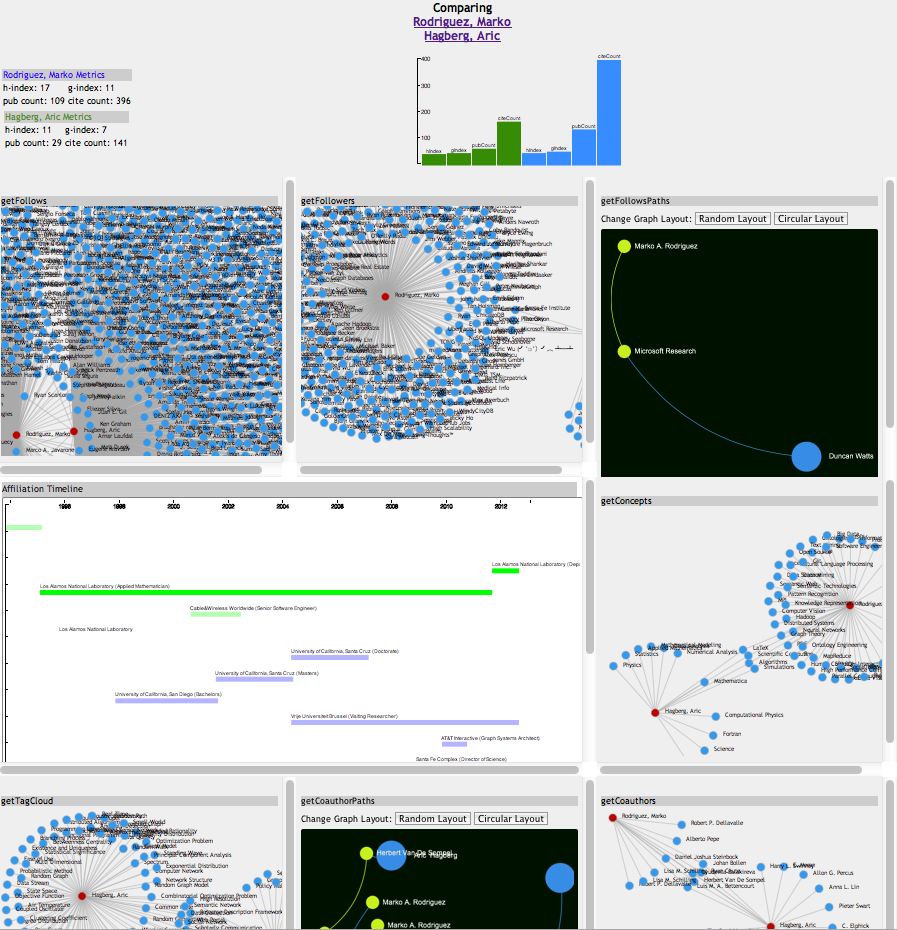 Figure 6: EgoSystem comparison interface
Figure 6: EgoSystem comparison interface
The following example shows the JSON request and response for a getFollowers service request:
Request:
{"uri": "http://twitter.com/twarko" "method": "getFollowers"}
Response:
{
"result": [
{
"properties": {
"outDegree": null,
"inDegree": null,
"location": null,
"handle": "drmichaelham",
"service": "twitter",
"logo": "http://a0.twimg.com/profile_images/2927745307/5e05b6cc43e0e10bb1dee2f95c5af5e7_normal.jpeg",
"name": "drmichaelham",
"startTime": null,
"endTime": null,
"frame": "gov.lanl.egosystem.frames.identities.twitter.TwitterPerson",
"locked": null,
"uri": "http://twitter.com/drmichaelham",
"alias": null
}
},
...
EgoSystem’s Web interface also allows adding new people to the graph via the “Man on the Street” form. A user can supply some basic demographic metadata about a person to which they seek a connection through a LANL alumni. This information, like the seed data used to initially populate the system, includes name, a place they worked, job title, a university they attended, and some keywords related to their area(s) of expertise. As with the initial bootstrap process, a platonic vertex is added for this person, and then each discovery method is executed. Any identities are added to the graph. The user can then immediately view the new person’s profile, look at their identities, concepts, institutions, and artifacts, find paths to them through LANL people, or compare them to other people in EgoSystem.
Profiles provide access to a person’s immediate neighborhood. The profile comparison tool and the path queries show a portion of the graph that links two people. There are also lower level tools for cross-graph analysis. The system can generate reports on graph-wide characteristics such as total vertex and edge counts, or counts by vertex or for all vertices which are of a particular type, or which have a property that has a particular value. Demographic reports such as how many postdocs came from or went to a given institution are possible because the underlying graph records the direction of an affiliation and the temporal data associated with that relationship. There are also some more advanced, focused reports for analysis such as by-institution flows. Data for these reports is output in standard graph markup languages because the resulting subgraph can be quite large. This enables users to download the graph representation and then load, visualize and manipulate the data using more robust desktop graph visualization tools such as Gephi.
