By Charlie Harper
Introduction
Computers may not be enjoying strawberries and cream yet (Turing 1950), but they are learning to do a lot of things once thought to be uniquely human. Tasks that were not so long ago difficult for a computer to complete accurately are now trivial. Take, for example, the recognition of handwriting. Try to think of a formal list of steps that you could give a computer in order for it to recognize handwriting. What formal steps do you follow when you read a handwritten document? How do you know that squiggle is a 3 or those two different looking scrawls are both 7s? It’s hard, if not impossible, to give a computer any formalized approach to this problem, let alone articulate how we as humans complete the process. Still, we do it seamlessly every single day because we’ve learned by seeing many examples and our brains are built to learn this ability (although, not without error, as you may find when you try to read that doctor’s prescription!). This is what lies at the heart of machine learning, too. Machine learning is not telling a computer how to, say, recognize handwriting in specific, formulaic steps; it’s programmatically building the structure necessary to learn this ability and then providing the examples from which to learn it.
The concept of machine learning (henceforward ML) has existed since the early days of computing (Turing 1950; Rosenblatt 1958; Samuel 1959). Only over the past decades, though, has the realistic application of ML been widely realized. The drastic improvements in the capabilities of machines to learn and to perform complicated tasks accurately has been due, in large part, to three accompanying changes:
- Computational power has increased dramatically, with the rise of parallel computing, powerful GPUs, and cloud computing of particular note
- The big data revolution has meant that datasets have ballooned in size and scope so that there are ample examples from which machines can learn
- Programming libraries and approaches have been developed that abstract away difficult mathematical and computational problems, and as a result, they have democratized the implementation of ML
The appearance of ML in our everyday lives (e.g. web searching, voice recognition, spam filtering, product recommendations, credit application approvals, red-light cameras, etc.) is occurring at a rapid pace, and its expansion across all aspects of human life will continue. What does this mean for the library? Well, at a most fundamental level, ML is precipitating and will continue to precipitate major and unpredictable societal changes. As centers of society and long-standing advocates of democratic principles, the opportunities and challenges arising from ML’s growth will pervade the library in every regard (Arlitsch and Newell 2017); staffing, patrons, funding, resources, and the entire community dynamic, to name a few things, will be impacted by coming technological changes. To meet these changes, we need to educate ourselves on the basic concepts that underlie ML, actively discuss the unresolved (unresolvable?) ethical dilemmas that the growing use of ML is spawning, and be aware of how ML can be and is being applied within the library itself.
What is Machine Learning?
Rather than programming a computer to follow a set of steps, ML is programming the computer to learn a set of steps based on examples or experience. When I say set of steps, what I’m properly talking about is an algorithm, or “a sequence of instructions that are carried out to transform the input to the output” (Alpaydin 2016, 16). A simple example of an algorithm is a mathematical formula, like x + y – z. Given this algorithm and a set of three numbers as input, a computer will produce a single number as output. For problems where there is a logical or mathematical solution, traditional algorithms leverage the immense power of computers to work wonders. There are many problems in life, though, where we can’t envision or create an algorithm. The example given above of recognizing handwriting is one. Still, this is a task that we’d like machines to complete and to do so with high accuracy. This is where ML comes in.
Whereas a traditional algorithm gives fixed steps to take an input and produce some output, ML uses an initial algorithm which takes examples of what we’d like it to learn as input and uses these examples to output a new algorithm that it has learned from the data (Figure 1). The process of feeding in examples to produce this learned algorithm is known as training. The learned algorithm, or what is called a model, can then be fed real world data, such as an image of a handwritten digit, as input and it will output a prediction, such as what it thinks this digit is.
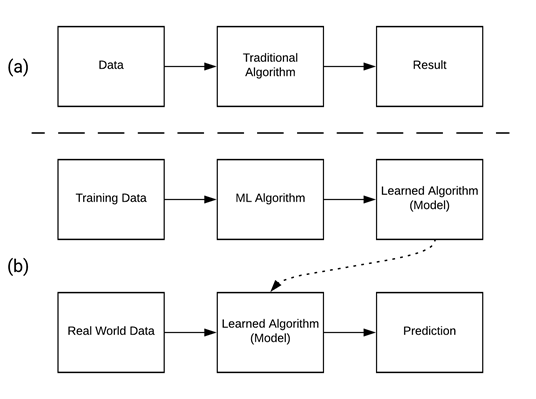
Figure 1. A traditional algorithm (a) versus a machine learning algorithm (b).
