by Daniel M. Coughlin, and Cynthia Hudson Vitale
Introduction
According to the Registry of Open Access (OA) Repository Mandates and Policies, within the United States there are over 80 institutionally based open access mandates and policies [1]. When Pennsylvania State University passed their OA policy in January 2020, it was critical to build upon past experiences and support the Penn State community in policy compliance with streamlined infrastructure and services. Penn State’s goals in passing and supporting the OA policy were multi-faceted. They wanted to: 1) increase the amount of open access content available worldwide; and 2) ensure compliance with the policy was as simple as possible for Penn State authors. Like many campus-based OA policies, the Penn State OA policy gives Penn State the non-exclusive right to make an electronic copy of the author’s accepted manuscript available to the public [3]. Authors are expected to provide this copy to the Penn State University Libraries no later than the date of publication . To note, authors do have the ability to obtain a waiver from this policy. In order to obtain a waiver a researcher can fill out a form that contains information about the publication and submit. Upon submission all requested waivers are granted.
Around the same time that Penn State passed its OA Policy, the Penn State Information Technology and Marketing & Communications departments began requesting author bibliometric data in order to populate faculty profiles, leveraging existing databases and information available through research information systems. The need to make the implementation of an Open Access policy with little overhead to our researchers, and the desire of other units on campus to access biographical and scholarly information from our faculty to populate these profiles had some commonality. In both use cases we were providing access to data from similar existing databases (most prominently Digital Measures, and Pure), there was frustration to access multiple APIs (Application programming interfaces) from teams on campus, and neither system had a complete picture of the scholarly output at Penn State. This scenario led us to develop our own system to mitigate these frustrations and solve these use cases.
Research information systems are not new or novel to the higher education ecosystem. OCLC defines RIM as, “the aggregation, curation, and utilization of metadata about research activities” in which “RIM systems collect and store metadata on research activities and outputs such as researchers and their affiliations; publications, datasets, and patents; grants and projects; academic service and honors; media reports; and statements of impact.” [3] Perhaps surprisingly, the term used to describe RIMs have evolved over the years or can mean different things in different geographic locations. These varying terms include university knowledge base, current research information systems (CRIS) [4], institutional information system (IIS), and research information management systems (RIM), among others. While there may be slight differences between each of these, the basic premise to aggregate research and make connections among entities remains consistent.
Within higher education university libraries have often been the leaders in developing and implementing these types of research information tools [5]. The 2018 OCLC Research and euroCRIS report Practices and Patterns in Research Information Management conducted a global survey on research information management practices – and found libraries to be key partners in RIMs especially in terms of “support for open access, metadata validation, training, and research data management”. In fact the survey found that over 91% of respondents listed “supporting institutional compliance for open science policies” as an extremely important, important, or somewhat important reason for developing a RIM system. This survey also found that institutions frequently used several systems to support research information workflows, both open-source, locally-developed, and commercial in nature.
Local landscape of RIMs
Not unlike many institutions of higher education, the Pennsylvania State University (Penn State) has purchased or locally developed many solutions and tools to find and aggregate research information about faculty on their campus. Penn State has a vendor product for faculty activity reporting (Watermark’s Digital Measures), searching for experts (Elsevier’s Pure), and has purchased bibliographic data from Clarivate, and has an API subscription for reading and writing content to faculty ORCID profiles. In addition, the University has a number of locally developed solutions, leveraging open access frameworks, for our data and open access repository (ScholarSphere), and our Graduate School Electronic Theses and Dissertations to name a couple. Penn State’s Researcher Metadata Database (RMD) integrates the data from these systems, and others, in order to power the workflow providing researchers an easy way to comply with the University’s Open Access Policy.
