By Sunitha Misra, Christopher A. Lee and Kam Woods
Introduction
With the increase in the acquisition of born-digital materials at collecting institutions, better tools are needed to manage, maintain and provide access to these complex resources. Moving these materials from fixed and removable media into sustainable preservation environments is a common task in libraries, archives and museums (LAMs). This can involve media that are already in their holdings (e.g., disks stored in boxes alongside non-digital materials), as well as materials being acquired for the first time from individual donors or other producers. In an effort to use available resources and avoid re-inventing the wheel, digital forensics tools have found applications in digital curation efforts within LAMs. Open source digital forensics software has been used to recover information from both removable media and fixed media (including hard disks). This paper introduces one such tool – called DIMAC (Disk Image Access for the Web) – which can be of use to end users of the materials – as well as LAM professionals – to analyze the data contained in the digital media.
Background
Technical challenges in curating born-digital materials have given rise to several initiatives incorporating digital forensic techniques to assist with curation. BitCurator[1] integrates open source digital forensics tools to extract and analyze metadata from digital media, as well as supporting triage tasks and producing reports to support preservation decisions. BitCurator is led by the School of Information and Library Science (SILS) at the University of North Carolina at Chapel Hill and Maryland Institute for Technology in the Humanities (MITH) at the University of Maryland; it addresses two core needs in collecting institutions: (1) integrating digital forensics tools and methods into the workflows and collection management environments of LAMs and (2) supporting mediated public access to forensically acquired data [5]. The BitCurator environment includes open source software including Guymager, fiwalk, bulk_extractor, and The Sleuth Kit[9] to capture data from media, as well as newly developed code to generate reports describing the contents of disk images. It also provides a unique graphical user interface used to invoke many of these tools. Early versions of BitCurator did not provide file-level access to the contents of disk images without requiring those images to be mounted as virtual drives. The tool described in this paper, DIMAC, fills this gap. It is intended to provide easy access to the contents of the files – both in a client-side application and within a web browser. This tool is likely to be useful for ongoing curation efforts conducted by LAMs including triage tasks, archival processing, preservation actions, and provision of public access.
Literature Review
Recovering data from digital media has been discussed in library and archives literature for several years [21] [22]. This includes recent investigations of forensic techniques to acquire and process digital collections [23] [24]. The Prometheus and PERPOS projects have developed software for data extraction, focusing on collecting contexts [25] [26] [27]. The project “Computer Forensics and Born-Digital Content in Cultural Heritage Collections” hosted a symposium and generated a report contributing to this discussion[3]. Kirschenbaum, Ovenden, and Redwine (2010) [3] introduce the field of digital forensics to LAM professionals, explaining the relevance of specific tools and principles. It also examines the convergences in the fields of archival study and law. A report in D-Lib Magazine [5] introduces the BitCurator project. It describes open source forensics software used by the project, and discusses relevant technologies including AFFLIB (The Advanced Forensic Format library) and DFXML (Digital forensics XML). Applying these concepts to practical applications in collecting institutions, Woods and Lee (2012) [7] introduce topics in digital forensics applicable to collecting institutions, including write-blocking (preventing changes to source media), disk imaging (extracting sector-by-sector copies of disks), redaction and triage.
All the tools presented in this paper assume that a disk image has been extracted from the relevant device. Triage is the process by which items (file system objects and metadata in particular) are ranked in terms of relevance or priority. Data triage may include identifying and analyzing deleted but recoverable data with potential value. These tasks often involve automating repetitive or technically challenging tasks during both appraisal and reprocessing after the ingest phase[5]. Redaction is removal or masking of sensitive information before end users access the materials. Woods and Lee (2012) [7] depict a potential archival workflow (beginning with media acquisition and ending with archival packaging) that includes triage and redaction tasks. Analyzing disk images using fiwalk and bulk_extractor in BitCurator is dealt with in detail in Woods, Lee and Misra (2013) [6]. Woods and Brown (2009) [1] describe the creation of a web-browsable CD-ROM collection, with further technical detail in Woods and Brown (2009)[2]. Woods and Lee (2012)[7] investigate how collecting institutions incorporate forensics tools into digital curation workflows and discuss future needs, including provision of file level access to disk images.
Rationale
The purpose of the prototype discussed here is to provide access to the contents and metadata of raw and forensically packaged[2] disk images via the web. Users can browse the contents of disk images and reduce the time spent on analysis and making preservation decisions when working with born-digital assets. This project will also facilitate end-user access to collections via a web browser. The tool may also be used to “mask out” specific items from within disk images that need to be restricted from public access. For example, disk images may contain sensitive information which should be closed, redacted, or available only to users with the appropriate permissions. A future enhancement of this tool (outside the scope of this paper) could provide the ability to elide this information from the view of users without these permissions.