The ML algorithms used to generate models are diverse, and certain algorithms are best suited for learning from particular types of data. Without getting bogged down in the details, though, each ML approach can be broadly categorized as one of three types of learning: supervised, unsupervised, and reinforcement.
Supervised learning (Alpaydin 2016, 38-54) trains with labeled data; in other words, each point of data in the dataset is already marked with the correct answer in advance. For our handwriting example, the training data could be a set of images of individual written characters, and each image includes a label with the correct character. The supervised learning algorithm will input each image, make a prediction, and check this against the label. As a result, the training process is able to measure (i.e. supervise) how well it’s performing and it will then attempt to iteratively improve the model over time as it sees more examples.
Unsupervised learning (Alpaydin 2016, 111-118), in contrast, uses datasets that are unlabeled. In order to learn from an unlabeled dataset, the algorithm applies statistical techniques with the goal of uncovering hidden patterns within the data. A common type of unsupervised learning is clustering, in which the algorithm tries to form coherent groups from the data. Then, when real world examples are fed into the trained model, a prediction will be made based on the group(s) to which the real world example is closest. Clustering documents, such as news articles, to generate categories or topics based on statistical similarities is one practical example of unsupervised learning.
Reinforcement learning (Alpaydin 2016, 125-132) relies on feedback from actions in order to learn. In reinforcement learning, instead of being fed a dataset, an agent acts within an environment, such as a game or a physical maze. Within this environment, the agent is allowed to take different actions based on the state of environment, such as moving left or right in a maze. To learn which actions it should take over time, a reward function is used. In a game, the agent might receive a reward for scoring points or, in the case of the maze, for reaching the end. The goal is for the agent to learn a set of actions that maximizes this reward. Whereas supervised learning is compared to learning with a teacher (i.e. being told if your answer was right or wrong immediately using labeled data), this approach has been compared to learning with a critic, who only tells you whether you did well or poorly (i.e. using the reward function) after you take a series of actions (Alpaydin 2016, 127).
A deeper look at a supervised learning example will illustrate a bit more about how ML works in practice. As an example, let’s take a common problem presented to ML beginners: train a model using passenger data to predict who survived the Titanic disaster. In itself, this trained model has no real world application, but it’s easy to see how something very similar, such as a model predicting survival rates in car accidents based on driver and car characteristics, does have practical implications. The Titanic dataset (Titanic: Machine Learning from Disaster) contains 1,309 passenger records and each record has 10 attributes or features (e.g. age, sex, fare, ticket class, etc.). One of these is a binary label indicating whether the passenger survived (=1) or not (=0), so we can apply a supervised ML approach to this data.
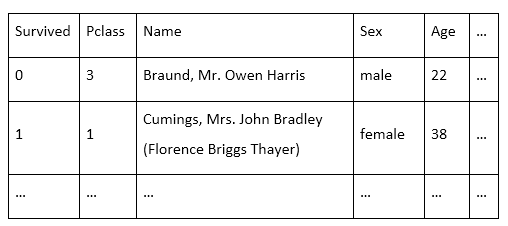
In practice, big datasets can have billions of records and thousands of features. Using all of these features would increase the computational time needed to train a model and might undermine your model’s predictive power by introducing irrelevant data. In any dataset, you need to identify only the important features relying on domain knowledge, statistical analysis, intuition, and experimentation. This process is known as feature selection. For the Titanic dataset, I know that women and children were given preference in lifeboats, so my domain knowledge tells me that sex and age are likely important features to select. On the other hand, name seems unimportant. Meanwhile, passenger class and ticket fare are probably strongly correlated. Do I need to keep both of these features? Only by training a model and verifying its accuracy will you discover whether you selected good features or not. The process of applying ML to data is truly both science and art.
