By Ross Singer and James Farrugia
Introduction
Any library developer knows the difficulty of trying to write applications that interact with or use data out of library systems. The situation is even more problematic for outside developers entering a library-based integration project, since they are likely ignorant of the historical baggage, seemingly obsolete protocols, and arcane file formats that are involved when accessing and using library metadata. Too often, costly library systems serve more as maximum security prisons than walled gardens. It can become impossibly difficult to integrate library systems into other local environments when the only ways to get data in or out require proprietary desktop clients or server-side command line scripts. If application programming interfaces (APIs) exist, they vary from system to system with regards to access and functionality.
Jangle (Just Another Next Generation Library Environment) [1] is a specification (and accompanying reference implementation) employing simple, common and well supported web protocols to enable the creation, maintenance and distribution of resources among library-related data sources. The goal is to standardize and simplify the process of getting data in and out of library systems, allowing content to proliferate outside of standard library applications and providing a level playing field for external developers building applications that interact with library systems.
This article will attempt to lay out the need for and role of Jangle. It begins with an overview of the past efforts to enable open data in libraries and the evolution of the Jangle project, including an introduction to the Atom Publishing Protocol and the Atom Syndication Format and a description of how Jangle employs these specifications. Then it describes the JangleR reference implementation, the Proof of Concept Unicorn Connector and the DLF ILS-DI adapter, showcasing the simplicity of developing applications to both expose and consume Jangle functionality. Since the project is relatively new and the specification is somewhat volatile, we will finish by discussing the future plans and making some predictions about where the next steps may lead.
A Brief History of Open Data and Libraries
There have been plenty of attempts in the past to provide more standardized access to library data. The MARC format itself was created solely for sharing records amongst libraries. Z39.50 [2] has done an admirable job at providing access to data given its age and its pre-HTTP protocol, but it generally only provides a search interface to bibliographic records; information about holdings is included in a limited percentage of libraries. Limitations on the number of search results and available indexes make it impossible to “harvest” all records from an institution, and the protocol is almost impossible to explain to parties outside of the library world. NCIP (NISO Circulation Interchange Protocol) [3], an attempt to provide circulation interoperability between libraries, suffers from a lack of implementation and support even within library systems. The NCIP implementations that do exist are different enough to thwart the goal of universal borrowing between systems produced by different vendors.
In 2004, NISO began an initiative known as VIEWS (Vendor Initiative for Enabling Web Services) to produce a standard for interoperable web services for library systems. The committee was to design a specification to enable standardized access to library data with metasearch applications as the major use case. Eventually rebranded as the NISO Web Services Working Group, the committee’s only legacy is a best practices document [4] for creating web services. The document lays out the ways this could be done, but prescribes nothing and offers no specifics on how the recommendations should be implemented in actual library systems.
Other groups (SRU [5], NISO Metasearch Initiative [6], and OASIS Search Web Services [7], for example) have defined standards to aid remote searching across institutions, but in many ways these are just incremental improvements to make Z39.50 fit less awkwardly in a web-centric universe. There have been no real attempts to provide uniform access to library data outside of searching or to provide interfaces to create or update resources maintained within library systems (outside of the institutional repository space). It is this vacant space that Jangle is intended to fill, providing a clear, straightforward API that uses the web’s de facto standards for creating, reading, updating, and deleting resources. The three major web standards that the Jangle API utilizes are:
- persistent URLs
- a RESTful design [8] that allows these URLs to be used to create, read, update, and delete web resources
- a protocol designed to support feed readers that can periodically poll data for updates, with the ability to customize the kind of data that users want to be fed
The Evolution of Jangle
Jangle began as a project within Talis [9] as a means to promote use and accelerate adoption of open library data. Its goal was to enable new development (local, open source or commercial) on existing library applications by providing an open framework and a consistent API. Jangle was intended to be an open source service-oriented architecture application based loosely on Talis’ Keystone product, which is used to enable integration between library functions and other institutional applications [10]. Keystone would remain a closed source application but would seed the RESTful web framework (known in Keystone as TalisSOA) for Jangle’s API. Connectors, small applications that contain the business logic for interacting with specific back-end services, could then be reused between Jangle and Keystone.
The TalisSOA framework, however, was complicated to set up; it had many dependencies and little documentation and a considerable amount of Java expertise was needed to create even a simple connector. Talis decided that this would prove to be too much of a burden to libraries that lacked the resources or skill set needed to develop connectors between their local systems and TalisSOA.
In an effort to make a prototype quickly, the developers built early Jangle designs using the Ruby on Rails web framework. JRuby (a fully compliant Ruby interpreter written completely in Java) was chosen as the platform so local developers could build their connector classes in Java, Ruby or other Java bytecode languages, such as Jython and Groovy. Frustrations with JRuby performance and use of Rails as a solely web services interface began to raise doubts about this direction. Questions arose as to whether or not a library-specific service-oriented architecture framework was even necessary.
After an early Jangle brainstorming session with the developers at Equinox Software Incorporated, Mike Rylander, Equinox’s Vice President of Research and Design, raised the idea of using the Atom Publishing Protocol (AtomPub) to provide a very simple REST interface for Jangle. After lying dormant for several months, this proposal was revived, bringing new life to the project when Jangle began to lose momentum due to a lack of clear direction in the face of other SOA projects. The focus of Jangle changed from creating a deliverable application providing web services to building an API that exposes resources within library systems using the Atom Publishing Protocol. A reference implementation of the specification would be built concurrently to test, demonstrate and validate the API as well as provide a very basic framework for libraries to get started.
Talis is still heavily involved in the Jangle community while the project tries to build its own momentum. The company is providing developer support and server resources in an effort to bootstrap the process. The Jangle community, however, is external to Talis and the decisions on direction and functionality of the project are made democratically and not subject to Talis’ corporate interests. Jangle is a project that has been released into the wild outside the control of any one organization.
Why AtomPub?