Several existing tools have some similarity to DIMAC. OSFMount [18] is a commercial tool which allows the user to mount disk images in a Windows host as a virtual drive. OSFMount is proprietary but freely distributed. It provides read-only access to disk images, but requires the image to be mounted, and does not support web-based browsing. Some digital preservation specific tools provide complementary functionality, but work on individual digital objects that have already been selected for preservation. One example is Archivematica [17], an open source digital preservation system, which provides a browser-based interface for managing digital objects. DIMAC can help with the earlier stage of selecting or deselecting digital objects for inclusion in a repository. Another relevant tool is Gumshoe Jr.[19], which provides searching and sorting on metadata of the files contained in an image. Gumshoe Jr. uses fiwalk to read disk images and to populate a Solr[3] index with file-level metadata to support searching and sorting on metadata. However, it does not provide access to the contents of files or file systems.
Methodology
DIMAC was developed as a web application that allows users to browse the contents of disk images, download files, and examine metadata within a web browser. A standalone application that can be run on a Linux machine (including both graphical and command-line interfaces) was also developed to allow access to disk images accessible in local storage or on network drives.
The standalone application and the DIMAC web application share many software dependencies (and some of the same code). They both allow users to treat disk images as serial objects that can be opened and parsed (for example, to view and download individual files and metadata items) without requiring mounting as a virtual device. The development of the standalone application and the DIMAC web service are described in detail in the following sections.
Evolution
This work evolved from software developed for the BitCurator project. Early releases of BitCurator provided tools to extract bitstreams from digital media and generate reports on both file systems and deleted or unallocated content. However, we found no open source tools providing a simple way for users to both browse the contents of disk images and extract files without mounting a disk image or creating a dedicated “case file”. Even relatively sophisticated tools and frameworks such as Autopsy and the Digital Forensics Framework did not address this use case, long provided by the freely available (but non-open source) tool FTK Imager.
We first developed a command-line tool that accepted a disk image, file path, and inode as arguments and output the contents of that file. This tool used the pytsk[11] API to extract the byte runs within the disk image corresponding to the file. An appropriate list of file path and associated inodes was required for this to be useful, which we generated in the form of a Digital Forensics XML (DFXML) file using the fiwalk utility.
This process was automated by modifying the BitCurator reporting tool with a new tab in the main graphical interface. The new tab brings the user to a new interface requiring a path to the DFXML file. Using this DFXML file, the inode of a given file is identified and passed to code capable of extracting the file contents. The tab was further refined to use only the disk image, running fiwalk and then launching a second window displaying the file structure of the disk image. This allows the user to simply click on the files to select and download. Future versions of the tool will incorporate code to render some file types in the interface itself, and display hexadecimal views.
This graphical interface was useful, but depended on the creation of the DFXML file, which could be time-consuming for larger disk images. Furthermore, not all of the file system metadata generated by fiwalk and written to the DFXML file was needed. As an alternative, we chose to call The Sleuth Kit application programming interface (API) directly to extract only the information required for navigation of disk content (also used by fiwalk when generating the DFXML file). DIMAC eliminates the need to run fiwalk, and is subsequently much more responsive.
DIMAC stores disk image and related file system metadata in a database. Modern disks often contain hundreds of thousands or millions of files. It is desirable to have near-instantaneous response in the web application, and a well-indexed database is better equipped to handle queries into such images rather than running forensics-specific utilities on the fly.
Functional Specification and User Interfaces
DIMAC allows users to access disk images in a variety of contexts – online, in reading rooms or in other customized environments. The user does not have to mount a physical device or disk image in order to access it, nor is any local software required (beyond a web browser) to analyze the contents of the media. However, the tool expects a disk image as a starting point. The BitCurator environment provides several tools for generating disk images, including Guymager, which has a graphical user interface.
As noted previously, the DIMAC web application evolved from existing work conducted for the BitCurator environment. The original BitCurator tools included a graphical user interface invoked using the BitCurator Reporting Tool, and a command-line tool to export the contents of a specific file. The original BitCurator command-line and GUI interfaces, along with the new DIMAC web application (separate from the BitCurator environment), are explained in detail in the subsequent sections.
BitCurator (command-line and GUI) interfaces
A user can invoke the tool on the command-line in a terminal in the BitCurator environment by providing the path to the disk image and an output directory. Executing the following command in the directory containing the Python script bc_disk_access.py[4] launches the file-access GUI. Providing the argument dfxmlfile is optional. If not provided, it generates it internally by invoking the fiwalk command. If the image is large (multi-Gigabyte or larger), generating the DFXML file may take some time. A spinning progress bar in the GUI indicates that generation of this file is under way.
python3 bc_disk_access.py –-image <image_name> [ --dfxmlfile <dfxmlfile>] --outdir <output directory>
Another way to launch the GUI is to use the BitCurator reporting tool and click on the “File Access” tab and choose the image name and the export directory in the slots provided. Figure 1 shows the BitCurator reporting tool when the disk access GUI is successfully launched.