Conclusion
EgoSystem’s discovery module, property graph, and Web interface work together to provide what we believe is a novel and useful aggregated social search capability for a defined community. It automates the otherwise time-consuming and laborious task of finding public online identities with a reasonably high degree of accuracy. It aggregates and stores this information, many aspects of which are inherently network oriented, as a richly descriptive property graph in a graph database. The results describe a community of former Lab-affiliates augmented with social network information, geographic data, institutional affiliations, temporal data, and data about their intellectual pursuits. As originally envisioned, select LANL staff can use this system to locate, re-establish contact, and establish closer ties between LANL and its alumni. Perhaps just as importantly, the connections that accumulate in this graph can reveal additional information that is not readily apparent. This could prove beneficial for activities such as recruiting and identifying partners for collaborations in the future.
Endnotes
[1] Hinchcliffe, Dion, 2014. Where is interoperability for social media? ZD Net, Enterprise Web 2.0, February 28, 2014. http://www.zdnet.com/where-is-interoperability-for-social-media-7000026894/
[2] Northern, Carlton T., and Nelson, Michael L. 2011. Unsupervised Approach to Discovering and Disambiguating Social Media Profiles, Proceedings of Mining Data Semantics (MDS 2011).
[3] Yi Fang, Luo Si and Mathur, Aditya P. 2010. Discriminative graphical models for faculty homepage discovery. Inf. Retr. 13, 6 (December 2010), 618-635. http://dx.doi.org/10.1007/s10791-010-9127-7
[4] Qi, X. and Davison, B. D. 2009. Web page classification: Features and algorithms. ACM Comput. Surv. 41, 2, Article 12 (February 2009), 31 pages http://doi.acm.org/10.1145/1459352.1459357
[5] Rodriguez, Marko A. and Neubauer, Peter. 2010. Constructions from dots and lines. Bulletin of the American Society for Information Science and Technology, Volume 36, Issue 6, pages 35–41, August/September 2010. http://dx.dio.org/10.1002/bult.2010.1720360610
[6] Blueprints. https://github.com/tinkerpop/blueprints/wiki
[7] Port, Sebastian. 2013. A Plain English Guide to Javascript Prototypes. http://sporto.github.io/blog/2013/02/22/a-plain-english-guide-to-javascript-prototypes/
[8] D3 Data-Driven Documents. http://d3js.org
About the Authors
James Powell is a Research Technologist in the Research Library at Los Alamos National Laboratory, where he is currently a member of the Digital Library Research & Prototyping Team. Since joining LANL, he’s been involved in a number of information retrieval projects that incorporate Semantic Web and graph analysis technologies. His current interests include Graph Theory and complex systems.
Harihar Shankar is a Research and Development Engineer in the Research Library at Los Alamos National Laboratory. He holds a Master’s degree in Computer Engineering from the University of New Mexico and his interests include digital preservation and retrieval, information infrastructure, data mining and scientific communication.
Dr. Marko A. Rodriguez is the founder and CEO of the graph computing company Aurelius, where the team focuses on the development of the open source graph computing technology. Marko is the lead developer of the Gremlin graph traversal language and the Faunus graph analytics engine. Previous to Aurelius, Marko was a graph architect at AT&T and a PostDoc at the Center for Non-Linear Studies at the Los Alamos National Laboratory, where he focused on the development of a multi-relational graph algebra. Marko received his masters and Ph.D. from the University of California at Santa Cruz in Computer Science and his bachelors in Cognitive Science from the University of California at San Diego.
Herbert Van de Sompel graduated in Mathematics and Computer Science at Ghent University (Belgium), and in 2000 obtained a Ph.D. in Communication Science there. For many years, he headed Library Automation at Ghent University. After leaving Ghent in 2000, he was Visiting Professor in Computer Science at Cornell University, and Director of e-Strategy and Programmes at the British Library. Currently, he is the team leader of the Prototyping Team at the Research Library of the Los Alamos National Laboratory. The Team does research regarding various aspects of scholarly communication in the digital age, including information infrastructure, interoperability, digital preservation and indicators for the assessment of the quality of units of scholarly communication. Herbert has played a major role in creating the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH), the Open Archives Initiative Object Reuse & Exchange specifications (OAI-ORE), the OpenURL Framework for Context-Sensitive Services, the SFX linking server, the bX scholarly recommender service, and info URI. Currently, he works with his team on the Open Annotation, Memento (time travel for the Web), ResourceSync, and Hiberlink projects.

Subscribe to comments: For this article | For all articles
Leave a Reply