When designing a web services interface, there are a variety of styles and protocols upon which the API could be based, including SOAP, XML-RPC, or custom REST API. When Jangle was first being developed, the API was based on the REST style with no conformance to any particular syntax or specification. The XML responses it produced varied from resource to resource with no uniform format across the application. This meant that Jangle would require custom schemas, clients and robust documentation in order to be usable. It was decided that utilizing a single standard protocol across Jangle would immediately make it more accessible, creating a much shallower learning curve for developers not versed in the library domain or Jangle.
The Atom Publishing Protocol (RFC5023) [11] is “an application-level protocol for publishing and editing Web Resources using HTTP [RFC2616] and XML 1.0.” Simply put, AtomPub advertises related groups of resources (collections), assigns them a URI and makes them available in the Atom Syndication Format (RFC4287) [12]. The protocol also specifies how to add, update and delete resources within a collection (using PUT, POST, and GET requests). These collections are aggregated by distinct services known as workspaces. The specific resources within the collection are called entries. AtomPub announces the workspaces and collections available via Atom Service Documents, XML documents that define the paths to collections and the appropriate MIME-types allowed for creating and editing content.
The Atom Syndication Format was designed to syndicate all kinds of data, so while its native elements seem more suitable for applications such as weblogs, the content field can include anything, from MARC XML [13] to EAD [14] to PDFs to binary MARC 21 [15]. The flexibility of the content field, as well as the ability to degrade gracefully for simple Atom clients (they will display the fields they understand, such as title and author and ignore the fields they cannot work with) is what makes Atom especially appealing. Since Atom was designed to be enhanced through domain-specific extensions, it can be quite flexible for diverse needs.
An additional benefit to AtomPub is that it assigns unique, permanent and dereferenceable URIs for each resource within the Atom feeds. These URIs are reusable within other applications, since they produce an Atom feed consisting of just that resource.
The most desirable attribute of AtomPub, however, is the broad base of support it is receiving from major web players. Google has based its entire GData API suite [16] upon the Atom Publishing Protocol, using a combination of its own extensions and other commonly used extensions, such as OpenSearch [17]. Microsoft has implemented AtomPub to enable access to its unified storage platform. The major blogging platforms, such as WordPress [18] and MovableType [19], have AtomPub interfaces to manage content remotely. With such a broad base of support from players that have a desire to make their content easily accessible everywhere, AtomPub has a wide client base, a growing user community, and expanding server support. The ability to draw upon cheap, commodity client libraries and learn from Google or Microsoft on how best to implement functionality makes the Atom Publishing Protocol a very attractive standard for new web services.
The Anatomy of Jangle
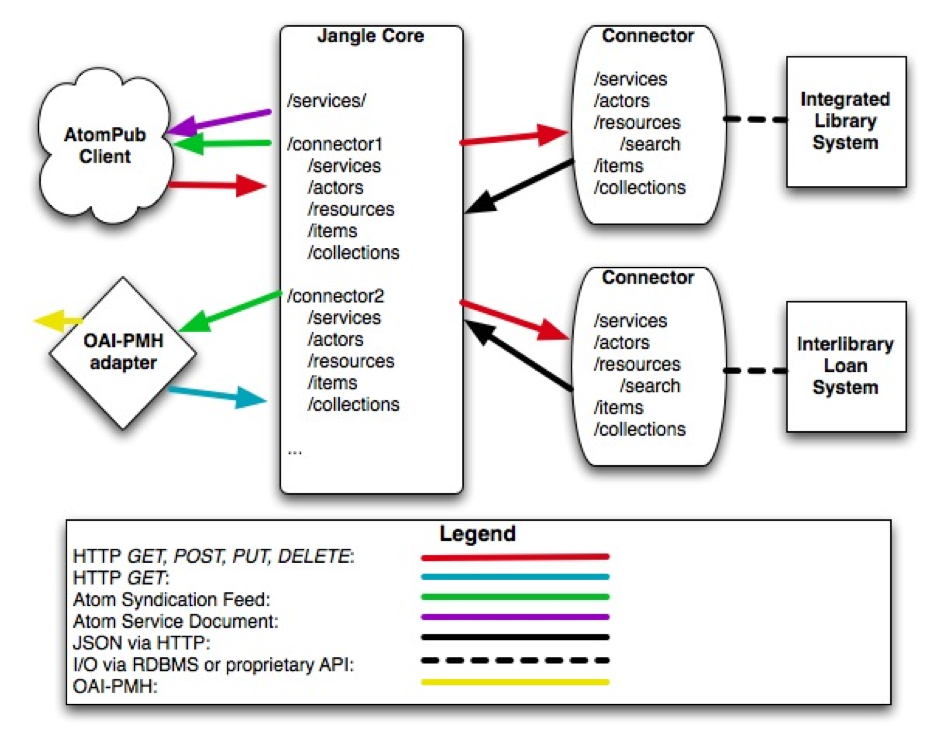
Jangle is comprised of two distinct pieces (Fig. 1):
- the publicly accessible interface, known as the Jangle core, which presents the AtomPub API to clients
- a federation of connectors, which take proxied HTTP requests from the core, translate them using the business logic of a particular local library application and return the results serialized as a JSON [20] representation of an Atom syndication document.
The two pieces communicate via HTTP, which means the core and connector can be written in two completely different languages. If multiple connectors are being used by the core, they could all be written in completely different languages.
The Core
The Jangle core is a very simple Atom Publishing Protocol server. This means that if you have the Jangle core running on a server, web clients can access Atom Syndication Format feeds of data provided by the connectors in addition to adding, updating and deleting that data in the underlying library applications. The core’s purpose is to manage the HTTP requests, proxy requests to the connectors and serialize the connectors’ JSON responses into XML. The Jangle core contains no business logic and does not help clients negotiate the appropriate connector to call. It is the responsibility of the client interacting with the Jangle core to understand the role and the context of the underlying library systems. The core can aid the client, however, by providing an Atom Service Document with a brief, human readable description of the available applications being proxied.