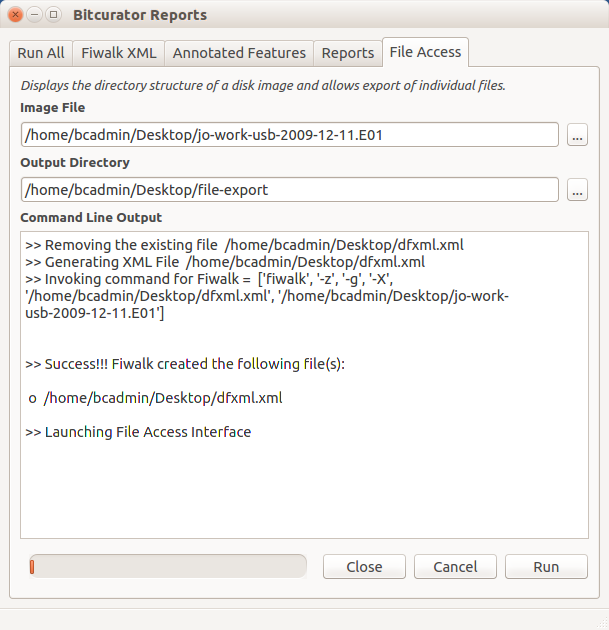
Figure 1. BitCurator Reporting tool launching File Access Interface
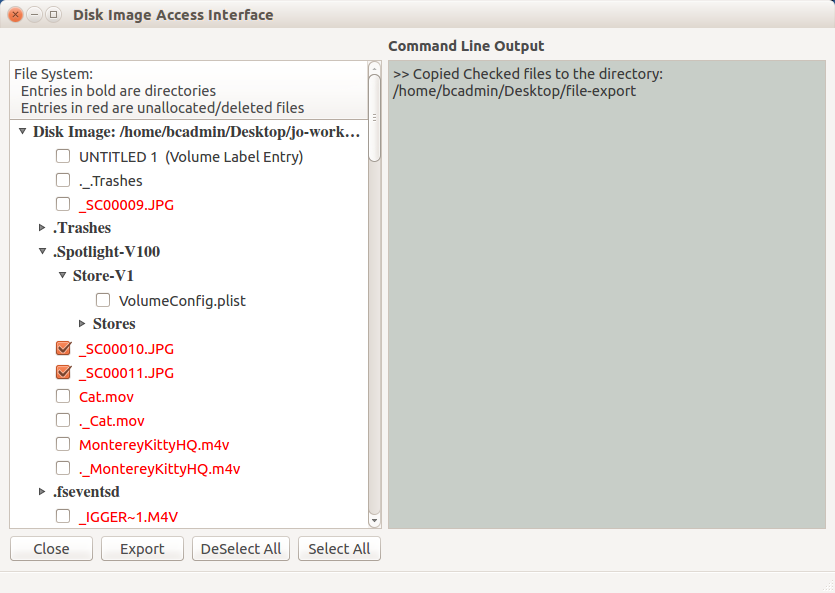
Figure 2. GUI based File Access Interface
The File Access GUI displays a tree view showing the directories and files present in a given disk image. There is a checkable box next to each file-level item. A directory can be expanded by clicking on the arrow next to the directory name. Contents of a given directory can be viewed by clicking on these arrows and expanding the depth of the tree, allowing full navigation of the disk images by expanding and collapsing subtrees as needed. This allows users working with disk images in digital collections to quickly navigate through file system as they would with “live” file systems mounted on their local machines. By clicking or double-clicking the check box associated with a file, a user can select or deselect the files he/she needs to view or export. All the files can be selected or deselected by selecting the “select all” or “deselect all” options respectively from the drop down menu from the window. Clicking on the “Export” button at the bottom of the tool downloads and displays the selected files. Log messages appear on the text-edit window on the right side of the interface.
