By Patrick Harrington
Introduction
As librarians at James Madison University pointed out when describing their library’s process of building a streaming video collection, “streaming media” is similar to other electronic formats (e.g., e-journals and e-books) in that it “requires a substantial number of additional steps to acquire and manage than tangible formats” [1]. While libraries can choose to host streaming content on their own servers, vendors providing streaming video content also make their content available through streaming video sites that the vendors host themselves. This reduces the cost of maintenance and storage for the libraries but libraries still have to give users the means of accessing the video content.
Libraries create metadata for video contents in a variety of ways depending on their library systems and the resources at their disposal. One common method involves adding bibliographic records, typically provided by the vendor, to their catalog so that users can find them in the online public access catalog (OPAC). In recent years libraries have made use of discovery services such as Primo that enable users to perform keyword searches of the OPAC, article databases, and streaming video simultaneously. In some cases, libraries can provide access to electronic resources without adding records because their discovery service can index the collection and retrieve results through access points maintained by the vendor. They can also develop a dedicated portal for accessing streaming videos.
Whether a library chooses to provide access through the OPAC or through a separate system for streaming video (or through a combination of the two), it is likely that the library will utilize MARC records at some point in its workflow. MARC records are the primary format for organizing information about library resources regardless whether those records are created through original or copy cataloging done by the library or provided by library vendors.
The MARC standard allows for the storage of a large amount of detailed information about a resource but can be intimidating to work with, especially for non-catalogers. Dublin Core was developed to describe a variety of resource types online. In their book Creating a Streaming Video Collection for Your Library, Duncan and Peterson maintain that “by using Dublin Core as its base schema, a system ensures interoperability, flexibility, simplicity, and consistency” and reduces the workload of trained catalogers since creating Dublin Core records is “easy for staff to learn and implement and quick to create.” [2]
Dublin Core is not without drawbacks. One significant disadvantage is the lack of granularity compared to MARC. This means that Dublin Core records often do not “provide enough information about complex resources with issues such as copyright or access information” [2]. While most vendors of streaming video for libraries primarily offer metadata in MARC format, cultural heritage institutions often utilize versions of Dublin Core when creating applications for the web. A 2009 paper from the International Conference on Dublin Core and Metadata Applications describes the relationship between Dublin Core and access to streaming video resources for the European digital library Europeana: “the widely adopted Dublin Core metadata element set have provided archives with the tools necessary to build meaningful services that provide unified access to archive videos online” [3]. In building the tool discussed in their paper, the creators of Video Active utilize a semi-automatic process whereby participating archives create a mapping of their own metadata to the Dublin Core elements [3].
Oomen et al. converted the XML files into RDF triples in order to allow for more sophisticated querying. While the Dublin Core metadata standard dictates what kind of information should be stored about a particular resource, RDF allows for machines to interpret logical relationships between pieces of information in order to provide more sophisticated querying. Oomen et al. provide an example of the kind of querying that is possible using this technology. In their example, they suggest a user query looking for items dealing with Germany:
This query is formulated in SeRQL “bring me items that has ‘geographical coverage’ the term ‘Germany’ and also bring me items of the narrow terms of ‘Germany.'” The field ‘geographical coverage’ gets values form[sic] the Video Active thesaurus. In this way, instead of getting only the items that have been explicitly defined that have geographical coverage the term ‘germany,’ we also retrieve the items from all the narrow terms of Germany (i.e. Hamburg, Thuerlinger, Saxony etc.) [3].
This kind of intelligent querying represents the promise of semantic web technology. While wider implementation of the semantic web points to more robust access systems than current methods, finding a way to enrich and utilize vendor-supplied metadata for keyword searching offers a way of enhancing access to this material in the near term.