Connectors
External clients can access resources provided by individual Jangle connectors using paths off of the Jangle core URL. Each connector provides its own service document to define the collections it provides. An imaginary Jangle core that is hosting both an integrated library system (ILS) and an electronic resources management system might have connector paths of http://jangle-core.example.org/catalog/ and http://jangle-core.example.org/erms/. Both of these would be able to return a service document (for the ILS, this might be http://jangle-core.example.org/catalog/services/), which would explain what resources are exposed by the connector. The proxied connectors are completely independent of each other and feeds cannot be created across multiple connectors within a single request. However, since Jangle provides permanent and reusable URIs for every resource, it is possible to use these URIs within the native library systems when describing entities in other applications.
Connectors require more knowledge of (and access to) the underlying library systems that they are exposing than the Jangle core. A connector is intended to abstract inconsistencies between library applications and break the underlying data up into the Jangle model. Connectors provide simple RESTful interfaces with five base paths (/services, /actors, /resources, /items and /collections) and return results to the Jangle core as JSON objects. The JSON objects also include the MIME-type defining how the Jangle core should serialize the response for the client. The connectors define the record formats available and the relationships between base entities (for example, how items are associated with actors) and manage the identifiers associated with any given resource.
Since a connector could potentially be used by multiple Jangle cores, a convention was necessary to notify the connector of the location from which it was being called. For this reason, the Jangle core sends an extra HTTP request header, called “connector_base”, with the base url of the request. The connector then has the absolute URI in the event it needs to be embedded in its content payload.
Entities
Jangle specifies only four base data types, or entities, to define all of the data contained in a given library system. The entities are:
- Actors: These are users of the underlying library system. For an integrated library system, these could correspond to borrowers. For an institutional repository, these might be the submitters.
- Resources: These are the primary records central to the exposed application’s purpose. In an integrated library system, these would be bibliographic and authority records. In an interlibrary loan application, they would be loan requests.
- Items: These are specific instances of Resources, such as physical copies, holdings, or specific electronic formats. In the case of a link resolver, these could refer to the holdings of a given database with regards to a particular journal.
- Collections: These are any grouping of any of the above entities, including groupings that pull from different entity types. Collections could be used to separate bibliographic records from authority records or to identify course reserves in an integrated library system. Collections have no inherent meaning of their own and a Jangle client should make no assumptions about what collections exist.
A fifth entity, Events, has been proposed, but it is unclear if this would be necessary or would cause too much complexity as its own base data type.
The entities map to corresponding base paths in the connector. For example, the URL to retrieve all of the Resources from a given connector would be http://jangle-connector.example.org/resources/ and the URL to retrieve the Actor with the local identifier 1234 would be http://jangle-connector.example.org/actors/1234. The output from these requests would be a JSON response (roughly resembling an Atom feed) with the intended resources bundled in an array called “entry.” JSON was chosen over XML for this task because it is so much easier to produce and parse, especially for known data structures. The main ‘record’ being returned would be contained in the entry’s content element, along with the record’s MIME-type (Fig. 2). The metadata itself is served ‘as is’ within the content field rather than being transformed to JSON. In the case of a bibliographic record, for instance, the content element could contain MARC XML or possibly MARC21. The Jangle core could then take this JSON response and serialize it into an XML document and serve the appropriate MIME-type and HTTP status (Fig. 3).
{
"type":"application\/atom+xml",
"extensions":{
},
"time":"2008-07-17T15:18:29-05:00",
"entry":[
{
"content":"<oai_dc:dc xsi:schemaLocation=\"http:\/\/www.openarchives.org\/OAI\/2.0\/oai_dc\/ \n http:\/\/www.openarchives.org\/OAI\/2.0\/oai_dc.xsd\" xmlns:dc=\"http:\/\/purl.org\/dc\/elements\/1.1\/\" xmlns:oai_dc=\"http:\/\/www.openarchives.org\/OAI\/2.0\/oai_dc\/\" xmlns:xsi=\"http:\/\/www.w3.org\/2001\/XMLSchema-instance\"><dc:creator>Conrad, Joseph,<\/dc:creator><dc:title>Chance<\/dc:title><\/oai_dc:dc>",
"created":"2008-03-18T15:56:52-05:00",
"updated":"2008-03-18T15:56:52-05:00",
"author":{
"name":"Conrad, Joseph,"
},
"content_type":"application\/xml",
"links":{
"alternate":[
{
"type":"application\/atom+xml;format=marc",
"href":"\/resources\/4107?record_format=marc"
},
{
"type":"application\/atom+xml;format=marcxml",
"href":"\/resources\/4107?record_format=marcxml"
},
{
"type":"application\/atom+xml;format=dc",
"href":"\/resources\/4107?record_format=dc"
},
{
"type":"text\/html",
"href":"http:\/\/catalog.jangle.org\/shared\/biblio_view.php?bibid=4107&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;tab=opac"
}
],
"related":[
{
"type":"application\/atom+xml",
"href":"\/collections\/2"
}
],
},
"title":"Chance",
"id":"\/resources\/4107"
}
],
"request":"\/resources\/4107?record_type=oai_dc"
}
<feed xmlns="http://www.w3.org/2005/Atom">
<title>openbiblio</title>
<link href="http://demo.jangle.org/openbiblio/resources/4107?record_format=oai_dc"/>
<updated>2008-07-17T15:25:16Z</updated>
<id>http://demo.jangle.org/openbiblio/resources/4107?record_format=oai_dc</id>
<entry>
<title>Chance</title>
<link href="http://demo.jangle.org/openbiblio/resources/4107"/>
<link type="application/atom+xml" href="http://demo.jangle.org/openbiblio/collections/2" rel="related"/>
<link type="application/atom+xml;format=marc" href="http://demo.jangle.org/openbiblio/resources/4107?record_format=marc" rel="alternate"/>
<link type="application/atom+xml;record_format=marcxml" href="http://demo.jangle.org/openbiblio/resources/4107?record_format=marcxml" rel="alternate"/>
<link type="application/atom+xml;record_format=dc" href="http://demo.jangle.org/openbiblio/resources/4107?record_format=dc" rel="alternate"/>
<link type="text/html" href="http://catalog.jangle.org/shared/biblio_view.php?bibid=4107&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;tab=opac" rel="alternate"/>
<author>
<name>Conrad, Joseph,</name>
</author>
<id>http://demo.jangle.org/openbiblio/resources/4107</id>
<updated>2008-03-18T15:56:52-05:00</updated>
<content type="application/xml">
<oai_dc:dc xsi:schemaLocation="http://www.openarchives.org/OAI/2.0/oai_dc/
http://www.openarchives.org/OAI/2.0/oai_dc.xsd" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:oai_dc="http://www.openarchives.org/OAI/2.0/oai_dc/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<dc:creator>Conrad, Joseph,</dc:creator>
<dc:title>Chance</dc:title>
</oai_dc:dc>
</content>
</entry>
</feed>
The Atom Serialization
While connectors provide JSON responses to the Jangle core, the Jangle core serializes this response into Atom Syndication Format. Jangle uses a few of these elements in a very specific manner.