It’s important to test the accuracy of your model and to avoid the problem of overfitting. If we were to feed all 1,309 passenger records into the ML algorithm, our model could reach 100% accuracy, but this is really misleading. It would have seen every example of data and therefore adjusted itself to account for all the nuances. We couldn’t then objectively test whether our model was actually good at predicting unseen data. In supervised learning, this is overcome by splitting data into a training set and a testing set (Figure 3). A general rule-of-thumb is to use a random 80/20 split of the original dataset. The training set is exclusively used to train the model. Afterwards, the testing set is fed into the trained model and its predictions are compared to the testing labels. This provides an objective measure of model accuracy and shows if your model is generalizable, or good with data it hasn’t seen before. This goal of model generalization is essential for real world ML applications. At that point, if the accuracy is insufficient, then other choices must be made with the design of the ML algorithm or feature selection, and a new model must be trained.

Figure 3. Training and Testing in Supervised Machine Learning.
Machine Learning (Ab)uses
The power of ML algorithms to learn from large datasets and then generate predictive models is exciting and frightening. It’s opening up new pathways for scientific and humanistic exploration, and raising pressing ethical questions at the same time. To address these concerns requires cross-disciplinary discussion and this naturally places the library in a key position to facilitate and enable such discussions.
The past years have witnessed a number of remarkable applications of ML. A few important examples are discussed below and their implications for ethical debates are raised. It’s worth noting that these examples are not meant to reflect the entirety of ML’s impact on society and I don’t discuss overtly positive examples, such as the great benefit ML has provided for medical diagnostic imaging; the below are examples that raise deep questions about the future role of ML in society and the examples may be unfamiliar to many. To underscore the points I’d like to draw from each, I discuss the examples under four headings: garbage in, garbage out; knowing the unknown; anonymized doesn’t mean anonymous; and redefining reality. The lines between each of these headings and the ensuing examples are fuzzy, though, and the groupings should be taken as a starting point for discussion and nothing more.
Garbage In, Garbage Out
It’s an old adage and easy to understand: inputting garbage data outputs garbage results. With ML, the problem of bad data and bad results has taken on new importance and created new difficulties because what constitutes “bad” data and results isn’t always clear or objectively definable. Data input into ML algorithms can often be bad unintentionally. This is particularly troubling when ML models are put into action before the validity of their results has been rigorously tested, and even if properly tested there’s no guarantee that models will continue to produce valid results. That is to say, ML doesn’t remove human subjectivity and error from decision making and prediction. Instead, it can actually reify human behavior in complex and unpredictable ways through the data on which a model is trained.
Image recognition technologies are a great example of how poorly selected training data can produce problematic models. In a study of IBM, Microsoft, and Face++ image gender classification products, Buolamwini and Gebru (2018) found significant discrepancies in the models’ accuracy based on race and gender. These products performed between 8.1% to 20.6% worse at assigning gender to images of women than men. For darker skinned women, the difference in error rate increased up to 34.4% when compared to images of lighter skinned males (Buolamwini and Gebru 2018, 8, 10). As a result, the authors argued that image training datasets need to include broader phenotypic and demographic representations of people (Buolamwini and Gebru 2018, 12). In other words, if your training data skews towards white males, then the accuracy of your model will also skew that way. Even if done unintentionally, poorly sampled, biased, or just plain bad training data will bake itself into your model.
On the other hand, when it comes to training with purposefully bad data, there’s no better example than chatbot Tay. In a move that can be hailed as only slightly more brilliant than the Windows Phone, Microsoft designed Tay to interact with and learn (i.e. train itself) from unfiltered tweets, including giving Tay the special ability to tag photos that were tweeted at it. Tay’s first moments of life on the internet were angelic and innocent. Within hours, however, the crush of Twitter trolls had converted poor, ignorant Tay, the ‘teenage’ AI bot, into a sexist, racist, genocidal supporter of Hitler (Vincent 2016). Microsoft quickly unplugged Tay (and as if to compound our collective heartbreak, the Windows Phone was officially euthanized only months later).