Creating the Site
Polk Library currently sources its streaming videos from three vendors. In 2016, library staff developed a separate website that would allow users to browse all the streaming videos available from the three different vendors and view thumbnails of videos as well as create personalized lists for future viewing. The streaming video site originally contained only a curated set of videos on topics which were thought to be of interest to students and faculty. The site was re-launched in 2017 with the aim of including all streaming videos available to library patrons. The relaunched site would also allow site administrators to create customized topical collections in response to current events or at the request of faculty and staff on campus by grouping together all videos with particular subject headings, geography terms, individuals, or series names as opposed to individually adding each title, as was the case with the previous version. A screenshot of the streaming video site is shown below:
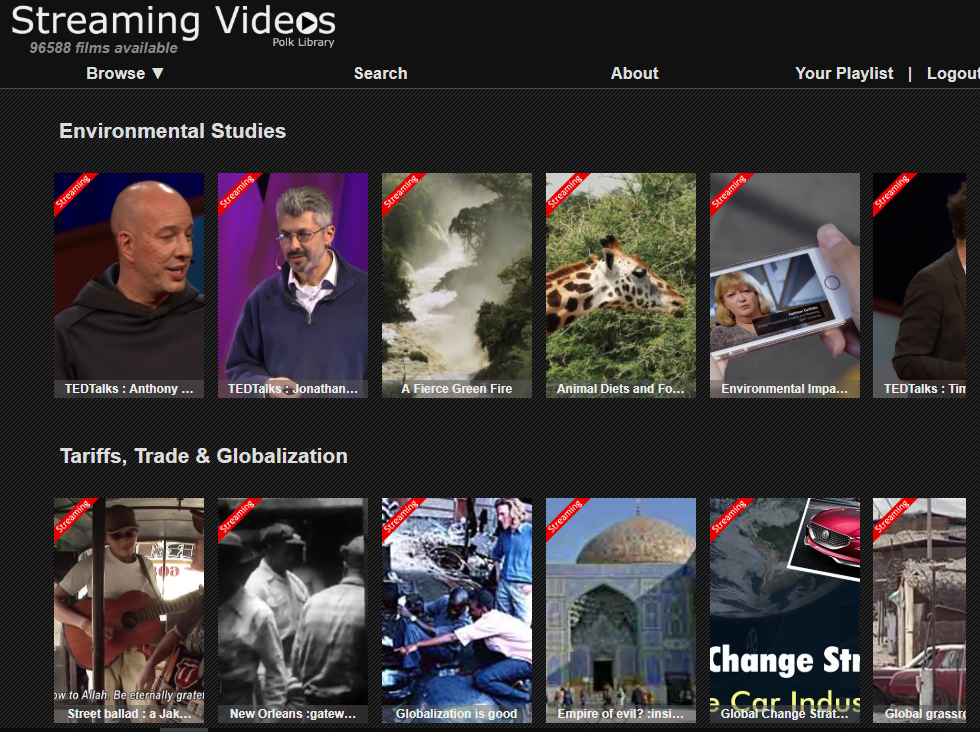 Figure 1. A screengrab from the streaming video site at Polk Library.
Figure 1. A screengrab from the streaming video site at Polk Library.
The site runs on the content management system Plone and is updated based on the addition of new titles or the release of new MARC records from vendors. When library staff are notified that new records or titles are available, the MARC records are downloaded and then a Python script extracts information from specified MARC fields to produce a comma-separated value (CSV) file which is then uploaded to the site. Once a server-side script captures a thumbnail for each video, it is made available to end users. Code for the streaming video site itself can be found here: https://github.com/polklibrary/polklibrary.content.viewer/tree/master/polklibrary.content.viewer.
This project had two main goals. One was to increase the visibility of this part of the library’s collection and give patrons a new way to explore the streaming videos available. The other more technically-specific goal was to integrate videos from three different vendors into one system so that videos about similar topics or geographical areas could be grouped into collections regardless of which vendor provided them. Enabling this kind of cross-vendor browsing required substantial cleanup and enrichment discussed in further detail in the following section.
Creating Metadata for the Streaming Video Site
Because the MARC standard was developed for use in library catalogs, the data had to be transformed to be effective for retrieval in the site itself. The Dublin Core Metadata Element Set provided the basis for the fields which would ultimately appear in the site. Not all elements from this set were used in the final crosswalk, such as the relation, language, and publisher elements. These were excluded because they were deemed not relevant to user interests or access compared to elements like description, title, contributor, and subject.
While transforming MARC records into Dublin Core records is a familiar task in libraries, differences in the extent and quality of the cataloging done across the various vendors meant that additional cleanup and enrichment was needed before the records could be added to the site if all the goals of the project were to be achieved. The figure below shows the subject heading fields provided by two different vendors for the same video, in this case a television documentary called “A Blooming Business.”
 Figure 2. Subject heading for “A Blooming Business” provided by two different vendors.
Figure 2. Subject heading for “A Blooming Business” provided by two different vendors.