Penn State has used Watermark’s Digital Measures to aggregate faculty activity for over a decade with various academic units. Information gathered in this system is used for the promotion and tenure process and creates a University Dossier. For example, Digital Measures has publications, grants, courses taught, service, presentations, etc. that represent the scholarly activity of a faculty member at Penn State. Over the years we have onboarded nearly all the colleges and campuses to use this system for faculty annual reviews and university dossiers. This system is largely a manual one for data entry among faculty and support staff, and where possible we’ve created integration points for automating this data entry. As a system of record for faculty promotion and tenure, the data is considered to be high quality and annually reviewed and updated. However, this data is not complete. Not all faculty members within a department may use Digital Measures, because they may have already completed their career promotion and tenure process, or their department may not require annual reviews. Though the data is of high quality, and we have good coverage of our faculty, the system is not comprehensive.
Elsevier’s Pure was purchased as a solution to solve the problems related to searching for researchers at Penn State based on areas of expertise. The data in Pure is essentially backed from another Elsevier product, Scopus, and allows a search front end to sit on top of this data for faceted search results. The data from Scopus that powers Pure, is classified into four broad subject areas: life sciences – 15.4% of titles, physical sciences – 28% of titles, health sciences – 30.4% of titles, and social sciences & humanities – 26.2% of titles [6]. While neither Digital Measures or Pure was a complete picture of all faculty activity, they both provided a valuable source of information on the output of faculty at Penn State.
The combination of the OA policy and a clear need for a mechanism to aggregate Penn State author research demanded a common database of this type of information. Specifically, Penn State developed an in-house solution that leveraged existing databases and infrastructure to build a local research information management system (RIMs), named the Researcher Metadata Database. Our goals in this project were to:
- Make this process repeatable so we could continue to populate our database over time.
- Provide access to the data for individual colleges, and campuses via a RestFUL API to populate faculty profile and department web pages.
- Have a dashboard that is able to run reports for common data requests.
- Power our Open Access Workflow to increase the footprint of openly accessible research at Penn State.
Open Access Workflow
Building an OA Policy compliance workflow that placed minimal burden on Penn State authors was critical. Ultimately, the team developed four mechanisms to Penn State OA Policy compliance:
- Uploading an Open Access document as part of the annual process in Digital Measures to support the Open Access Policy.
- Uploading it to an Open Access repository and having that discovered via Open Access Button
- Following our workflow from RMD that asks a researcher to upload an open access copy of an article that previously was not openly accessible publication
- A researcher, unsolicited, uploads their article to ScholarSphere and keeps the permissions to make it openly accessible.
Considerable discussions and workflows were examined to ensure an implementation with minimal complexity to the researcher, while also being a sustainable method for support staff. For example, allowing researchers to reply to an automated email with an attached document would be extremely simple; however, if there are multiple publications it could make sorting out which paper belongs to which citation unnecessarily difficult. Ultimately, the simplest workflow was to email researchers a listing of publications that are applicable to the Open Access Policy, which then linked to our Researcher Metadata Database. Researchers may submit a paper to our institutional repository, provide an existing open access URL for publication, or submit a waiver to the policy.
Now that the RMD has this updated information it is able to determine that researchers should not be asked about these papers again as we remove it from our list of publications that is not openly accessible. Figure 1 displays the workflow from a number of the systems discussed, in and out of RMD as well as the attributes or metadata fields that are being sent to the system. If a publication does not have an openly accessible URL, an automated email is sent to the researcher requesting a copy that will then be deposited into our Institutional Repository, ScholarSphere.