As mentioned earlier, connectors define the relationships between base entities. These relationships are handled via <link> elements within the Atom entry. The URL for the Items associated with a particular Resource (after being rewritten to Atom by the Jangle core) might look like http://jangle-core.example.org/example_service/resources/12345/items/ and would return an Atom feed of the Items associated with Resource 12345. The reverse is also true, where http://jangle-core.example.org/catalog/items/987654/resources/ would return an Atom feed with the Resource record associated with Item 987654. The benefit of these <link> elements is that users (people or programs) can discover related information, not just the information that was asked for. If an initial request was for Resource (bibliographic record) X, the connector also makes available a link to all the Item records associated with that Resource (see orange highlighting in Fig. 4).
The Atom entries also provide alternate representation links to other metadata formats available via Jangle (see yellow highlighting in Fig. 4). In an effort to help client applications identify the different metadata formats offered (and to comply with Atom Syndication specification), the MIME-type of alternate links (application/atom+xml) is extended with the record_format parameter to declare what will be transported in the atom:content field. For example, if the Atom feed is returning MARC XML in its entry content fields, the MIME-type returned would be application/atom+xml;record_format=marcxml. As these values are arbitrary strings, it would be helpful for Jangle and other initiatives to produce a SKOS vocabulary to provide consistent identifiers ensuring agreement on what these strings actually mean. The vocabulary would not be exclusive to Jangle, but available to any applications or specifications that require agreement on metadata formats, such as UnAPI [21].
<feed xmlns="http://www.w3.org/2005/Atom">
<title>openbiblio</title>
<link href="http://demo.jangle.org/openbiblio/resources/5975?record_format=marcxml"/>
<updated>2008-07-17T15:27:57Z</updated>
<id>http://demo.jangle.org/openbiblio/resources/5975?record_format=marcxml</id>
<entry>
<title>The Works of Samuel Johnson in Nine Volumes Volume IV: the Adventurer; the Idler</title>
<link href="http://demo.jangle.org/openbiblio/resources/5975"/>
<link type="application/atom+xml" href="http://demo.jangle.org/openbiblio/resources/5975/items/" rel="related"/>
<link type="application/atom+xml" href="http://demo.jangle.org/openbiblio/collections/2" rel="related"/>
<link type="application/atom+xml;record_format=marc" href="http://demo.jangle.org/openbiblio/resources/5975?record_format=marc" rel="alternate"/>
<link type="application/atom+xml;record_format=dc" href="http://demo.jangle.org/openbiblio/resources/5975?record_format=dc" rel="alternate"/>
<link type="text/html" href="http://catalog.jangle.org/shared/biblio_view.php?bibid=5975&tab=opac" rel="alternate"/>
<author>
<name>Johnson, Samuel,&t;/name>
</author>
<id>http://demo.jangle.org/openbiblio/resources/5975</id>
<updated>2008-03-18T15:57:00-05:00</updated>
<content type="application/xml">
<record xmlns='http://www.loc.gov/MARC21/slim'>
<leader> Z 22 4500</leader>
<datafield tag='245' ind1='0' ind2='0'>
<subfield code='a'>The Works of Samuel Johnson in Nine Volumes Volume IV: the Adventurer; the Idler</subfield>
<subfield code='c'>by Samuel Johnson</subfield>
<subfield code='h'>[electronic resource] /</subfield>
</datafield>
<datafield tag='100' ind1='0' ind2='z'>
<subfield code='a'>Johnson, Samuel,</subfield>
<subfield code='d'>1709-1784</subfield>
</datafield>
<datafield tag='42' ind1='z' ind2='z'><subfield code='a'>dc</subfield></datafield>
<datafield tag='260' ind1='z' ind2='z'>
<subfield code='b'>Project Gutenberg,</subfield>
<subfield code='c'>2004</subfield>
</datafield>
<datafield tag='500' ind1='z' ind2='z'><subfield code='a'>Project Gutenberg</subfield></datafield>
<datafield tag='506' ind1='z' ind2='z'><subfield code='a'>Freely available.</subfield></datafield>
<datafield tag='516' ind1='z' ind2='z'><subfield code='a'>Electronic text</subfield></datafield>
<datafield tag='830' ind1='z' ind2='z'>
<subfield code='a'>Project Gutenberg</subfield><subfield code='v'>12050</subfield>
</datafield>
<datafield tag='856' ind1='z' ind2='z'>
<subfield code='u'>http://www.gutenberg.org/etext/12050</subfield>
</datafield>
<datafield tag='856' ind1='z' ind2='z'>
<subfield code='u'>http://www.gutenberg.org/license</subfield>
<subfield code='3'>Rights</subfield>
</datafield>
</record>
</content>
</entry>
</feed>
Since each collection of entities may contain many hundreds of thousands to millions of resources, feeds from the base entity URLs (i.e. /actors/ or /items/) are paged according to RFC 5005 [22]. Paging is also available when searching entities via OpenSearch. Since one of the features of Atom is the expectation that it will be extended, the JSON responses from each connector include a hash to specify namespaces and namespace prefixes used in the entries. It is possible the JSON objects will use a standardized XML style notation (such as Badgerfish [23]) by the time of an official Jangle API specification release, but discussions have only just begun of the possibilities.
