by Ian Lamb and Catherine Larson
In September 2015, two researchers with the Federal Reserve Board in Washington, D.C. released a study that shook the field of economics [1]. After attempting to replicate the findings of 67 papers published in 13 different economics journals, Andrew C. Chang and Phillip Li were only able to successfully reproduce the results of 33% of the papers. Even after directly contacting the original authors for help, this number only rose to 49%, meaning that more than half of the sample was irreproducible.
Chang and Li’s paper was unflattering to the field, but it was just one of a growing number of similar studies in other sciences. Just a few months before, in August 2015, Science published a damning study proving that only 36 out of 100 psychology studies were reproducible, even when using the original study materials [2].
These papers made headlines, but what made them possible is a growing movement to encourage the sharing of research data for reuse or reproduction. Publications such as PLOS [3], and government bodies such as the White House’s Office of Science and Technology Policy now require that authors share data or provide a data sharing plan [4]. And libraries are particularly well placed to foster this sharing, with our expertise in resource classification, metadata, and discoverability, as well as our close relationship with our research communities.
At NYU Langone Medical Center, the Department of Population Health (DPH) informed their library liaisons that researchers were having difficulty locating datasets relevant to their work. Even when they decided on a dataset to use, actually getting access to it could be a labyrinthine process. Many large public health datasets are split into multiple sections that are hosted on different websites, making it difficult to know which one to use. They can be subject to confusing licensing agreements, and often even the data itself is confusing or lacks a thorough data dictionary. For these reasons, researchers often try to work with an individual who has used the dataset before and can serve as a guide of sorts, but they would have to rely on word-of-mouth to locate these individuals. A project began to take shape that would marry the classification, discoverability, and web development abilities of the Health Sciences Library with the research experiences of faculty at the DPH. With this project, it was hoped that we could help researchers locate useful data for their studies as well as provide a way for them to share their own data with the world [5].
A metadata schema would have to be developed that could accommodate these public datasets as well as data produced in-house by NYU’s own researchers. Once developed, a “data catalog” website would be created that combined a full-featured, faceted search with this rich metadata schema, and provided an administrative interface so non-technical staff could perform basic CRUD functions on these datasets without any assistance. Given the DPH’s focus on large, population-level datasets such as the US Census and the American Time Use Survey, it was decided that we would not store datasets locally. This avoided several practical problems including the cost of indefinitely storing petabytes of data. It also allows us to catalog data that researchers may be reluctant to share just yet, or data that contains personal information that has not yet been de-identified.
Groundwork
The first step was for librarians to begin work on a metadata schema using examples from existing data catalogs. Nature’s journal Scientific Data, which began publishing in 2014, is a wonderful example of data sharing and contains detailed, peer-reviewed descriptions of scientific datasets. However, we found their “Data Descriptor” article type to be too detailed, and too limited in scope for our purposes. We also looked at existing tools such as Dryad (http://wiki.datadryad.org/Metadata_Profile ), DataCite (https://schema.datacite.org/meta/kernel-3.1/index.html ) and the W3C Data Catalog Vocabulary (https://www.w3.org/TR/vocab-dcat). In fact, one of our librarians looked at 45 NIH data sharing repository metadata schemas to identify their most common metadata elements [6]. His research informed both the NIH’s BioCADDIE initiative [7] – which attempts to define a standard data descriptor format for all disciplines – and our own catalog. We believe strongly that using standard or at least similar metadata elements will be an advantage in the future and will increase the compatibility of our catalog with others.
Simultaneously, developers were searching for existing data catalogs and trying to learn from them. We found one such example made using Drupal, which was convenient because several of our own websites run on Drupal, and as a full-featured CMS it would include the CRUD (Create, Read, Update, and Delete) functionality and administrative interface we desired. We were excited by this possibility and got to work building a prototype. Before long, however, it became clear this was not a workable solution for us. Though our metadata at this time was not complex, making Drupal aware of it and searching it was not easy. Within Drupal, a Content Type was created that could accommodate the metadata, but building a search interface that worked anything like we wanted proved difficult. Developers felt they were wrestling with Drupal (perhaps a common feeling among Drupal developers) and this strategy was dropped.
More promising was the example set by the National Snow and Ice Data Center (NSIDC) (http://nsidc.org/data/search/), affiliated with the University of Colorado – Boulder. Their search page is a slick JavaScript-based page, written mostly with the Backbone framework and using modern tools like Underscore.js and Require.js. Their search worked well by our standards, and the results even included helpful maps showing the geographic areas covered by the dataset.
A Whole New World
Seeing the success that NSIDC had using Backbone – and because our developers were interested in learning this new tool – we set out to see what could be done. It was also decided at this time that to get the full-featured and flexible search we needed, Apache Solr would be the only reasonable solution. We had some limited experience with Solr after using it on another project, but it was our first time using it for a purely search-focused project. And yet, after surprisingly little time, a working prototype of the Data Catalog was up and running that used Solr, Backbone.js, jQuery and Underscore.js almost exclusively.