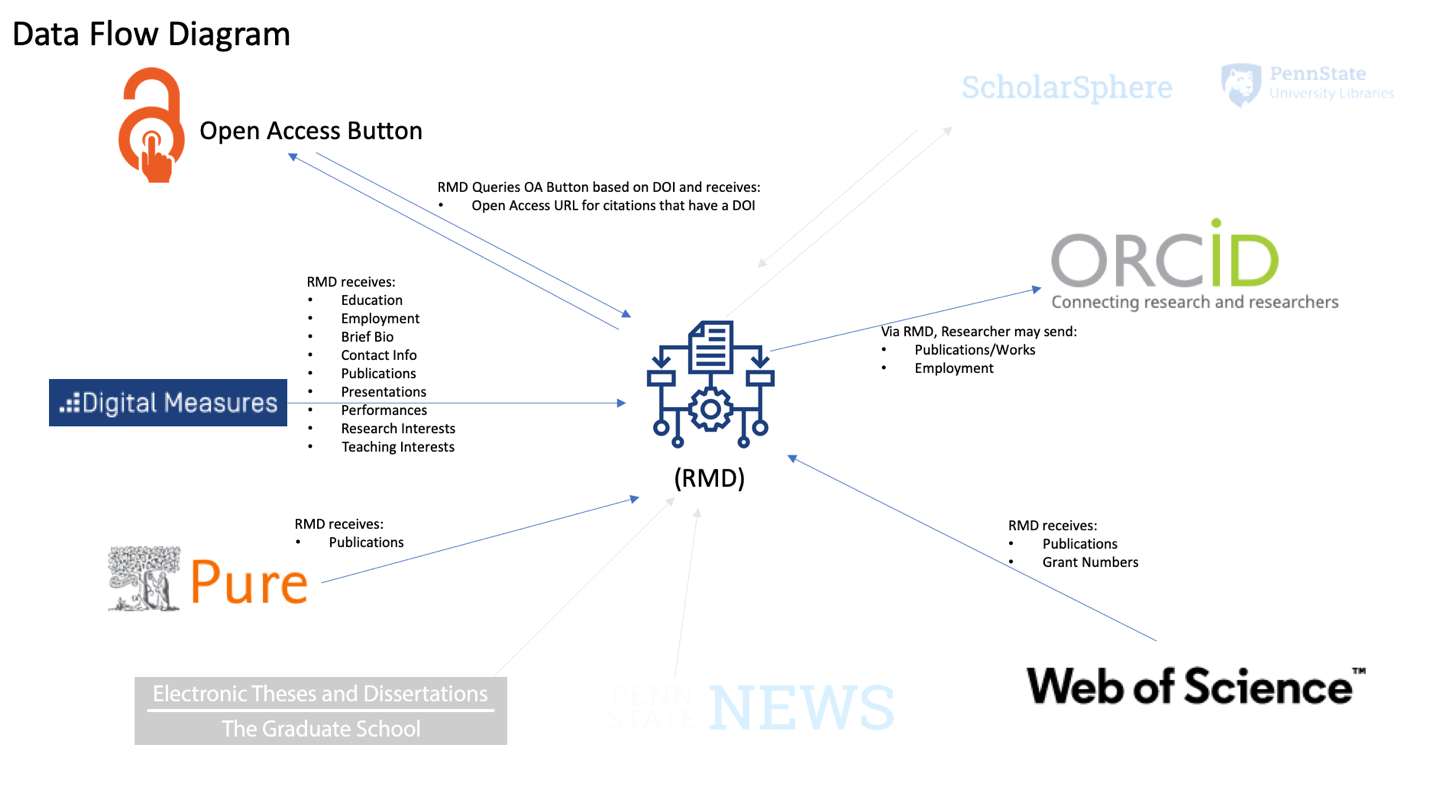
Figure 1. Data Flow of Penn State’s Researcher Metadata Database.
To date, there are over 300K publications records in the Researcher Metadata Database (RMD), and over 65% of those have a digital object identifier (DOI). Open Access Button provides access to their database of millions of Open Access articles by way of DOI query. The initial work in May of 2020 found that nearly 20% of Penn State research is openly accessible, since then that number has grown to 34.5% as of July 2021. Open Access Button provides the RMD system the insight to know what publications have openly accessible URLs based on Penn State’s policy and the publication date of the work and if the work does or does not have an openly accessible link.
ORCID API Subscription
Another mechanism or tool used to reduce faculty burden in meeting the Penn State OA Policy was through the use of the ORCID API. ORCID provides a persistent digital identifier (an ORCID iD) that an author owns and controls, and that distinguishes them from every other researcher. An author can connect their iD with their professional information — affiliations, grants, publications, peer review, and more. Additionally, the iD may be used to share information with other systems, ensuring they get recognition for all their contributions, saving time and hassle, and reducing the risk of errors.