Tay is an extreme example, but bad actors can alter ML models purposefully by manipulating training data. Determining how, when, and by whom a large dataset has been manipulated for possibly ulterior motives isn’t a straightforward process. For this reason, documenting and publicizing the source of a dataset and its “chain of custody,” so to speak, are more important than ever. Someday that dataset might end up training an ML model! Simultaneously, vetting the provenience of a dataset and thoroughly understanding its composition is a must for anyone building an ML model that may end up in real world use.
Knowing the Unknown
The ability of ML to reveal hidden traits about ourselves and others is striking. From a medical perspective, revealing what we as humans cannot see provides an amazing tool for diagnosing and treating disease. Concurrently, ML’s penetrating gaze is altering the nature of privacy and diminishing our individual power to keep things about ourselves hidden from public view. It also has the potential to reveal things about ourselves that we did not know and did not want to know.
A recent study found that facial images contain much more information about sexual orientation than a human can recognize (Wang and Kosinski 2018). When given five images of an individual, an ML model was able to correctly predict sexual orientation 91% of the time for males and 83% of the time for females. With only a single image, its accuracy was still a staggering 81% for males and 71% for females. Take a moment to consider this level of accuracy and just how easy it is to acquire a mere five images of someone. What else might be accurately predictable from data that was once thought benign? How will such predictive power be deployed in good and bad ways?
Another major group of ML models being used to reveal the unknown are found in criminal risk-assessment tools. One such tool is COMPAS (Correctional Offender Management Profiling for Alternative Sanctions), a product of a corporation called Northpointe. The tool uses a model trained to predict recidivism. A ProPublica study showed that the assessment tool predicts recidivism correctly 61% of the time (an accuracy which already strikes me as particularly heinous given its use), but when broken down by race, black defendants are twice as likely as white defendants to be labeled as at a high risk for recidivism, but not actually re-offend (Angwin et al. 2016). These predictions by COMPAS are especially consequential because they’re used by judges during criminal sentencing. As of 2016, ProPublica noted that the results of these risk-assessments were given to judges in Arizona, Colorado, Delaware, Kentucky, Louisiana, Oklahoma, Virginia, Washington, and Wisconsin when they considered how to sentence a defendant (Angwin et al. 2016).
Meanwhile, the Durham (UK) police have been using HART (Harm Assessment Risk Tool) to predict a suspect’s risk of committing a crime in the next two years (Burgess 2018, Oswald et al. 2018). HART utilizes a number of categories, including age and gender, to rank an individual as at low, moderate, or high risk of reoffending. HART also originally utilized postcode information, a spatial variable that risked creating a feedback loop in which police target certain areas for more scrutiny and therefore generate more arrests in those areas. The higher volume of arrests in these postcodes then feedbacks into the model and iteratively draws further police scrutiny (Oswald et al. 2018, 228-229). In a positive example of external pressure, the publicization of this feedback danger has led the Durham police to remove the postcode variable from HART (Burgess 2018). Another notable feature of HART, which is in tandem with the prediction of sexual orientation from facial features, is that there’s a significant discrepancy between what HART predicts and what a human predicts (Burgess 2018).
In the case of both COMPAS and HART, decisions that significantly impact the lives of individuals are being guided by ML models. This raises serious questions not only about the data with which these models are being trained, but about the role of predictive technologies in criminal justice. Models generated by ML algorithms are opaque to human scrutiny; the whole point of ML is that humans can’t formulate algorithmic steps to make these predictions, so instead the ML algorithms generate complex models to make predictions. As a result, it’s very difficult to know how the model is working internally. Models are tested for accuracy after training, but this procedure is again limited by the dataset available to you and it’s directly impacted by the choices you’ve made in feature selection, such as choosing sex or postcode as features.
To what extent should technologies that cannot be easily scrutinized by defendants, especially when the technologies are proprietary, be drawn into criminal justice? ProPublica cites at least one objectionable example of COMPAS’ current impact: an already agreed upon plea deal between defendant and prosecutor was explicitly rejected by a judge as a result of the defendant’s high-risk score produced by COMPAS (Burgess 2018). The judge then sentenced the defendant to two years in state prison rather than the agreed upon one year in county jail.