Some things about Backbone proved to be incredibly useful, almost game-changing compared to the traditional server-side world of PHP and Python that our developers were used to. One such piece was the built-in publish/subscribe event system, whereby any object in your application can listen for events emitted by any other object, and trigger their own. This is a common design pattern, but in Backbone, it could not be simpler to set up. By simply declaring a top-level variable to hold the Events object (var megaphone = _.extend({},Backbone.Events);), any View (or other object) in your application can communicate with any other without directly referencing it. So if an object does something noteworthy – like, say, receives new results from Solr – it can publish this fact easily by using our “megaphone” system:
megaphone.trigger("Solr:newResults",data);
Any other object in your application can listen for this event as easily, and also specify a method to be called when it happens (in this case showResultsFound())
var resultsView = Backbone.View.extend({
initialize: function() {
this.listenTo(megaphone,
"Solr:newResults",
this.showResultsFound);
}
});
Using this paradigm, Views can function almost as independent actors, listening for whatever is relevant to them and then reacting to that data according to their own sets of rules. But the real beauty stems from the fact that in Backbone, these Views are attached directly to DOM elements on your page. This becomes a very fun way to think about your site, and it’s one of the chief advantages of a JavaScript-based front-end framework: a webpage that would be more or less static after being served up by a server-side framework now becomes malleable and vibrant, almost alive, with each DOM node able to update itself and to influence any other nodes to do the same, each playing by their own rules. With some creative animations this effect can really be amplified.
We liked that Backbone, though it is “minimalist,” did enforce a few good practices. The Model-View-Controller paradigm and the use of RESTful URL structures are some of the few rules that Backbone has, and they are good ones. While your JavaScript files will grow greatly in size, at least the functionality is compartmentalized in a way that makes sense and will continue to make sense indefinitely.
A third appealing aspect of Backbone is a direct result of that minimalism: its much-touted flexibility. Coming from Drupal, a project which is approaching 15 years old and which has its own way of doing things to the point of having its own ecosystem, it was a great relief for developers to be able to come up with an idea and immediately know how to implement it, and to be able to use relatively basic JavaScript and HTML to do so. We did not have that sense of “wrestling” with the framework that we had with Drupal. Rather, we had a ton of freedom with how the page looked and how it interacted with other systems and with itself.
And yet, despite these and other advantages, life with Backbone was not perfect. In fact, as our requirements grew and work began on the authentication and content management functionality, we saw some very stark limitations. It became clear that, while Backbone is commonly referred to as a framework, its name tells the real story: it is really just a skeletal add-on to JQuery that provides a few useful features. And while Backbone is often praised for being unopinionated, after a while one gets the impression that it is actually quite opinionated when it comes to the things it doesn’t do — which is most things. Functionality that those coming from other MVC frameworks might take for granted will have to be crafted from scratch in Backbone, which means you cannot “stand on the shoulders of experts.” For instance, authentication and sessions will have to be handled manually, leaving room for error. All decisions about application structure and memory management fall to the developer, and there are some known pitfalls that cause memory leaks.
To address these shortcomings, a plethora of additional JavaScript libraries have been created to give more structure and functionality to Backbone. These include Marionette (http://marionettejs.com/), Backbone Boilerplate (https://github.com/tbranyen/backbone-boilerplate), Chaplin (http://chaplinjs.org/), Epoxy.js (http://epoxyjs.org/), Backbone Session (https://www.npmjs.com/package/backbone-session), and others. But adding more libraries would seem to defeat the purpose of using such a lightweight framework in the first place.
Most damning for our purposes, however, was Backbone’s naïve assumption – a strong opinion, if you will – that it will always be interacting with a perfectly crafted RESTful backend that communicates in JSON. Basically, if the server you are communicating with does not strictly follow the RESTful URL structure and use the HTTP methods as prescribed, you will spend significant time overriding basic Backbone functions in order to communicate with it. Solr does speak JSON, but like most other search software, it has its own URL structure and relies on numerous URL parameters – many with their own unique syntax – to craft the search. So, we had to create a PHP script that essentially translates between Backbone and Solr. While it wasn’t such a big deal at first, as the search functionality grew increasingly complex, this translation became more and more difficult to manage. It dawned on us that for our application to be of any use, we would either have to use numerous additional JavaScript libraries, or rely on more of these server-side scripts to handle basic functionality. Whether approaching it from a theoretical, systems design standpoint, or a practical, long-term maintenance standpoint, neither solution was appealing.