While the genre term “Documentary films” and the “Human rights” heading appear in both records, one vendor applied geographic subdivisions in subfield z while the other vendor did not. Additionally, one vendor seemed to emphasize the specific industry discussed in the documentary, in this case cut flowers, while the other focused on geopolitical issues like globalization. These differences are to be expected considering two catalogers will not always catalog the same thing in the same way, but some reclamation and enhancement is necessary if users are to use subject terms to find resources similar to ones they have already found without having to account for cataloging differences across vendors.
The Python library PyMARC is used to read in the vendor-supplied MARC file, extract the relevant fields, and output a CSV file suitable for upload to the streaming video site. A table showing the fields used in the streaming video site at Polk Library along with the corresponding MARC field (or fields) from which the fields are populated can be found below.
Table 1. Fields in Streaming Video site along with their source MARC field.
| Streaming Video Site Field | MARC Field(s) |
| filmID | 001 |
| Creator | 100 |
| Title | 245 |
| Date | 260 subfield c |
| Runtime | 300 |
| Series | 490 |
| Summary | 520 |
| Associated Entities | 600,610,700 |
| Geographical Terms | 651 subfield a,650 subfield z |
| Subjects | 650 |
| Genre | 655 |
| URL | 856 subfield u |
Initially the subject terms were consolidated into a list of shared terms which were then applied to any video which contained them in its title, summary or subject headings. This process was an attempt to simplify the process of making collections by reducing the number of possible subject terms in the site and minimize the effort needed to create collections on a particular topic that could overcome the discrepancies in cataloging between the three streaming video vendors at Polk Library. However, this workflow was abandoned because the resulting set of possible subject terms was too narrow to be useful when building collections on the site. Instead, all subject terms in the MARC record are now included on the streaming video site.
While most videos had at least one subject heading in the MARC record, other topical information, such as particular geographical areas covered in a video, was considered useful for users of the site but not always present in the vendor-supplied metadata. Obtaining this information was of interest particularly for collection building, as it would allow administrators to create collections for particular geographical areas or to limit topical collections to videos about that area (e.g., politics in Russia or government in the United Kingdom).
This was the most challenging aspect of the metadata creation and cleanup process. Since the initial upload consisted of around 65,000 records and new videos are added regularly, a programmatic means of identifying geographic terms was the only viable option. While most of the videos had subject terms in the 650 field, the 651 field, which is meant for geographic information, was rarely used by any of the three vendors.
In order to generate this geographical information, a number of methods, including a few Python libraries as well as parsing of existing subject headings, were used to try and generate geographic terms for the streaming videos. All three methods generated geographic terms for at least some streaming videos, but each method approached the problem in a different way. In one method, the Natural Language Toolkit (NLTK), a natural language processing library, was used to parse descriptions of videos in order to identify geographical place names based on sentence structure. Another method relied on regular expressions to identify place names in text. The third and final method explored in this paper leverages the structure of Library of Congress subject headings so that geographic subdivisions in subject headings are used to populate a standalone metadata field in the final site. Each of these methods will be discussed in more detail, followed by the results of a systematic comparison of each method.
Generating Geographic Terms with the NLTK
According to its developers, the NLTK is “a leading platform for building Python programs to work with human language data,” supporting a number of natural language processing tasks including named entity recognition [4]. Named entity recognition is a subset of natural language processing that grew out of the realization that “it is essential to recognize information units like names, including person, organization, and location names” [5]. One well-known classifier for named entity recognition is the Stanford Named Entity Recognizer (NER), which analyzes text with the purpose of identifying persons, organizations, and locations within that text [4]. Together the NLTK and Stanford NER rely on heuristic modeling to capture the structure of a sentence by identifying various parts of the sentence, including but not limited to named entities. Depending on the size and complexity of the sentences, this can be a very computationally intensive process.
One reason this approach may be preferable is that it does not require an exhaustive list of all potential locations in order to search for locations in a string of text. Because of this feature, it was thought that using the NLTK and Stanford NER would be an adequate, if time-consuming, solution to the problem of generating geographic tags for each video.
In order to use the NLTK and Stanford NER, a Python script takes a set of records and then parses the summary of each video. While the Stanford NER attempted to extract all named entities, only terms identified as locations were used to populate the geographic field for each video. By design, the NER identifies more than just geographical terms, so the Python script would first have the NER analyze the full summary and then look for all the terms tagged as being locations so that they could be added as geographic terms for that particular video.