Anonymized Doesn’t Mean Anonymous
Large datasets are at the heart of ML and modern analytics. To protect individuals’ privacy on matters such as health, criminal victimization, or academic performance, datasets are traditionally anonymized before analysis, but anonymous and private have never been the same thing. Can you guess where I’m going with this? Now, in the era of big data and ML, anonymized and anonymity are no longer the same thing either as it’s increasingly possible to re-identify supposedly anonymous data.
Textually, this has manifested in the field of stylometry, which statistically analyzes characteristics of writers’ language. In the digital humanities, stylometry appears extensively for literary studies, but its applications are wider ranging. For example, it can also be used to deanonymize article submissions. Payer et al. (2015) found that once an author had published at least three articles, it was possible to begin attributing anonymous submissions to that author. Like all ML approaches, this type of deanonymization relies on existing data, but as individuals post written content to social media, they’re also unwittingly building a dataset that ML algorithms can consume for future textual analysis. Meanwhile, social networks themselves can be de-anonymized (Ma et al. 2017). What impact will this power of deanonymization have on the future of free and open discussion (what if you couldn’t check out books anonymously)?
Another example of deanonymization that is frighteningly futuristic mixes ML and genomic data. The danger and ability to identify individuals by name from anonymized genomic data without the use of ML has already existed for a number of years (Sweeney, Abu, and Winn 2013). Using ML techniques, genomic re-identification has reached a new, inconceivable level. Instead of compiling disparate datasets to assign names to genomic samples, genomic samples alone are now providing identifying information. With a trained ML model, Lippert et al. (2017) recreated the faces of individuals from their genomic sequences. The recreations are not perfect, but they are striking in their similarity (Figure 4). What does it mean that you may be leaving your name or even an image of your face everytime you leave behind DNA? Obviously, this could have great impact on criminal forensics, but it’s a slippery slope. If this and similar technologies become readily available, how else might they be deployed and what limits can/should we place on their use?

Figure 4. Actual faces, left, and ML facial reconstructions from genomic data, right (Lippert et al. 2017, fig. 2)
Redefining Reality
Perhaps the most awesome power of ML that has emerged recently is its ability to alter and create media that challenges our sense of reality. This ability has been driven by the invention of Generative Adversarial Networks (GANs). GANs work by harnessing the power of two neural networks, which compete against each other. One network generates (hence generative) something, such as a fake image. The other network fights (hence adversarial) to separate out the faked content from real content. As each network improves, their pairing drives the generative network to create progressively better content in order to better fool the other neural network. The result is an internal arms race. These powerful GANs have created some shockingly realistic content, including astonishing images of fake celebrities (Figure 5; Karras et al. 2018; Metz and Collins 2018) and art in various styles (Elgammal, Liu, Elhoseiny, and Mazzone 2017).

Figure 5. Images of fake celebrities generated by a GAN (Karras et al. 2018, fig. 10)
Deepfakes (Wikipedia: Deepfakes, 2018) and similar spin-offs, though, have been the most extreme example of GANs. They have also been called, “one of the cruelest, most invasive forms of identity theft invented in the internet era” (Foer 2018). Not limited to still images, Deepfakes creates realistic videos of existing individuals. In April 2018, Buzzfeed and comedian Jordan Peele released a “real fake” PSA video of Obama, who gave his opinion of Donald Trump and warned of the dangers of fake news. The technology has also notoriously been used to transfer the faces of celebrities, such as Emma Watson, Taylor Swift, and Emilia Clarke, into pornography (Dold 2018; Lee 2018). Right now this technology is mostly limited to celebrities because of the number of images required for it to work well in video, but this is not true for all GANs (and it won’t be true of Deepfakes forever).
Lyrebird (https://lyrebird.ai/) provides a similar functionality for audio. It claims that with only a single minute of recorded audio, it can create a voice that sounds like anyone (Mark 2018). Like the five images required to accurately predict sexual orientation, one minute of recorded audio isn’t much. In light of such powerful GANs, existing discussions of “fake news” are quaint. What happens when the news really is fake in the truest sense of the word? As it stands, ML means that our images, voices, and mannerism are copyable and mimicable. This presents the very real possibility for a loss of ownership of our own identities and it eviscerates existing notions of reality by undermining what our eyes and ears tell us is “real.” The dystopian possibilites are palpable.