Once More Unto the Breach
Simultaneously, librarians were cataloging a growing list of datasets, and their need for a full-fledged administrative interface to manage their metadata was growing. This would require the addition of LDAP authentication with our institution’s Active Directory, session management, detailed input forms with validation, and much more – all those things that Backbone doesn’t do. As planning for this next phase started, and our heads buzzed with a dozen add-on JavaScript libraries that could help us, a painful decision was eventually made to put the Backbone version on the backburner and move forward with a more traditional server-side framework: Symfony (https://symfony.com/).
While starting again was not an easy choice to make, the advantages were immediately obvious. Symfony has an authentication system that meshed relatively easily with our institution’s Active Directory system and automatically generates CSRF tokens. Session management is robust, flexible and built-in, and memory management is almost never a concern. The form system is a bit inelegant and has a steep learning curve, but form validation is a dream, performed automatically based on PHP annotations in the source file itself – the same annotations used by the Doctrine ORM tool to construct the database automagically.
Before we look at how easy it is to set up the database, let’s take a quick look at the data model we ended up with. As mentioned previously, librarians drew heavily on existing metadata schemas. We had our own unique needs, mostly stemming from our desire to include both “external” datasets (such as the US Census) and “internal” ones (those produced in-house by our researchers). For example, while it’s fair to assume that external datasets are catalogued elsewhere, for internal datasets, our own catalog is likely to be the authoritative reference. To adequately describe both types of data would require a somewhat complex schema. For example, external datasets have a “Local Expert” field, which denotes an individual at our institution who has agreed to help fellow researchers who wish to use one of these datasets, which can be enormous and quite confusing. Those who wish to use internal datasets, however, are encouraged to contact the author directly, as he or she is the expert and is usually the only one who can provide access to the data. There is also the challenge of being able to describe datasets from different fields. At this point we’ve been working closely with the Department of Population Health, but we will eventually need to accommodate data from our clinical and basic science departments, so we included fields where we can describe equipment such as microscopes and imaging devices.
Another source of complexity was translating this all to a normalized relational database. Many of these metadata fields represent items that are entities unto themselves and need their own tables, relating back to the Dataset via a many-to-many relationship. For example, a Publisher has an existence apart from any Dataset it may be associated with. By creating a separate Publisher entity (in Symfony and in the database), any information about a publisher can be managed independently and changes are reflected immediately in all related Dataset records.
This is all pretty standard, but developers were concerned with the sheer number of entities required to faithfully represent this flexible model. Figure 1 is a partial representation of our database, showing most of the complexity. In total, our model required 24 separate entities and 54 database tables. To display a full Dataset record requires at least 20-30 database calls, as reported by Symfony’s built-in debugging tools. While the database was conceptually pure, we began to wonder if it would perform well enough in the real world to be of any use. Perhaps some entities should be reevaluated for possible merging back into the main Dataset entity.