Alternate command-line tool to export files from disk images
As an alternative in the BitCurator environment, a user can choose to display the contents of a specific file within the media, by providing the name of the file as a parameter in the command-line tool. Following is an example of the command displaying the contents of the specified file and the output of the command:
$ python3 bc_disk_access.py --image ~/aaa/charlie-work-usb-2009-12-11.aff --filename Email/Charlie_2009-12-04_0941_Sent.txt --cat
>> Generating XML File /home/sunitha/aaa/dfxmlfile.xml
>> Invoking command for Fiwalk = ['fiwalk', '-f', '-X', '/home/sunitha/aaa/dfxmlfile.xml', '/home/sunitha/aaa/charlie-work-usb-2009-12-11.aff']
>>> Generated the file /home/sunitha/aaa/dfxmlfile.xml
>> Dumping Contents of the file : Email/Charlie_2009-12-04_0941_Sent.txt
Subject: I Found Something
From: Charlie <charlie@xxx.yyy>
Date: Fri, 04 Dec 2009 09:41:47 -0800
To: andy@xxx.com
Andy,
Lucky for me, I just happened to stumble ..
Web Interface – Disk Image Access (DIMAC)
The DIMAC web application (independent of the BitCurator tool described in the sections above) provides a web interface allowing users to examine the contents of disk images (stored on the web host or in a network-accessible directory) within a browser. Navigating into these disk images displays directories and the files they contain, along with relevant metadata contained within the file system.
The start page displays disk images available for browsing (see Figure 3). The directory containing the disk images can be specified before running the tool simply by entering a new path in the Flask[10] configuration file.
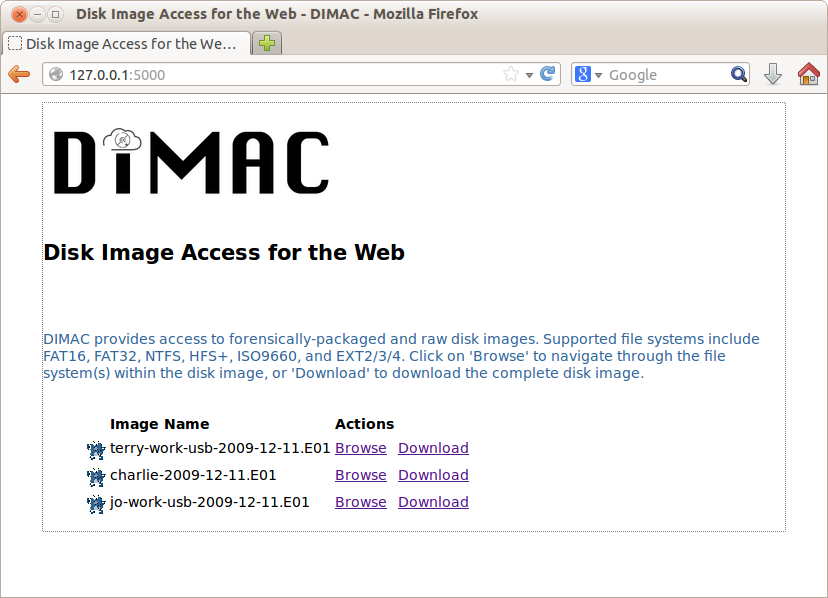
Figure 3. DIMAC: Access interface displaying disk image list
Clicking on the icon to the left of a specific disk image name generates a page showing some technical metadata associated with that disk image, including the date and time of capture, the MD5 sum, and the size (see Figure 4).
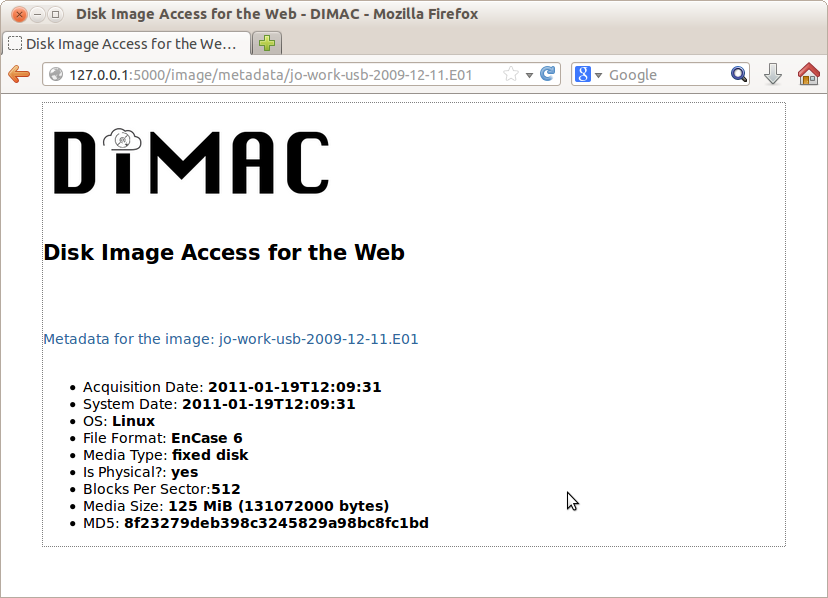
Figure 4. Disk Image Metadata
The main page (Figure 3) provides two links to the right of each image: “Browse” and “Download”. Clicking on the “Download” link downloads the entire image to the client (useful in particular for disk images that contain executable or installable software). Clicking on the “Browse” option of a particular disk image generates a page showing the partition information along with the file system(s) contained on the given partition(s) (see Figure 5).