The Role of the Library
There are many benefits arising from ML, but also great potential for unintended consequences and outright wrongdoing. Recognizing our own ignorance of ML’s future developments and impacts, and avoiding the all-to-common fallacy that computer results are tantamount to an absolute truth is fundamental. The library needs to participate in shaping this future, and there are particular areas of focus that it should consider.
Offering guidance on information literacy, data documentation, and source vetting all fall within the traditional realm of a library’s activities. These issues are exceedingly more important than in the past and are becoming increasingly complicated. Traditional models of instruction and collaboration on these topics need continuous improvement to match the changing times; they also require the activate role of technically-minded individuals whose education falls outside the scope of traditional LIS degrees. The privacy (or really lack thereof) and ethics of data collection and dissemination should become an integral part of information literacy services. Now that images, video, and audio can be faked in staggering ways, the reality of source origin is becoming increasingly messy, too. Facilitating and promoting critical thinking and awareness within the community is a must.
Since ML is a cross-disciplinary and cutting-edge field, libraries should act to bring together diverse groups for ongoing discussions that focus on ethical guidelines and the societal implications of ML. Humanists, scientists, community members, and elected officials each have differing stakes in the outcomes of ML and the library can provide the forum and guidance necessary to mediate their views in a meaningful way. One particular point of exploration should be the increasing primacy of metrics that reduces human complexity to a mathematical exercise. The same metrical slant that has led to the creation of dubious predictors of recidivism is spreading, and its growth is particularly clear across all levels of academia and education. Assessments and rankings that are easily measurable have become the norm (Muller 2018, 65-101). In higher education, libraries are particularly in danger of being overly drawn into this academic ranking mania.
Because of its centrality to education, there are many calls to begin aggregating library data with larger university data in order to effectively create university-wide data centers. Matthews (2012) pointed out that despite anecdotal and gate count evidence, almost all academic libraries really have no idea of who is actually using the library and for what purposes. He argued that, as a result, the library should look beyond its own data and examine the larger picture of university outcomes by aggregating internal data with university-wide data in an accessible data warehouse. Equally, Matthews argued that a large amount of data should be collected within the library for the purpose of assessment and demonstrating library value to the university. This intensive collection and aggregation scheme would be “the enabling tool that will allow a library to prepare credible analysis of the library’s impact in the lives of its students, faculty, and researchers” (Matthews 2012, 400). Renaud et al. (2015) implemented such a system in limited form by aggregating data sets to measure the correlation of GPA and library use. Again, the argument was made that this was a good way to show library impact on university wide goals. In light of growing datasets, such library records are just now starting to be subjected to ML. For example, Litsey and Mauldin (2017) generated ML predictions of ILL usage and dreamed of an eventual system that would “[monitor] all library transactions from circulation, the holdings, the ILL transactions, the reserves items and even the e- journals” (Litsey and Mauldin 2017, 143).
The growing collection of library data, aggregation with university-wide data, and nascent application of ML to these dataset are all done with good intentions, but they are extremely precarious. As we know apparently anonymized datasets are not necessarily private, and as data is united in more complex ways it becomes increasingly more powerful. The same mentality of assigning a recidivism score during a criminal sentencing is easily extended to assigning a “success” score to individual students. This possibility may be too attractive for administrators to resist, and libraries should by all means responsibly analyze their own data, but the walls of the library shouldn’t be breached, and collection management shouldn’t be solely driven by machine predictions.