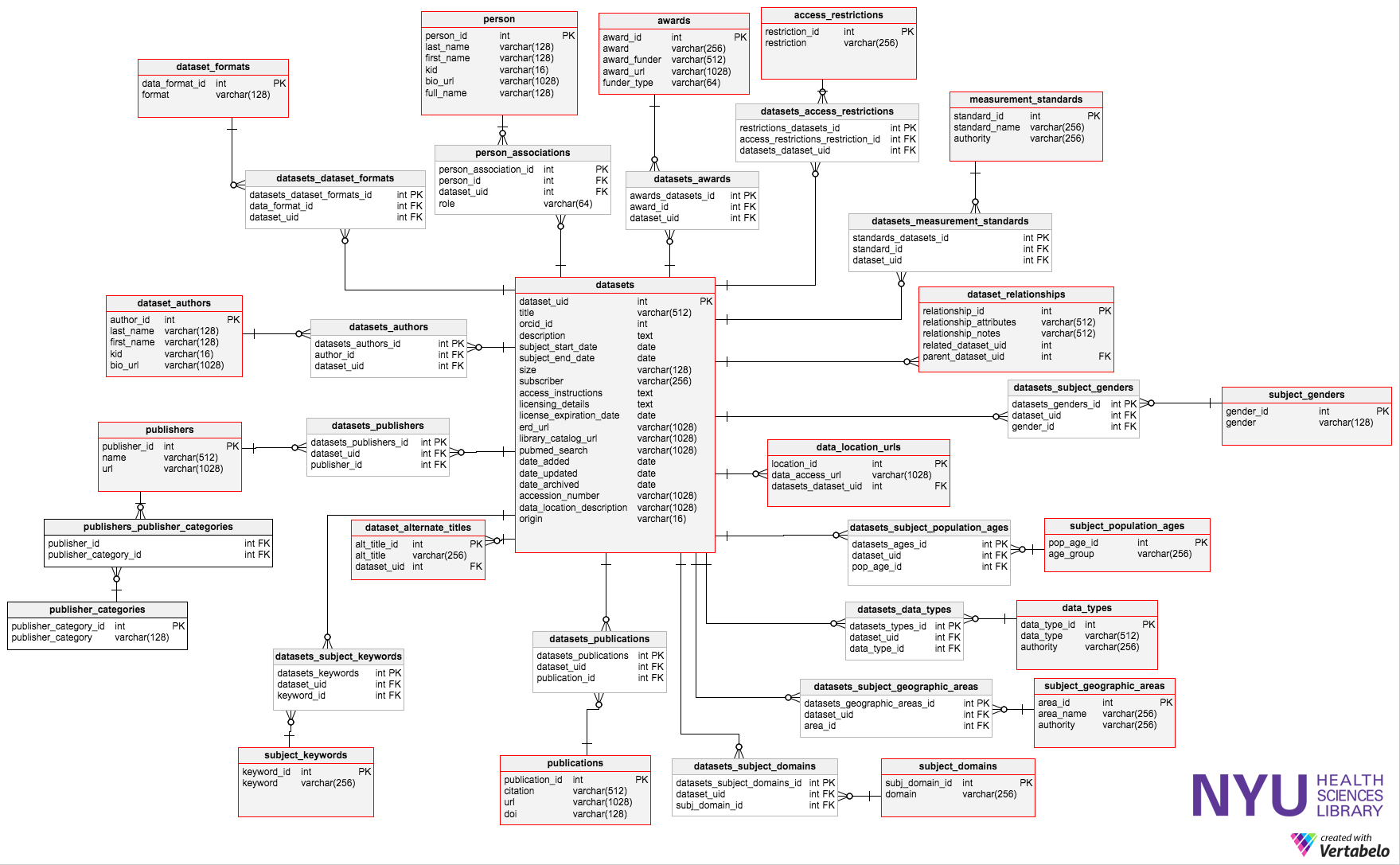
Figure 1.
Despite our concerns about performance, in the end there were no issues whatsoever. Even the most complex Dataset records load almost instantaneously. The Doctrine Object-Relational Mapping (ORM) tool that ships with Symfony (http://www.doctrine-project.org/) handles most of the database communication behind the scenes, so it’s hard to be sure what’s happening without detailed knowledge of how it works. It does seem to avoid complicated joins in favor of separate queries, which probably helps with responsiveness. But we credit Symfony’s multiple layers of caching for most of the boost. At the database itself, there is of course the built-in MySQL query cache, which speeds up a repeat query by more than half in our case. Interestingly, the Doctrine ORM also maintains its own query cache on the web server, as well as a results cache and metadata cache. Additionally, Symfony provides two options for storing a class map to help it find your source files. There is a built-in option that uses Composer (a PHP dependency manager – https://getcomposer.org) to build a giant array of the paths to all your class files. The other option – and the one we chose – is to use the APC byte code cache to store this class map for ultra-fast retrieval. We also went further and used APC to store a bootstrap cache, which is a big file containing the full definitions of all our classes so that in most cases, Symfony doesn’t have to load the source files at all. Most of this caching was enabled by default except the APC caches, which we enabled simply by uncommenting a few lines in Symfony’s configuration files.
Even without the performance issues, we would have had some real struggles constructing this network of relationships by hand, so it was great that we didn’t have to. The process is done almost entirely automatically by use of Symfony’s built-in command line tool. While defining classes and properties, the developer can use PHP Annotations to describe what they want the database to look like (http://doctrine-common.readthedocs.org/en/latest/reference/annotations.html). The command-line tool then reads all these annotations and translates them to SQL commands to create the database. We loved this system because it enabled us to define the database structure in the same place where we are creating the object. For example, the following code not only declares a few object properties, it also describes the table structure for Doctrine, and sets constraints on the object which are then enforced by MySQL as well as by Symfony’s form validation service.
use Doctrine\ORM\Mapping as ORM;
use Symfony\Bridge\Doctrine\Validator\Constraints\UniqueEntity;
/**
* @ORM\Entity
* @ORM\Table(name="publishers")
* @UniqueEntity("publisher_name")
*/
class Publisher {
/**
* @ORM\Column(type="integer",name="publisher_id")
* @ORM\Id
* @ORM\GeneratedValue(strategy="AUTO")
*/
protected $id;
/**
* @ORM\Column(type="string",length=255,nullable=false)
*/
protected $publisher_name;
}
In the annotations on the class, we’ve told Doctrine that this is a new entity represented by the table “publishers.” We’ve also told the form validator that the “publisher_name” field needs to be unique. Furthermore, using annotations on the “publisher_name” field, we’ve told Doctrine that the database must limit this string field to 255 characters and allow null values. Though we didn’t explicitly tell the form validator about these two constraints, it will honor both of them as part of its “field options guessing.”