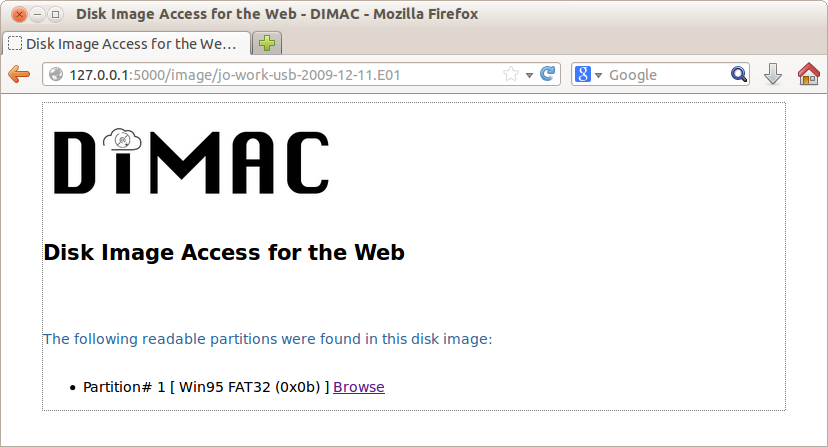
Figure 5. DIMAC displaying partition information for a specific disk image
Clicking on a specific partition takes the user to new page showing the contents of the root directory for the file system in that partition (see Figure 6). For each file listed, it displays the file type – whether it is a directory (indicated by the letter “d”) or a regular file (indicated by the letter “f”), size, modified time and whether it is deleted or allocated (indicated by “Yes” or “No”).
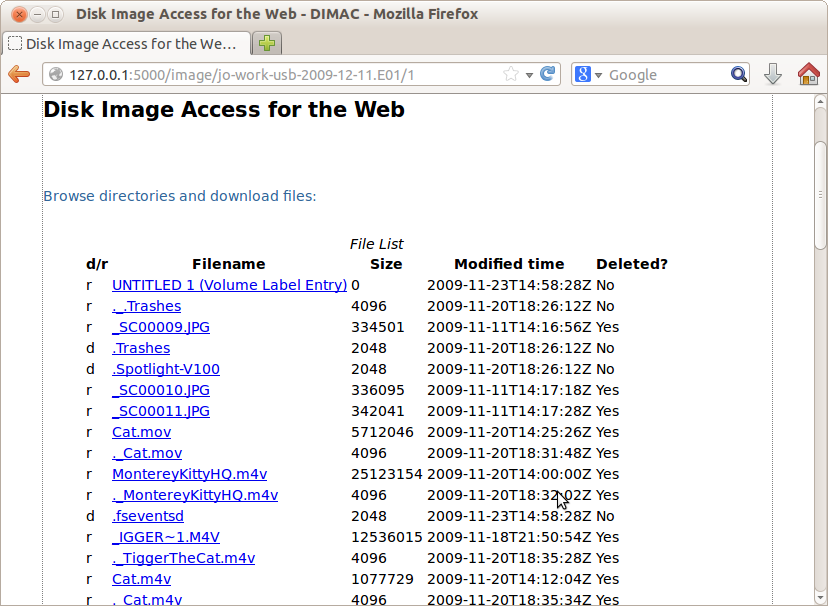
Figure 6. File Access Interface displaying directory listing
Clicking on a directory displays the contents of that directory. Clicking on a file prompts the user to download the contents of the file to their machine. Future versions will display the contents of that file in a separate window, if appropriate rendering software is available on the user’s machine.
Design and Implementation
The design goals for DIMAC included using only open source applications and libraries, simplicity of setup and execution, and relatively low processing overhead.
Our original approach was to use Apache and web.py to develop the web access component of DIMAC. However, the libtsk3 APIs exhibited some integration issues with web.py[5], which would have delayed our design and implementation. We ultimately chose Flask[10], a web application microframework that allows the developer to select extensions to handle the database abstraction layer and manage forms, among other tasks. Because Flask is lightweight, it allows for rapid prototyping of web applications.