An additional point to make is that every single dataset has the potential to become a source for predictive ML models. Seemingly benign library data can equally reveal amazing and unexpected things about people. Libraries are now acting as massive stores of data, including personal information, borrowing histories, reference questions, entrance/exit data, security surveillance records, program and meeting attendance, room rentals, and web surfing habits. This data is so extensive it can even be considered “big data” (Berman 2018). Concurrently, there’s the growing problem of 3rd parties who offer access to e-resources, and collect and retain information on patrons (Rubel 2014). These 3rd parties aren’t necessarily held to the same standards of privacy as libraries and librarians must carefully review their policies and advocate against 3rd party data collection. Fister raised an excellent question when she asked, “Do the new capabilities of data mining offer libraries valuable opportunities to peer into individual students’ experiences to improve learning and demonstrate value – or does it pose a significant challenge to one of librarians’ most revered values, patron privacy?” (Fister 2015). Although the two terms have overlap, we could easily replace the words ‘data mining’ with ‘machine learning’ and ask the same question. The problems of privacy, intellectual freedom, and censorship that arise from big data and ML, including the emerging conflicts with traditional library ethics and values, are just beginning to be addressed (Jones and Salo 2018).
Ultimately, libraries need to be attentive to these fast-paced socio-technical changes and to keep a taut finger on the mechanical pulse of machine learning. I’ll readily admit that I don’t know where this is all going, but I know that we’re all going along for the ride willingly or not, and the library must do so with a watchful eye.
References
Alpaydin E. 2016. Machine Learning: The New AI. Cambridge (MA): MIT Press.
Angwin J, Larson J, Mattu S, Kirchner L. 2016. Machine Bias. ProPublica [Internet]. [cited 6 June 2018] Available from: https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
Arlitsch K, Newell B. 2017. Thriving in the Age of Accelerations: A Brief Look at the Societal Effects of Artificial Intelligence and the Opportunities for Libraries. Journal of Library Administration 57:789-798.
Berman, E. 2018. Big Brother is Watching You: The Ethical Role of Libraries and Big Data [Internet]. [cited 13 July 2018] Available from: https://chooseprivacyeveryday.org/the-ethical-role-of-libraries-and-big-data/
Buolamwini J, Gebru T. 2018. Gender Shades: Intersection Accuracy Disparities in Commercial gender Classification. Proceedings of Machine Learning Research 81:1-15.
Burgess M. 2018. UK Police are Using AI to Inform Custodial Decisions–But It Could Be Discriminating Against the Poor. Wired [Internet]. [cited 7 June 2018] Available from: http://www.wired.co.uk/article/police-ai-uk-durham-hart-checkpoint-algorithm-edit
Dold, C. 2018. Face-Swapping Porn: How a Creepy Internet Trend Could Threaten Democracy. Rolling Stone [Internet]. [cited 10 June 2018] Available from: https://www.rollingstone.com/culture/features/face-swapping-porn-how-creepy-trend-could-threaten-democracy-w518929
Elgammal A, Liu B, Elhoseiny M, Mazzone M. 2017. CAN: Creative Adversarial Networks Generating “Art” by Learning About Styles and Deviating from Style Norms [Internet]. [cited 10 June 2018] Available from: https://arxiv.org/abs/1706.07068
Fister B. Big Data or Big Brother? Data, Ethics, and Academic Libraries [Internet]. [cited 12 July 2018] Available from: https://barbarafister.net/LIbigdata.pdf
Foer F. 2018. The Era of Fake Video Begins. The Atlantic [Internet]. [cited 7 June 2018] Available from: https://www.theatlantic.com/magazine/archive/2018/05/realitys-end/556877/
Jones KML, Salo D. 2018. Learning Analytics and the Academic Library: Professional Ethics Commitments at a Crossroads. College & Research Libraries 79(3):304-323.
Karras T, Aila T, Laine S, Lehtinen J. 2018. Progressive Growing of GANs for Improved Quality, Stability, and Variation. ICRL 2018 [Internet]. [cited 11 June 2018] Available from: http://research.nvidia.com/sites/default/files/pubs/2017-10_Progressive-Growing-of/karras2018iclr-paper.pdf
Lee D. 2018. Deepfakes Porn Has Serious Consequences [Internet]. [cited 10 June 2018] Available from: https://www.bbc.com/news/technology-42912529
Lippert C, Sabatini R, Maher MC, Kang EY, Lee S, Arikan O, Harley A, Bernal A, Garst P, Lavrenk V, et al. 2017. Identification of Individuals by Trait Prediction Using Whole-Genome Sequencing Data. PNAS [Internet]. [cited 10 June 2018] Available from: https://doi.org/10.1073/pnas.1711125114
Litsey R, Mauldin W. 2017. Knowing What the Patron Wants: Using Predictive Analytics to Transform Library Decision Making. Journal of Academic Librarianship 44:140-144.