Below is a snippet showing how the NLTK was used to identify the geographic terms within the summary of each film:
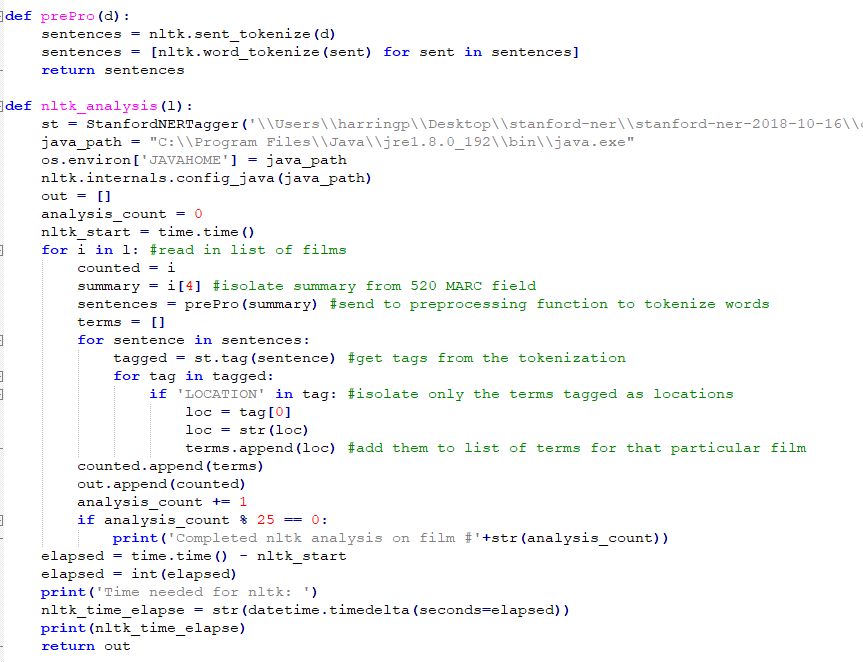 Figure 3. Code snippet showing implementation of NLTK.
Figure 3. Code snippet showing implementation of NLTK.
Generating Geographic Tags with Regular Expressions
In contrast to the NLTK/NER method, the Python library GeoText relies on regular expressions to search for references to geographic locations based on comparing input text to a predefined list of geographic locations which are built into the library [6]. Regular expressions consist of query sequences which are used to identify particular characters within a chunk of text. While the NLTK is concerned with parsing sentences based on modeling their linguistic structure, regular expressions ignore grammatical context and instead focus on matching a specific character sequence.
Below is a snippet of code showing how the GeoText library was used to identify the geographic terms for each film:
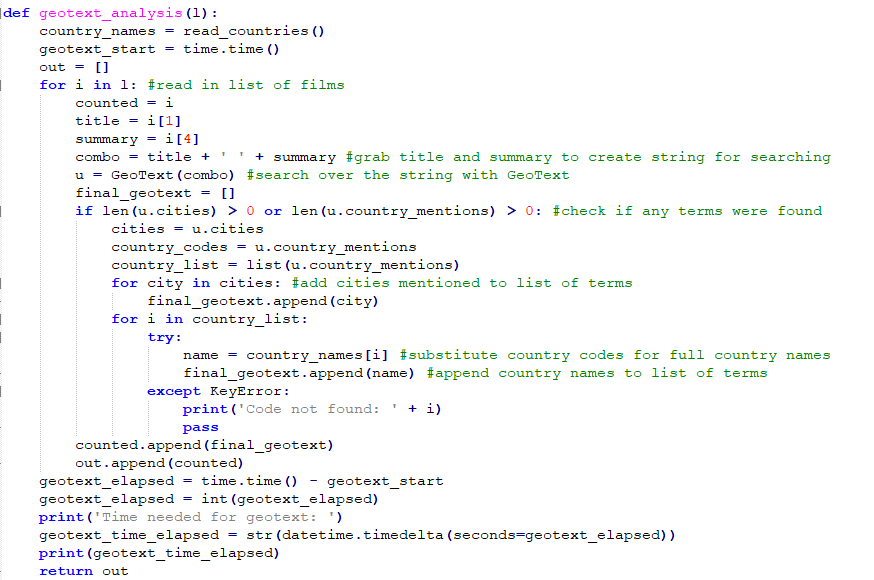 Figure 4. Code snippet showing GeoText implementation.