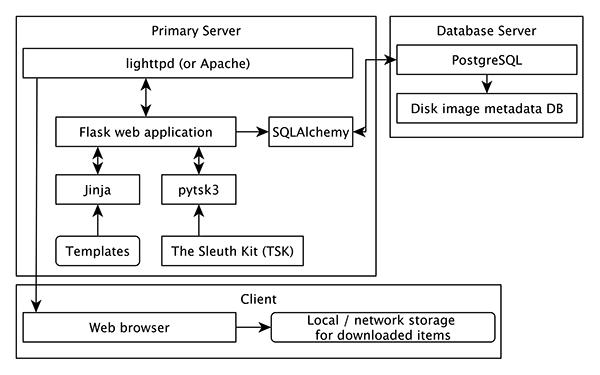
Figure 7. Software model
The block diagram in Figure 7 shows the software model used by the Disk Image Analysis Tool (DIMAC). The main web application, written in Python, runs on Linux server and provides a web service that allows users to navigate through web pages to view the metadata and the contents of the disk image. The web application uses the Flask[10] web application microframework, and depends on the pytsk[11] Python interface to The Sleuth Kit to manipulate disk images.
The Sleuth Kit (TSK)[9] is a complete file-system analysis tool. It provides a general purpose library, libtsk3, which is written in C++. This software library provides APIs to export functions including listing all the partitions of an image, files in a given directory, and dumping the contents of a specified file under a directory tree. pytsk3[11] is a Python binding wrapped around libtsk3 shared object, and provides the same interface APIs in Python.
Disk image metadata is stored in a PostgreSQL database and indexed to provide a high degree of responsiveness when interacting with the web application. Note that in the current DIMAC implementation, the web server and database server are run on the same host machine for simplicity.
Flask[10] is a web application microservices framework for Python. It uses the Web Server Gateway Interface (WSGI) and Jinja2[12], a templating language for Python, to enable rapid development of sophisticated web applications. The Flask framework depends on three important concepts: an application object, a routing system, and a template engine. The DIMAC application defines one Flask application object, which is an instance of the Flask class. Each invocation of the DIMAC tool creates an instance of this object. The routing system provides a framework to pass arguments and invoke a particular template. Web pages are dynamically generated for the purpose specified in the routing routine. Templates are written in the Jinja2 templating framework, which mimics the Python language and provides the flexibility to create dynamic web pages based on available content. The routing routine calls the API render_template with the relevant arguments to invoke the given template.
Web applications developed using Flask are database-driven. In DIMAC, we use a PostgreSQL database to store disk image and file level metadata to improve performance as the user navigates through a disk image within a browser. However, not all users may wish to use PostgreSQL, particularly if they already have a database server running a different RDBMS.
To accommodate a range of back-end RDBMS’s and provide a high degree of control over the relational components, we use SQLAlchemy[14], a Python SQL toolkit that treats the database as a relational algebra engine. SQLAlchemy includes an object-relational mapper that decouples the object model from the database schema. This allows the application to use simple, succinct commands to manipulate and query databases in a manner that is largely agnostic with respect to the RDBMS. Flask-SQLAlchemy [15] is an extension for Flask that adds support for SQLAlchemy to Flask applications (See Figure 7).
Unit/Feature Test
The three tools listed in the Methodology section were tested using four disk images with one partition each and one image with four partitions[6]. For the BitCurator GUI option, various combinations of files and directories were checked and were downloaded. DIMAC was tested to ensure the directory structure was being properly rendered at each level, files could be downloaded, and navigation options operated correctly in each dynamically rendered web page. Downloaded files were examined to ensure the size of each file downloaded corresponded to the total size of the byte runs identified in the disk image, and whether the time taken to download the files was within reasonable limits. For the command-line option to extract individual files, files were chosen from different directories and tested to ensure the integrity of their contents.
Discussion and Future Work
As indicated in a presentation at Code4Lib 2013 [16], processing and managing legacy born-digital materials can be extremely time consuming. The technical problems they pose may require significant intellectual and technical resources, and there is no guarantee that the process will go smoothly: One tool might work for recovering and analyzing a particular type of legacy medium, but not another. The reasons for this are multifaceted. For example, software tools built to mount disk images and raw devices may not be capable of mounting certain legacy devices. Simply mounting the device or disk image can require significant technical expertise on the part of the user. Applications such as DIMAC can alleviate some of these problems. DIMAC does not require the image to be mounted, and requires minimal technical expertise. It is a relatively simple tool (just a few hundred lines of code), is open source, and has been designed to be easy to use and modify. The DIMAC source code is currently hosted on GitHub (master repository at https://github.com/kamwoods/DIMAC). Two of the authors of this paper (Sunitha Misra and Kam Woods) are the primary contributors, and further development is planned beginning in Fall 2014.