The Jangle API itself makes no recommendations or requirements regarding the data that is available for any given system, in large part since the data may vary wildly between different kinds of library systems. An interlibrary loan system and an archival finding aid manager may have very few overlapping data points. Instead, the expectation is that data requirements can be delegated to community profiles or best practices for a given application domain. This way, connector implementers working with integrated library systems can determine the appropriate responses and the most practical way of utilizing Collections without worrying about how their decisions apply to other library systems.
Jangle’s job is merely to expose data. It is up to the communities to decide the best way to utilize Jangle to meet their needs.
Adapters: Since Atom’s not for everybody
The uniformity of Jangle’s API, regardless of the variations in backend systems it provides access to, allows for a third tier, called adapters, to sit in front of a Jangle core implementation and provide more traditional library interfaces, such as OAI-PMH or NCIP. If a single SRU or NCIP adapter can be built on top of Jangle, every library system with a Jangle connector can make use of this adapter. This would enable the implementation of traditional library standards across a far greater percentage of library systems. The reality, of course, may not be this quite this simple, but economies of scale make the development of particularly complicated standards-based protocols much more immediately beneficial.
JangleR: The Jangle Reference Implementation
Since Jangle is still very much a proof of concept and a work in progress, it was important to have a simple reference implementation to test API proposals, demonstrate Jangle’s potential and provide a basic AtomPub server and connector framework for developers to build their own connectors against. The current Jangle reference implementation is known as JangleR. Ruby was chosen for this application, mainly to provide a working prototype very quickly. A side benefit of this decision was the ability to build the reference core and connector architectures on the Sinatra framework [24]. Sinatra is well suited to REST interfaces because it allows the developer to set a particular action to happen at a specific route (or URL path). Different actions for the same route can be defined depending on the HTTP method used to call the path. Layers of path hierarchy are then quite simple, since they effectively just map to a particular method. Since the logic of dealing with the requests is all handled by the framework, the core and connector frameworks are quite small, measuring about 150 lines and 360 lines of Ruby, respectively.
Also, an example connector was needed for testing in the reference implementation. We chose to build a connector for the OpenBiblio open source integrated library system [25] because the OpenBiblio ILS was simple; it ran on cheap, shared web hosting, required little maintenance or administration to run, and, most importantly, provided a fairly good representation of the data structures within the more sophisticated commercial and open source library systems without the overhead required to implement them. The database was seeded with MARC records from Project Gutenberg to represent a library collection. The borrowers were populated with the names and addresses of the representatives and senators of the 110th Congress of the United States. A script was written to assign a random number of item records to each bibliographic record (with the possibility of zero), set a current circulation status, and, if that status was “Checked Out”, assign the item to a borrower at random.
The OpenBiblio connector uses the JangleR connector framework. It defines GET (read only) interfaces for accessing Actors, Resources, Items and Collections. Actors return their data using the popular vCard format. Resources may be returned as MARC XML, MARC 21 or OAI Dublin Core. An OpenSearch interface is also available for Resources, allowing clients to search on particular fields, such as title, author, subject and date modified. Items are offered in the simpleAvailability format [26] defined in the recommendation of the Digital Library Federation’s Integrated Library System Discovery Interface (DLF ILS-DI) Task Group and in the Document Availability Information API (DAIA) format [27]. Other holdings and availability formats will be available in the future. Collections for this connector are currently groups of Resources as set in OpenBiblio itself (such as “Adult Non-fiction”).
In an effort to show the relationship between Jangle and the DLF ILS Discovery Interface Task Group’s recommendation, an ILS-DI adapter providing Level 1: Basic Discovery Interfaces functionality [28] was also written as part of JangleR. This illustrates the role of adapters within the Jangle framework as, theoretically, this adapter should work on top of any Jangle implementation with an integrated library system connector. The adapter combines Open Archives Initiative Protocol for Metadata Harvesting [29] (OAI-PMH) to provide the HarvestBibliographicRecords and HarvestExpandedRecords functionality with simple CGI-style interfaces to provide the GetAvailability and GoToBibliographicRequestPage methods. For GetAvailability, the adapter uses the Item entity directly. For GoToBibliographicRequestPage, Jangle’s Resource entity provides a <link> element to a text/html representation; the adapter parses the record and redirects the client to that URL.
The frameworks in JangleR are released under the GNU Public License version 2 (GPLv2), meaning they are freely available and the source open for review or adaptation [30]. The connectors built using the framework do not have to conform to GPLv2, since the connector logic exists in files outside of the framework itself. The strong copyleft license allows other developers to port the framework to other languages easily by ensuring that the code is always available to see.
Proof-of-Concept Unicorn Connector (PCUC)
Connectors are simple RESTful interfaces that define five base paths (/services, /actors, /resources, /items and /collections) and return their results as JSON hashes. The JSON hashes also include the MIME-type that the Jangle core should serialize the response as.
A proof-of-concept Unicorn connector (PCUC) has been written by James Farrugia at Drew University. So far, only certain URI patterns have been implemented, based on three of the five base paths (/services, /resources, and /items). The PCUC was written to test the feasibility of implementing a Jangle connector for Unicorn (a commercial ILS provided by SirsiDynix), and it deals only with read access to certain bibliographic- and item-level information.
Specifically, the following URI patterns have been implemented for accessing resources:
- /services – This URI indicates which services are offered. For now, services pertaining only to Resources and Items are offered – i.e., no services are currently offered for Actors or Collections.
- /resources – This URI is currently hard-coded to return a list of the first twenty bibliographic records.