Now, we just run a simple command and Doctrine sets up the database just the way we asked:
php app/console doctrine:schema:update --force
Annotations are also used to set up join tables, foreign keys, and pretty much anything else you want out of a database. While it’s nice to have everything in one place, these declarations can get very verbose and represent almost a pseudo-language that must be learned. Look at this annotation declaring the relationship between the Dataset entity and the Related Equipment entity:
/**
* @ORM\ManyToMany(
* targetEntity="RelatedEquipment",
* cascade={"persist"},
* inversedBy="datasets"
* )
* @ORM\JoinTable(
* name="datasets_related_equipment",
* schema="datasets_related_equipment",
* joinColumns={
* @ORM\JoinColumn(
* name="dataset_uid",
* referencedColumnName="dataset_uid"
* )
* },
* inverseJoinColumns={
* @ORM\JoinColumn(
* name="related_equipment_id",
* referencedColumnName="related_equipment_id"
* )
* }
* )
* @ORM\OrderBy({"related_equipment"="ASC"})
*/
protected $related_equipment;
Much of this can supposedly be done automatically, but there are some quirks and we found that explicitly defining our relationships and join tables in this way prevented Symfony from misinterpreting us.
Integration with Solr, while imperfect, was much easier than in Backbone. We used Symfony’s concept of Service Containers to create an object that is globally accessible in the application and would provide a simple interface whereby any object could communicate with Solr. We also created an object “SearchState” to hold the current state of the user’s search – what facets are currently activated, what keywords have been entered, what page they are viewing, etc. The HTTP request is fed to the SearchState object, which reads the URL parameters and sets its properties accordingly. It then gets passed to the SolrSearchr service, which painstakingly constructs a URL that Solr will accept, and then fetches the results. The results are fed into a “SearchResults” object that is eventually rendered through a template and presented to the user. The process looks like this in our controller:
// reading the search state
$currentSearch = new SearchState($request);
// calling the Service
$solr = $this->get('SolrSearchr');
// setting search parameters in the Service
$solr->setUserSearch($currentSearch);
$resultsFromSolr = $solr->fetchFromSolr();
$results = new SearchResults($resultsFromSolr);
We are pleased with this elegant solution, but we did not use the word “painstaking” lightly. While Symfony was happy to communicate with Solr outside the constraints of a prescribed URL structure (unlike Backbone), it turns out that Solr is extremely particular in its own ways. For example, Solr has incredible support for faceted searches, but the URL syntax required to set it up is somewhat verbose, and the date facets (e.g. limiting the search to between 1975 and 1984) use a different syntax than non-date facets. And the facets are just one of seven distinct URL components that are necessary to represent our search. Just as an example, a search query where the user has specified a keyword and activated one date facet and one non-date facet looks like this:
http://yoursolrserver.com/solr/data_catalog/select? q=text%3A%22health%22+OR+dataset_title%3A%22health%22 &facet=true&facet.mincount=1 &facet.field=subject_domain_fq &facet.field=subject_geographic_area_fq &facet.field=access_restrictions_fq &fq=subject_domain_fq%3A%22Quality+of+Health+Care%22 &fq=dataset_years%3A%5B1975-01-01T00%3A00%3A00Z+TO+1984-12-29T12%3A59%3A59Z%5D &facet.range=dataset_years &f.dataset_years.facet.range.start=NOW/YEAR-40YEAR &f.dataset_years.facet.range.end=NOW/YEAR &f.dataset_years.facet.range.gap=%2b10YEAR &f.dataset_years.facet.range.hardend=true &f.dataset_years.facet.range.other=before &sort=score+desc &start=0 &rows=10 &fl=id,dataset_title,dataset_alt_title,description,subject_domain,access_restrictions,local_experts,subject_geographic_area,dataset_start_date,dataset_end_date &wt=json
Not apocalyptic, but it does take some care to dynamically produce a search URL like this that is valid every time.
Then, when the facets are returned as part of the JSON response, the facet counts (e.g. how many items the search would return if limited by that facet) are in an array separate from the rest of the results, with a flat structure that must be walked through:
["Delivery of Health Care",4,"Health Care Costs",2,"Population Characteristics",1]
We find Solr to be easy to use overall and very powerful. While there is endless customization available to advanced users, a totally stock installation of Solr after maybe five minutes of setup time is already better than any other search tool we’ve seen.
Formal Complaints
The last piece of the puzzle was the administrative interface. We’ve alluded to the form system before, and dealing with the forms was probably the most challenging part of this project. With such a complex data model to enter, as well as the different metadata elements required for internal vs. external datasets, and the management of 16 of our related entities (Publishers, Local Experts, Grants/Awards, etc.) we ran up against some limitations of Symfony’s form system but, in the end, are happy with the results.