Figure 4. Code snippet showing GeoText implementation.
One significant benefit of the regular expression approach compared to the NLTK is that regular expressions are much faster. However, this speed comes at a price, as it simply looks for matches without taking into account the structure of the sentence or the context in which a particular term is used. The GeoText library presented some unique challenges because there were a number of very common English words or proper nouns that the library identified as geographic locations (e.g. “Along”, “Police”, “University”). For example, without cleanup, video titles or descriptions which included the word “along” would appear to users as having to do with the city in India, thus undoing much of the benefit of this metadata enrichment. Because the library is able to identify so many geographic terms, it was only by manually evaluating the results on large files that all these potentially erroneous terms could be identified and removed. For this project, a file consisting of 264 common English words and proper names which were identified as locations by GeoText were removed if detected, though they were preserved for the purposes of testing in the trials outlined below.
At times, the GeoText library correctly identifies a place but can generate false positives by associating a city name with a different country than one might expect. For example, the script will correctly identify the string “Barcelona” as a place name, but when both country code and city name are included in the geographic field it becomes clear that the library has identified the city of Barcelona, Venezuela even though most appearances of the city name were in reference to the Spanish city, not the Venezuelan. By removing the country but keeping the city name, these can be disambiguated at least in practice, but manual evaluation is needed in order to perform this cleanup if site administrators want to make a collection about Venezuela.
In addition to removing terms which were homographs of locations according to GeoText, the library generates two letter country codes when either the name of a country is detected or the name of a city within that country is detected. Thus, a separate function in the Python script would swap the two letter country code for the full name of the country using a dictionary. This also speaks to another limitation of the method: any important geographical locations that were not cities or countries (e.g. multi-national regions or geological formations) would not be included as geographic terms if only GeoText is used to generate geographic terms.
Using Library of Congress Subject Headings
According to the MARC standard, subject added entries which contain a geographic name are to be recorded in the 651 field. In theory, simply extracting values from this field could yield useful geographic terms for each video. Unfortunately, this field is not found very often in the MARC records provided by the three streaming video vendors.
Subject added entries which are topical terms, found in the 650 field, provide another opportunity to extract this metadata, at least in some cases. According to the MARC standard, subfield a could include a topical term while subfield z is where geographic subdivisions for a subject heading are encoded.
Subfield z is exclusively meant for geographic subdivisions. Some videos may not have any geographic subdivisions in their subject headings, but this method would leverage the existing metadata for each video rather than require additional metadata be generated and then cleaned, as would be the case using either of the other methods listed above. In this particular case, both the 651 and 650 subfield z for each record were checked for geographic terms as part of the same script, with any terms found there automatically extracted.
Comparison and Evaluation
A systematic comparison of the three methods explored for the purposes of creating this streaming video site lays out the strengths and weaknesses of each method. First, Python was used to create 10 sample files each composed of 200 randomly selected records from each of the three vendors, extracting data from the MARC fields based on the mapping shown above. Then a single Python script applied the GeoText library to the title and summary of each video and the Stanford Named Entity Recognizer to the summary of each video. In addition to these two methods, PyMARC was used to extract the contents of 651 subfield a and 650 subfield z in the vendor-supplied MARC record. The results of these two were then compared to the geographic terms held in the 651 and 650 subfield z fields if either field was present.
The most noticeable difference between these two methods is the time required. Every test of the GeoText method took under a second to run, while all but one test of the NLTK method required over an hour and a half to run. While there were significant differences in time needed for each method, the number of videos for which geographic terms could be generated based on existing metadata were quite similar for each, as shown in the table below. These numbers only measure whether terms could be generated for a particular sample of videos, not the quality or utility of the terms generated. They are given along with the “tagging percentage,” which reflects the average percentage of videos for which geographic terms were generated by each of the three methods tested. These values are averages across the 10 samples, each consisting of 600 total records.