- /resources/I – This URI returns the bibliographic record associated with unique record identifier I, which is a positive integer, ranging from 1 to the number of resources (bibliographic records) in the collection at Drew University (roughly 570,000). If the integer I is larger than the number of resources in the catalog, the server returns a 404 error.
- /items/B – This URI returns item information for the item identified by the unique identifier “B” (for a book this is usually a barcode).
- /resources/I/items – This URI returns item information for all the items associated with a given resource (bibliographic record) uniquely identified by the integer I.
Examples of URI patterns that have not yet been implemented are:
- /resources/I1,I2 – Given a list of bibliographic identifiers, return information about multiple bibliographic records.
- /resources/sI1-I2 – Given a range of bibliographic identifiers, return information about multiple bibliographic records.
- /items/B1,B2 – Given a list of item identifiers, return information about multiple item records.
- /resources/B1,B2/items/ – Given a list of bibliographic identifiers, return information about all the item records associated with the bibliographic records identified by B1 and B2.
Some details on how the PCUC is implemented
We implemented the Proof-of-Concept Unicorn Connector using Apache’s mod_rewrite and rewrite rules in .htaccess (Fig. 5) to invoke particular PHP scripts on the Unicorn server. These PHP scripts do two principal tasks: interact with the Unicorn API to retrieve information relevant to the HTTP GET request, and then format this information into a JSON string that uses a Jangle-specified syntax. The JSON string, with an appropriate MIME type, is sent back to the Jangle Core, which then appropriately serializes the data to its proper XML representation (such as an Atom feed or service document).
# for one bib rec: http://myserver.mydomain/resources/12345 RewriteRule ^resources\/([0-9]+)$ Jangle/resourcesOneBibId.php?entity=resource&idType=resource&id=$1 # for one item rec: http://mysever.mydomain/items/3114005851463 RewriteRule ^items\/([0-9]+)$ Jangle/itemsOneItemId.php?entity=item&idType=item&id=$1
Conceptually, the connector implements a simple and straightforward process: it takes the parameters from the URI, uses those parameters to interact with Unicorn, extracts information from Unicorn, parses that information into Jangle-specified JSON syntax, and sends everything back with a JSON MIME type. In reality, it took a bit of doing to get everything working, but all the doing was done in about 2 weeks.
For pragmatic and institutional reasons, we used PHP on a Windows 2003 machine that is Drew University’s Unicorn test server. In addition to invoking a recent Unicorn API tool (available as of release GL 3.1), we also needed a way to convert our MARC records to MARC XML. We chose the freely available yaz-marcdump program from IndexData [31]. Then we needed two other capabilities: the ability to convert XML to JSON within PHP, and the ability to work with a JSON string as a PHP associative array (i.e., a hash). The first one was found in some off-the-web PHP software [32]; the second one is built in to PHP itself. Finally, we needed to parse and reformat a variety of time stamps, ranging from the current system time, to the MARC control field 005 time, to the form of the time returned by Unicorn for item creation and due dates. Getting the details correct for these different timestamps took a particularly long time.
The following factors made writing the PCUC take more time than it otherwise might have:
- It took some time to understand the syntax and contents of the different JSON strings that the Jangle core expects. Although the overall syntax was similar for the different URI patterns, each implemented URI pattern required slightly different contents in its JSON string.
- The two authors spent a fair amount of time going back and forth with each other to clarify, test, and implement the expected JSON coming from the Unicorn connector.
- The developer’s knowledge of Jangle’s conceptual framework was very limited at the start of the project.
The following factors made writing the PCUC take less time than it otherwise might have:
- The developer of the Unicorn connector had experience working with the Unicorn API from previous Unicorn-related work that was done for the VuFind project [33].
- We were able think of the problem in easy conceptual terms: when a URI of this form hits your server, send back a JSON string, with MIME type JSON, that looks like so.
- We had concrete examples from the OpenBiblio connector for the JangleR Reference Implementation, which we could use to understand and model our JSON strings.
- We used Apache and the RewriteRules it makes available in mod_rewrite.
Having done this work, we have a basic proof-of-concept Unicorn connector for Jangle. Furthermore, we are confident that it would be not be difficult to write additional Unicorn connector scripts that would implement additional URI forms for Resources and Items. Finally, if writing the Unicorn connector components for Actors and Collections proves to be essentially no more difficult than writing the proof-of-concept for Resources and Items has been, then there is good reason to believe that a full-blown Unicorn connector for Jangle can indeed be written for GET requests.
As for PUT, POST, and DELETE requests utilized for updating and deleting resources via AtomPub, a Unicorn connector for Resources, Items, Actors, and Collections would need to access Unicorn’s API in ways that were not done with the PCUC. Specifically, API calls for PUT, POST, and DELETE, which are different from the API calls used for GET requests, would need to be able to change Unicorn data, rather than simply read it. Unicorn does have API calls that a DELETE request, for example, could invoke to delete a resource and all its associated items. Unicorn also makes available other API calls that can be used to change data on the Unicorn server. Whether or not Unicorn has available all API functionality necessary for any PUT, POST, or DELETE request in the Jangle framework has yet to be investigated. We should also point out that there are definitely security issues involved with HTTP requests that can change data — for instance, we would not want to give permission to just any web service to delete resources. There may also be SirsiDynix proprietary issues related to the use of API commands that do more than just read information from Unicorn.
Possible Jangle connectors for various kinds of systems
The integrated library system
Certainly one of the most important and, potentially, common uses for Jangle will be to expose the data from the integrated library system. This is useful for a variety of tasks, from providing bibliographic and availability data to discovery interfaces to exposing borrower account information to a campus portal or financial system.
|
Entity |
Types of data included |
Possible formats available |
|
Actors |
Borrowers |
vCard, FOAF, finance formats for fines |
|
Resources |
Bibliographic records, subject and name authorities |
MARC21, MARC XML, Dublin Core, MODS, MADS |
|
Items |
Physical Items, Serials Holdings |
ISO 20775, MARC 21 for Holdings Data, DLF simpleAvailability, NCIP |
|
Collections |
Bibliographic records, authorities, distinctions between item types (serials, monographs, government documents, etc.), course reserves |
defers to the entities in the collection |
A discovery system could stay up to date by polling the Atom feed for Resources at various intervals for changes. Targeted discovery systems could be created by harvesting the feeds of distinct Collections, allowing for very specific interfaces to resources such as serials or videos.