Symfony does have a very easy option to render an entire form. Basically, you would pass a Form object to your template in your controller, and then in the template (Twig, in this case) simply write:
{{ form(form) }}
This will render the form tags, all the fields, as well as the submit button and CSRF tokens. However, this is not very useful in practice. You can’t control the order the fields appear in, there’s no control of CSS tags, and in a very long form (like ours) there’s no way to break the fields into sections to improve usability. In the end, most Symfony developers will be declaring each form field manually in a special class file, for each entity that needs a form. It is a painstaking and repetitive process that is somehow more tedious than writing the entire form in raw HTML. For instance, the configuration of one of our form fields looks like this:
$builder->add('publishers', 'entity', array(
'class' => 'AppBundle:Publisher',
'property'=> 'publisher_name',
'required' => false,
'query_builder'=> function(EntityRepository $er) {
return $er->createQueryBuilder('u')->orderBy('u.publisher_name','ASC');
},
'attr'=>array('style'=>'width:100%'),
'multiple' => true,
'by_reference'=>false,
'label' => 'Publishers',
));
That’s 12 lines to configure one form field, which is actually a pretty basic field with little customization. Much like those complicated database annotations, this markup is a little too verbose and idiosyncratic for our taste. Also, our form has 41 fields.
In the template it is much easier, and most fields can be rendered like so:
{{ form_row(form.publishers) }}
But that’s not the whole story. Imagine that you have 100 publishers in the database. To prevent spelling errors and duplicate entries, and to improve usability, it would be prudent to include autosuggest in this form field. It would also be very useful to be able to add a new Publisher record directly from the main data entry form, without having to leave the form and come back after creating that Publisher. Librarians requested both of these features, a totally reasonable request, but one which required quite a bit of work to integrate with Symfony’s form system. We found Symfony’s documentation on some aspects of its Form system to be sorely lacking.
The Select2.js library includes a number of great features to really spruce up a <select> element, including autosuggest. This part was relatively easy. The difficult part was being able to select a brand new entity that was just added to the database (using a modal box containing that entity’s form). The main entry form must be made aware of the entity that was added in the modal so it can be added to the <select> box. We ended up using HTML data-* attributes to pass the name of the entity back and forth between the main form and the modal popup. We also needed to do some string manipulation to match the type of the entity with Symfony’s generated ID tags in order to find the proper <select> box. We eventually got this all sorted out — but the form still threw errors on every attempt to submit. It turns out that Symfony uses the actual primary key value from the database as the “value” for each option in a <select> field. This means that we have to calculate the key for the newly-added entity just as the database would so we can use it as the “value” in the options list. In the end, the JavaScript needed to accomplish all that looks like this:
// on submitting the form from the modal
$('#addEntityFormModal').on('submit','form', function(e) {
e.preventDefault();
$('#loading-indicator').show();
var form = $(this);
postForm(form ,function(response) {
$('#addEntityFormModalContent').html(response);
// get the name of the Entity type (e.g. Publisher), and the name of the item that was just added
var displayName = $('#addEntityFormModalContent #entity-display-name').attr('data-displayname');
var addedEntityName = $('#addEntityFormModalContent #added-entity-name').text().trim();
// figure out the ID generated by Symfony for the relevant form element
var selectBoxId = 'select#dataset_' + displayName.replace(/ /g,'_') +'s';
// get the max value of the options, increment like the database would, add new item to end
var optionsList = $(selectBoxId + ' option').map(function() {
return $(this).attr("value");}).get();
var maxValue = Math.max.apply(Math, optionsList);
var nextOption = maxValue + 10; // if your database IDs increment by 10
$(selectBoxId).append(''+addedEntityName+'');
// get the list of already-selected items, if any, and add ours to the end
var currentVals = $(selectBoxId).val();
if (currentVals) {
currentVals[currentVals.length] = nextOption;
$(selectBoxId).val(currentVals).trigger("change");
}
else {
currentVals = [nextOption];
$(selectBoxId).val(currentVals).trigger("change");
}
});
return false;
});
The JavaScript isn’t that complicated, but due to a lack of official documentation, and a very limited number of blog posts from people who had attempted a similar thing, it took some time and frustration to arrive at a working solution. Furthermore, from a conceptual standpoint, we don’t love how tightly coupled this form is with the database, nor how much it relies on finicky string manipulation and data-* elements. However, the form works excellently now, and librarians and developers alike find it easy to use. In fact it is hard to imagine a form of this complexity being very usable at all without these features.