Table 2 Comparison of tagging percentage for the three enrichment methods tested.
| Videos with LC Terms | LC Tagging Percentage | Videos with NLTK terms | NLTK Tagging Percentage | Videos with GeoText Terms | GeoText Tagging Percentage | |
| Average | 158 | 26% | 286 | 48% | 294 | 49% |
| Median | 161 | 27% | 289 | 48% | 295 | 49% |
| Max | 171 | 29% | 301 | 50% | 318 | 53% |
In addition to determining whether any geographic terms could be generated, the results of each method were also compared with each other to identify any terms shared by two of the three methods or, in some cases, all three methods. The table below shows the results of these comparisons, again averaged across 10 sample files of 600 records each.
Table 3 Comparison of common terms between each of the three enrichment methods tested.
| NLTK/GeoText Common Terms | NLTK/MARC Common Terms | GeoText/MARC Common Terms | NLTK/GeoText/MARC
Common Terms |
|
| Average | 176 | 15 | 30 | 10 |
| Median | 175 | 15 | 30 | 11 |
| Max | 194 | 18 | 36 | 13 |
As shown in the table above, both the NLTK method and GeoText method were more likely to have generated the same geographic term for a particular video than they were to match any geographic terms provided in the MARC record. While a majority of the videos had few terms, looking at those for which both methods were able to generate many terms may offer guidance to those looking to enrich or create geographic terms for streaming videos based on textual metadata.
One video identified during testing generated a large number of terms in both methods and while it was an outlier in the dataset, it is worth discussing in greater detail because it contained many of the problems inherent in trying to generate this kind of metadata. In this case, the original MARC record provided by the vendor includes a brief summary of the plot of the video along with a listing of film festivals where the video won an award, including the city and country where the film festival took place. These names and places make up a significant number of the geographic terms generated by both methods.
The video in question is a documentary about the logging industry in Papua New Guinea. Both the NLTK/NER method and the GeoText library identified Papua New Guinea as a geographic term in the record while also including 13 other geographic terms which are merely festivals where the film was screened. While both of these methods correctly identified Papua New Guinea as a relevant geographic term because it was found in the summary, the term did not appear in either the 651 subfield a or 650 subfield z. The list of shared erroneous terms would have been longer if the GeoText library had not failed to recognize the erroneous term “Quebec” in the record because it will only recognize the term if it includes the diacritic (i.e., “Québec”).
This is of course just one example, but contained in this one record is a decent summary of the key challenges in enhancing metadata for streaming video based on existing textual records, particularly when working with many records at a time. The implicit assumption guiding the attempt to generate this kind of metadata was that geographic location is a meaningful concept from an access perspective, meaning both end users and site administrators would like to browse or group videos together by the geographic locations discussed in the video. While advancements in internet infrastructure have made streaming video over the web more technologically feasible, users are still dependent on text-based descriptions of those videos if they are to be found either by browsing particular subject and geographic headings or through keyword searching.
A closer look at videos for which the NTLK and GeoText identified at least one identical term reveals the challenges of working with either method. Below is a table of the terms generated by the NLTK and GeoText libraries for five videos which had at least one term in common between all three methods. The values are presented as they appear with no cleanup or deduplication, with the exception of adding the full country name in place of the two-letter country codes that are provided by the GeoText library.
Table 4 Sample of terms generated before cleanup for each of the three enrichment methods tested.
| 651/650$z Terms | NLTK Terms | GeoText Terms |
| ‘Brazil’, ‘Peru’, ‘Argentina’, ‘Brazil’ | ‘Brazil’, ‘Peru’, ‘Argentina’ | |
| ‘Australia’, ‘Australia’ | ‘Warren’, ‘Australia’, ‘United States’ | |
| ‘United’, ‘States’, ‘Alaska’, ‘St.’, ‘Patrick’, “‘s”, ‘Cathedral’, ‘New’, ‘York’, ‘JFK’, ‘Library’, ‘Denver’ |
‘New York’, ‘Denver’, ‘United States’ |
|
| ‘England’, ‘France’, ‘Virginia’, ‘Antietam’ | ‘Most’, ‘Virginia’, ‘Union’, ‘Lincoln’, ‘United States’, ‘France’, ‘Czech Republic’, ‘South Africa’ | |
| Australia. | ‘Earth’, ‘Australia’, ‘Gondwana’, ‘Earth’ | ‘Australia’ |
While both libraries identify cities and countries, the NLTK also included specific locations within those cities, such as St. Patrick’s Cathedral in New York City, while the GeoText library included seemingly erroneous countries such as the Czech Republic, which was included because the description contained the word “most” (the name of a town and district in the Czech Republic). Of the five videos shown here, only the last video had any geographic terms in the MARC record.