DIMAC could be used in two distinct applications in LAMs. A typical use case could involve a curator making selection decisions about disk images extracted from physical media. Selected images could be placed in an appropriate location for access (for example, on an existing server or network share). Another use case could involve a patron browsing through the LAM database looking for a specific file level item. The patron could examine metadata (and other manually generated finding aids) related to a particular disk image, browse the contents of that disk image, and download files of interest. This latter use case is similar to that in Woods, Kam and Brown(2009)[1] where patrons use a web interface to access the contents of CD-ROM disk images. Similarly, LAMs could use standard virtual machine (VM) technologies in place of or as a supplement to existing workstations.
As discussed earlier, DIMAC generates and stores metadata of the disk images in a PostgreSQL database, which is queried when users click on relevant links. As a future enhancement, it would be beneficial to store the metadata information of individual files, which can be retrieved on demand (along with a downloaded file) or rendered in-browser before deciding to download a file. LAM personnel could use this information in the curation process. DIMAC could also be used to carry out tasks that feed into other tools in later stages of the workflow. For example, DIMAC could be used to extract the files to be curated along with their metadata, at which point they could be prepared for ingest into an archiving and preservation platform such as Archivematica.
Another potential enhancement of DIMAC is the addition of redaction capabilities – modules allowing the removal or masking of selected information from public view. Using this feature, the content provider could mask out specific contents from the database. For example, certain files or a specific portion of a directory tree could be tagged to be masked. A redaction utility could also be invoked to create a redacted disk image prior to provision of access. This would automatically exclude files that carry sensitive information or mask off such information within the files.
Finally, database support could be extended to store data generated by tools such as bulk_extractor, identifying relevant features of interest (including potentially private and sensitive data) that appear on the disk. This information could then be browsed on demand from within the web browser, or redacted as necessary.
Conclusion
A workflow in a LAM is never completely finalized [8], and there is a constant stream of improved tools to handle artifacts and reprocess older materials. While born-digital materials have existed in collections for many years, digital curation processes are still in their infancy. Tools like DIMAC, which demand relatively little technical expertise on the part of the user, will hopefully be simple to incorporate into workflows. The DIMAC tool provides remote access to the contents of disk images with very little overhead, could help with masking potentially sensitive information, and provides a generic interface to anyone familiar with web browsing. DIMAC is open-source software, which should further support adaptation to fit into the diverse workflows of LAMs.
Notes
[1] The BitCurator project is funded by the Andrew W. Mellon Foundation.
[2] Forensic disk image formats include the Expert Witness Format and the Advanced Forensic Format. Forensic formats act as a secure, read-only wrapper for raw disk images and generally include substantial capture and technical metadata not available with raw images.
[3]Solr is an open source search platform from the Apache Lucene project
[4] For example, in the BitCurator environment, $HOME/Tools/bitcurator/python
[5] Web framework for Python (www.webpy.org)
[6] At the time of writing this paper, the feature is still being tested with an image with four partitions.
Bibliography
[1] Woods, Kam and Brown, Geoffery, “Creating Virtual CD-ROM Collections”, International Journal of Digital Curation , 2/No-4 (2009)
[2] Woods, Kam and Brown, Geoffery, “From Imaging to Access – Effective Preservation of Legacy Removable Media.“, Archiving (2009): Preservation Strategies and Imaging Technologies for Cultural Heritage Institutions and Memory Organizations: Final Program and Proceedings, pages 213-218.
[3] Kirschenbaum, Matthew G., Ovenden, Richard, Redwine, Gabriela and research assistance from Rachel Donahue, “Digital forensics and Born-Digital Content in Cultural Heritage Collections.”, Washington, DC: Council on Library and Information Resources (2010).
[4] Lee, Christopher A., Woods, Kam, Kirschenbaum, Matthew and Chassanoff, Alexandra. “From Bitstreams to Heritage: Putting Digital Forensics into practice in Collecting Institutions.”, A White Paper on BitCurator project. (2013)
[5] Lee, Christopher A., Kirschenbaum, Matthew, Chassanoff , Alexandra, Olsen, Porter, Woods, Kam. (2012). “BitCurator: Tools and Techniques for Digital Forensics in Collecting Institutions”, D-Lib Magazine May/June 2012 18/No 5/6.
[6] Woods, Kam, Lee, Christopher A., Misra, Sunitha, “Automatic Analysis and Visualization of disk images and File systems for preservation.”, Proceedings of Archiving 2013 (Springfield, VA: Society for Imaging Science and Technology, 2013), 239-244.
[7] Woods, Kam and Lee, Christopher A., “Acquisition and Processing of Disk Images to further archival goals”, Proceedings of Archiving 2012, Springfield, VA, Society for Imaging Science and Technology, pg. 147-152.