Despite the length of the form, we decided to keep it all on one page rather than going with a tabbed or multi-page setup. Since this form would be used both for the initial data entry and for editing metadata in existing entries, we wanted to make sure it would be easy to scan the whole form, reference other sections, and jump around as needed. These goals are very difficult to meet with a tabbed or multi-page form. For example, it’s easy to lose your place in a large multi-page form, and browsers tend not to handle the back button well when dealing with forms. Since most of the fields in a multi-page or tabbed form are hidden at any given time, it’s difficult to refer back to what you entered somewhere else. Compounding that difficulty is that it’s often not clear which fields live on which page or tab. As a result, you must click out of your current tab/page in order to search for the field on another (e.g. “Did we put the ‘Local Expert’ field on the Contact Information page, or the Access Information page?”). Our decision to individually render each form field, while tedious, allowed us to split it up into sections with plenty of white space, which we find quite manageable. Section headers are prominent, making it easy to jump to your desired field, and no more than a few fields scroll into view at a time, keeping it from overwhelming the user:
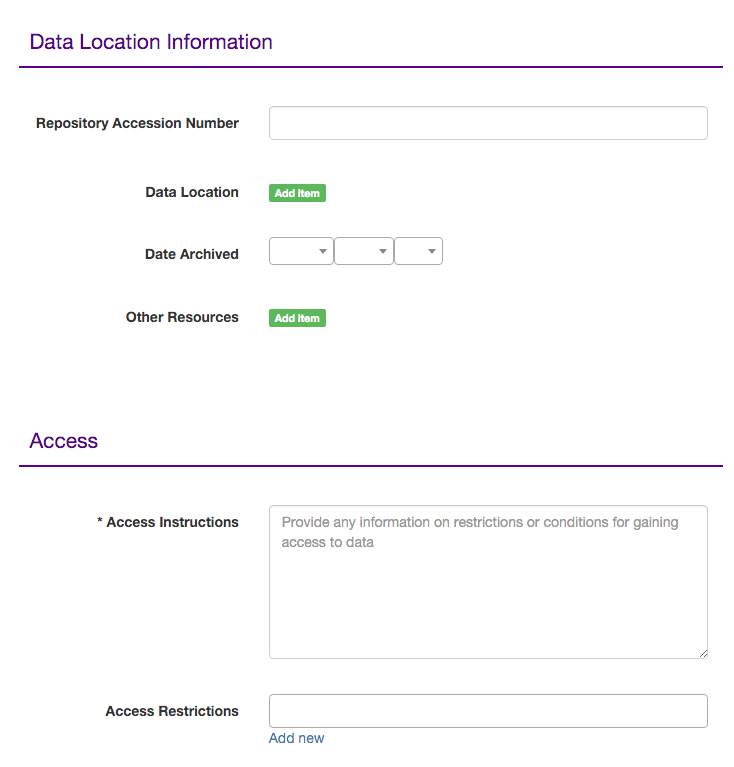
Figure 2.
Conclusion
The Data Catalog went live last year. We began collecting statistics shortly after launch, and we’ve had over 9,100 unique page views, with almost 200 users clicking through to access a dataset. We are working with the Department of Population Health and others in our institution to encourage more researchers to take this opportunity to make their data discoverable to the world and improve the quality of scientific research wherever possible.
This year, we also plan to release our source code on GitHub so that other institutions can set up a catalog of their own with much less development time. Our application provides a JSON output, as well as a Linked Open Data output in the form of JSON-LD embedded into every page, making it theoretically possible for future installations of the Catalog to link up and for it to become a kind of metasearch across institutions. Of course, this is a long way away, and we are content with the progress we have made so far. We invite you to visit our catalog at: http://datacatalog.med.nyu.edu and feel free to drop us a line with any questions or comments.