Relying solely on geographic terms in the MARC records might make for less cleanup, but there will also be fewer geographic terms. Conversely, either method of generating these terms from textual descriptions will require significant cleanup if the metadata is to be both comprehensible and useful to end users.
A table summarizing the benefits and drawbacks of each method can be found below:
Table 5 Benefits and drawbacks of each of the three methods tested.
| Method | Benefits | Drawbacks |
| NLTK |
|
|
| GeoText |
|
|
| Extraction from MARC fields |
|
|
As more audiovisual media becomes available, packaging the media with adequate and accurate metadata about the audiovisual object will be crucial to making the material accessible to users. The challenges faced in creating the site are indicative of how difficult it is to extract this information in batches if it is not provided from the beginning. Though there is nothing particularly cutting edge about the techniques used here from a programming perspective, since much of the searching was done with publicly available libraries, it would have been completely unnecessary if vendors had made full use of the MARC standard, which has fields for recording geographic coverage information, in creating the catalog records that were to be shared by their customers.
Table 6 Comparison of tagging percentage for three vendors tested.
| Videos with terms in MARC Record | Videos with NLTK Terms | Videos with GeoText Terms | |
| Vendor 1 | 10% | 55% | 56% |
| Vendor 2 | 40% | 38% | 41% |
| Vendor 3 | 30% | 51% | 50% |
The table above gives the percentage of videos which had geographic locations in either the 651 or 650 subfield z fields, averaged across the 10 random samples along with the number of videos for which the NLTK or GeoText library were able to identify geographic terms, also averaged across the 10 samples. Assuming that geographic information is an important access point for users, there are clear disparities in how different vendors choose to utilize the MARC standard, which in turn will impact which of the three methods above would be most effective should libraries endeavor to build a similar streaming video site as the one at Polk Library.
Extreme machine learning technologies suggest the possibility of automatic classification of audiovisual material [7]. For now, the nature of current discovery services demands that high quality textual metadata accompany audiovisual material if that material is to be accessible.
Despite the deficiencies of language to adequately reflect all dimensions of audiovisual material, textual description remains the primary access point for most web services. Even if digital technologies for processing and analyzing audiovisual material continue to improve, high-quality metadata and the technologies needed to process and enrich them at scale will remain an essential part of delivering audiovisual content to users.
Bibliography
[1] Duncan C, Peterson, E. 2012. You Ought to Be in Pictures: Bringing Streaming Video to Your Library. In: Bernhardt B, Hinds L, Strauch K, editors. Something’s Gotta Give: Charleson Conference Proceedings; 2011 Nov 2–5; Charleston. West Lafayette (IN): Purdue University Press. p. 453.
[2] Duncan CJ, Peterson ED. 2014. Creating a Streaming Video Collection for Your Library. Lanham (MD): Rowman & Littlefield. p. 41.
[3] Oomen J, Christaki A, Tzouvaras V. 2009. Television Heritage and the Semantic Web: Video Active and EUscreen. In: Dublin Core Metadata Initiative International Conference on Dublin Core and Metadata Applications; 2009 Oct 12-15; Seoul. p. 97–105, 98.
[4] Bird S, Klein E, Loper E. 2009. Natural Language Processing with Python. Boston (MA): O’Reilly Media Inc. http://nltk.org/book.
[5] Nadeau D, Sekine S. A Survey of Named Entity Recognition and Classification. 2009. In: Sekine S, Ranchhod E, editors. Named Entities: Recognition, Classification and Use. Amsterdam: John Benjamins Publishing Company. p. 3.
[6] Palenzuela YM. 2014. GeoText [Internet].[cited 2019 Jun 20]. Available from: https://geotext.readthedocs.io/en/latest/.
[7] Lu B, Wang G, Yuan Y, Han D. 2013. Semantic concept detection for video based on extreme learning machine. Neurocomputing 102:176-183.
About the Author
Patrick Harrington is a Metadata Specialist at the University of Minnesota and previously the Metadata Librarian at the University of Wisconsin-Oshkosh. He holds an MLIS from the iSchool at the University of Illinois.
Acknowledgments
Thank you to David Hietpas for his work in developing the streaming video site as well as assisting with the redesign of the metadata workflow.

Subscribe to comments: For this article | For all articles
Leave a Reply