Ma J, Giao Y, Hu G, Huang Y, Sangaiah AK, Zhang C, Wang Y, Zhang R. 2017. De-Anonymizing Social Networks with Random Forest Classifier. IEEE Access 6: 10139-10150.
Mark T. 2018. Can You Believe Your Own Ears? With New ‘Fake News’ Tech, Not Necessarily. NPR [Internet]. [cited 10 June 2018] Available from: https://www.npr.org/2018/04/04/599126774/can-you-believe-your-own-ears-with-new-fake-news-tech-not-necessarily
Marsland S. 2015. Machine Learning, 2nd ed. Boca Raton (FL): CRC Press.
Matthews JR. 2012. Assessing Library Contributions to University Outcomes: The Need for Individual Student Level Data. Library Management 33(6/7):389-402.
Metz C, Collins K. How an A.I. 2018. ‘Cat-and-Mouse Game’ Generates Believable Fake Photos. New York Times, 2 January 2018 [Internet]. [cited 10 June 2018] Available from: https://www.nytimes.com/interactive/2018/01/02/technology/ai-generated-photos.html
Muller, JZ. 2018. The Tyranny of Metrics. Princeton (NJ): Princeton University Press.
Oswald M, Grace J, Urwin S, Barnes GC. 2018. Algorithmic Risk Assessment Policing Models: Lesson from the Durham HART Model and ‘Experimental’ Proportionality. Information & Communications Technology Law 27(2):223-250.
Payer M, Huang L, Gong NZ, Borgolte N, Frank M. 2015. What You Submit Is Who You Are: A Multimodal Approach for Deanonymizing Scientific Publications. IEE Transactions on Information Forensics and Security 10(1):200-212.
Renaud J, Britton S, Wang D, Ogihara M. 2015. Mining Library and University Data to Understand Library Use Patterns. The Electronic Library 33(3):355-372.
Rosenblatt F. 1958. The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychology Review 65(6):386-408.
Rubel, A. 2014. Libraries, Electronic Resources, and Privacy: The Case for Positive Intellectual Freedom. The Library Quarterly: Information, Community, Policy 84(2):183-208.
Rubel A. 2014. Libraries, Electronic Resources, and Privacy: The Case for Positive Intellectual Freedom. The Library Quarterly 84(2):183-208.
Samuel AL. 1959. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development 3(3):210-229.
Sweeney L, Abu A, Winn J. 2013. Identifying Participants in the Personal Genome Project by Name (A Re-identification Experiment). Data Privacy Lab [Internet]. [cited 11 June 2018] Available from: https://privacytools.seas.harvard.edu/publications/identifying-participants-personal-genome-project-name
Titanic: Machine Learning from Disaster [Internet]. 2018. Kaggle. Available from: https://www.kaggle.com/c/titanic.
Turing AM. 1950. Computing Machinery and Intelligence. Mind LIX(236):433-460.
Vincent J. 2016. Twitter Taught Microsoft’s AI Chatbot to Be a Racist Asshole in Less than a Day. The Verge [Internet]. [cited 6 June 2018] Available from: https://www.theverge.com/2016/3/24/11297050/tay-microsoft-chatbot-racist
Wang Y, Kosinski M. 2018. Deep Neural Networks Are More Accurate Than Humans at Detecting Sexual Orientation from Facial Images. Journal of Personality and Social Psychology 114(2):246-257.
Wikipedia, The Free Encyclopedia, s.v. “Deepfake,” (accessed August 6, 2018), https://en.wikipedia.org/wiki/Deepfake
About the Author(s):
Charlie Harper is the Digital Scholarship Librarian at Case Western Reserve University, where he collaborates on and manages a variety of digital projects. Much of his work currently centers on the interdisciplinary applications of machine learning, text analysis, and GIS.

Subscribe to comments: For this article | For all articles
Leave a Reply