[8] Gengenbach, Martin J., “The Way We Do it Here: Mapping Digital Forensics Workflows in Collecting Institutions” Master’s paper, UNC, Chapel Hill, 2012.
[9] “The Sleuth Kit (TSK)” Last Modified March 21, 2014. http://www.sleuthkit.org/sleuthkit/
[10] “Flask – Web development, one drop at a time.” Accessed February 14, 2014. http://flask.pocoo.org
[11] “pytsk: Python bindings for The Sleuth Kit.” Last Modified 28 May, 2012. https://code.google.com/p/pytsk/wiki/OverView
[12] “Jinja2: Template Designer Documentation” Accessed February 14 2014. http://jinja.pocoo.org/docs/templates/
[13] The Sleuth Kit, “Overview,” Last Modified 21 March 2014. http://www.sleuthkit.org/sleuthkit
[14] SQLAlchemy, “The Python SQL Toolkit and Object Relational Mapper” Last Modified February 8, 2014
http://www.sqlalchemy.org
[15] “Flask-SQLAlchemy” Last Modified May 28, 2012. http://pythonhosted.org/Flask-SQLAlchemy
[16] Mennerich, Don and Matienzo, Mark A, “Pitfall! Working with Legacy Born Digital Materials in Special Collections”, Presented at Code4Lib 2013, Chicago, Illinois.
[17] “Archivematica” Last Modified February 19 2014. https://www.archivematica.org/wiki/Main_Page
[18] PassMark Software, “OSFMount” Last Modified February 9, 2014. http://www.osforensics.com/tools/mount-disk-images.html
[19] “Gumshoe Jr.” Accessed March 2014. https://github.com/anarchivist/gumshoe
[20] Matienzo, Mark, “fiwalk With Me: Building Emergent Pre-Ingest Workflows for Digital Archival Records using Open Source Forensic Software”, Feb 09, 2011,Last Modified August 2, 2013. http://www.slideshare.net/anarchivist/fiwalk-with-me-building-emergent-preingest-workflows-for-digital-archival-records-using-open-source-forensic-software
[21] Woodyard, Deborah. “Data Recovery and Providing Access to Digital Manuscripts.” Paper presented at the Information Online 2001 Conference, Syndney, Australia, January 16-18, 2001.
[22] Ross, Seamus, and Ann Gow. “Digital Archaeology: Rescuing Neglected and Damaged Data Resources.” London: British Library, 1999.
[23] John, Jeremy Leighton. “Adapting Existing Technologies for Digitally Archiving Personal Lives: Digital Forensics, Ancestral Computing, and Evolutionary Perspectives and Tools.” Paper presented at iPRES 2008: The Fifth International Conference on Preservation of Digital Objects, London, UK, September 29-30, 2008.
[24] Garfinkel, Simson, and David Cox. “Finding and Archiving the Internet Footprint.” Paper presented at the First Digital Lives Research Conference: Personal Digital Archives for the 21st Century, London, UK, February 9-11, 2009.
[25] Elford, Douglas, Nicholas Del Pozo, Snezana Mihajlovic, David Pearson, Gerard Clifton, and Colin Webb.. “Media Matters: Developing Processes for Preserving Digital Objects on Physical Carriers at the National Library of Australia.” Paper presented at the 74th IFLA General Conference and Council, Québec, Canada, August 10-14, 2008.
[26] Underwood, William E., and Sandra L. Laib. “PERPOS: An Electronic Records Repository and Archival Processing System.” Paper presented at the International Symposium on Digital Curation (DigCCurr 2007), Chapel Hill, NC, April 18-20, 2007.
[27] Underwood, William, Marlit Hayslett, Sheila Isbell, Sandra Laib, Scott Sherrill, and Matthew Underwood. “Advanced Decision Support for Archival Processing of Presidential Electronic Records: Final Scientific and Technical Report.” Technical Report ITTL/CSITD 09-05. October 2009.
About the Authors:
Sunitha Misra is a Masters student in the School of Information and Library Science at the University of North Carolina at Chapel Hill. She is currently a software developer on the BitCurator project.
Christopher (Cal) Lee is an Associate Professor at the School of Information and Library Science at the University of North Carolina at Chapel Hill. His primary area of research is the long-term curation of digital collections. He is Principal Investigator for the BitCurator project and editor of I, Digital: Personal Collections in the Digital Era published by the Society of American Archivists.
Kam Woods is currently a Postdoctoral Research Associate in the School of Information and Library Science at the University of North Carolina at Chapel HilL His research interests include long-term digital preservation, digital archiving, and the application of digital forensics tools and techniques to archival and preservation data analysis and
management.

Subscribe to comments: For this article | For all articles
Leave a Reply