Changes to the borrower’s account in the ILS could be propagated in real time as users update address information or pay fines in the central portal system or courseware.
Interlibrary loan system
Most of the uses surrounding a Jangle interface to an interlibrary loan system would likely revolve around providing borrowers with status information regarding their requests or delivery of their requests in an electronic format. It would also be possible to provide more sophisticated reports of materials requested and, depending on the system and the library policies, even allow for the creation of requests from within other applications.
|
Entity |
Types of data included |
Possible formats available |
|
Actors |
Borrowers, Lending institutions, Borrowing institutions |
vCard, FOAF, finance formats for fines |
|
Resources |
Interlibrary loan requests |
ISO ILL, OpenURL metadata formats, Dublin Core |
|
Items |
Loaned items |
Circulation and location information, PDFs |
Collections have a less obvious analog in this context and would probably be more usefully applied for local needs.
Because Items would be associated with Actors and Resources, a feed of the status of the user’s request could be displayed in their account in other systems, such as the OPAC or central portal.
Institutional repository
Although a Jangle interface to an institutional repository would probably overlap with the goals of the SWORD project (more on this in “How Jangle gets along with its neighbors” section), SWORD does not define most of the activity involved with interacting with a repository. Jangle would most likely defer to SWORD for dealing with submission to an archive and, instead, focus on making the data available.
|
Entity |
Types of data included |
Possible formats available |
|
Actors |
Submitters, Authors |
vCard, FOAF |
|
Resources |
Archived object metadata |
Dublin Core, BibTex, Endnote, RIS, BiblioOntology, PREMIS |
|
Items |
Electronic formats available |
PDF, Postscript, MS Word, Excel, SCORM learning objects |
|
Collections |
Departments, subjects, special collections |
Dublin Core to describe the collection, defer to the entities within the collection |
Feeds could then be provided by author or department to include in other applications. Discovery systems could harvest the collections relevant to their domain.
Course reserves management system
The most obvious use case for a Jangle interface to a course reserves system would be to include feeds of class readings in courseware or a central portal. Another scenario would be to enable instructors to add reserves from other interfaces, such as a link resolver, metasearch tool, or courseware.
|
Entity |
Types of data included |
Possible formats available |
|
Actor |
Instructors, Students |
FOAF |
|
Resources |
Journal articles, Book chapters, Annotations, Instructions |
OpenURL metadata formats, Dublin Core, Atom |
|
Items |
Scanned copies, circulating copies at reserves desk |
Circulation and location information, OpenURL link, PDF |
|
Collections |
Course information |
Atom to describe classes, defer to entities within the collection |
In the case of course reserves, it is easy to see Actors related to Collections, Collections related to Resources and Resources related to Items. Circulation information for a physical reserve item could be pulled directly from a Jangle connector for the ILS if the URI is provided. The ILS could also feed the reserves system as items are placed on reserves status in the catalog.
How Jangle gets along with its neighbors
Since there are other initiatives in place that share similarities with Jangle, it seems appropriate to see how Jangle fits in with them, if there are any conflicts or overlaps and how they may be resolved.
SWORD
SWORD [34] (Simple Web-service Offering Repository Deposit) is a protocol developed to manage the submission of objects to repository systems. The project has the backing of the major open source repository platforms (DSpace, Fedora and E-Prints) and uses the Atom Publishing Protocol as the basis of its API. SWORD, however, only defines the POST method for submitting objects since its purpose is to manage the ingestion of resources into repositories. Retrieval, update and delete are out of scope for the initiative, so Jangle could, theoretically, provide that functionality. Jangle, in turn, could simply rely on SWORD for defining POST behavior in a repository community profile and provide guidance for specifying the creation of resources across the entire specification.
The SWORD and Jangle projects can be mutually beneficial for one another.
OAI-ORE
OAI-ORE [35] (Open Archives Initiative-Object Reuse and Exchange) is a protocol for sharing collections of resources and the graph of the relationships between them for minting a URI to define that graph. OAI-ORE does this via an RDF graph of aggregated resources called a Resource Map. While OAI-ORE does define an Atom Syndication feed serialization, there are few other similarities between this protocol and Jangle. Jangle does not define aggregations in the same context as OAI-ORE and only defines the relationships between internal Jangle entities in a very simplistic model. OAI-ORE has no capacity for creating, updating or deleting resources, only providing read access to data.
These two initiatives appear to be addressing fairly different problems.
Digital Library Federation Integrated Library System Discovery Interface Task Group
The Digital Library Federation’s Integrated Library System Discovery Interface Task Group (ILS-DI) [36] produced a formal API recommendation describing methods to expose data from and interact with integrated library systems. The recommendation lays out a series of functions and defines their purpose and role. Instead of being a turnkey protocol, the ILS-DI API takes a best of breed approach, suggesting protocols such as OAI-PMH or OpenURL to meet the functional requirements. The recommendation makes no mandates as to how the functionality should be achieved. Different implementations can use different protocols to provide the same functionality.
The relationship between Jangle and the ILS-DI is an unusual one. Jangle has identified the ILS-DI API as a primary use case influencing its development. Instead of directly competing, the role of Jangle with regards to the API is that of the enabler. Since the interfaces needed to meet the goals of the ILS-DI API do not currently exist in many integrated library systems, Jangle could quite easily fill that role. Since a Jangle adapter should be able to work across many Jangle implementations, a single ILS-DI adapter could establish a de-facto standard for how specific methods are implemented.
In short, Jangle is trying to provide the underlying API upon which the ILS-DI API can be built across all integrated library systems.