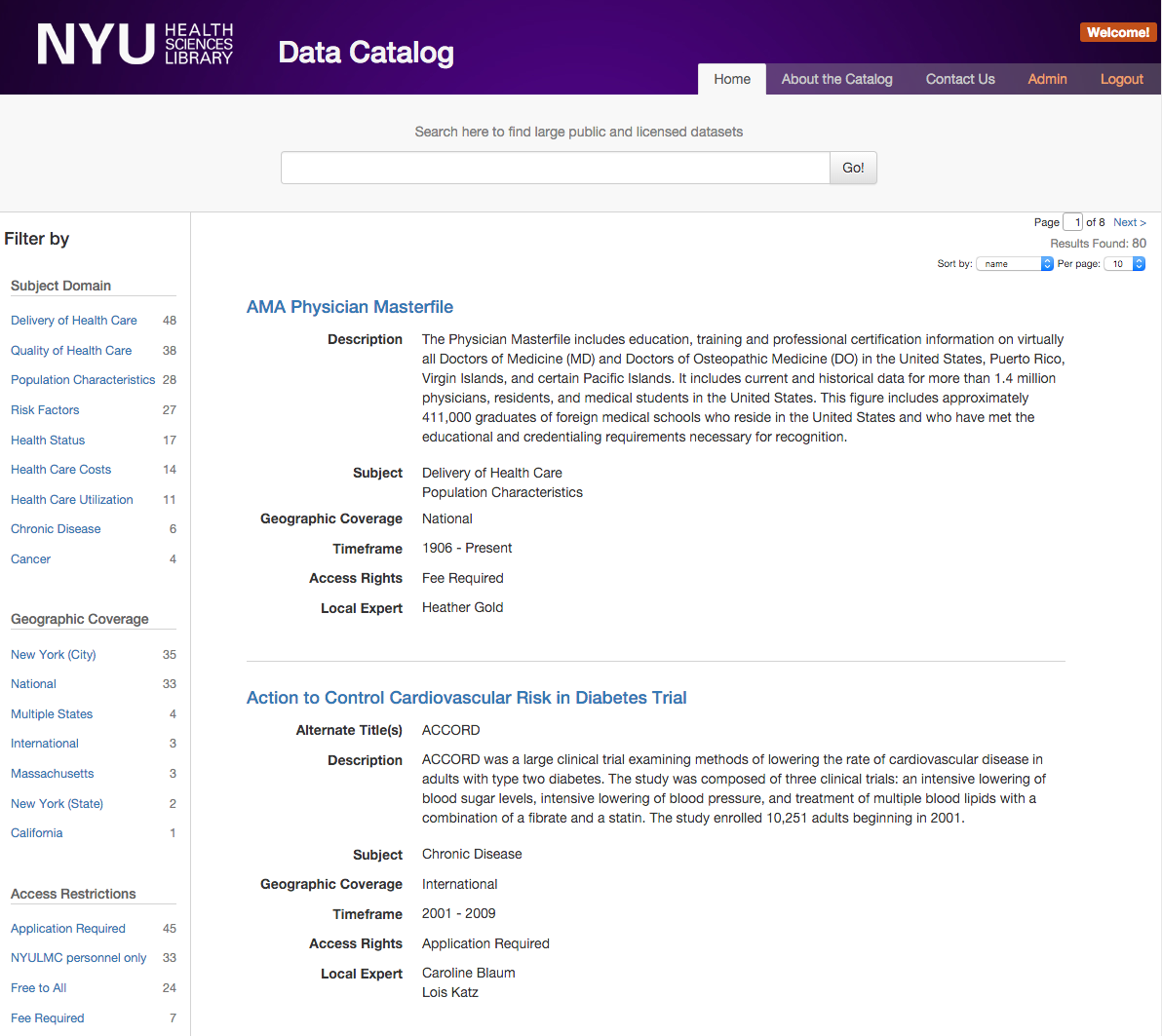
Figure 3.
References
[1] Board, F. R., Chang, A. C., & Li, P. (2015). Is Economics Research Replicable?? Sixty Published Papers from Thirteen Journals Say “ Usually Not .”
[2] Open Science Collaboration (2015). Estimating the reproducibility of psychological science. Science, 349(6251), aac4716–aac4716. http://doi.org/10.1126/science.aac4716
[3] ONE, P. (2014). Sharing of data, materials, and software. Retrieved from http://journals.plos.org/plosone/s/data-availability#loc-acceptable-data-sharing-methods
[4] Holdren, John P. (2013). Increasing Access to the Results of Federally Funded Scientific Research [Memorandum]. Washington, DC: Office of Science and Technology Policy. Retrieved from https://www.whitehouse.gov/sites/default/files/microsites/ostp/ostp_public_access_memo_2013.pdf
[5] Read, K., Athens, J., Lamb, I., Nicholson, J., Chin, S., Xu, J., … Surkis, A. (2015). Promoting Data Reuse and Collaboration at an Academic Medical Center. International Journal of Digital Curation, 10(1), 260–267. http://doi.org/10.2218/ijdc.v10i1.366
[6] Read, K. (2015). Common Metadata Elements for Cataloging Biomedical Datasets. Figshare. http://doi.org/10.6084/m9.figshare.1496573
[7] Members, W. (2015). WG3-MetadataSpecifications: NIH BD2K bioCADDIE Data Discovery Index WG3 Metadata Specification v1. Zenodo. Retrieved from https://zenodo.org/record/28019#.VsdMMPkrJhE
About the Authors
Ian Lamb (ian.lamb@med.nyu.edu) is a full-stack web developer at the New York University Health Sciences Library, part of the NYU School of Medicine. He focuses on building friendly and usable systems to advance the institution’s clinical, educational and research goals.
Catherine Larson (catherine.larson@med.nyu.edu) is the Head of the Systems & Technology department and Systems Librarian at the New York University Health Sciences Library. Her work centers on providing technical support and usability assessment for the Library’s systems with emphasis on design and user experience.

Subscribe to comments: For this article | For all articles
Leave a Reply