One of the first ways in which Penn State leveraged the ORCID API was in connection with a user’s local, Penn State Access Account. If the user does not have an ORCID iD, then the application will create an ORCID iD and the subsequent link to the Penn State Access Account. Additionally, when linking the accounts, the user gives access to Penn State to update their ORCID records with works, grants, employment, etc.
More recently, we connected Digital Measures to the ORCID API. In this connection, Digital Measures can read content from ORCID and import that content, but it cannot write content that is stored in Digital Measures. This limitation makes it useful for a smaller fraction of our faculty that are actively updating their ORCID record. Our difficulty here was again in creating an easy way for faculty to get a large amount of their content into ORCID.
ORCID Integration
As we worked with other units on campus to discuss RMD, the Office of the Senior Vice President for Research approached us to find out if we could help with the pending NSF grant requirements, specifically the mandate for SciENcv, a researcher profile system for those who seek federal grants, on bio sketches and current and pending grants.
National Science Foundation (NSF) grant requirements now allow faculty to fill out a downloadable PDF for their bio sketch or they can import content that exists in their ORCID profile. However, many faculty do not have content in their ORCID profile, and either do not have an ORCID iD or have not linked their ORCID iD with their Penn State Access Account. RMD leveraged the ORCID API to push data from RMD to ORCID at the request of the researcher. Now, on the same page that provides an Penn State author the ability to upload content to the institutional repository, ScholarSphere, the researcher can also push their citation to ORCID (Figure 2). Additionally, from a separate screen, a faculty member can push their organization to ORCID as well. Through RMD a faculty member can grant permission to RMD to update their ORCID profile, and once that authorization is complete, they can click a button to add these records to their ORCID profile. Once these works are in their ORCID profile, they can be imported into SciENcv and linked into their NSF bio sketch.
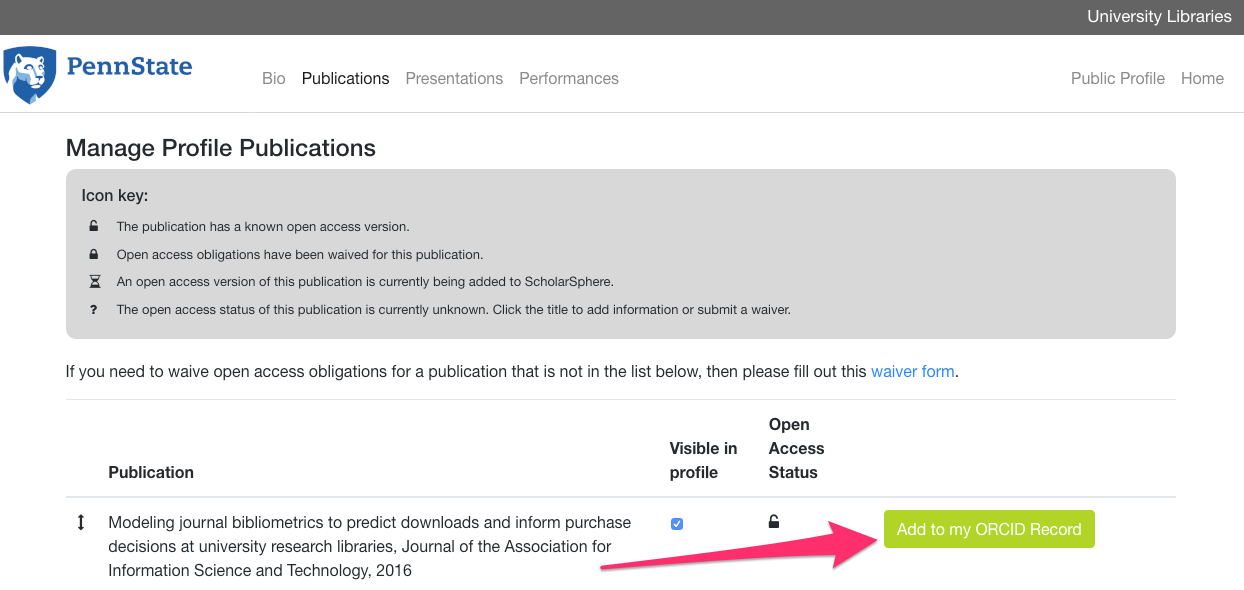
Figure 2.