The current state of Jangle
The Jangle community decided to first specify read requests (HTTP GET) for all of the base entities before moving into the more complicated write functionality. The connector APIs have been fairly stable although they need to be vetted against multiple implementations. Since the connector API is limited to basic Atom, a means of extending the API needs to be formalized before the first Jangle specification is released. This way connector providers can tap into versatility of Atom extensions, and if there is a standardized notation for how to parse them, the Jangle core does not have to keep up with the semantics of each and every extension (especially ad-hoc ones) and can instead, directly translate the JSON into XML.
Once Jangle is working satisfactorily to communicate between at least three different library systems and a consumer application (such as an OPAC replacement), the API will be written up as a formal specification document and released as 1.0. Currently, there is the OpenBiblio connector and the Proof-of-Concept Unicorn connector and work has begun on a Talis Alto [37] connector.
Development of the specification takes place on Jangle’s website, the mailing list [38], and the project page for the Jangle development repository [39]. The community votes on all major decisions and periodically does “approval polls” to make sure the project has not veered beyond the community’s vision or expectations. The process, as well as the community, is open to anyone interested in participating.
When the specification is stable for the 1.0 release, a PHP implementation of the connector framework will also be released as open source. The PHP framework is considered critical to the success of the project, since it the language of choice in many libraries and is so easily deployed.
Tomorrow and beyond
After GET requests have stabilized and the first API specification document has been released, the community will vote on the next HTTP method to focus on (POST, PUT, DELETE, etc.). It is also possible that the community will decide to focus on implementing all methods for a particular underlying system. While development of the protocol has been quite swift during this iteration, it is expected the release cycles will slow considerably when changes to the local data stores are introduced.
In the near future, the ideal would be to replace the Jangle core with a more established AtomPub server application, such as Apache’s Abdera [40]. Since Jangle in its current state does nothing to address authentication or authorization (and the specification will only mention that security is at the discretion of the implementor), piggybacking on an existing project that already has these features would be pragmatic and relieve some of the development burden.
Since development of Jangle really takes place at the connector level, it is desirable to have connector frameworks in a variety of major languages: Java, Perl and Python (since Ruby and PHP should already be addressed). It would also be desirable to supply a suite of connectors to various open source applications beyond integrated library systems: institutional repositories, interlibrary loan, course reserves, etc. to help guide the community profile development for various kinds of systems.
This would also be the stage for soliciting vendor support for Jangle by showing how easy it is to implement and how quickly the vendor could meet the demands of initiatives such as the DLF ILS-DI. In fact, by implementing Jangle, it is quite possible that vendors could rely on their customers and competitors to provide them with the functionality needed to provide various protocol interfaces.
And back to reality
Jangle is by no means a panacea for all of the woes of library interoperability. It cannot make free text holdings information magically machine parseable. It requires considerable agreement on compatible data formats and jargon. It cannot overcome politics and differences in policy that will still cause headaches for the developers tasked with designing a system that works across institutions.
It does however make library data available using a simple mechanism that can be accessed with cheap, commodity client libraries. No knowledge of library data formats or transfer protocols is necessary. Rather, once connectors are built (which would require knowledge of the underlying library applications), software clients outside the library world need only the knowledge of a commonly used programming language and standardized web protocols in order to access and make library data available. These same clients can be used to create, edit and delete resources. The whole universe of library data, liberated from the arcane world of proprietary library applications, will be available for developers outside the library domain.
Notes
[2] http://www.loc.gov/z3950/agency/
[3] http://ncip.envisionware.com/
[4] http://www.niso.org/publications/rp/rp-2006-01.pdf
[5] http://www.loc.gov/standards/sru/
[6] http://www.niso.org/apps/group_public/workgroup.php?wg_abbrev=mi
[7] http://www.oasis-open.org/committees/tc_home.php?wg_abbrev=search-ws
[8] For an introduction to RESTful design, see http://en.wikipedia.org/wiki/Restful and http://www.infoq.com/articles/rest-introduction
[9] http://www.talis.com/
[10] http://www.talis.com/integration/
[11] http://bitworking.org/projects/atom/rfc5023.html
[12] http://www.atomenabled.org/developers/syndication/atom-format-spec.php
[13] http://www.loc.gov/standards/marcxml/
[16] http://code.google.com/more/#products-dataapis-gdata
[17] http://www.opensearch.org/Home
[18] http://codex.wordpress.org/AtomPub
[19] http://www.movabletype.org/documentation/developer/api/atompub/
[20] http://json.org
[21] http://unapi.info
[22] http://www.ietf.org/rfc/rfc5005.txt
[23] http://badgerfish.ning.com
[24] http://sinatrarb.com
[25] http://obiblio.sourceforge.net
[26] http://onlinebooks.library.upenn.edu/schemas/dlfexpanded.xsd
[27] http://www.gbv.de/wikis/cls/Document_Availability_Information_API
[28] http://diglib.org/architectures/ilsdi/
[29] http://www.openarchives.org/pmh/
[30] http://code.google.com/p/jangle/source/checkout
[31] http://www.indexdata.com/yaz/doc/yaz-marcdump.tkl
[32] http://www.ibm.com/developerworks/xml/library/x-xml2jsonphp/ and http://pear.php.net/pepr/pepr-proposal-show.php?id=198
[34] http://www.ukoln.ac.uk/repositories/digirep/index/SWORD
[35] http://www.openarchives.org/ore/
[36] http://diglib.org/architectures/ilsdi/
[37] http://www.talis.com/alto/
[38] http://groups.google.com/group/jangle-discuss
[39] http://code.google.com/p/jangle
[40] http://incubator.apache.org/abdera/
About the Authors
Ross Singer is Interoperability and Open Standards Champion at Talis. His blog can be found at http://dilettantes.code4lib.org/.
James Farrugia currently works as Systems Librarian at Drew University. He can be reached at jfarrugi@drew.edu

Subscribe to comments: For this article | For all articles
Leave a Reply