Researcher Metadata Database ORCID iD integration to push works to an ORCID Profile.
The selected fields (researchers, publications, and organization history) are relevant to the NSF grant requirements, and although it is not possible to directly integrate with SciENcv, this option allows a researcher the capability to push the buttons to upload citations rather than manually enter them into ORCID or a PDF. Additionally, if other large granting agencies such as National Institute of Health (NIH) follow a similar pattern then the application will be in a good position to provide a solution.
Providing Access
An additional goal of the RMD was to provide access to our data. There are many other colleges and campuses at Penn State that would like to access this information for the purpose of faculty and department web pages (Figure 3). There is a perpetual challenge faced by the Marketing and Communications departments of these units to keep information up to date. Given that one of the sources for our data is from Digital Measures, our faculty use this system for the process of annual review and promotion and tenure, so the content in there is likely to be high quality and up to date. Integrating this data with content from other systems, such as Open Access Button, the RMD has been able to not only provide citations, but also provide links to the actual content of a citation that is not behind a paywall. This increases the exposure of our researcher’s scholarship and their affiliated department, institute, lab, etc.

Figure 3. Penn State’s Food Science Department using data from the Researcher Metadata API to publish citations and links to their Open Access copies.
Challenges
Throughout this work two of the largest challenges have been the duplication of data and disambiguation of researchers. Because content comes from so many different sources, there is bound to be a subset of that data that has already been entered into many of these systems. In fact, a large source of frustration for researchers is wondering why they may have to enter data into one system if it already exists in another.
In many of the more recent published academic journal articles in RMD there are identifiers for the papers (Digital Object Identifiers, DOI) that can be automatically scanned and matched for sameness. However, if the information is manually entered into a system such as Digital Measures, and a user does not enter a DOI it is more difficult to programmatically determine if the paper is a duplication of another. This scenario has created a two-part process to de-duplicate papers. First, the system applies a matching algorithm to do an initial pass of similar or like metadata for the article’s titles, authors, and DOIs to merge duplicates. Then, the remaining papers are manually reviewed and de-duped.
Our data indicates that between 2015-2019, there was a rise in papers with DOIs from 63% to 78%; however, this means 20+% of papers still do not have a DOI. At eight and ten thousand papers being produced at Penn State in a year, this amounts to potentially thousands of duplicates annually.
Publications that we have imported via Digital Measures and Pure are linked to a Penn State researcher. This helps disambiguate these publications because we know they belong to a particular Penn State researcher. However, in the case of Clarivate, the data doesn’t have a link back to the Penn State author. The system can search for matches that may exist in the database and assume based on matching up both sets of data.
In the case where the system is unable to determine the Penn State author with certainty, the system will guess and make the publication visible to only the Penn State author. The researcher can either confirm or deny that paper within the same interface that allows them to push content to ORCID and ScholarSphere.
These two issues reflect the importance of identifiers in accurately identifying the research output for an institution. It’s important to have a universal identifier for the researcher, such as ORCID, as well as an identifier for the output, such as a DOI. A lack of these identifiers creates a tremendous amount of manual de-duplication. The initial de-duplication process required nearly 40,000 citations to de-duplicate. Once this problem is solved, future updates to the data will not produce anything more than a couple hundred at most. The problem is ongoing, but after an initial challenge, it is much more manageable.
Future Developments
There are several areas to (1) enhance RMD, (2) further reduce Penn State author burden, and (3) support the compliance mechanism for the Penn State OA Policy moving forward. As previously mentioned, it was integral to provide as many ways for a Penn State author to make their work openly accessible, while also automating these modes of compliance, where possible. For example, if a Penn State author uploads their openly accessible article into Digital Measures, it is a manual process for the compliance team to deposit a copy into ScholarSphere and set it to open access. Future developments will focus on automating that workflow. Alternatively, the process to upload a publication to ScholarSphere via RMD now takes place in a more seamless way and eliminates the need for support staff to update URLs manually.
Another future development will be to create an OAI-PMH endpoint that will allow Open Access Button to download content from ScholarSphere. And finally, RMD will be able to write links to OA articles back into Digital Measures and have the University Dossier not only print researcher’s citations, but also links to the content.
Ultimately, the Researcher Metadata Database has a process that is repeatable so that information can be updated over time. The system provides access to the data via a standardized API and can run reports for common requests on data for internal/University stakeholders. There is a workflow that will increase the footprint of openly accessible research at Penn State and has provided a starting point for knowing what is already open and sharing that content via faculty and department websites. All of this has enabled the libraries to be in a position to help reduce faculty burden in other areas, such as integrating with ORCID to publish information that can be used for NSF grant proposals.
Acknowledgements: Nicole Gampe, Alex Kiessling, Laura DeAntonio, Kevin Fraccalvieri, Justin Patterson, Adam Wead, Brandy Karl, Ana Enriquez, Seth Erickson, Briana Ezray, Eric Durante, Natalie Nash, Chet Swalina, Scott Woods
About the authors
Daniel Coughlin (dmc186@psu.edu) has worked in Information Technology for almost 20 years and nearly half of that in Libraries. He has spent many years as a software developer, primarily working on web applications. Currently, Dan is the department head for Libraries Strategic Technologies at University Libraries, Penn State and in his free time is typically trying to chase or find his dog, Millie, in Rothrock State Forrest.
Cynthia Hudson Vitale (cvitale@arl.org) is the Director of Scholars and Scholarship at the Association of Research Libraries. In this role she collaborates with key partners, allies, and joint ventures to promote ARL’s broad mission of open, equitable scholarly communication, information stewardship, and publishing. Prior to joining ARL she worked for over 15 years in research libraries building and managing services for computational research and open publishing.
Notes
[1] See: http://roarmap.eprints.org/cgi/search/archive/advanced?screen=Search&dataset=archive&country=840&policymaker_type=research_org&policymaker_name_merge=ALL&policymaker_name=&policy_adoption=&policy_effecive=&mandate_content_types_merge=ANY&apc_fun_url_merge=ALL&apc_fun_url=&satisfyall=ALL&order=policymaker_name&_action_search=Search
[2] See: https://policy.psu.edu/policies/ac02
[3] Bryant, Rebecca, Anna Clements, Carol Feltes, David Groenewegen, Simon Huggard, Holly Mercer, Roxanne Missingham, Maliaca Oxnam, Anne Rauh and John Wright. 2017. Research Information Management: Defining RIM and the Library’s Role. Dublin, OH: OCLC Research. https://doi.org/10.25333/C3NK88.
[4] Sivertsen G. (2019) Developing Current Research Information Systems (CRIS) as Data Sources for Studies of Research. In: Glänzel W., Moed H.F., Schmoch U., Thelwall M. (eds) Springer Handbook of Science and Technology Indicators. Springer Handbooks. Springer, Cham. https://doi.org/10.1007/978-3-030-02511-3_25
[5] Dempsey, Lorcan. “Research Information Management Systems: A New Service Category”, LorcanDempsey.net, October 26, 2014. https://www.lorcandempsey.net/orweblog/research-information-management-systems-a-new-service-category/
[6] Scopus Content Coverage Guide. https://www.elsevier.com/__data/assets/pdf_file/0007/69451/Scopus_ContentCoverage_Guide_WEB.pdf. Accessed July 31, 2021.

Subscribe to comments: For this article | For all articles
Leave a Reply